これは、このセクションの複数ページの印刷可能なビューです。 印刷するには、ここをクリックしてください.
ローンンチ
- 1: チュートリアル: W&B ローンンチ 基本事項
- 2: ローンチの用語と概念
- 3: Launch を設定する
- 3.1: ローンンチエージェントを設定する
- 3.2: ローンンチキューを設定する
- 3.3: チュートリアル: Docker を使用して W&B ローンンチを設定する
- 3.4: チュートリアル: Kubernetes上でW&B ローンンチ を設定する
- 3.5: チュートリアル: SageMaker で W&B Launch を設定する
- 3.6: チュートリアル: Vertex AI で W&B Launch を設定する
- 4: Launch FAQ
- 4.1: `wandb launch -d` または `wandb job create image` が、レジストリからプルせずに全体のDockerアーティファクトをアップロードしていますか?
- 4.2: Dockerキュー内の複数のジョブが同じアーティファクトをダウンロードする場合、キャッシュは使用されますか、それとも毎回のrunで再ダウンロードされますか?
- 4.3: Kubernetes でエージェントにはどのような権限が必要ですか?
- 4.4: Launch で "permission denied" エラーを修正するにはどうすればよいですか?
- 4.5: W&B Launch はどのようにしてイメージを作成しますか?
- 4.6: W&B Launch を GPU 上での Tensorflow と連携させるにはどうすればよいですか?
- 4.7: W&B に Dockerfile を指定して、Docker イメージを作成してもらうことはできますか?
- 4.8: アクセラレータベースイメージにはどのような要件がありますか?
- 4.9: ターゲット環境で Launch は計算リソースを自動でプロビジョニング (そしてスピンダウン) できますか?
- 4.10: ローンチは並列化をサポートしていますか?ジョブによって消費されるリソースを制限する方法はありますか?
- 4.11: ローンチを効果的に使用するためのベストプラクティスはありますか?
- 4.12: キューにプッシュできる人をどのように制御しますか?
- 4.13: クリックするのが嫌いです - UI を通さずに Launch を使用できますか?
- 4.14: ジョブやオートメーションのためのシークレットを指定することはできますか?例えば、ユーザーに直接見せたくないAPIキーのようなものですか?
- 4.15: 管理者はどのユーザーが修正アクセスを持つかをどのように制限できますか?
- 4.16: 私が W&B にコンテナを作成してほしくない場合でも、Launch を使用できますか?
- 5: W&B Launch を使用してスイープを作成する
- 6: ローンンチ インテグレーション ガイド
- 6.1: Dagster
- 6.2: Minikube でシングルノード GPU クラスターを起動する
- 6.3: NVIDIA NeMo 推論マイクロサービスデプロイジョブ
- 6.4: Volcano でマルチノードジョブをローンチする
- 7: ジョブを作成してデプロイする
- 7.1: ローンンチ ジョブを表示する
- 7.2: ローンンチキューを監視する
- 7.3: ローンンチジョブを作成する
- 7.4: キューにジョブを追加
- 7.5: ジョブ入力を管理する
1 - チュートリアル: W&B ローンンチ 基本事項
What is Launch?
W&B Launch を使用して、トレーニング Runs をデスクトップから Amazon SageMaker、Kubernetes などの計算リソースに簡単にスケールできます。W&B Launch の設定が完了すると、トレーニング スクリプト、モデルの評価スイート、プロダクション推論用のモデルの準備などを、数回のクリックとコマンドで迅速に実行できます。
仕組み
Launch は、launch jobs、queues、agents の3つの基本的なコンポーネントで構成されています。
launch jobは、ML ワークフローでタスクを設定および実行するためのブループリントです。Launch Job を作成したら、launch queue に追加できます。Launch Queue は、Amazon SageMaker や Kubernetes クラスターなどの特定のコンピュートターゲットリソースに Jobs を構成して送信できる先入れ先出し (FIFO) のキューです。
ジョブがキューに追加されると、launch agents がそのキューをポーリングし、キューによってターゲットとされたシステムでジョブを実行します。
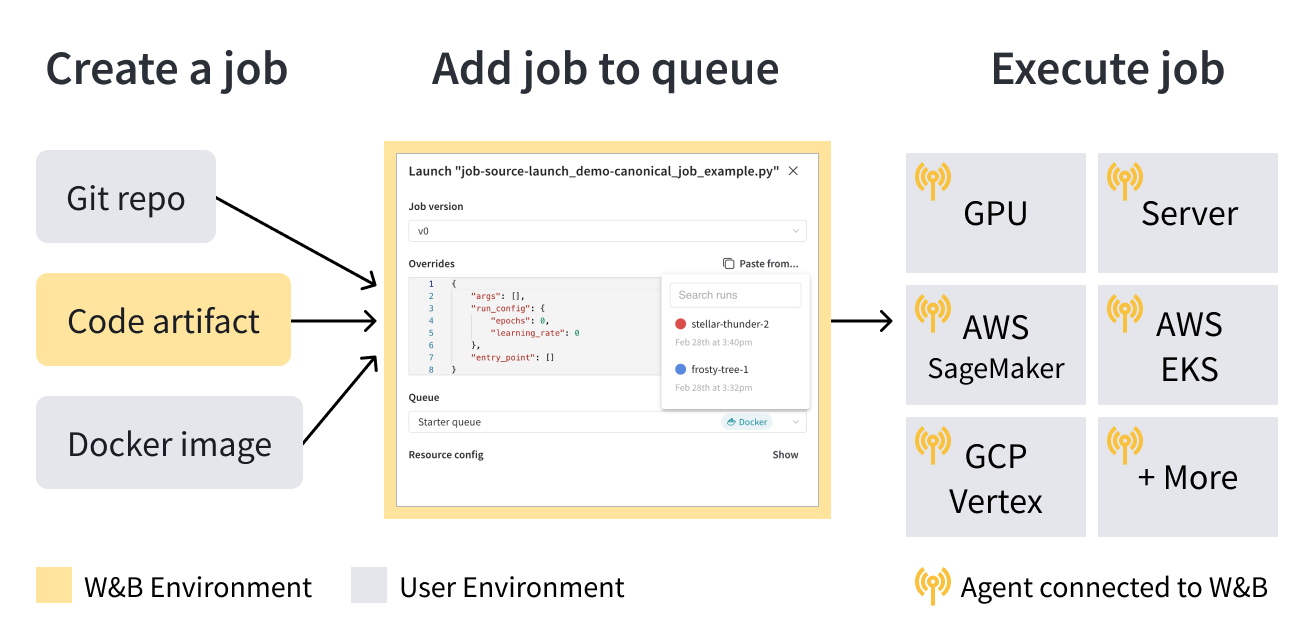
ユースケースに基づいて、あなた自身またはチームの誰かが選択した compute resource target(たとえば、Amazon SageMaker)に従って Launch Queue を設定し、独自のインフラストラクチャーに Launch エージェントをデプロイします。
Launch Jobs、キューの仕組み、Launch エージェント、および W&B Launch の動作に関する追加情報については、Terms and Concepts ページを参照してください。
開始方法
ユースケースに応じて、W&B Launch を始めるために次のリソースを確認してください。
- 初めて W&B Launch を使用する場合は、Walkthrough ガイドを閲覧することをお勧めします。
- W&B Launch の設定方法を学びます。
- Launch Job を作成します。
- Triton へのデプロイや LLM の評価などの一般的なタスクのテンプレートについては、W&B Launch の公開ジョブ GitHub リポジトリ をチェックしてください。
- このリポジトリから作成された Launch Job は、この公開された
wandb/jobsproject W&B プロジェクトで閲覧できます。
- このリポジトリから作成された Launch Job は、この公開された
Walkthrough
このページでは、W&B Launch ワークフローの基本を案内します。
Prerequisites
開始する前に、次の前提条件が満たされていることを確認してください。
- https://wandb.ai/site でアカウントに登録し、その後 W&B アカウントにログインします。
- この Walkthrough には、動作する Docker CLI とエンジン付きのマシンへのターミナル アクセスが必要です。詳細については Docker インストールガイド を参照してください。
- W&B Python SDK バージョン
0.17.1以上をインストールします:
pip install wandb>=0.17.1
- ターミナル内で
wandb loginを実行するか、WANDB_API_KEY環境変数を設定して W&B を認証します。
ターミナル内で以下を実行します:
```bash
wandb login
```
```bash
WANDB_API_KEY=<your-api-key>
```
`<your-api-key>` をあなたの W&B API キーに置き換えます。
Create a launch job
Docker イメージ、git リポジトリから、またはローカルソースコードから3つの方法のいずれかで Launch Job を作成します。
W&B にメッセージをログする事前に作成されたコンテナを実行するには、ターミナルを開いて次のコマンドを実行します。
wandb launch --docker-image wandb/job_hello_world:main --project launch-quickstart
前述のコマンドは、コンテナイメージ wandb/job_hello_world:main をダウンロードして実行します。
Launch は、wandb でログされたすべての情報を launch-quickstart プロジェクトに報告するようにコンテナを設定します。コンテナは W&B にメッセージをログし、新しく作成された Run へのリンクを W&B に表示します。リンクをクリックして、W&B UI で Run を確認します。
同じ hello-world ジョブを W&B Launch jobs リポジトリ内のソースコード から起動するには、次のコマンドを実行します。
wandb launch --uri https://github.com/wandb/launch-jobs.git \\
--job-name hello-world-git --project launch-quickstart \\
--build-context jobs/hello_world --dockerfile Dockerfile.wandb \\
--entry-point "python job.py"
このコマンドは次のことを行います。
- W&B Launch jobs リポジトリ を一時ディレクトリにクローンします。
- hello プロジェクト内に hello-world-git という名前のジョブを作成します。このジョブは、コードの実行に使用される正確なソースコードと設定を追跡します。
jobs/hello_worldディレクトリとDockerfile.wandbからコンテナイメージをビルドします。- コンテナを開始し、
job.pyPython スクリプトを実行します。
コンソール出力には、イメージのビルドと実行が表示されます。コンテナの出力は、前の例とほぼ同じである必要があります。
git リポジトリにバージョン管理されていないコードは、--uri 引数にローカルディレクトリパスを指定することで起動できます。
空のディレクトリを作成し、次の内容を持つ train.py という名前の Python スクリプトを追加します。
import wandb
with wandb.init() as run:
run.log({"hello": "world"})
次の内容で requirements.txt ファイルを追加します。
wandb>=0.17.1
ディレクトリ内から次のコマンドを実行します。
wandb launch --uri . --job-name hello-world-code --project launch-quickstart --entry-point "python train.py"
このコマンドは次のことを行います。
- 現在のディレクトリの内容を W&B に Code Artifact としてログします。
- launch-quickstart プロジェクトに hello-world-code という名前のジョブを作成します。
train.pyとrequirements.txtを基礎イメージにコピーしてコンテナイメージをビルドし、pip installで要件をインストールします。- コンテナを開始して
python train.pyを実行します。
Create a queue
Launch は、Teams が共有計算を中心にワークフローを構築するのを支援するように設計されています。これまでの例では、wandb launch コマンドがローカルマシンでコンテナを同期的に実行しました。Launch キューとエージェントを使用すると、共有リソースでジョブを非同期に実行し、優先順位付けやハイパーパラメータ最適化などの高度な機能を実現できます。基本的なキューを作成するには、次の手順に従います。
- wandb.ai/launch にアクセスし、Create a queue ボタンをクリックします。
- キューを関連付ける Entity を選択します。
- Queue name を入力します。
- Resource として Docker を選択します。
- 今のところ、Configuration は空白のままにします。
- Create queue をクリックします :rocket:
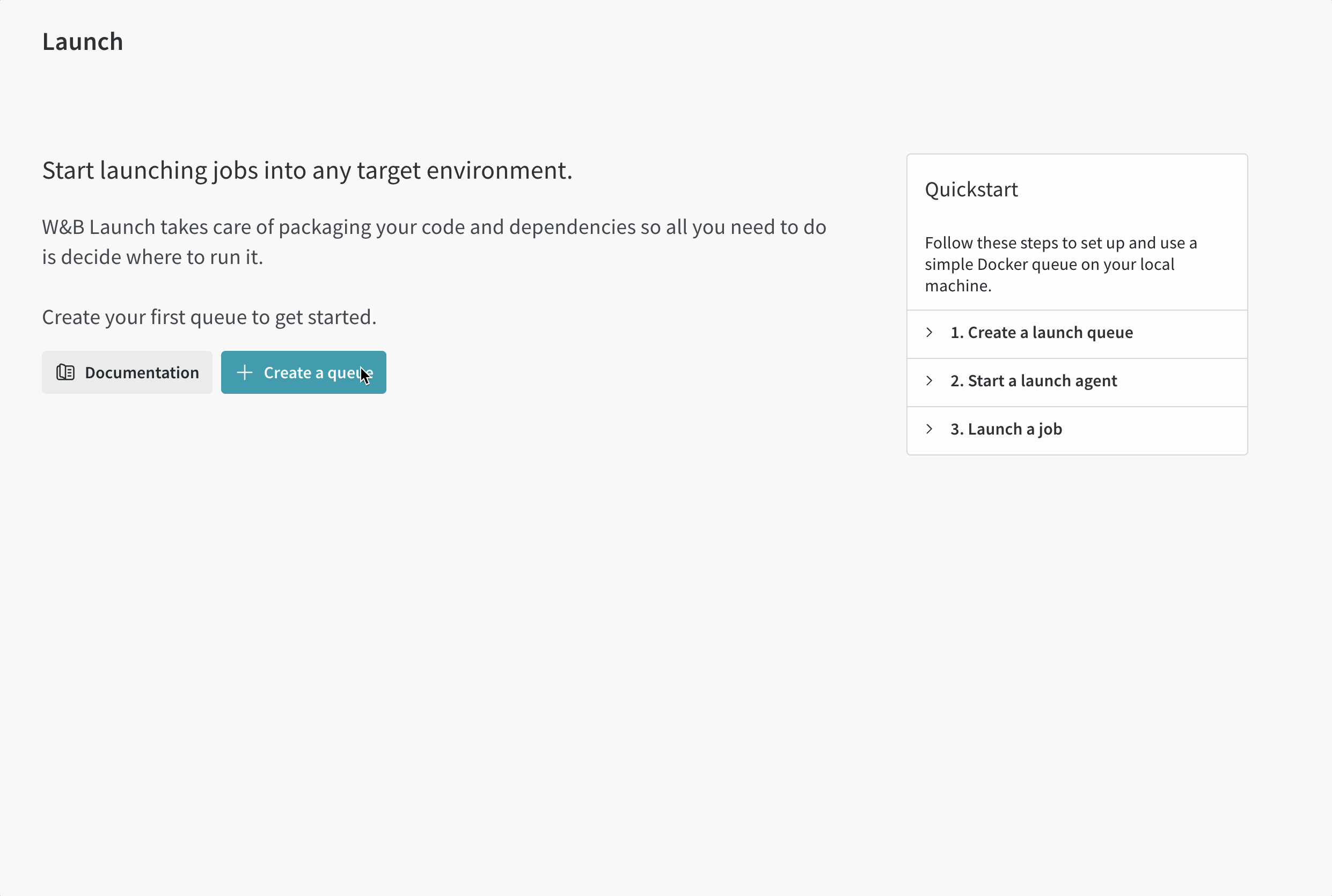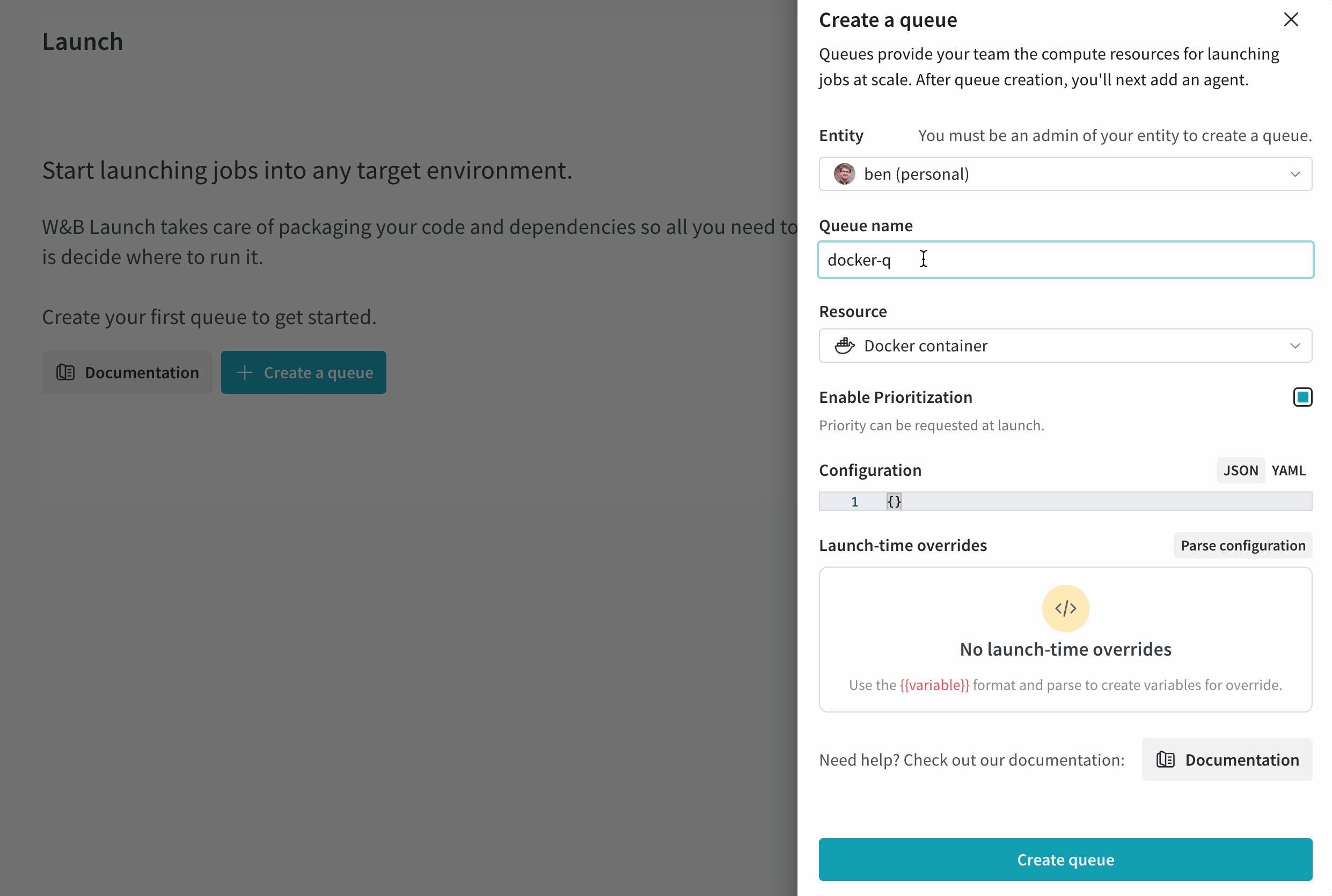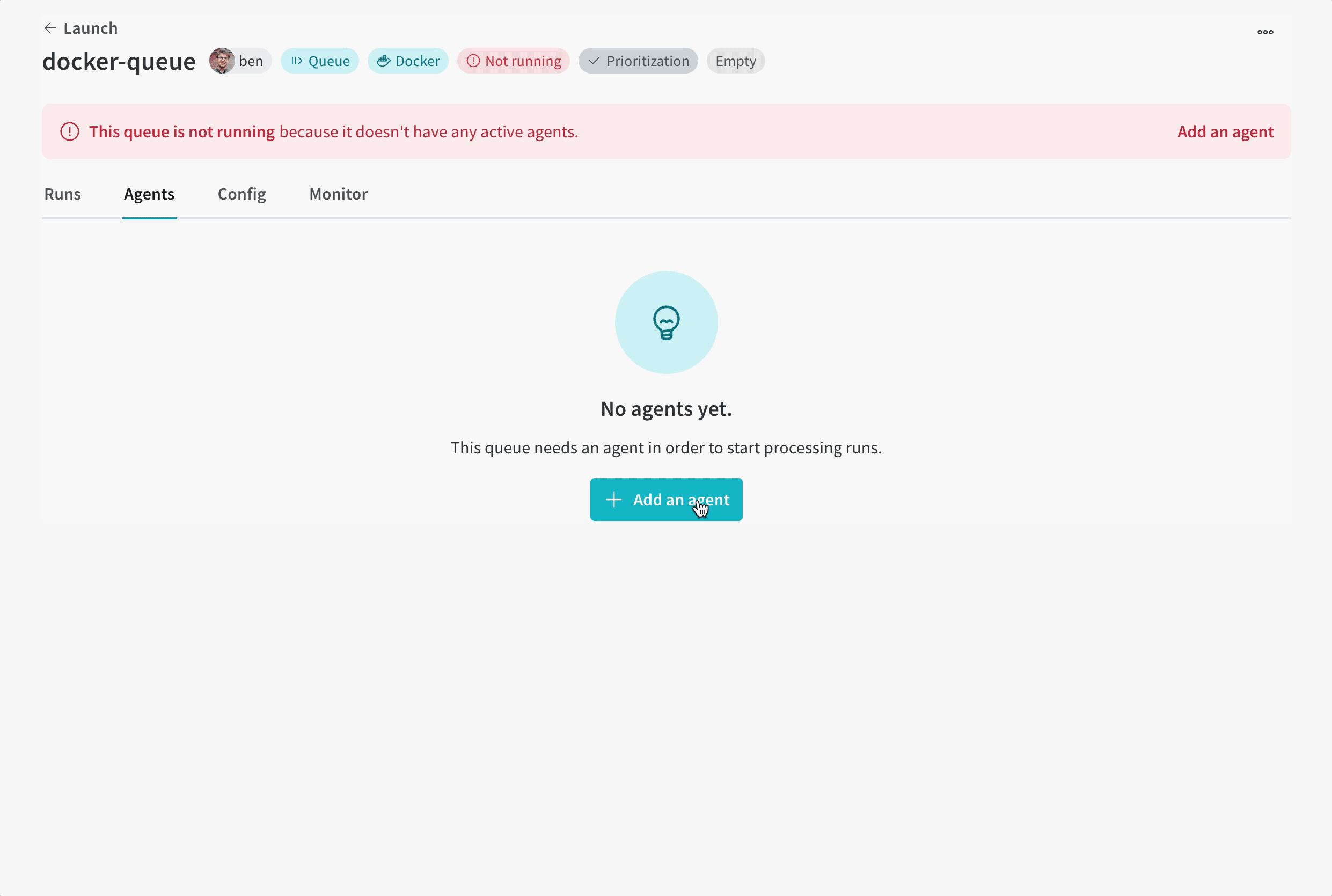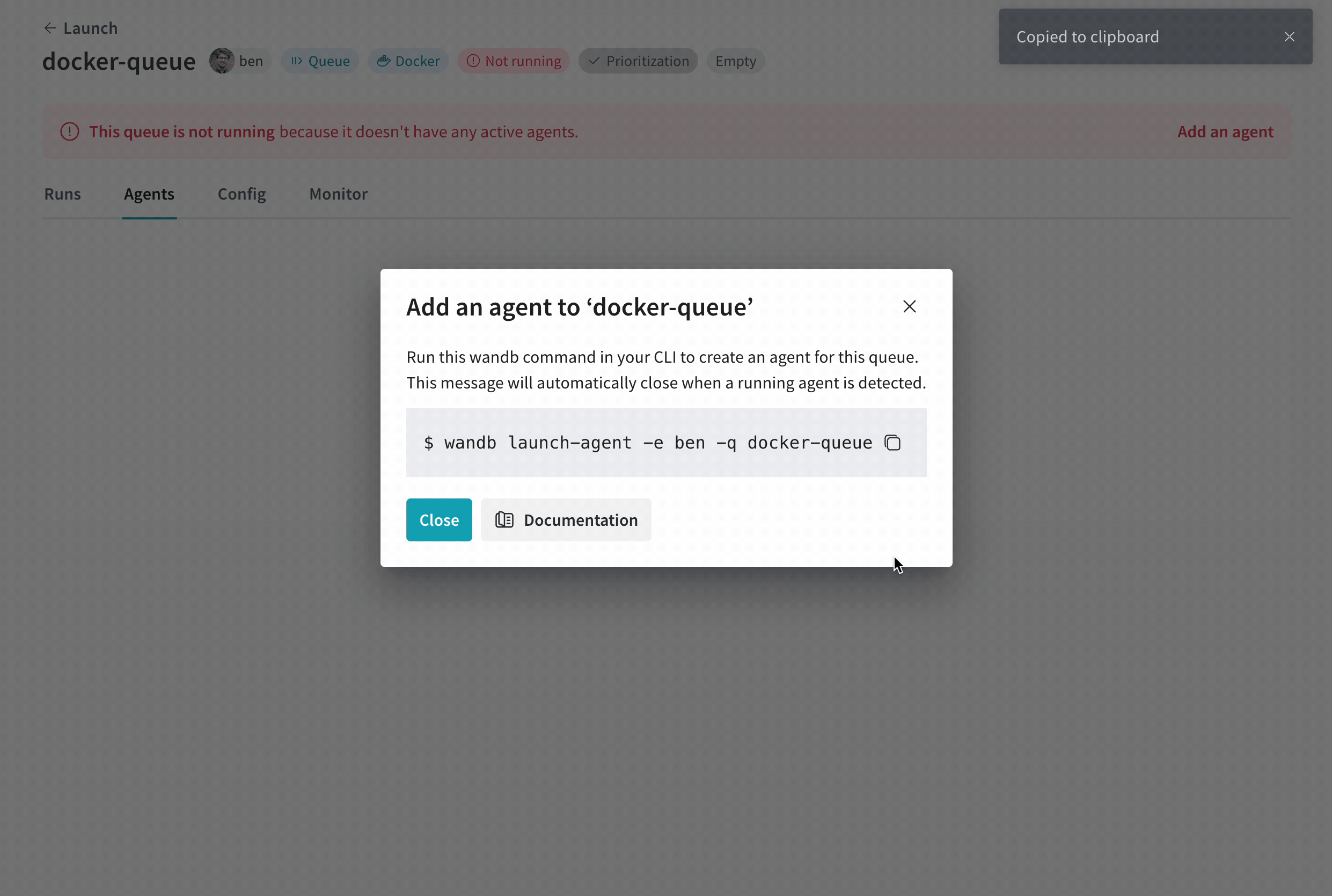
ボタンをクリックすると、ブラウザはキュー表示の Agents タブにリダイレクトされます。キューにエージェントがポーリングされるまで、キューは Not active 状態のままです。
高度なキューの設定オプションについては、advanced queue setup ページ を参照してください。
Connect an agent to the queue
キューにポーリング エージェントがない場合、キュー ビューには画面上部の赤いバナーに Add an agent ボタンが表示されます。ボタンをクリックしてコマンドをコピーし、エージェントを実行します。コマンドは次のようになります。
wandb launch-agent --queue <queue-name> --entity <entity-name>
コマンドをターミナルで実行してエージェントを起動します。エージェントは指定されたキューをポーリングして、実行するジョブを収集します。受信後、エージェントはジョブのためにコンテナイメージをダウンロードまたはビルドして実行します。wandb launch コマンドがローカルで実行されたかのように。
Launch ページ に戻って、キューが Active として表示されていることを確認します。
Submit a job to the queue
W&B アカウントの launch-quickstart プロジェクトに移動し、画面の左側のナビゲーションから Jobs タブを開きます。
Jobs ページには、以前に実行された Runs から作成された W&B Jobs のリストが表示されます。Launch Job をクリックすると、ソースコード、依存関係、およびジョブから作成されたすべての Runs を表示できます。この Walkthrough を完了すると、リストに3つのジョブが表示されるはずです。
新しいジョブのいずれかを選択し、それをキューに送信する手順は次のとおりです。
- Launch ボタンをクリックして、ジョブをキューに送信します。 Launch ドロワーが表示されます。
- 先ほど作成した Queue を選択し、Launch をクリックします。
これにより、ジョブがキューに送信されます。このキューをポーリングするエージェントがジョブを取得し、実行します。ジョブの進行状況は、W&B UI からやターミナル内のエージェントの出力を調査することで監視できます。
wandb launch コマンドは --queue 引数を指定することで Jobs をキューに直接プッシュできます。たとえば、hello-world コンテナジョブをキューに送信するには、次のコマンドを実行します。
wandb launch --docker-image wandb/job_hello_world:main --project launch-quickstart --queue <queue-name>
2 - ローンチの用語と概念
W&B ローンンチを使用すると、ジョブをキューに追加して run を作成します。ジョブは W&B と組み合わせた Python スクリプトです。キューは、ターゲットリソースで実行するジョブのリストを保持します。エージェントはキューからジョブを取り出し、ターゲットリソース上でジョブを実行します。W&B はローンンチジョブを W&B が run をトラッキングするのと同様にトラッキングします。
ローンンチジョブ
ローンンチジョブは、完了するタスクを表す特定の種類の W&B Artifact です。例えば、一般的なローンンチジョブには、モデルのトレーニングやモデルの評価トリガーがあります。ジョブ定義には以下が含まれます:
- Pythonコードやその他のファイルアセット、少なくとも1つの実行可能なエントリポイントを含む。
