これは、このセクションの複数ページの印刷可能なビューです。 印刷するには、ここをクリックしてください.
W&B アプリ UI リファレンス
- 1: パネル
- 1.1: 折れ線グラフ
- 1.1.1: 折れ線グラフのリファレンス
- 1.1.2: ポイント集約
- 1.1.3: スムーズなラインプロット
- 1.2: 棒グラフ
- 1.3: 並列座標
- 1.4: 散布図
- 1.5: コードを保存して差分を取る
- 1.6: パラメータの重要度
- 1.7: run メトリクスを比較する
- 1.8: クエリパネル
- 1.8.1: オブジェクトを埋め込む
- 2: カスタムチャート
- 2.1: チュートリアル: カスタムチャートの使用
- 3: ワークスペース、セクション、パネル設定を管理する
- 4: 設定
- 4.1: ユーザー設定を管理する
- 4.2: 請求設定を管理する
- 4.3: チーム設定を管理する
- 4.4: メール設定を管理する
- 4.5: チームを管理する
- 4.6: ストレージを管理する
- 4.7: システム メトリクス
- 4.8: 匿名モード
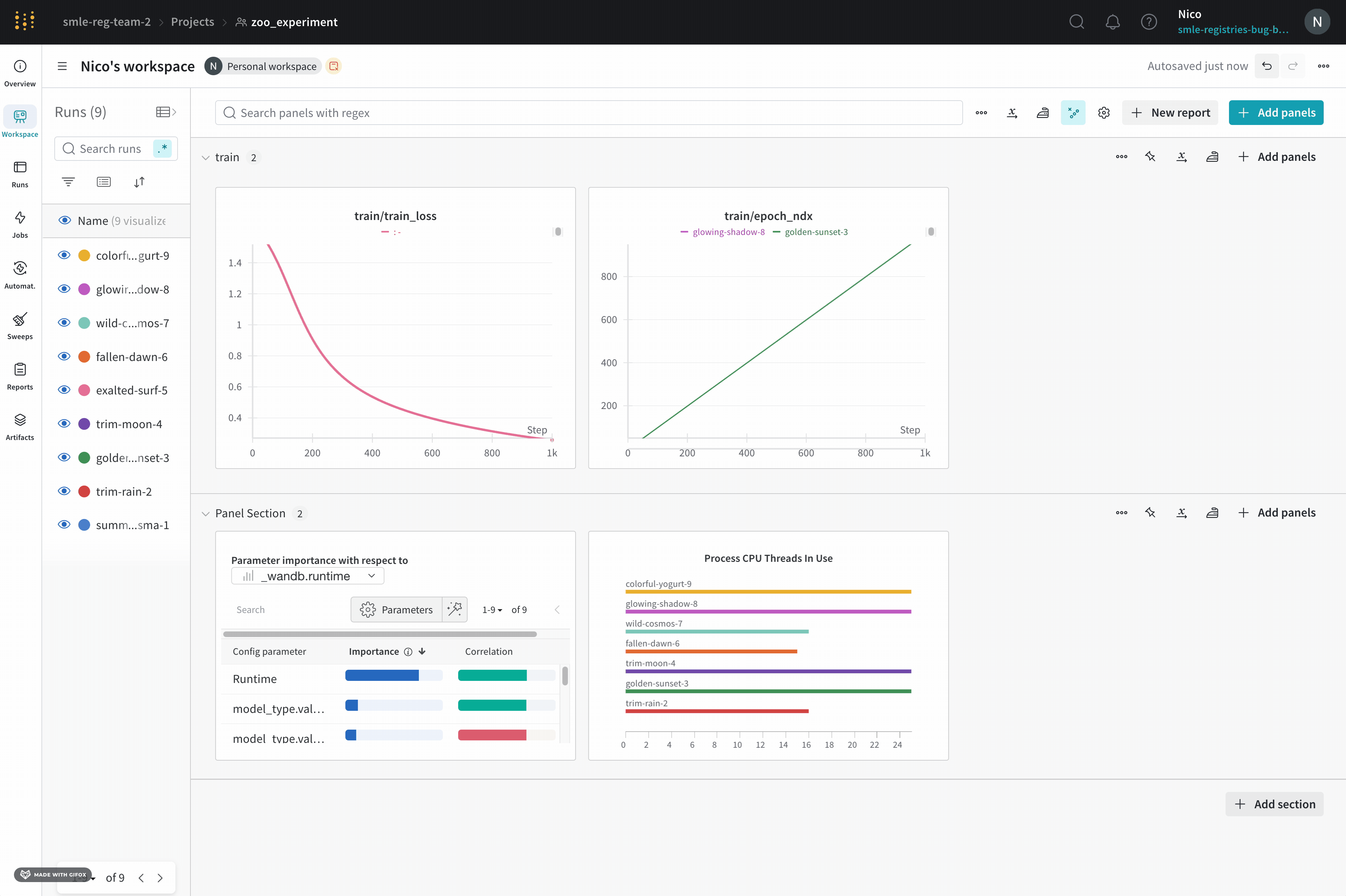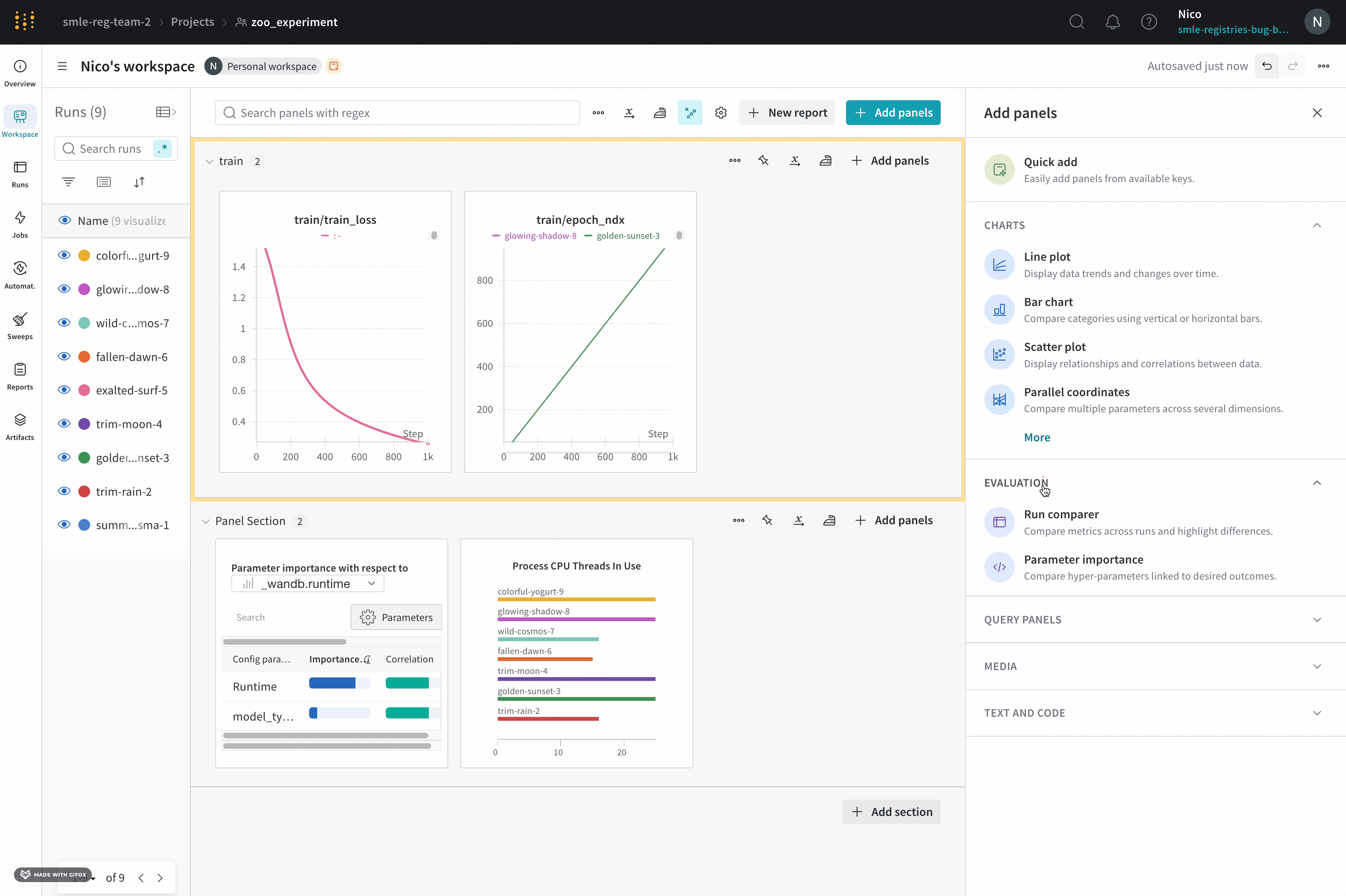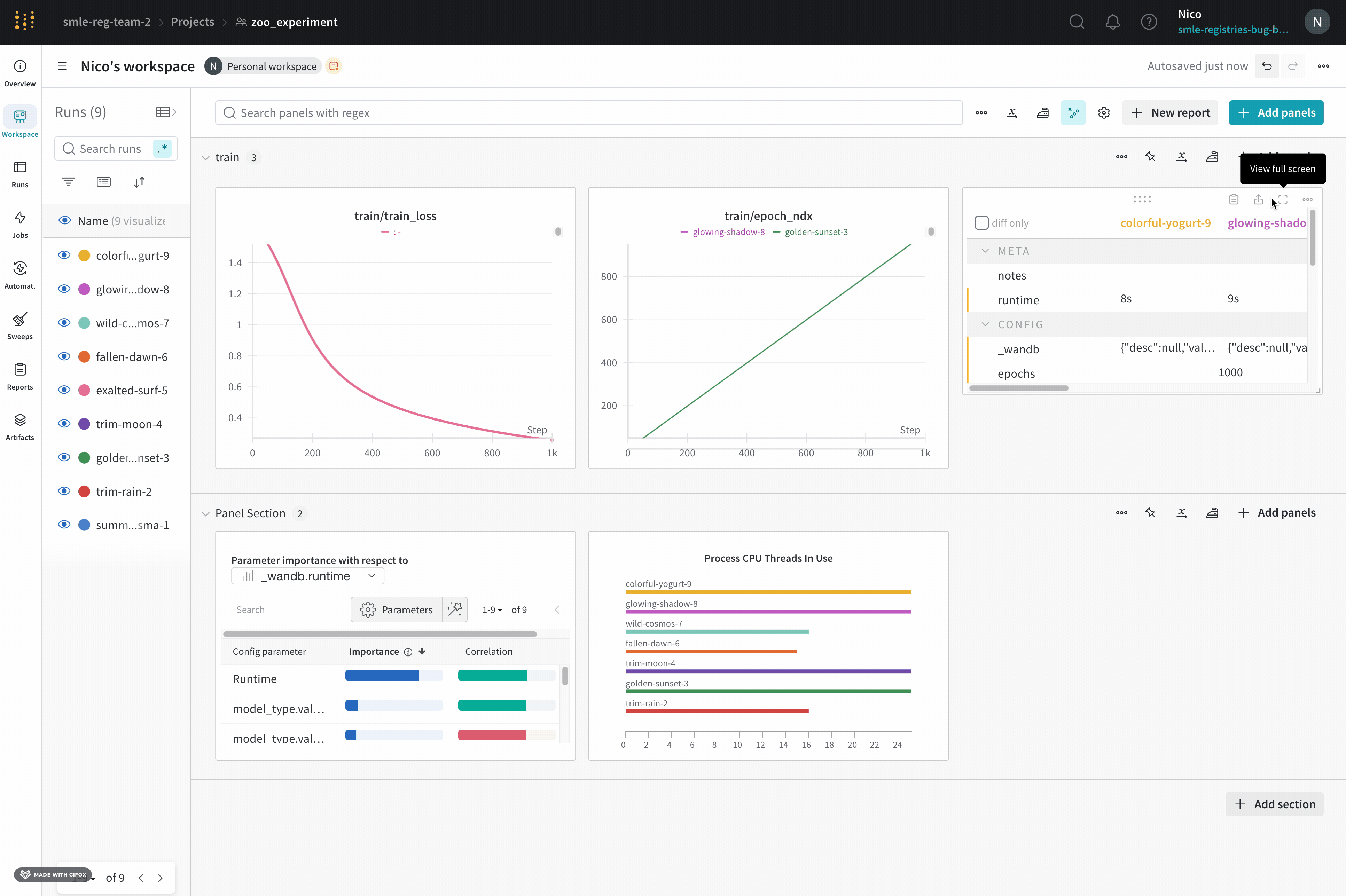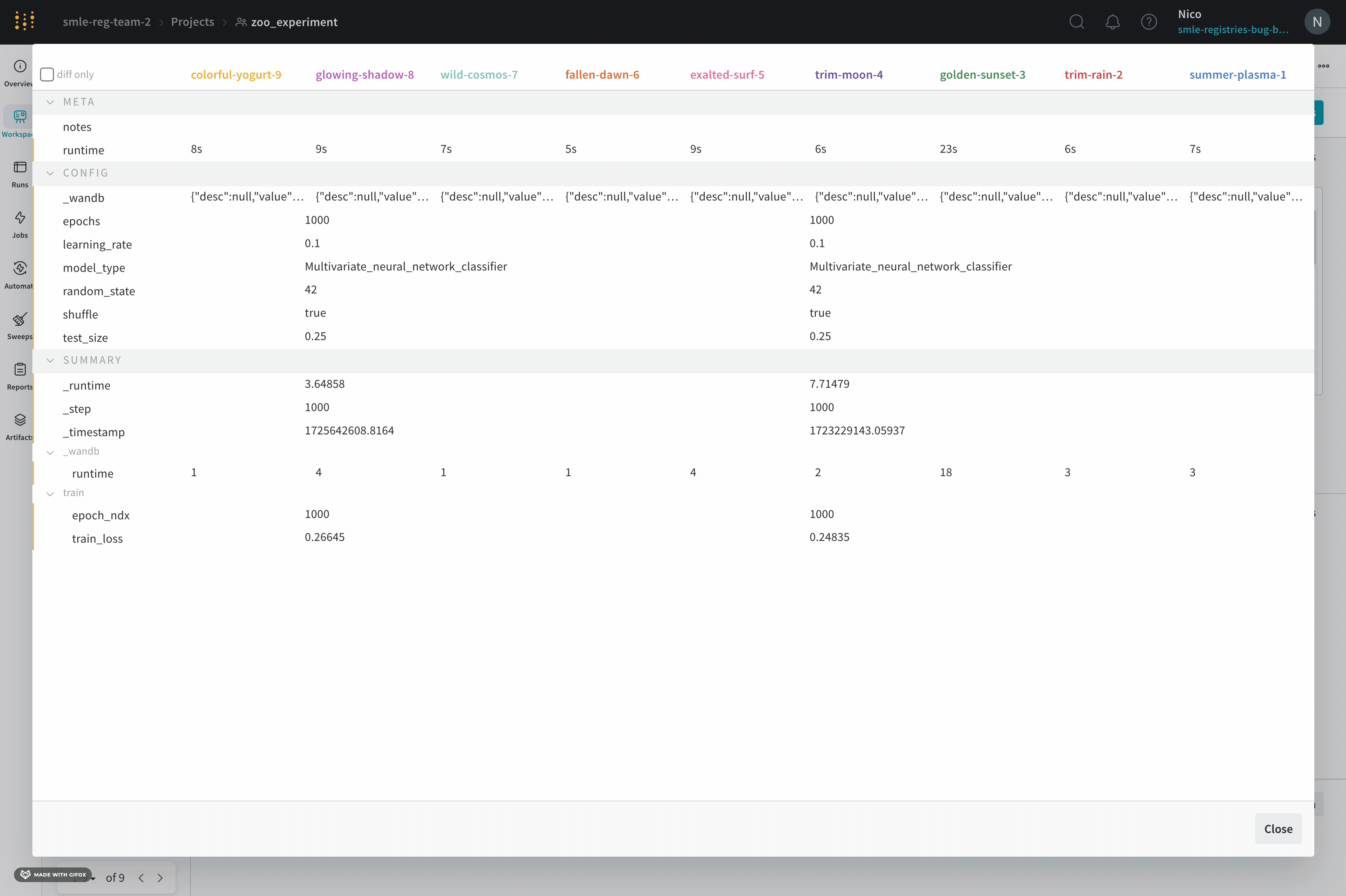
1 - パネル
ワークスペースパネルの可視化機能を使用して ログされたデータ をキーごとに探り、ハイパーパラメーターと出力メトリクスの関係を可視化することなどができます。
ワークスペースモード
W&B Projects は2つの異なるワークスペースモードをサポートしています。ワークスペース名の横のアイコンがそのモードを示しています。
| アイコン | ワークスペースモード |
|---|---|
 |
Automated workspaces はプロジェクト内でログされたすべてのキーに対して自動的にパネルを生成します。自動ワークスペースを選ぶ理由:
|
 |
Manual workspaces は最初は空白で、ユーザーによって意図的に追加されたパネルのみが表示されます。手動ワークスペースを選ぶ理由:
|
ワークスペースがパネルを生成する方法を変更するには、ワークスペースをリセットするを行います。
ワークスペースの変更を元に戻す
ワークスペースの変更を元に戻すには、Undo ボタン(左向きの矢印)をクリックするか、CMD + Z (macOS) または CTRL + Z (Windows / Linux) を入力します。ワークスペースをリセットする方法
ワークスペースのリセット手順:
- ワークスペースの上部でアクションメニュー
...をクリックします。 - Reset workspace をクリックします。
ワークスペースレイアウトの設定
ワークスペースレイアウトを設定するには、ワークスペースの上部近くにある Settings をクリックし、次に Workspace layout をクリックします。
- 検索時に空のセクションを隠す(デフォルトではオン)
- パネルをアルファベット順に並べ替え(デフォルトではオフ)
- セクションの編成(デフォルトでは最初のプレフィックスでグループ化)。この設定を変更するには:
- 鍵アイコンをクリックします。
- セクション内のパネルをどのようにグループ化するか選択します。
ワークスペース内のラインプロットのデフォルトを設定するには、Line plots を参照してください。
セクションのレイアウトを設定する
セクションのレイアウトを設定するには、その歯車アイコンをクリックし、次に Display preferences をクリックします。
- ツールチップ内での色付き run 名前のオン/オフ(デフォルトではオン)
- 仲間のチャートツールチップでハイライトされた run のみを表示(デフォルトではオフ)
- ツールチップに表示される run の数(単一の run、すべての run、または Default)
- プライマリチャートツールチップでの run 名前の完全な表示(デフォルトではオフ)
パネルを全画面表示する
全画面表示モードでは、run 選択が表示され、パネルは通常の1000バケツではなく、10,000バケツでの完全な精度のサンプリングモードプロットを使用します。
全画面表示モードでパネルを表示するには:
- パネルの上にカーソルを合わせます。
- パネルのアクションメニュー
...をクリックし、次に全画面ボタンをクリックします。これはビューファインダーまたは四角の四隅を示すアウトラインのように見えます。
- 全画面表示モードでパネルを表示している間に パネルを共有する と、生成されたリンクは自動的に全画面表示モードで開きます。
全画面表示モードからパネルのワークスペースに戻るには、ページ上部の左向き矢印をクリックします。
パネルを追加する
このセクションでは、ワークスペースにパネルを追加するさまざまな方法を示します。
パネルを手動で追加する
パネルをワークスペースに一度に1つずつ、グローバルまたはセクションレベルで追加できます。
- グローバルにパネルを追加するには、パネル検索フィールドの近くにあるコントロールバーで Add panels をクリックします。
- セクションに直接パネルを追加するには、セクションのアクション
...メニューをクリックし、次に + Add panels をクリックします。 - 追加するパネルの種類を選択します。例えばチャート。パネルの設定詳細が表示され、デフォルトが選択されます。
- 必要に応じて、パネルとその表示設定をカスタマイズします。設定オプションは選択したパネルのタイプに依存します。各パネルタイプのオプションについてもっと知るには、以下の関連セクションを参照してください。Line plots や Bar plots など。
- Apply をクリックします。
クイック追加でパネルを追加する
Quick add を使用して、選択した各キーに対して自動的にパネルを追加できます。これをグローバルまたはセクションレベルで行うことができます。
- グローバルに Quick add を使用してパネルを追加するには、パネル検索フィールド近くのコントロールバーで Add panels をクリックし、それから Quick add をクリックします。
- セクションに直接 Quick add を使用してパネルを追加するには、セクションのアクション
...メニューをクリック、Add panels をクリックし、それから Quick add をクリックします。 - パネルのリストが表示されます。チェックマークのある各パネルはすでにワークスペースに含まれています。
- 利用可能なすべてのパネルを追加するには、リストの上の Add
panels ボタンをクリックします。Quick Add リストが閉じられ、新しいパネルがワークスペースに表示されます。 - リストから個別にパネルを追加するには、そのパネルの行にカーソルを合わせ、それから Add をクリックします。追加したい各パネルについてこのステップを繰り返し、Quick Add リストの右上にある X をクリックして閉じます。新しいパネルがワークスペースに表示されます。
- 利用可能なすべてのパネルを追加するには、リストの上の Add
- 必要に応じて、パネルの設定をカスタマイズします。
パネルを共有する
このセクションでは、リンクを使ってパネルを共有する方法を示します。
リンクを使ってパネルを共有するには、次のどちらかを行います:
- パネルを全画面表示モードで表示している間、ブラウザからURLをコピーします。
- アクションメニュー
...をクリックし、Copy panel URL を選択します。
ユーザーまたはチームにリンクを共有します。リンクにアクセスすると、そのパネルは 全画面モード で開きます。
全画面表示モードからパネルのワークスペースに戻るには、ページ上部の左向き矢印をクリックします。
プログラムでパネルの全画面リンクを構成する
特定の状況、たとえば オートメーションを作成する場合などに、パネルの全画面URLを含めると便利です。このセクションでは、パネルの全画面URLの形式を示します。以下の例では、ブラケット内の entity, project, panel, section 名を置き換えてください。
https://wandb.ai/<ENTITY_NAME>/<PROJECT_NAME>?panelDisplayName=<PANEL_NAME>&panelSectionName=<SECTON_NAME>
同じセクション内の複数のパネルが同じ名前を持つ場合、このURLはその名前を持つ最初のパネルを開きます。
パネルを埋め込んでソーシャルメディアで共有する
ウェブサイトにパネルを埋め込んだり、ソーシャルメディアで共有するには、そのパネルがリンクを持つ誰でも閲覧できる状態でなければなりません。プロジェクトがプライベートであれば、そのプロジェクトのメンバーのみがパネルを閲覧できます。プロジェクトが公開されていれば、リンクを持つ誰でもそのパネルを閲覧できます。
ソーシャルメディアでパネルを埋め込んで共有するコードを取得する手順:
- ワークスペースからパネルの上にカーソルを合わせ、そのアクションメニュー
...をクリックします。 - Share タブをクリックします。
- 招待した人だけにアクセス権 を リンクを持つ全員が閲覧可能 に変更します。そうしないと次のステップのオプションは使用できません。
- Twitterで共有, Redditで共有, LinkedInで共有, または 埋め込みリンクをコピー を選択します。
パネルレポートをメールで送信する
単一のパネルをスタンドアロンのレポートとしてメールする手順:
- パネルの上にカーソルを合わせ、パネルのアクションメニュー
...をクリックします。 - Share panel in report をクリックします。
- Invite タブを選択します。
- メールアドレスまたはユーザー名を入力します。
- 必要に応じて、** can view** を can edit に変更します。
- Invite をクリックします。W&B はユーザーに対し、共有するパネルのみを含むレポートのクリック可能なリンクをメールで送信します。
パネルを共有する場合とは異なり、受信者はこのレポートからワークスペースにアクセスできません。
パネルを管理する
パネルを編集する
パネルを編集する手順:
- 鉛筆アイコンをクリックします。
- パネルの設定を変更します。
- パネルを別のタイプに変更するには、タイプを選択し、設定を構成します。
- Apply をクリックします。
パネルを移動する
異なるセクションにパネルを移動するには、パネルのドラッグハンドルを使用します。リストから新しいセクションを選択するには:
- 必要に応じて、最後のセクションの後に Add section をクリックして新しいセクションを作成します。
- パネルのアクション
...メニューをクリックします。 - Move をクリックし、新しいセクションを選択します。
また、ドラッグハンドルを使用して、セクション内のパネルを並べ替えることもできます。
パネルを複製する
パネルを複製する手順:
- パネルの上部でアクション
...メニューをクリックします。 - Duplicate をクリックします。
必要に応じて、複製したパネルを カスタマイズ または 移動 することができます。
パネルを削除する
パネルを削除する手順:
- パネルの上にマウスを移動します。
- アクション
...メニューを選択します。 - Delete をクリックします。
手動ワークスペースからすべてのパネルを削除するには、そのアクション ... メニューをクリックし、Clear all panels をクリックします。
自動または手動ワークスペースからすべてのパネルを削除するには、ワークスペースをリセットします。Automatic を選択すると、デフォルトのパネルセットから開始します。Manual を選択すると、パネルのない空のワークスペースから開始します。
セクションを管理する
デフォルトでは、ワークスペース内のセクションはキーのログ階層を反映しています。ただし、手動ワークスペースでは、一度パネルを追加し始めるとセクションが表示されます。
セクションを追加する
セクションを追加するには、最後のセクションの後に Add section をクリックします。
既存のセクションの前または後に新しいセクションを追加するには、セクションのアクション ... メニューをクリックし、New section below または New section above をクリックします。
セクションのパネルを管理する
多くのパネルを持つセクションは、Standard grid レイアウトを使用している場合デフォルトでページ分割されます。ページに表示されるパネルの数は、パネルの設定とセクション内のパネルのサイズによります。
- セクションが使用しているレイアウトを確認するには、セクションのアクション
...メニューをクリックします。セクションのレイアウトを変更するには、Layout grid セクションで Standard grid または Custom grid を選択します。 - パネルのサイズを変更するには、パネルの上にカーソルを合わせて、ドラッグハンドルをクリックし、パネルのサイズを調整します。
- セクションが Standard grid を使用している場合、1つのパネルのサイズを変更すると、そのセクション内のすべてのパネルのサイズが変更されます。
- セクションが Custom grid を使用している場合、それぞれのパネルのサイズを個別にカスタマイズできます。
- ページに表示するパネルの数をカスタマイズするには:
- セクションの上部で 1 to
of をクリックします。ここで<X>は表示中のパネル数、<Y>はパネルの合計数です。 - 1ページに表示するパネルの数を最大100まで選択します。
- 多くのパネルがある場合にすべてのパネルを表示するには、パネルを Custom grid レイアウトを使用するように構成します。セクションのアクション
...メニューをクリックし、Layout grid セクションで Custom grid を選択します。 - セクションからパネルを削除するには:
- パネルにカーソルを合わせ、そのアクション
...メニューをクリックします。 - Delete をクリックします。
ワークスペースを自動ワークスペースにリセットすると、削除されたすべてのパネルが再び表示されます。
セクション名を変更する
セクション名を変更するには、そのアクション ... メニューから Rename section をクリックします。
セクションを削除する
セクションを削除するには、その ... メニューをクリックして Delete section をクリックします。これにより、セクションとそのパネルも削除されます。
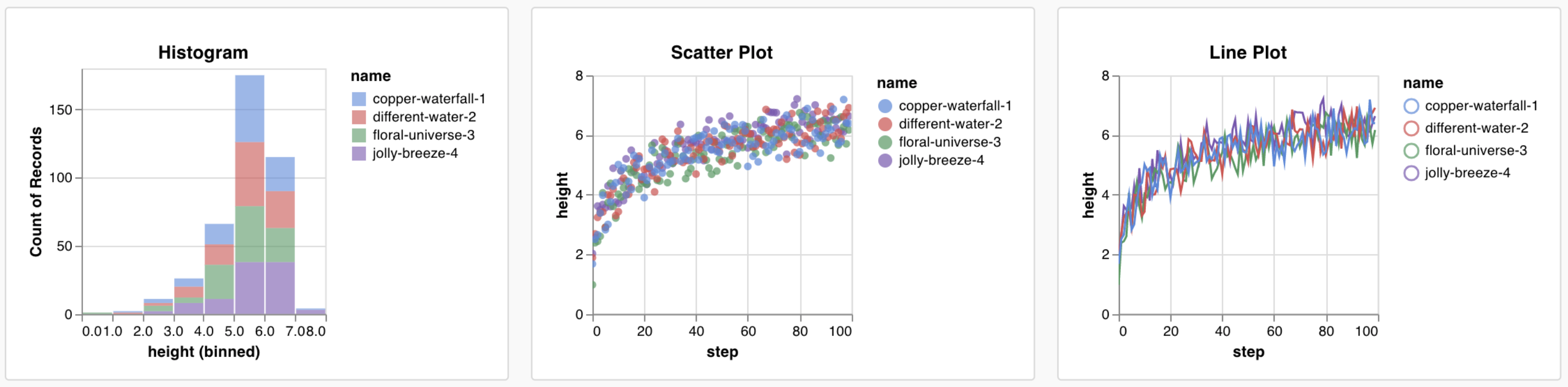
1.1 - 折れ線グラフ
ラインプロットは、wandb.log() でメトリクスを時間経過とともにプロットするとデフォルトで表示されます。複数のラインを同じプロットで比較したり、カスタム軸を計算したり、ラベルをリネームしたりするために、チャート設定をカスタマイズできます。
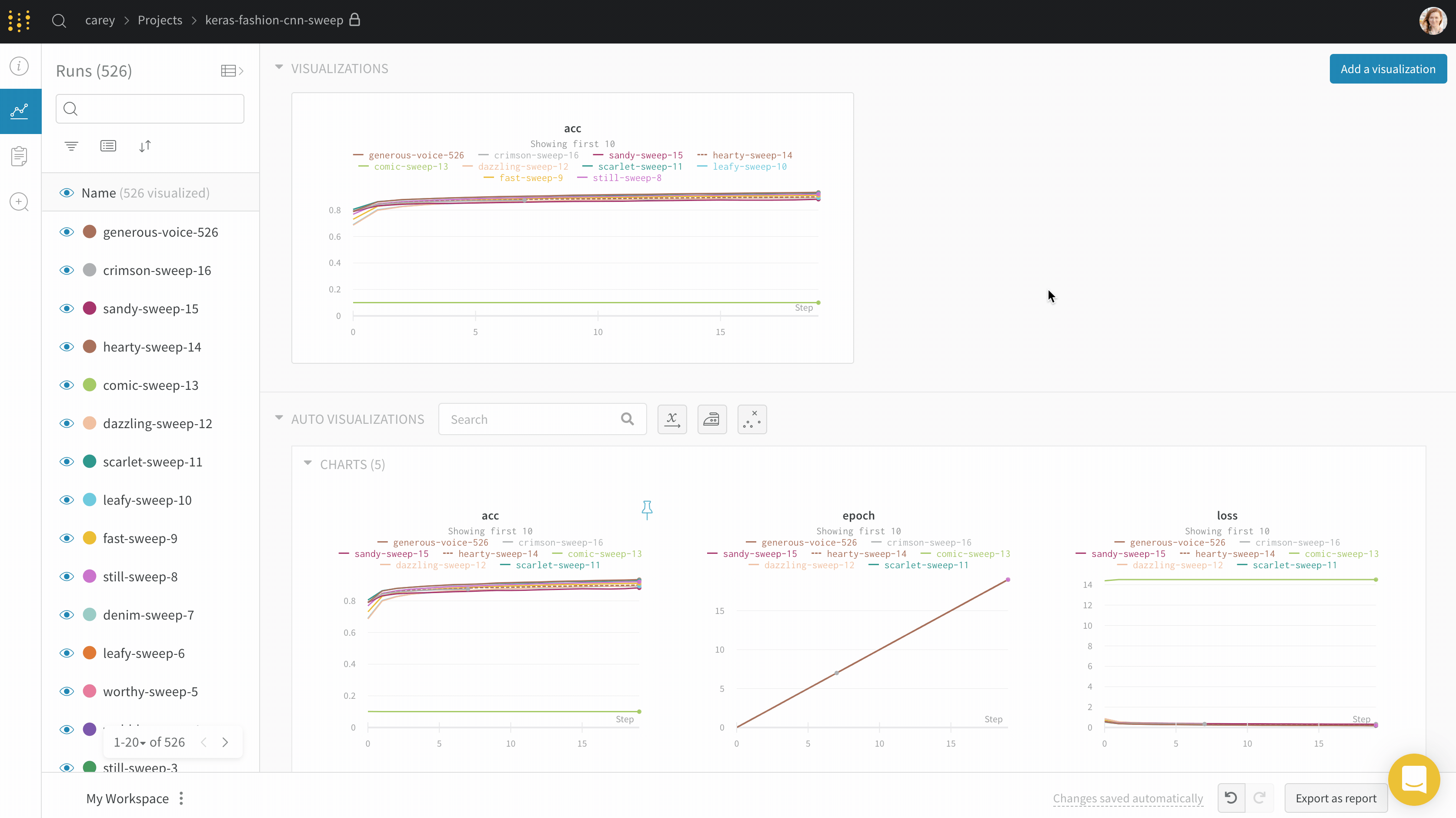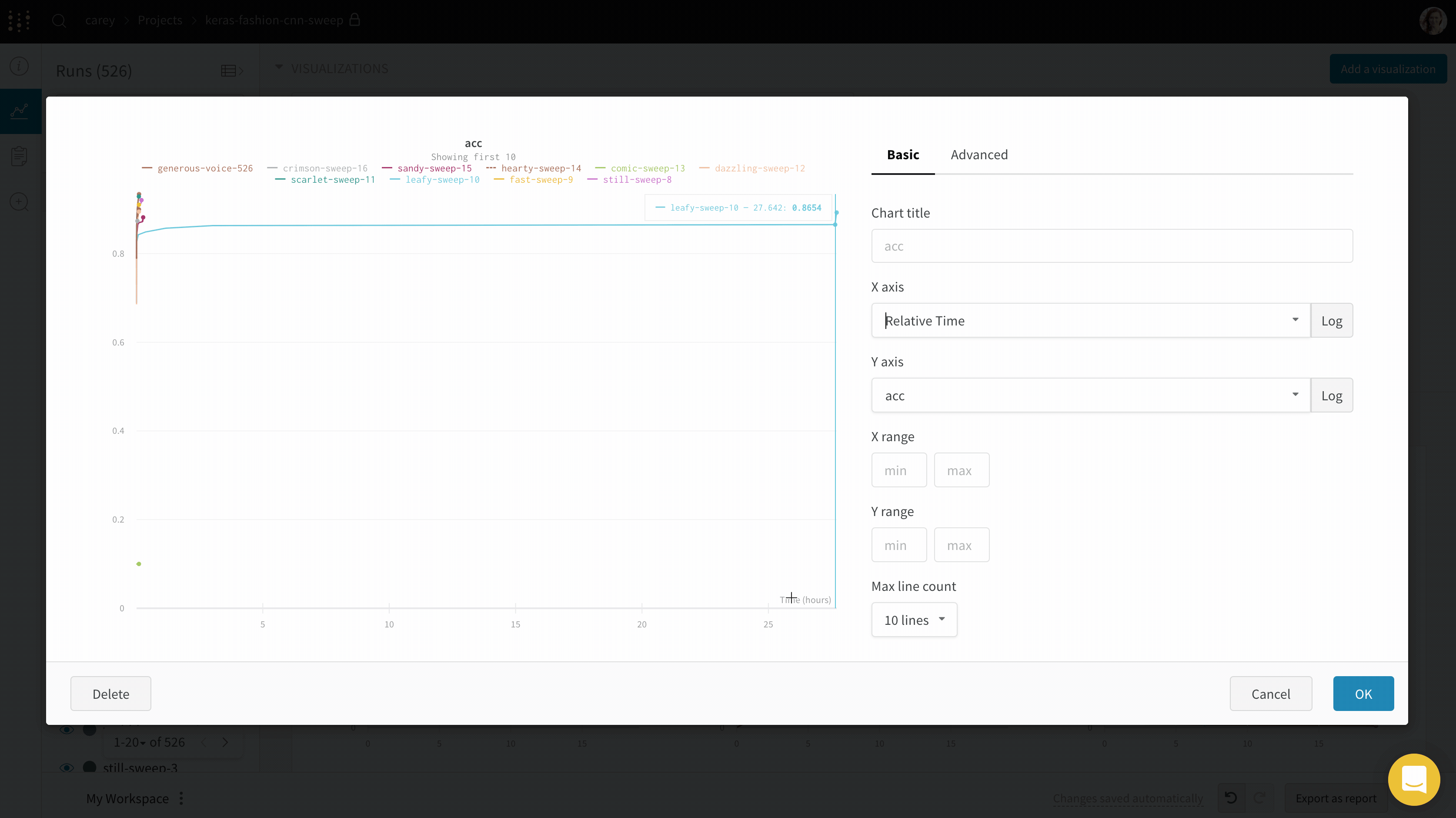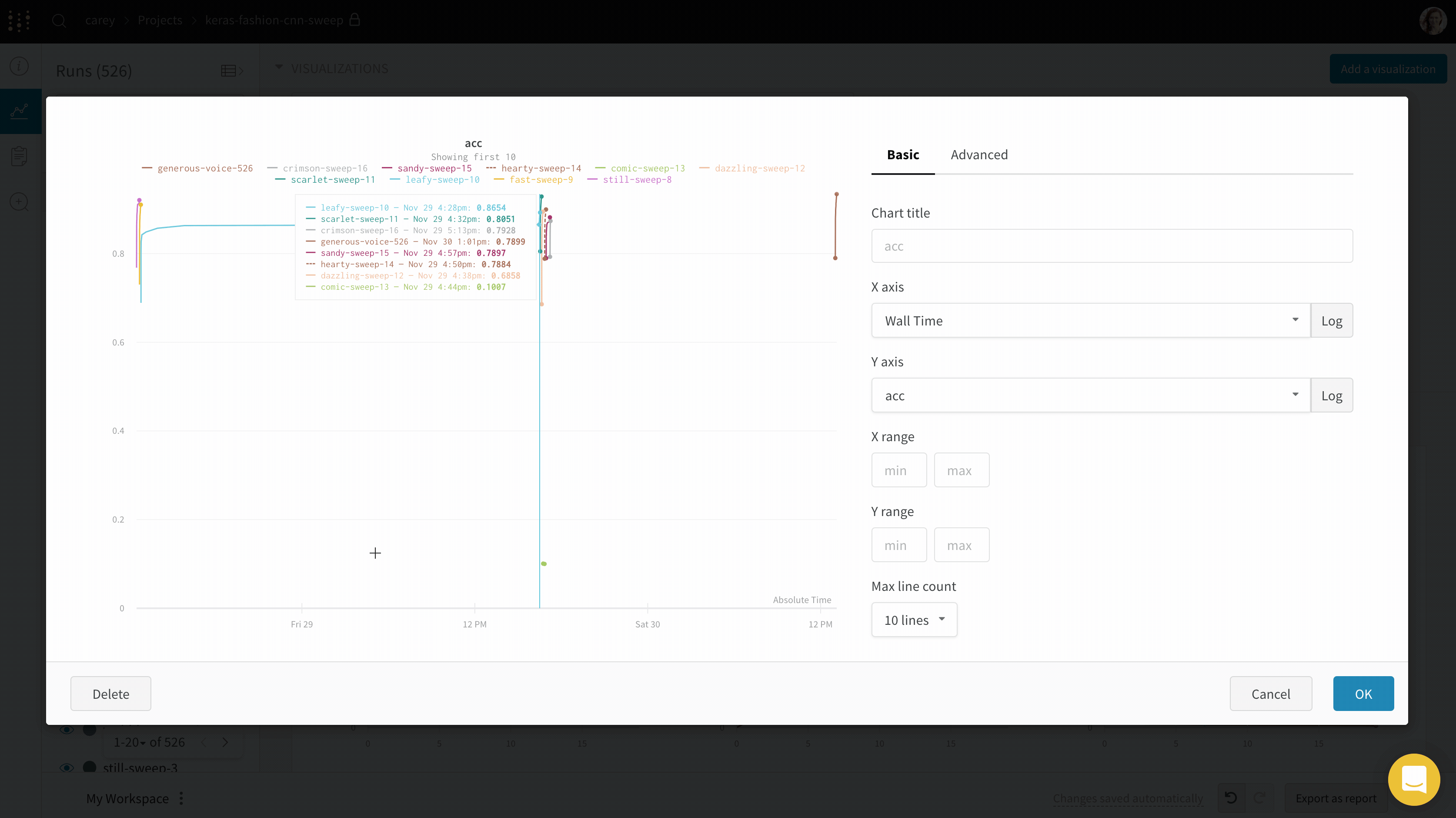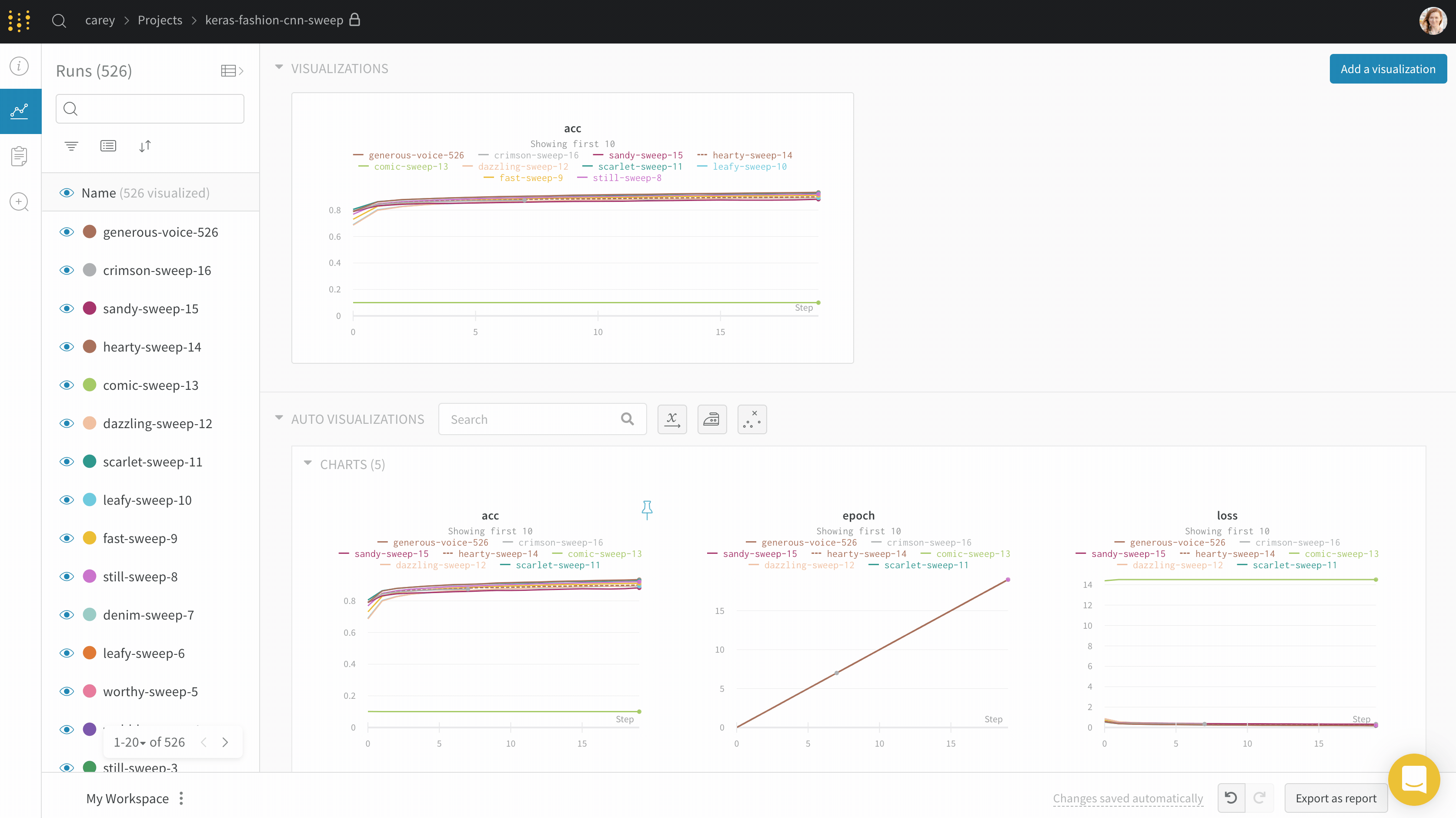
ラインプロット設定を編集する
このセクションでは、個々のラインプロットパネル、セクション内のすべてのラインプロットパネル、またはワークスペース内のすべてのラインプロットパネルの設定を編集する方法を紹介します。
wandb.log() の呼び出しで y 軸と一緒にログを取るようにしてください。個別のラインプロット
個々のラインプロットの設定は、セクションまたはワークスペースのラインプロット設定を上書きします。ラインプロットをカスタマイズするには:
- パネルの上にマウスをホバーさせ、ギアアイコンをクリックします。
- 表示されるモーダル内で、設定 を編集するタブを選択します。
- 適用 をクリックします。
ラインプロット設定
次の設定をラインプロットに設定できます:
データ: プロットのデータ表示の詳細を設定します。
- X: X 軸に使用する値を選択します (デフォルトは Step です)。X 軸を 相対時間 に変更したり、W&B でログを取った値に基づいてカスタム軸を選択したりできます。
- 相対時間 (Wall) はプロセス開始以降の時計時間で、もし 1 日後に run を再開して何かをログした場合、それは 24 時間にプロットされます。
- 相対時間 (プロセス) は実行中のプロセス内の時間で、もし 10 秒間 run を実行し、1 日後に再開した場合、そのポイントは 10 秒にプロットされます。
- ウォール時間 はグラフ上の最初の run 開始からの経過時間を示します。
- Step はデフォルトで
wandb.log()が呼び出されるたびに増加し、モデルからログされたトレーニングステップの数を反映することになっています。
- Y: メトリクスや時間経過とともに変化するハイパーパラメーターなど、ログに取られた値から1つ以上の y 軸を選択します。
- X軸 および Y軸 の最小値と最大値 (オプション)。
- ポイント集計メソッド. ランダムサンプリング (デフォルト) または フルフェデリティ。詳細は サンプリング を参照。
- スムージング: ラインプロットのスムージングを変更します。デフォルトは 時間加重EMA です。その他の値には スムージングなし, ランニング平均, および ガウシアン があります。
- 外れ値: 外れ値を除外して、デフォルトのプロット最小値および最大値スケールを再設定します。