- 入力(設定パラメータ)および出力(ログされたメトリクス)に関する情報。
- 環境に関する情報。(例えば、
requirements.txt、ベースのDockerfile)。
ジョブ定義には3つの主要な種類があります:
| Job types | Definition | How to run this job type |
|---|---|---|
| アーティファクトベース(またはコードベース)のジョブ | コードや他のアセットが W&B アーティファクトとして保存される。 | アーティファクトベースのジョブを実行するには、ローンンチエージェントがビルダーで設定されている必要があります。 |
| Git ベースのジョブ | コードや他のアセットが git リポジトリの特定のコミット、ブランチ、またはタグからクローンされる。 | Git ベースのジョブを実行するには、ローンンチエージェントがビルダーと git リポジトリの資格情報で設定されている必要があります。 |
| イメージベースのジョブ | コードや他のアセットが Docker イメージに組み込まれている。 | イメージベースのジョブを実行するには、ローンンチエージェントがイメージリポジトリの資格情報で設定されている必要があるかもしれません。 |
wandb.init を呼び出して正常に完了する必要があります。これにより、W&B ワークスペース内でトラッキング目的の run が作成されます。作成したジョブは、プロジェクトワークスペースの Jobs タブの W&B アプリで見つけることができます。そこから、ジョブを設定して様々な ターゲットリソース で実行するための launch queue に送信できます。
Launch queue
ローンンチキューは、特定のターゲットリソースで実行するジョブの順序付けられたリストです。ローンンチキューは先入れ先出し (FIFO) です。持てるキューの数に実質的な制限はありませんが、1 つのターゲットリソースごとに 1 つのキューが理想的です。ジョブは W&B アプリ UI、W&B CLI または Python SDK を使用してエンキューできます。1 つまたは複数のローンンチエージェントを設定して、キューからアイテムを引き出し、それをキューのターゲットリソースで実行することができます。
Target resources
ローンンチキューがジョブを実行するために設定された計算環境をターゲットリソースと呼びます。
W&B ローンンチは以下のターゲットリソースをサポートしています:
各ターゲットリソースは、リソース設定と呼ばれる異なる設定パラメータを受け入れます。リソース設定は各ローンンチキューによって定義されるデフォルト値を持ちますが、各ジョブによって個別に上書きすることができます。各ターゲットリソースの詳細については、ドキュメントを参照してください。
Launch agent
ローンンチエージェントは、ジョブを実行するためにローンンチキューを定期的にチェックする軽量で持続的なプログラムです。ローンンチエージェントがジョブを受け取ると、まずジョブ定義からイメージをビルドまたはプルし、それをターゲットリソースで実行します。
1 つのエージェントは複数のキューをポーリングすることができますが、エージェントはポーリングするキューのバックするターゲットリソースすべてをサポートするように正しく設定されている必要があります。
Launch agent environment
エージェント環境は、ローンンチエージェントが実行され、ジョブのポーリングを行う環境です。
3 - Launch を設定する
このページでは、W&B Launch を設定するために必要な上位レベルの手順について説明しています。
- キューのセットアップ: キューはFIFOであり、キュー設定を持っています。キューの設定は、ジョブがどこでどのように対象リソースで実行されるかを制御します。
- エージェントのセットアップ: エージェントはあなたのマシン/インフラストラクチャー上で実行され、1つ以上のキューからローンチジョブをポールします。ジョブがプルされると、エージェントはイメージがビルドされ、利用可能であることを確認します。その後、エージェントはジョブを対象リソースに送信します。
キューのセットアップ
Launch キューは、特定の対象リソースとそのリソースに特有の追加設定を指すように設定する必要があります。例えば、Kubernetes クラスターを指すローンチキューは、環境変数を含めたり、カスタムネームスペースのローンチキュー設定を設定したりします。キューを作成する際には、使用したい対象リソースとそのリソースに使用する設定の両方を指定します。
エージェントがキューからジョブを受け取ると、キュー設定も受け取ります。エージェントがジョブを対象リソースに送信する際には、キュー設定とジョブ自体のオーバーライドを含めます。例えば、ジョブ設定を使用して、特定のジョブインスタンスのみの Amazon SageMaker インスタンスタイプを指定することができます。この場合、エンドユーザーインターフェースとして queue config templates を使用することが一般的です。
キューの作成
- wandb.ai/launch で Launch App へ移動します。
- 画面の右上にあるcreate queueボタンをクリックします。
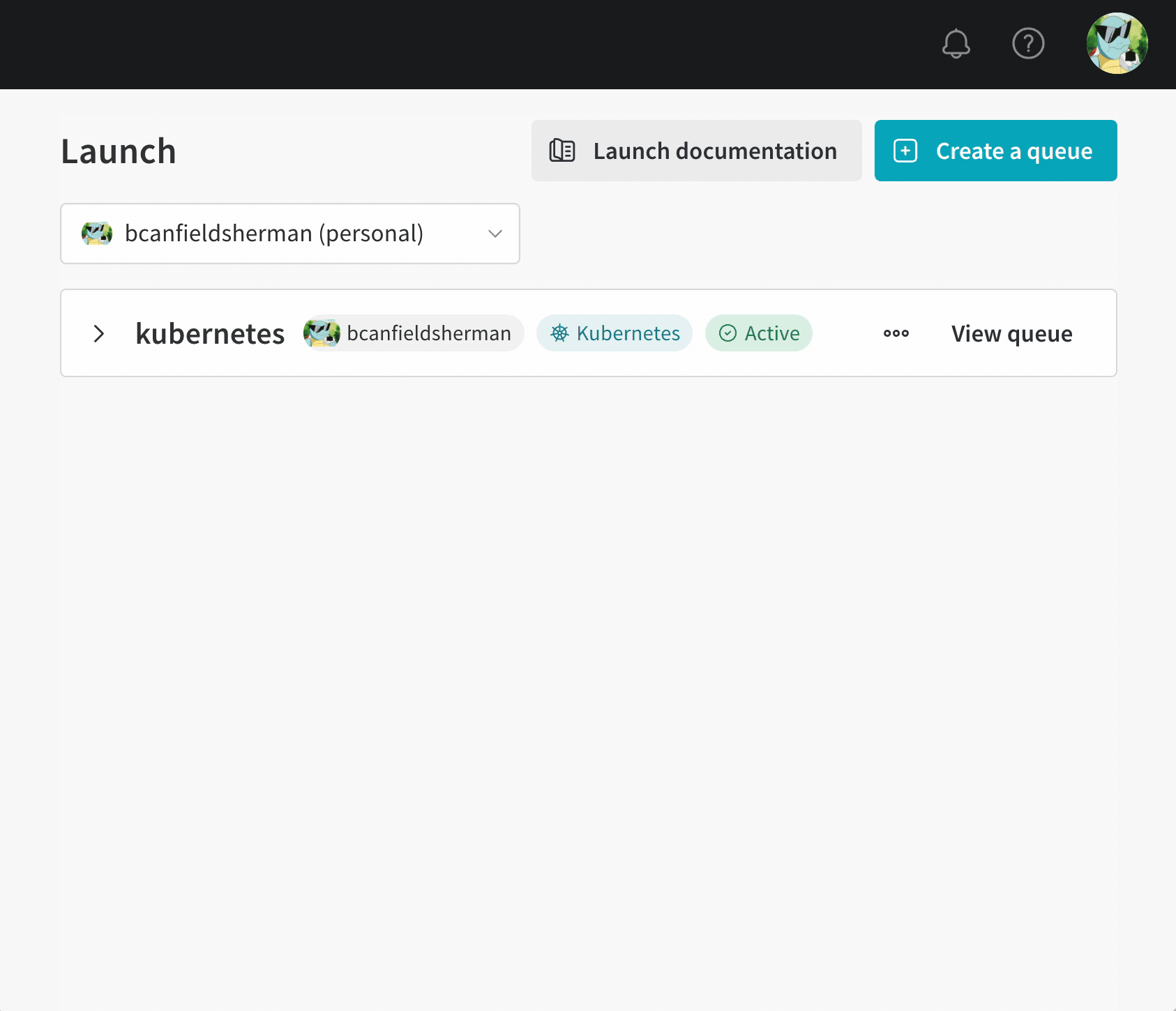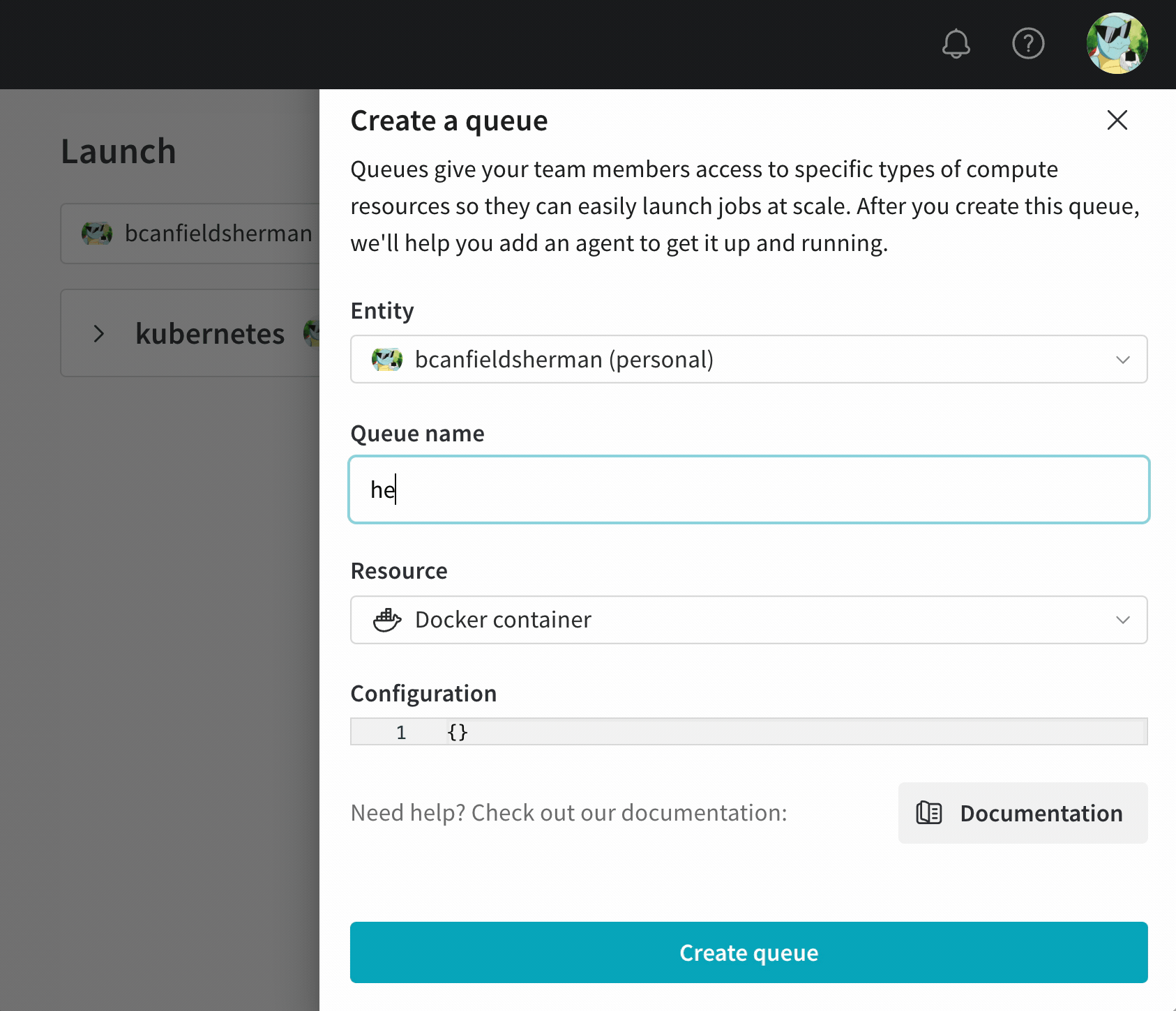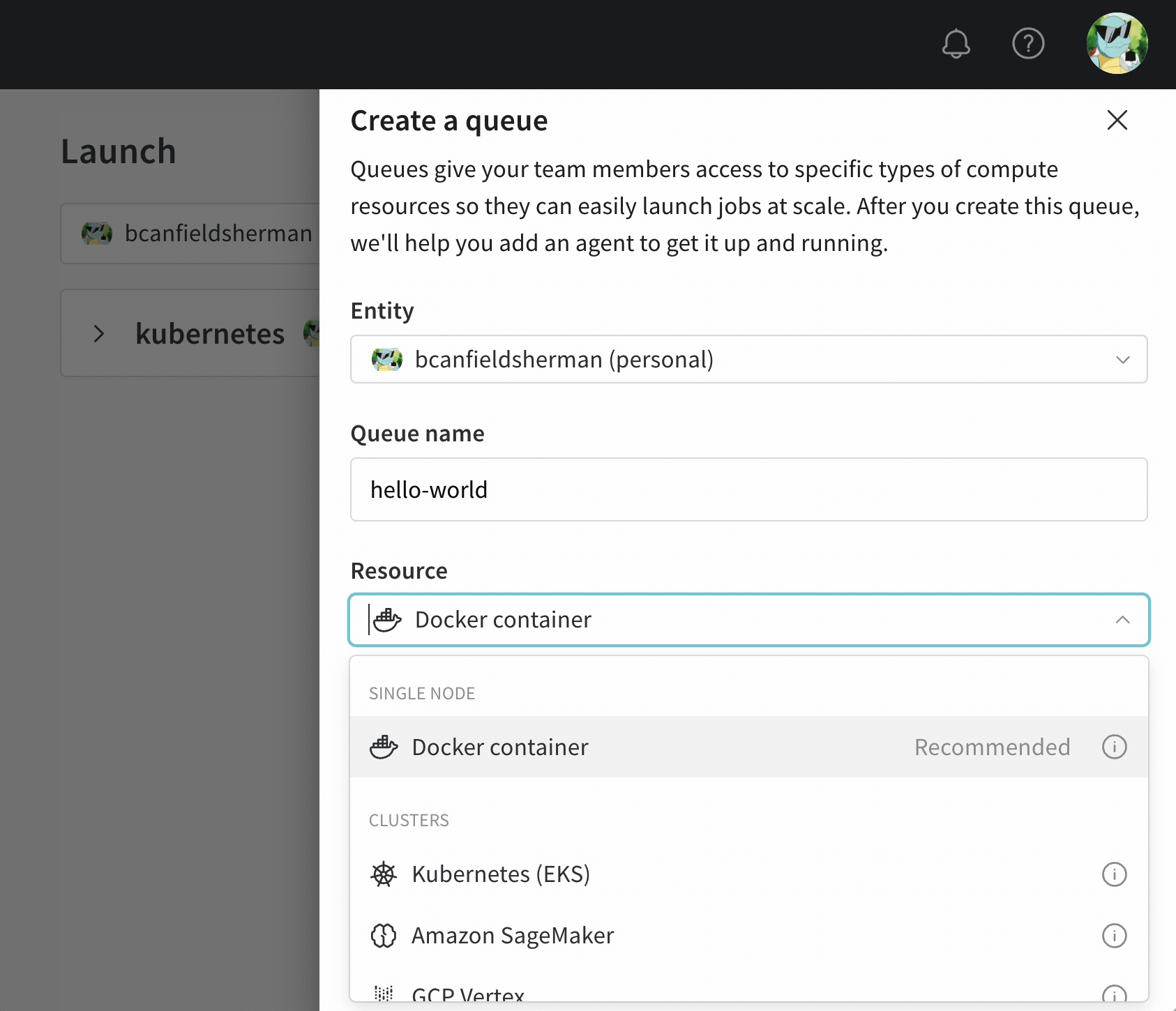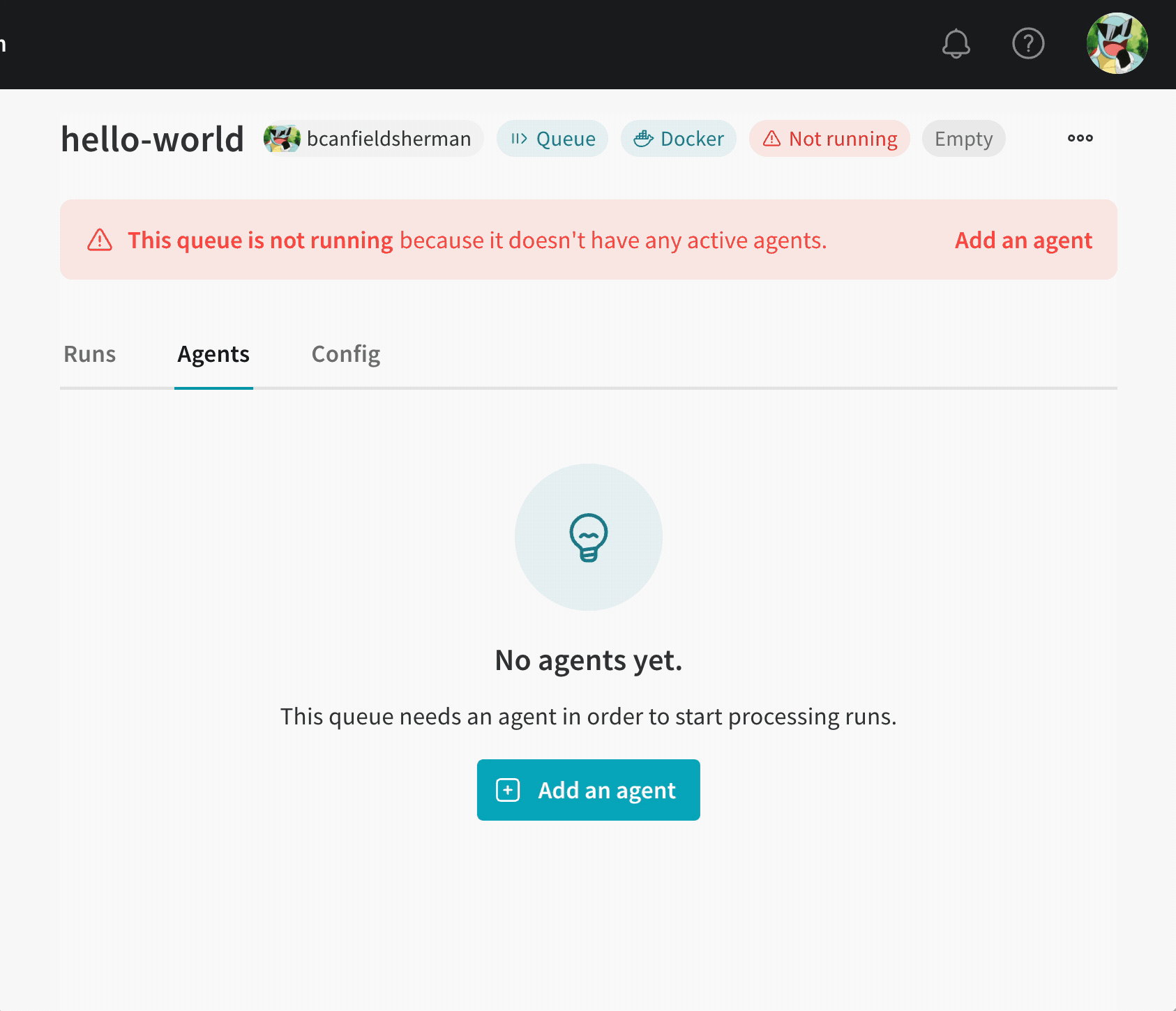
- Entity のドロップダウンメニューから、そのキューが所属する エンティティ を選択します。
- Queue フィールドにキューの名前を入力します。
- Resource のドロップダウンから、ジョブをこのキューに追加する際に使用する計算リソースを選択します。
- このキューのPrioritizationを許可するかどうかを選択します。優先度が有効になっている場合、チームのユーザーは起動ジョブをエンキューする際にその優先度を定義できます。優先度が高いジョブは、優先度が低いジョブより先に実行されます。
- Configuration フィールドに、JSON または YAML 形式でリソース設定を提供します。設定ドキュメントの構造とセマンティクスは、キューが指すリソースタイプに依存します。詳細については、対象リソースに関する専用の設定ページを参照してください。
ローンチエージェントのセットアップ
ローンチエージェントは、ジョブのための1つ以上のローンチキューをポールする長時間実行されるプロセスです。ローンチエージェントは、FIFO 順序または優先順序でジョブをデキューし、ポールするキューに依存します。エージェントがキューからジョブをデキューすると、そのジョブのためにイメージをオプションでビルドします。その後、エージェントはジョブをキュー設定で指定された設定オプションとともに対象リソースに送信します。
W&B は、特定のユーザーの APIキー ではなく、サービスアカウントの APIキー でエージェントを起動することをお勧めします。サービスアカウントの APIキー を使用することには次の2つの利点があります。
- エージェントは、特定のユーザーに依存しません。
- Launch によって作成された run に関連付けられた作成者が、エージェントに関連付けられたユーザーではなく、ローンチジョブを送信したユーザーとして Launch に表示されます。
エージェントの設定
launch-config.yaml という名前の YAML ファイルでローンチエージェントを設定します。デフォルトでは、W&B は ~/.config/wandb/launch-config.yaml に設定ファイルを確認します。ローンチエージェントをアクティブにするときに、異なるディレクトリーを指定することもできます。
ローンチエージェントの設定ファイルの内容は、ローンチエージェントの環境、ローンチキューの対象リソース、Dockerビルダ要件、クラウドレジストリ要件などに依存します。
ユースケースに関係なく、ローンチエージェントにはコア設定可能なオプションがあります。
max_jobs: エージェントが並行して実行できるジョブの最大数entity: キューが所属するエンティティqueues: エージェントが監視する1つ以上のキューの名前
wandb launch-agent コマンドを参照してください。次の YAML スニペットは、コアローンチエージェント設定キーを指定する方法を示しています。
# 最大同時 run 数を指定します。-1 = 無制限
max_jobs: -1
entity: <entity-name>
# ポールするキューのリスト
queues:
- <queue-name>
コンテナビルダーの設定
ローンチエージェントをイメージ構築に使用するように設定できます。Git リポジトリまたはコードアーティファクトから作成されたローンチジョブを使用する場合、コンテナビルダーを使用するようにエージェントを設定する必要があります。Create a launch job を参照して、ローンチジョブの作成方法について詳しく学んでください。
W&B Launch は3つのビルダーオプションをサポートしています:
- Docker: DockerビルダーはローカルのDockerデーモンを使用してイメージをビルドします。
- Kaniko: Kaniko は、Dockerデーモンが利用できない環境でのイメージ構築を可能にする Google のプロジェクトです。
- Noop: エージェントはジョブをビルドしようとせず、代わりに事前にビルドされたイメージをプルするだけです。
エージェントが Dockerデーモンが利用できない環境でポールしている場合(例えば、Kubernetesクラスター)、Kanikoビルダーを使用してください。
Kanikoビルダーの詳細については、Set up Kubernetes を参照してください。
イメージビルダーを指定するには、エージェント設定にビルダーキーを含めます。例えば、次のコードスニペットは、DockerまたはKanikoを使用することを指定するローンチ設定(launch-config.yaml)の一部を示しています。
builder:
type: docker | kaniko | noop
コンテナレジストリの設定
場合によっては、ローンチエージェントをクラウドレジストリに接続したいかもしれません。ローンチエージェントをクラウドレジストリに接続したい一般的なシナリオは次のとおりです:
- ジョブをビルドした場所以外の環境(強力なワークステーションやクラスターなど)でジョブを実行したい場合。
- エージェントを使用してイメージをビルドし、Amazon SageMakerやVertexAIでこれらのイメージを実行したい場合。
- エージェントにイメージリポジトリからプルするための資格情報を提供してもらいたい場合。
コンテナレジストリと対話するようにエージェントを設定する方法の詳細については、Advanced agent set ページを参照してください。
ローンチエージェントのアクティブ化
launch-agent W&B CLIコマンドを使用してローンチエージェントをアクティブ化します:
wandb launch-agent -q <queue-1> -q <queue-2> --max-jobs 5
いくつかのユースケースでは、ローンチエージェントをKubernetesクラスター内からキューをポールするように設定したいかもしれません。Advanced queue set up page を参照して、詳細情報を得てください。
3.1 - ローンンチエージェントを設定する
高度なエージェント設定
このガイドでは、W&B ローンチエージェントを設定して、さまざまな環境でコンテナイメージを作成する方法について情報を提供します。
ビルドは git およびコードアーティファクトジョブにのみ必要です。イメージジョブにはビルドは必要ありません。
ジョブタイプの詳細については、「ローンチジョブの作成」を参照してください。
ビルダー
ローンチエージェントは、Docker または Kaniko を使用してイメージをビルドできます。
- Kaniko: Kubernetes で特権コンテナとしてビルドを実行せずにコンテナイメージをビルドします。
- Docker: ローカルで
docker buildコマンドを実行してコンテナイメージをビルドします。
ビルダータイプは、ローンチエージェントの設定で builder.type キーを使用して、docker、kaniko、またはビルドをオフにするための noop に制御できます。デフォルトでは、エージェントの Helm チャートは builder.type を noop に設定します。builder セクションの追加キーは、ビルドプロセスを設定するために使用されます。
エージェントの設定でビルダーが指定されていない場合、有効な docker CLI が見つかると、エージェントは自動的に Docker を使用します。Docker が利用できない場合、エージェントは noop をデフォルトとします。
コンテナレジストリへのプッシュ
ローンチエージェントは、ビルドするすべてのイメージに一意のソースハッシュでタグを付けます。エージェントは、builder.destination キーで指定されたレジストリにイメージをプッシュします。
たとえば、builder.destination キーが my-registry.example.com/my-repository に設定されている場合、エージェントはイメージに my-registry.example.com/my-repository:<source-hash> というタグを付けてプッシュします。イメージがすでにレジストリに存在する場合、ビルドはスキップされます。
エージェント設定
Helm チャートを経由してエージェントをデプロイする場合、エージェント設定は values.yaml ファイルの agentConfig キーに提供する必要があります。
自分で wandb launch-agent を使用してエージェントを呼び出す場合、エージェント設定を --config フラグを使用して YAML ファイルのパスとして提供できます。デフォルトでは、設定は ~/.config/wandb/launch-config.yaml から読み込まれます。
ローンチエージェントの設定 (launch-config.yaml) 内で、ターゲットリソース環境とコンテナレジストリの名前をそれぞれ environment と registry キーに提供します。
環境とレジストリに基づいてローンチエージェントを設定する方法を、以下のタブで示します。
AWS 環境設定には地域キーが必要です。リージョンはエージェントが実行される AWS 地域であるべきです。
environment:
type: aws
region: <aws-region>
builder:
type: <kaniko|docker>
# エージェントがイメージを保存する ECR レポジトリの URI。
# リージョンが環境に設定した内容と一致することを確認してください。
destination: <account-id>.ecr.<aws-region>.amazonaws.com/<repository-name>
# Kaniko を使用する場合、エージェントがビルドコンテキストを保存する S3 バケットを指定します。
build-context-store: s3://<bucket-name>/<path>
エージェントは boto3 を使用してデフォルトの AWS 資格情報を読み込みます。デフォルトの AWS 資格情報の設定方法については、boto3 ドキュメント を参照してください。
Google Cloud 環境には、region および project キーが必要です。region にはエージェントが実行されるリージョンを設定し、project にはエージェントが実行される Google Cloud プロジェクトを設定します。エージェントは Python の google.auth.default() を使用してデフォルトの資格情報を読み込みます。
environment:
type: gcp
region: <gcp-region>
project: <gcp-project-id>
builder:
type: <kaniko|docker>
# エージェントがイメージを保存するアーティファクトリポジトリとイメージ名の URI。
# リージョンとプロジェクトが環境に設定した内容と一致することを確認してください。
uri: <region>-docker.pkg.dev/<project-id>/<repository-name>/<image-name>
# Kaniko を使用する場合、エージェントがビルドコンテキストを保存する GCS バケットを指定します。
build-context-store: gs://<bucket-name>/<path>
デフォルトの GCP 資格情報をエージェントが利用できるように設定する方法については、google-auth ドキュメント を参照してください。
Azure 環境には追加のキーは必要ありません。エージェントが起動するときに、azure.identity.DefaultAzureCredential() を使用してデフォルトの Azure 資格情報を読み込みます。
environment:
type: azure
builder:
type: <kaniko|docker>
# エージェントがイメージを保存する Azure コンテナレジストリレポジトリの URI。
destination: https://<registry-name>.azurecr.io/<repository-name>
# Kaniko を使用する場合、エージェントがビルドコンテキストを保存する Azure Blob Storage コンテナを指定します。
build-context-store: https://<storage-account-name>.blob.core.windows.net/<container-name>
デフォルトの Azure 資格情報の設定方法については、azure-identity ドキュメント を参照してください。
エージェント権限
エージェントの必要な権限はユースケースによって異なります。
クラウドレジストリ権限
ローンチエージェントがクラウドレジストリと対話するために通常必要な権限は以下の通りです。
{
'Version': '2012-10-17',
'Statement':
[
{
'Effect': 'Allow',
'Action':
[
'ecr:CreateRepository',
'ecr:UploadLayerPart',
'ecr:PutImage',
'ecr:CompleteLayerUpload',
'ecr:InitiateLayerUpload',
'ecr:DescribeRepositories',
'ecr:DescribeImages',
'ecr:BatchCheckLayerAvailability',
'ecr:BatchDeleteImage',
],
'Resource': 'arn:aws:ecr:<region>:<account-id>:repository/<repository>',
},
{
'Effect': 'Allow',
'Action': 'ecr:GetAuthorizationToken',
'Resource': '*',
},
],
}
artifactregistry.dockerimages.list;
artifactregistry.repositories.downloadArtifacts;
artifactregistry.repositories.list;
artifactregistry.repositories.uploadArtifacts;
Kaniko ビルダーを使用する場合は、AcrPush ロールを追加してください。
Kaniko のためのストレージ権限
ローンチエージェントは、Kaniko ビルダーを使用している場合、クラウドストレージにプッシュする権限が必要です。Kaniko はビルドジョブを実行するポッドの外にコンテキストストアを使用します。
AWS での Kaniko ビルダーの推奨コンテキストストアは Amazon S3 です。エージェントが S3 バケットにアクセスするためのポリシーは以下の通りです:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "ListObjectsInBucket",
"Effect": "Allow",
"Action": ["s3:ListBucket"],
"Resource": ["arn:aws:s3:::<BUCKET-NAME>"]
},
{
"Sid": "AllObjectActions",
"Effect": "Allow",
"Action": "s3:*Object",
"Resource": ["arn:aws:s3:::<BUCKET-NAME>/*"]
}
]
}
GCP では、エージェントが GCS にビルドコンテキストをアップロードするために必要な IAM 権限は次の通りです:
storage.buckets.get;
storage.objects.create;
storage.objects.delete;
storage.objects.get;
Azure Blob Storage にビルドコンテキストをアップロードするためには、Storage Blob Data Contributor ロールが必要です。
Kaniko ビルドのカスタマイズ
Kaniko ジョブが使用する Kubernetes ジョブ仕様をエージェント設定の builder.kaniko-config キーに指定します。例えば:
builder:
type: kaniko
build-context-store: <my-build-context-store>
destination: <my-image-destination>
build-job-name: wandb-image-build
kaniko-config:
spec:
template:
spec:
containers:
- args:
- "--cache=false" # 引数は "key=value" の形式でなければなりません
env:
- name: "MY_ENV_VAR"
value: "my-env-var-value"
Launch エージェントを CoreWeave にデプロイ
オプションとして、W&B Launch エージェントを CoreWeave クラウドインフラストラクチャにデプロイできます。CoreWeave は GPU 加速ワークロード専用に構築されたクラウドインフラストラクチャです。
CoreWeave に Launch エージェントをデプロイする方法については、CoreWeave ドキュメント を参照してください。
3.2 - ローンンチキューを設定する
以下のページでは、ローンチキューオプションの設定方法について説明します。
キュー設定テンプレートのセットアップ
Queue Config Templates を使用して、計算リソースの消費に関するガードレールを管理します。メモリ消費量、GPU、実行時間などのフィールドに対して、デフォルト、最小値、および最大値を設定します。
config templates を使用してキューを設定した後、チームのメンバーは、あなたが定義した範囲内のフィールドのみを変更することができます。
キューテンプレートの設定
既存のキューでキューテンプレートを設定するか、新しいキューを作成することができます。
- https://wandb.ai/launch のローンチアプリに移動します。
- テンプレートを追加したいキューの名前の横にある View queue を選択します。
- Config タブを選択します。これにより、キューの作成日時、キュー設定、および既存のローンチタイムオーバーライドに関する情報が表示されます。
- Queue config セクションに移動します。
- テンプレートを作成したい設定キー-値を特定します。
- 設定内の値をテンプレートフィールドに置き換えます。テンプレートフィールドは
{{variable-name}}の形式をとります。 - Parse configuration ボタンをクリックします。設定を解析すると、W&B は作成した各テンプレートの下にキュー設定タイルを自動的に作成します。
- 生成された各タイルに対して、キュー設定が許可できるデータ型 (文字列、整数、浮動小数点数) を最初に指定する必要があります。これを行うために、Type ドロップダウンメニューからデータ型を選択します。
- データ型に基づいて、各タイル内に表示されるフィールドを完成させます。
- Save config をクリックします。
例えば、チームが使用できる AWS インスタンスを制限するテンプレートを作成したい場合、テンプレートフィールドを追加する前のキュー設定は次のようになります:
RoleArn: arn:aws:iam:region:account-id:resource-type/resource-id
ResourceConfig:
InstanceType: ml.m4.xlarge
InstanceCount: 1
VolumeSizeInGB: 2
OutputDataConfig:
S3OutputPath: s3://bucketname
StoppingCondition:
MaxRuntimeInSeconds: 3600
InstanceType にテンプレートフィールドを追加すると、設定は次のようになります:
RoleArn: arn:aws:iam:region:account-id:resource-type/resource-id
ResourceConfig:
InstanceType: "{{aws_instance}}"
InstanceCount: 1
VolumeSizeInGB: 2
OutputDataConfig:
S3OutputPath: s3://bucketname
StoppingCondition:
MaxRuntimeInSeconds: 3600
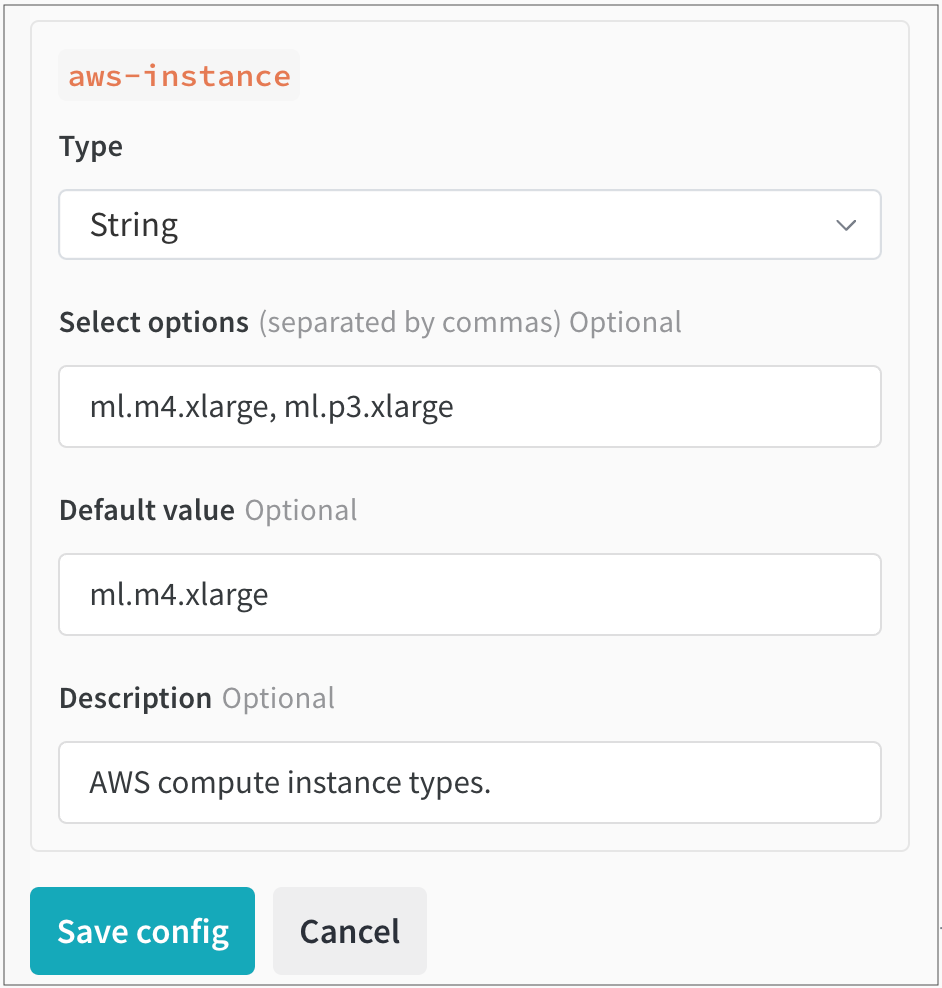
次に、Parse configuration をクリックします。新しいタイル aws-instance が Queue config の下に表示されます。
そこで、Type ドロップダウンからデータ型として String を選択します。これにより、ユーザーが選択できる値を指定できるフィールドが表示されます。例えば、次の画像では、チームの管理者がユーザーが選べる 2 つの異なる AWS インスタンスタイプ (ml.m4.xlarge と ml.p3.xlarge) を設定しています:
ローンチジョブを動的に設定する
キュー設定は、エージェントがキューからジョブをデキューするときに評価されるマクロを使用して動的に設定できます。以下のマクロを設定できます:
| マクロ | 説明 |
|---|---|
${project_name} |
run がローンチされるプロジェクトの名前。 |
${entity_name} |
run がローンチされるプロジェクトの所有者。 |
${run_id} |
ローンチされる run の ID。 |
${run_name} |
ローンチされる run の名前。 |
${image_uri} |
この run のコンテナイメージの URI。 |
${MY_ENV_VAR}) は、エージェントの環境から環境変数で置き換えられます。アクセラレータ (GPU) で実行されるイメージをビルドするためのローンチエージェントの使用
アクセラレータ環境で実行されるイメージをビルドするためにローンチを使用する場合、アクセラレータベースイメージを指定する必要があります。
このアクセラレータベースイメージは次の要件を満たしている必要があります:
- Debian 互換 (Launch Dockerfile は python を取得するために apt-get を使用します)
- CPU & GPU ハードウェアインストラクションセットとの互換性 (使用する GPU がサポートする CUDA バージョンであることを確認してください)
- あなたが提供するアクセラレータバージョンと ML アルゴリズムにインストールされたパッケージ間の互換性
- ハードウェアとの互換性を確立するために必要な追加ステップを要求するパッケージのインストール
TensorFlow で GPU を使用する方法
TensorFlow が GPU を適切に利用することを確認してください。これを達成するために、キューリソース設定の builder.accelerator.base_image キーで Docker イメージとそのイメージタグを指定します。
例えば、tensorflow/tensorflow:latest-gpu ベースイメージは、TensorFlow が GPU を適切に使用することを保証します。これはキュー設定でリソース設定を使用して設定できます。
以下の JSON スニペットは、キュー設定で TensorFlow ベースイメージを指定する方法を示しています:
{
"builder": {
"accelerator": {
"base_image": "tensorflow/tensorflow:latest-gpu"
}
}
}
3.3 - チュートリアル: Docker を使用して W&B ローンンチを設定する
以下のガイドでは、ローカルマシンでドッカーを使用してW&B Launchを設定し、ローンンチエージェントの環境とキューの対象リソースとして使用する方法を説明します。
ドッカーを使用してジョブを実行し、同じローカルマシン上でローンンチエージェントの環境として使用することは、クラスター管理システム(Kubernetesなど)がインストールされていないマシンにコンピュートがある場合に特に役立ちます。
また、強力なワークステーションでのワークロードを実行するためにドッキューを使用することもできます。
ドッカーをW&B Launchと一緒に使用する場合、W&Bはまずイメージをビルドし、そのイメージからコンテナをビルドして実行します。イメージはDockerの docker run <image-uri> コマンドでビルドされます。キュー設定は、docker run コマンドに渡される追加の引数として解釈されます。
Dockerキューの設定
Dockerの対象リソースのためのローンンチキュー設定は、docker run CLIコマンドで定義された同じオプションを受け入れます。
エージェントはキュー設定で定義されたオプションを受け取り、その後、受け取ったオプションをローンンチジョブの設定からのオーバーライドとマージし、対象リソース(この場合はローカルマシン)で実行される最終的な docker run コマンドを生成します。
次の2つの構文変換が行われます:
- 繰り返しオプションは、キュー設定でリストとして定義されます。
- フラグオプションは、キュー設定で
trueの値を持つブール値として定義されます。
例えば、以下のキュー設定:
{
"env": ["MY_ENV_VAR=value", "MY_EXISTING_ENV_VAR"],
"volume": "/mnt/datasets:/mnt/datasets",
"rm": true,
"gpus": "all"
}
結果として以下の docker run コマンドになります:
docker run \
--env MY_ENV_VAR=value \
--env MY_EXISTING_ENV_VAR \
--volume "/mnt/datasets:/mnt/datasets" \
--rm <image-uri> \
--gpus all
ボリュームは文字列のリストまたは単一の文字列として指定できます。複数のボリュームを指定する場合はリストを使用してください。