- 最大 run またはグループ数: この数値を増やすことで、ラインプロットに一度により多くのラインを表示します。デフォルトは 10 run です。チャートの一番上に “最初の 10 run を表示中” というメッセージが表示され、利用可能な run が 10 個を超える場合、チャートが表示できる数を制約していることが分かります。
- チャートタイプ: ラインプロット、エリアプロット、および パーセンテージエリアプロットの中で切り替えます。
グルーピング: プロット内で run をどのようにグループ化し集計するかを設定します。
- グループ化基準: 列を選択し、その列に同じ値を持つすべての run がグループ化されます。
- Agg: 集計— グラフ上のラインの値です。オプションはグループの平均、中央値、最小、最大です。
チャート: パネル、X軸、Y軸のタイトルを指定し、凡例を表示または非表示に設定し、その位置を設定します。
凡例: パネルの凡例の外観をカスタマイズします、もし有効化されている場合。
- 凡例: プロットの各ラインに対する凡例のフィールド、それぞれのラインのプロット内の凡例。
- 凡例テンプレート: テンプレートの上部に表示される凡例およびマウスオーバー時にプロットに表示される伝説で, 表示したい具体的なテキストおよび変数を定義します。
式: パネルにカスタム計算式を追加します。
- Y軸式: グラフに計算されたメトリクスを追加。ログされたメトリクスやハイパーパラメーターのような設定値を使用してカスタムラインを計算することができます。
- X軸式: 計算された値を使用して x 軸を再スケーリングします。有用な変数には、デフォルトの x 軸の step などが含まれ、サマリー値を参照するための構文は
${summary:value}です。
セクション内のすべてのラインプロット
ワークスペースの設定を上書きして、セクション内のすべてのラインプロットのデフォルトの設定をカスタマイズするには:
- セクションのギアアイコンをクリックして設定を開きます。
- 表示されるモーダル内で、データ または 表示設定 タブを選択して、セクションのデフォルトの設定を構成します。各 データ 設定の詳細については、前述のセクション 個別のラインプロット を参照してください。各表示設定の詳細については、セクションレイアウトの構成 を参照してください。
ワークスペース内のすべてのラインプロット
ワークスペース内のすべてのラインプロットのデフォルト設定をカスタマイズするには:
- 設定 というラベルの付いたギアがあるワークスペースの設定をクリックします。
- ラインプロット をクリックします。
- 表示されるモーダル内で、データ または 表示設定 タブを選択して、ワークスペースのデフォルト設定を構成します。
-
各 データ 設定の詳細については、前述のセクション 個別のラインプロット を参照してください。
-
各 表示設定 セクションの詳細については、ワークスペース表示設定 を参照してください。ワークスペースレベルで、ラインプロットのデフォルト ズーム 振る舞いを構成できます。この設定は、x 軸キーが一致するラインプロット間でズームの同期を制御します。デフォルトでは無効です。
-
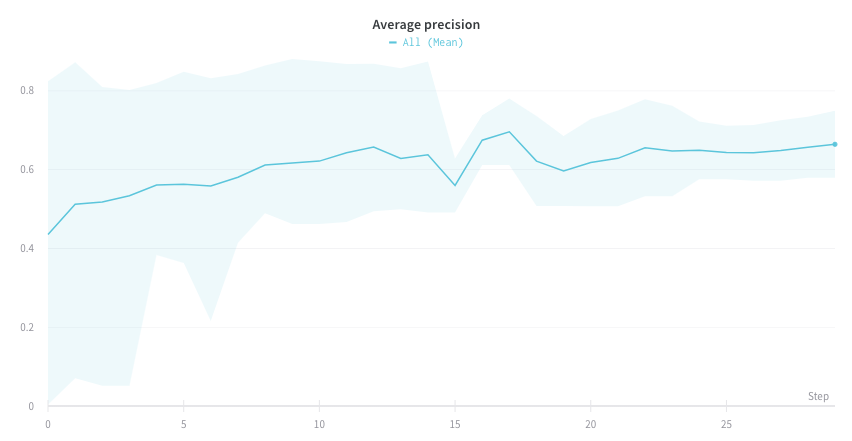
プロット上で平均値を可視化する
複数の異なる実験があり、その値の平均をプロットで見たい場合は、テーブルのグルーピング機能を使用できます。runテーブルの上部で “グループ化” をクリックし、“すべて” を選択してグラフに平均値を表示します。
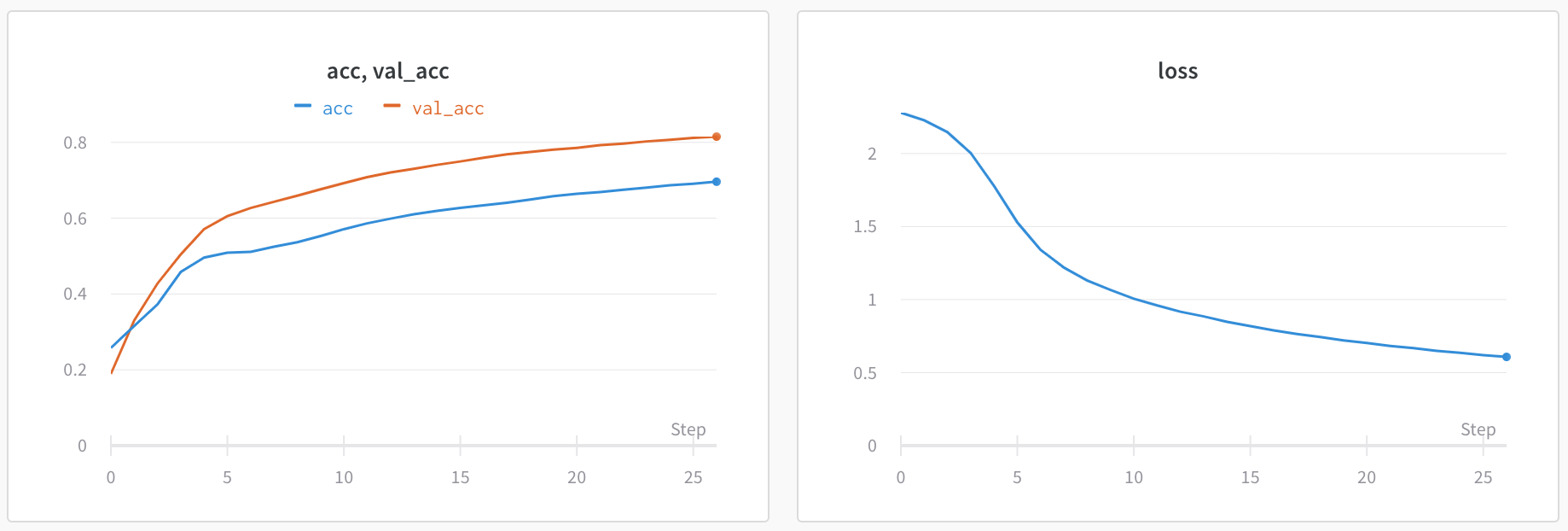
以下は平均化する前のグラフの例です:
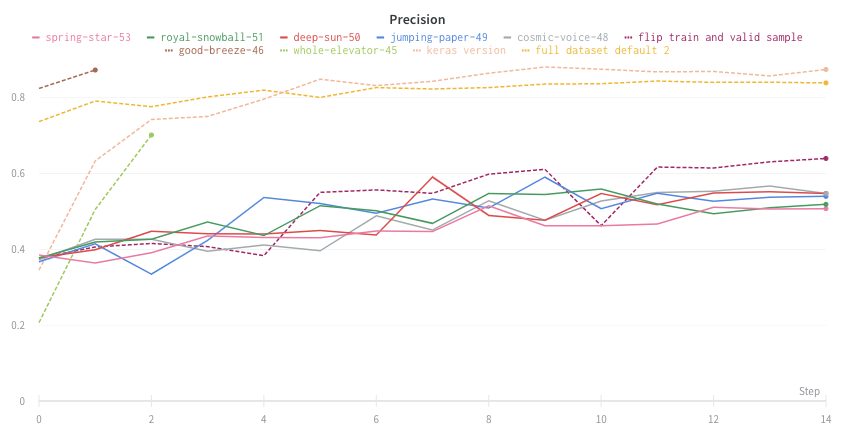
次の画像は、グループ化されたラインを使用して run における平均値を示すグラフです。
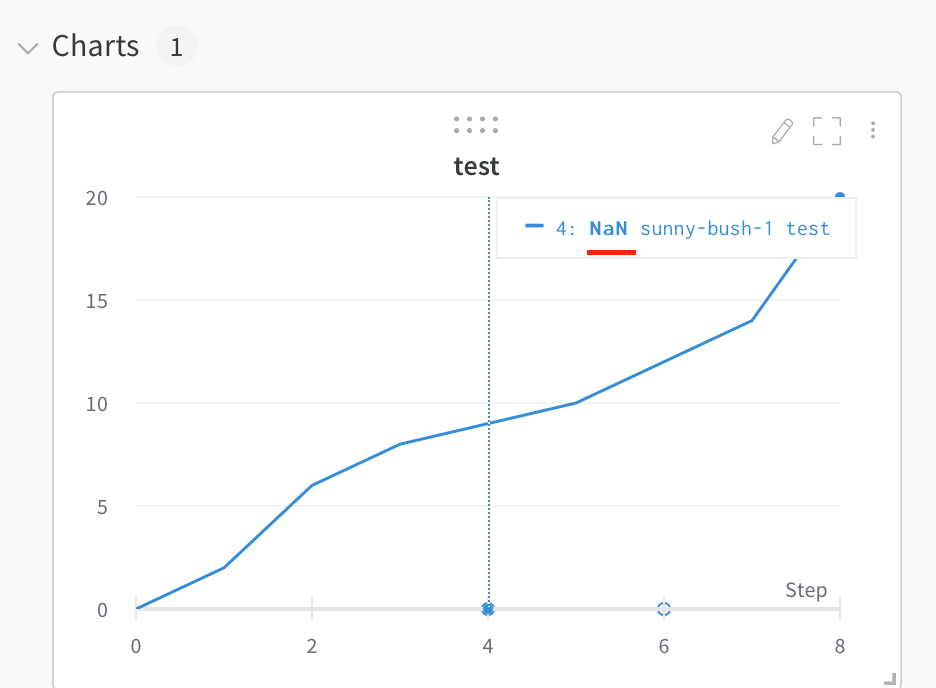
プロット上で NaN 値を可視化する
wandb.log を使用して、PyTorch テンソルを含む NaN 値をラインプロットでプロットすることもできます。例えば:
wandb.log({"test": [..., float("nan"), ...]})
2 つのメトリクスを 1 つのチャートで比較する
- ページの右上隅にある パネルを追加 ボタンを選択します。
- 表示される左側のパネルで評価のドロップダウンを展開します。
- Run comparer を選択します。
ラインプロットの色を変更する
時々、run のデフォルトの色が比較には適していないことがあります。この問題を解決するために、wandb は手動で色を変更できる2つの方法を提供しています。
各 run は初期化時にデフォルトでランダムな色が割り当てられます。

どの色をクリックすると、手動で選択できるカラーパレットが表示されます。
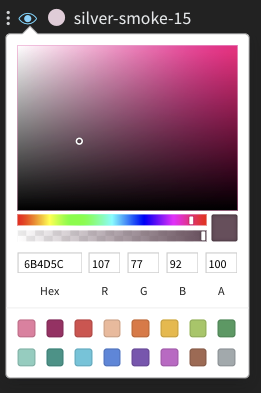
- 設定を編集したいパネルにマウスをホバーさせます。
- 表示される鉛筆アイコンを選択します。
- 凡例 タブを選択します。
異なる x 軸で可視化する
実験がかかった絶対時間を見たい場合や、実験が実行された日を見たい場合は、x 軸を切り替えることができます。ここでは、ステップから相対時間、そして壁時間に切り替える例を示します。
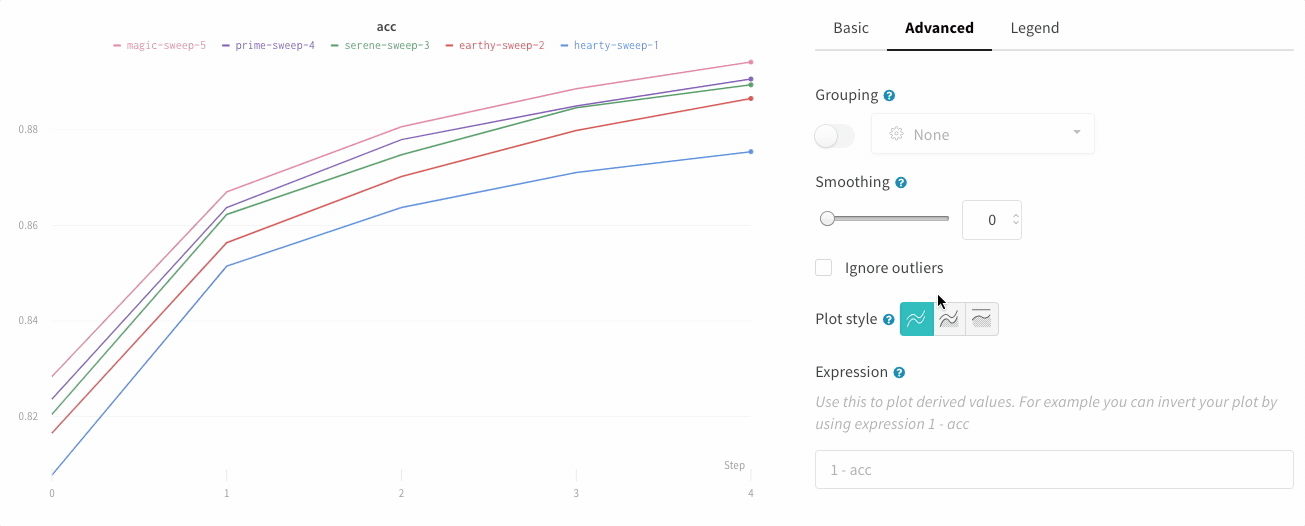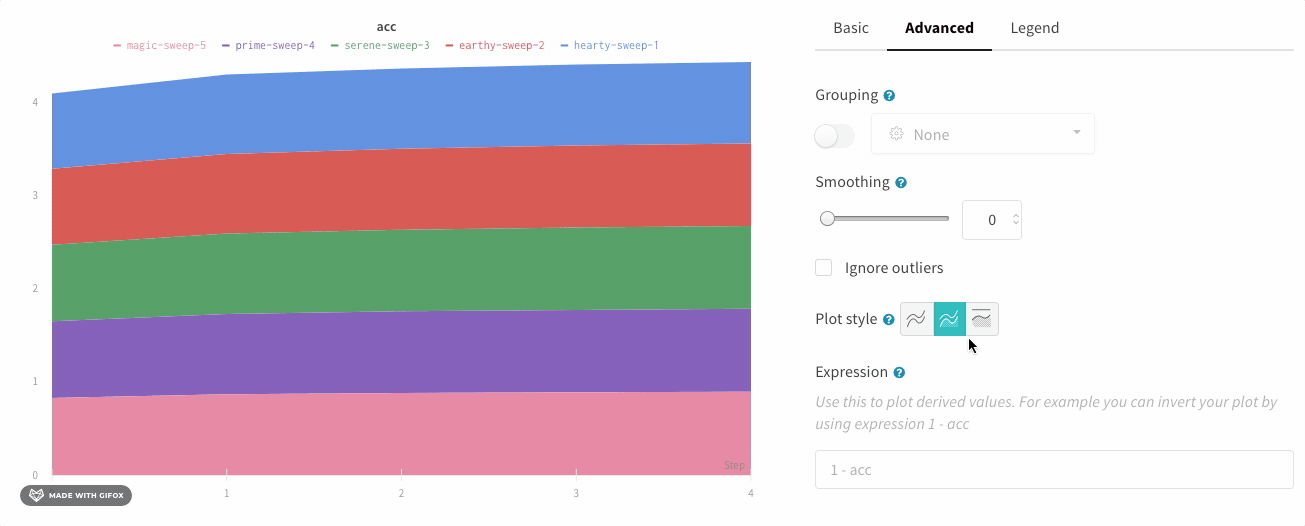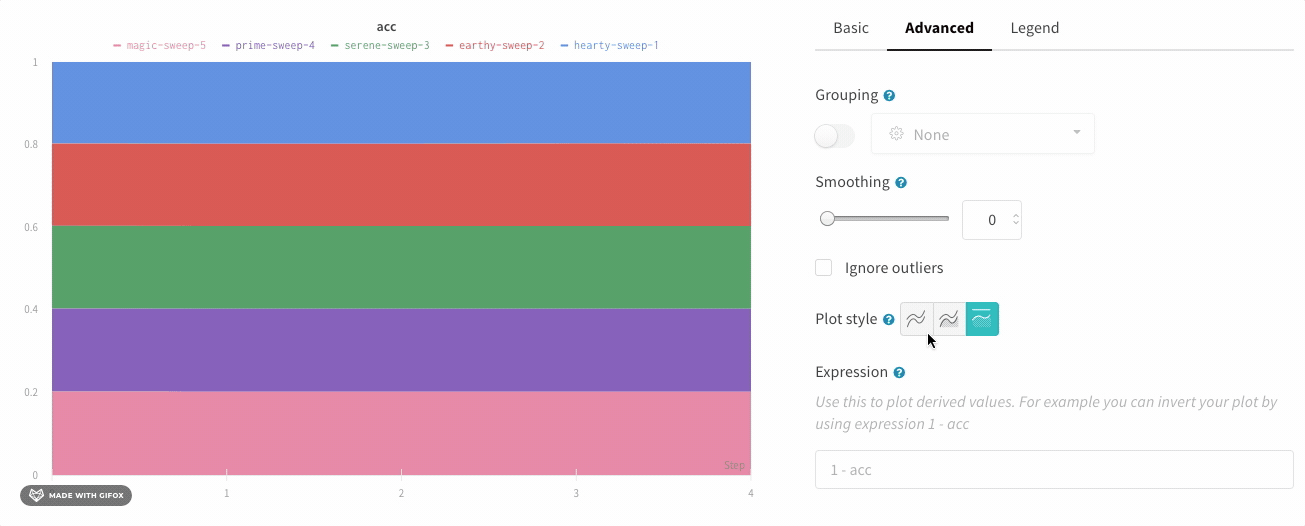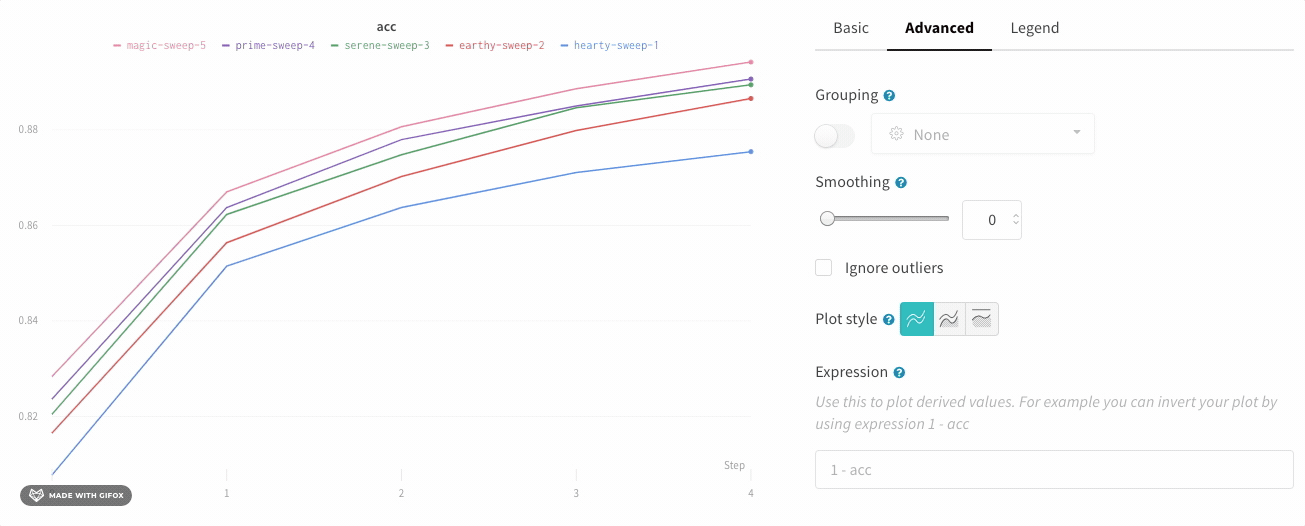
エリアプロット
詳細設定タブでさまざまなプロットスタイルをクリックすると、エリアプロットまたはパーセンテージエリアプロットを取得できます。
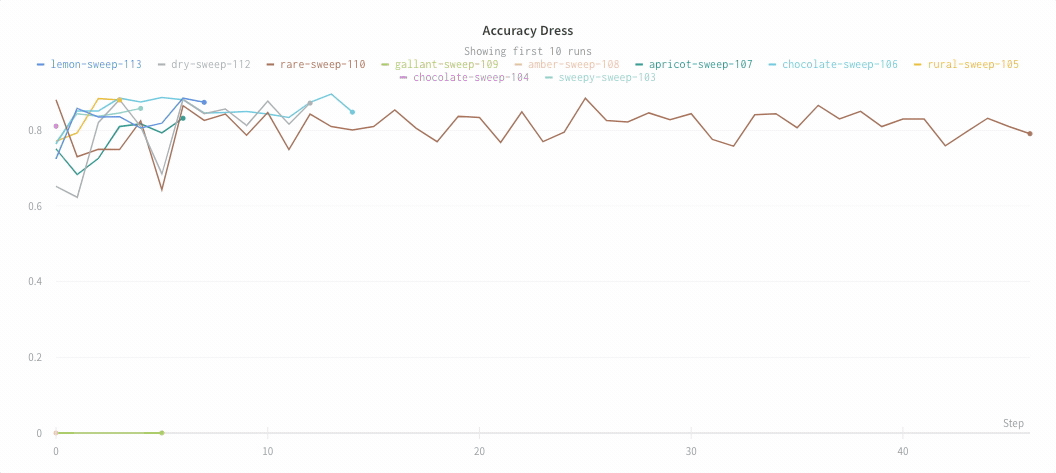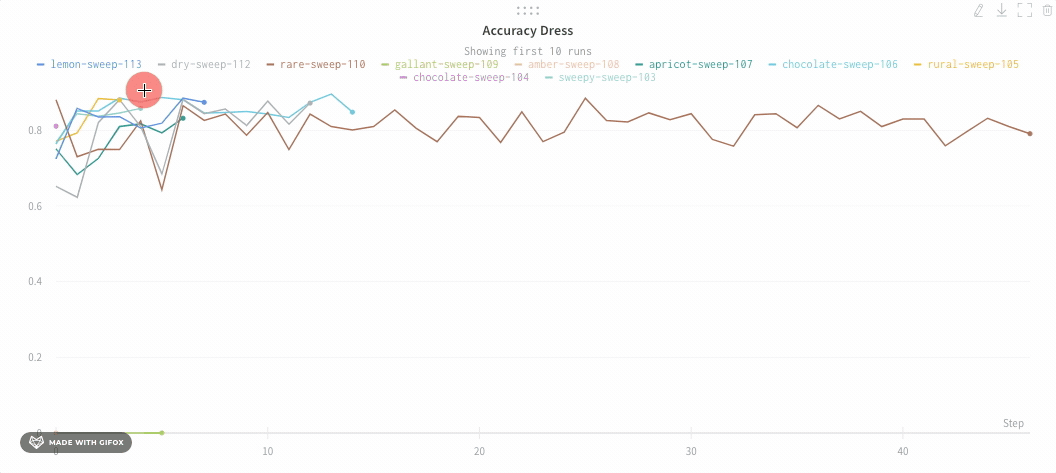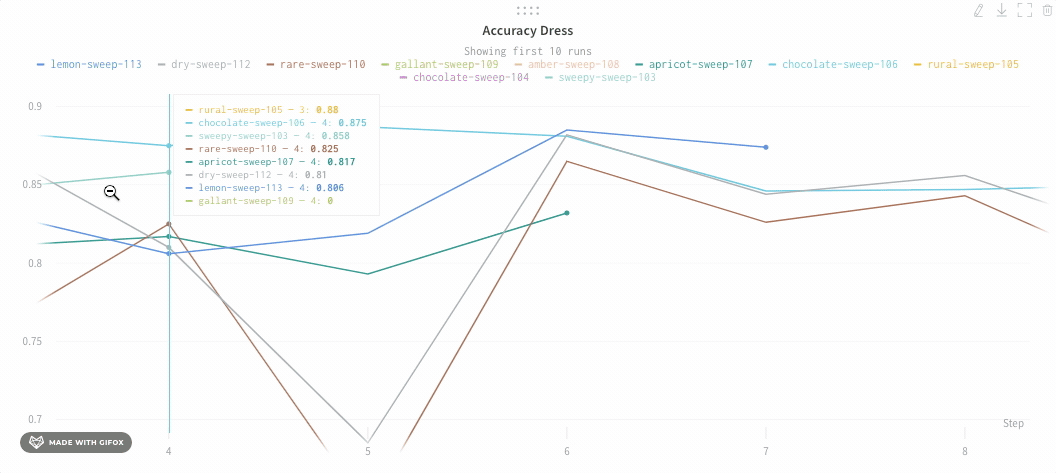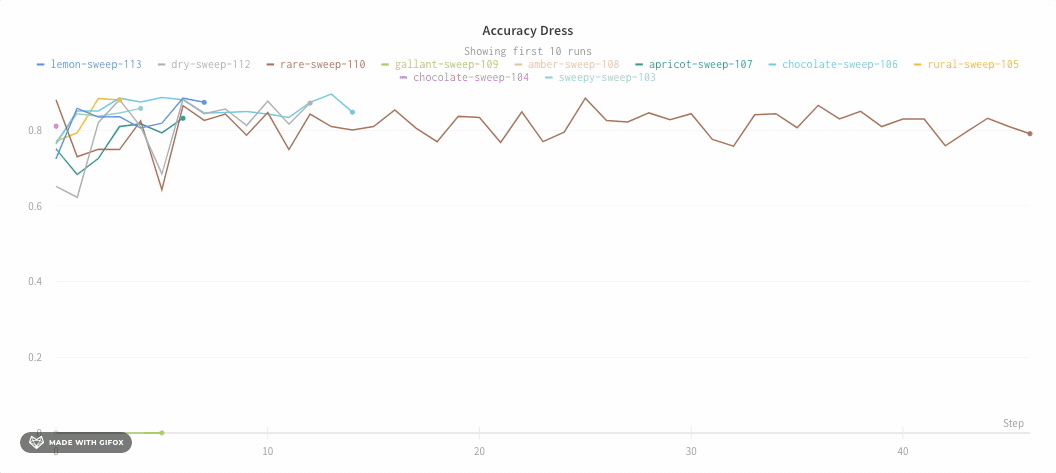
ズーム
直線をクリックしてドラッグすると垂直および水平方向に同時にズームします。これにより、x軸とy軸のズームが変更されます。
チャートの凡例の非表示
この簡単なトグルでラインプロットの凡例をオフにできます:
1.1.1 - 折れ線グラフのリファレンス
X軸
折れ線グラフのX軸を、W&B.logで記録した任意の値に設定できます。ただし、それが常に数値として記録されている必要があります。
Y軸の変数
Y軸の変数は、wandb.logで記録した任意の値に設定できます。ただし、数値、数値の配列、または数値のヒストグラムを記録している必要があります。変数に対して1500点以上を記録した場合、W&Bは1500点にサンプリングします。
X範囲とY範囲
プロットのXとYの最大値と最小値を変更できます。
X範囲のデフォルトは、X軸の最小値から最大値までです。
Y範囲のデフォルトは、メトリクスの最小値と0からメトリクスの最大値までです。
最大run/グループ数
デフォルトでは、10 runまたはrunのグループのみがプロットされます。runは、runsテーブルまたはrunセットの上位から取得されるため、runsテーブルやrunセットを並べ替えると、表示されるrunを変更できます。
凡例
チャートの凡例を制御して、任意のrunに対して記録した任意のconfig値やrunのメタデータ、例えば作成日時やrunを作成したユーザーを表示できます。
例:
${run:displayName} - ${config:dropout} は、各runの凡例名を royal-sweep - 0.5 のようにします。ここで royal-sweep はrun名で、0.5 は dropout という名前のconfigパラメータです。
グラフにカーソルを合わせたときにクロスヘアで特定の点の値を表示するために、[[ ]] 内に値を設定できます。例えば \[\[ $x: $y ($original) ]] は “2: 3 (2.9)” のように表示されます。
[[ ]] 内でサポートされる値は以下の通りです:
| 値 | 意味 |
|---|---|
${x} |
X値 |
${y} |
Y値(平滑化調整を含む) |
${original} |
平滑化調整を含まないY値 |
${mean} |
グループ化されたrunの平均 |
${stddev} |
グループ化されたrunの標準偏差 |
${min} |
グループ化されたrunの最小値 |
${max} |
グループ化されたrunの最大値 |
${percent} |
全体のパーセント(積み上げ面チャート用) |
グループ化
全てのrunをグループ化するか、個々の変数でグループをすることができます。また、テーブル内部でグループ化することによってグループを有効にすると、そのグループは自動的にグラフに反映されます。
スムージング
スムージング係数を0から1の間で設定できます。0はスムージングなし、1は最大スムージングを意味します。詳細はスムージング係数の設定についてを参照してください。
外れ値を無視
デフォルトのプロットの最小値と最大値のスケールから外れ値を除外するようにプロットをリスケールします。この設定がプロットに与える影響は、プロットのサンプリングモードに依存します。
- ランダムサンプリングモードを使用するプロットでは、外れ値を無視を有効にすると、5%から95%の点のみが表示されます。外れ値が表示される場合、それらは他の点と異なるフォーマットでは表示されません。
- 完全な忠実度モードを使用するプロットでは、全ての点が常に表示され、各バケットの最後の値まで凝縮されます。外れ値を無視が有効になっている場合、各バケットの最小値と最大値の境界がシェーディングされます。それ以外の場合は、領域はシェーディングされません。
式の表現
式の表現を使用して、1-accuracyのようにメトリクスから派生した値をプロットできます。現在、単一のメトリクスをプロットしている場合にのみ機能します。+、-、*、/、%といった簡単な算術式、および**を使用してべき乗を行うことができます。
プロットスタイル
折れ線グラフのスタイルを選択します。
折れ線プロット:
面プロット:
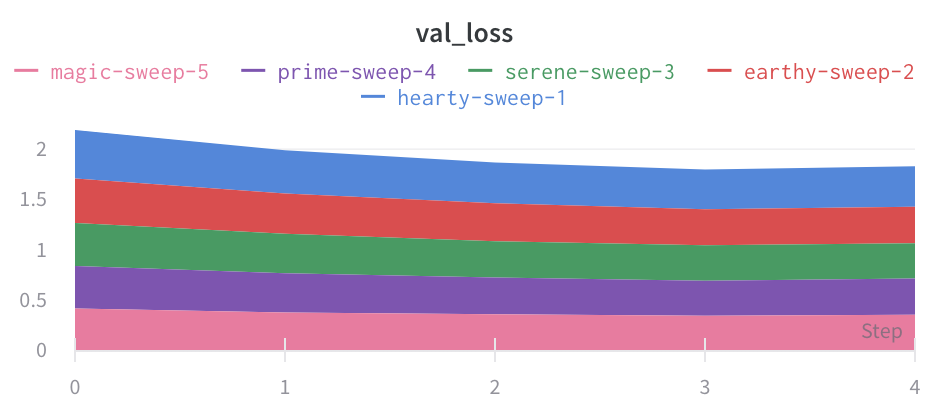
パーセンテージエリアプロット:
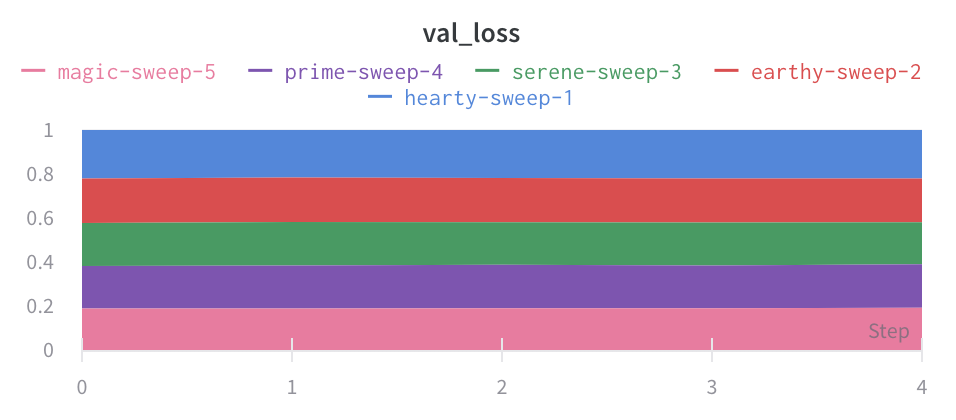
1.1.2 - ポイント集約
Use point aggregation methods within your line plots for improved data visualization accuracy and performance. There are two types of point aggregation modes: full fidelity and random sampling. W&B uses full fidelity mode by default.
Full fidelity
Full fidelity modeを使用すると、W&Bはデータポイントの数に基づいてx軸を動的なバケットに分割します。そして、それぞれのバケット内の最小、最大、平均値を計算し、線プロットのポイント集約をレンダリングします。
フルフィデリティモードを使用する際のポイント集約の3つの主な利点は次のとおりです:
- 極値とスパイクを保持する: データ内の極値とスパイクを保持します。
- 最小値と最大値のレンダリングを設定する: W&Bアプリを使用して、極値(最小/最大)を影付きエリアとして表示するかどうかをインタラクティブに決定できます。
- データの忠実度を失わずにデータを探索する: W&Bは特定のデータポイントにズームインするとx軸のバケットサイズを再計算します。これにより、正確さを失うことなくデータを探索できることを保証します。キャッシュを使用して以前に計算された集計を保存することで、ロード時間を短縮するのに役立ちます。これは、特に大規模なデータセットをナビゲートしている場合に便利です。
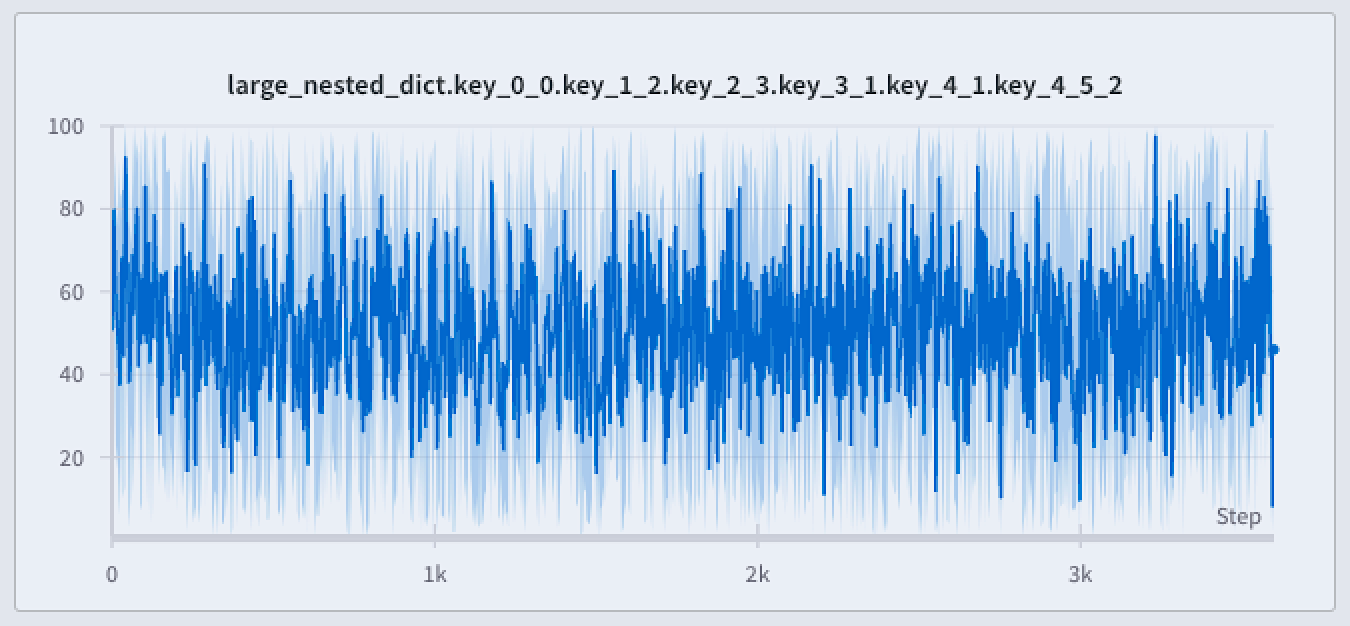
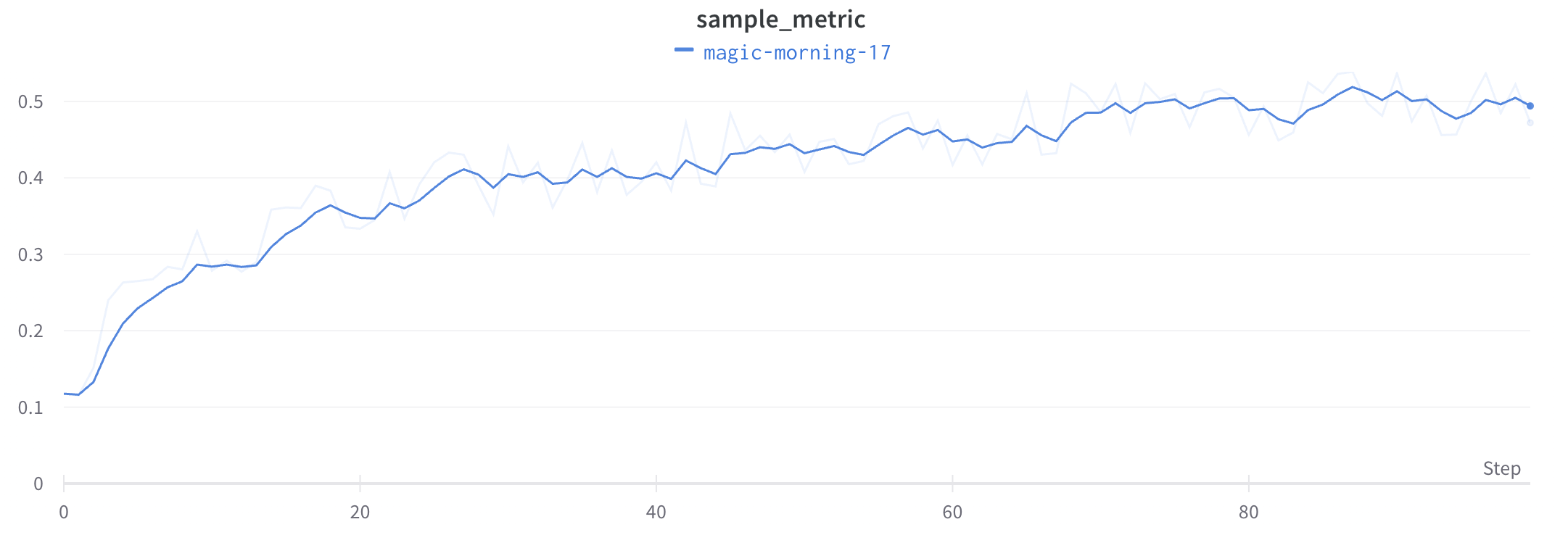
最小値と最大値のレンダリングの設定
線プロットの周囲に影付きのエリアを使って最小値と最大値を表示または非表示にします。
次の画像は、青い線プロットを示しています。薄い青の影付きエリアは各バケットの最小値と最大値を表しています。
線プロットで最小値と最大値をレンダリングする方法は3通りあります:
- Never: 最小/最大値は影付きエリアとして表示されません。x軸のバケット全体に渡る集約された線だけを表示します。
- On hover: グラフにカーソルを合わせると、最小/最大値の影付きエリアが動的に表示されます。このオプションは、ビューをシンプルに保ちながら、範囲をインタラクティブに検査することを可能にします。
- Always: 最小/最大の影付きエリアは常にグラフのすべてのバケットで一貫して表示され、常に全範囲の値を視覚化するのに役立ちます。これにより、グラフに多くのrunsが視覚化されている場合、視覚的なノイズが発生する可能性があります。
デフォルトでは、最小値と最大値は影付きエリアとして表示されません。影付きエリアオプションの1つを表示するには、以下の手順に従ってください:
- W&Bプロジェクトに移動します。
- 左のタブでWorkspaceアイコンを選択します。
- 画面の右上隅にある歯車アイコンを、Add panelsボタンの左側に選択します。
- 表示されるUIスライダーからLine plotsを選択します。
- Point aggregationセクション内で、Show min/max values as a shaded areaドロップダウンメニューからOn hoverまたはAlwaysを選択します。
- W&Bプロジェクトに移動します。
- 左のタブでWorkspaceアイコンを選択します。
- フルフィデリティモードを有効にしたい線プロットパネルを選択します。
- 表示されるモーダル内で、Show min/max values as a shaded areaドロップダウンメニューからOn hoverまたはAlwaysを選択します。
データの忠実度を失わずにデータを探索する
データセットの特定の領域を分析し、極値やスパイクなどの重要なポイントを見逃さないようにします。線プロットをズームインすると、W&Bは各バケット内の最小、最大、および平均値を計算するために使用されるバケットサイズを調整します。
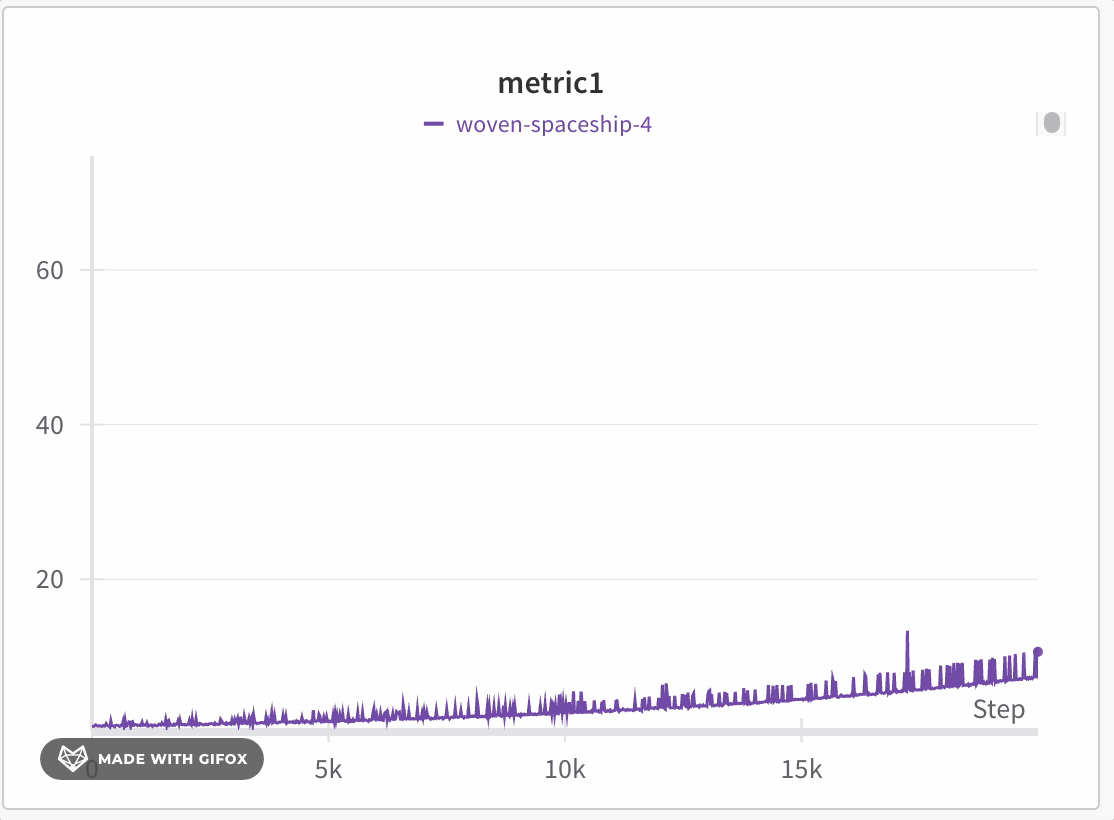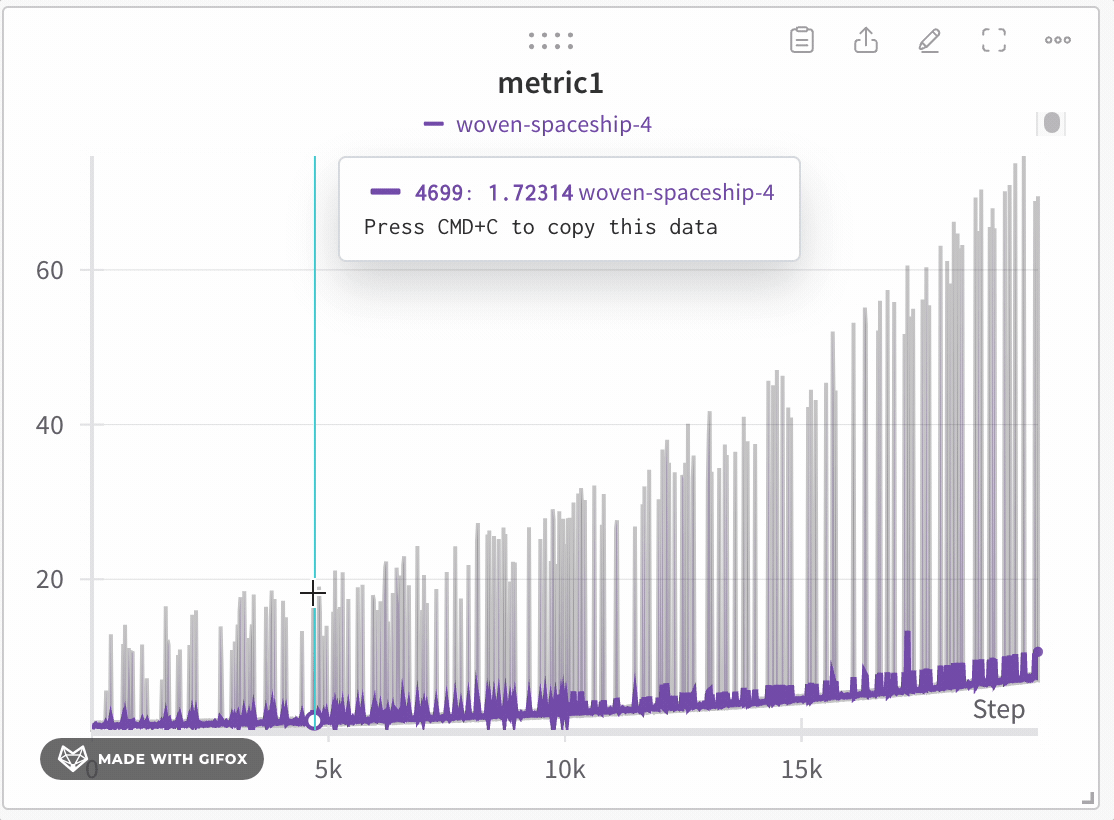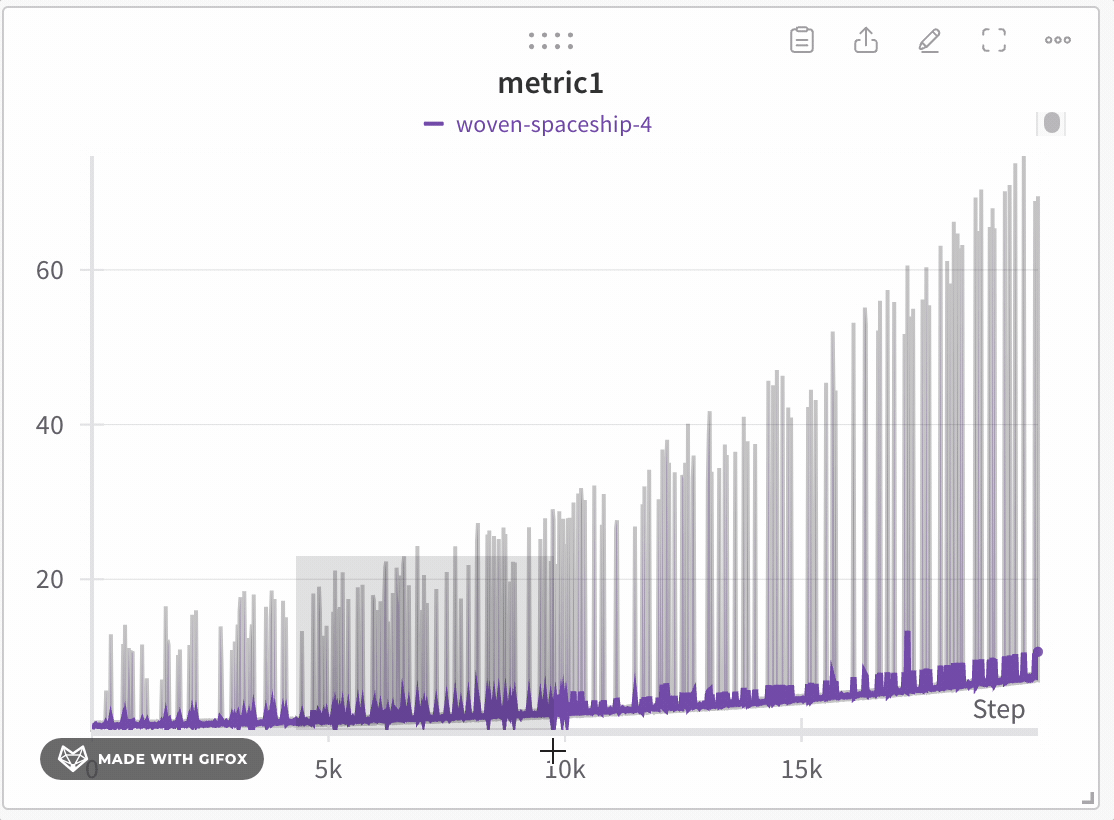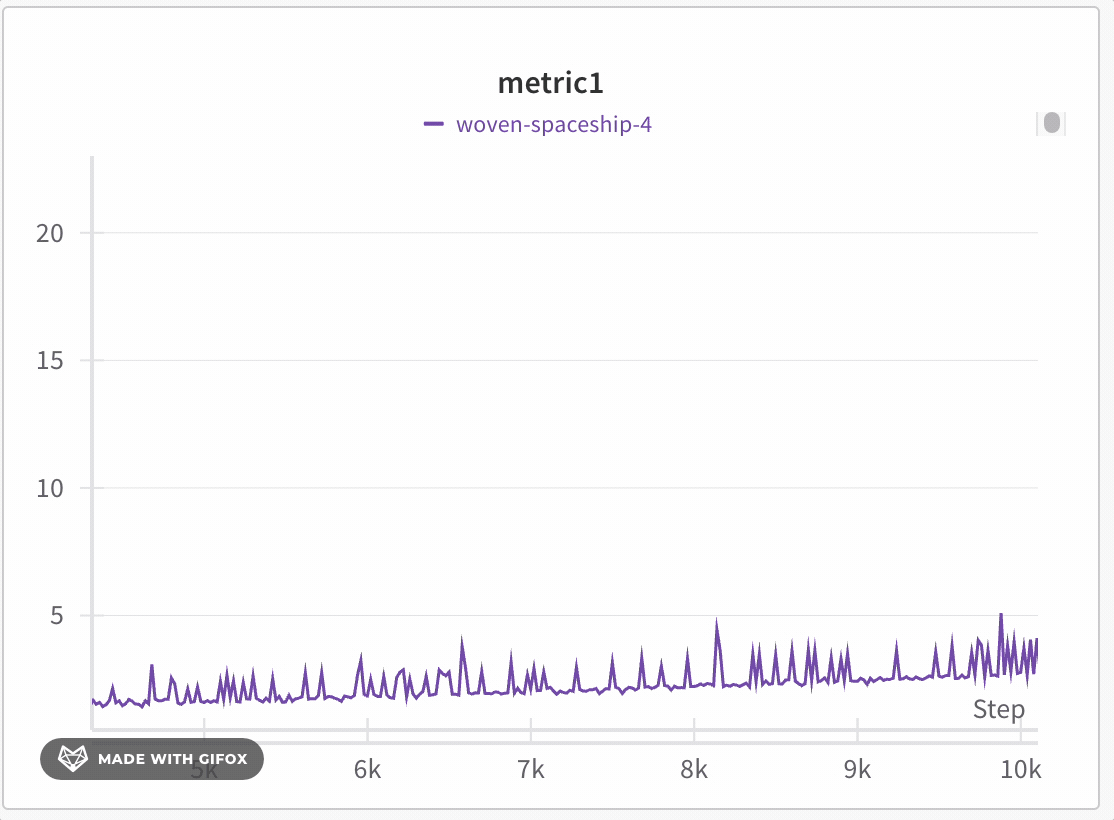
W&Bはデフォルトでx軸を1000のバケットに動的に分割します。各バケットに対し、W&Bは以下の値を計算します:
- Minimum: そのバケット内の最小値。
- Maximum: そのバケット内の最大値。
- Average: そのバケット内のすべてのポイントの平均値。
W&Bは、すべてのプロットでデータの完全な表現を保持し、極値を含める方法でバケット内の値をプロットします。1,000ポイント以下にズームインすると、フルフィデリティモードは追加の集約なしにすべてのデータポイントをレンダリングします。
線プロットをズームインするには、次の手順に従います:
- W&Bプロジェクトに移動します。
- 左のタブでWorkspaceアイコンを選択します。
- 必要に応じて、ワークスペースに線プロットパネルを追加するか、既存の線プロットパネルに移動します。
- ズームインしたい特定の領域を選択するためにクリックしてドラッグします。
Line plot grouping and expressions
Line Plot Groupingを使用すると、W&Bは選択されたモードに基づいて以下を適用します:
- Non-windowed sampling (grouping): x軸でrunsを超えてポイントを整列させます。複数のポイントが同じx値を共有する場合、平均が取られ、そうでない場合は離散的なポイントとして表示されます。
- Windowed sampling (grouping and expressions): x軸を250のバケットまたは最も長い線のポイント数に分割します(いずれか小さい方)。W&Bは各バケット内のポイントの平均を取ります。
- Full fidelity (grouping and expressions): 非ウィンドウ化サンプリングに似ていますが、パフォーマンスと詳細のバランスを取るためにrunごとに最大500ポイントを取得します。
Random sampling
Random samplingはラインプロットをレンダリングするために1,500のランダムにサンプリングされたポイントを使用します。大量のデータポイントがある場合、パフォーマンスの理由でランダムサンプリングが有用です。
ランダムサンプリングを有効にする
デフォルトでは、W&Bはフルフィデリティモードを使用します。ランダムサンプリングを有効にするには、次の手順に従います:
- W&Bプロジェクトに移動します。
- 左のタブでWorkspaceアイコンを選択します。
- 画面の右上隅にある歯車アイコンを、Add panelsボタンの左側に選択します。
- 表示されるUIスライダーからLine plotsを選択します。
- Point aggregationセクションからRandom samplingを選択します。
- W&Bプロジェクトに移動します。
- 左のタブでWorkspaceアイコンを選択します。
- ランダムサンプリングを有効にしたい線プロットパネルを選択します。