ドッカーは値が割り当てられていない環境変数をローンンチエージェントの環境から自動的に渡します。これは、ローンンチエージェントが環境変数 MY_EXISTING_ENV_VAR を持っている場合、その環境変数がコンテナ内で利用可能であることを意味します。これは、キュー設定で公開せずに他の設定キーを使用したい場合に便利です。
docker run コマンドの --gpus フラグを使って、ドッカーコンテナで利用可能なGPUを指定できます。gpus フラグの使用方法について詳しくは、Dockerのドキュメントをご覧ください。
-
Dockerコンテナ内でGPUを使用するには、NVIDIA Container Toolkit をインストールしてください。
-
コードやアーティファクトをソースとするジョブからイメージをビルドする場合、NVIDIA Container Toolkitを含めるためにエージェントでベースイメージをオーバーライドできます。 例えば、キュー内でベースイメージを
tensorflow/tensorflow:latest-gpuにオーバーライドできます:{ "builder": { "accelerator": { "base_image": "tensorflow/tensorflow:latest-gpu" } } }
キューの作成
W&B CLIを使用して、ドッカーをコンピュートリソースとして使用するキューを作成します:
- Launchページに移動します。
- Create Queue ボタンをクリックします。
- キューを作成したい Entity を選択します。
- Name フィールドにキューの名前を入力します。
- Resource として Docker を選択します。
- Configuration フィールドにドッカーキューの設定を定義します。
- Create Queue ボタンをクリックしてキューを作成します。
ローカルマシンでローンンチエージェントを設定する
ローンンチエージェントを launch-config.yaml という名前の YAML 設定ファイルで設定します。デフォルトでは、W&B は ~/.config/wandb/launch-config.yaml で設定ファイルをチェックします。ローンンチエージェントをアクティベートするときに異なるディレクトリをオプションとして指定できます。
wandb launch-agent コマンドを参照してください。コアエージェント設定オプション
以下のタブは、W&B CLIとYAML設定ファイルを使用して、コアエージェント設定オプションを指定する方法を示しています:
wandb launch-agent -q <queue-name> --max-jobs <n>
max_jobs: <n concurrent jobs>
queues:
- <queue-name>
ドッカーイメージビルダー
マシン上のローンンチエージェントは、ドッカーイメージをビルドするように設定できます。デフォルトでは、これらのイメージはマシンのローカルイメージリポジトリに保存されます。ローンンチエージェントがドッカーイメージをビルドできるようにするには、ローンンチエージェント設定で builder キーを docker に設定します:
builder:
type: docker
エージェントがドッカーイメージをビルドせず、代わりにレジストリからの事前ビルドイメージを使用したい場合は、ローンンチエージェント設定で builder キーを noop に設定します:
builder:
type: noop
コンテナレジストリ
Launch は Dockerhub、Google Container Registry、Azure Container Registry、Amazon ECR などの外部コンテナレジストリを使用します。 異なる環境でジョブを実行したい場合は、コンテナレジストリから引き出せるようにエージェントを設定してください。
ローンンチエージェントをクラウドレジストリと接続する方法について詳しくは、Advanced agent setup ページを参照してください。
3.4 - チュートリアル: Kubernetes上でW&B ローンンチ を設定する
W&B Launch を使用して、ML エンジニアが Kubernetes ですでに管理しているリソースを簡単に利用できるようにし、Kubernetes クラスターに ML ワークロードをプッシュできます。
W&B は、あなたのクラスターにデプロイできる公式の Launch agent イメージ を提供しており、これは W&B が管理する Helm チャート を使用します。
W&B は Kaniko ビルダーを使用して、Launch agent が Kubernetes クラスター内で Docker イメージをビルドできるようにします。Launch agent のための Kaniko のセットアップ方法や、ジョブビルディングをオフにしてプレビルドした Docker イメージのみを使用する方法については、Advanced agent set up を参照してください。
kubectl アクセスが必要です。通常、クラスター管理者や同等の権限を持つカスタムロールを持つユーザーが必要です。Kubernetes のキューを設定する
Kubernetes のターゲットリソースに対する Launch キューの設定は、Kubernetes Job スペック または Kubernetes Custom Resource スペック のいずれかに似ています。
Launch キューを作成する際に、Kubernetes ワークロードリソーススペックの任意の側面を制御できます。
spec:
template:
spec:
containers:
- env:
- name: MY_ENV_VAR
value: some-value
resources:
requests:
cpu: 1000m
memory: 1Gi
metadata:
labels:
queue: k8s-test
namespace: wandb
一部のユースケースでは、CustomResource の定義を使用したいかもしれません。例えば、マルチノードの分散トレーニングを実行したい場合に CustomResource が便利です。Volcano を使用してマルチノードジョブを Launch で使用するためのアプリケーションの例をチュートリアルで参照してください。別のユースケースとして、W&B Launch を Kubeflow と一緒に使用したい場合があるかもしれません。
以下の YAML スニペットは、Kubeflow を使用したサンプルの Launch キュー設定を示しています:
kubernetes:
kind: PyTorchJob
spec:
pytorchReplicaSpecs:
Master:
replicas: 1
template:
spec:
containers:
- name: pytorch
image: '${image_uri}'
imagePullPolicy: Always
restartPolicy: Never
Worker:
replicas: 2
template:
spec:
containers:
- name: pytorch
image: '${image_uri}'
imagePullPolicy: Always
restartPolicy: Never
ttlSecondsAfterFinished: 600
metadata:
name: '${run_id}-pytorch-job'
apiVersion: kubeflow.org/v1
セキュリティ上の理由から、W&B は、Launch キューに指定されていない場合、次のリソースを注入します:
securityContextbackOffLimitttlSecondsAfterFinished
次の YAML スニペットは、これらの値が Launch キューにどのように現れるかを示しています:
spec:
template:
`backOffLimit`: 0
ttlSecondsAfterFinished: 60
securityContext:
allowPrivilegeEscalation: False,
capabilities:
drop:
- ALL,
seccompProfile:
type: "RuntimeDefault"
キューを作成する
Kubernetes を計算リソースとして使用する W&B アプリでキューを作成します:
- Launch page に移動します。
- Create Queue ボタンをクリックします。
- キューを作成したい Entity を選択します。
- Name フィールドにキューの名前を入力します。
- Resource として Kubernetes を選択します。
- Configuration フィールドに、前のセクションで設定した Kubernetes Job ワークフロースペックまたは Custom Resource スペックを入力します。
Helm を使って Launch agent を設定する
W&B が提供する Helm チャート を使用して、Launch agent を Kubernetes クラスターにデプロイします。values.yaml ファイルを使って、Launch agent の振る舞いを制御します。
Launch agent の設定ファイル (~/.config/wandb/launch-config.yaml) に通常定義されるコンテンツを values.yaml ファイルの launchConfig キーに指定します。
例えば、Kaniko Docker イメージビルダーを使用する EKS での Launch agent ルーンを可能にする Launch agent 設定があるとします:
queues:
- <queue name>
max_jobs: <n concurrent jobs>
environment:
type: aws
region: us-east-1
registry:
type: ecr
uri: <my-registry-uri>
builder:
type: kaniko
build-context-store: <s3-bucket-uri>
values.yaml ファイル内では、次のようになります:
agent:
labels: {}
# W&B API key.
apiKey: ''
# Container image to use for the agent.
image: wandb/launch-agent:latest
# Image pull policy for agent image.
imagePullPolicy: Always
# Resources block for the agent spec.
resources:
limits:
cpu: 1000m
memory: 1Gi
# Namespace to deploy launch agent into
namespace: wandb
# W&B api url (Set yours here)
baseUrl: https://api.wandb.ai
# Additional target namespaces that the launch agent can deploy into
additionalTargetNamespaces:
- default
- wandb
# This should be set to the literal contents of your launch agent config.
launchConfig: |
queues:
- <queue name>
max_jobs: <n concurrent jobs>
environment:
type: aws
region: <aws-region>
registry:
type: ecr
uri: <my-registry-uri>
builder:
type: kaniko
build-context-store: <s3-bucket-uri>
# The contents of a git credentials file. This will be stored in a k8s secret
# and mounted into the agent container. Set this if you want to clone private
# repos.
gitCreds: |
# Annotations for the wandb service account. Useful when setting up workload identity on gcp.
serviceAccount:
annotations:
iam.gke.io/gcp-service-account:
azure.workload.identity/client-id:
# Set to access key for azure storage if using kaniko with azure.
azureStorageAccessKey: ''
レジストリ、環境、および必要なエージェント権限に関する詳細は、Advanced agent set up を参照してください。
3.5 - チュートリアル: SageMaker で W&B Launch を設定する
W&B Launch を使用して、提供されたアルゴリズムやカスタムアルゴリズムを使用して SageMaker プラットフォーム上で機械学習モデルをトレーニングするための ラーンンチ ジョブを Amazon SageMaker に送信できます。SageMaker はコンピュート リソースの立ち上げとリリースを担当するため、EKS クラスターを持たないチームには良い選択肢となります。
Amazon SageMaker に接続された W&B Launch キューに送信された ラーンンチ ジョブは、CreateTrainingJob API を使用して SageMaker トレーニング ジョブとして実行されます。 CreateTrainingJob API に送信される引数を制御するには、 ラーンンチ キュー設定 を使用します。
Amazon SageMaker は トレーニング ジョブを実行するために Docker イメージを使用しています。SageMaker によってプルされるイメージは、Amazon Elastic Container Registry (ECR) に保存する必要があります。 つまり、トレーニングに使用するイメージは ECR に保存する必要があります。
前提条件
始める前に、以下の前提条件を確認してください:
- Docker イメージを作成するかどうかを決定します。
- AWS リソースを設定し、S3、ECR、および Sagemaker IAM ロールに関する情報を収集します。
- Launch エージェントのための IAM ロールを作成します。
Docker イメージを作成するかどうかを決定する
W&B Launch エージェントに Docker イメージを作成させるかどうかを決定します。選択肢は 2 つあります。
- ローンンチ エージェントに Docker イメージの構築を許可し、Amazon ECR にイメージをプッシュし、SageMaker Training ジョブの送信を許可します。このオプションは、トレーニング コードを迅速に反復する ML エンジニアにいくらかの簡素化を提供できます。
- ローンンチ エージェントが、トレーニングまたは推論スクリプトを含む既存の Docker イメージを使用します。このオプションは既存の CI システムに適しています。このオプションを選択する場合は、Amazon ECR のコンテナ レジストリに Docker イメージを手動でアップロードする必要があります。
AWS リソースを設定する
お好みの AWS リージョンで次の AWS リソースが設定されていることを確認してください :
- コンテナ イメージを保存するための ECR リポジトリ。
- SageMaker トレーニング ジョブの入力と出力を保存するための 1 つまたは複数の S3 バケット。
- Amazon SageMaker がトレーニング ジョブを実行し、Amazon ECR と Amazon S3 と対話することを許可する IAM ロール。
これらのリソースの ARN をメモしておいてください。SageMaker 用に Launch キュー設定 を定義するときに ARN が必要になります。
Launch エージェント用の IAM ポリシーを作成する
- AWS の IAM 画面から、新しいポリシーを作成します。
- JSON ポリシーエディターに切り替え、以下のポリシーをケースに基づいて貼り付けます。
<>で囲まれた値を実際の値に置き換えてください:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"logs:DescribeLogStreams",
"SageMaker:AddTags",
"SageMaker:CreateTrainingJob",
"SageMaker:DescribeTrainingJob"
],
"Resource": "arn:aws:sagemaker:<region>:<account-id>:*"
},
{
"Effect": "Allow",
"Action": "iam:PassRole",
"Resource": "arn:aws:iam::<account-id>:role/<RoleArn-from-queue-config>"
},
{
"Effect": "Allow",
"Action": "kms:CreateGrant",
"Resource": "<ARN-OF-KMS-KEY>",
"Condition": {
"StringEquals": {
"kms:ViaService": "SageMaker.<region>.amazonaws.com",
"kms:GrantIsForAWSResource": "true"
}
}
}
]
}
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"logs:DescribeLogStreams",
"SageMaker:AddTags",
"SageMaker:CreateTrainingJob",
"SageMaker:DescribeTrainingJob"
],
"Resource": "arn:aws:sagemaker:<region>:<account-id>:*"
},
{
"Effect": "Allow",
"Action": "iam:PassRole",
"Resource": "arn:aws:iam::<account-id>:role/<RoleArn-from-queue-config>"
},
{
"Effect": "Allow",
"Action": [
"ecr:CreateRepository",
"ecr:UploadLayerPart",
"ecr:PutImage",
"ecr:CompleteLayerUpload",
"ecr:InitiateLayerUpload",
"ecr:DescribeRepositories",
"ecr:DescribeImages",
"ecr:BatchCheckLayerAvailability",
"ecr:BatchDeleteImage"
],
"Resource": "arn:aws:ecr:<region>:<account-id>:repository/<repository>"
},
{
"Effect": "Allow",
"Action": "ecr:GetAuthorizationToken",
"Resource": "*"
},
{
"Effect": "Allow",
"Action": "kms:CreateGrant",
"Resource": "<ARN-OF-KMS-KEY>",
"Condition": {
"StringEquals": {
"kms:ViaService": "SageMaker.<region>.amazonaws.com",
"kms:GrantIsForAWSResource": "true"
}
}
}
]
}
- 次へ をクリックします。
- ポリシーに名前と説明を付けます。
- ポリシー作成 をクリックします。
Launch エージェント用の IAM ロールを作成する
Launch エージェントには、Amazon SageMaker トレーニング ジョブを作成する権限が必要です。以下の手順に従って IAM ロールを作成します:
- AWS の IAM 画面から、新しいロールを作成します。
- 信頼されたエンティティ として AWS アカウント (または組織のポリシーに適したオプション) を選択します。
- 権限画面をスクロールし、上で作成したポリシー名を選択します。
- ロールに名前と説明を付けます。
- ロールの作成 を選択します。
- ロールの ARN を記録します。これを設定するときに Launch エージェント用に ARN を指定します。
IAM ロールの作成方法について詳しくは、AWS Identity and Access Management ドキュメント を参照してください。
- エージェントがイメージを構築できるようにするには、高度なエージェントの設定で追加の権限が必要です。
- SageMaker キューの
kms:CreateGrant権限は、関連する ResourceConfig に指定された VolumeKmsKeyId がある場合にのみ必要であり、関連するロールにこの操作を許可するポリシーがない場合に限ります。
SageMaker 用に Launch キューを設定する
次に、W&B アプリで SageMaker をコンピュート リソースとして使用するキューを作成します:
- Launch アプリ に移動します。
- キューを作成 ボタンをクリックします。
- キューを作成する エンティティ を選択します。
- 名前 フィールドにキューの名前を入力します。
- リソース として SageMaker を選択します。
- 設定 フィールド内で、SageMaker ジョブに関する情報を提供します。デフォルトでは、W&B は YAML および JSON の
CreateTrainingJobリクエストボディを自動生成します:
{
"RoleArn": "<REQUIRED>",
"ResourceConfig": {
"InstanceType": "ml.m4.xlarge",
"InstanceCount": 1,
"VolumeSizeInGB": 2
},
"OutputDataConfig": {
"S3OutputPath": "<REQUIRED>"
},
"StoppingCondition": {
"MaxRuntimeInSeconds": 3600
}
}
少なくとも以下を指定する必要があります :
RoleArn: SageMaker 実行 IAM ロールの ARN (前提条件 を参照してください)。Launch agent IAM ロールとは混同しないでください。OutputDataConfig.S3OutputPath: SageMaker の出力が保存される Amazon S3 URI を指定します。ResourceConfig: リソース設定の必須仕様です。リソース設定のオプションはこちらに記載されています。StoppingCondition: トレーニング ジョブの停止条件の必須仕様です。オプションはこちらに記載されています。
- キューを作成 ボタンをクリックします。
Launch エージェントをセットアップする
次のセクションでは、エージェントをデプロイする場所と、デプロイ場所に基づいてエージェントをどのように設定するかを説明します。
Amazon SageMaker キューに Launch エージェントをデプロイする方法にはいくつかのオプションがあります: ローカルマシン、EC2 インスタンス、または EKSクラスターで。エージェントをデプロイする場所に基づいてアプリケーション エージェントを適切に構成します。
ローンンチ エージェントを実行する場所を決定する
プロダクション ワークロードおよび既に EKS クラスターを持つ顧客には、この Helm チャートを使用して EKS クラスターに ラーンンチ エージェント をデプロイすることをお勧めします。
現在の EKS クラスターがないプロダクション ワークロードには、EC2 インスタンスが適したオプションです。Launch エージェント インスタンスは常に稼働していますが、t2.micro サイズの EC2 インスタンスという比較的手頃なインスタンスで十分です。
実験的または個人のユースケースには、ローカルマシンに Launch エージェントを実行するのがすばやく始める方法です。
選択したユースケースに基づいて、以下のタブに記載されている指示に従って Launch エージェントを適切に設定してください:
W&B は、エージェントを EKS クラスターでインストールするために、W&B 管理 helm チャート の使用を強く推奨しています。
Amazon EC2 ダッシュボードに移動し、次のステップを完了します:
- インスタンスを起動 をクリックします。
- 名前 フィールドに名前を入力します。タグをオプションで追加します。
- インスタンスタイプ から、あなたの EC2 コンテナ用のインスタンスタイプを選択します。1vCPU と 1GiB のメモリ以上は必要ありません (例えば t2.micro)。
- キーペア(ログイン) フィールドで、組織内の新しいキーペアを作成します。後のステップで選択した SSH クライアントで EC2 インスタンスに 接続する ために、このキーペアを使用します。
- ネットワーク設定 で、組織に適したセキュリティグループを選択します。
- 詳細設定 を展開します。IAM インスタンスプロファイル として、上記で作成した ローンンチ エージェント IAM ロールを選択します。
- サマリー フィールドを確認します。正しければ、インスタンスを起動 を選択します。
AWS 上の EC2 ダッシュボードの左側パネル内の インスタンス に移動します。作成した EC2 インスタンスが稼働している ( インスタンス状態 列を参照) ことを確認します。EC2 インスタンスが稼働していることを確認したら、ローカルマシンのターミナルに移動し、次の手順を完了します:
- 接続 を選択します。
- SSH クライアント タブを選択し、EC2 インスタンスに接続するための指示に従います。
- EC2インスタンス内で、次のパッケージをインストールします:
sudo yum install python311 -y && python3 -m ensurepip --upgrade && pip3 install wandb && pip3 install wandb[launch]
- 次に、EC2 インスタンス内に Docker をインストールして起動します:
sudo yum update -y && sudo yum install -y docker python3 && sudo systemctl start docker && sudo systemctl enable docker && sudo usermod -a -G docker ec2-user
newgrp docker
これで、Launchエージェントの構成を設定する準備が整いました。
ローカルマシンでポーリングを実行するエージェントとロールを関連付けるには、~/.aws/config と ~/.aws/credentials にある AWS 設定ファイルを使用します。前のステップで作成した Launch エージェントの IAM ロール ARN を指定します。
[profile SageMaker-agent]
role_arn = arn:aws:iam::<account-id>:role/<agent-role-name>
source_profile = default
[default]
aws_access_key_id=<access-key-id>
aws_secret_access_key=<secret-access-key>
aws_session_token=<session-token>
セッショントークンは、その主データと関連付けられた AWS リソースによって最大長が 1 時間または 3 日であることに注意してください。
Launch エージェントを設定する
launch-config.yaml という名前の YAML 設定ファイルで Launch エージェントを設定します。
デフォルトでは、W&B は ~/.config/wandb/launch-config.yaml にある設定ファイルを確認します。エージェントをアクティブにする際に -c フラグで別のディレクトリを指定することも可能です。
以下の YAML スニペットは、コア設定エージェントオプションを指定する方法を示しています:
max_jobs: -1
queues:
- <queue-name>
environment:
type: aws
region: <your-region>
registry:
type: ecr
uri: <ecr-repo-arn>
builder:
type: docker
エージェントは wandb launch-agent で開始します。
(オプション) Docker イメージを Amazon ECR にプッシュする
Launch ジョブを含む Docker イメージを Amazon ECR レポジトリにアップロードします。画像ベースのジョブを使用している場合、Docker イメージは新しい Launch ジョブを送信する前に ECR レジストリに存在している必要があります。
3.6 - チュートリアル: Vertex AI で W&B Launch を設定する
W&B Launch を使用して、Vertex AI トレーニングジョブとしてジョブを実行するために送信することができます。Vertex AI トレーニングジョブでは、Vertex AI プラットフォーム上の提供されたアルゴリズムまたはカスタムアルゴリズムを使用して機械学習モデルをトレーニングすることができます。ローンチジョブが開始されると、Vertex AI が基盤となるインフラストラクチャー、スケーリング、およびオーケストレーションを管理します。
W&B Launch は、google-cloud-aiplatform SDK の CustomJob クラスを介して Vertex AI と連携します。CustomJob のパラメータは、ローンチキュー設定で制御できます。Vertex AI は、GCP 外のプライベートレジストリからイメージをプルするように設定することはできません。つまり、Vertex AI と W&B Launch を使用したい場合、コンテナイメージを GCP またはパブリックレジストリに保存する必要があります。コンテナイメージを Vertex ジョブでアクセス可能にするための詳細は、Vertex AI ドキュメントを参照してください。
前提条件
- Vertex AI API が有効になっている GCP プロジェクトを作成またはアクセスしてください。 API を有効にする方法については、GCP API コンソールドキュメント を参照してください。
- Vertex で実行したいイメージを保存するための GCP Artifact Registry リポジトリを作成してください。 詳細については、GCP Artifact Registry ドキュメント を参照してください。
- Vertex AI がメタデータを保存するステージング GCS バケットを作成してください。 このバケットは、Vertex AI ワークロードと同じリージョンにある必要があります。ステージングおよびビルドコンテキストには同じバケットを使用できます。
- Vertex AI ジョブを立ち上げるために必要な権限を持つサービスアカウントを作成してください。 サービスアカウントに権限を割り当てる方法については、GCP IAM ドキュメント を参照してください。
- サービスアカウントに Vertex ジョブを管理する権限を付与してください。
| パーミッション | リソーススコープ | 説明 |
|---|---|---|