- 表示されるモーダル内で、Point aggregation methodセクションからRandom samplingを選択します。
サンプリングされていないデータへのアクセス
W&B Run APIを使用して、run中にログされたメトリクスの完全な履歴にアクセスできます。次の例は、特定のrunから損失値を取得し処理する方法を示しています:
# W&B APIを初期化
run = api.run("l2k2/examples-numpy-boston/i0wt6xua")
# 'Loss'メトリクスの履歴を取得
history = run.scan_history(keys=["Loss"])
# 履歴から損失値を抽出
losses = [row["Loss"] for row in history]
1.1.3 - スムーズなラインプロット
W&B は 3 つのタイプの平滑化をサポートしています:
- 指数移動平均 (デフォルト)
- ガウス平滑化
- 移動平均
- 指数移動平均 - Tensorboard (非推奨)
これらが インタラクティブな W&B レポートでどのように動作するかをご覧ください。
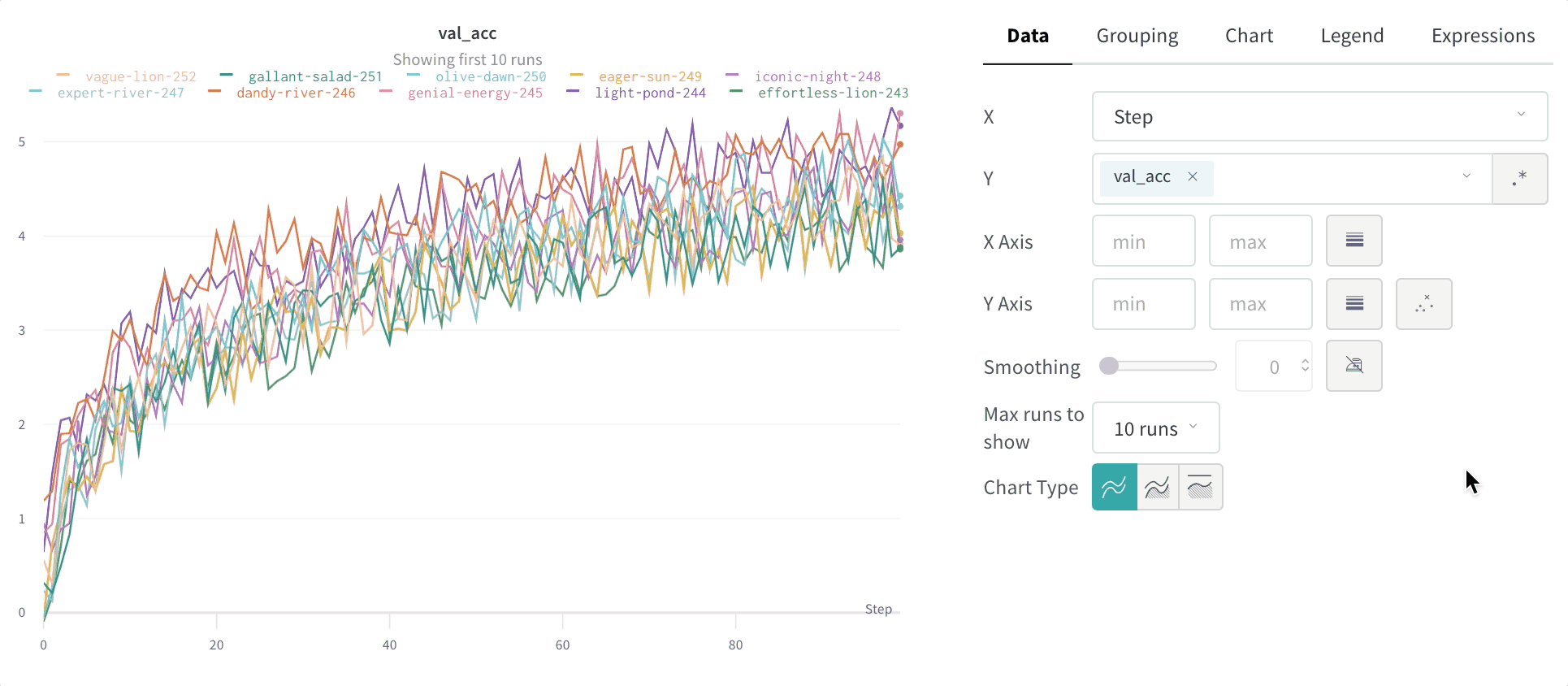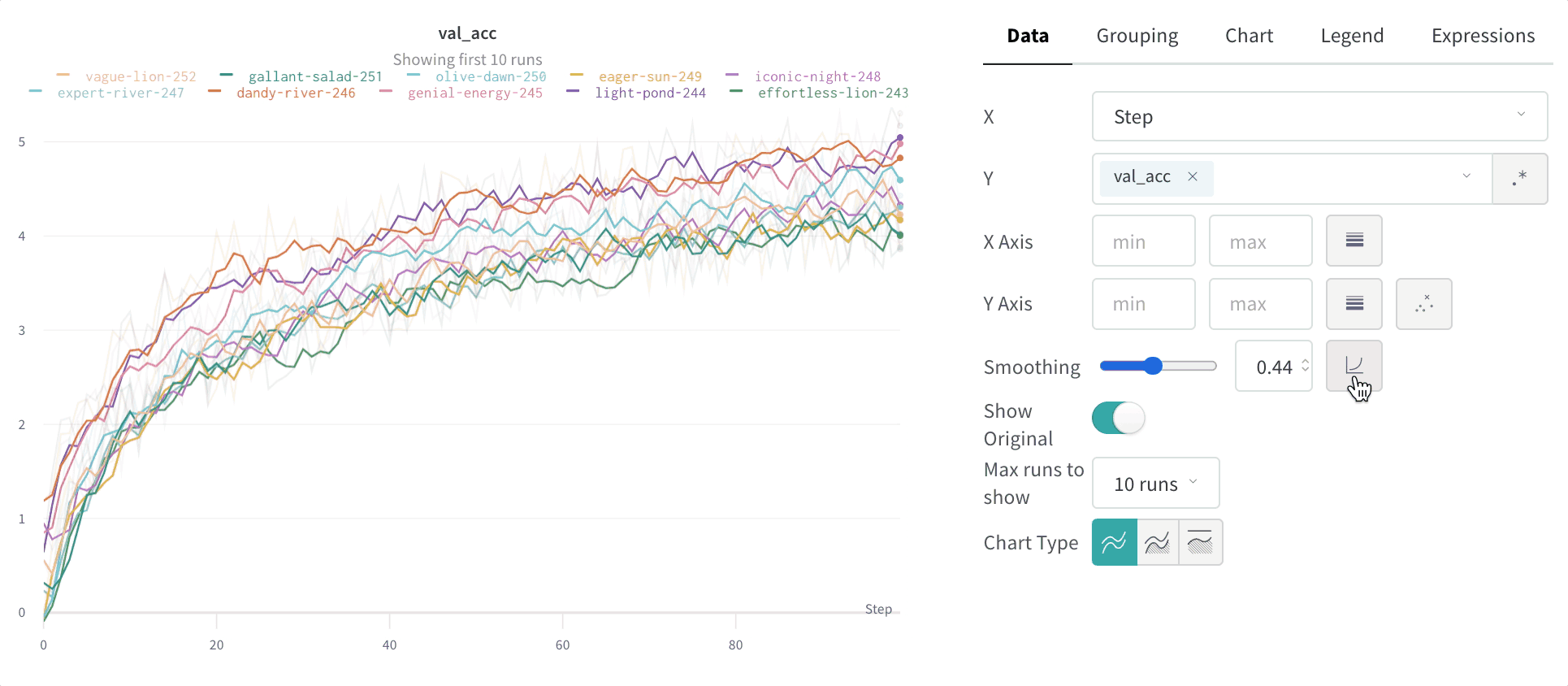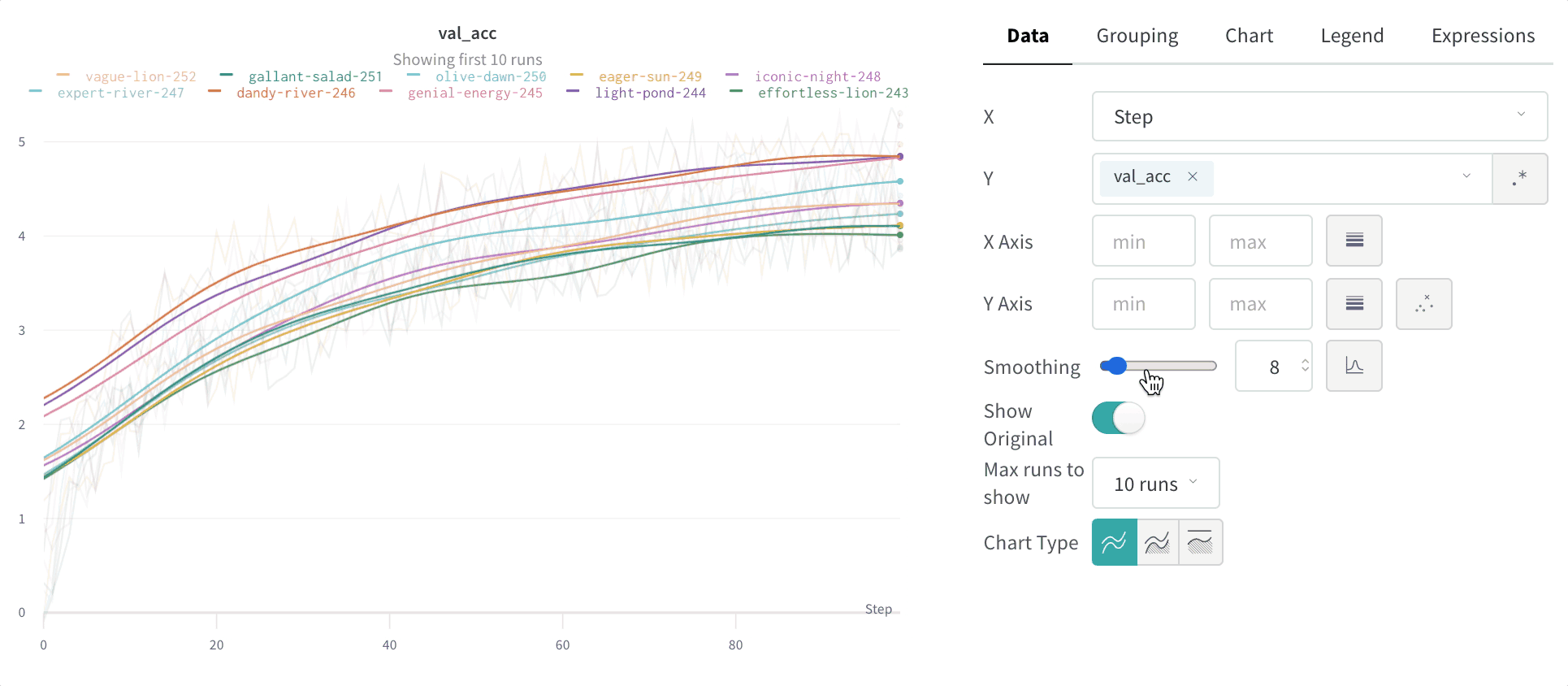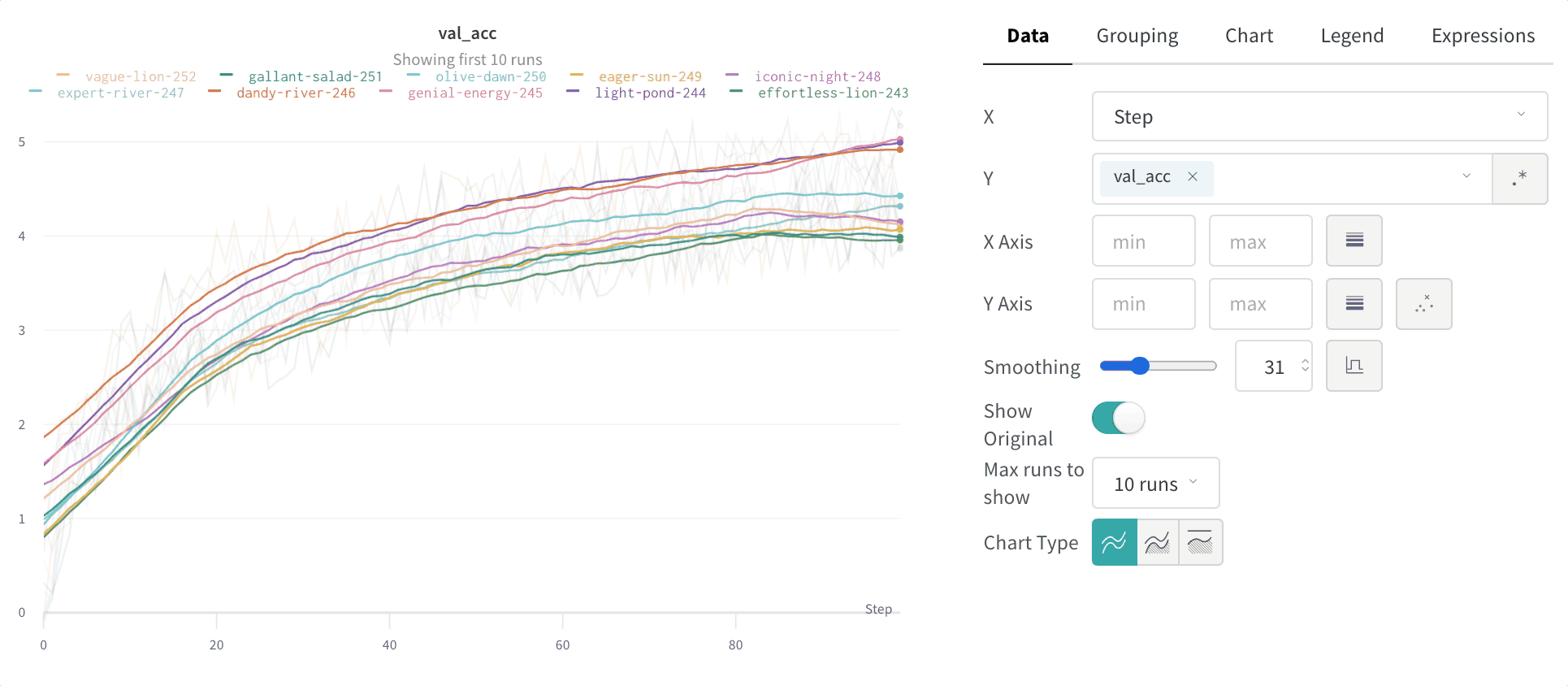
指数移動平均 (デフォルト)
指数平滑化は、時系列データを指数的に減衰させることで、過去のデータポイントの重みを滑らかにする手法です。範囲は 0 から 1 です。背景については 指数平滑化 をご覧ください。時系列の初期値がゼロに偏らないようにするためのデバイアス項が追加されています。
EMA アルゴリズムは、線上の点の密度(x 軸範囲の単位当たりの y 値の数)を考慮に入れます。これにより、異なる特性を持つ複数の線を同時に表示する際に、一貫した平滑化が可能になります。
これが内部でどのように動作するかのサンプルコードです:
const smoothingWeight = Math.min(Math.sqrt(smoothingParam || 0), 0.999);
let lastY = yValues.length > 0 ? 0 : NaN;
let debiasWeight = 0;
return yValues.map((yPoint, index) => {
const prevX = index > 0 ? index - 1 : 0;
// VIEWPORT_SCALE は結果をチャートの x 軸範囲にスケーリングします
const changeInX =
((xValues[index] - xValues[prevX]) / rangeOfX) * VIEWPORT_SCALE;
const smoothingWeightAdj = Math.pow(smoothingWeight, changeInX);
lastY = lastY * smoothingWeightAdj + yPoint;
debiasWeight = debiasWeight * smoothingWeightAdj + 1;
return lastY / debiasWeight;
});
これがアプリ内でどのように見えるかはこちらをご覧ください in the app:
ガウス平滑化
ガウス平滑化(またはガウスカーネル平滑化)は、標準偏差が平滑化パラメータとして指定されるガウス分布に対応する重みを用いてポイントの加重平均を計算します。入力 x 値ごとに平滑化された値が計算されます。
ガウス平滑化は、TensorBoard の振る舞いと一致させる必要がない場合の標準的な選択肢です。指数移動平均とは異なり、ポイントは前後の値に基づいて平滑化されます。
これがアプリ内でどのように見えるかはこちらをご覧ください in the app:
移動平均
移動平均は、与えられた x 値の前後のウィンドウ内のポイントの平均でそのポイントを置き換える平滑化アルゴリズムです。詳細は “Boxcar Filter” を参照してください https://en.wikipedia.org/wiki/Moving_average。移動平均のために選択されたパラメータは、Weights and Biases に移動平均で考慮するポイントの数を伝えます。
ポイントが x 軸上で不均一に配置されている場合は、ガウス平滑化を検討してください。
次の画像は、アプリ内での移動アプリの表示例を示しています in the app:
指数移動平均 (非推奨)
TensorBoard EMA アルゴリズムは、同じチャート上で一貫したポイント密度を持たない複数の線を正確に平滑化することができないため、非推奨とされました。
指数移動平均は、TensorBoard の平滑化アルゴリズムと一致するように実装されています。範囲は 0 から 1 です。背景については 指数平滑化 をご覧ください。時系列の初期値がゼロに偏らないようにするためのデバイアス項が追加されています。
これが内部でどのように動作するかのサンプルコードです:
data.forEach(d => {
const nextVal = d;
last = last * smoothingWeight + (1 - smoothingWeight) * nextVal;
numAccum++;
debiasWeight = 1.0 - Math.pow(smoothingWeight, numAccum);
smoothedData.push(last / debiasWeight);
これがアプリ内でどのように見えるかはこちらをご覧ください in the app:
実装の詳細
すべての平滑化アルゴリズムはサンプリングされたデータで実行されます。つまり、1500 ポイント以上をログに記録した場合、平滑化アルゴリズムはサーバーからポイントがダウンロードされた後に実行されます。平滑化アルゴリズムの目的は、データ内のパターンを迅速に見つけることです。多くのログを持つメトリクスに対して正確な平滑化された値が必要な場合は、API を介してメトリクスをダウンロードし、自分自身の平滑化メソッドを実行する方が良いかもしれません。
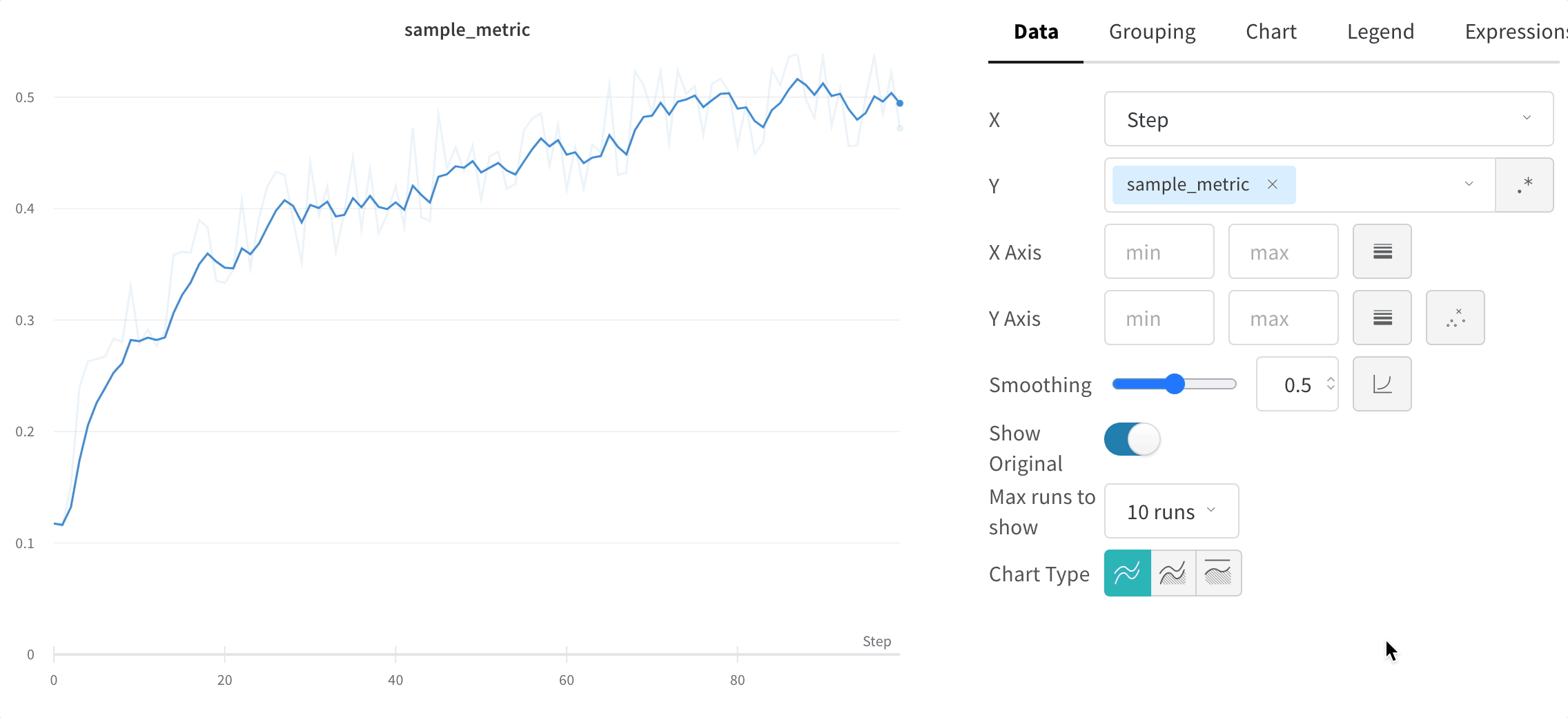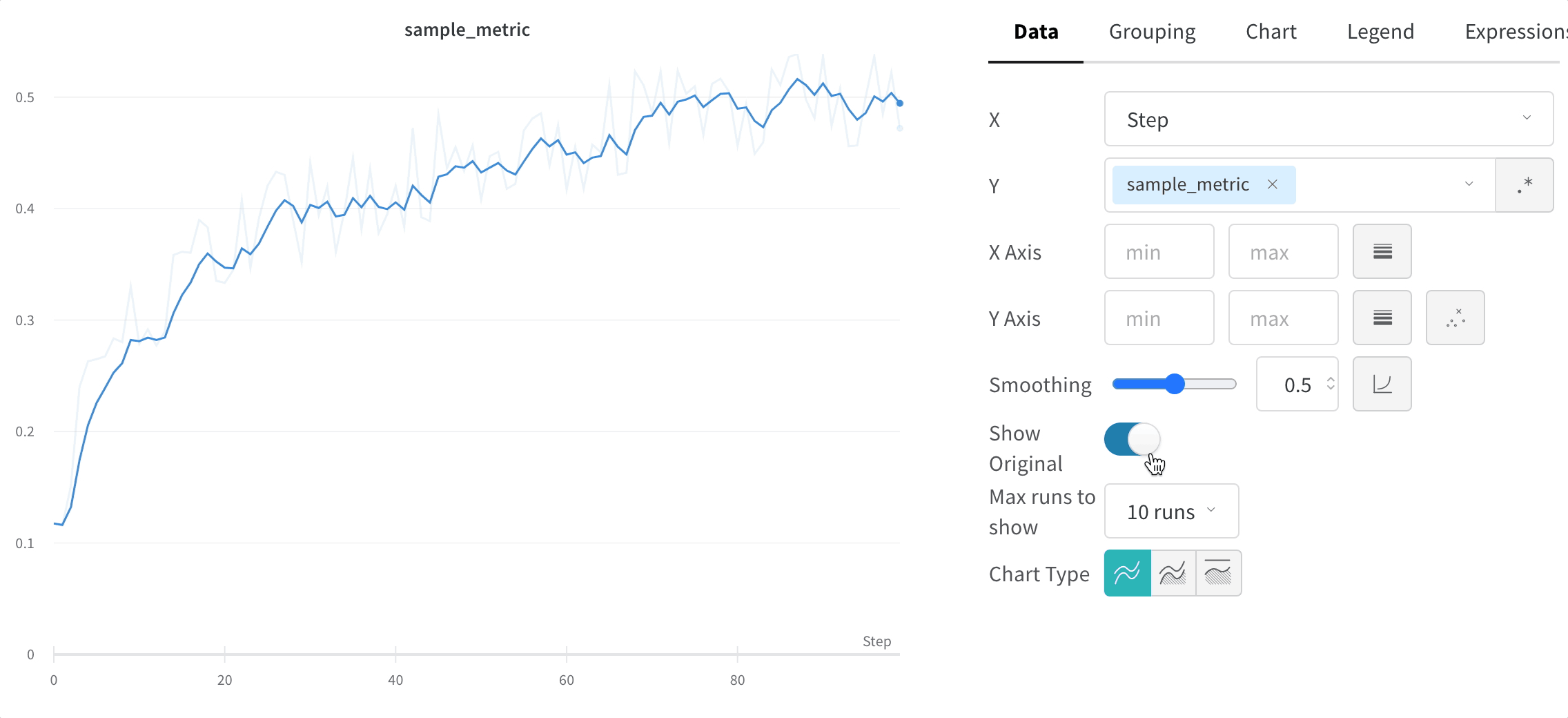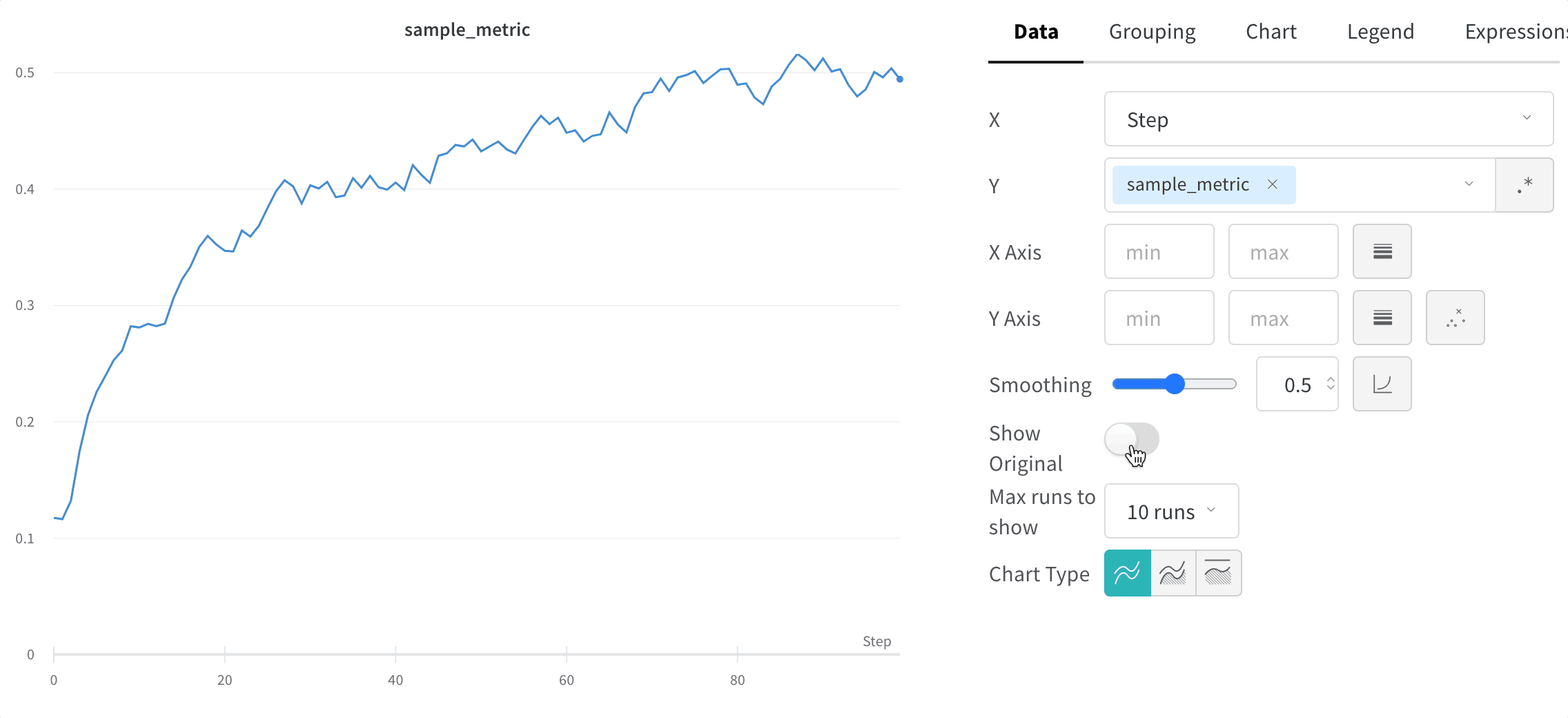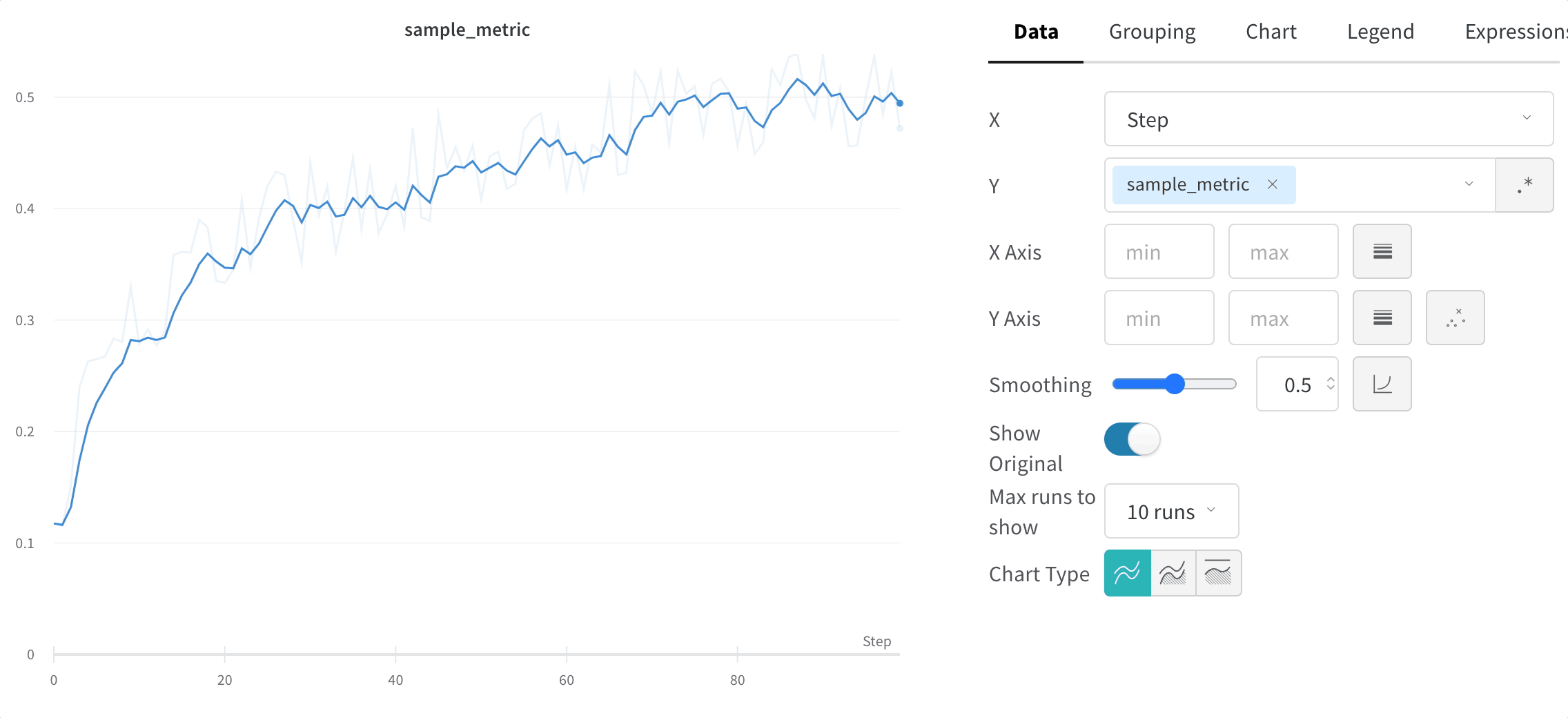
元のデータを非表示にする
デフォルトでは、オリジナルの非平滑化データを背景として薄い線で表示します。この表示をオフにするには、Show Original トグルをクリックしてください。
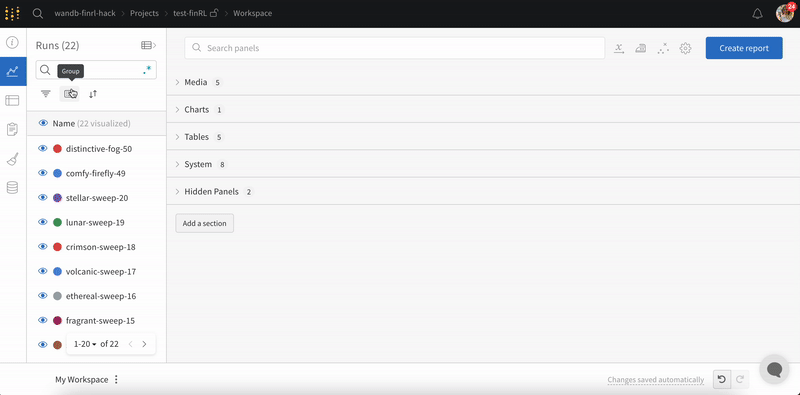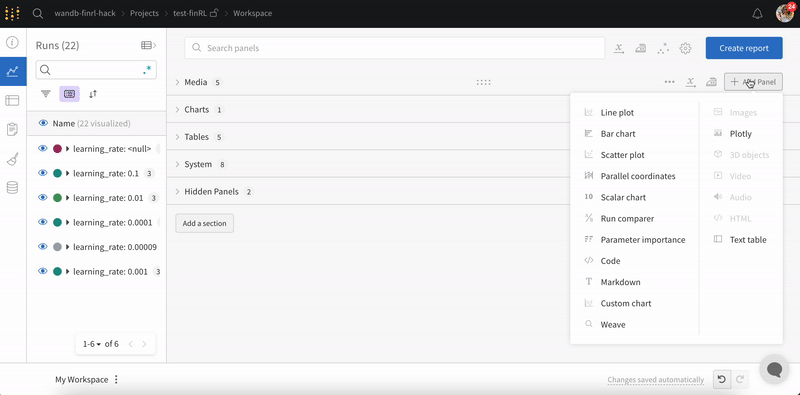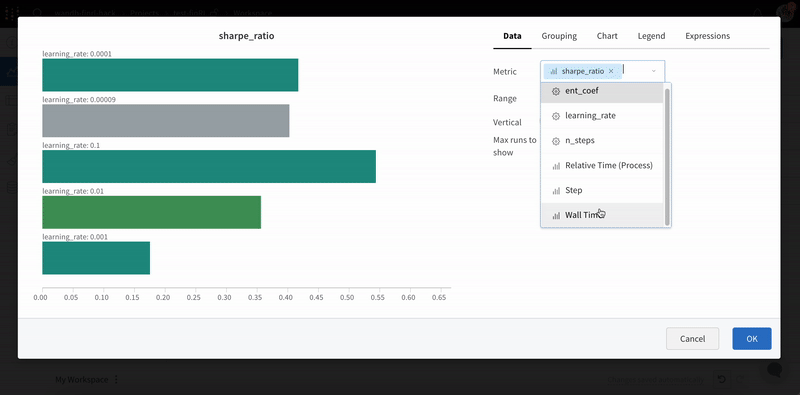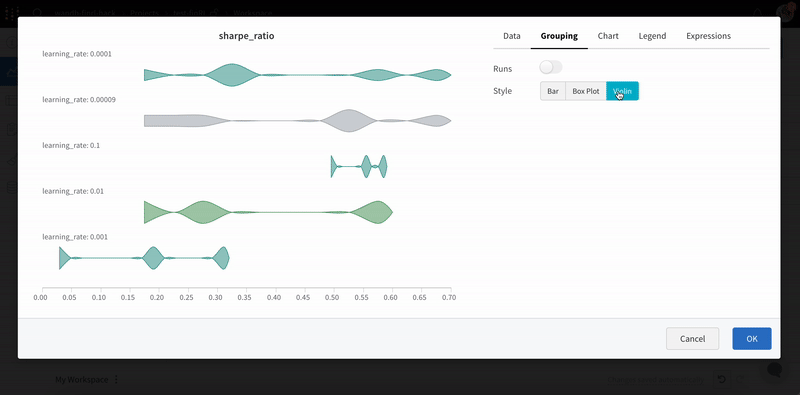
1.2 - 棒グラフ
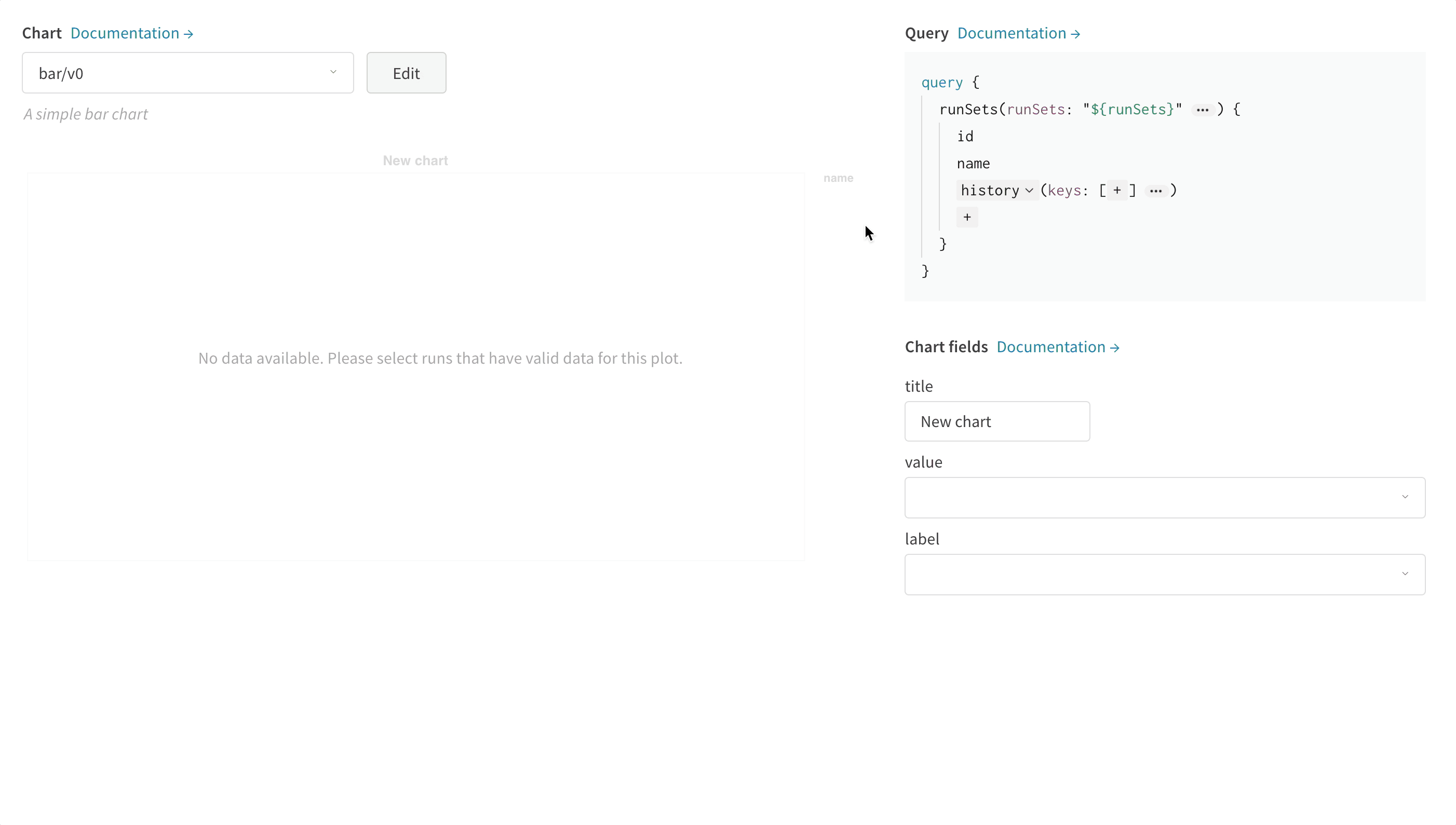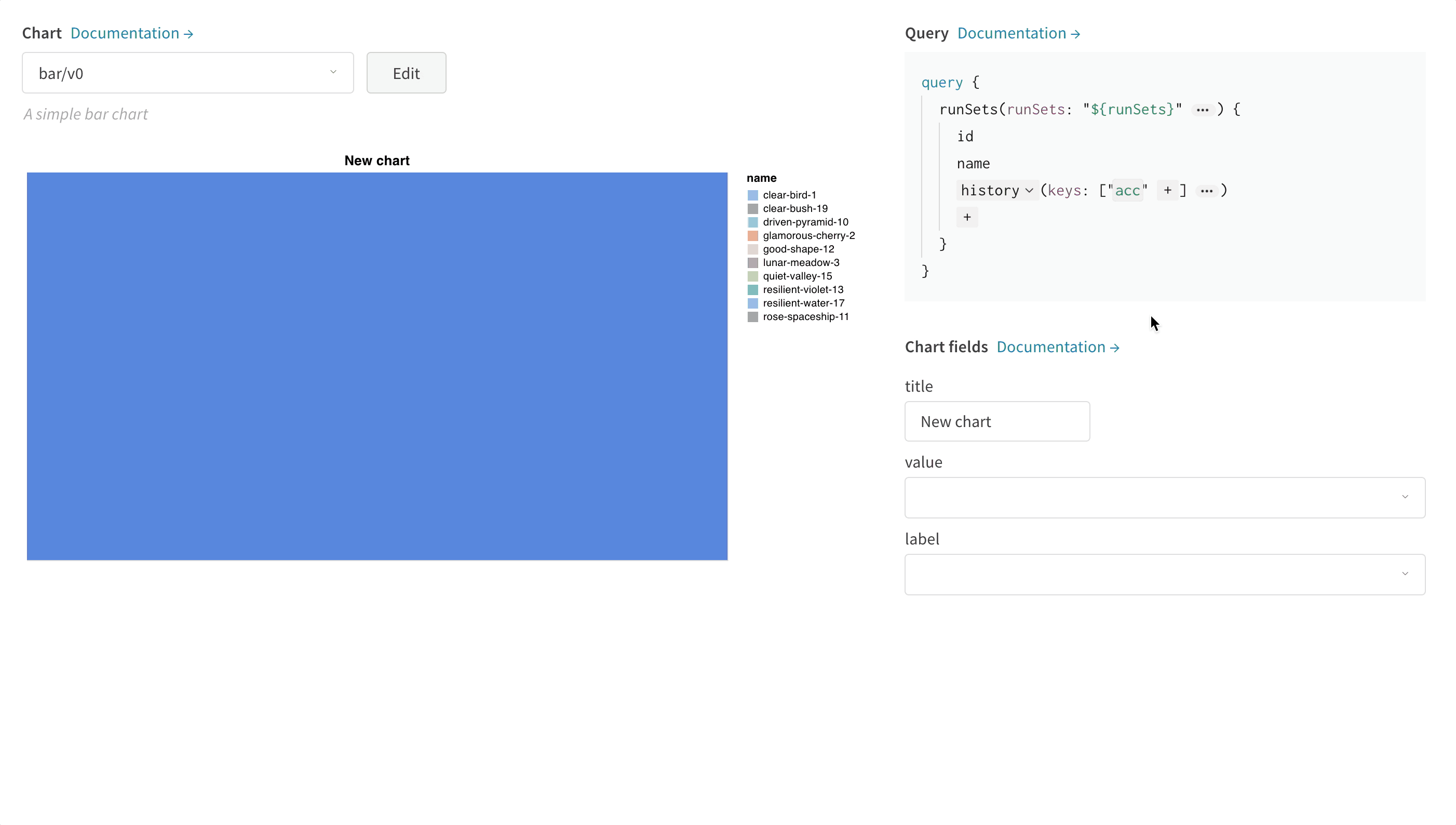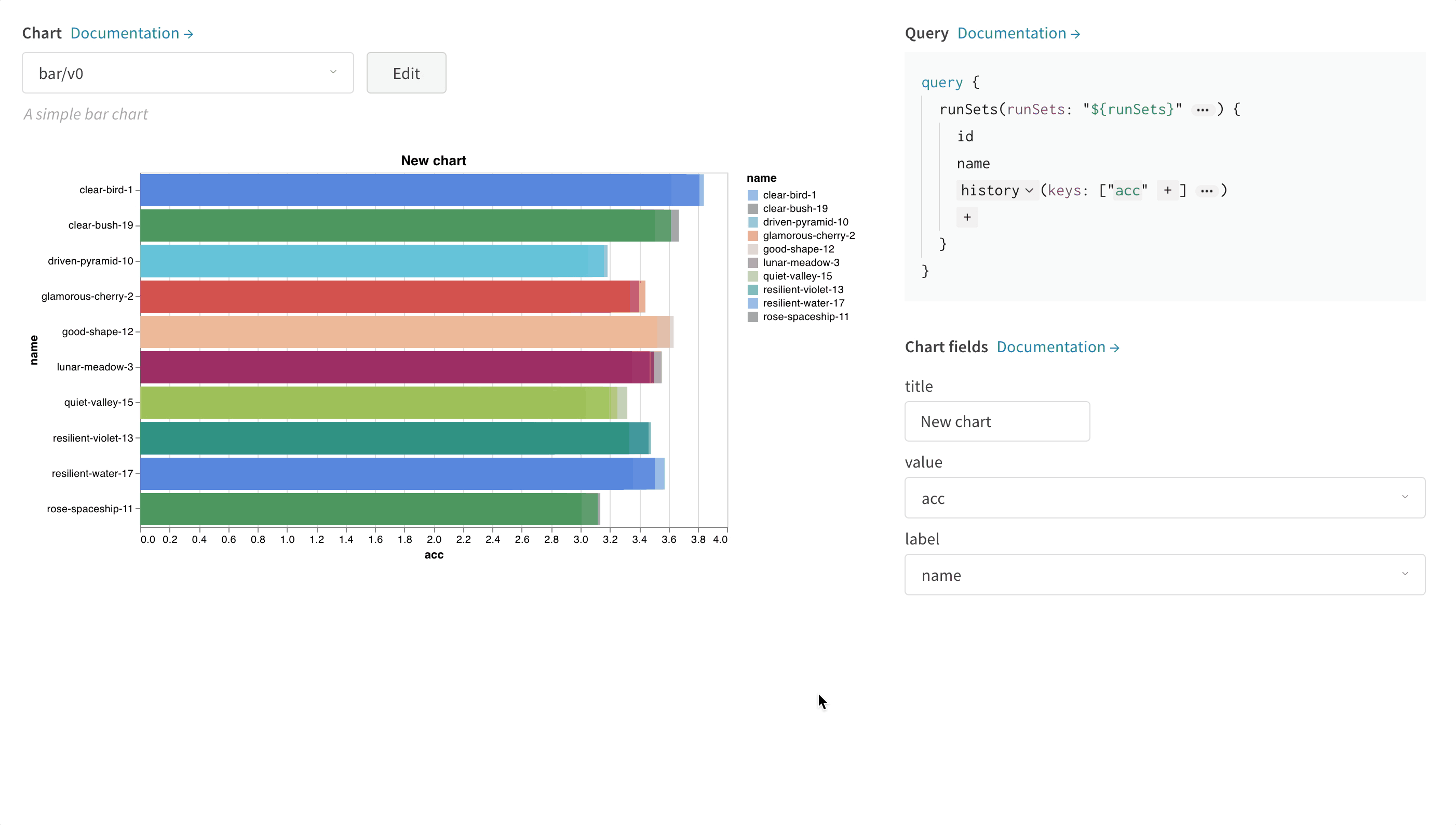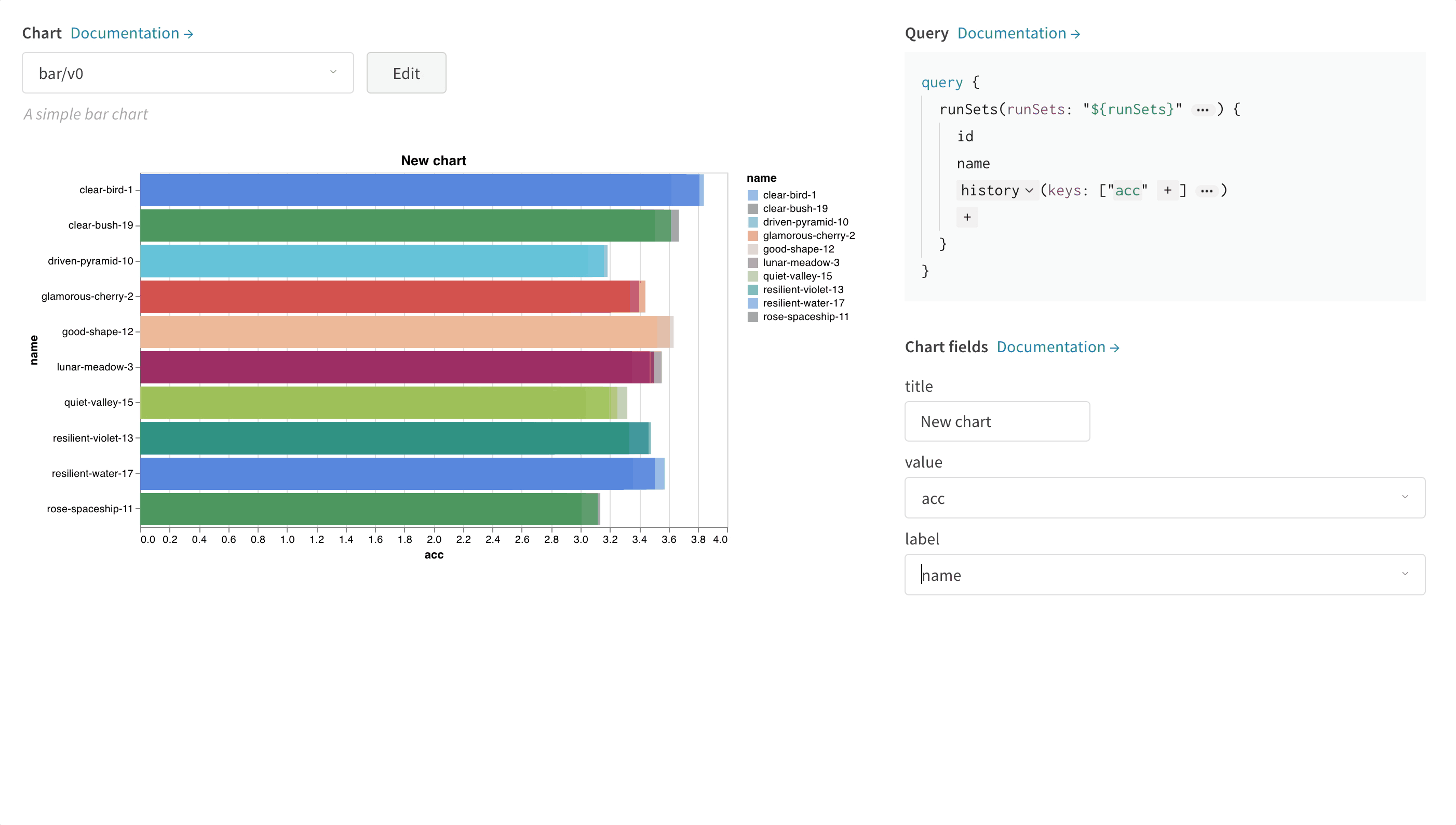
棒グラフは、矩形のバーでカテゴリカルデータを表示し、縦または横にプロットできます。全てのログされた値が長さ1の場合、wandb.log() を使用するとデフォルトで棒グラフが表示されます。
チャートの設定をカスタマイズして、表示する run の最大数を制限したり、任意の設定で run をグループ化したり、ラベルの名前を変更したりできます。
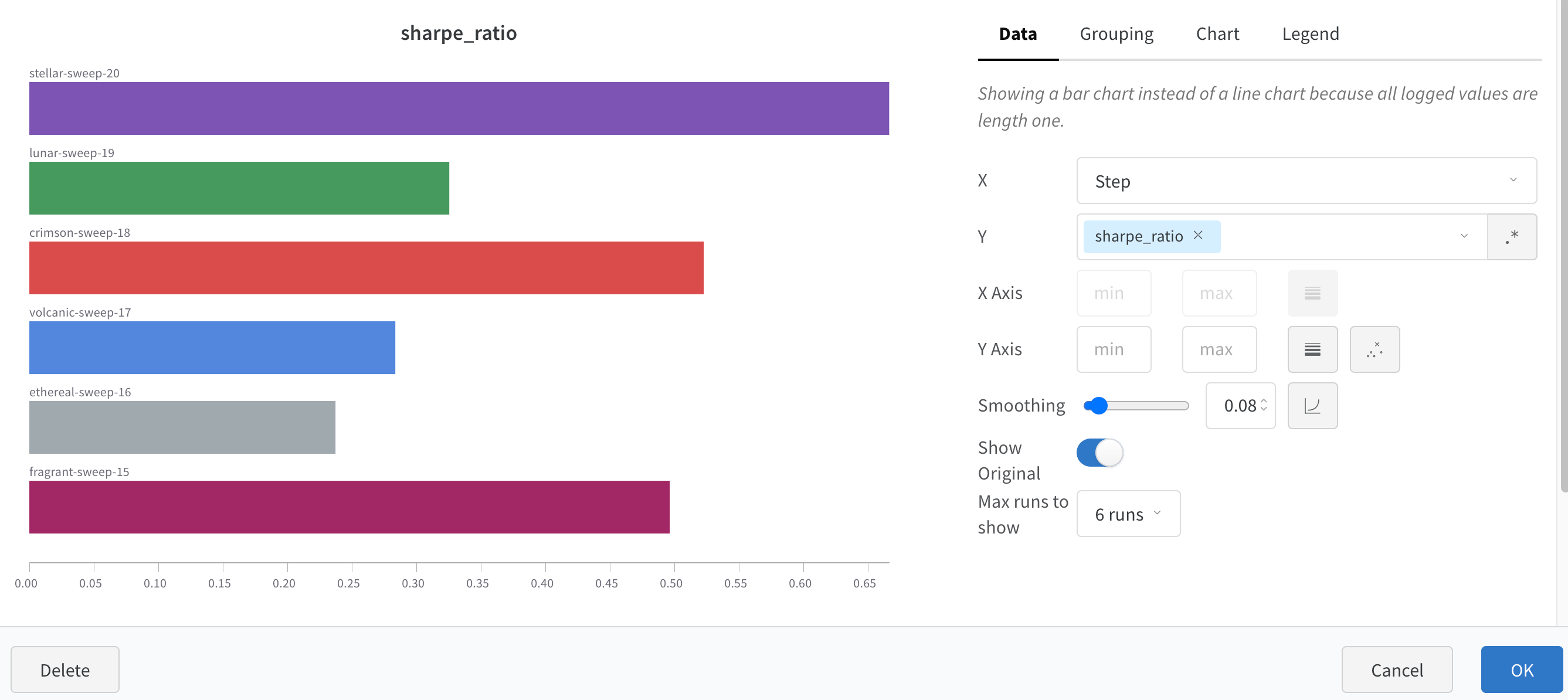
棒グラフのカスタマイズ
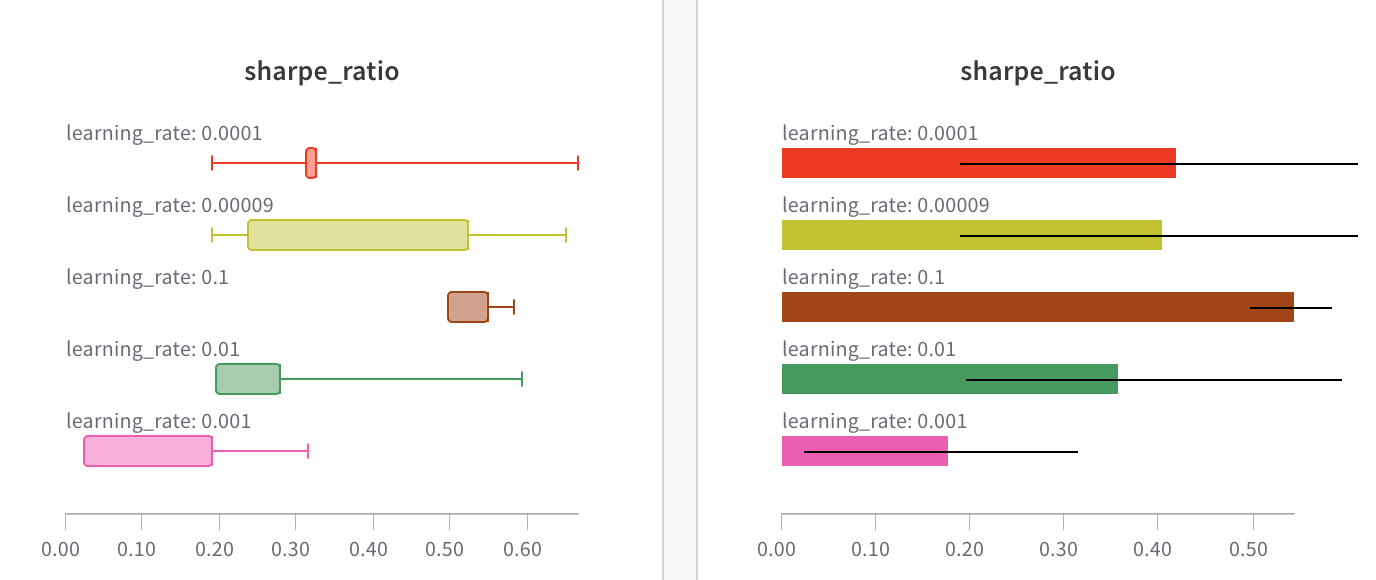
Box または Violin プロットを作成して、多くの要約統計量を1つのチャートタイプに組み合わせることもできます。
- run テーブルで run をグループ化します。
- ワークスペースで ‘Add panel’ をクリックします。
- 標準の ‘Bar Chart’ を追加し、プロットする指標を選択します。
- ‘Grouping’ タブの下で ‘box plot’ や ‘Violin’ などを選択して、これらのスタイルのいずれかをプロットします。
1.3 - 並列座標
大規模なハイパーパラメーターとモデルメトリクスの関係を一目で要約できるのがパラレル座標チャートです。
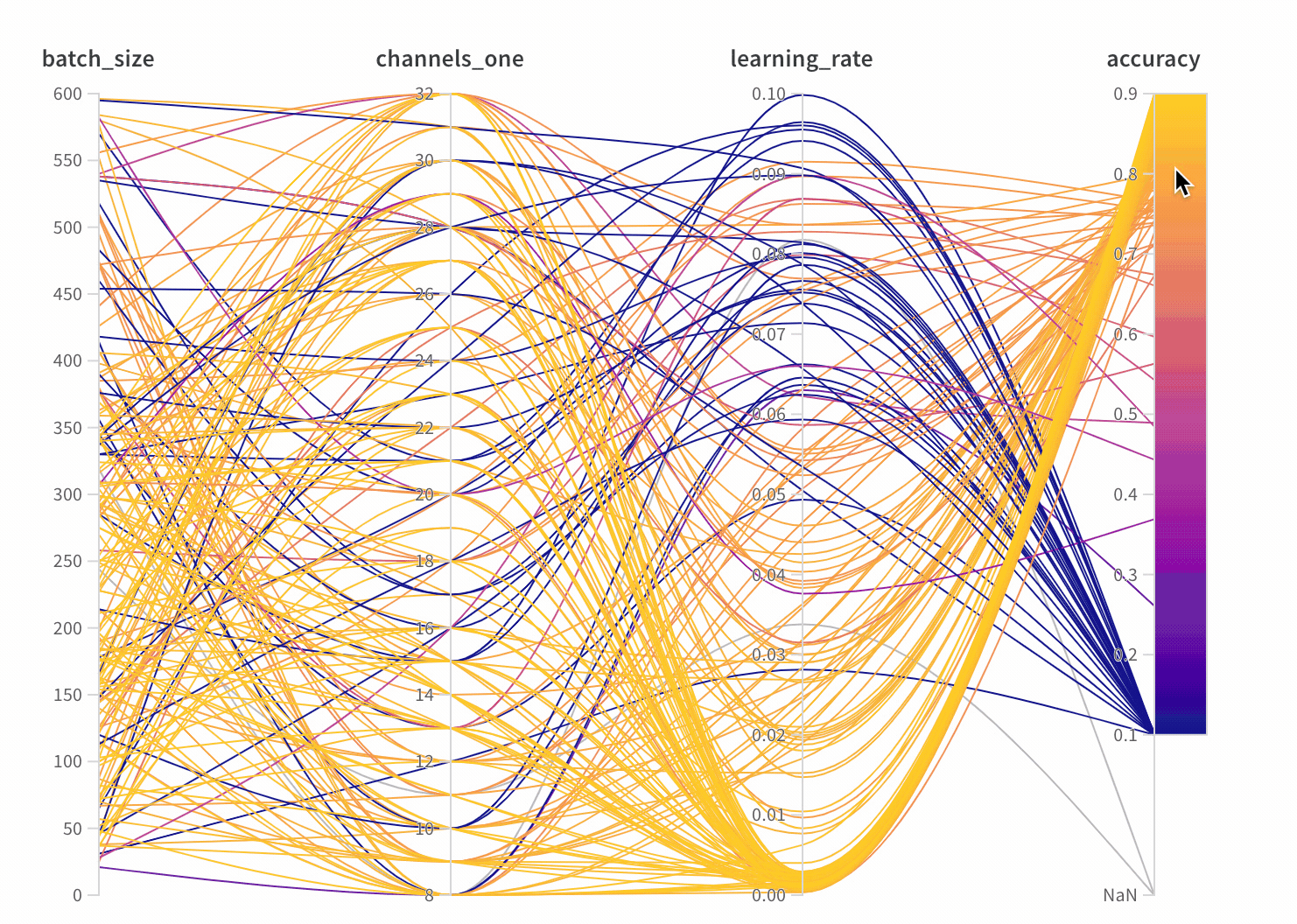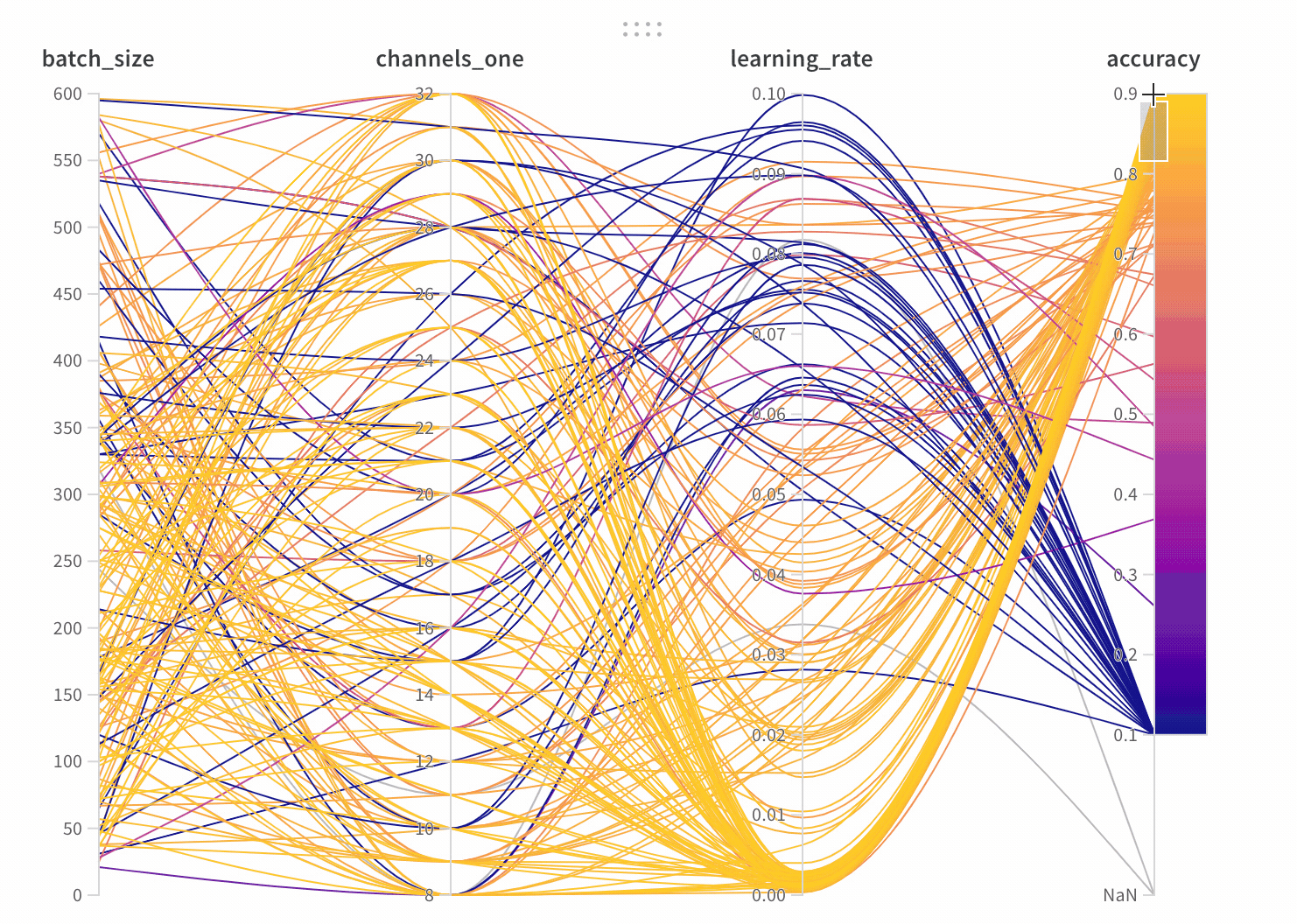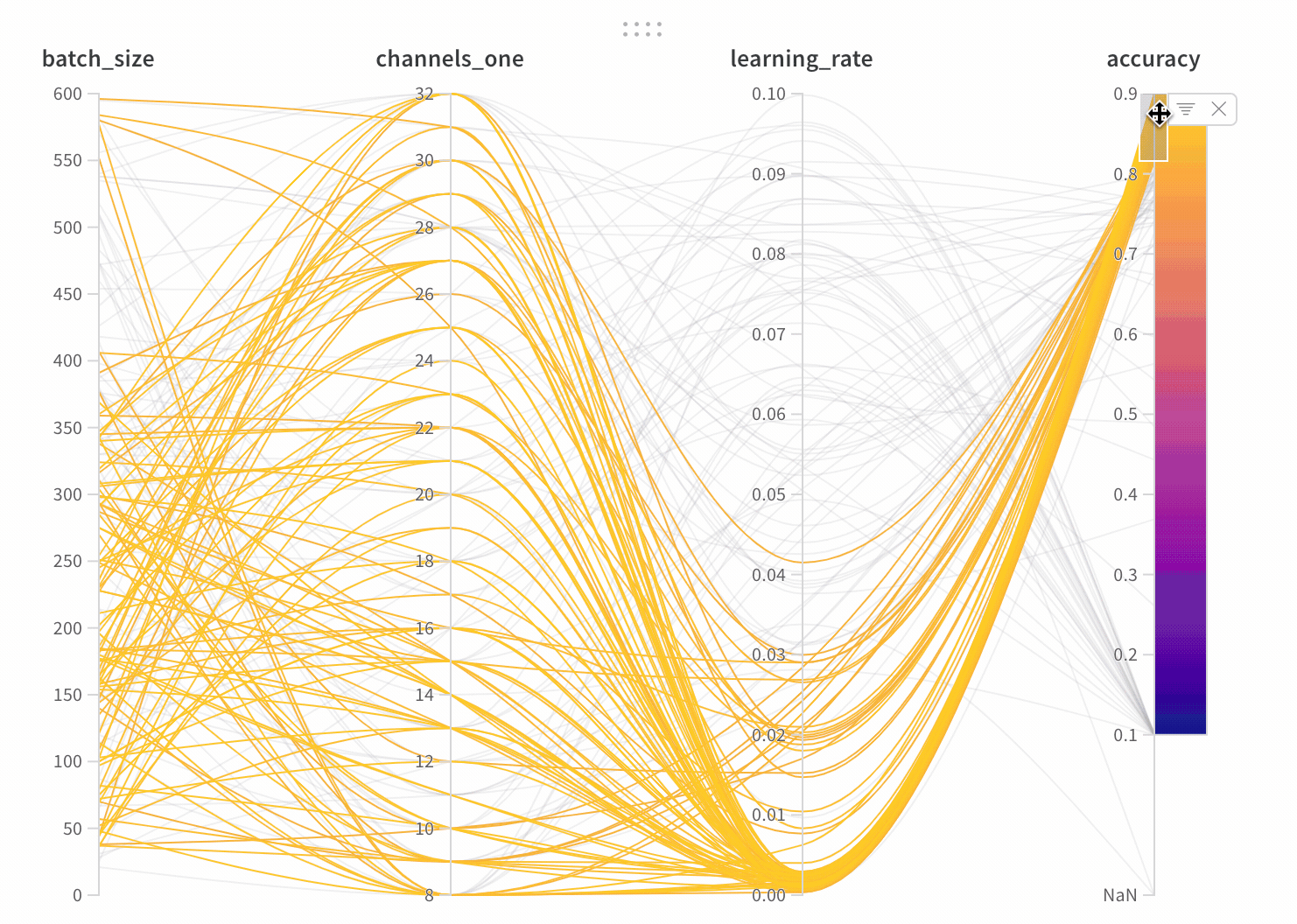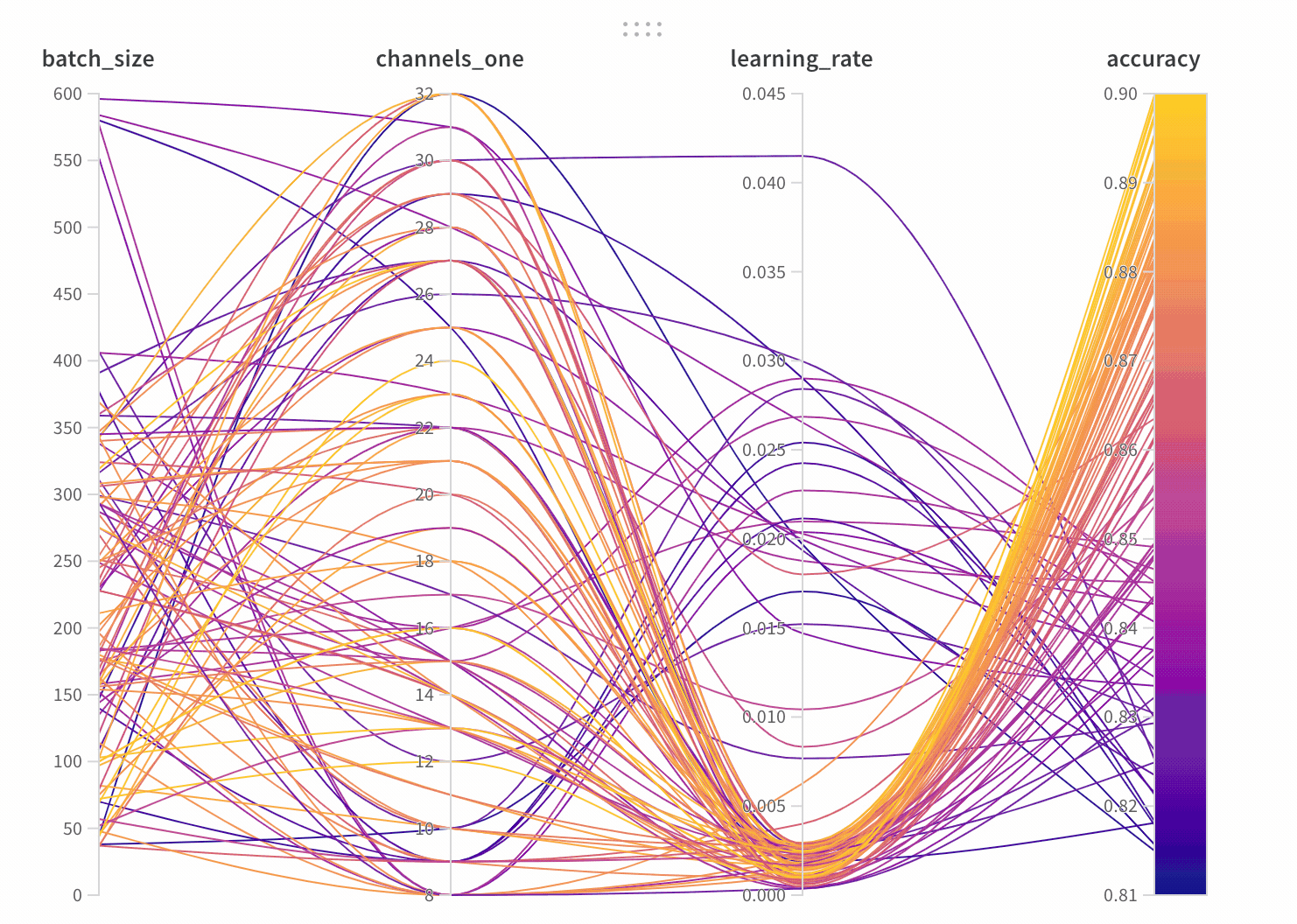
- 軸:
wandb.configからのさまざまなハイパーパラメーターとwandb.logからのメトリクス。 - ライン: 各ラインは単一の run を表します。ラインにマウスを合わせると、その run の詳細がツールチップで表示されます。現在のフィルターに一致するすべてのラインが表示されますが、目をオフにすると、ラインはグレー表示されます。
パラレル座標パネルを作成する
- ワークスペースのランディングページへ移動
- Add Panels をクリック
- Parallel coordinates を選択
パネル設定
パネルを設定するには、パネルの右上にある編集ボタンをクリックします。
- ツールチップ: ホバーすると、各 run の情報が表示されます
- タイトル: 軸のタイトルを編集して、より読みやすくします
- 勾配: グラデーションを好きな色の範囲にカスタマイズ
- ログスケール: 各軸は個別にログスケールで表示するように設定できます
- 軸の反転: 軸の方向を切り替え—正確性と損失を両方持つカラムがあるときに便利です
1.4 - 散布図
このページでは、W&B で散布図を使用する方法を示します。
ユースケース
散布図を使用して、複数の runs を比較し、実験のパフォーマンスを視覚化します。
- 最小値、最大値、および平均値のプロットラインを表示する。
- メタデータのツールチップをカスタマイズする。
- ポイントの色を制御する。
- 軸の範囲を調整する。
- 軸に対して対数スケールを使用する。
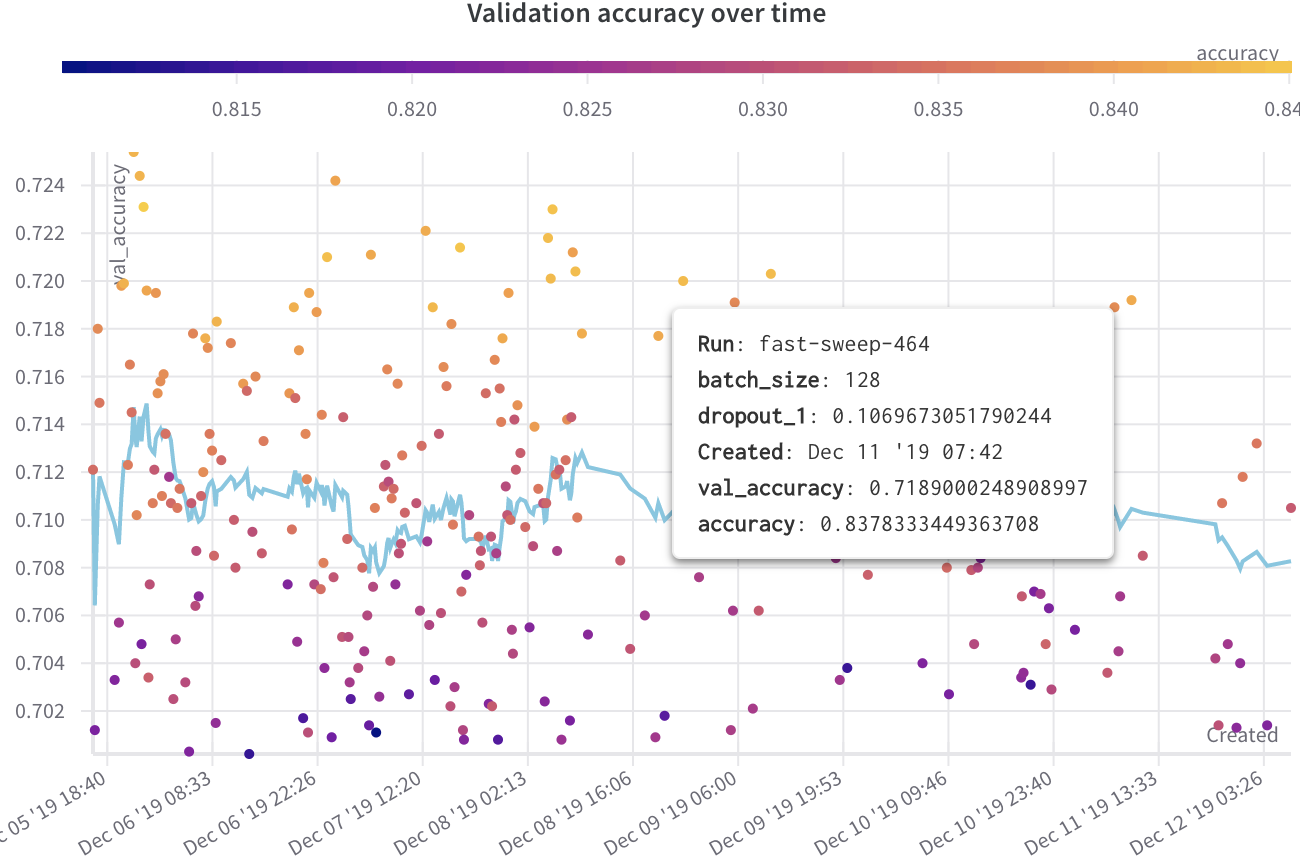
例
次の例では、異なるモデルの数週間にわたる実験による検証精度を表示する散布図を示しています。ツールチップには、バッチサイズ、ドロップアウト、および軸の値が含まれています。また、検証精度のランニング平均を示す線も表示されます。
散布図を作成する
W&B UI で散布図を作成するには:
- Workspaces タブに移動します。
- Charts パネルで、アクションメニュー
...をクリックします。 - ポップアップメニューから、Add panels を選択します。
- Add panels メニューで、Scatter plot を選択します。
- プロットしたいデータを表示するために
xおよびy軸を設定します。必要に応じて、軸の最大および最小範囲を設定するか、z軸を追加してください。 - Apply をクリックして散布図を作成します。
- 新しい散布図を Charts パネルで確認します。
1.5 - コードを保存して差分を取る
デフォルトでは、W&Bは最新のgitコミットハッシュのみを保存します。UIで実験間のコードを動的に比較するためのより多くのコード機能を有効にできます。
wandb バージョン 0.8.28 から、W&Bは wandb.init() を呼び出すメインのトレーニングファイルからコードを保存することができます。
ライブラリコードを保存する
コード保存を有効にすると、W&Bは wandb.init() を呼び出したファイルからコードを保存します。追加のライブラリコードを保存するには、以下の3つのオプションがあります:
wandb.init を呼び出した後に wandb.run.log_code(".") を呼び出す
import wandb
wandb.init()
wandb.run.log_code(".")
code_dir を設定して wandb.init に設定オブジェクトを渡す
import wandb
wandb.init(settings=wandb.Settings(code_dir="."))
これにより、現在のディレクトリーおよびすべてのサブディレクトリー内のPythonソースコードファイルがアーティファクトとしてキャプチャされます。保存されるソースコードファイルの種類と場所をより詳細に制御するには、リファレンスドキュメントを参照してください。
UIでコード保存を設定する
コード保存をプログラム的に設定する以外に、W&Bアカウントの設定でこの機能を切り替えることもできます。これを有効にすると、アカウントに関連付けられているすべてのチームでコード保存が有効になります。
デフォルトでは、W&Bはすべてのチームでコード保存を無効にします。
- W&Bアカウントにログインします。
- 設定 > プライバシー に移動します。
- プロジェクトとコンテンツのセキュリティ の下で、デフォルトのコード保存を無効にする をオンにします。
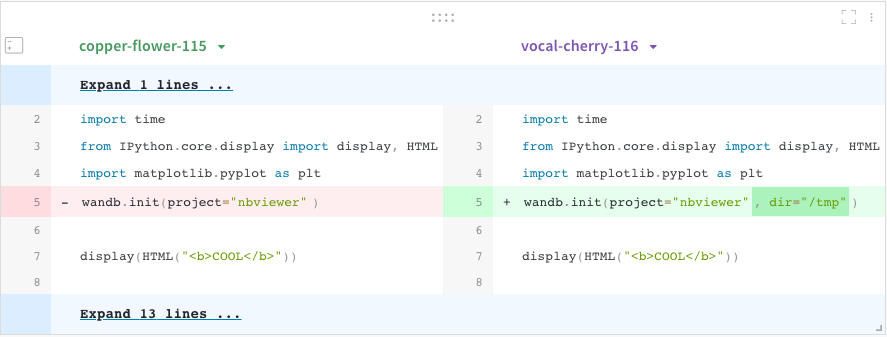
コードコンペアラー
異なるW&B runで使用されたコードを比較する:
- ページの右上隅にある パネルを追加 ボタンを選択します。
- TEXT AND CODE ドロップダウンを展開し、コード を選択します。
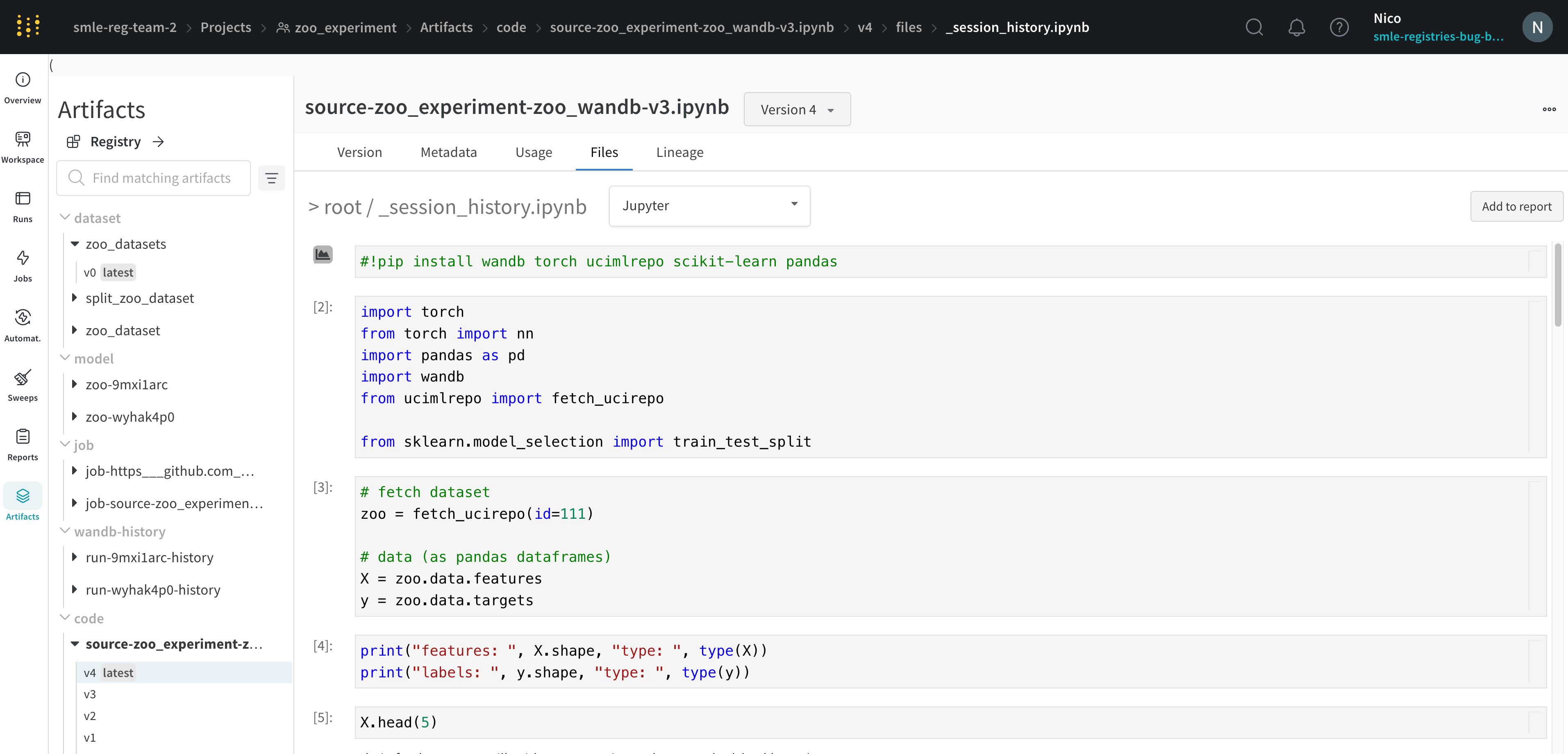
Jupyterセッション履歴
W&BはJupyterノートブックセッションで実行されたコードの履歴を保存します。Jupyter内でwandb.init() を呼び出すと、W&Bは現在のセッションで実行されたコードの履歴を含むJupyterノートブックを自動的に保存するフックを追加します。
- コードが含まれているプロジェクトワークスペースに移動します。
- 左ナビゲーションバーのArtifacts タブを選択します。
- コードアーティファクトを展開します。
- ファイルタブを選択します。
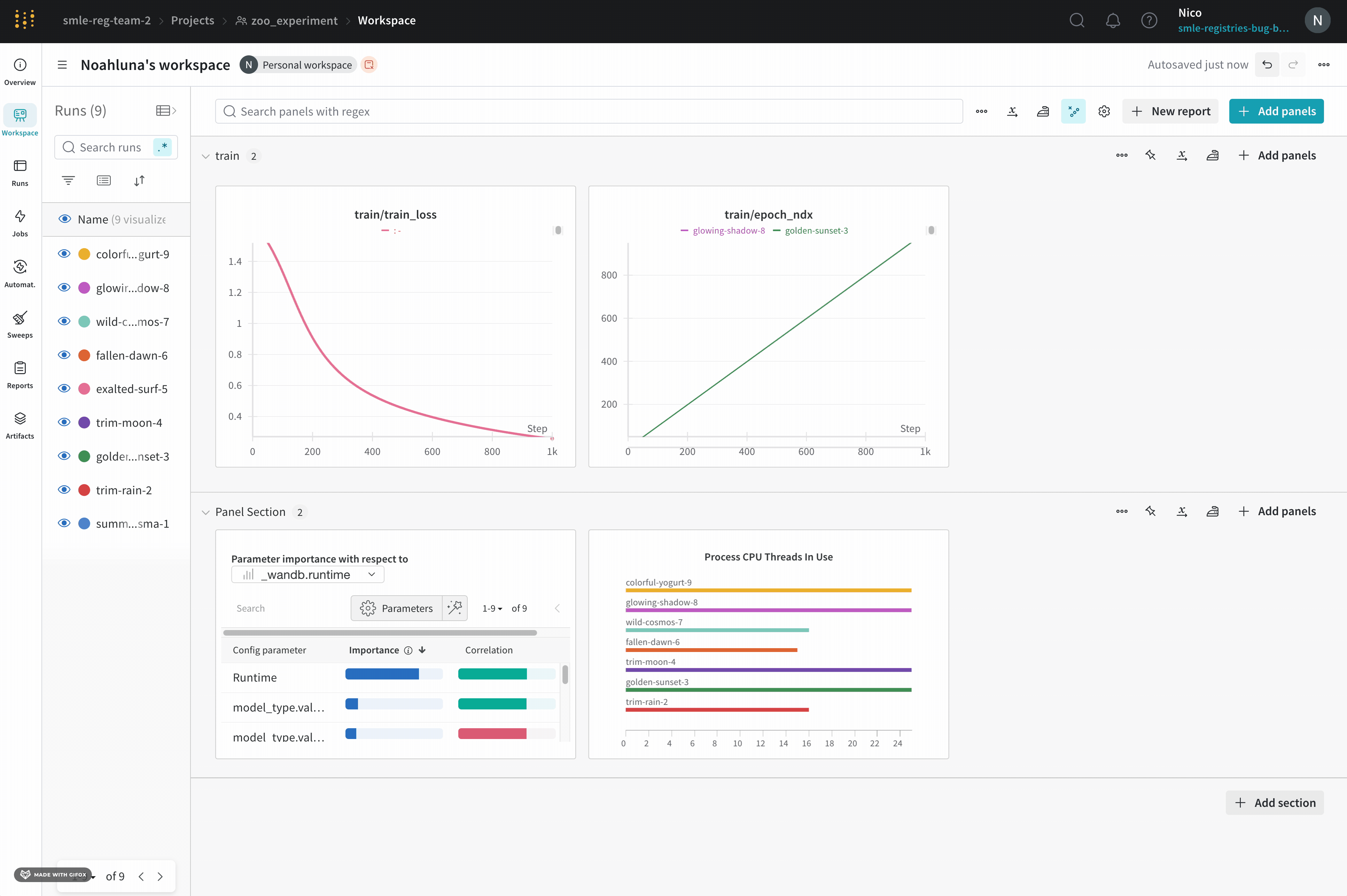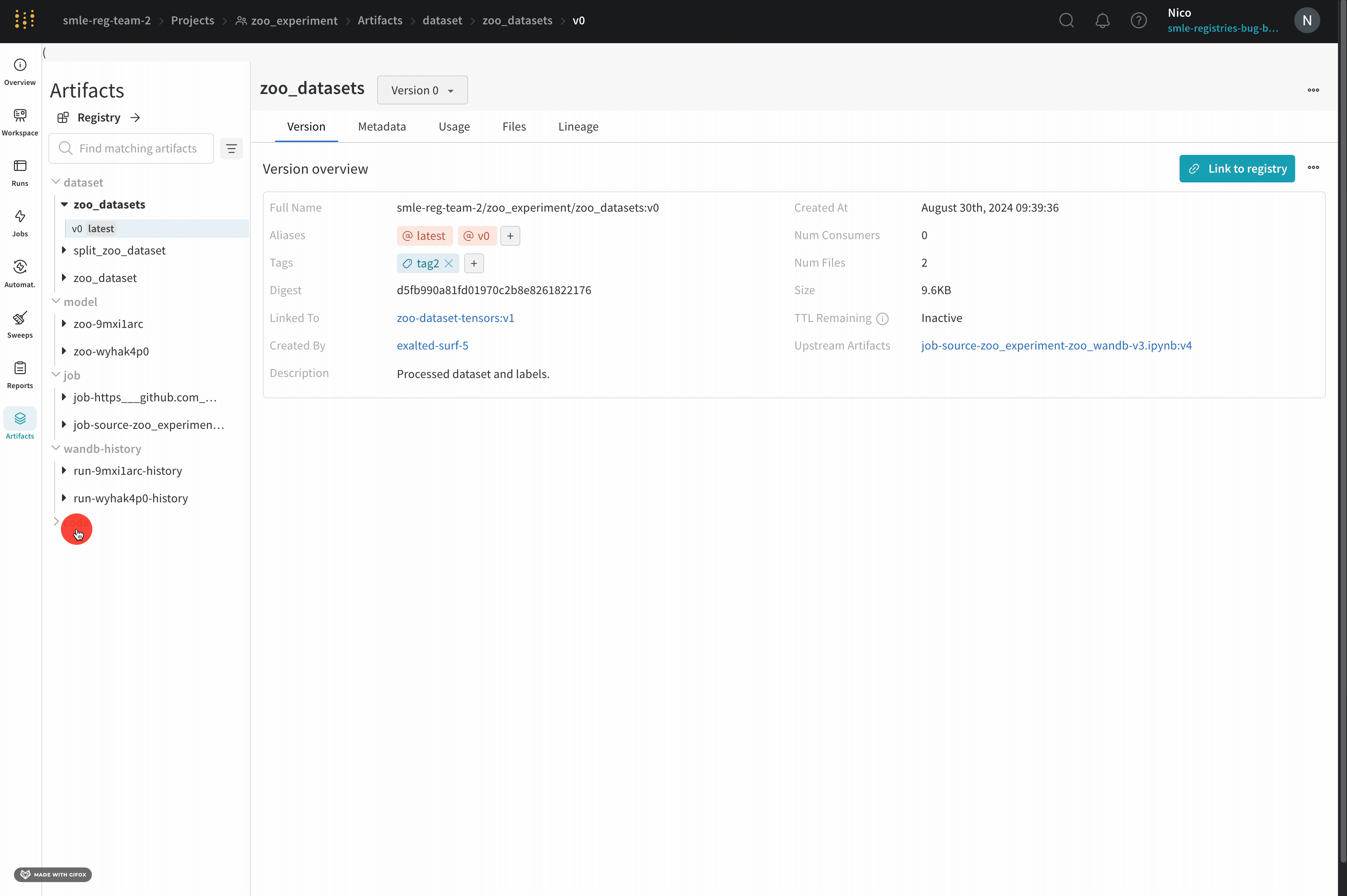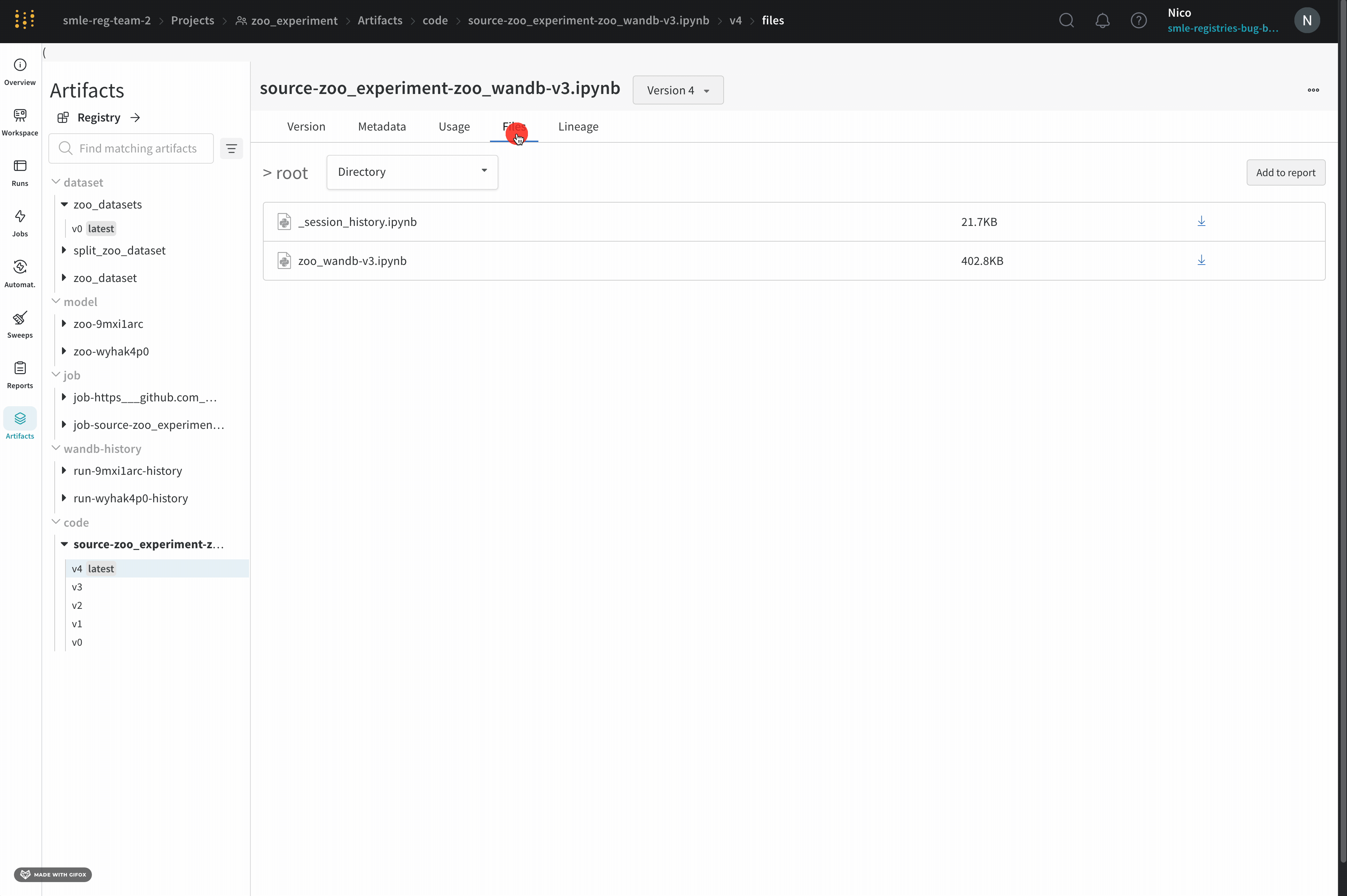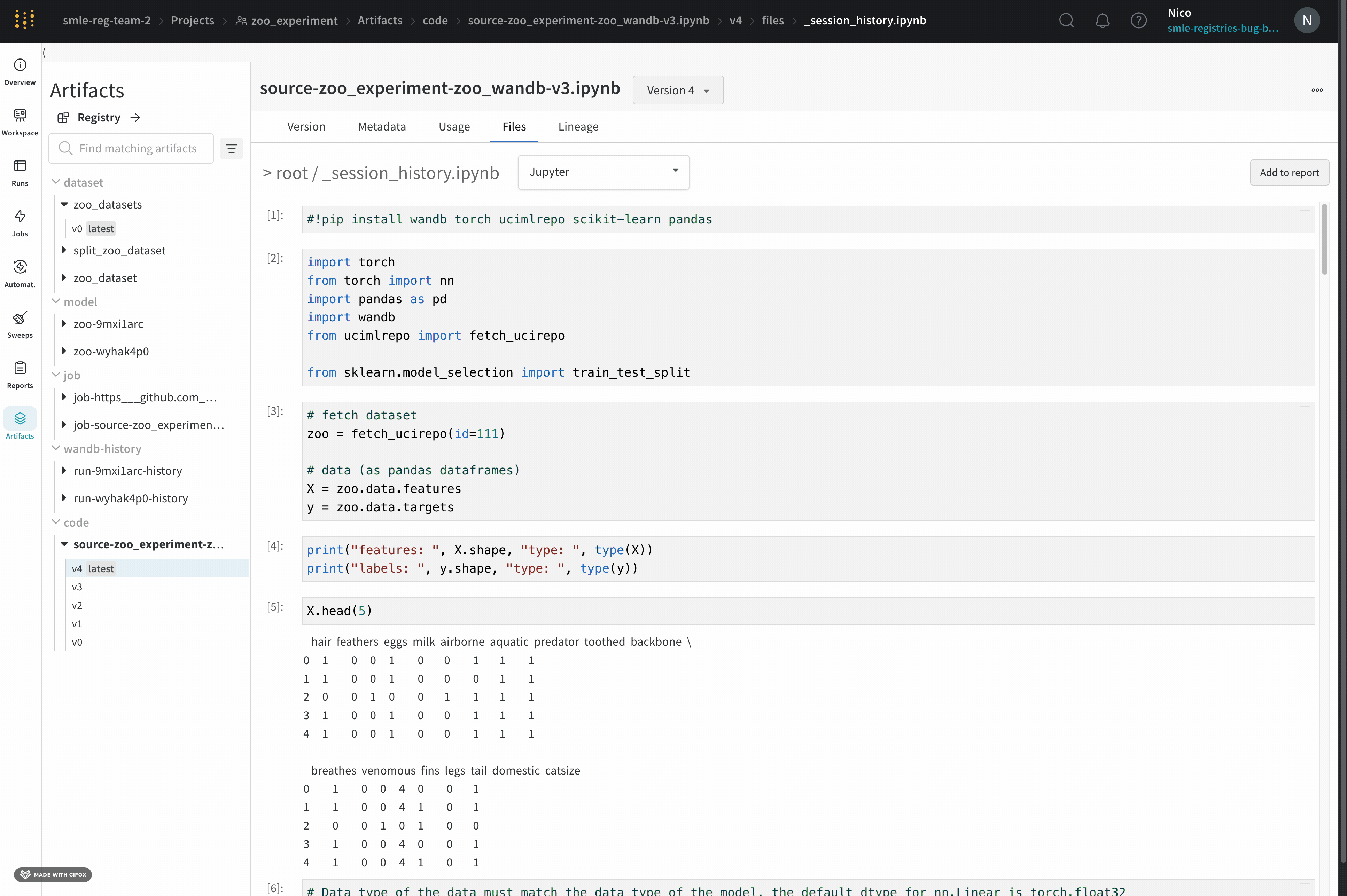
これは、セッションで実行されたセルと、iPythonの表示メソッドを呼び出して作成された出力を表示します。これにより、指定されたrunのJupyter内でどのコードが実行されたかを正確に確認することができます。可能な場合、W&Bはノートブックの最新バージョンも保存し、コードディレクトリー内で見つけることができます。
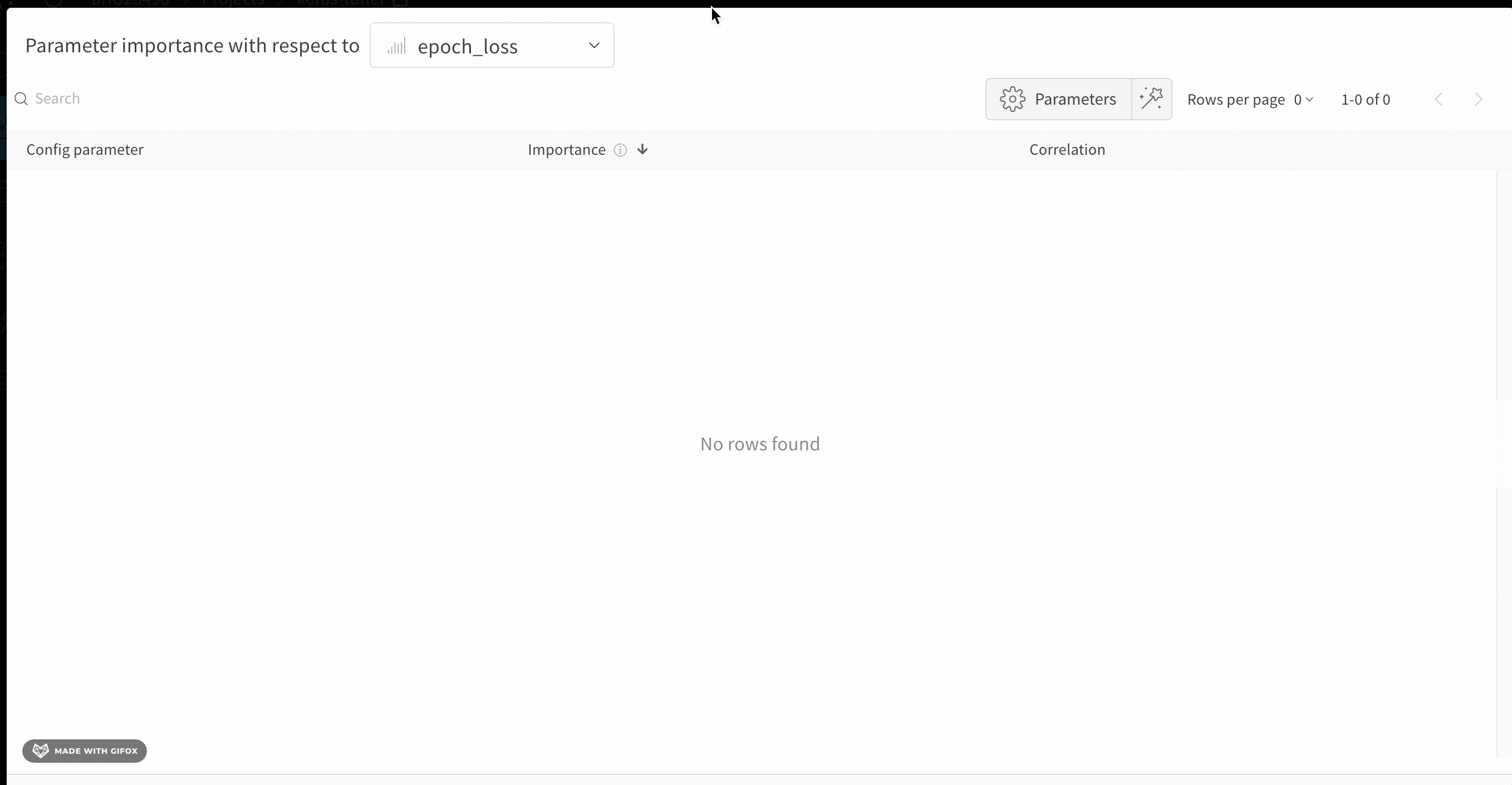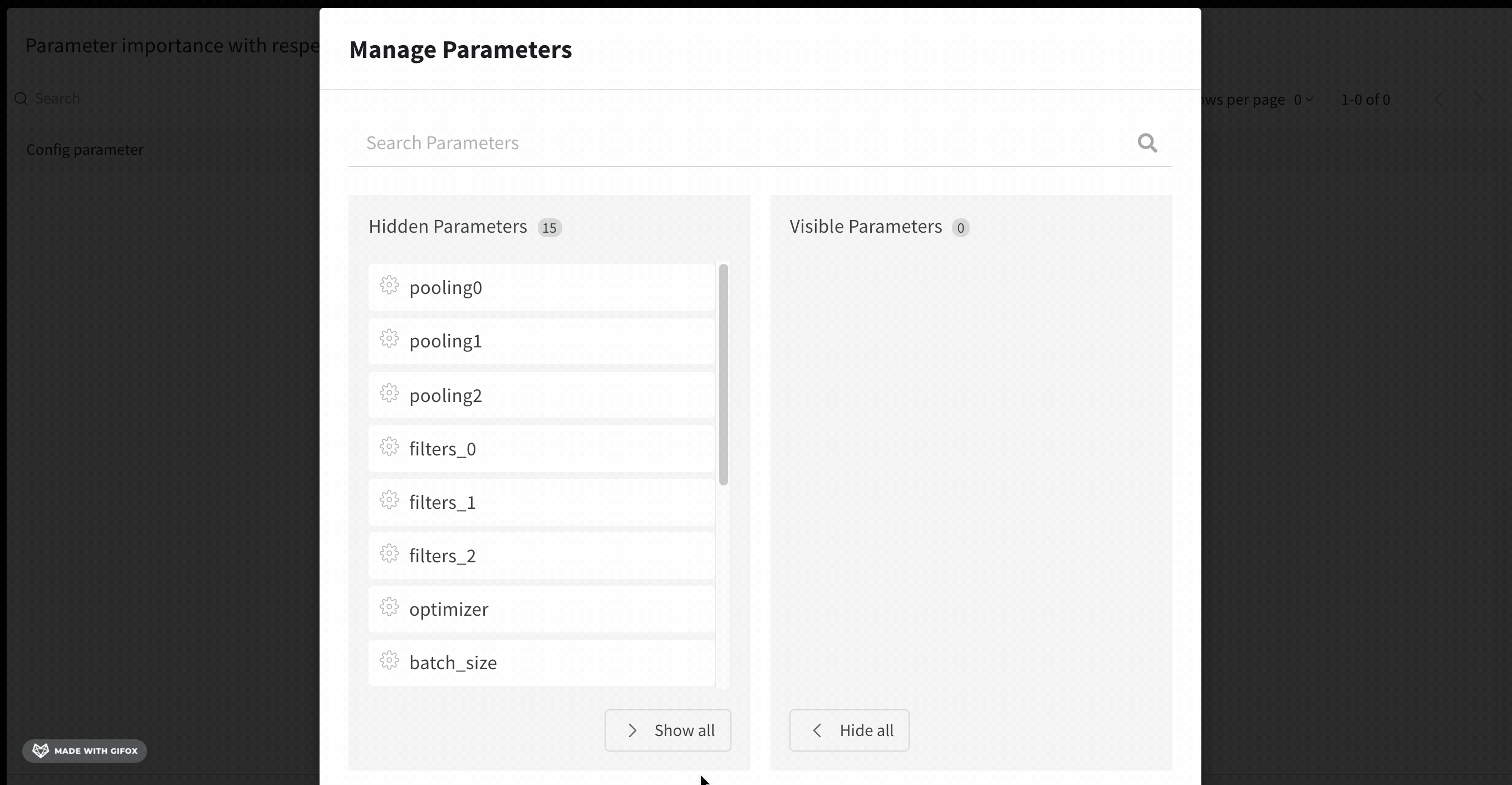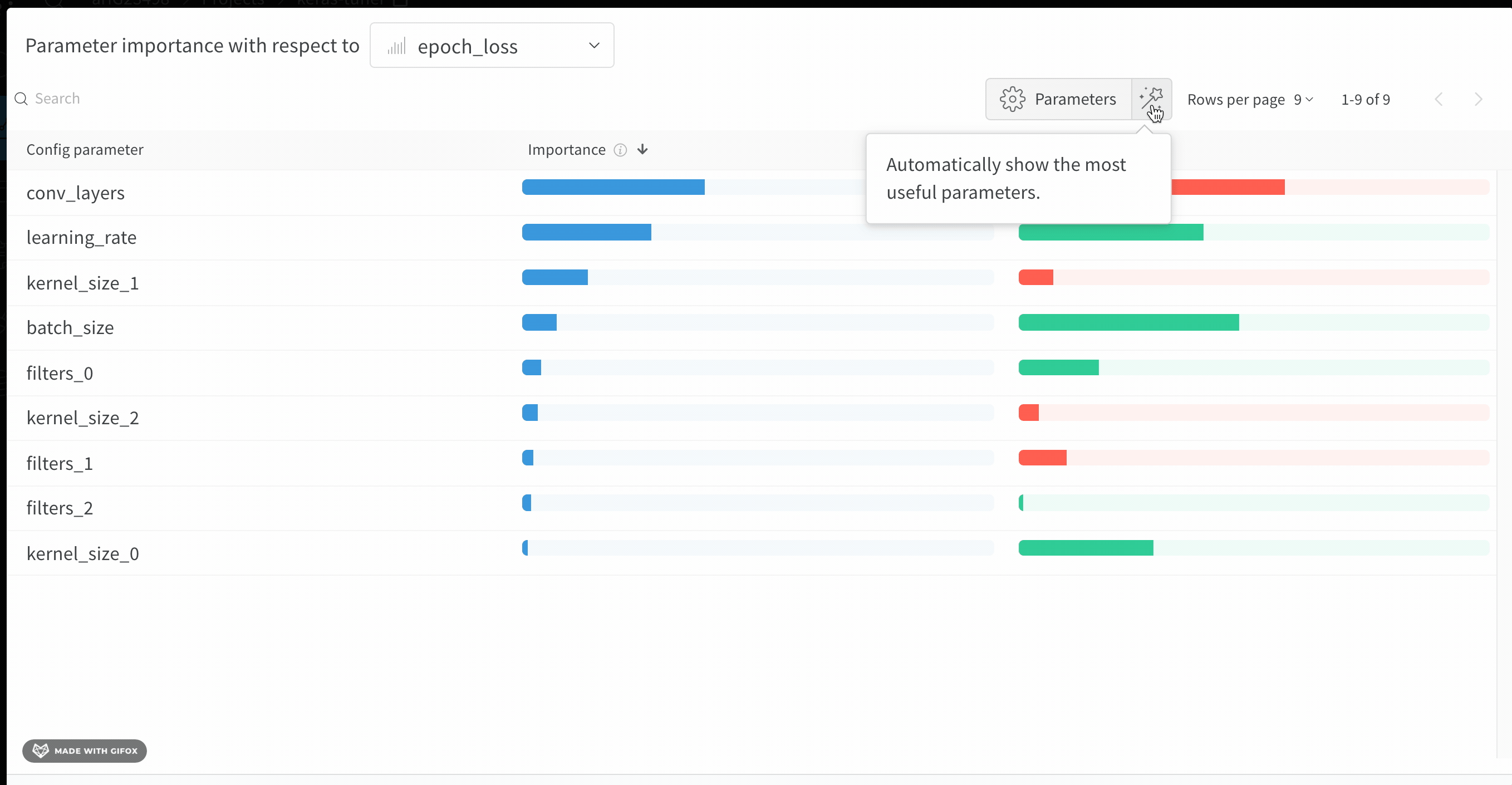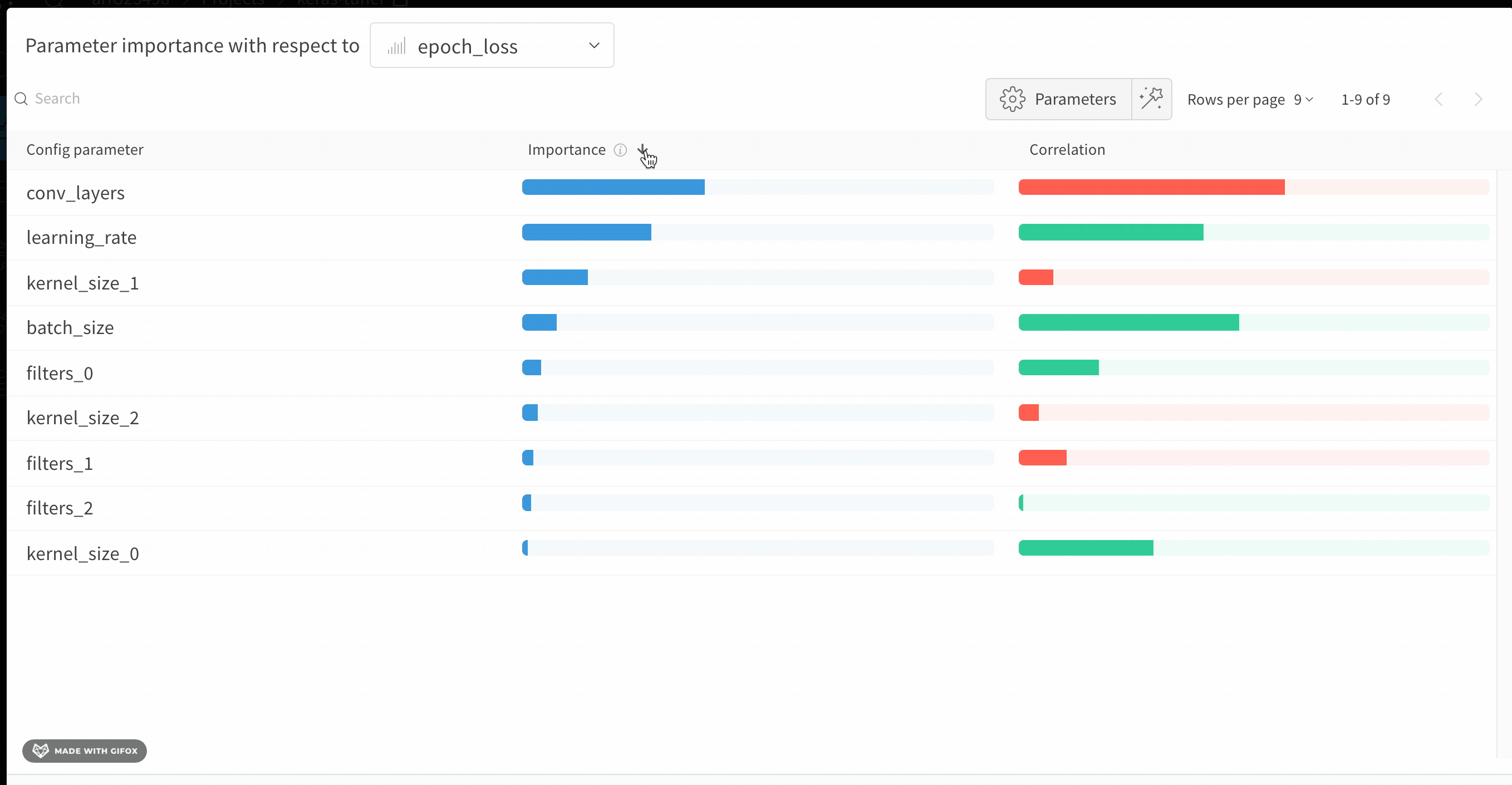
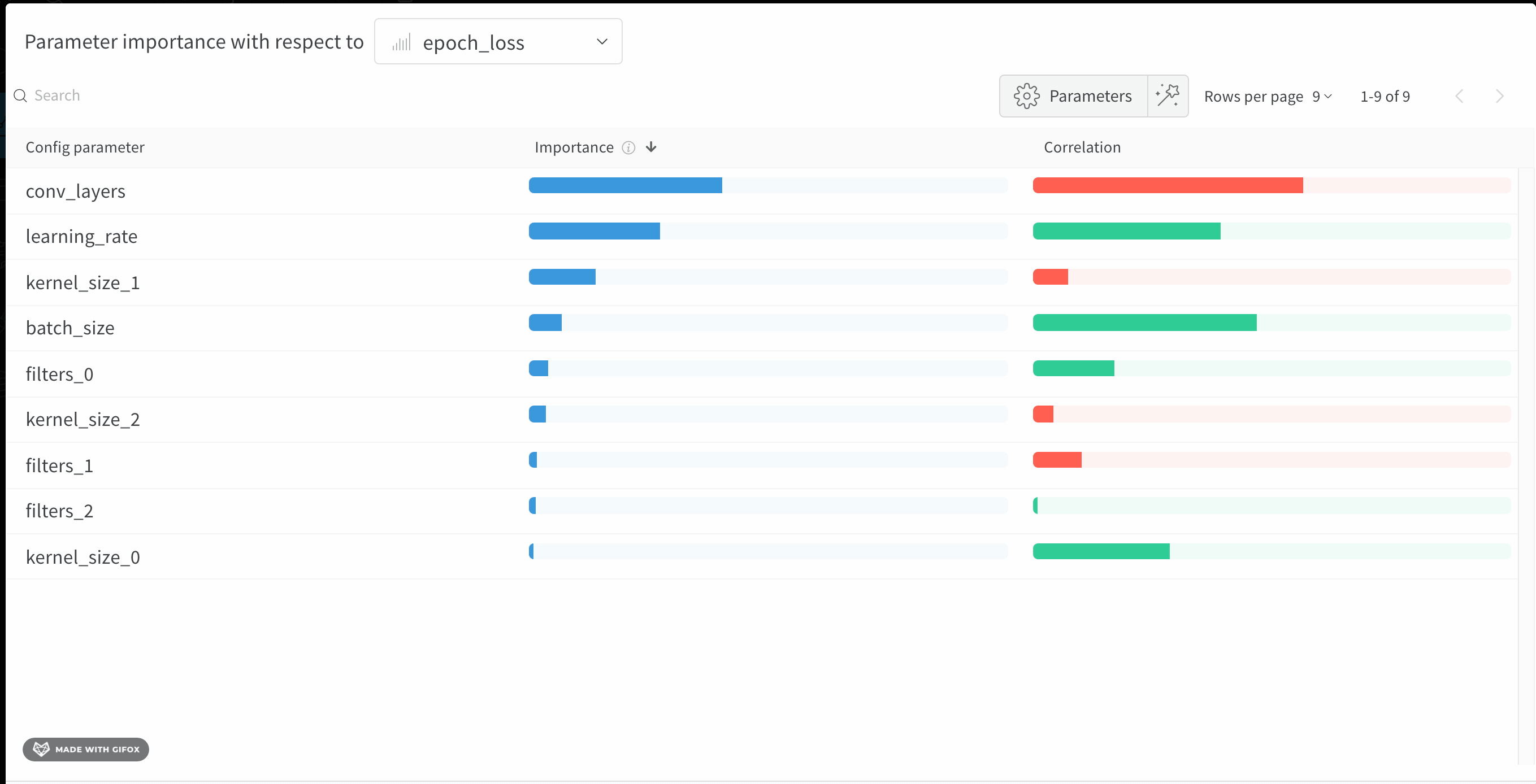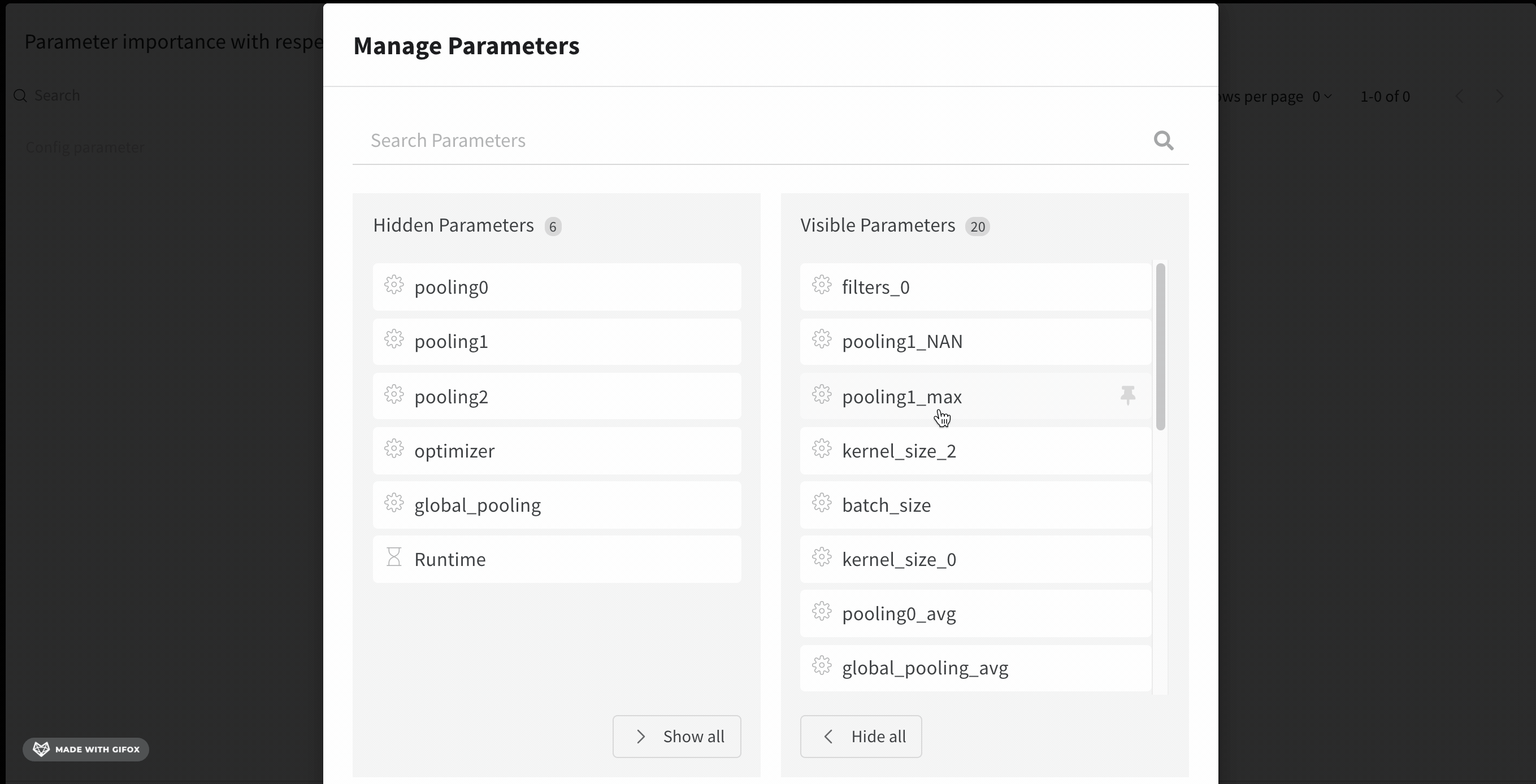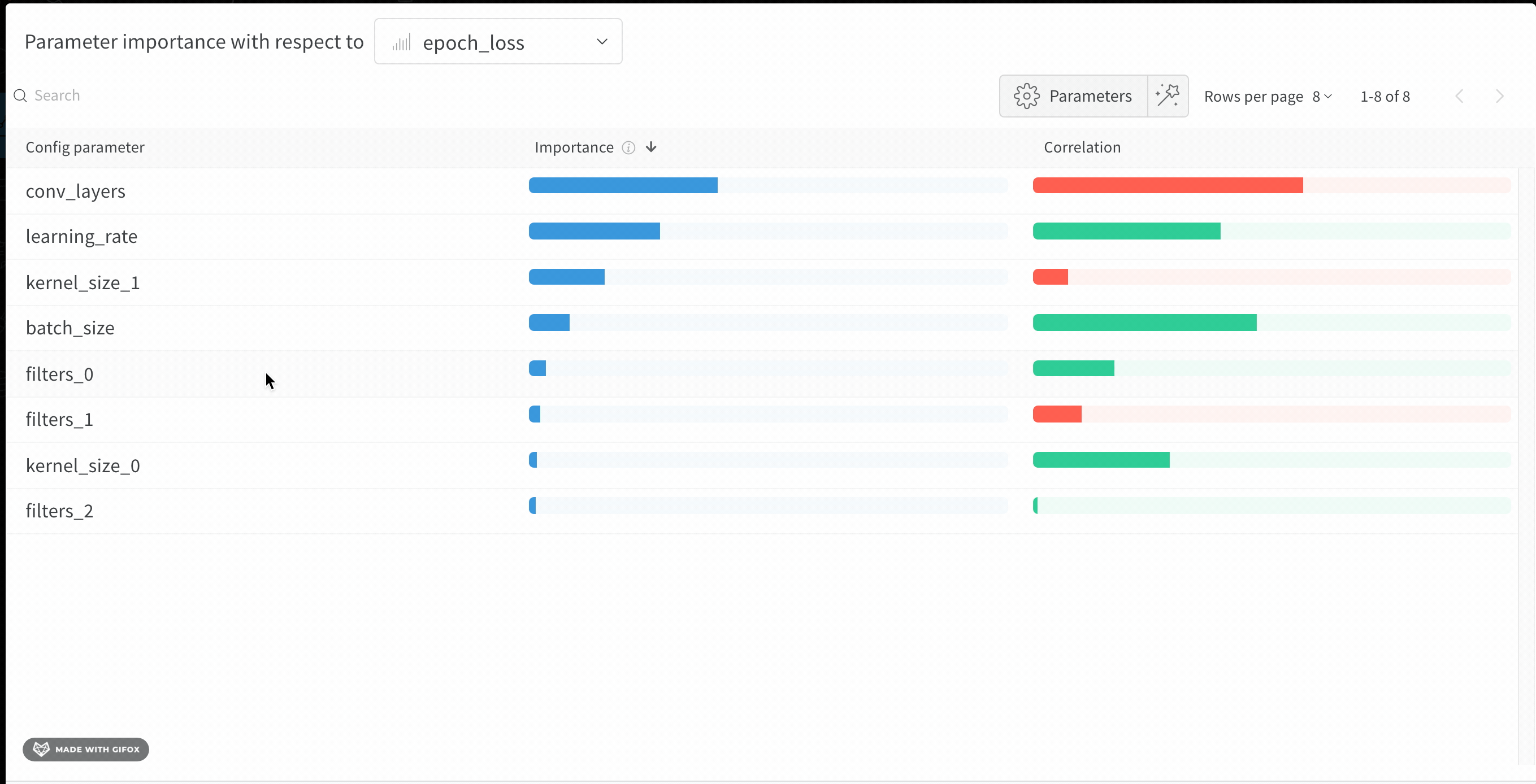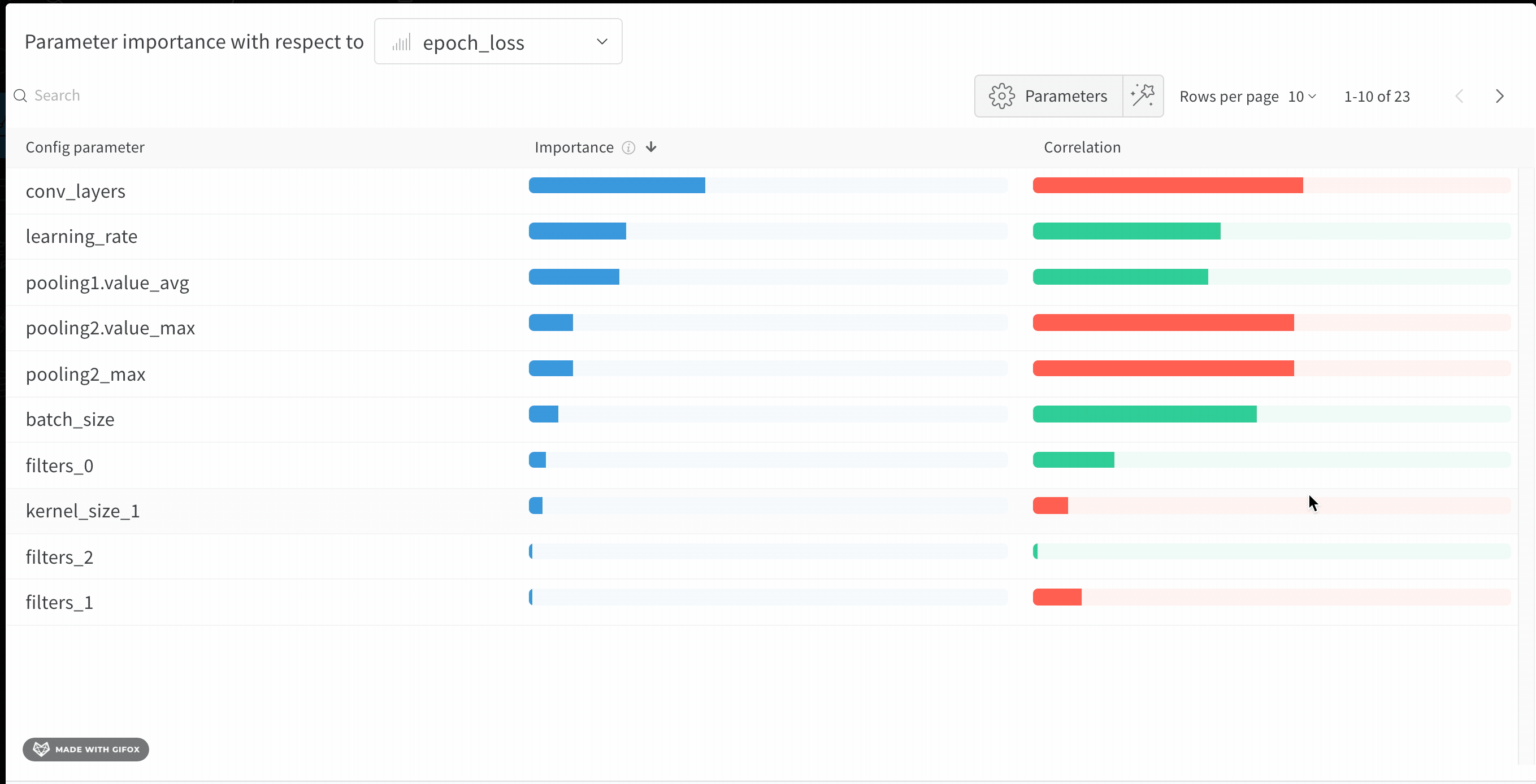
1.6 - パラメータの重要度
ハイパーパラメーターがどのようにメトリクスの望ましい値の予測に役立ったか、また高い相関があったかを発見しましょう。
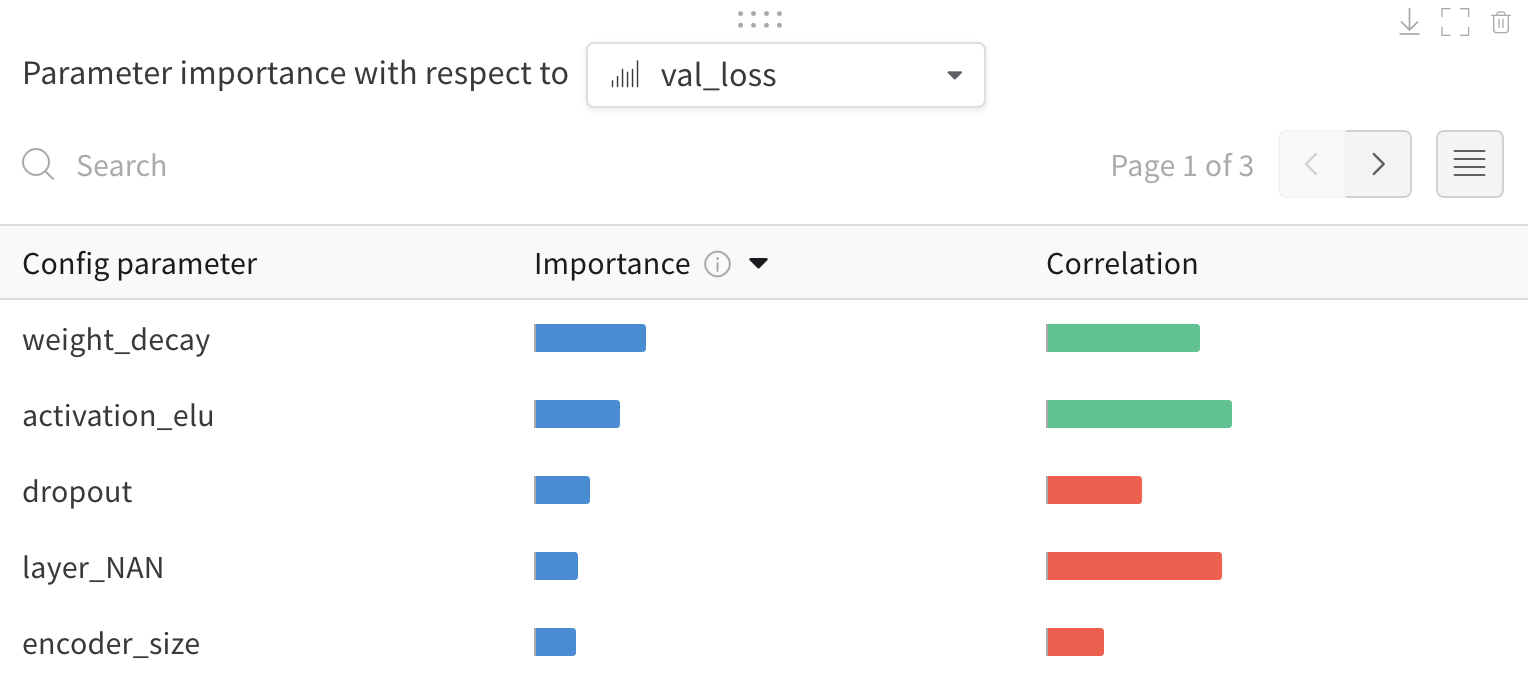
相関 とは、ハイパーパラメーターと選択されたメトリクスの線形相関を意味します(この場合は val_loss)。したがって、高い相関はハイパーパラメーターの値が高いとき、メトリクスの値も高くなり、その逆もまた然りであることを示します。相関は注目すべき素晴らしいメトリクスですが、入力間の二次の相互作用を捉えることはできず、非常に異なる範囲の入力を比較することが煩雑になる可能性があります。
そのため、W&Bは 重要度 メトリクスも計算します。W&Bはハイパーパラメーターを入力として、ランダムフォレストをトレーニングし、メトリクスをターゲット出力として、ランダムフォレストの特徴重要度値をレポートします。
この手法のアイデアは、Jeremy Howard との会話からインスピレーションを受け、Fast.aiにおいてハイパーパラメータースペースを探るためのランダムフォレストの特徴重要度の使用を推進してきたことから生まれました。W&Bはこの分析の背後にある動機を学ぶために、この講義 (およびこれらのノート)をチェックすることを強くお勧めします。
ハイパーパラメーター重要度パネルは、高い相関のハイパーパラメーター間の複雑な相互作用を解きほぐします。そして、モデルのパフォーマンスを予測する上で、どのハイパーパラメーターが最も重要であるかを示すことによって、ハイパーパラメーターの探索を調整するのに役立ちます。
ハイパーパラメーター重要度パネルの作成
- W&B プロジェクトに移動します。
- Add panels ボタンを選択します。
- CHARTS ドロップダウンを展開し、ドロップダウンから Parallel coordinates を選択します。
パラメーターマネージャーを使用して、表示および非表示のパラメーターを手動で設定できます。
ハイパーパラメーター重要度パネルの解釈
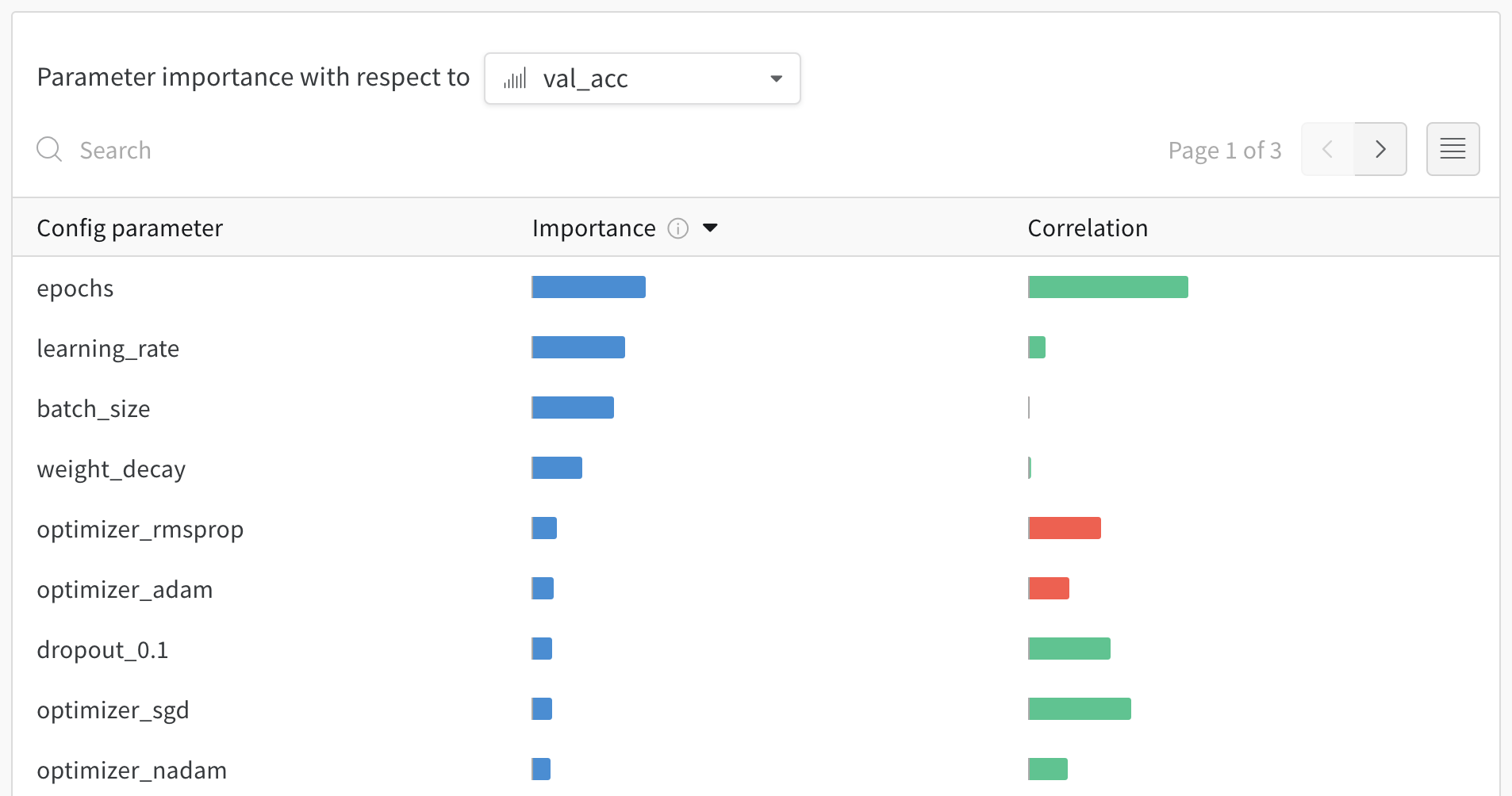
このパネルは、トレーニングスクリプト内で wandb.config オブジェクトに渡されたすべてのパラメーターを表示します。次に、これらのconfigパラメーターの特徴重要度と、それが選択されたモデルメトリクス(この場合は val_loss)との相関を示します。
重要度
重要度列は、選択したメトリクスを予測する際に、各ハイパーパラメーターがどの程度役立ったかを示します。多数のハイパーパラメーターを調整し始めて、それらの中からさらなる探索の価値があるものを特定するためにこのプロットを使用するシナリオを想像してみてください。その後の Sweeps は、最も重要なハイパーパラメーターに限定し、より良いモデルをより速く、安価に見つけることができます。
上記の画像では、epochs, learning_rate, batch_size と weight_decay がかなり重要であることがわかります。
相関
相関は、個々のハイパーパラメーターとメトリクスの値との間の線形関係を捉えます。これにより、SGDオプティマイザーなどのハイパーパラメーターの使用と val_loss 間に有意な関係があるかどうかという問題に答えます(この場合、答えは「はい」です)。相関値は-1から1の範囲であり、正の値は正の線形相関を、負の値は負の線形相関を示し、0の値は相関がないことを示します。一般的に、どちらの方向でも0.7を超える値は強い相関を示します。
このグラフを使用して、メトリクスと高い相関のある値(この場合は確率的勾配降下法やadamを選択し、rmspropやnadamよりも優先することがあります)をさらに調査したり、より多くのエポックでトレーニングしたりすることができます。
- 相関は関連の証拠を示しますが、必ずしも因果関係を示すわけではありません。
- 相関は外れ値に敏感であり、特に試されたハイパーパラメーターのサンプルサイズが小さい場合は、強い関係を中程度のものに変える可能性があります。
- 最後に、相関はハイパーパラメーターとメトリクス間の線形関係のみを捉えます。強い多項式関係がある場合、相関ではそれを捉えられません。
重要度と相関の違いは、重要度がハイパーパラメーター間の相互作用を考慮に入れる一方で、相関は個々のハイパーパラメーターがメトリクスに与える影響のみを測定するという事実から生じます。第二に、相関は線形関係のみを捉えるのに対し、重要度はより複雑な関係を捉えることができます。
見てわかるように、重要度と相関はどちらもハイパーパラメーターがモデルのパフォーマンスにどのように影響するかを理解するための強力なツールです。
1.7 - run メトリクスを比較する
Run Comparer を使用して、異なる run 間でメトリクスがどのように異なるかを確認します。
- ページの右上にある Add panels ボタンを選択します。
- 表示される左側のパネルから Evaluation ドロップダウンを展開します。
- Run comparer を選択します。
diff only オプションを切り替えて、 run 間で値が同じ行を非表示にします。
1.8 - クエリパネル
weave-plot を追加してください。クエリパネルを使用してデータをクエリし、インタラクティブに視覚化します。
クエリパネルを作成する
ワークスペースまたはレポート内にクエリを追加します。
- プロジェクトのワークスペースに移動します。
- 右上のコーナーにある
Add panelをクリックします。 - ドロップダウンから
Query panelを選択します。
/Query panel と入力して選択します。
または、一連の Runs とクエリを関連付けることができます。
- レポート内で、
/Panel gridと入力して選択します。 Add panelボタンをクリックします。- ドロップダウンから
Query panelを選択します。
クエリコンポーネント
式
クエリ式を使用して、W&Bに保存されたデータ、例えば Runs、Artifacts、Models、Tables などをクエリします。
例: テーブルをクエリする
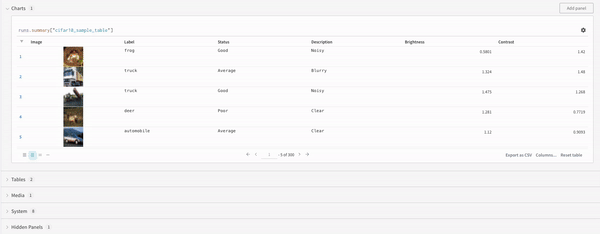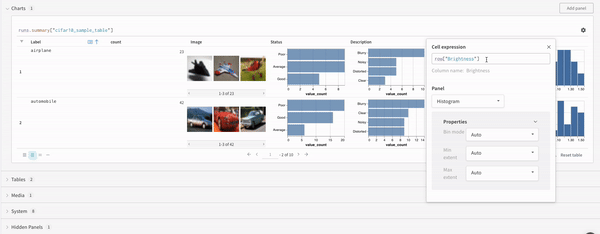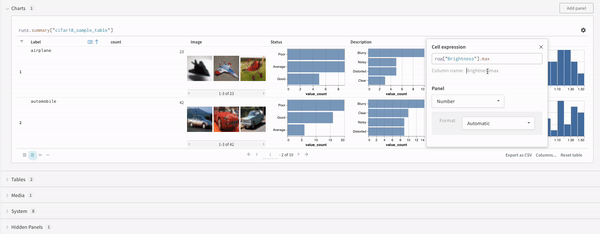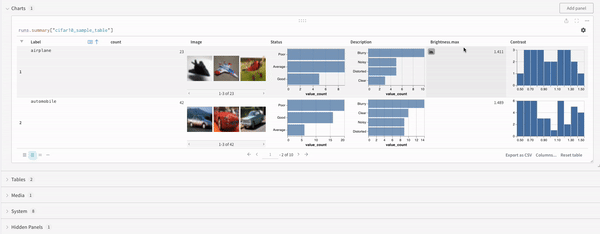
W&B Tableをクエリしたいとします。トレーニングコード内で "cifar10_sample_table" という名前のテーブルをログします:
import wandb
wandb.log({"cifar10_sample_table":<MY_TABLE>})
クエリパネル内でテーブルをクエリするには次のようにします:
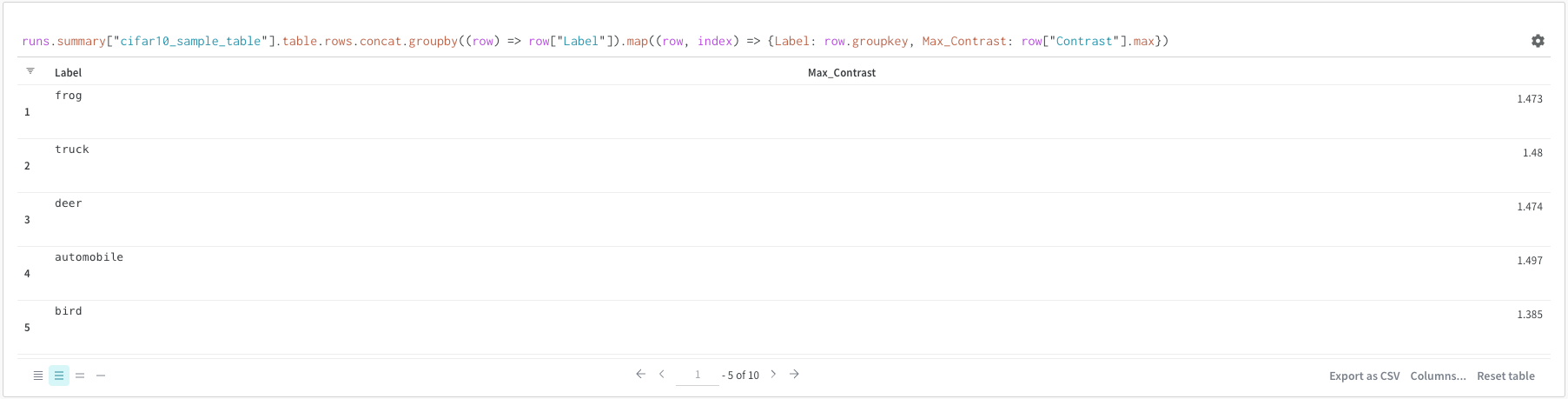
runs.summary["cifar10_sample_table"]

これを分解すると:
runsは、ワークスペースに Query Panel があるときに自動的に Query Panel Expressions に注入される変数です。その値は、その特定のワークスペースに表示される Runs のリストです。Run内の利用可能な異なる属性についてはこちらをお読みください。summaryは、Run の Summary オブジェクトを返す操作です。Opsは マップされる ため、この操作はリスト内の各 Run に適用され、その結果として Summary オブジェクトのリストが生成されます。["cifar10_sample_table"]は Pick 操作(角括弧で示され)、predictionsというパラメータを持ちます。Summary オブジェクトは辞書またはマップのように動作するため、この操作は各 Summary オブジェクトからpredictionsフィールドを選択します。
インタラクティブに独自のクエリの書き方を学ぶには、こちらのレポートを参照してください。
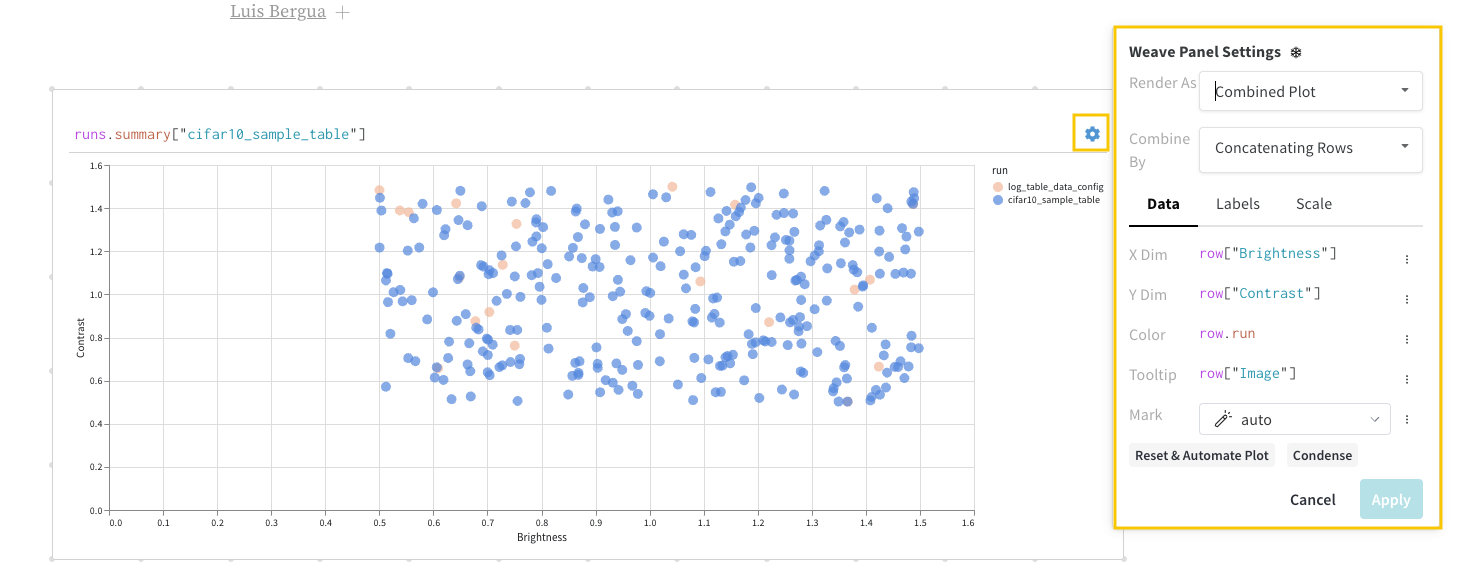
設定
パネルの左上コーナーにあるギアアイコンを選択してクエリ設定を展開します。これにより、ユーザーはパネルのタイプと結果パネルのパラメータを設定できます。
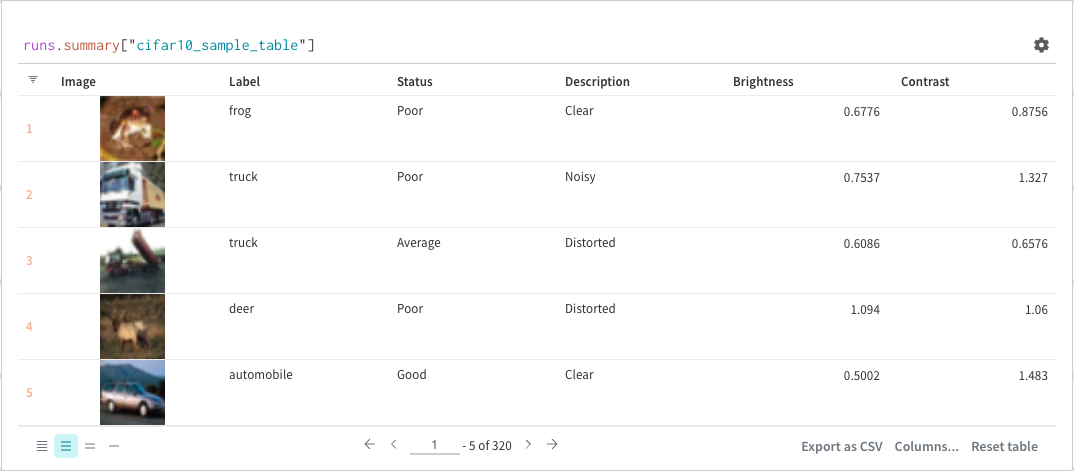
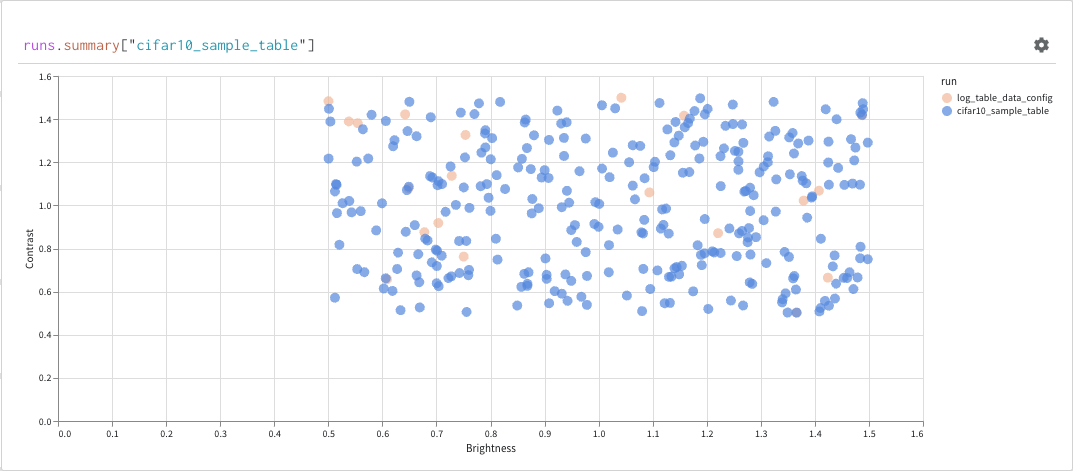
結果パネル
最後に、クエリ結果パネルは、選択したクエリパネル、設定によって設定された構成に基づいて、データをインタラクティブに表示する形式でクエリ式の結果をレンダリングします。次の画像は、同じデータのテーブルとプロットを示しています。
基本操作
次に、クエリパネル内で行える一般的な操作を示します。
ソート
列オプションからソートします:
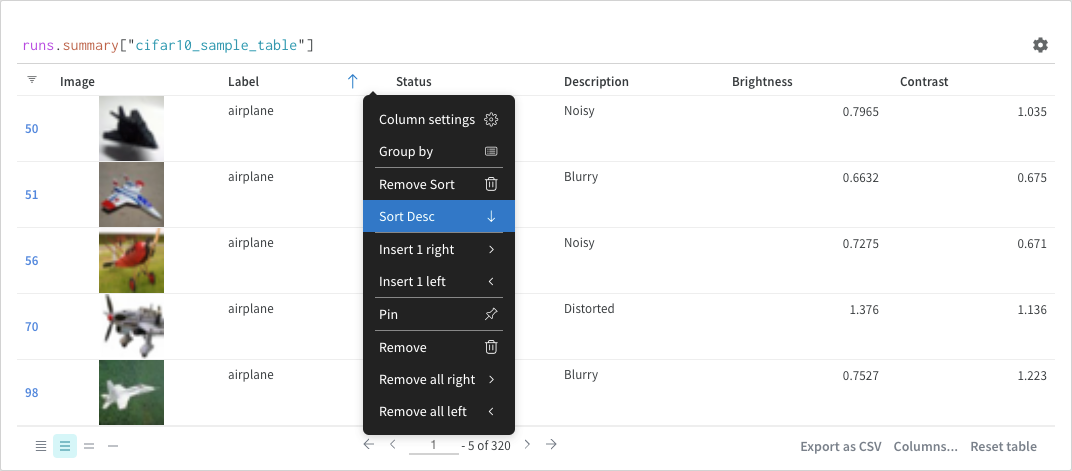
フィルター
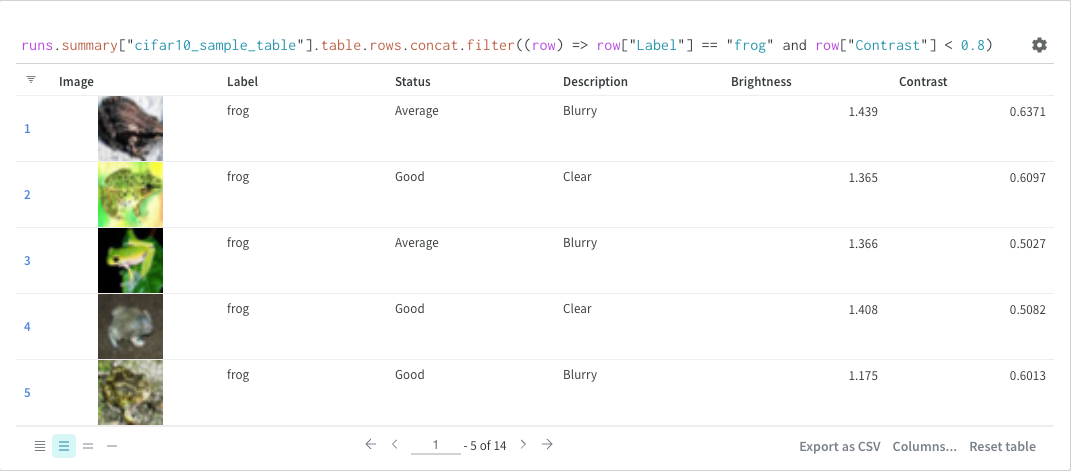
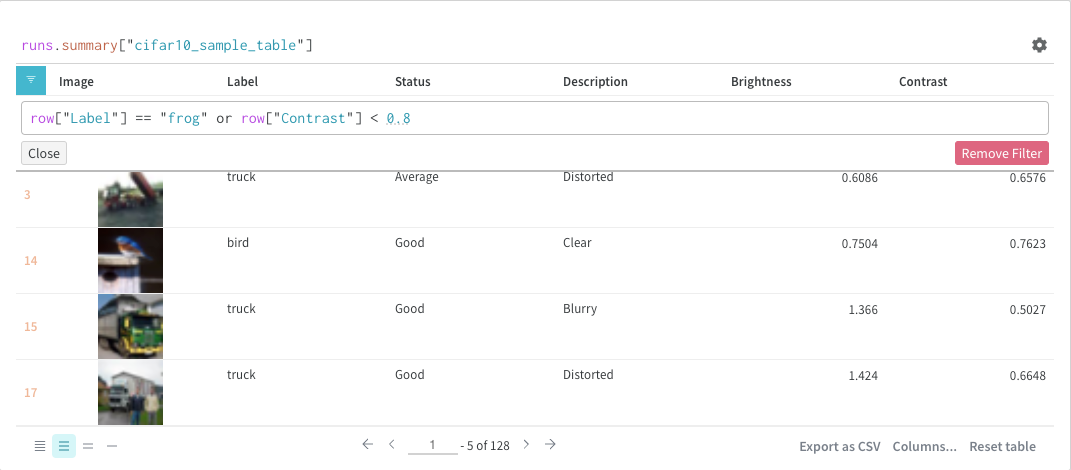
クエリ内で直接、または左上隅のフィルターボタンを使用してフィルターできます(2枚目の画像)。
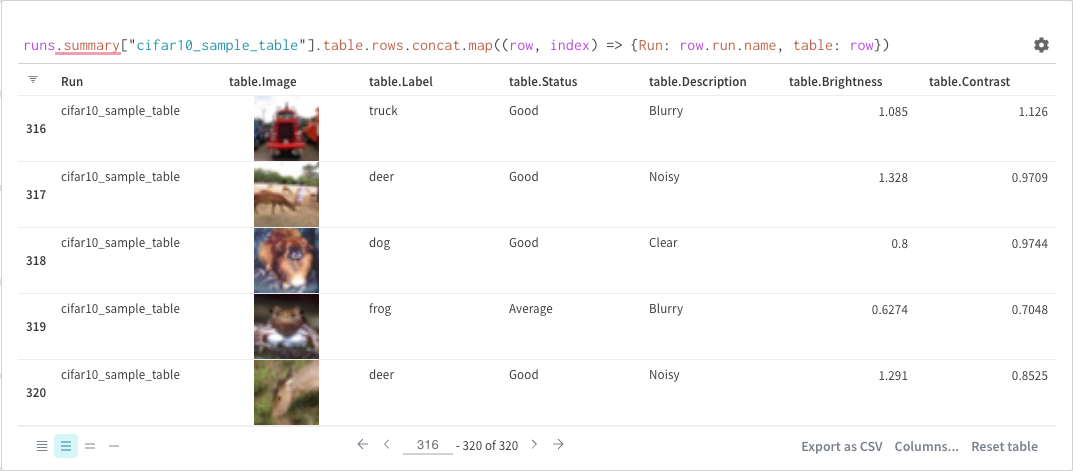
マップ
マップ操作はリストを反復し、データ内の各要素に関数を適用します。これは、パネルクエリを使用して直接行うことも、列オプションから新しい列を挿入することによって行うこともできます。

グループ化
クエリを使用してまたは列オプションからグループ化できます。
連結
連結操作により、2つのテーブルを連結し、パネル設定から連結または結合できます。
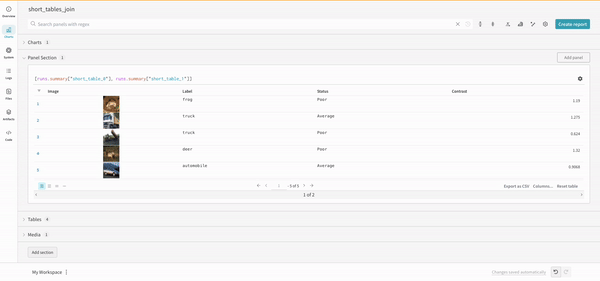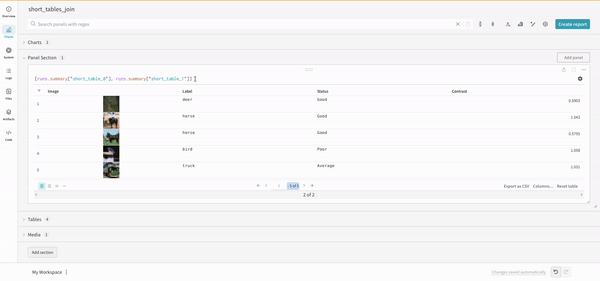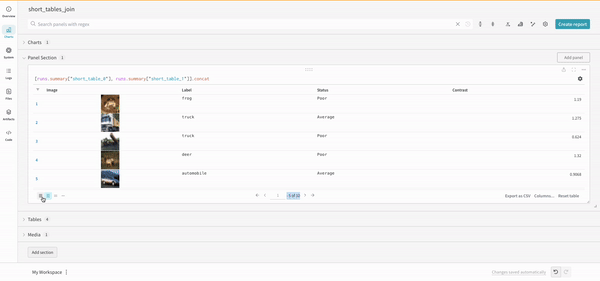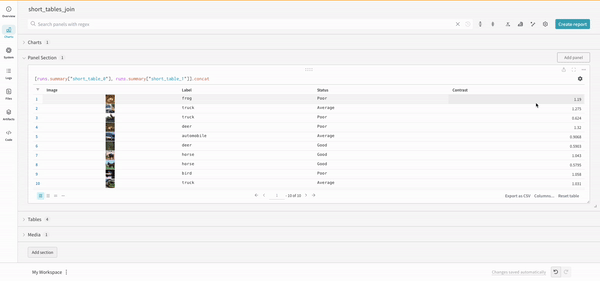
結合
クエリ内でテーブルを直接結合することも可能です。次のクエリ式を考えてみてください:
project("luis_team_test", "weave_example_queries").runs.summary["short_table_0"].table.rows.concat.join(\
project("luis_team_test", "weave_example_queries").runs.summary["short_table_1"].table.rows.concat,\
(row) => row["Label"],(row) => row["Label"], "Table1", "Table2",\
"false", "false")
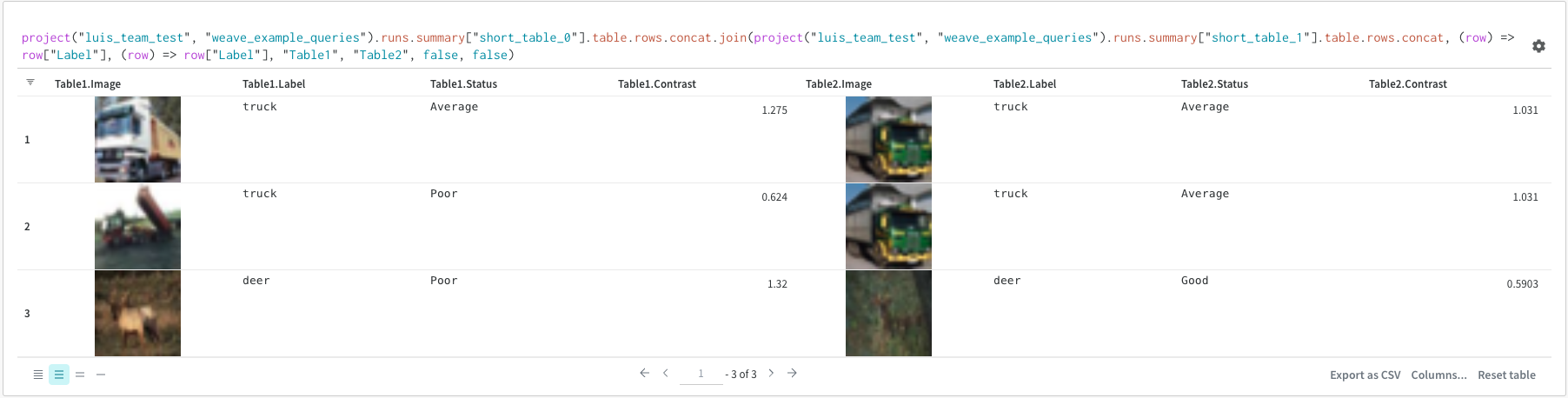
左のテーブルは次のように生成されます:
project("luis_team_test", "weave_example_queries").\
runs.summary["short_table_0"].table.rows.concat.join
右のテーブルは次のように生成されます:
project("luis_team_test", "weave_example_queries").\
runs.summary["short_table_1"].table.rows.concat
ここで:
(row) => row["Label"]は各テーブルのセレクタであり、結合する列を決定します"Table1"と"Table2"は、結合された各テーブルの名前ですtrueとfalseは、左および右の内/外部結合設定です
Runsオブジェクト
クエリパネルを使用して runs オブジェクトにアクセスします。Runオブジェクトは、実験の記録を保存します。詳細については、こちらのレポートのセクションを参照してくださいが、簡単な概要として、runs オブジェクトには以下が含まれます:
summary: Runの結果を要約する情報の辞書です。精度や損失のようなスカラーや、大きなファイルを含むことができます。デフォルトでは、wandb.log()は記録された時系列の最終的な値をsummaryに設定します。直接summaryの内容を設定することもできます。summaryはRunの出力と考えてください。history: モデルがトレーニング中に変化する値を格納するための辞書のリストです。コマンドwandb.log()はこのオブジェクトに追加します。config: Runの設定情報を含む辞書で、トレーニングランのハイパーパラメーターやデータセットアーティファクトを作成するランの前処理方法などが含まれます。これらはRunの「入力」として考えてください。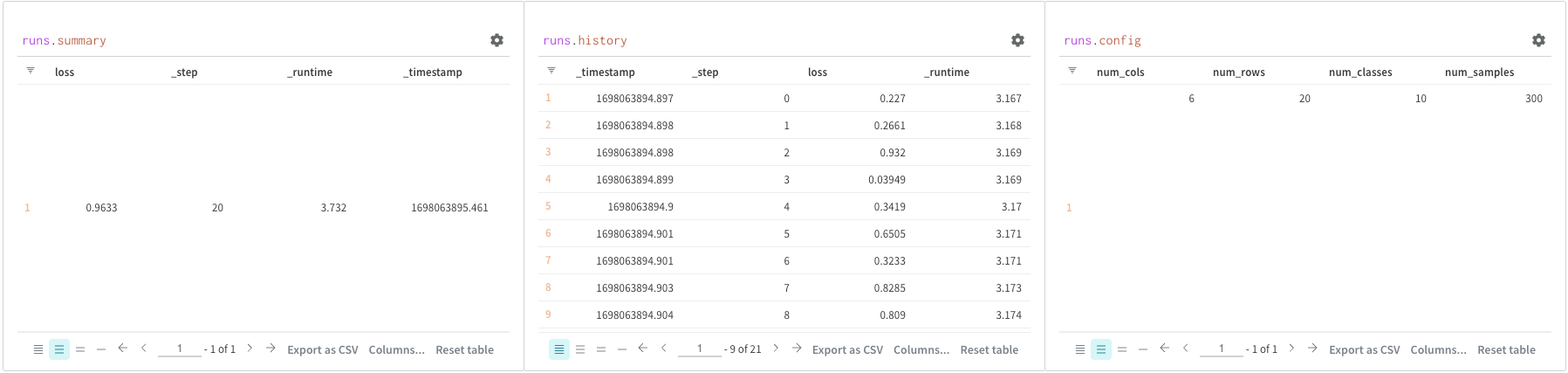
Artifactsにアクセスする
Artifacts は W&B の中核概念です。これは、バージョン管理された名前付きファイルやディレクトリーのコレクションです。Artifacts を使用して、モデルの重み、データセット、およびその他のファイルやディレクトリーを追跡します。Artifacts は W&B に保存され、他の runs でダウンロードまたは使用できます。詳細と例は、こちらのセクションのレポートで確認できます。Artifacts は通常、project オブジェクトからアクセスします:
project.artifactVersion(): プロジェクト内の特定の名前とバージョンのアーティファクトバージョンを返しますproject.artifact(""): プロジェクト内の特定の名前のアーティファクトを返します。その後、.versionsを使用してこのアーティファクトのすべてのバージョンのリストを取得できますproject.artifactType(): プロジェクト内の特定の名前のartifactTypeを返します。その後、.artifactsを使用して、このタイプを持つすべてのアーティファクトのリストを取得できますproject.artifactTypes: プロジェクト内のすべてのアーティファクトタイプのリストを返します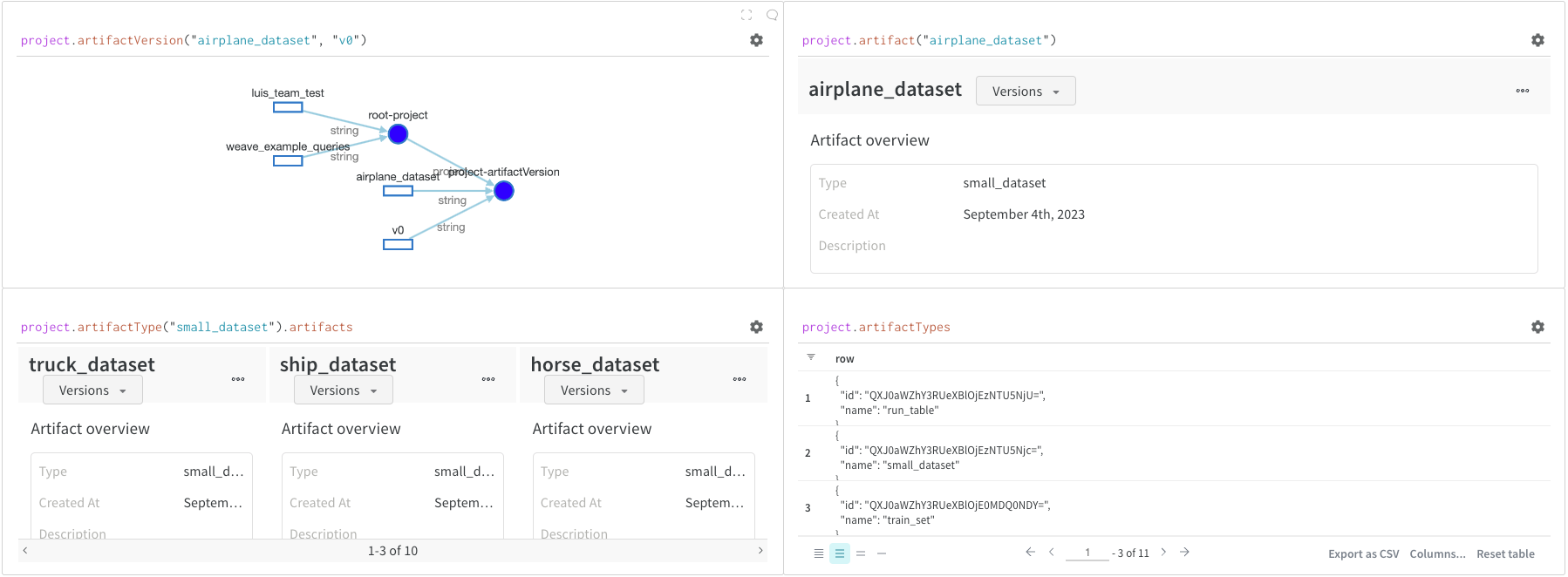
1.8.1 - オブジェクトを埋め込む
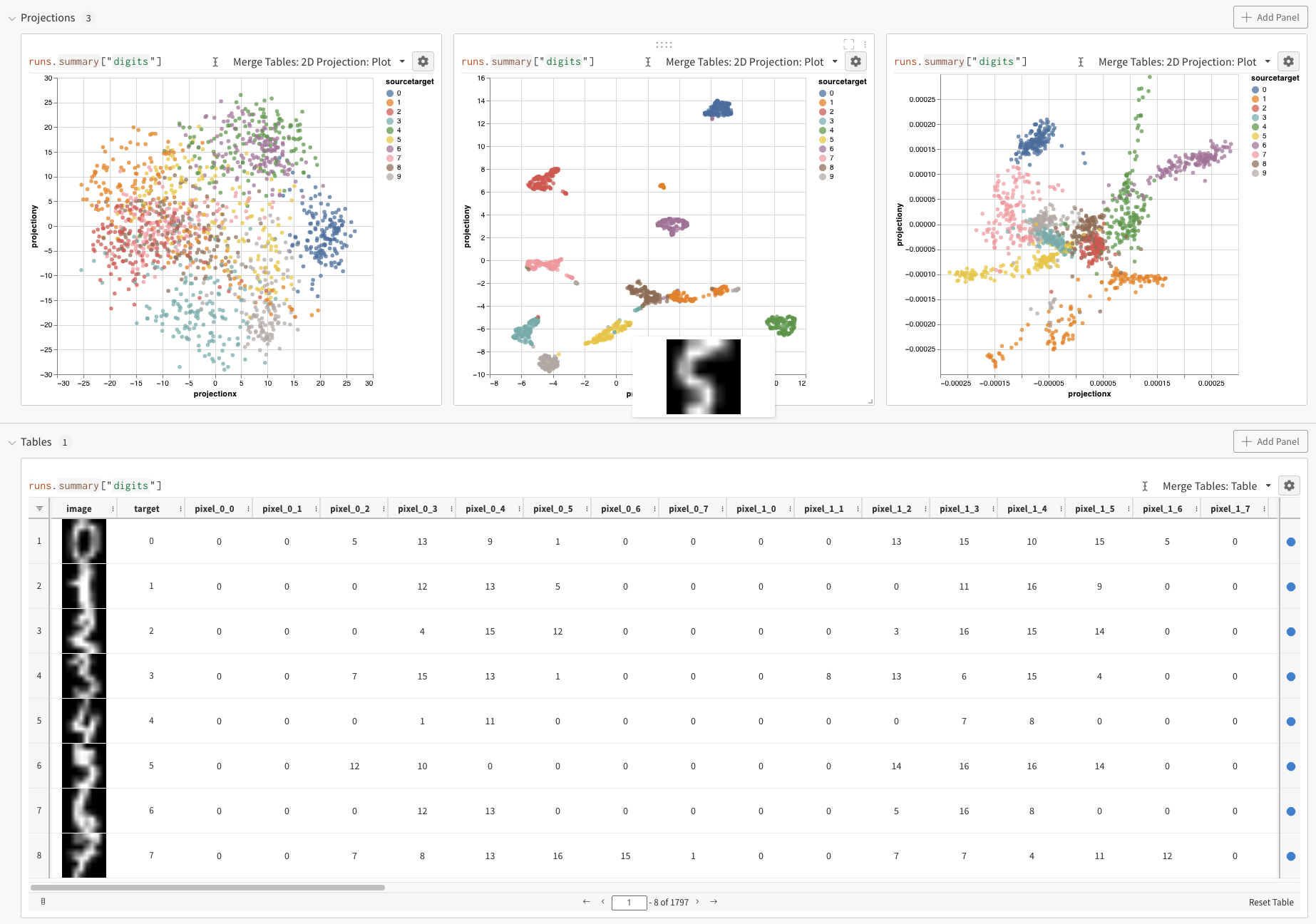
Embeddings はオブジェクト(人物、画像、投稿、単語など)を数字のリストで表現するために使用されます。これを ベクトル と呼ぶこともあります。機械学習やデータサイエンスのユースケースでは、Embeddings は様々な手法を用いて生成でき、幅広いアプリケーションで利用されます。このページでは、読者が Embeddings に精通しており、W&B 内でそれらを視覚的に分析することに関心があることを前提としています。
Embedding の例
ハローワールド
W&B を使用すると、wandb.Table クラスを使用して Embeddings をログできます。以下は、5 次元からなる 3 つの Embeddings の例です。
import wandb
wandb.init(project="embedding_tutorial")
embeddings = [
# D1 D2 D3 D4 D5
[0.2, 0.4, 0.1, 0.7, 0.5], # embedding 1
[0.3, 0.1, 0.9, 0.2, 0.7], # embedding 2
[0.4, 0.5, 0.2, 0.2, 0.1], # embedding 3
]
wandb.log(
{"embeddings": wandb.Table(columns=["D1", "D2", "D3", "D4", "D5"], data=embeddings)}
)
wandb.finish()
上記のコードを実行すると、W&B ダッシュボードにデータを含む新しいテーブルが作成されます。右上のパネルセレクタから 2D Projection を選択して Embeddings を 2 次元でプロットすることができます。デフォルトで賢明な設定が自動的に選択されますが、設定メニューから簡単に上書きできます。この例では、利用可能な 5 つの数値次元をすべて自動的に使用しています。
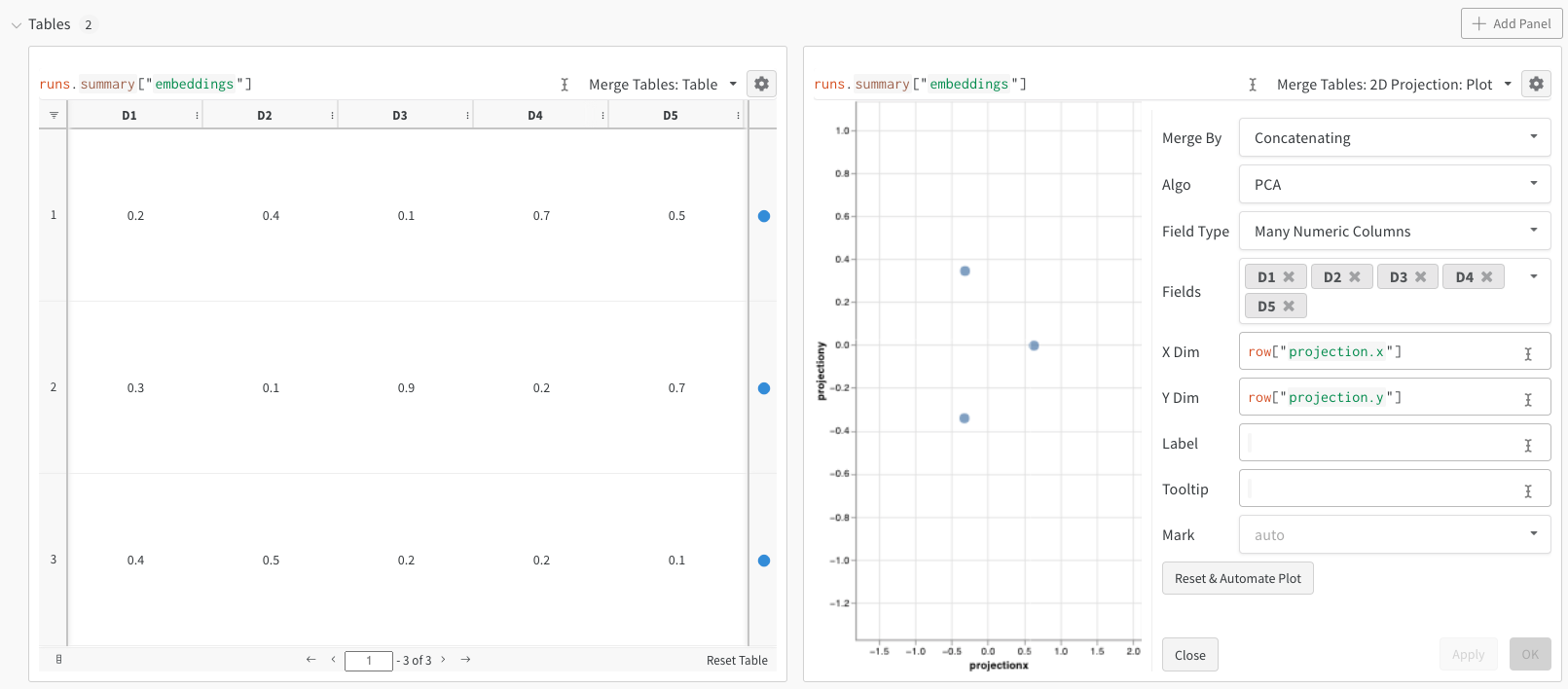
数字のMNIST
上記の例では Embeddings の基本的なログ方法を示しましたが、通常はもっと多くの次元とサンプルを扱います。UCI の手書き数字データセット UCI ML hand-written digits datasetを使って、SciKit-Learn を通じて提供される MNIST 数字データセットを考えてみましょう。このデータセットには 64 次元を持つ 1797 のレコードが含まれています。この問題は10クラスの分類ユースケースです。また、可視化のために入力データを画像に変換することもできます。
import wandb
from sklearn.datasets import load_digits
wandb.init(project="embedding_tutorial")
# データセットをロードする
ds = load_digits(as_frame=True)
df = ds.data
# "target" カラムを作成する
df["target"] = ds.target.astype(str)
cols = df.columns.tolist()
df = df[cols[-1:] + cols[:-1]]
# "image" カラムを作成する
df["image"] = df.apply(
lambda row: wandb.Image(row[1:].values.reshape(8, 8) / 16.0), axis=1
)
cols = df.columns.tolist()
df = df[cols[-1:] + cols[:-1]]
wandb.log({"digits": df})
wandb.finish()
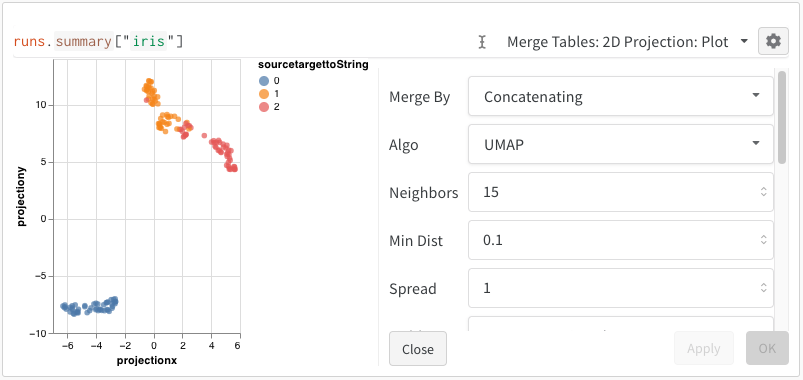
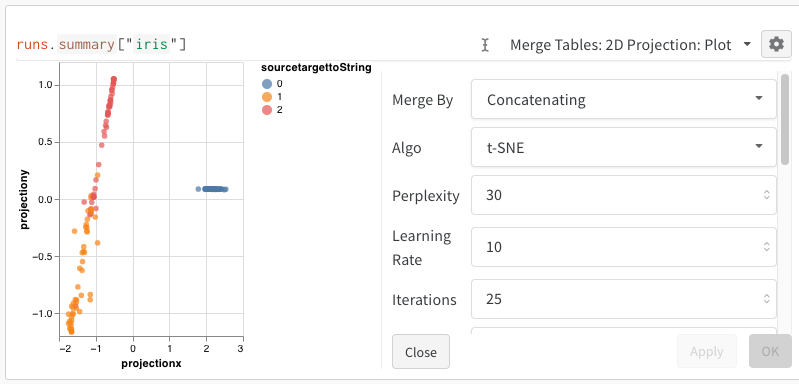
上記のコードを実行した後、再び UI にテーブルが表示されます。 2D Projection を選択することで、Embedding の定義、色付け、アルゴリズム(PCA, UMAP, t-SNE)、アルゴリズムのパラメータ、さらにはオーバーレイ(この場合、点の上にマウスを置くと画像が表示されます)の設定を行うことができます。この特定のケースでは、すべて「スマートデフォルト」が設定されており、2D Projection をクリックするだけで非常に類似したものが見えるはずです。(この例を試してみてください)。
ログオプション
Embeddings はさまざまなフォーマットでログすることができます:
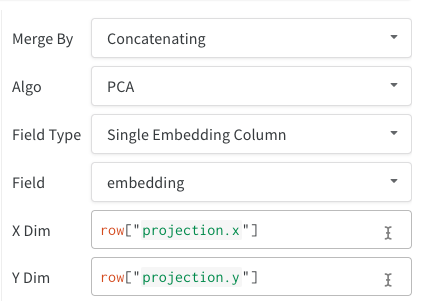
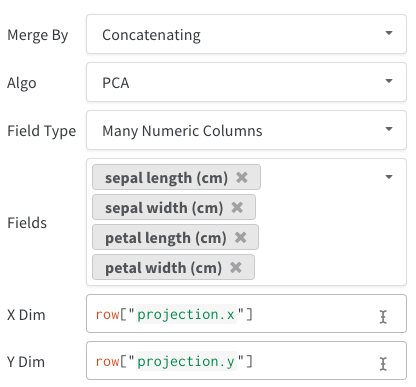
- 単一の埋め込みカラム: データがすでに「行列」形式になっていることが多いです。この場合、カラムのデータ型は
list[int],list[float], またはnp.ndarrayにすることができます。 - 複数の数値カラム: 上記の2つの例では、各次元に対してカラムを作成するこの方法を使用します。現在、セルには Python の
intまたはfloatが受け入れられます。
さらに、他のすべてのテーブルと同様に、テーブルを構築する方法について多くのオプションがあります:
- データフレーム から直接
wandb.Table(dataframe=df)を使用して - データのリスト から直接