aiplatform.customJobs.create |
指定された GCP プロジェクト | プロジェクト内で新しい機械学習ジョブを作成することができます。 |
aiplatform.customJobs.list |
指定された GCP プロジェクト | プロジェクト内の機械学習ジョブを列挙することができます。 |
aiplatform.customJobs.get |
指定された GCP プロジェクト | プロジェクト内の特定の機械学習ジョブの情報を取得することができます。 |
spec.service_account フィールドを使用して、W&B の run 用のカスタムサービスアカウントを選択できます。Vertex AI 用キューを設定
Vertex AI リソース用のキュー設定は、Vertex AI Python SDK の CustomJob コンストラクタと run メソッドへの入力を指定します。リソース設定は spec および run キーに格納されます。
specキーには、Vertex AI Python SDK のCustomJobコンストラクタ の名前付き引数の値が含まれています。runキーには、Vertex AI Python SDK のCustomJobクラスのrunメソッドの名前付き引数の値が含まれています。
実行環境のカスタマイズは主に spec.worker_pool_specs リストで行われます。ワーカープール仕様は、ジョブを実行する作業者グループを定義します。デフォルトの設定のワーカー仕様は、アクセラレータのない n1-standard-4 マシンを 1 台要求します。必要に応じてマシンタイプ、アクセラレータタイプ、数を変更することができます。
利用可能なマシンタイプやアクセラレータタイプについての詳細は、Vertex AI ドキュメント を参照してください。
キューを作成
Vertex AI を計算リソースとして使用するキューを W&B アプリで作成する:
- Launch ページ に移動します。
- Create Queue ボタンをクリックします。
- キューを作成したい Entity を選択します。
- Name フィールドにキューの名前を入力します。
- Resource として GCP Vertex を選択します。
- Configuration フィールドに、前のセクションで定義した Vertex AI
CustomJobについての情報を入力します。デフォルトで、W&B は次のような YAML および JSON のリクエストボディを自動入力します:
spec:
worker_pool_specs:
- machine_spec:
machine_type: n1-standard-4
accelerator_type: ACCELERATOR_TYPE_UNSPECIFIED
accelerator_count: 0
replica_count: 1
container_spec:
image_uri: ${image_uri}
staging_bucket:
- キューを設定したら、Create Queue ボタンをクリックします。
最低限指定する必要があるのは以下です:
spec.worker_pool_specs: 非空のワーカープール仕様リスト。spec.staging_bucket: Vertex AI アセットとメタデータのステージングに使用する GCS バケット。
一部の Vertex AI ドキュメントには、すべてのキーがキャメルケースで表示されるワーカープール仕様が示されています。例: workerPoolSpecs。 Vertex AI Python SDK では、これらのキーにスネークケースを使用します。例:worker_pool_specs。
ローンチキュー設定のすべてのキーはスネークケースを使用する必要があります。
ローンチエージェントを設定
ローンチエージェントは、デフォルトでは ~/.config/wandb/launch-config.yaml にある設定ファイルを介して設定可能です。
max_jobs:
Vertex AI で実行されるイメージをローンチエージェントに構築してもらいたい場合は、Advanced agent set up を参照してください。
エージェント権限を設定
このサービスアカウントとして認証する方法は複数あります。Workload Identity、ダウンロードされたサービスアカウント JSON、環境変数、Google Cloud Platform コマンドラインツール、またはこれらのメソッドの組み合わせを通じて実現できます。
4 - Launch FAQ
4.1 - `wandb launch -d` または `wandb job create image` が、レジストリからプルせずに全体のDockerアーティファクトをアップロードしていますか?
wandb launch -d コマンドは、イメージをレジストリにアップロードしません。イメージは別途レジストリにアップロードしてください。以下の手順に従ってください。
- イメージをビルドします。
- イメージをレジストリにプッシュします。
ワークフローは以下の通りです:
docker build -t <repo-url>:<tag> .
docker push <repo-url>:<tag>
wandb launch -d <repo-url>:<tag>
ローンチエージェントは、指定されたコンテナを指すジョブを立ち上げます。コンテナレジストリからイメージを取得するエージェントアクセスの設定例については、Advanced agent setupを参照してください。
Kubernetes を使用する場合は、Kubernetes クラスターのポッドが、イメージがプッシュされたレジストリにアクセスできることを確認してください。
4.2 - Dockerキュー内の複数のジョブが同じアーティファクトをダウンロードする場合、キャッシュは使用されますか、それとも毎回のrunで再ダウンロードされますか?
キャッシュは存在しません。各ローンチジョブは独立して動作します。キューの設定で Docker の引数を使用して、共有キャッシュをマウントするようにキューまたはエージェントを設定してください。
さらに、特定のユースケースに対して、W&B アーティファクトキャッシュを永続ボリュームとしてマウントします。
4.3 - Kubernetes でエージェントにはどのような権限が必要ですか?
Kubernetesマニフェストは、wandb ネームスペースで wandb-launch-agent という名前のロールを作成します。このロールは、エージェントが wandb ネームスペースでポッド、configmaps、secretsを作成し、ポッドのログに アクセス することを可能にします。wandb-cluster-role は、エージェントがポッドを作成し、ポッドのログに アクセス し、secrets、ジョブを作成し、指定されたネームスペース全体でジョブのステータスを確認できるようにします。
4.4 - Launch で "permission denied" エラーを修正するにはどうすればよいですか?
エラーメッセージ Launch Error: Permission denied に遭遇した場合、これは、目的のプロジェクトにログを記録するための権限が不十分であることを示しています。考えられる原因は次のとおりです:
- このマシンにログインしていません。コマンドラインで
wandb loginを実行してください。 - 指定されたエンティティが存在しません。エンティティは、ユーザーのユーザー名または既存のチームの名前である必要があります。必要に応じて、Subscriptions page でチームを作成してください。
- プロジェクトの権限がありません。プロジェクトの作成者にプライバシー設定を Open に変更するよう依頼して、プロジェクトに run をログできるようにしてください。
4.5 - W&B Launch はどのようにしてイメージを作成しますか?
画像のビルド手順は、ジョブのソースとリソース設定で指定されたアクセラレータのベース画像によって異なります。
キューを設定する場合やジョブを送信する際には、キューやジョブのリソース設定にベースアクセラレータ画像を含めてください:
{
"builder": {
"accelerator": {
"base_image": "image-name"
}
}
}
ビルドプロセスには、ジョブタイプと提供されたアクセラレータのベース画像に基づいて、以下のアクションが含まれます:
| | apt を使用して Python をインストール | Python パッケージをインストール | ユーザーと作業ディレクトリを作成 | コードを画像にコピー | エントリーポイントを設定 | |
4.6 - W&B Launch を GPU 上での Tensorflow と連携させるにはどうすればよいですか?
TensorFlow ジョブで GPU を使用する場合、コンテナビルド用にカスタムベースイメージを指定します。これにより、run 中の正しい GPU 利用が保証されます。リソース設定の builder.accelerator.base_image キーの下にイメージタグを追加します。例えば:
{
"gpus": "all",
"builder": {
"accelerator": {
"base_image": "tensorflow/tensorflow:latest-gpu"
}
}
}
W&B バージョン 0.15.6 以前では、base_image の親キーとして accelerator の代わりに cuda を使用してください。
4.7 - W&B に Dockerfile を指定して、Docker イメージを作成してもらうことはできますか?
この機能は、要件が安定しているがコードベースが頻繁に変化するプロジェクトに適しています。
Dockerfile を設定した後、W&B に指定する方法は次の3つです:
- Dockerfile.wandb を使用する
- W&B CLI を使用する
- W&B App を使用する
W&B run のエントリポイントと同じディレクトリーに Dockerfile.wandb ファイルを含めます。W&B はこのファイルを組み込みの Dockerfile ではなく使用します。
wandb launch コマンドに --dockerfile フラグを使用してジョブをキューに追加します:
wandb launch --dockerfile path/to/Dockerfile
W&B App でジョブをキューに追加する際、Overrides セクションで Dockerfile のパスを指定します。それをキーと値のペアとして入力し、キーを "dockerfile"、値を Dockerfile のパスとします。
次の JSON は、ローカルディレクトリーに Dockerfile を含む方法を示しています:
{
"args": [],
"run_config": {
"lr": 0,
"batch_size": 0,
"epochs": 0
},
"entrypoint": [],
"dockerfile": "./Dockerfile"
}
4.8 - アクセラレータベースイメージにはどのような要件がありますか?
アクセラレータを使用するジョブには、必要なアクセラレータコンポーネントを含む基本イメージを提供してください。アクセラレータイメージに関しては、以下の要件を確認してください:
- Debian との互換性(Launch Dockerfile は Python をインストールするために apt-get を使用します)
- サポートされている CPU と GPU ハードウェアの命令セット(意図した GPU に対する CUDA バージョンの互換性を確認)
- 提供されるアクセラレータバージョンと機械学習アルゴリズム内のパッケージとの互換性
- ハードウェアとの互換性のために追加のステップが必要なパッケージのインストール
4.9 - ターゲット環境で Launch は計算リソースを自動でプロビジョニング (そしてスピンダウン) できますか?
このプロセスは環境に依存します。Amazon SageMaker と Vertex でリソースが提供されます。Kubernetes では、オートスケーラーが需要に基づいてリソースを自動的に調整します。W&B のソリューション アーキテクトが Kubernetes インフラストラクチャーの設定を支援し、再試行、自動スケーリング、およびスポット インスタンス ノード プールの使用を可能にします。サポートについては、support@wandb.com に連絡するか、共有された Slack チャンネルを使用してください。
4.10 - ローンチは並列化をサポートしていますか?ジョブによって消費されるリソースを制限する方法はありますか?
Launch は、複数の GPU およびノードにわたるジョブのスケーリングをサポートします。詳細については、このガイドを参照してください。
各 Launch エージェントには max_jobs パラメータが設定されており、同時に実行できるジョブの最大数を決定します。適切なローンチ インフラストラクチャーに接続されていれば、複数のエージェントが単一のキューを指すことができます。
リソース設定では、CPU、GPU、メモリ、およびその他のリソースに対してキューまたはジョブ実行レベルでの制限を設定できます。Kubernetes でリソース制限付きのキューを設定する方法については、このガイドを参照してください。
スイープの場合、以下のブロックをキュー設定に含めて、同時に実行される run の数を制限してください。
scheduler:
num_workers: 4
4.11 - ローンチを効果的に使用するためのベストプラクティスはありますか?
-
エージェントを起動する前にキューを作成し、簡単に設定を可能にします。これを行わないと、キューが追加されるまでエージェントが正しく動作しないエラーが発生します。
-
W&B のサービスアカウントを作成してエージェントを起動し、個別のユーザーアカウントにリンクされていないことを確認します。
-
wandb.configを使用してハイパーパラメーターを管理し、ジョブ再実行時に上書きできるようにします。argparse の使用方法については、このガイドを参照してください。
4.12 - キューにプッシュできる人をどのように制御しますか?
キューはユーザー チームに特有です。 キュー作成時に所有するエンティティを定義します。 アクセスを制限するには、チームメンバーシップを変更します。
4.13 - クリックするのが嫌いです - UI を通さずに Launch を使用できますか?
はい。標準の wandb CLI にはジョブをローンンチするための launch サブコマンドが含まれています。詳細については、以下のコマンドを実行してください。
wandb launch --help
4.14 - ジョブやオートメーションのためのシークレットを指定することはできますか?例えば、ユーザーに直接見せたくないAPIキーのようなものですか?
はい。次の手順に従ってください:
-
run 用の指定された名前空間に Kubernetes のシークレットを作成します。コマンドは以下の通りです:
kubectl create secret -n <namespace> generic <secret_name> <secret_value> -
シークレットを作成したら、run が開始する際にシークレットを注入するようにキューを設定します。クラスター管理者だけがシークレットを見ることができ、エンドユーザーはそれを確認できません。
4.15 - 管理者はどのユーザーが修正アクセスを持つかをどのように制限できますか?
アクセスを制御するために、チームの管理者でないユーザー向けに特定のキューのフィールドを queue config templates を通じて設定します。チーム管理者は、非管理者ユーザーがどのフィールドを閲覧できるかを定義し、編集の制限を設定します。キューを作成または編集する能力を持っているのはチーム管理者のみです。
4.16 - 私が W&B にコンテナを作成してほしくない場合でも、Launch を使用できますか?