wandb.Table(data=[...], columns=[...])を使用して - 行単位で段階的に テーブルを構築する(コード内にループがある場合に最適)。
table.add_data(...)を使ってテーブルに行を追加します。 - テーブルに 埋め込みカラム を追加する(Embedding の形式で予測のリストがある場合に最適):
table.add_col("col_name", ...) - 計算済みカラム を追加する(関数やモデルをテーブル全体に適用したい場合に最適):
table.add_computed_columns(lambda row, ndx: {"embedding": model.predict(row)})
プロットオプション
2D Projection を選択した後、ギアアイコンをクリックしてレンダリング設定を編集できます。上記のカラムの選択に加えて、興味のあるアルゴリズム(および必要なパラメータ)を選ぶことができます。以下に、UMAP と t-SNE の各パラメータが表示されています。
2 - カスタムチャート
W&Bプロジェクトでカスタムチャートを作成しましょう。任意のデータテーブルをログし、自由に可視化できます。フォント、色、ツールチップの詳細をVegaの力でコントロールしましょう。
- コード: 例のColabノートブックを試してみてください。
- ビデオ: ウォークスルービデオを視聴します。
- 例: KerasとSklearnのデモノートブック
仕組み
- データをログする: スクリプトから、configとサマリーデータをログします。
- チャートをカスタマイズする: GraphQLクエリを使ってログされたデータを呼び出します。Vega、強力な可視化文法でクエリの結果を可視化します。
- チャートをログする: あなた自身のプリセットをスクリプトから
wandb.plot_table()で呼び出します。
期待したデータが表示されない場合、選択した Runs に求めている列がログされていない可能性があります。チャートを保存し、Runsテーブルに戻って、選択した Runs を目のアイコンで確認してください。
スクリプトからチャートをログする
組み込みプリセット
W&Bにはスクリプトから直接ログできるいくつかの組み込みチャートプリセットがあります。これらには、ラインプロット、スキャッタープロット、バーチャート、ヒストグラム、PR曲線、ROC曲線が含まれます。
wandb.plot.line()
カスタムラインプロットをログします — 任意の軸xとy上の接続され順序付けされた点(x,y)のリストです。
data = [[x, y] for (x, y) in zip(x_values, y_values)]
table = wandb.Table(data=data, columns=["x", "y"])
wandb.log(
{
"my_custom_plot_id": wandb.plot.line(
table, "x", "y", title="Custom Y vs X Line Plot"
)
}
)
ラインプロットは任意の2次元上に曲線をログします。もし2つのlistの値を互いにプロットする場合、listの値の数が完全に一致している必要があります(例えば、各点はxとyを持たなければなりません)。
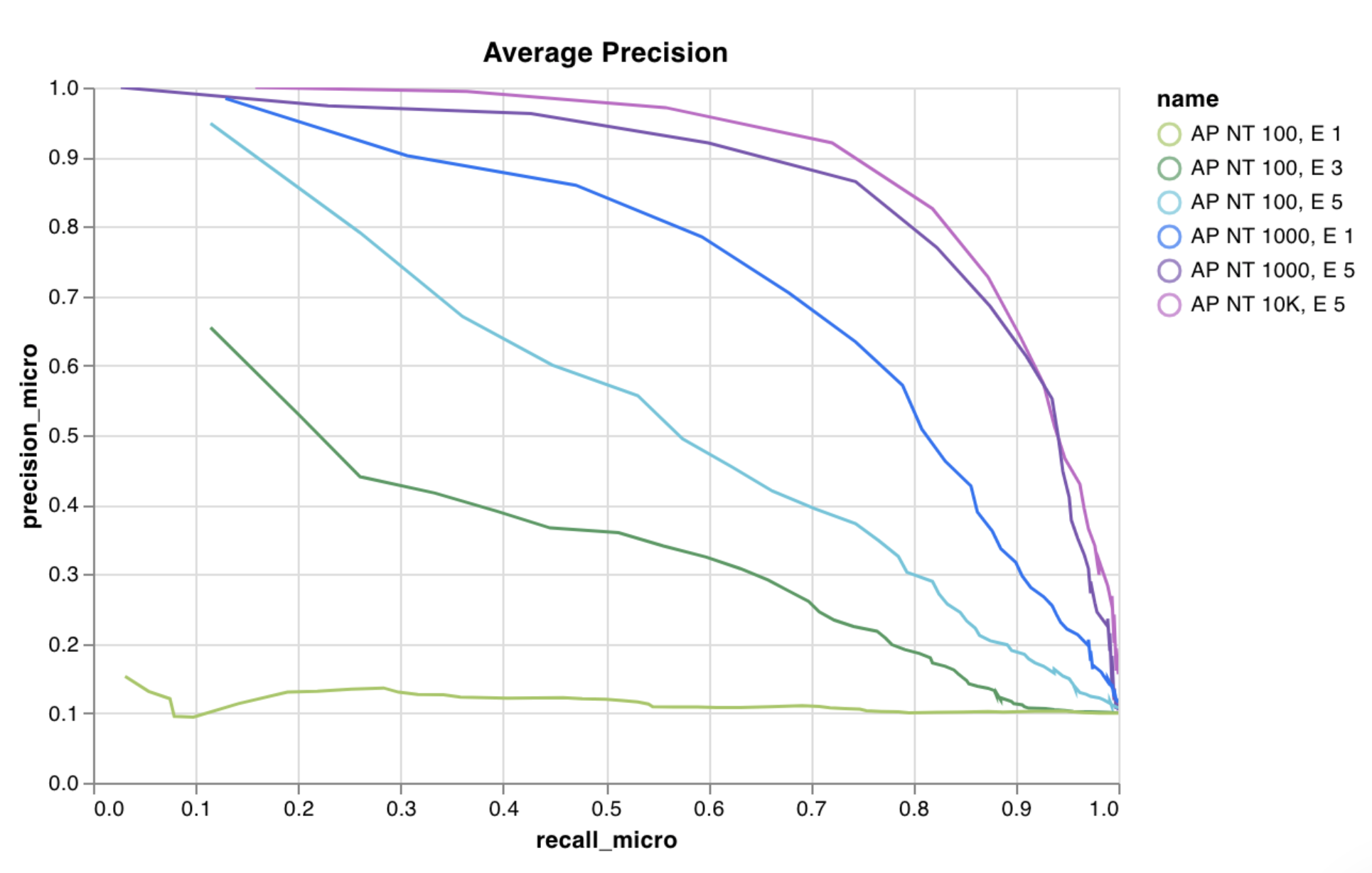
例のレポートを確認するか、例のGoogle Colabノートブックを試すことができます。
wandb.plot.scatter()
カスタムスキャッタープロットをログします — 任意の軸xとy上の点(x, y)のリストです。
data = [[x, y] for (x, y) in zip(class_x_prediction_scores, class_y_prediction_scores)]
table = wandb.Table(data=data, columns=["class_x", "class_y"])
wandb.log({"my_custom_id": wandb.plot.scatter(table, "class_x", "class_y")})
任意の2次元上にスキャッターポイントをログするためにこれを使うことができます。もし2つのlistの値を互いにプロットする場合、listの値の数が完全に一致している必要があります(例えば、各点はxとyを持たなければなりません)。
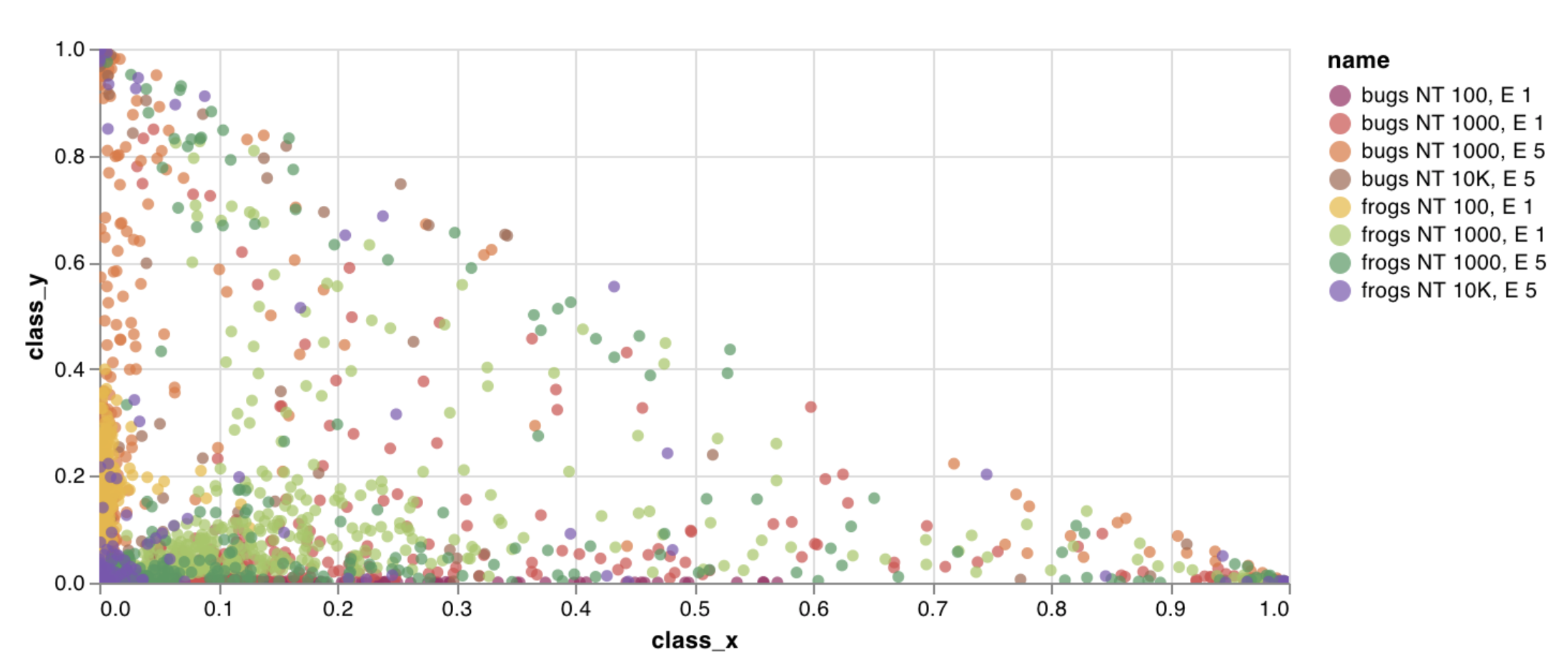
例のレポートを確認するか、例のGoogle Colabノートブックを試すことができます。
wandb.plot.bar()
カスタムバーチャートをログします — ラベル付き値のリストをバーとして表示する — 数行でネイティブに:
data = [[label, val] for (label, val) in zip(labels, values)]
table = wandb.Table(data=data, columns=["label", "value"])
wandb.log(
{
"my_bar_chart_id": wandb.plot.bar(
table, "label", "value", title="Custom Bar Chart"
)
}
)
任意のバーチャートをログするためにこれを使用することができます。list内のラベルと値の数は完全に一致している必要があります(例えば、各データポイントが両方を持つ必要があります)。
例のレポートを確認するか、例のGoogle Colabノートブックを試すことができます。
wandb.plot.histogram()
カスタムヒストグラムをログします — いくつかの行で値をカウントまたは出現頻度によってビンにソートします。予測信頼度スコア(scores)のリストがあるとしましょう。それらの分布を可視化したいとします。
data = [[s] for s in scores]
table = wandb.Table(data=data, columns=["scores"])
wandb.log({"my_histogram": wandb.plot.histogram(table, "scores", title=None)})
任意のヒストグラムをログするためにこれを使用することができます。注意として、 data は list of lists であり、2次元配列の行と列をサポートすることを意図しています。
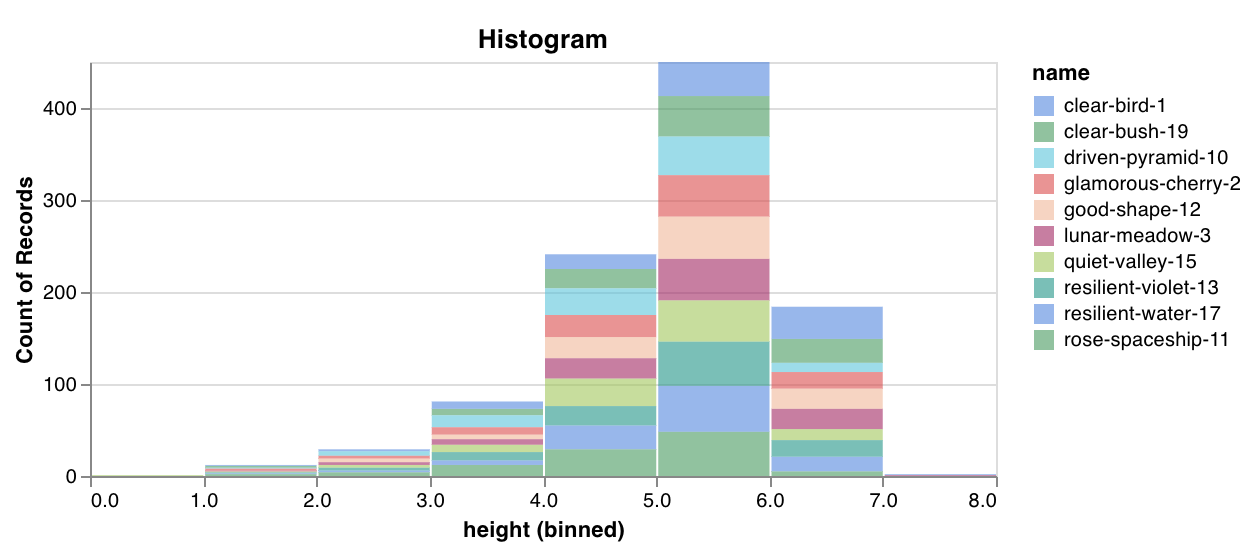
例のレポートを確認するか、例のGoogle Colabノートブックを試すことができます。
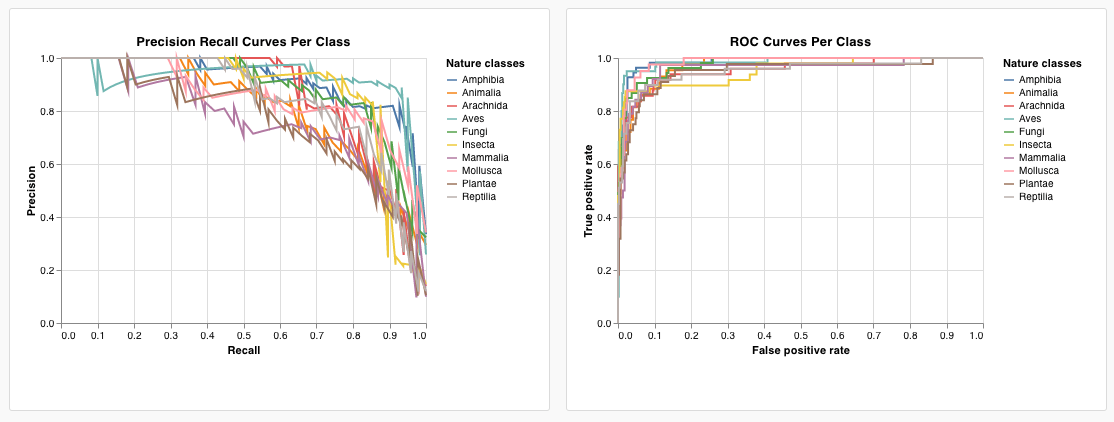
wandb.plot.pr_curve()
Precision-Recall curve を1行で作成します。
plot = wandb.plot.pr_curve(ground_truth, predictions, labels=None, classes_to_plot=None)
wandb.log({"pr": plot})
コードが次にアクセス可能なときにこれをログできます:
- モデルの予測スコア (
predictions) の一群の例 - それらの例の対応する正解ラベル (
ground_truth) - (オプション)ラベルまたはクラス名のリスト (
labels=["cat", "dog", "bird"...]ラベルインデックス0はcat、1番目はdog、2番目はbird…) - (オプション)プロットに可視化するラベルのサブセット(リスト形式のまま)
例のレポートを確認するか、例のGoogle Colabノートブックを試すことができます。
wandb.plot.roc_curve()
ROC curve を1行で作成します。
plot = wandb.plot.roc_curve(
ground_truth, predictions, labels=None, classes_to_plot=None
)
wandb.log({"roc": plot})
コードが次にアクセス可能なときにこれをログできます:
- モデルの予測スコア (
predictions) の一群の例 - それらの例の対応する正解ラベル (
ground_truth) - (オプション)ラベルまたはクラス名のリスト (
labels=["cat", "dog", "bird"...]ラベルインデックス0はcat、1番目はdog、2番目はbird…) - (オプション)このプロットに可視化するラベルのサブセット(リスト形式のまま)
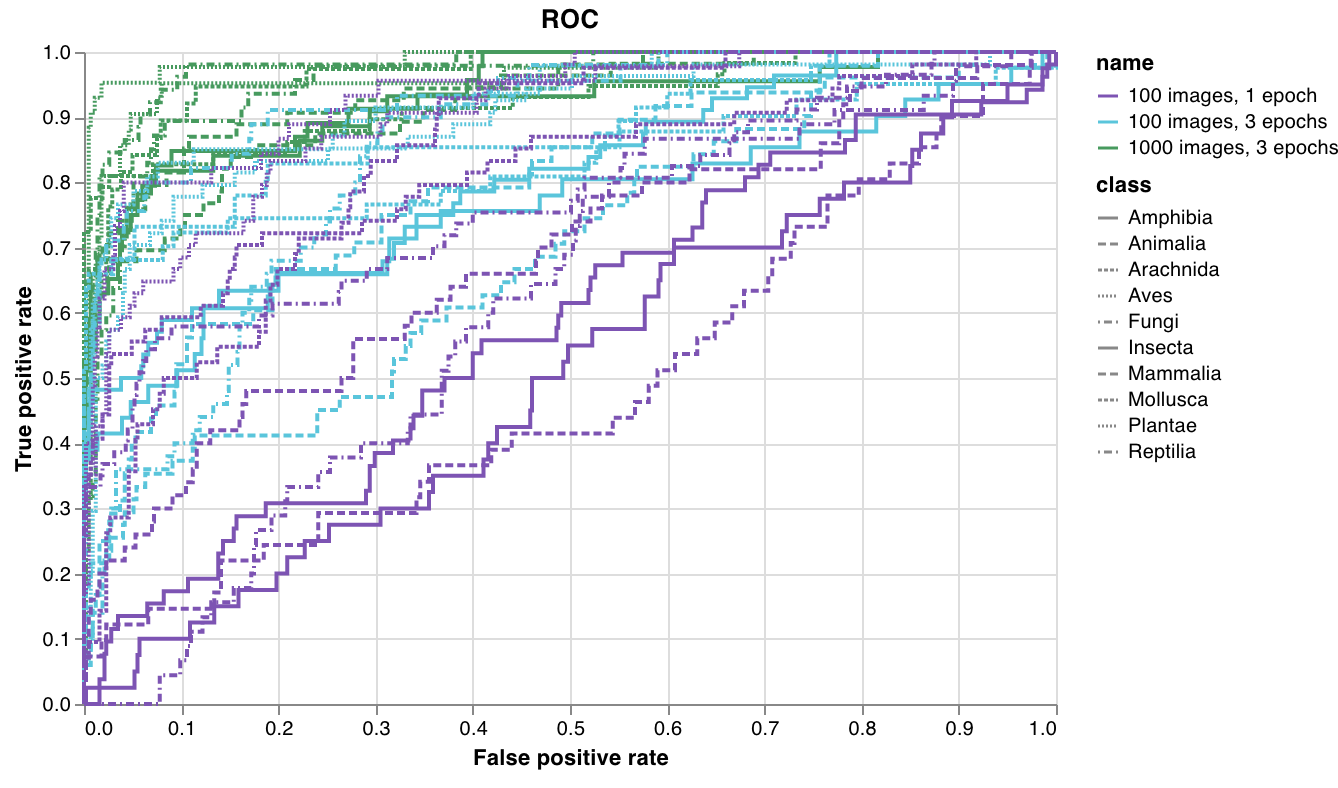
例のレポートを確認するか、例のGoogle Colabノートブックを試すことができます。
カスタムプリセット
組み込みプリセットを調整するか新しいプリセットを作成し、チャートを保存します。チャートIDを使ってそのカスタムプリセットに直接スクリプトからデータをログします。例のGoogle Colabノートブックを試す。
# プロットする列を持つテーブルを作成します
table = wandb.Table(data=data, columns=["step", "height"])
# テーブルの列からチャートのフィールドへのマッピング
fields = {"x": "step", "value": "height"}
# 新しいカスタムチャートプリセットを埋めるためにテーブルを使用
# 保存した自身のチャートプリセットを使用するには、vega_spec_nameを変更します
my_custom_chart = wandb.plot_table(
vega_spec_name="carey/new_chart",
data_table=table,
fields=fields,
)
データをログする
スクリプトから次のデータタイプをログし、カスタムチャートで使用できます。
- Config: 実験の初期設定(独立変数)。これは実験の開始時に
wandb.configにキーとしてログされた名前付きフィールドを含みます。例えば:wandb.config.learning_rate = 0.0001 - Summary: トレーニング中にログされた単一の値(結果や従属変数)。例えば、
wandb.log({"val_acc" : 0.8})。トレーニング中にwandb.log()を使用してキーに複数回書き込んだ場合、サマリーはそのキーの最終的な値に設定されます。 - History: ログされたスカラーの時系列全体は、
historyフィールドを通じてクエリに利用可能です。 - summaryTable: 複数の値のリストをログする必要がある場合、
wandb.Table()を使用してそのデータを保存し、それをカスタムパネルでクエリします。 - historyTable: 履歴データを確認したい場合、カスタムチャートパネルで
historyTableをクエリします。wandb.Table()の呼び出しごとまたはカスタムチャートのログごとに、そのステップにおける履歴に新しいテーブルが作成されます。
カスタムテーブルをログする方法
wandb.Table() を使ってデータを2次元配列としてログします。一般的にこのテーブルの各行は一つのデータポイントを表し、各列はプロットしたい各データポイントの関連フィールド/次元を示しています。カスタムパネルを設定する際、 wandb.log() に渡された名前付きキー(以下の custom_data_table)を通じてテーブル全体にアクセスでき、個別のフィールドには列の名前(x, y, z)を通じてアクセスできます。実験のさまざまなタイムステップでテーブルをログすることができます。各テーブルの最大サイズは10,000行です。例のGoogle Colabを試す。
# データのカスタムテーブルをログする
my_custom_data = [[x1, y1, z1], [x2, y2, z2]]
wandb.log(
{"custom_data_table": wandb.Table(data=my_custom_data, columns=["x", "y", "z"])}
)
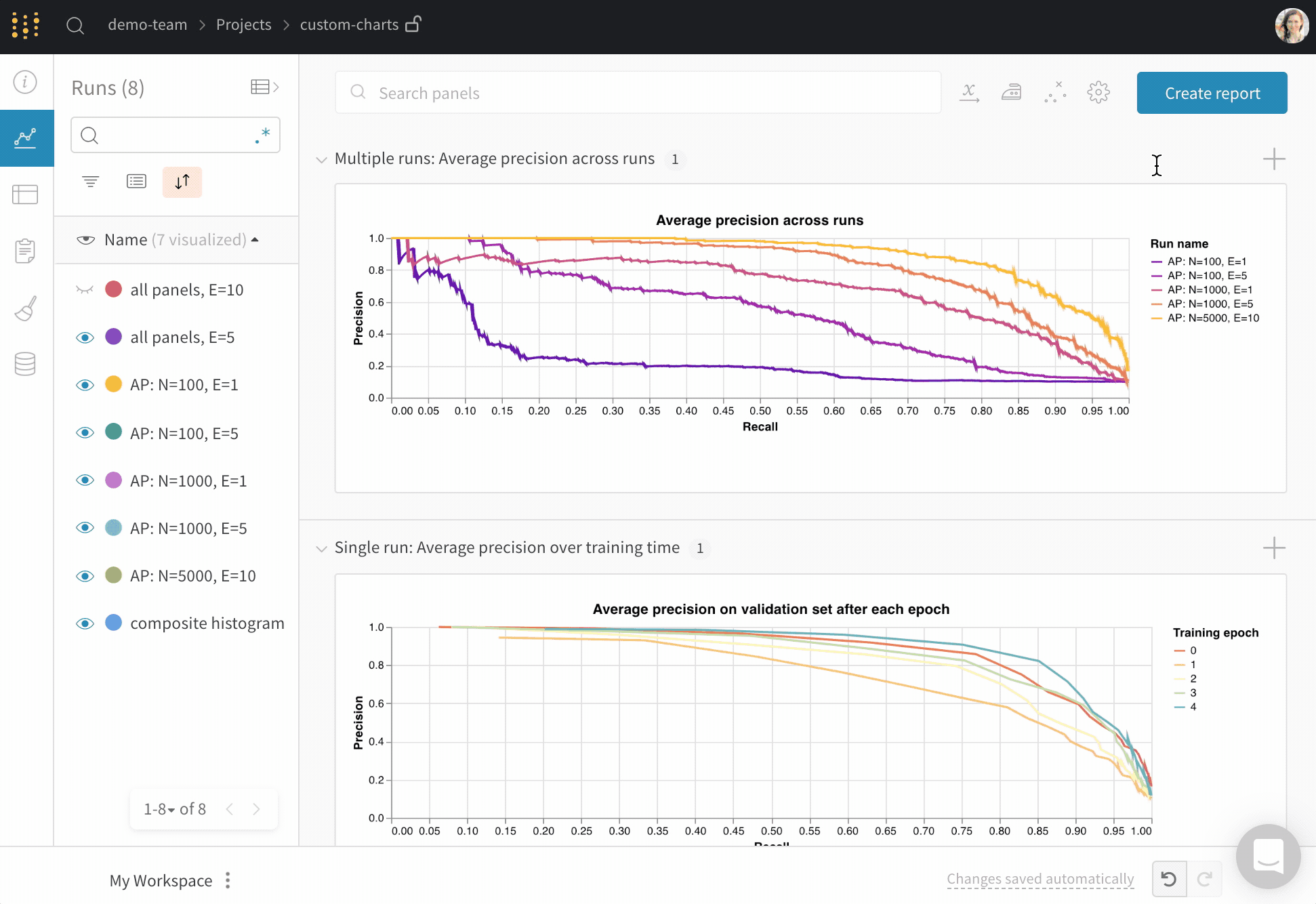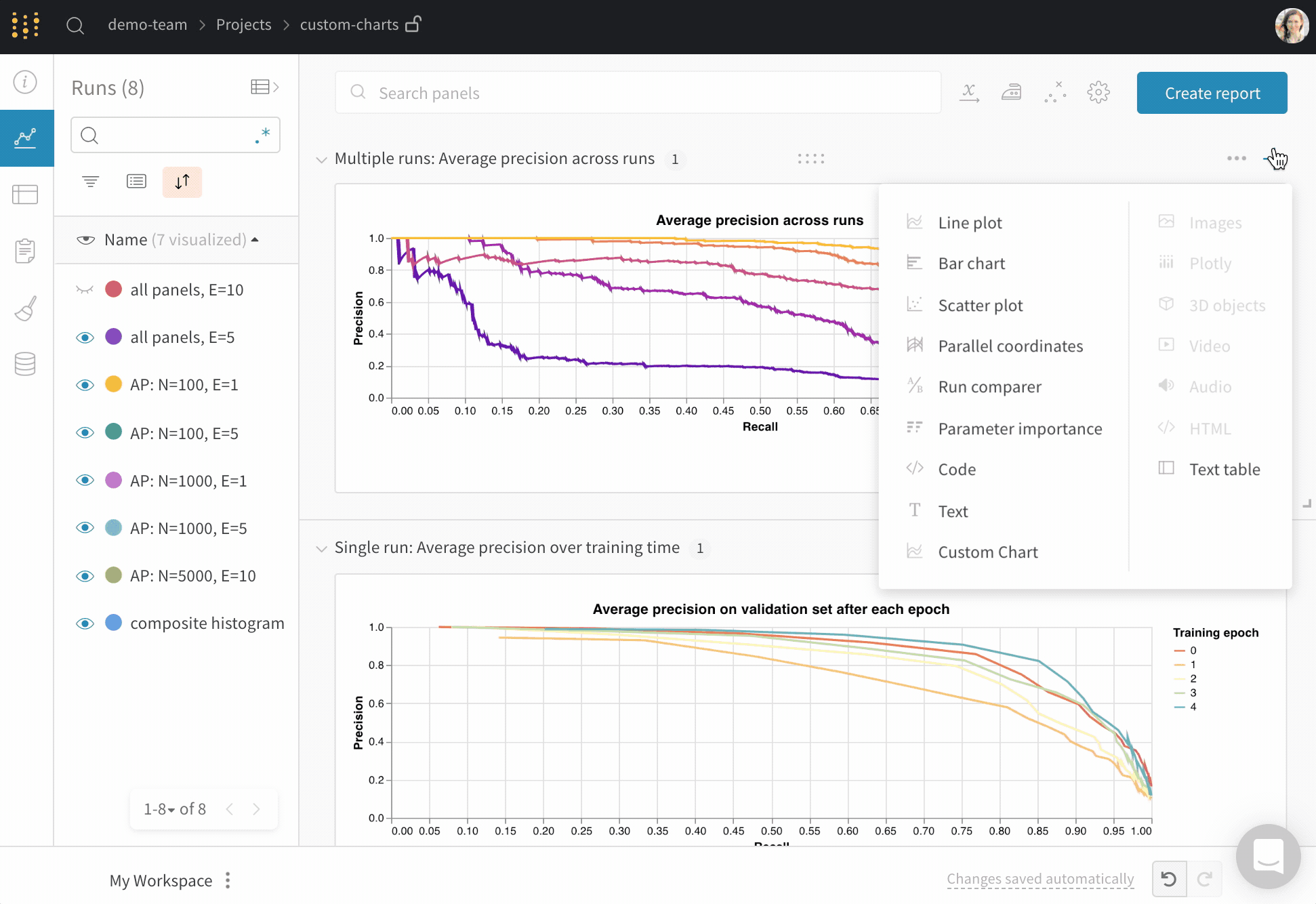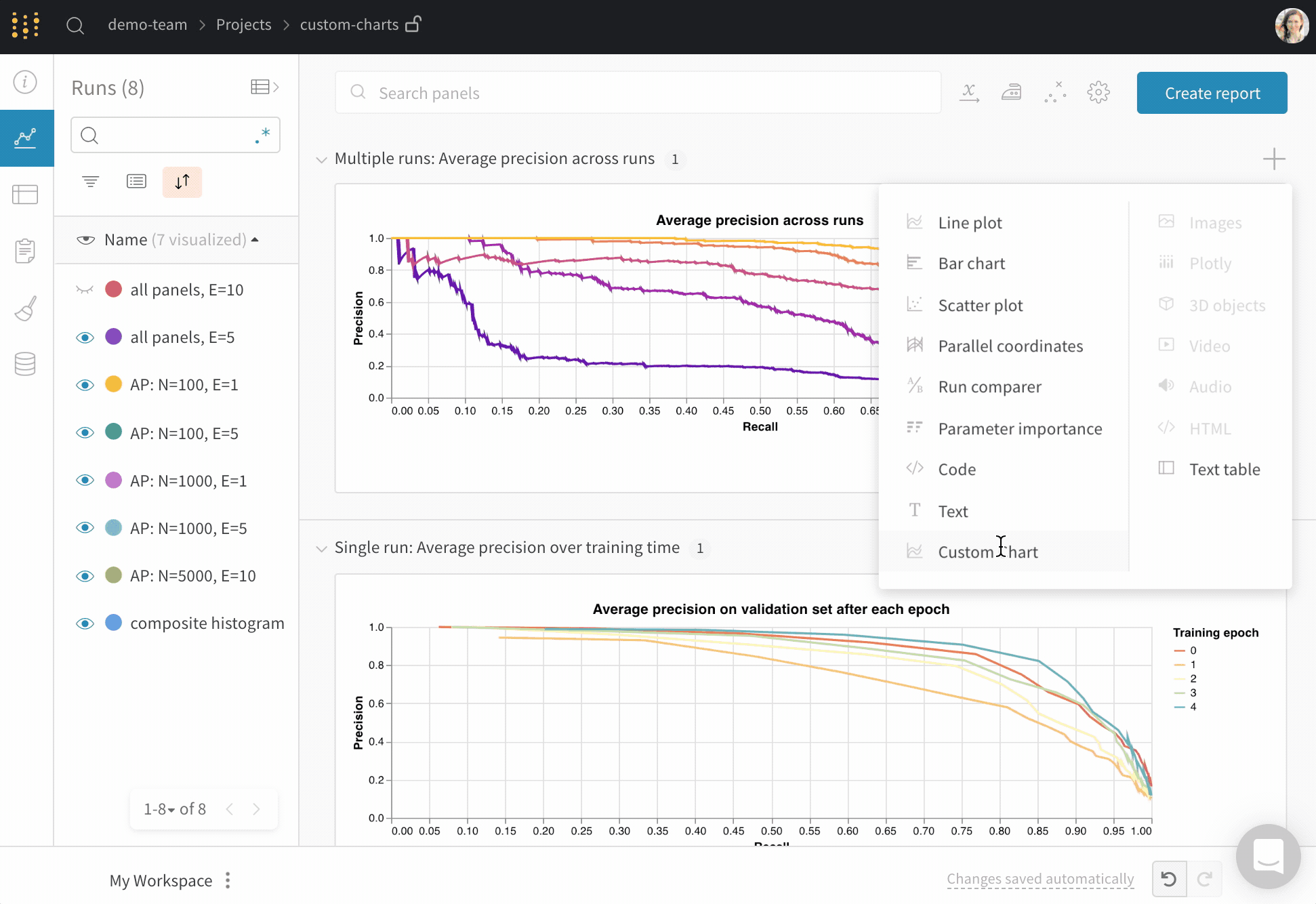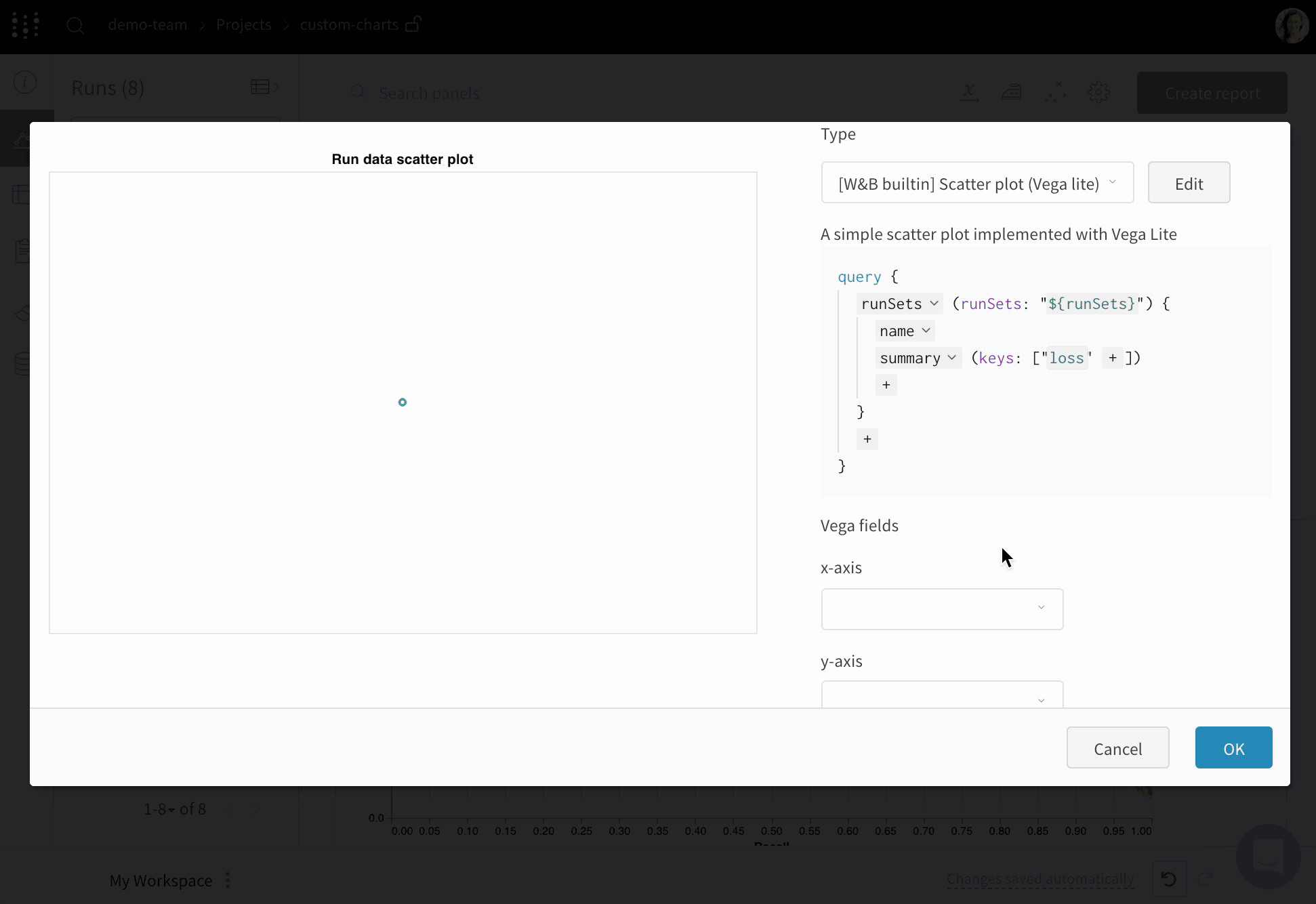
チャートをカスタマイズする
新しいカスタムチャートを追加して開始し、次にクエリを編集して表示可能な Runs からデータを選択します。クエリはGraphQLを使用して、実行での設定、サマリー、履歴フィールドからデータを取得します。
カスタム可視化
右上のChartを選択してデフォルトプリセットから始めましょう。次に、Chart fieldsを選択してクエリから引き出したデータをチャートの対応するフィールドにマッピングします。
次の画像は、メトリックをどのように選択し、それを下のバーチャートフィールドにマッピングするかの一例を示しています。
Vegaを編集する方法
パネルの上部にあるEditをクリックしてVega編集モードに入ります。ここでは、Vega仕様を定義して、UIでインタラクティブなチャートを作成することができます。チャートの任意の面を変更できます。例えば、タイトルを変更したり、異なるカラー スキームを選択したり、曲線を接続された線ではなく一連の点として表示したりできます。また、Vega変換を使用して値の配列をヒストグラムにビン分けするなど、データ自体にも変更を加えることができます。パネルプレビューはインタラクティブに更新されるため、Vega仕様やクエリを編集している間に変更の効果を確認できます。Vegaのドキュメントとチュートリアルを参照してください。
フィールド参照
W&Bからチャートにデータを引き込むには、Vega仕様のどこにでも"${field:<field-name>}" 形式のテンプレート文字列を追加します。これによりChart Fieldsエリアにドロップダウンが作成され、ユーザーがクエリ結果の列を選択してVegaにマップできます。
フィールドのデフォルト値を設定するには、この構文を使用します:"${field:<field-name>:<placeholder text>}"
チャートプリセットの保存
モーダルの下部にあるボタンで、特定の可視化パネルに変更を適用します。または、プロジェクト内の他の場所で使用するためにVega仕様を保存できます。使い回しができるチャート定義を保存するには、Vegaエディタの上部にあるSave asをクリックしてプリセットに名前を付けます。
記事とガイド
- The W&B Machine Learning Visualization IDE
- Visualizing NLP Attention Based Models
- Visualizing The Effect of Attention on Gradient Flow
- Logging arbitrary curves
共通のユースケース
- 誤差線のあるバープロットをカスタマイズする
- モデル検証メトリクスの表示(PR曲線のようにカスタムx-y座標が必要なもの)
- 2つの異なるモデル/実験からのデータ分布をヒストグラムとして重ね合わせる
- トレーニング中のスナップショットで複数のポイントにわたるメトリックの変化を示す
- W&Bにまだないユニークな可視化を作成する(そして、できればそれを世界と共有する)
2.1 - チュートリアル: カスタムチャートの使用
カスタムチャートを使用して、パネルに読み込むデータとその可視化を制御します。
1. データを W&B にログする
まず、スクリプトにデータをログします。ハイパーパラメーターのようなトレーニングの開始時に設定される単一のポイントには wandb.config を使用します。時間の経過に伴う複数のポイントには wandb.log() を使用し、wandb.Table() でカスタムの2D配列をログします。ログされたキーごとに最大10,000データポイントのログを推奨します。
# データのカスタムテーブルをログする
my_custom_data = [[x1, y1, z1], [x2, y2, z2]]
wandb.log(
{"custom_data_table": wandb.Table(data=my_custom_data, columns=["x", "y", "z"])}
)
データテーブルをログするための短い例のノートブック を試してみてください。次のステップでカスタムチャートを設定します。生成されたチャートが ライブレポート でどのように見えるか確認できます。
2. クエリを作成する
データを視覚化するためにログしたら、プロジェクトページに移動し、新しいパネルを追加するために + ボタンをクリックし、Custom Chart を選びます。このワークスペース で案内に従うことができます。

クエリを追加する
summaryをクリックしてhistoryTableを選択し、run 履歴からデータを引き出す新しいクエリを設定します。wandb.Table()をログしたキーを入力します。上記のコードスニペットではmy_custom_tableでした。例のノートブック では、キーはpr_curveとroc_curveです。
Vega フィールドを設定する
これらの列がクエリに読み込まれたので、Vega フィールドのドロップダウンメニューで選択オプションとして利用可能です:
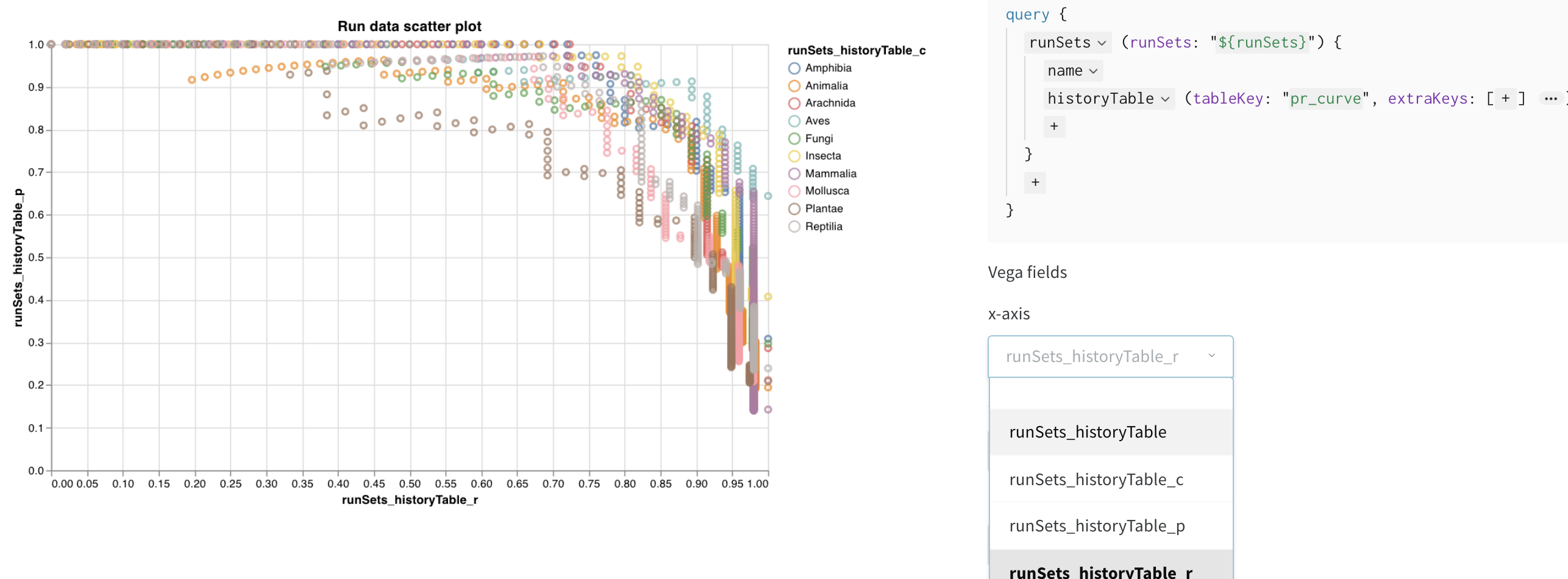
- x-axis: runSets_historyTable_r (recall)
- y-axis: runSets_historyTable_p (precision)
- color: runSets_historyTable_c (class label)
3. チャートをカスタマイズする
見た目はかなり良いですが、散布図から折れ線グラフに切り替えたいと思います。組み込みチャートの Vega スペックを変更するために Edit をクリックします。このワークスペース で案内に従うことができます。

Vega スペックを更新して可視化をカスタマイズしました:
- プロット、凡例、x-axis、および y-axis のタイトルを追加 (各フィールドに「title」を設定)
- 「mark」の 値を「point」から「line」に変更
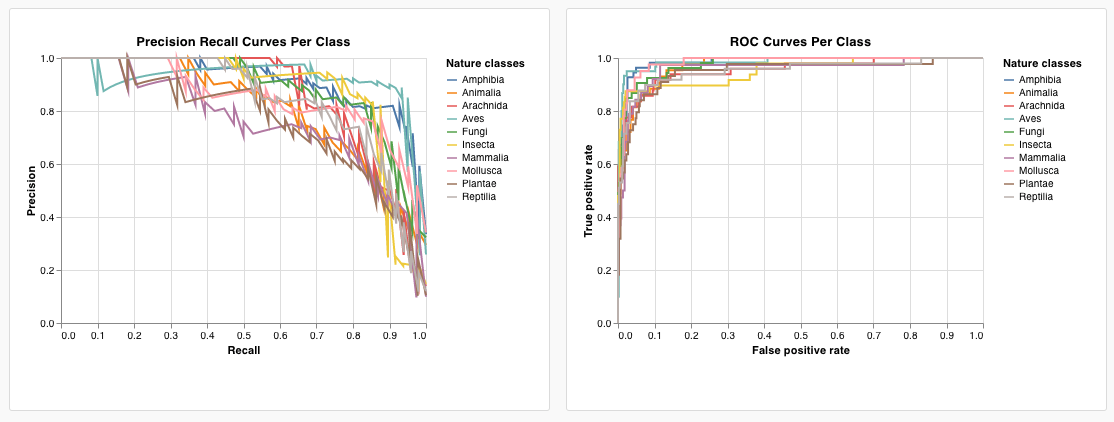
- 使用されていない「size」フィールドを削除
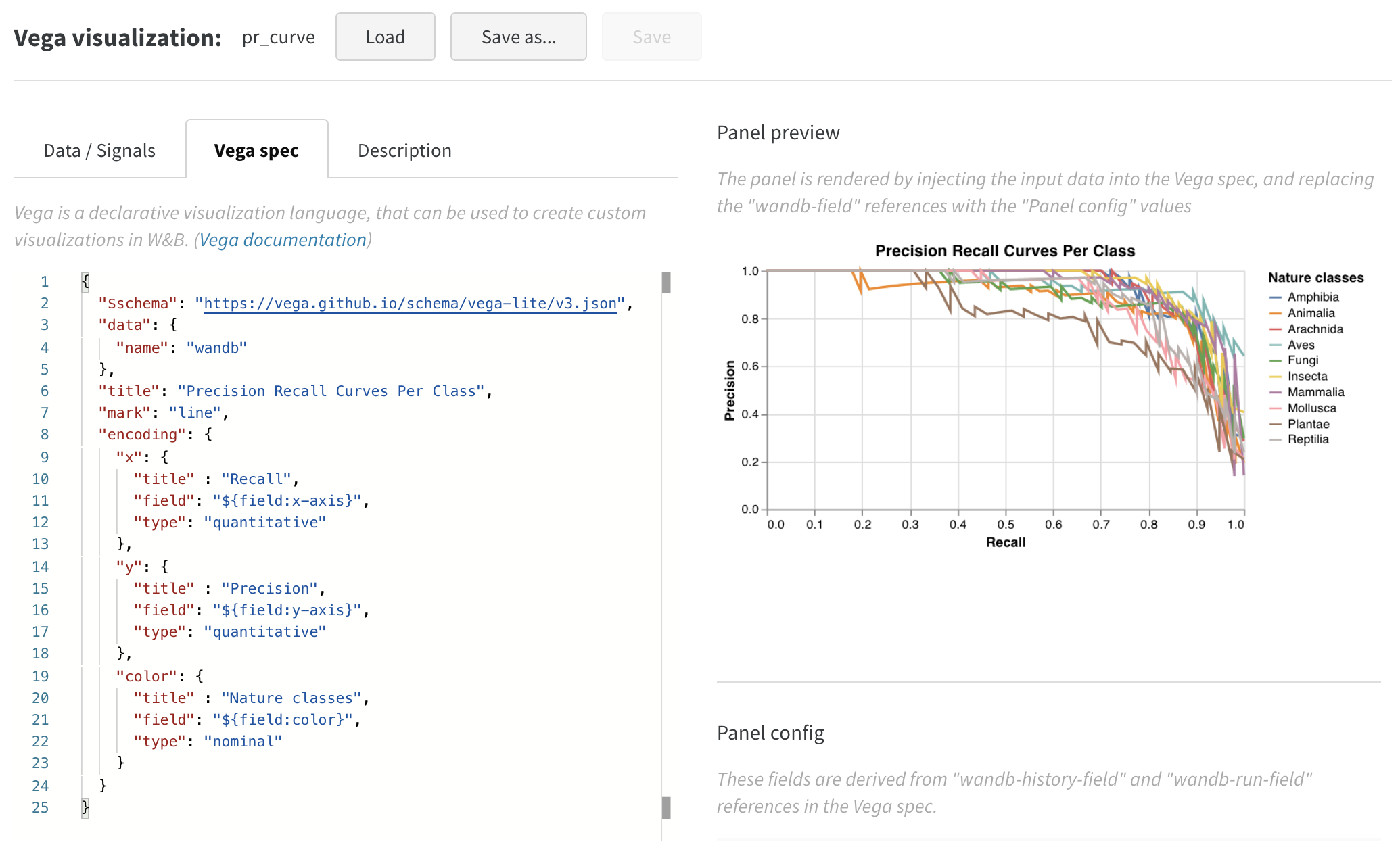
これを別の場所で使用できるプリセットとして保存するには、ページ上部の Save as をクリックします。結果は次の通り、ROC 曲線と共に次のようになります:
ボーナス: コンポジットヒストグラム
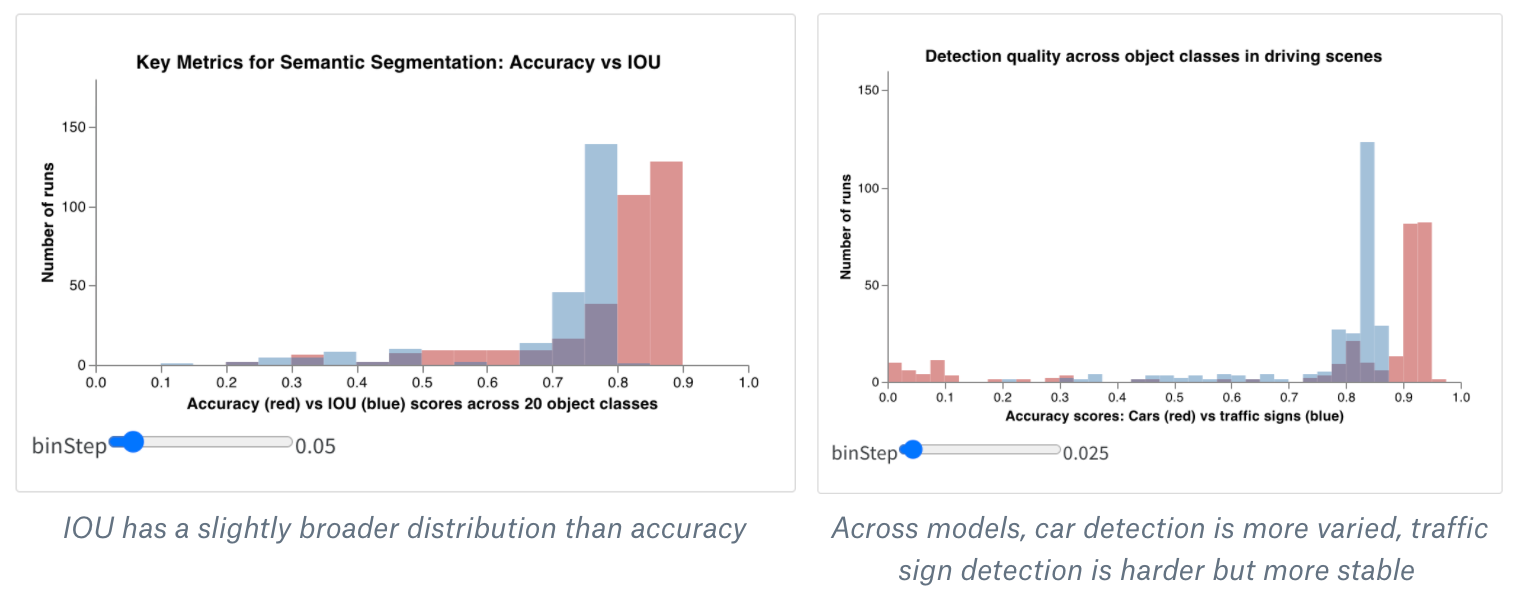
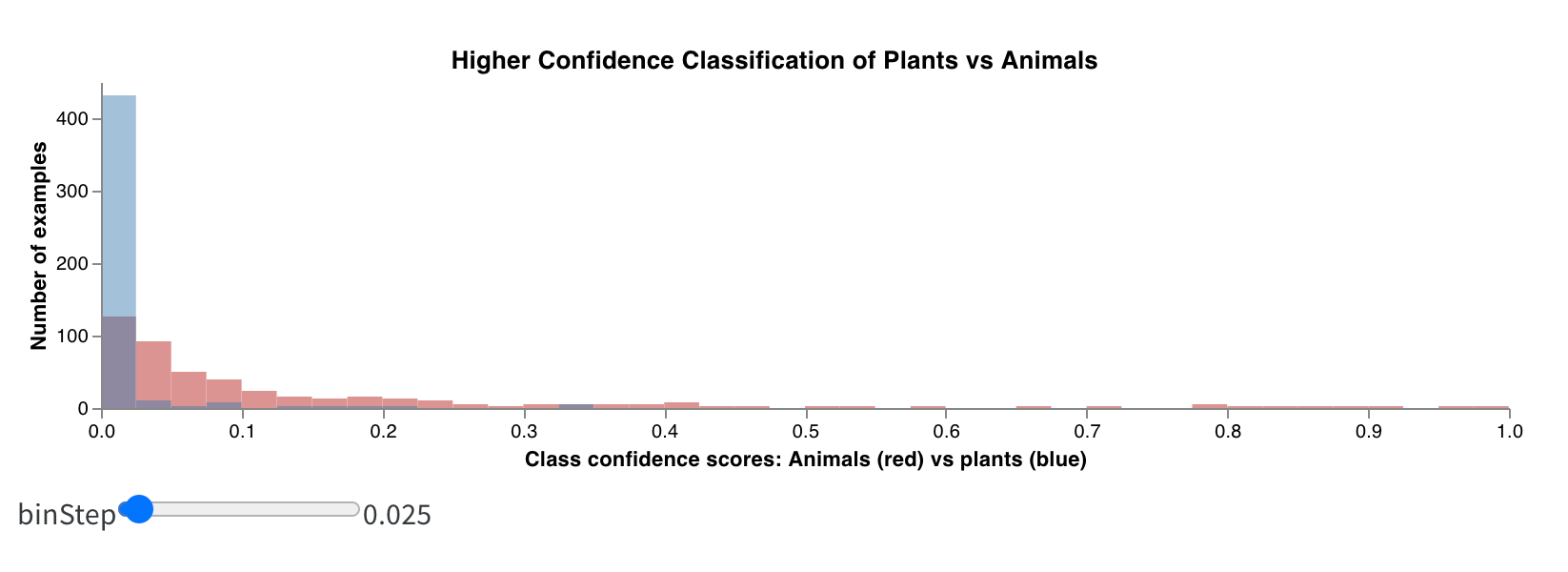
ヒストグラムは、数値の分布を可視化し、大きなデータセットを理解するのに役立ちます。コンポジットヒストグラムは、同じビンにまたがる複数の分布を示し、異なるモデルまたはモデル内の異なるクラス間で2つ以上のメトリクスを比較することができます。ドライブシーンのオブジェクトを検出するセマンティックセグメンテーションモデルの場合、精度最適化と Intersection over union (IOU) の効果を比較したり、異なるモデルが車(データの大きく一般的な領域)と交通標識(より小さく一般的でない領域)をどれだけよく検出するかを知りたいかもしれません。デモ Colab では、生命体の10クラスのうち2つのクラスの信頼スコアを比較できます。
カスタム合成ヒストグラムパネルのバージョンを作成するには:
- ワークスペース または レポート で新しい Custom Chart パネルを作成します(「Custom Chart」可視化を追加することによって)。右上の「Edit」ボタンを押して、組み込みパネルタイプから始めて Vega スペックを変更します。
- 組み込みの Vega スペックを私の Vega におけるコンポジットヒストグラムの MVP コード に置き換えます。メインタイトル、軸タイトル、入力ドメイン、および Vega syntax](https://vega.github.io/) を使用して、他の詳細を直接変更できます(色を変更したり、3番目のヒストグラムを追加したりできます :)
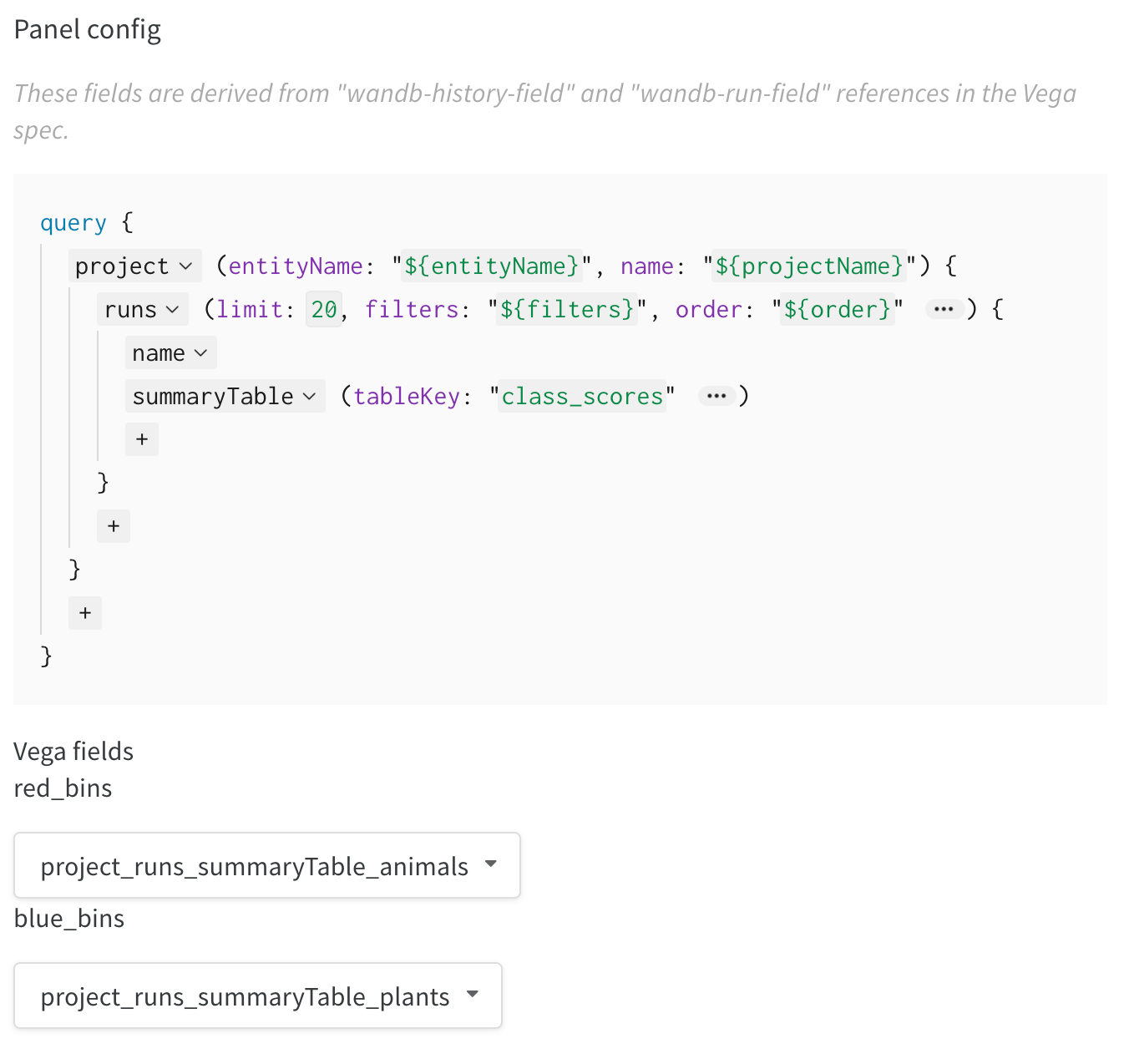
- 正しいデータを wandb ログから読み込むために右側のクエリを修正します。
summaryTableフィールドを追加し、対応する ’tableKey’ をclass_scoresに設定して、run でログしたwandb.Tableを取得します。これにより、wandb.Tableのクラススコアとしてログされた列を使用して、ドロップダウン メニューから2つのヒストグラムビンセット (red_binsとblue_bins) を埋めることができます。私の例では、赤ビンの動物クラスの予測スコアと青ビンの植物の予測スコアを選びました。 - プレビュー表示に表示されるプロットに満足するまで、Vega スペックとクエリを変更し続けることができます。完了したら、上部で Save as をクリックしてカスタムプロットに名前を付けて再利用できるようにします。 次に Apply from panel library をクリックしてプロットを終了します。
私の非常に短い実験の結果は次のようになりました:1,000エポックで1,000エグゼンプルだけでトレーニングすると、モデルはほとんどの画像が植物でないことに非常に自信を持ち、どの画像が動物かについては非常に不確かです。
3 - ワークスペース、セクション、パネル設定を管理する
Within a given workspace page there are three different setting levels: workspaces, sections, and panels. ワークスペース設定 は、ワークスペース全体に適用されます。セクション設定 は、セクション内のすべてのパネルに適用されます。パネル設定 は、個々のパネルに適用されます。
ワークスペース設定
ワークスペース設定は、すべてのセクションとそれらのセクション内のすべてのパネルに適用されます。編集できるワークスペース設定は次の2種類です: Workspace layout と Line plots。Workspace layouts はワークスペースの構造を決定し、Line plots 設定はワークスペース内のラインプロットのデフォルト設定を制御します。
このワークスペースの全体的な構造に適用される設定を編集するには:
- プロジェクトワークスペースに移動します。
- New report ボタンの横にある歯車のアイコンをクリックして、ワークスペース設定を表示します。
- ワークスペースのレイアウトを変更するには Workspace layout を選択するか、ワークスペース内のラインプロットのデフォルト設定を設定するには Line plots を選択します。
ワークスペースレイアウトオプション
ワークスペースのレイアウトを設定して、ワークスペースの全体的な構造を定義します。これには、セクションのロジックとパネルの配置が含まれます。
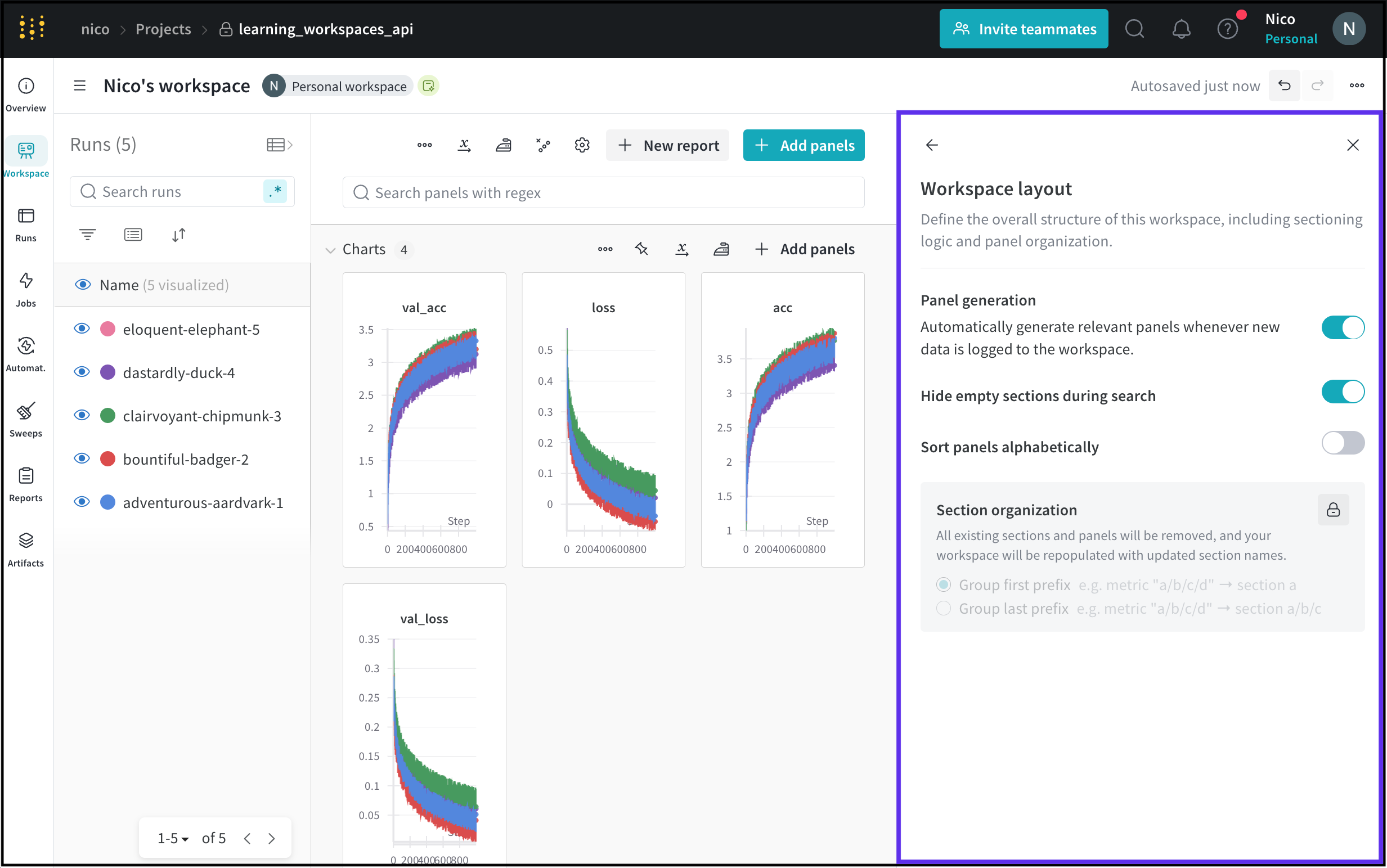
ワークスペースレイアウトオプションページでは、ワークスペースがパネルを自動か手動で生成するかが表示されます。ワークスペースのパネル生成モードを調整するには、Panels を参照してください。
この表は、各ワークスペースのレイアウトオプションについて説明しています。
| ワークスペース設定 | 説明 |
|---|---|
| 検索中に空のセクションを非表示 | パネルを検索するときにパネルを含まないセクションを非表示にします。 |
| パネルをアルファベット順に並べ替え | ワークスペース内のパネルをアルファベット順に並べ替えます。 |
| セクションの組織化 | 既存のすべてのセクションとパネルを削除し、新しいセクション名で再配置します。また、新しく配置されたセクションを最初または最後のプレフィックスでグループ化します。 |
ラインプロットオプション
ワークスペースのLine plots設定を変更して、ラインプロットのグローバルデフォルトとカスタムルールを設定します。
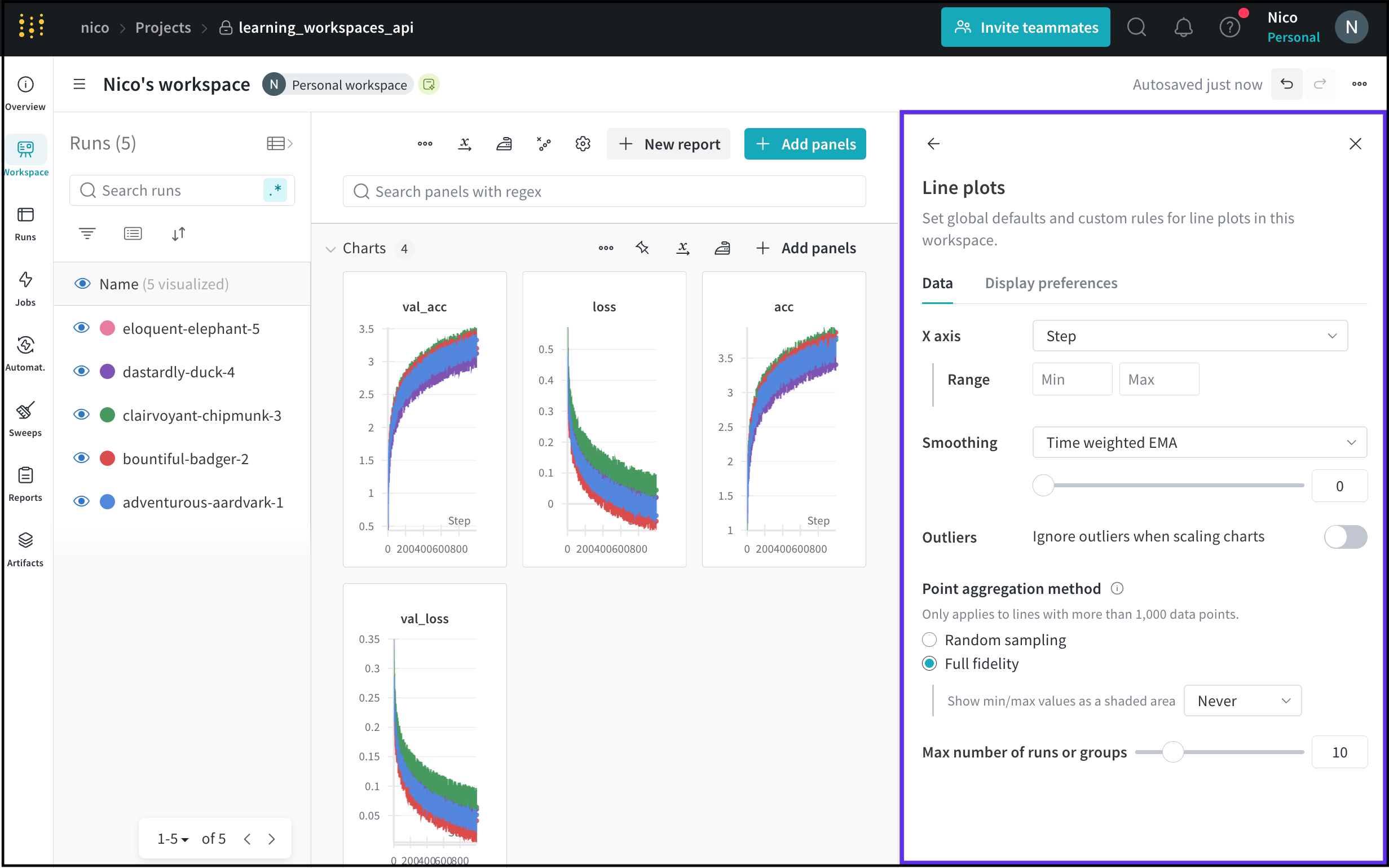
Line plots 設定内で編集できる主要な設定は2つあります: Data と Display preferences。Data タブには次の設定が含まれています:
| ラインプロット設定 | 説明 |
|---|---|
| X軸 | ラインプロットのx軸のスケール。x軸はデフォルトで Step に設定されています。x軸オプションのリストは次の表を参照してください。 |
| 範囲 | x軸に表示する最小値と最大値の設定。 |
| 平滑化 | ラインプロットの平滑化を変更します。平滑化の詳細については、Smooth line plots を参照してください。 |
| 異常値 | 異常値を除外するためにプロットの最小スケールと最大スケールを再設定します。 |
| ポイント集計方法 | Data Visualization の精度とパフォーマンスを向上させます。詳細については、Point aggregation を参照してください。 |
| 最大の runs またはグループの数 | ラインプロットに表示する最大の runs またはグループ数を制限します。 |
Step 以外にも、x軸には他のオプションがあります:
| X軸オプション | 説明 |
|---|---|
| 相対時間 (Wall) | プロセスが開始してからのタイムスタンプ。例えば、run を開始して次の日にその run を再開したとします。その場合、記録されたポイントは24時間後です。 |
| 相対時間 (Process) | 実行中のプロセス内のタイムスタンプ。例えば、run を開始して10秒間続け、その後次の日に再開したとします。その場合、記録されたポイントは10秒です。 |
| ウォールタイム | グラフで最初の run が開始してから経過した時間(分)。 |
| Step | wandb.log() を呼び出すたびに増加します。 |
Display preferences タブ内で、以下の設定を切り替えることができます:
| ディスプレイ設定 | 説明 |
|---|---|
| すべてのパネルから凡例を削除 | パネルの凡例を削除します |
| ツールチップ内でカラード run 名を表示 | ツールチップ内で run をカラードテキストとして表示します |
| コンパニオンチャートツールチップで、ハイライトされた run のみを表示 | チャートツールチップ内でハイライトされた run のみを表示します |
| ツールチップ内に表示される run の数 | ツールチップ内で表示される run の数を表示します |
| プライマリチャートのツールチップにフル run 名を表示 | チャートツールチップで run のフルネームを表示します |
セクション設定
セクション設定は、そのセクション内のすべてのパネルに適用されます。ワークスペースセクション内では、パネルをソートしたり、並べ替えたり、セクション名を変更したりできます。
セクション設定を変更するには、セクションの右上隅にある3つの水平ドット (…) を選択します。
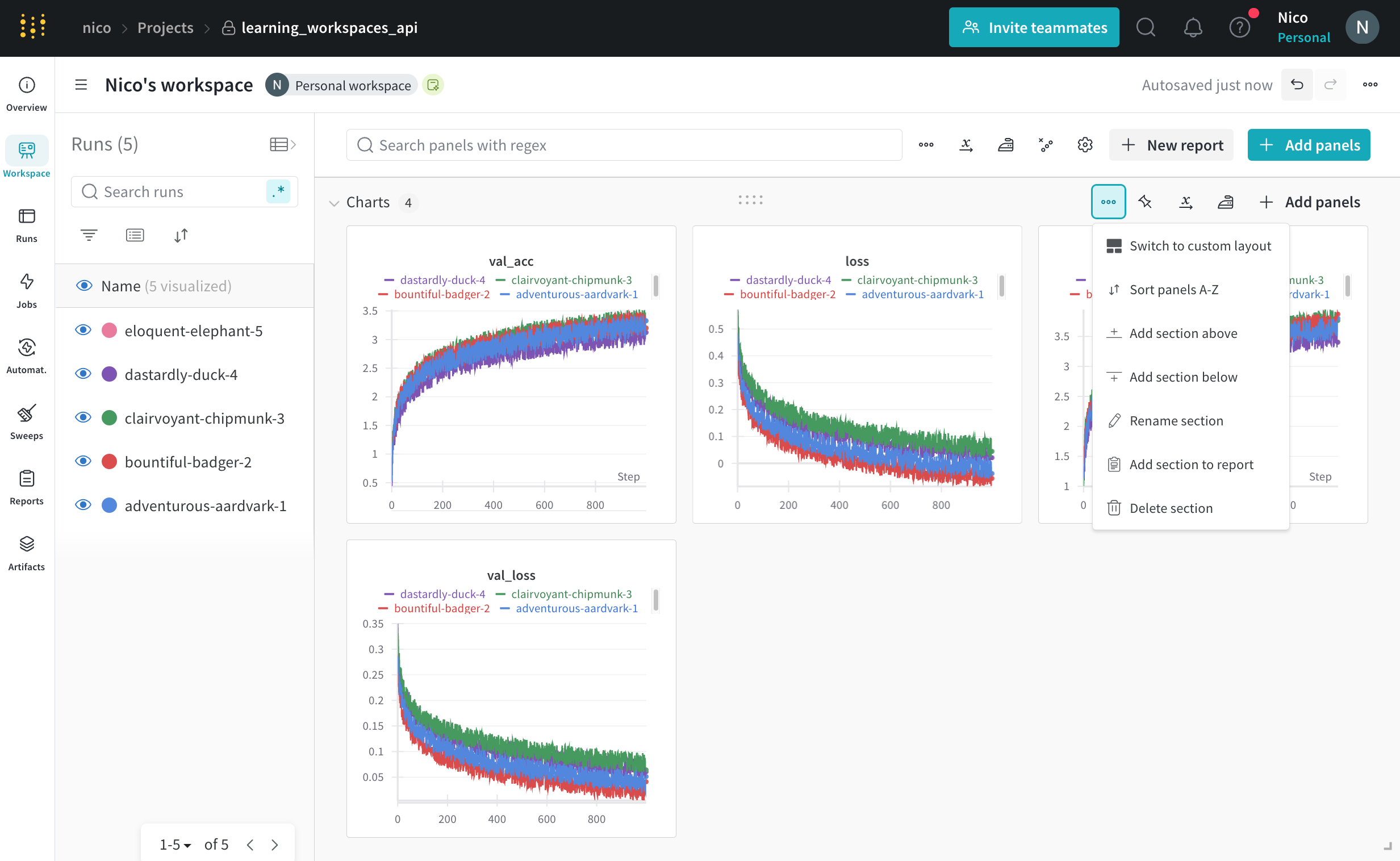
ドロップダウンから、セクション全体に適用される次の設定を編集できます:
| セクション設定 | 説明 |
|---|---|
| セクションの名前を変更 | セクションの名前を変更します |
| パネルを A-Z に並べ替え | セクション内のパネルをアルファベット順に並べ替えます |
| パネルを並べ替え | セクション内でパネルを手動で並べ替えるために、パネルを選択してドラッグします |
以下のアニメーションは、セクション内でパネルを並べ替える方法を示しています:
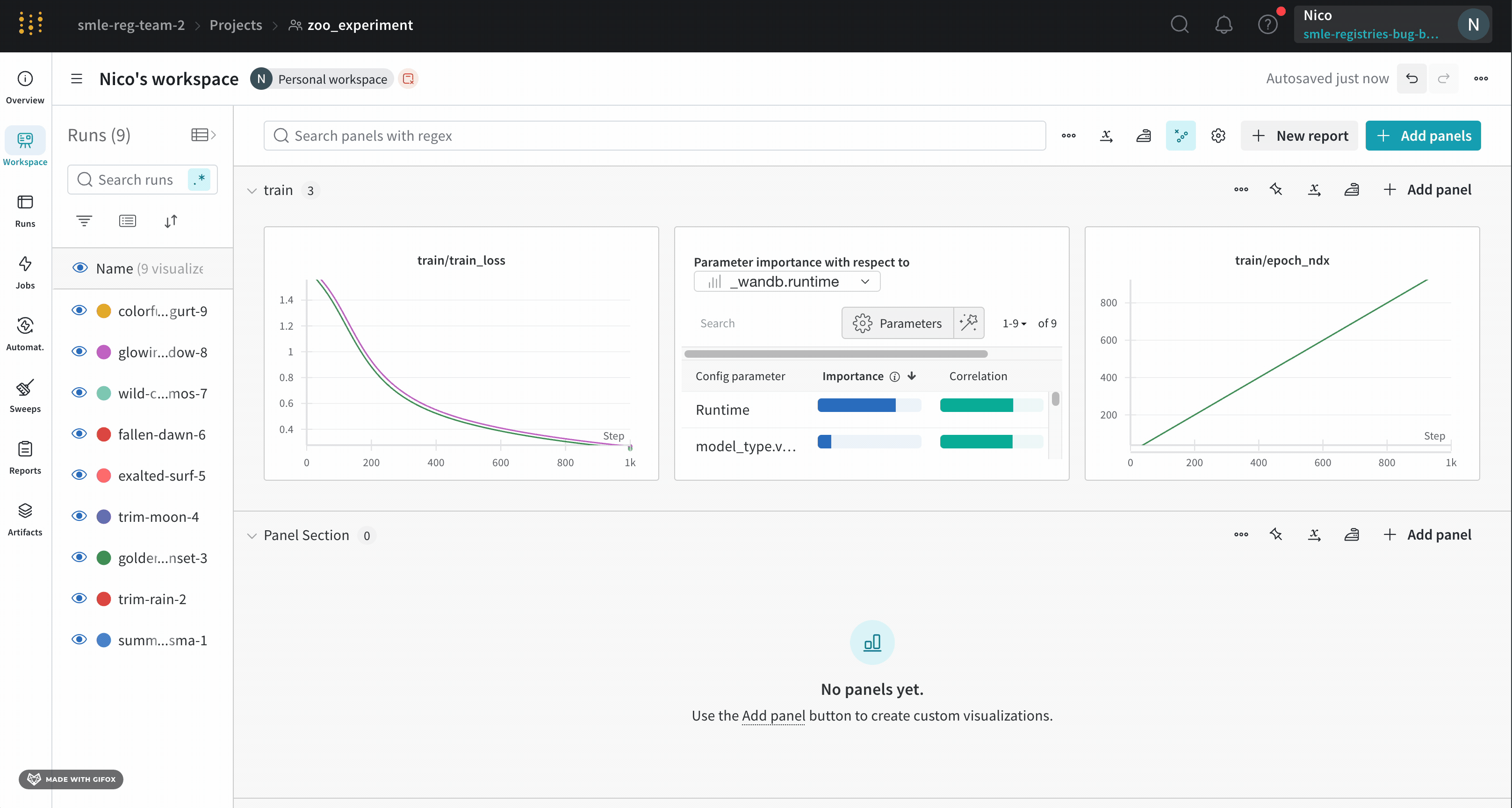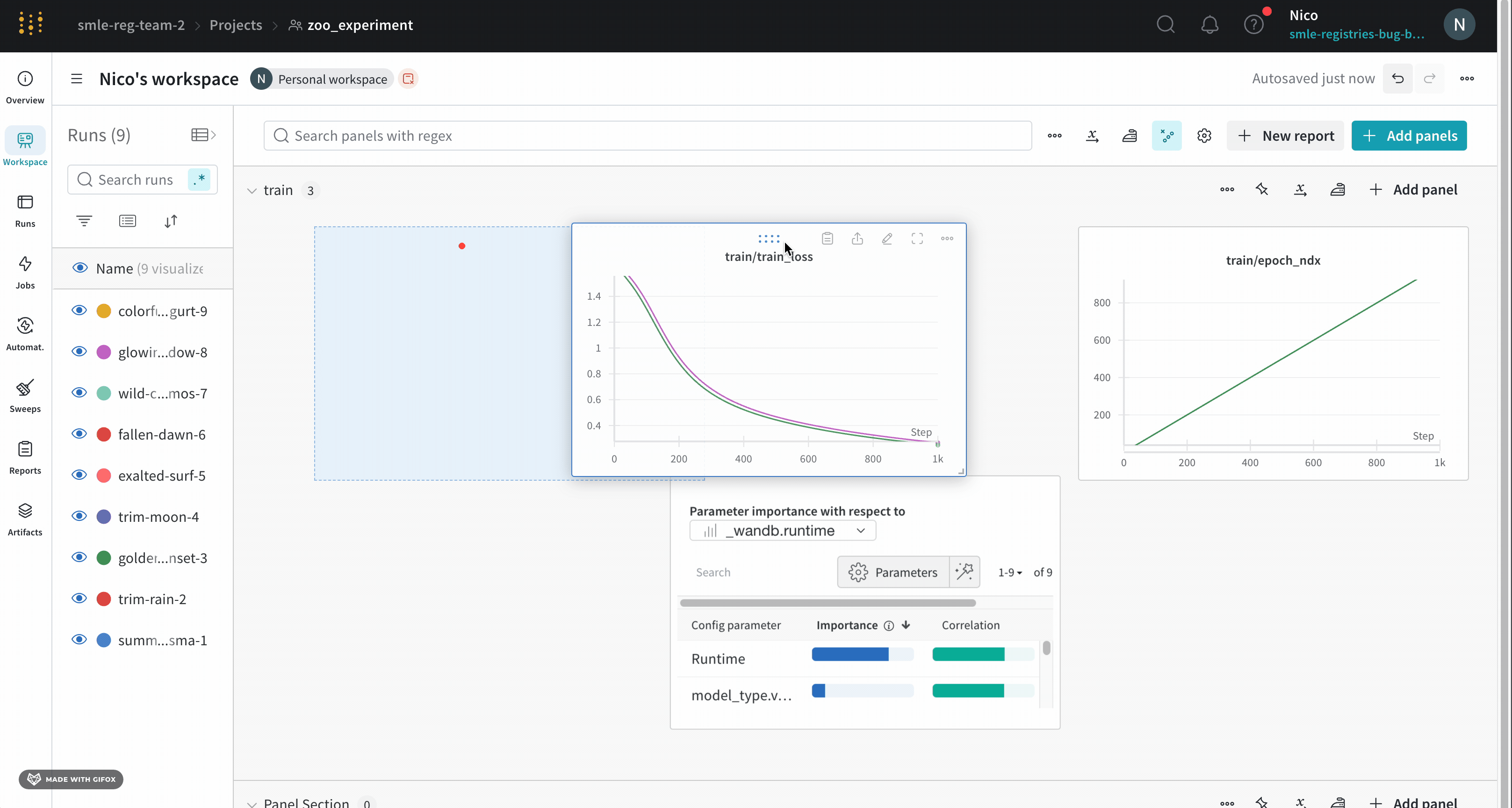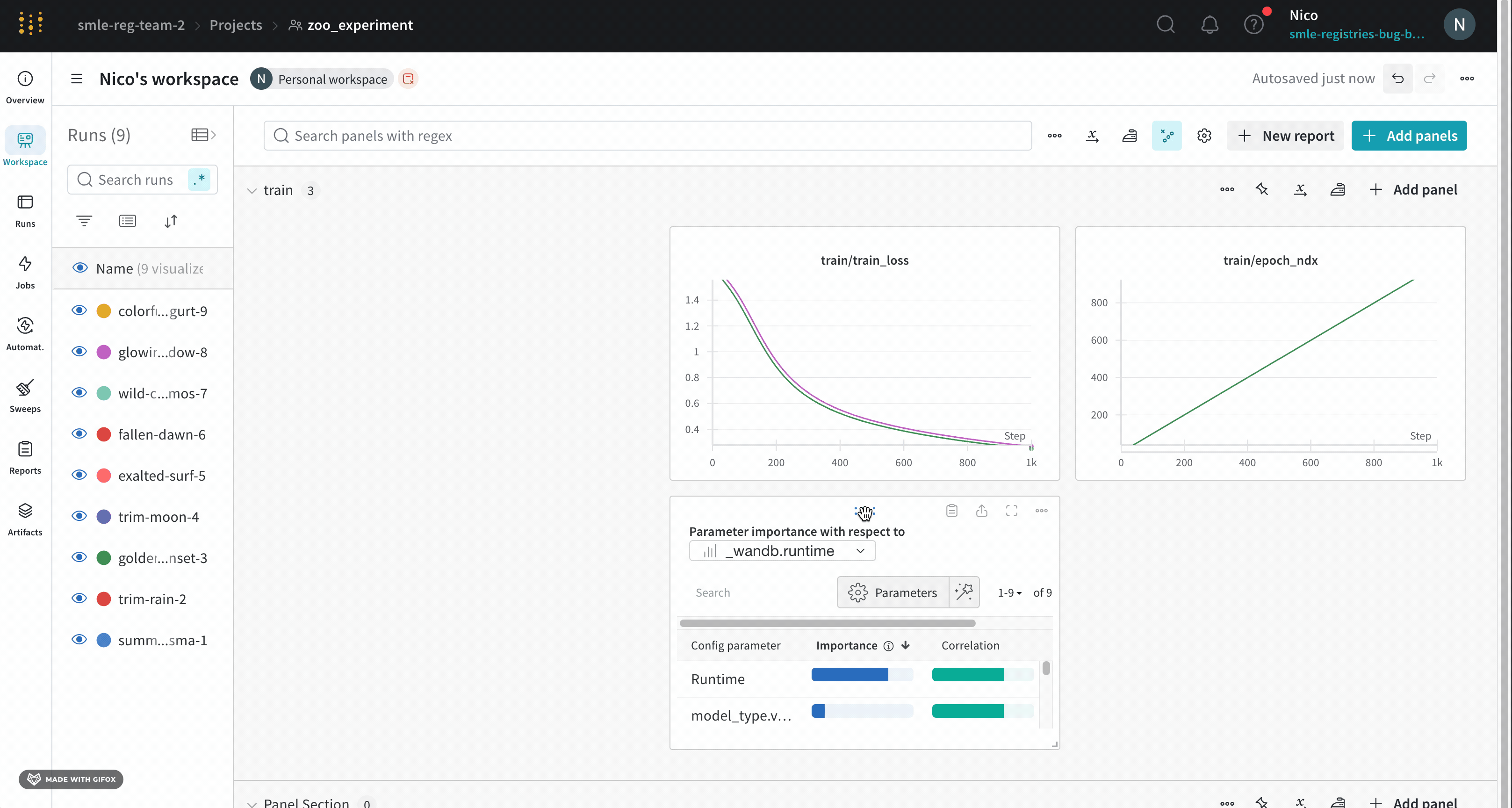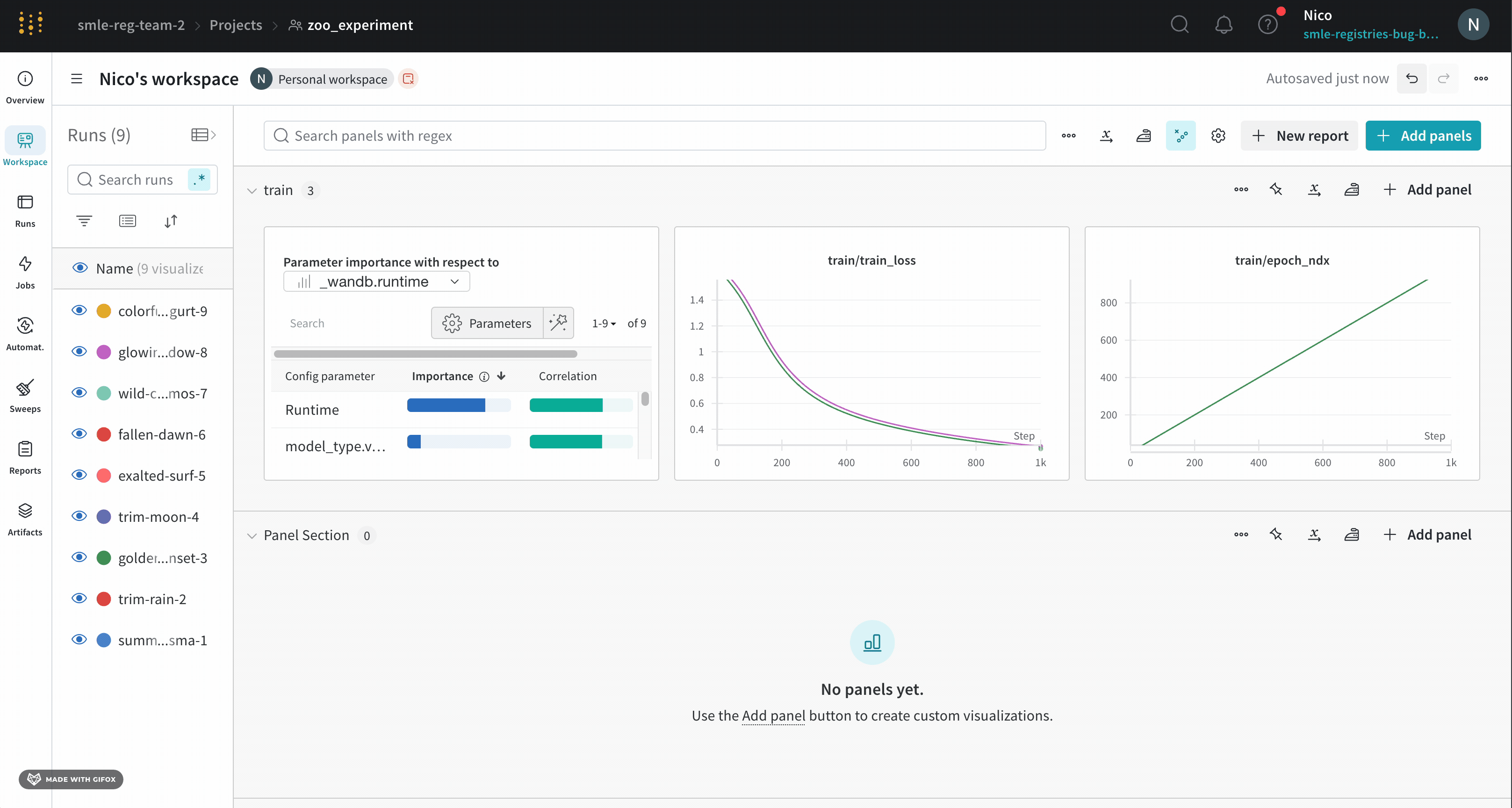
パネル設定
個々のパネルの設定をカスタマイズして、同じプロットで複数のラインを比較したり、カスタム軸を計算したり、ラベルを変更したりすることができます。パネルの設定を編集するには:
- 編集したいパネルにマウスを乗せます。
- 現れる鉛筆アイコンを選択します。
- 表示されたモーダル内で、パネルのデータ、ディスプレイの設定などに関連する設定を編集できます。
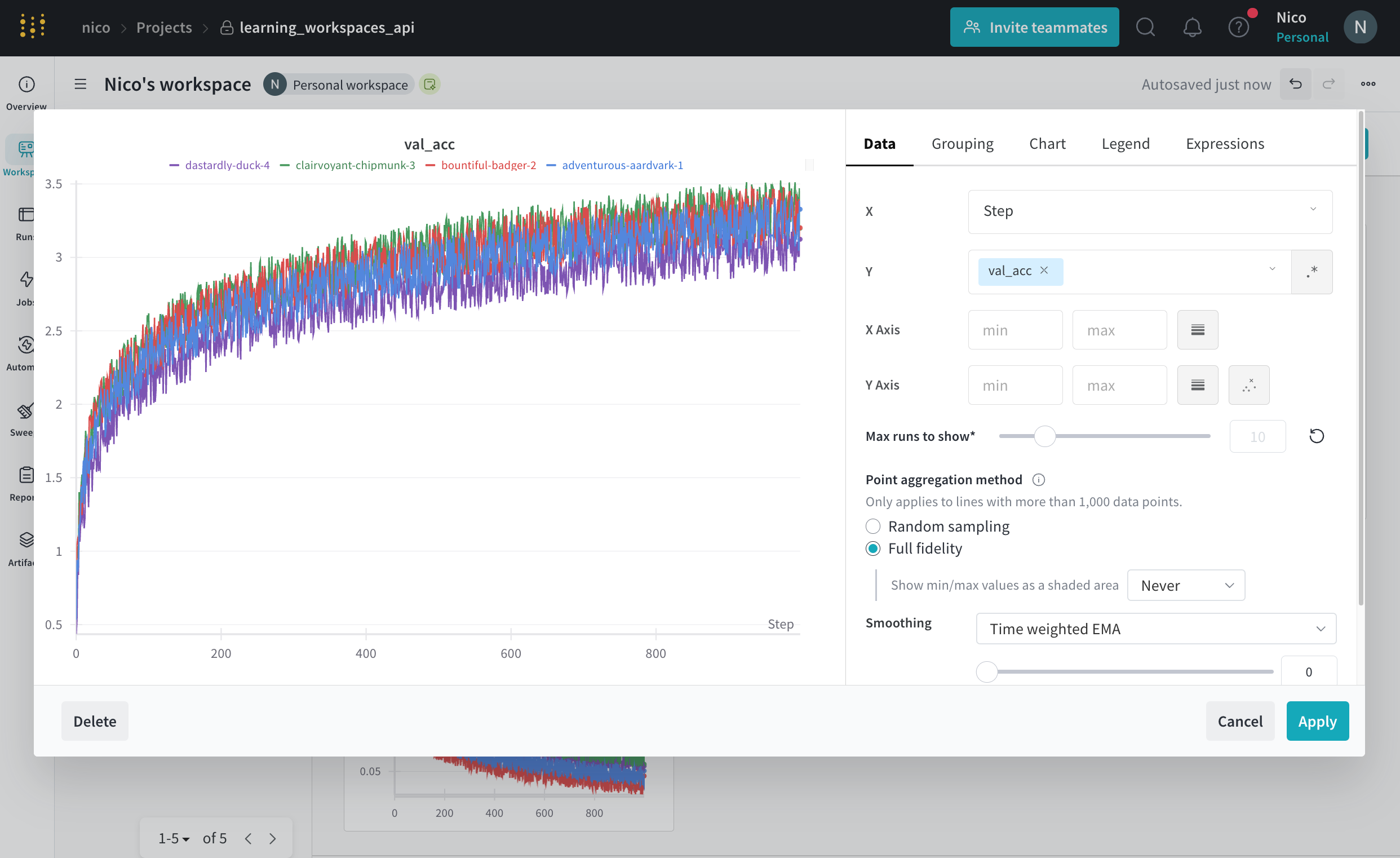
パネルに適用できる設定の完全なリストについては、Edit line panel settings を参照してください。
4 - 設定
あなたの個別のユーザーアカウント内で編集できるのは、プロフィール写真、表示名、地理的な位置、経歴情報、アカウントに関連付けられたメール、および run のアラート管理です。また、設定ページを使用して GitHub リポジトリをリンクしたり、アカウントを削除したりできます。詳細はユーザー設定をご覧ください。
チーム設定ページを使用して、新しいメンバーをチームに招待または削除したり、チームの run のアラートを管理したり、プライバシー設定を変更したり、ストレージ使用量を表示および管理したりできます。チーム設定の詳細については、チーム設定をご覧ください。
4.1 - ユーザー設定を管理する
ナビゲートして、 ユーザープロフィールページに移動し、右上のユーザーアイコンを選択します。 ドロップダウンメニューから、Settings を選択します。
Profile
Profile セクションでは、アカウント名と所属機関を管理および変更できます。オプションで、経歴、所在地、個人や所属機関のウェブサイトのリンクを追加したり、プロフィール画像をアップロードしたりできます。
イントロの編集
イントロを編集するには、プロフィールの上部にある Edit をクリックします。 開く WYSIWYG エディターは Markdown をサポートしています。
- 行を編集するには、それをクリックします。 時間を短縮するために、
/を入力し、リストから Markdown を選択できます。 - アイテムのドラッグハンドルを使って移動します。
- ブロックを削除するには、ドラッグハンドルをクリックしてから Delete をクリックします。
- 変更を保存するには、Save をクリックします。
SNS バッジの追加
@weights_biases アカウントのフォローバッジを X に追加するには、HTML の <img> タグを含む Markdown スタイルのリンクを追加します。そのバッジ画像にリンクさせます。

<img> タグでは、width、height、またはその両方を指定できます。どちらか一方だけを指定すると、画像の比率は維持されます。
Teams
Team セクションで新しいチームを作成します。 新しいチームを作成するには、New team ボタンを選択し、次の情報を提供します。
- Team name - チームの名前。チーム名はユニークでなければなりません。チーム名は変更できません。
- Team type - Work または Academic ボタンを選択します。
- Company/Organization - チームの会社または組織の名前を提供します。 ドロップダウンメニューから会社または組織を選択します。 オプションで新しい組織を提供することもできます。
ベータ機能
Beta Features セクションでは、開発中の新製品の楽しいアドオンやプレビューをオプションで有効にできます。有効にしたいベータ機能の横にある切り替えスイッチを選択します。
アラート
Runs がクラッシュしたり、終了したり、カスタムアラートを設定した際に通知を受け取ります。wandb.alert() を使用して電子メールまたは Slack 経由で通知を受け取ります。受け取りたいアラートイベントタイプの横にあるスイッチを切り替えます。
- Runs finished: Weights and Biases の run が正常に完了したかどうか。
- Run crashed: run が終了しなかった場合の通知。
アラートの設定と管理方法の詳細については、Send alerts with wandb.alert を参照してください。
個人 GitHub インテグレーション
個人の Github アカウントを接続します。 Github アカウントを接続するには:
- Connect Github ボタンを選択します。これにより、オープン認証(OAuth)ページにリダイレクトされます。
- Organization access セクションでアクセスを許可する組織を選択します。
- Authorize wandb を選択します。
アカウントの削除
アカウントを削除するには、Delete Account ボタンを選択します。
ストレージ
Storage セクションでは、Weights and Biases サーバーにおけるアカウントの総メモリ使用量について説明しています。 デフォルトのストレージプランは 100GB です。ストレージと料金の詳細については、Pricing ページをご覧ください。
4.2 - 請求設定を管理する
ナビゲートして ユーザー プロフィール ページ へ行き、右上隅の ユーザー アイコン を選択します。ドロップダウンから Billing を選択するか、Settings を選択してから Billing タブを選択してください。
プランの詳細
プランの詳細 セクションは、あなたの組織の現在のプラン、料金、制限、使用状況を要約します。
- ユーザーの詳細とリストについては、Manage users をクリックしてください。
- 使用状況の詳細については、View usage をクリックしてください。
- あなたの組織が使用するストレージの量(無料と有料の両方)。ここから追加のストレージを購入したり、現在使用中のストレージを管理したりできます。storage settings についての詳細を学んでください。
ここから、プランを比較したり、営業と話をすることができます。
プランの使用量
このセクションでは現在の使用状況を視覚的に要約し、今後の使用料金を表示します。使用量の月ごとの詳細を知るには、個々のタイルで View usage をクリックしてください。カレンダー月、チーム、プロジェクトごとの使用量をエクスポートするには、Export CSV をクリックしてください。
使用状況アラート
有料プランを使用している組織の場合、管理者は特定のしきい値に達したときに 1 回の請求期間ごとに 電子メールでアラートを受け取ります。billing admin である場合は組織の制限を増やす方法の詳細情報と、そうでない場合の billing admin への連絡方法を提供します。Pro plan では、billing admin のみが使用状況アラートを受け取ります。
これらのアラートは設定可能ではなく、以下の場合に送信されます:
- 組織が月ごとの使用カテゴリの制限に近づいたとき (85% の使用時間)、およびプランに基づいて 100% の制限に達したとき。
- 請求期間中の組織の累積平均料金が以下のしきい値を超えると、$200、$450、$700、$1000。これらの追加料金は、追跡時間、ストレージ、または Weave データの取り込みでプランに含まれる以上の使用が組織で積み重なると発生します。