事前に構築された Docker イメージを起動するには、以下のコマンドを実行してください。<> 内のプレースホルダーを具体的な情報に置き換えてください:
wandb launch -d <docker-image-uri> -q <queue-name> -E <entrypoint>
このコマンドはジョブを作成し、run を開始します。
イメージからジョブを作成するには、以下のコマンドを使用してください:
wandb job create image <image-name> -p <project> -e <entity>
5 - W&B Launch を使用してスイープを作成する
ハイパーパラメータチューニングジョブを W&B Launch を使って作成します。Launch の Sweeps を使用すると、指定されたハイパーパラメーターでスイープするためのスイープスケジューラーが、Launch Queue にプッシュされます。スイープスケジューラーはエージェントによってピックアップされると開始され、選択されたハイパーパラメーターでスイープする run を同じキューにローンチします。これはスイープが終了するか、または停止するまで続きます。
デフォルトの W&B Sweep スケジューリングエンジンを使用するか、独自のカスタムスケジューラーを実装することができます。
- 標準スイープスケジューラー: デフォルトの W&B Sweep スケジューリングエンジンを使用して W&B Sweeps を制御します。
bayes、grid、randomメソッドが利用可能です。 - カスタムスイープスケジューラー: スイープスケジューラーをジョブとして動作するように設定します。このオプションにより、完全なカスタマイズが可能です。標準のスイープスケジューラーを拡張して追加のログを含める方法の例は、以下のセクションに記載されています。
W&B 標準スケジューラーを使用したスイープの作成
Launch で W&B Sweeps を作成します。W&B App を使用してインタラクティブにスイープを作成することも、W&B CLI を使用してプログラム的にスイープを作成することもできます。Launch スイープの高度な設定、スケジューラーのカスタマイズを可能にする CLI を使用します。
W&B App を使って、インタラクティブにスイープを作成します。
- W&B App であなたの W&B プロジェクトへ移動します。
- 左側のパネルからスイープのアイコン(ほうきのイメージ)を選択します。
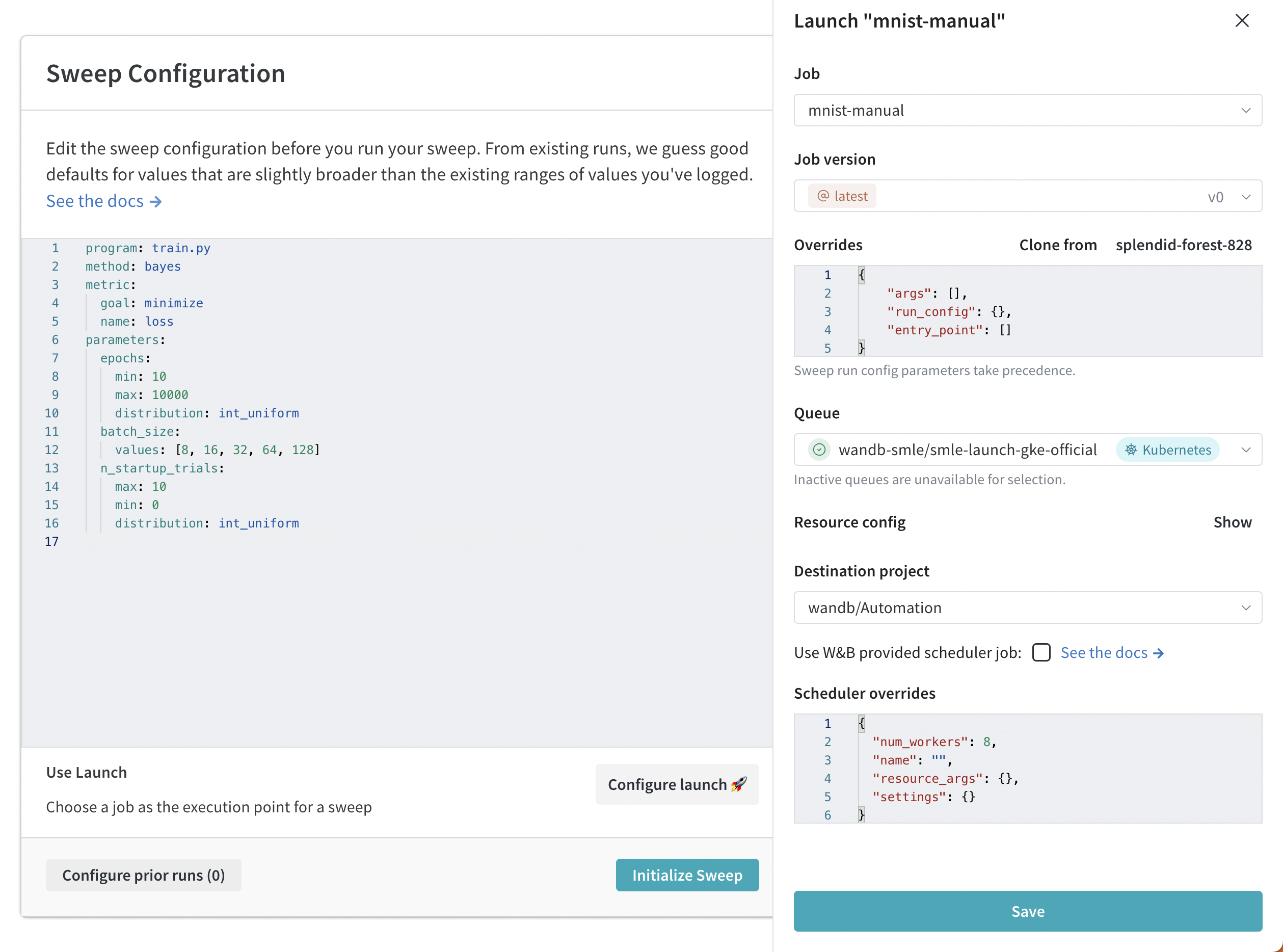
- 次に、Create Sweep ボタンを選択します。
- Configure Launch 🚀 ボタンをクリックします。
- Job ドロップダウンメニューから、スイープを作成したい仕事の名前とバージョンを選択します。
- Queue ドロップダウンメニューを使用して、スイープを実行するキューを選択します。
- Job Priority ドロップダウンで、Launch ジョブの優先度を指定します。Launch Queue が優先度をサポートしていない場合、Launch ジョブの優先度は「Medium」に設定されます。
- (オプション) run またはスイープスケジューラーの引数を override 設定します。例えば、スケジューラーオーバーライドを使用して、スケジューラーが管理する同時 run の数を
num_workersを使って設定します。 - (オプション) Destination Project ドロップダウンメニューを使用してスイープを保存するプロジェクトを選択します。
- Save をクリックします。
- Launch Sweep を選択します。
W&B CLI を使って、Launch でプログラム的に W&B Sweep を作成します。
- Sweep の設定を作成します。
- スイープ設定内で完全なジョブ名を指定します。
- スイープエージェントを初期化します。
例えば、以下のコードスニペットでは、ジョブの値に 'wandb/jobs/Hello World 2:latest' を指定しています。
# launch-sweep-config.yaml
job: 'wandb/jobs/Hello World 2:latest'
description: launch jobsを使ったスイープの例
method: bayes
metric:
goal: minimize
name: loss_metric
parameters:
learning_rate:
max: 0.02
min: 0
distribution: uniform
epochs:
max: 20
min: 0
distribution: int_uniform
# スケジューラ用のオプションパラメーター:
# scheduler:
# num_workers: 1 # 同時にスイープを実行するスレッド数
# docker_image: <スケジューラー用のベースイメージ>
# resource: <例: local-container...>
# resource_args: # run に渡されるリソース引数
# env:
# - WANDB_API_KEY
# Launch 用のオプションパラメーター
# launch:
# registry: <イメージのプル用のレジストリ>
スイープ設定の作成方法についての情報は、Define sweep configuration ページを参照してください。
- 次に、スイープを初期化します。設定ファイルのパス、ジョブキューの名前、W&B エンティティ、プロジェクトの名前を指定します。
wandb launch-sweep <path/to/yaml/file> --queue <queue_name> --entity <your_entity> --project <project_name>
W&B Sweeps についての詳細は、Tune Hyperparameters チャプターを参照してください。
カスタムスイープスケジューラーの作成
W&B スケジューラーまたはカスタムスケジューラーを使用してカスタムスイープスケジューラーを作成します。
0.15.4 以上である必要があります。W&B スイープスケジューリングロジックをジョブとして使用して Launch スイープを作成します。
- パブリックの wandb/sweep-jobs プロジェクトで Wandb スケジューラージョブを識別するか、以下のジョブ名を使用します:
'wandb/sweep-jobs/job-wandb-sweep-scheduler:latest' - この名前を指す
jobキーを含む追加のschedulerブロックで設定 yaml を構築します。例は以下の通りです。 - 新しい設定で
wandb launch-sweepコマンドを使用します。
例の設定:
# launch-sweep-config.yaml
description: スケジューラージョブを使用したLaunchスイープ設定
scheduler:
job: wandb/sweep-jobs/job-wandb-sweep-scheduler:latest
num_workers: 8 # 8つの同時スイープ実行を許可
# スイープが実行するトレーニング/チューニングジョブ
job: wandb/sweep-jobs/job-fashion-MNIST-train:latest
method: grid
parameters:
learning_rate:
min: 0.0001
max: 0.1
カスタムスケジューラーは、スケジューラージョブを作成することで作成できます。このガイドの目的のために、WandbScheduler を変更してより多くのログを提供します。
wandb/launch-jobsリポジトリをクローンします(特定の場所:wandb/launch-jobs/jobs/sweep_schedulers)- これで、
wandb_scheduler.pyを修正して、ログの増加を達成できます。例:_poll関数にログを追加します。これは、毎回のポーリングサイクル(設定可能なタイミング)で呼び出され、次のスイープ run をローンチする前に行います。 - 修正したファイルを実行して、以下のコマンドでジョブを作成します:
python wandb_scheduler.py --project <project> --entity <entity> --name CustomWandbScheduler - 作成されたジョブの名前を、UI または前の呼び出しの出力で識別します。特に指定がない場合、これはコードアーティファクトジョブです。
- スケジューラーが新しいジョブを指すようにスイープの設定を作成します。
...
scheduler:
job: '<entity>/<project>/job-CustomWandbScheduler:latest'
...
Optuna は、指定されたモデルに最適なハイパーパラメーターを見つけるために様々なアルゴリズムを使用するハイパーパラメータ最適化フレームワークです(W&B と似ています)。サンプリングアルゴリズム に加え、Optuna は数多くの プルーニングアルゴリズム も提供し、パフォーマンスが低い run を早期に終了させることができます。多数の run を実行する際、これは時間とリソースを節約するのに特に有用です。クラスは非常に設定可能で、scheduler.settings.pruner/sampler.args ブロックに期待されるパラメーターを渡すだけです。
Optuna のスケジューリングロジックをジョブとして使用して Launch スイープを作成します。
-
まず、独自のジョブを作成するか、ビルド済みの Optuna スケジューラーイメージジョブを使用します。
- 独自のジョブを作成する方法の例については、
wandb/launch-jobsリポジトリを参照してください。 - ビルド済みの Optuna イメージを使用するには、
wandb/sweep-jobsプロジェクトでjob-optuna-sweep-schedulerへ移動するか、ジョブ名を使用します:wandb/sweep-jobs/job-optuna-sweep-scheduler:latest。
- 独自のジョブを作成する方法の例については、
-
ジョブを作成した後、スイープを作成できます。Optuna スケジューラージョブを指す
jobキーを含むschedulerブロックを含むスイープ設定を構築します(以下の例)。
# optuna_config_basic.yaml
description: ベーシックな Optuna スケジューラー
job: wandb/sweep-jobs/job-fashion-MNIST-train:latest
run_cap: 5
metric:
name: epoch/val_loss
goal: minimize
scheduler:
job: wandb/sweep-jobs/job-optuna-sweep-scheduler:latest
resource: local-container # イメージからソースされるスケジューラージョブに必須
num_workers: 2
# optuna 特有の設定
settings:
pruner:
type: PercentilePruner
args:
percentile: 25.0 # 75% の run を終了
n_warmup_steps: 10 # 最初の x ステップではプルーニングを無効に
parameters:
learning_rate:
min: 0.0001
max: 0.1
- 最後に、launch-sweep コマンドでアクティブキューにスイープをローンチします。
wandb launch-sweep <config.yaml> -q <queue> -p <project> -e <entity>
Optuna スイープスケジューラージョブの正確な実装については、wandb/launch-jobs を参照してください。Optuna スケジューラーで可能な例については、wandb/examples をチェックしてください。
カスタムスイープスケジューラージョブで可能な例は、jobs/sweep_schedulers 以下の wandb/launch-jobs リポジトリにあります。このガイドは、公開されている Wandb スケジューラージョブ の使用方法を示し、またカスタムスイープスケジューラージョブを作成するプロセスを示しています。
launch で sweeps を再開する方法
以前に実行されたスイープから launch-sweep を再開することも可能です。ハイパーパラメーターとトレーニングジョブは変更できませんが、スケジューラー固有のパラメーターおよび送信先キューは変更可能です。
- 以前に実行された launch-sweep のスイープ名/ID を特定します。スイープ ID は 8 文字の文字列です(例:
hhd16935)。W&B App のプロジェクトで見つけることができます。 - スケジューラーパラメーターを変更する場合、更新された設定ファイルを構成します。
- ターミナルで、次のコマンドを実行します。
<と>で囲まれている内容を自身の情報で置き換えます。
wandb launch-sweep <optional config.yaml> --resume_id <sweep id> --queue <queue_name>
6 - ローンンチ インテグレーション ガイド
6.1 - Dagster
Dagster と W&B (W&B) を使用して MLOps パイプラインを調整し、ML アセットを維持します。W&B とのインテグレーションにより、Dagster 内で以下が簡単になります:
- W&B Artifacts の使用と作成。
- W&B Registry で Registered Models の使用と作成。
- W&B Launch を使用して専用のコンピュートでトレーニングジョブを実行します。
- ops とアセットで wandb クライアントを使用します。
W&B Dagster インテグレーションは W&B 専用の Dagster リソースと IO マネージャーを提供します:
wandb_resource: W&B API への認証と通信に使用される Dagster リソース。wandb_artifacts_io_manager: W&B Artifacts を処理するために使用される Dagster IO マネージャー。
以下のガイドでは、Dagster で W&B を使用するための前提条件の満たし方、ops とアセットで W&B Artifacts を作成して使用する方法、W&B Launch の利用方法、そして推奨されるベストプラクティスについて説明します。
始める前に
Dagster を Weights and Biases 内で使用するためには、以下のリソースが必要です:
- W&B API Key。
- W&B entity (ユーザーまたはチーム): Entity は W&B Runs と Artifacts を送信する場所のユーザー名またはチーム名です。Runs をログに記録する前に、W&B App の UI でアカウントまたはチームエンティティを作成しておいてください。エンティティを指定しない場合、その run はデフォルトのエンティティに送信されます。通常、これはあなたのユーザー名です。設定の「Project Defaults」内でデフォルトのエンティティを変更できます。
- W&B project: W&B Runs が保存されるプロジェクトの名前。
W&B entity は、W&B App のそのユーザーまたはチームページのプロフィールページをチェックすることで見つけられます。既存の W&B project を使用するか、新しいものを作成することができます。新しいプロジェクトは、W&B App のホームページまたはユーザー/チームのプロフィールページで作成できます。プロジェクトが存在しない場合は、初回使用時に自動的に作成されます。以下の手順は API キーを取得する方法を示しています:
APIキーの取得方法
- W&B にログインします。注:W&B サーバーを使用している場合は、管理者にインスタンスのホスト名を尋ねてください。
- 認証ページ またはユーザー/チーム設定で APIキーを集めます。プロダクション環境では、そのキーを所有するために サービスアカウント を使用することをお勧めします。
- その APIキー用に環境変数を設定します。
WANDB_API_KEY=YOUR_KEYをエクスポートします。
以下の例は、Dagster コード内で API キーを指定する場所を示しています。wandb_config のネストされた辞書内でエンティティとプロジェクト名を必ず指定してください。異なる W&B Project を使用したい場合は、異なる wandb_config の値を異なる ops/assets に渡すことができます。渡すことができる可能性のあるキーについての詳細は、以下の設定セクションを参照してください。
例: @job の設定
# これを config.yaml に追加します
# 代わりに、Dagit's Launchpad または JobDefinition.execute_in_process で設定することもできます
# 参考: https://docs.dagster.io/concepts/configuration/config-schema#specifying-runtime-configuration
resources:
wandb_config:
config:
entity: my_entity # これをあなたの W&B entity に置き換えます
project: my_project # これをあなたの W&B project に置き換えます
@job(
resource_defs={
"wandb_config": make_values_resource(
entity=str,
project=str,
),
"wandb_resource": wandb_resource.configured(
{"api_key": {"env": "WANDB_API_KEY"}}
),
"io_manager": wandb_artifacts_io_manager,
}
)
def simple_job_example():