使用状況や請求に関する質問については、アカウントチームまたはサポートにお問い合わせください。
支払い方法
このセクションでは、組織に登録されている支払い方法を表示します。支払い方法を追加していない場合、プランをアップグレードするか、有料ストレージを追加するときに追加を求められます。
Billing admin
このセクションでは、現在の billing admin を表示します。billing admin は組織の管理者であり、すべての請求関連メールを受信し、支払い方法を表示および管理することができます。
billing admin を変更するか、追加の users に役割を割り当てるには:
- Manage roles をクリックします。
- ユーザーを検索します。
- そのユーザーの行の Billing admin フィールドをクリックします。
- 要約を読んでから、Change billing user をクリックします。
請求書
クレジットカードによる支払いを行う場合、このセクションでは月ごとの請求書を表示できます。
- 銀行振込で支払う Enterprise アカウントの場合、このセクションは空白です。質問については、アカウントチームにお問い合わせください。
- 組織に請求がない場合、請求書は生成されません。
4.3 - チーム設定を管理する
チーム設定
チームの設定を変更します。メンバー、アバター、通知、プライバシー、利用状況を含みます。組織の管理者およびチームの管理者は、チームの設定を表示および編集できます。
メンバー
メンバーセクションでは、保留中の招待と、チームに参加する招待を受け入れたメンバーのリストを表示します。各メンバーのリストには、メンバーの名前、ユーザー名、メール、チームの役割、および Models や Weave へのアクセス権限が表示されます。これらは組織から継承されます。標準のチーム役割 Admin、Member、View-only から選択できます。組織が カスタムロールの作成をしている場合、カスタムロールを割り当てることもできます。
チームの作成、管理、およびチームのメンバーシップと役割の管理についての詳細は、Add and Manage Teams を参照してください。新しいメンバーを招待できる人や、チームの他のプライバシー設定を設定するには、プライバシー を参照してください。
アバター
Avatar セクションに移動して画像をアップロードすることで、アバターを設定します。
- Update Avatar を選択し、ファイルダイアログを表示します。
- ファイルダイアログから使用したい画像を選択します。
アラート
run がクラッシュしたり、完了したり、カスタムアラートを設定したりしたときにチームに通知します。チームは、メールまたは Slack を通じてアラートを受け取ることができます。
受け取りたいイベントタイプの横にあるスイッチを切り替えます。Weights and Biases はデフォルトで以下のイベントタイプオプションを提供します:
- Runs finished: Weights and Biases の run が正常に完了したかどうか。
- Run crashed: run が完了できなかった場合。
アラートの設定と管理についての詳細は、wandb.alert を使用したアラートの送信 を参照してください。
Slack 通知
Slack の送信先を設定し、チームのオートメーションが、新しいアーティファクトが作成されたときや、run のメトリックが設定された閾値に達したときなどに Registry やプロジェクトでイベントが発生すると通知を送信できるようにします。Slack オートメーションの作成を参照してください。
This feature is available for all Enterprise licenses.
ウェブフック
チームのオートメーションが、新しいアーティファクトが作成されたときや、run のメトリックが設定された閾値に達したときなどに Registry やプロジェクトでイベントが発生すると動作するようにウェブフックを設定します。Webhook オートメーションの作成を参照してください。
This feature is available for all Enterprise licenses.
プライバシー
Privacy セクションに移動してプライバシー設定を変更します。プライバシー設定を変更できるのは組織の管理者のみです。
- 今後のプロジェクトを公開したり、レポートを公開で共有したりする機能をオフにします。
- チームの管理者だけでなく、どのチームメンバーも他のメンバーを招待できます。
- デフォルトでコードの保存がオンになっているかどうかを管理します。
使用状況
Usage セクションでは、チームが Weights and Biases サーバーで消費した合計メモリ使用量について説明します。デフォルトのストレージプランは100GBです。ストレージと価格についての詳細は、Pricing ページを参照してください。
ストレージ
Storage セクションでは、チームのデータに対して使用されるクラウドストレージバケットの設定を説明します。詳細は Secure Storage Connector を参照するか、セルフホスティングしている場合は W&B Server ドキュメントをチェックしてください。
4.4 - メール設定を管理する
Add, delete, manage email types and primary email addresses in your W&B プロファイル 設定 ページ. Select your profile icon in the upper right corner of the W&B ダッシュボード. From the dropdown, select 設定. Within the 設定 ページ, scroll down to the Emails ダッシュボード:
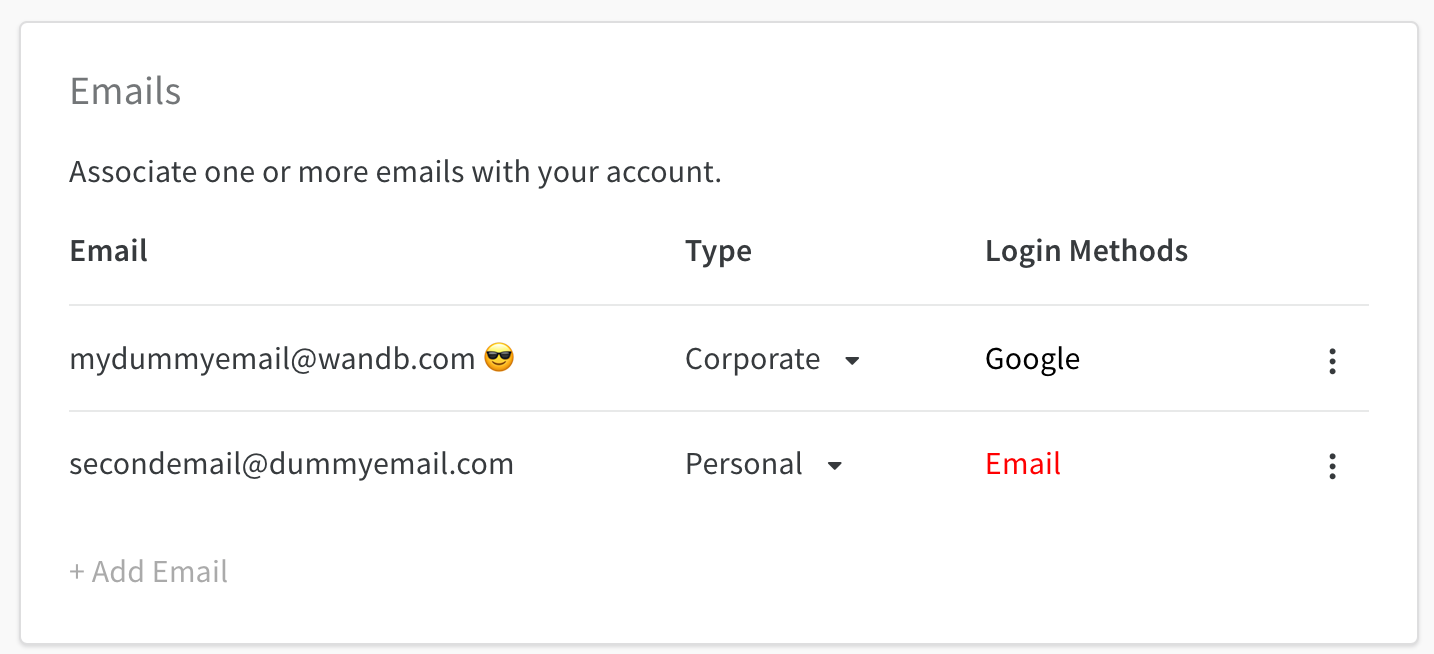
プライマリーメール の管理
プライマリーメール は 😎 絵文字でマークされています。プライマリーメール は、W&B アカウントを作成する際に提供したメールで自動的に定義されます。
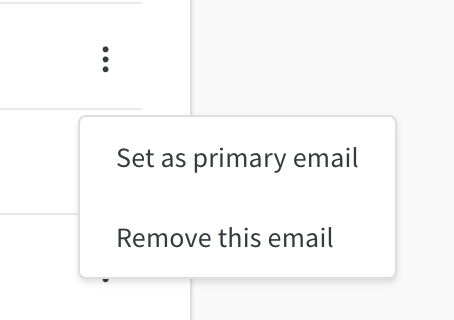
Weights And Biases アカウント に関連付けられている プライマリーメール を変更するには、ケバブ ドロップダウン を選択します:
メールを追加
+ Add Email を選択して、メールを追加します。これにより、Auth0 ページに移動します。新しいメールの資格情報を入力するか、シングル サインオン (SSO) を使用して接続できます。
メールを削除
ケバブ ドロップダウン を選択し、Delete Emails を選択して、W&B アカウント に登録されているメールを削除します
ログイン メソッド
ログイン メソッド 列には、アカウントに関連付けられているログイン メソッド が表示されます。
W&B アカウントを作成すると、確認メールがアカウント に送信されます。メール アドレス を確認するまで、メール アカウント は確認されていないと見なされます。未確認のメールは赤で表示されます。
元の確認メールがメール アカウントに送信されていない場合、もう一度メール アドレスでログインを試みて、2 回目の確認メールを取得してください。
アカウントのログインの問題がある場合は、support@wandb.com にお問い合わせください。
4.5 - チームを管理する
W&B Teams を使用して、あなたの ML チームのための中心的なワークスペースを作り、モデルをより迅速に構築しましょう。
- チームが試した全ての実験管理を追跡し、作業の重複を防ぎます。
- 以前にトレーニングしたモデルを保存し再現します。
- 進捗や成果を上司やコラボレーターと共有します。
- リグレッションをキャッチし、パフォーマンスが低下したときにすぐに通知を受け取ります。
- モデルの性能をベンチマークし、モデルのバージョンを比較します。
協力的なチームを作成する
- サインアップまたはログインして、無料の W&B アカウントを取得します。
- ナビゲーションバーで チームを招待 をクリックします。
- チームを作成し、コラボレーターを招待します。
- チームの設定については、チーム設定の管理を参照してください。
チームプロフィールを作成する
あなたのチームのプロフィールページをカスタマイズして、イントロダクションを示したり、公開されているまたはチームメンバーに表示されるレポートやプロジェクトを見せることができます。レポート、プロジェクト、外部リンクを提示します。
- 最良の研究を強調表示し、訪問者にあなたの最良の公開レポートを見せる
- 最もアクティブなプロジェクトを披露し、チームメイトがそれらを見つけやすくする
- あなたの会社や研究室のウェブサイトや公開した論文への外部リンクを追加することで コラボレーターを見つける
チームメンバーを削除する
チーム管理者はチーム設定ページを開き、去るメンバーの名前の横にある削除ボタンをクリックします。チームにログされている run はユーザーが去った後も留まります。
チームの役割と権限を管理する
同僚をチームに招待するときにチームの役割を選択します。以下のチームの役割オプションがあります:
- 管理者: チーム管理者は他の管理者やチームメンバーを追加および削除できます。すべてのプロジェクトを変更する権限と完全な削除権限を持っています。これには、run、プロジェクト、Artifacts、スイープの削除が含まれますが、これに限定されません。
- メンバー: チームの通常のメンバーです。デフォルトでは、管理者のみがチームメンバーを招待できます。この振る舞いを変更するには、チーム設定の管理を参照してください。
チームメンバーは自分が作成した run のみを削除できます。メンバー A と B がいるとします。メンバー B が team B のプロジェクトからメンバー A が所有する別のプロジェクトに run を移動します。メンバー A は、メンバー B がメンバー A のプロジェクトに移動した run を削除できません。管理者は、チームメンバーによって作成された run およびスイープ run を管理できます。
- 閲覧のみ (エンタープライズ限定機能): 閲覧のみのメンバーは、run、レポート、ワークスペースのようなチーム内のアセットを閲覧できます。彼らはレポートを追跡し、コメントを残すことができますが、プロジェクト概要、レポート、run を作成、編集、または削除することはできません。
- カスタム役割 (エンタープライズ限定機能): カスタム役割は、組織管理者が 閲覧のみ または メンバー のいずれかの役割に基づいて新しい役割を作成し、より詳細なアクセス制御を実現するための追加の権限と共にそれを構成させます。その後、チーム管理者がそれぞれのチームのユーザーにこれらのカスタム役割を割り当てることができます。詳細については、Introducing Custom Roles for W&B Teams を参照してください。
- サービスアカウント (エンタープライズ限定機能): Use service accounts to automate workflows を参照してください。
チーム設定
チーム設定では、チームとそのメンバーのための設定を管理できます。これらの特権により、W&B 内でチームを効果的に監督および整理できます。
| 権限 | 閲覧のみ | チームメンバー | チーム管理者 |
|---|---|---|---|
| チームメンバーを追加 | X | ||
| チームメンバーを削除 | X | ||
| チーム設定を管理 | X |
レジストリ
以下の表は、特定のチーム全体で適用されるすべてのプロジェクトに関連する権限を示しています。
| 権限 | 閲覧のみ | チームメンバー | レジストリ管理者 | チーム管理者 |
|---|---|---|---|---|
| エイリアスを追加する | X | X | X | |
| モデルをレジストリに追加する | X | X | X | |
| レジストリ内のモデルを閲覧する | X | X | X | X |
| モデルをダウンロードする | X | X | X | X |
| レジストリ管理者を追加または削除する | X | X | ||
| 保護されたエイリアスを追加または削除する | X |
保護されたエイリアスの詳細については、レジストリアクセス制御 を参照してください。
レポート
レポート権限は、レポートの作成、閲覧、編集へのアクセスを許可します。以下の表は、特定のチーム全体でのすべてのレポートに適用される権限を列挙しています。
| 権限 | 閲覧のみ | チームメンバー | チーム管理者 |
|---|---|---|---|
| レポートを閲覧する | X | X | X |
| レポートを作成する | X | X | |
| レポートを編集する | X (チームメンバーは自分のレポートのみ編集できます) | X | |
| レポートを削除する | X (チームメンバーは自分のレポートのみ編集できます) | X |
実験管理
以下の表は、特定のチーム全体でのすべての実験に適用される権限を示しています。
| 権限 | 閲覧のみ | チームメンバー | チーム管理者 |
|---|---|---|---|
| 実験のメタデータを閲覧する(履歴メトリクス、システムメトリクス、ファイル、およびログを含む) | X | X | X |
| 実験パネルとワークスペースを編集する | X | X | |
| 実験をログする | X | X | |
| 実験を削除する | X (チームメンバーは自分が作成した実験のみ削除できます) | X | |
| 実験を停止する | X (チームメンバーは自分が作成した実験のみ停止できます) | X |
Artifacts
以下の表は、特定のチーム全体でのすべてのアーティファクトに適用される権限を示しています。
| 権限 | 閲覧のみ | チームメンバー | チーム管理者 |
|---|---|---|---|
| アーティファクトを閲覧する | X | X | X |
| アーティファクトを作成する | X | X | |
| アーティファクトを削除する | X | X | |
| メタデータを編集する | X | X | |
| エイリアスを編集する | X | X | |
| エイリアスを削除する | X | X | |
| アーティファクトをダウンロードする | X | X |
システム設定 (W&B サーバーのみ)
システム権限を使用して、チームとそのメンバーを作成および管理し、システム設定を調整します。これらの特権により、W&B インスタンスを効果的に管理および維持することができます。
| 権限 | 閲覧のみ | チームメンバー | チーム管理者 | システム管理者 |
|---|---|---|---|---|
| システム設定を設定する | X | |||
| チームを作成/削除する | X |
チームサービスアカウントの振る舞い
- トレーニング環境でチームを設定すると、そのチームからのサービスアカウントを使用して、そのチーム内のプライベートまたはパブリックプロジェクトに run をログすることができます。さらに、環境内に WANDB_USERNAME または WANDB_USER_EMAIL 変数が存在し、参照されるユーザーがそのチームのメンバーである場合、その run をそのユーザーに割り当てることができます。
- トレーニング環境でチームを 設定せず、サービスアカウントを使用する場合、サービスアカウントの親チーム内の指定されたプロジェクトに run をログします。この場合も、環境内に WANDB_USERNAME または WANDB_USER_EMAIL 変数が存在し、参照されるユーザーがサービスアカウントの親チームのメンバーである場合、その run をそのユーザーに割り当てることができます。
- サービスアカウントは親チームとは異なるチーム内のプライベートプロジェクトに run をログすることはできません。サービスアカウントは、プロジェクトが
Openプロジェクトの可視性に設定されている場合にのみプロジェクトにログできます。
チームトライアル
W&B プランの詳細については、価格ページを参照してください。ダッシュボード UI または Export API を利用して、いつでもすべてのデータをダウンロードできます。
プライバシー設定
チーム設定ページで、すべてのチームプロジェクトのプライバシー設定を見ることができます:
app.wandb.ai/teams/your-team-name
高度な設定
安全なストレージコネクタ
チームレベルの安全なストレージコネクタにより、チームは自分たちのクラウドストレージバケットを W&B とともに使用できます。これは、非常に機密性の高いデータまたは厳しいコンプライアンス要件を持つチームにとって、データアクセス制御およびデータ分離を向上させます。安全なストレージコネクタ を参照してください。
4.6 - ストレージを管理する
If you are approaching or exceeding your storage limit, there are multiple paths forward to manage your data. The path that’s best for you will depend on your account type and your current project setup.
ストレージ消費の管理
W&B は、ストレージ消費を最適化するためのさまざまなメソッドを提供しています:
- reference Artifacts を使用して、W&B システム外に保存されたファイルを追跡し、それらを W&B ストレージにアップロードする代わりに使用してください。
- ストレージには外部クラウドストレージバケットを使用します。 (エンタープライズのみ)
データの削除
ストレージ制限以下に留めるためにデータを削除することも選択できます。これを行う方法はいくつかあります:
- アプリの UI を使って対話的にデータを削除します。
- Artifacts に TTL ポリシーを設定 し、自動的に削除されるようにします。
4.7 - システム メトリクス
このページでは、W&B SDKによって追跡されるシステムメトリクスについての詳細情報を提供します。
wandb は、15秒ごとに自動的にシステムメトリクスをログに記録します。CPU
プロセスCPUパーセント (CPU)
プロセスによるCPU使用率を、利用可能なCPU数で正規化したものです。
W&Bは、このメトリクスに cpu タグを割り当てます。
プロセスCPUスレッド
プロセスによって利用されるスレッドの数です。
W&Bは、このメトリクスに proc.cpu.threads タグを割り当てます。
ディスク
デフォルトでは、/ パスの使用状況メトリクスが収集されます。監視するパスを設定するには、次の設定を使用します:
run = wandb.init(
settings=wandb.Settings(
x_stats_disk_paths=("/System/Volumes/Data", "/home", "/mnt/data"),
),
)
ディスク使用率パーセント
指定されたパスに対するシステム全体のディスク使用率をパーセントで表します。
W&Bは、このメトリクスに disk.{path}.usagePercent タグを割り当てます。
ディスク使用量
指定されたパスに対するシステム全体のディスク使用量をギガバイト(GB)で表します。 アクセス可能なパスがサンプリングされ、各パスのディスク使用量(GB)がサンプルに追加されます。
W&Bは、このメトリクスに disk.{path}.usageGB タグを割り当てます。
ディスクイン
システム全体のディスク読み込み量をメガバイト(MB)で示します。最初のサンプルが取られた時点で初期ディスク読み込みバイト数が記録されます。その後のサンプルは、現在の読み込みバイト数と初期値との差を計算します。
W&Bは、このメトリクスに disk.in タグを割り当てます。
ディスクアウト
システム全体のディスク書き込み量をメガバイト(MB)で示します。最初のサンプルが取られた時点で初期ディスク書き込みバイト数が記録されます。その後のサンプルは、現在の書き込みバイト数と初期値との差を計算します。
W&Bは、このメトリクスに disk.out タグを割り当てます。
メモリ
プロセスメモリRSS
プロセスのためのメモリResident Set Size (RSS)をメガバイト(MB)で表します。RSSは、プロセスによって占有されるメモリの一部であり、主記憶(RAM)に保持されるものです。
W&Bは、このメトリクスに proc.memory.rssMB タグを割り当てます。
プロセスメモリパーセント
プロセスのメモリ使用率を、利用可能なメモリ全体に対するパーセントで示します。
W&Bは、このメトリクスに proc.memory.percent タグを割り当てます。
メモリパーセント
システム全体のメモリ使用率を、利用可能なメモリ全体に対するパーセントで表します。
W&Bは、このメトリクスに memory_percent タグを割り当てます。
メモリアベイラブル
システム全体の利用可能なメモリをメガバイト(MB)で示します。
W&Bは、このメトリクスに proc.memory.availableMB タグを割り当てます。
ネットワーク
ネットワーク送信
ネットワーク上で送信されたバイトの合計を示します。 最初にメトリクスが初期化された際に、送信されたバイトの初期値が記録されます。その後のサンプルでは、現在の送信バイト数と初期値との差を計算します。
W&Bは、このメトリクスに network.sent タグを割り当てます。
ネットワーク受信
ネットワーク上で受信されたバイトの合計を示します。 ネットワーク送信と同様に、メトリクスが最初に初期化された際に、受信されたバイトの初期値が記録されます。後続のサンプルでは、現在の受信バイト数と初期値との差を計算します。
W&Bは、このメトリクスに network.recv タグを割り当てます。
NVIDIA GPU
以下に説明するメトリクスに加え、プロセスおよびその子孫が特定のGPUを使用する場合、W&Bは対応するメトリクスを gpu.process.{gpu_index}.{metric_name} としてキャプチャします。
GPUメモリ利用率
各GPUのGPUメモリ利用率をパーセントで表します。
W&Bは、このメトリクスに gpu.{gpu_index}.memory タグを割り当てます。
GPUメモリアロケート
各GPUの全利用可能メモリに対するGPUメモリの割り当てをパーセントで示します。
W&Bは、このメトリクスに gpu.{gpu_index}.memoryAllocated タグを割り当てます。
GPUメモリアロケートバイト
各GPUのGPUメモリ割り当てをバイト単位で指定します。
W&Bは、このメトリクスに gpu.{gpu_index}.memoryAllocatedBytes タグを割り当てます。
GPU利用率
各GPUのGPU利用率をパーセントで示します。
W&Bは、このメトリクスに gpu.{gpu_index}.gpu タグを割り当てます。
GPU温度
各GPUの温度を摂氏で示します。
W&Bは、このメトリクスに gpu.{gpu_index}.temp タグを割り当てます。
GPU電力使用ワット
各GPUの電力使用量をワットで示します。
W&Bは、このメトリクスに gpu.{gpu_index}.powerWatts タグを割り当てます。
GPU電力使用パーセント
各GPUの電力容量に対する電力使用をパーセントで示します。
W&Bは、このメトリクスに gpu.{gpu_index}.powerPercent タグを割り当てます。
GPU SMクロックスピード
GPUのストリーミングマルチプロセッサ (SM) のクロックスピードをMHzで表します。このメトリクスは、計算タスクを担当するGPUコア内のプロセッシング速度を示唆しています。
W&Bは、このメトリクスに gpu.{gpu_index}.smClock タグを割り当てます。
GPUメモリクロックスピード
GPUメモリのクロックスピードをMHzで表します。これは、GPUメモリと処理コア間のデータ転送速度に影響を与えます。
W&Bは、このメトリクスに gpu.{gpu_index}.memoryClock タグを割り当てます。
GPUグラフィックスクロックスピード
GPUでのグラフィックスレンダリング操作の基本クロックスピードをMHzで示します。このメトリクスは、可視化またはレンダリングタスク中のパフォーマンスを反映することが多いです。
W&Bは、このメトリクスに gpu.{gpu_index}.graphicsClock タグを割り当てます。
GPU訂正されたメモリエラー
W&Bが自動的にエラーチェックプロトコルを使用して訂正する、GPU上のメモリエラーのカウントを追跡します。これにより、回復可能なハードウェアの問題を示します。
W&Bは、このメトリクスに gpu.{gpu_index}.correctedMemoryErrors タグを割り当てます。
GPU訂正されていないメモリエラー
W&Bが訂正しない、GPU上のメモリエラーのカウントを追跡します。これにより、処理の信頼性に影響を与える可能性がある回復不可能なエラーを示します。
W&Bは、このメトリクスに gpu.{gpu_index}.unCorrectedMemoryErrors タグを割り当てます。
GPUエンコーダ利用率
GPUのビデオエンコーダの利用率をパーセントで表し、エンコーディングタスク(例えばビデオレンダリング)が実行されているときの負荷を示します。
W&Bは、このメトリクスに gpu.{gpu_index}.encoderUtilization タグを割り当てます。
AMD GPU
W&Bは、AMDが提供する rocm-smi ツールの出力からメトリクスを抽出します(rocm-smi -a --json)。
ROCm 6.x (最新) および 5.x フォーマットがサポートされています。AMD ROCm ドキュメンテーションでROCmフォーマットの詳細を確認できます。新しいフォーマットにはより詳細が含まれています。
AMD GPU利用率
各AMD GPUデバイスのGPU利用率をパーセントで表します。
W&Bは、このメトリクスに gpu.{gpu_index}.gpu タグを割り当てます。
AMD GPUメモリアロケート
各AMD GPUデバイスの全利用可能メモリに対するGPUメモリの割り当てをパーセントで示します。
W&Bは、このメトリクスに gpu.{gpu_index}.memoryAllocated タグを割り当てます。
AMD GPU温度
各AMD GPUデバイスの温度を摂氏で示します。
W&Bは、このメトリクスに gpu.{gpu_index}.temp タグを割り当てます。
AMD GPU電力使用ワット
各AMD GPUデバイスの電力使用量をワットで示します。
W&Bは、このメトリクスに gpu.{gpu_index}.powerWatts タグを割り当てます。
AMD GPU電力使用パーセント
各AMD GPUデバイスの電力容量に対する電力使用をパーセントで示します。
W&Bは、このメトリクスに gpu.{gpu_index}.powerPercent をこのメトリクスに割り当てます。
Apple ARM Mac GPU
Apple GPU利用率
特にARM Mac上のApple GPUデバイスにおけるGPU利用率をパーセントで示します。
W&Bは、このメトリクスに gpu.0.gpu タグを割り当てます。
Apple GPUメモリアロケート
ARM Mac上のApple GPUデバイスにおける全利用可能メモリに対するGPUメモリの割り当てをパーセントで示します。
W&Bは、このメトリクスに gpu.0.memoryAllocated タグを割り当てます。
Apple GPU温度
ARM Mac上のApple GPUデバイスの温度を摂氏で示します。
W&Bは、このメトリクスに gpu.0.temp タグを割り当てます。
Apple GPU電力使用ワット
ARM Mac上のApple GPUデバイスの電力使用量をワットで示します。
W&Bは、このメトリクスに gpu.0.powerWatts タグを割り当てます。
Apple GPU電力使用パーセント
ARM Mac上のApple GPUデバイスの電力容量に対する電力使用をパーセントで示します。
W&Bは、このメトリクスに gpu.0.powerPercent タグを割り当てます。
Graphcore IPU
Graphcore IPU(インテリジェンスポロセッシングユニット)は、機械知能タスクのために特別に設計されたユニークなハードウェアアクセラレータです。
IPUデバイスメトリクス
これらのメトリクスは、特定のIPUデバイスのさまざまな統計を表します。各メトリクスには、デバイスID(device_id)とメトリクスキー(metric_key)があり、それを識別します。W&Bは、このメトリクスに ipu.{device_id}.{metric_key} タグを割り当てます。
メトリクスは、Graphcore の gcipuinfo バイナリと相互作用する専用の gcipuinfo ライブラリを使用して抽出されます。sample メソッドは、プロセスID(pid)に関連する各IPUデバイスのこれらのメトリクスを取得します。時間の経過とともに変化するメトリクスまたはデバイスのメトリクスが最初に取得されたときにのみログに記録され、冗長なデータのログを回避します。
各メトリクスに対して、メトリクスの値をその生の文字列表現から抽出するために parse_metric メソッドが使用されます。メトリクスは、複数のサンプルを通じて aggregate メソッドを使用して集計されます。
利用可能なメトリクスとその単位は次のとおりです:
- 平均ボード温度 (
average board temp (C)): IPUボードの温度を摂氏で示します。 - 平均ダイ温度 (
average die temp (C)): IPUダイの温度を摂氏で示します。 - クロックスピード (
clock (MHz)): IPUのクロックスピードをMHzで示します。 - IPU電力 (
ipu power (W)): IPUの電力消費量をワットで示します。 - IPU利用率 (
ipu utilisation (%)): IPUの利用率をパーセントで示します。 - IPUセッション利用率 (
ipu utilisation (session) (%)): 現在のセッションに特化したIPU利用率をパーセントで示します。 - データリンクスピード (
speed (GT/s)): データ転送速度をGiga-transfers毎秒で示します。
Google クラウド TPU
テンソルプロセッシングユニット(TPU)は、Googleによって開発されたASIC(アプリケーション特定統合回路)で、機械学習のワークロードを加速するために使用されます。
TPUメモリ使用量
各TPUコアあたりの現在の高帯域幅メモリ使用量をバイト単位で示します。
W&Bは、このメトリクスに tpu.{tpu_index}.memoryUsageBytes タグを割り当てます。
TPUメモリ使用率
各TPUコアあたりの現在の高帯域幅メモリ使用率をパーセントで示します。
W&Bは、このメトリクスに tpu.{tpu_index}.memoryUsageBytes タグを割り当てます。
TPUデューティサイクル
TPUデバイスごとのTensorCoreデューティサイクルのパーセントです。サンプル期間中、アクセラレータTensorCoreが積極的に処理していた時間の割合を追跡します。大きな値は、より良いTensorCoreの利用率を意味します。
W&Bは、このメトリクスに tpu.{tpu_index}.dutyCycle タグを割り当てます。
AWS Trainium
AWS Trainiumは、機械学習ワークロードの高速化に焦点を当てた、AWSが提供する特殊なハードウェアプラットフォームです。AWSの neuron-monitor ツールを使用して、AWS Trainiumメトリクスをキャプチャします。
Trainiumニューロンコア利用率
各ニューロンコアごとの利用率をパーセントで示します。
W&Bは、このメトリクスに trn.{core_index}.neuroncore_utilization タグを割り当てます。
Trainiumホストメモリ使用量、合計
ホストの総メモリ消費量をバイト単位で示します。
W&Bは、このメトリクスに trn.host_total_memory_usage タグを割り当てます。
Trainiumニューロンデバイス総メモリ使用量
ニューロンデバイス上の総メモリ使用量をバイト単位で示します。
W&Bは、このメトリクスに trn.neuron_device_total_memory_usage) タグを割り当てます。
Trainiumホストメモリ使用量の内訳:
以下はホストのメモリ使用量の内訳です:
- アプリケーションメモリ (
trn.host_total_memory_usage.application_memory): アプリケーションによって使用されるメモリ。 - 定数 (
trn.host_total_memory_usage.constants): 定数に使用されるメモリ。 - DMAバッファ (
trn.host_total_memory_usage.dma_buffers): ダイレクトメモリアクセスバッファに使用されるメモリ。 - テンソル (
trn.host_total_memory_usage.tensors): テンソルに使用されるメモリ。
Trainiumニューロンコアメモリ使用量の内訳
各ニューロンコアのメモリ使用に関する詳細情報:
- 定数 (
trn.{core_index}.neuroncore_memory_usage.constants) - モデルコード (
trn.{core_index}.neuroncore_memory_usage.model_code) - モデル共有スクラッチパッド (
trn.{core_index}.neuroncore_memory_usage.model_shared_scratchpad) - ランタイムメモリ (
trn.{core_index}.neuroncore_memory_usage.runtime_memory) - テンソル (
trn.{core_index}.neuroncore_memory_usage.tensors)
OpenMetrics
カスタム正規表現ベースのメトリックフィルタを適用できるOpenMetrics / Prometheus互換データをエクスポートする外部エンドポイントからメトリクスをキャプチャし、ログに記録します。
特定のケースで NVIDIA DCGM-Exporter を使用してGPUクラスターのパフォーマンスを監視する方法の詳細な例については、このレポートを参照してください。
4.8 - 匿名モード
コードを誰でも簡単に実行できるように公開していますか? 匿名モードを使用して、誰かがあなたのコードを実行し、W&B ダッシュボードを見て、W&B アカウントを作成することなく結果を視覚化できるようにします。
結果が匿名モードでログに記録されるようにするには、次のようにします:
import wandb
wandb.init(anonymous="allow")
例えば、次のコードスニペットは、W&B でアーティファクトを作成し、ログに記録する方法を示しています:
import wandb
run = wandb.init(anonymous="allow")
artifact = wandb.Artifact(name="art1", type="foo")
artifact.add_file(local_path="path/to/file")
run.log_artifact(artifact)
run.finish()
例のノートブックを試してみて、匿名モードがどのように機能するかを確認してください。