my_op()
例: アセットを使用する @repository の設定
from dagster_wandb import wandb_artifacts_io_manager, wandb_resource
from dagster import (
load_assets_from_package_module,
make_values_resource,
repository,
with_resources,
)
from . import assets
@repository
def my_repository():
return [
*with_resources(
load_assets_from_package_module(assets),
resource_defs={
"wandb_config": make_values_resource(
entity=str,
project=str,
),
"wandb_resource": wandb_resource.configured(
{"api_key": {"env": "WANDB_API_KEY"}}
),
"wandb_artifacts_manager": wandb_artifacts_io_manager.configured(
{"cache_duration_in_minutes": 60} # ファイルを 1 時間だけキャッシュする
),
},
resource_config_by_key={
"wandb_config": {
"config": {
"entity": "my_entity", # これをあなたの W&B entity に置き換えます
"project": "my_project", # これをあなたの W&B project に置き換えます
}
}
},
),
]
この例では @job の例と異なり IO Manager キャッシュ期間を設定しています。
設定
以下の設定オプションは、インテグレーションによって提供される W&B 専用 Dagster リソースと IO マネージャーの設定として使用されます。
wandb_resource: W&B API と通信するために使用される Dagster リソース。提供された APIキー を使用して自動的に認証されます。プロパティ:api_key: (ストリング, 必須): W&B API と通信するために必要な W&B APIキー。host: (ストリング, オプショナル): 使用したい API ホストサーバー。W&B Server を使用している場合にのみ必要です。デフォルトはパブリッククラウドのホスト、https://api.wandb.aiです。
wandb_artifacts_io_manager: W&B Artifacts を消費するための Dagster IO マネージャー。プロパティ:base_dir: (整数, オプショナル) ローカルストレージとキャッシュに使用される基本ディレクトリ。W&B Artifacts と W&B Run のログはそのディレクトリから読み書きされます。デフォルトではDAGSTER_HOMEディレクトリを使用します。cache_duration_in_minutes: (整数, オプショナル) W&B Artifacts と W&B Run ログをローカルストレージに保持する時間。指定された時間が経過しアクセスされなかったファイルとディレクトリはキャッシュから削除されます。キャッシュのクリアは IO マネージャーの実行の終了時に行われます。キャッシュを無効にしたい場合は 0 に設定してください。キャッシュはジョブ間でアーティファクトが再利用されるときに速度を向上させます。デフォルトは30日間です。run_id: (ストリング, オプショナル): この run の一意のIDで再開に使用されます。プロジェクト内で一意である必要があり、run を削除した場合、IDを再利用することはできません。短い説明名は name フィールドを使用し、ハイパーパラメーターを保存して runs 間で比較するために config を使用してください。IDには/\#?%:という特殊文字を含めることはできません。Dagster 内で実験管理を行う場合、IO マネージャーが run を再開できるように Run ID を設定する必要があります。デフォルトでは Dagster Run ID に設定されます。例:7e4df022-1bf2-44b5-a383-bb852df4077e。run_name: (ストリング, オプショナル) この run を UI で識別しやすくするための短い表示名。デフォルトでは、以下の形式の文字列です:dagster-run-[8最初のDagster Run IDの文字]。たとえば、dagster-run-7e4df022。run_tags: (list[str], オプショナル): この run の UI にタグ一覧を埋める文字列リスト。タグは runs をまとめて整理したりbaselineやproductionなど一時的なラベルを適用するのに便利です。UIでタグを追加・削除したり特定のタグを持つ run だけを絞り込むのは簡単です。インテグレーションで使用される W&B Run にはdagster_wandbタグが付きます。
W&B Artifacts を使用する
W&B Artifact とのインテグレーションは Dagster IO マネージャーに依存しています。
IO マネージャー は、アセットまたは op の出力を保存し、それを下流のアセットまたは ops への入力として読み込む責任を持つユーザ提供のオブジェクトです。たとえば、IO マネージャーはファイルシステム上のファイルからオブジェクトを保存および読み込む可能性があります。
今回のインテグレーションは W&B Artifacts 用のIO マネージャーを提供します。これにより Dagster の @op または @asset は W&B Artifacts をネイティブに作成および消費できます。ここに Python リストを含むデータセットタイプの W&B Artifact を生み出す @asset の簡単な例があります。
@asset(
name="my_artifact",
metadata={
"wandb_artifact_arguments": {
"type": "dataset",
}
},
io_manager_key="wandb_artifacts_manager",
)
def create_dataset():
return [1, 2, 3] # これは Artifact に保存されます
@op、@asset、@multi_asset をメタデータ設定で注釈を付けてアーティファクトを記述できます。同様に、W&B Artifacts を Dagster 外部で作成された場合でも消費できます。
W&B Artifacts を書き込む
続行する前に、W&B Artifacts の使用方法について十分な理解を持っていることをお勧めします。Guide on Artifacts を検討してください。
Python 関数からオブジェクトを返すことで W&B Artifact を書き込みます。W&B でサポートされているオブジェクトは以下の通りです:
- Python オブジェクト (int, dict, list…)
- W&B オブジェクト (Table, Image, Graph…)
- W&B Artifact オブジェクト
以下の例は、Dagster アセット (@asset) を使用して W&B Artifacts を書き込む方法を示しています:
pickle モジュールでシリアライズできるものは何でも、インテグレーションによって作成された Artifact にピクルスされて追加されます。ダグスター内でその Artifact を読むときに内容が読み込まれます(さらなる詳細については Read artifacts を参照してください)。
@asset(
name="my_artifact",
metadata={
"wandb_artifact_arguments": {
"type": "dataset",
}
},
io_manager_key="wandb_artifacts_manager",
)
def create_dataset():
return [1, 2, 3]
W&B は複数のピクルスベースのシリアライズモジュール(pickle, dill, cloudpickle, joblib) をサポートしています。また、ONNX や PMML といったより高度なシリアライズも利用できます。Serialization セクションを参照してください。
ネイティブ W&B オブジェクト (例: Table, Image, or Graph) のいずれかが作成された Artifact にインテグレーションによって追加されます。以下は Table を使った例です。
import wandb
@asset(
name="my_artifact",
metadata={
"wandb_artifact_arguments": {
"type": "dataset",
}
},
io_manager_key="wandb_artifacts_manager",
)
def create_dataset_in_table():
return wandb.Table(columns=["a", "b", "c"], data=[[1, 2, 3]])
複雑なユースケースの場合、独自の Artifact オブジェクトを構築する必要があるかもしれません。インテグレーションは、統合の両側のメタデータを拡充するなど、便利な追加機能も提供しています。
import wandb
MY_ASSET = "my_asset"
@asset(
name=MY_ASSET,
io_manager_key="wandb_artifacts_manager",
)
def create_artifact():
artifact = wandb.Artifact(MY_ASSET, "dataset")
table = wandb.Table(columns=["a", "b", "c"], data=[[1, 2, 3]])
artifact.add(table, "my_table")
return artifact
設定
@op、@asset、および @multi_asset の設定を行うために使用される辞書 wandb_artifact_configuration があり、この辞書はメタデータとしてデコレータの引数で渡される必要があります。この設定は、W&B Artifacts の IO マネージャーの読み取りと書き込みを制御するために必要です。
@op の場合、Out メタデータ引数を介して出力メタデータにあります。
@asset の場合、アセットのメタデータ引数にあります。
@multi_asset の場合、AssetOut メタデータ引数を介して各出力メタデータにあります。
以下のコード例は、@op、@asset、および @multi_asset 計算で辞書を構成する方法を示しています:
@op の例:
@op(
out=Out(
metadata={
"wandb_artifact_configuration": {
"name": "my_artifact",
"type": "dataset",
}
}
)
)
def create_dataset():
return [1, 2, 3]
@asset の例:
@asset(
name="my_artifact",
metadata={
"wandb_artifact_configuration": {
"type": "dataset",
}
},
io_manager_key="wandb_artifacts_manager",
)
def create_dataset():
return [1, 2, 3]
設定を通じて名前を渡す必要はありません。@asset にはすでに名前があります。インテグレーションはアセット名として Artifact 名を設定します。
@multi_asset の例:
@multi_asset(
name="create_datasets",
outs={
"first_table": AssetOut(
metadata={
"wandb_artifact_configuration": {
"type": "training_dataset",
}
},
io_manager_key="wandb_artifacts_manager",
),
"second_table": AssetOut(
metadata={
"wandb_artifact_configuration": {
"type": "validation_dataset",
}
},
io_manager_key="wandb_artifacts_manager",
),
},
group_name="my_multi_asset_group",
)
def create_datasets():
first_table = wandb.Table(columns=["a", "b", "c"], data=[[1, 2, 3]])
second_table = wandb.Table(columns=["d", "e"], data=[[4, 5]])
return first_table, second_table
サポートされたプロパティ:
name: (str) このアーティファクトの人間が読み取り可能な名前で、その名前で UI内でこのアーティファクトを識別したり use_artifact 呼び出しで参照したりできます。名前には文字、数字、アンダースコア、ハイフン、ドットを含めることができます。プロジェクト内で一意である必要があります。@opに必須です。type: (str) アーティファクトのタイプで、アーティファクトを整理し差別化するために使用されます。一般的なタイプにはデータセットやモデルがありますが、任意の文字列を使用することができ、数字、アンダースコア、ハイフン、ドットを含めることができます。出力がすでにアーティファクトでない場合に必要です。description: (str) アーティファクトを説明するための自由なテキスト.説明は Markdownとして UIでレンダリングされるため,テーブル,リンクなどを配置するのに良い場所です。aliases: (list[str]) アーティファクトに適用したい 1つ以上のエイリアスを含む配列。インテグレーションは、それが設定されていようとなかろうと「最新」のタグもそのリストに追加します。これはモデルとデータセットのバージョン管理に効果的な方法です。add_dirs: 配列(list[dict[str, Any]]): Artifact に含める各ローカルディレクトリの設定を含む配列。SDK内の同名メソッドと同じ引数をサポートしています。add_files: 配列(list[dict[str, Any]]): Artifact に含める各ローカルファイルの設定を含む配列。SDK内の同名メソッドと同じ引数をサポートしています。add_references: 配列(list[dict[str, Any]]): Artifact に含める各外部リファレンスの設定を含む配列。SDK内の同名メソッドと同じ引数をサポートしています。serialization_module: (dict) 使用するシリアライズモジュールの設定。詳細については シリアル化 セクションを参照してください。name: (str) シリアライズモジュールの名前。受け入れられる値:pickle,dill,cloudpickle,joblib。モジュールはローカルで使用可能である必要があります。parameters: (dict[str, Any]) シリアライズ関数に渡されるオプション引数。モジュールの dump メソッドと同じ引数を受け入れます。例えば、{"compress": 3, "protocol": 4}。
高度な例:
@asset(
name="my_advanced_artifact",
metadata={
"wandb_artifact_configuration": {
"type": "dataset",
"description": "My *Markdown* description",
"aliases": ["my_first_alias", "my_second_alias"],
"add_dirs": [
{
"name": "My directory",
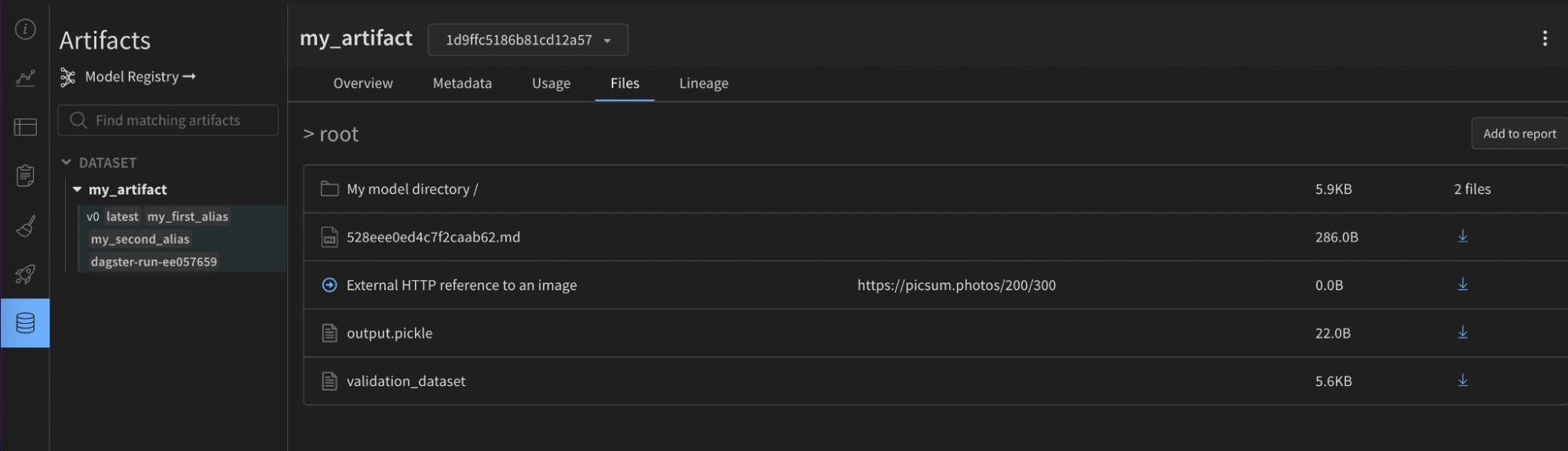
"local_path": "path/to/directory",
}
],
"add_files": [
{
"name": "validation_dataset",
"local_path": "path/to/data.json",
},
{
"is_tmp": True,
"local_path": "path/to/temp",
},
],
"add_references": [
{
"uri": "https://picsum.photos/200/300",
"name": "External HTTP reference to an image",
},
{
"uri": "s3://my-bucket/datasets/mnist",
"name": "External S3 reference",
},
],
}
},
io_manager_key="wandb_artifacts_manager",
)
def create_advanced_artifact():
return [1, 2, 3]
アセットは統合の両側で有用なメタデータとともに実体化されます:
- W&B 側: ソースインテグレーション名とバージョン、使用された python バージョン、pickle プロトコルバージョンなど。
- Dagster 側:
- Dagster Run ID
- W&B Run: ID、名前、パス、URL
- W&B Artifact: ID、名前、タイプ、バージョン、サイズ、URL
- W&B エンティティ
- W&B プロジェクト
以下の画像は、Dagster アセットに追加された W&B からのメタデータを示しています。この情報は、インテグレーションがなければ利用できませんでした。
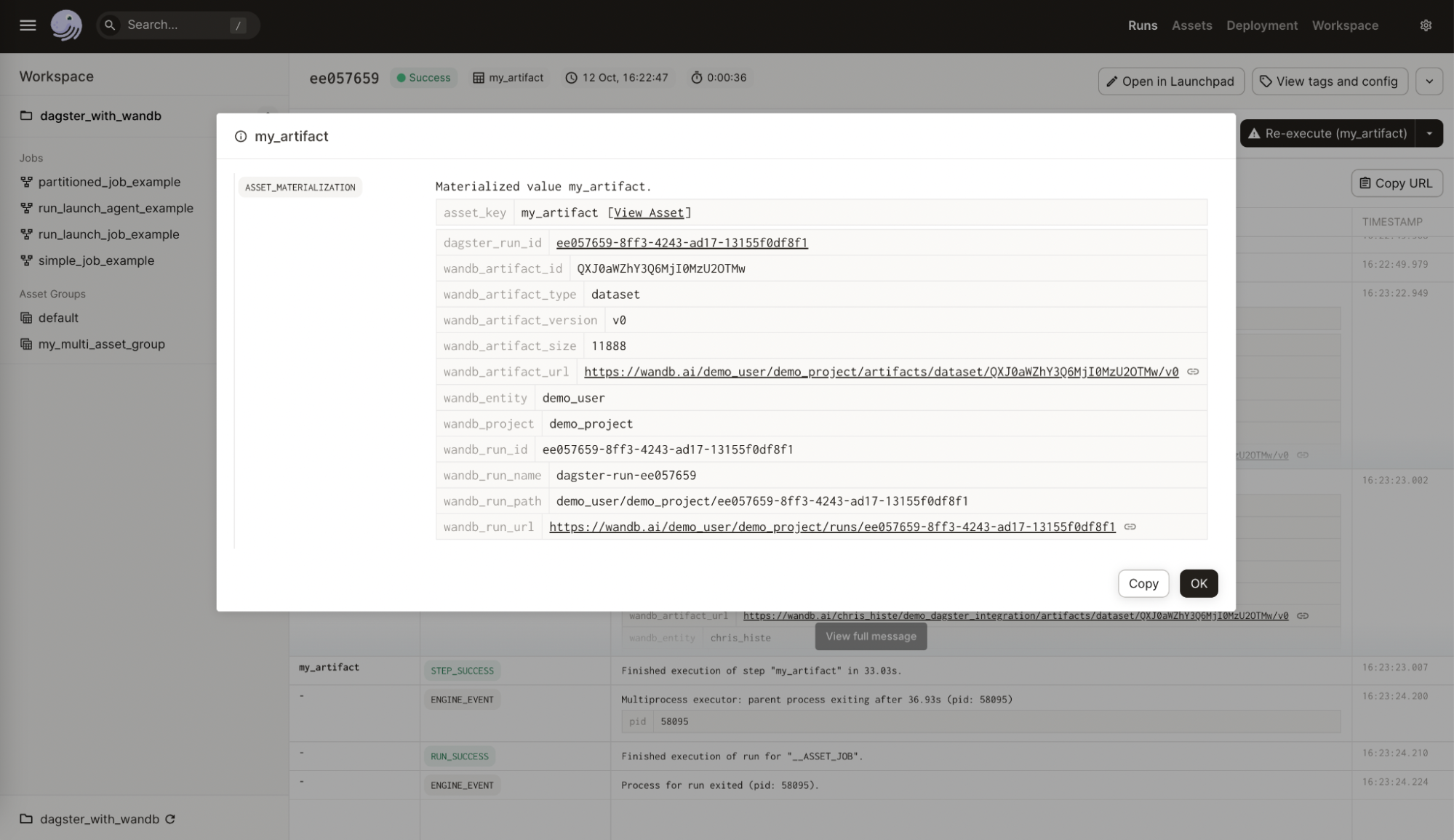
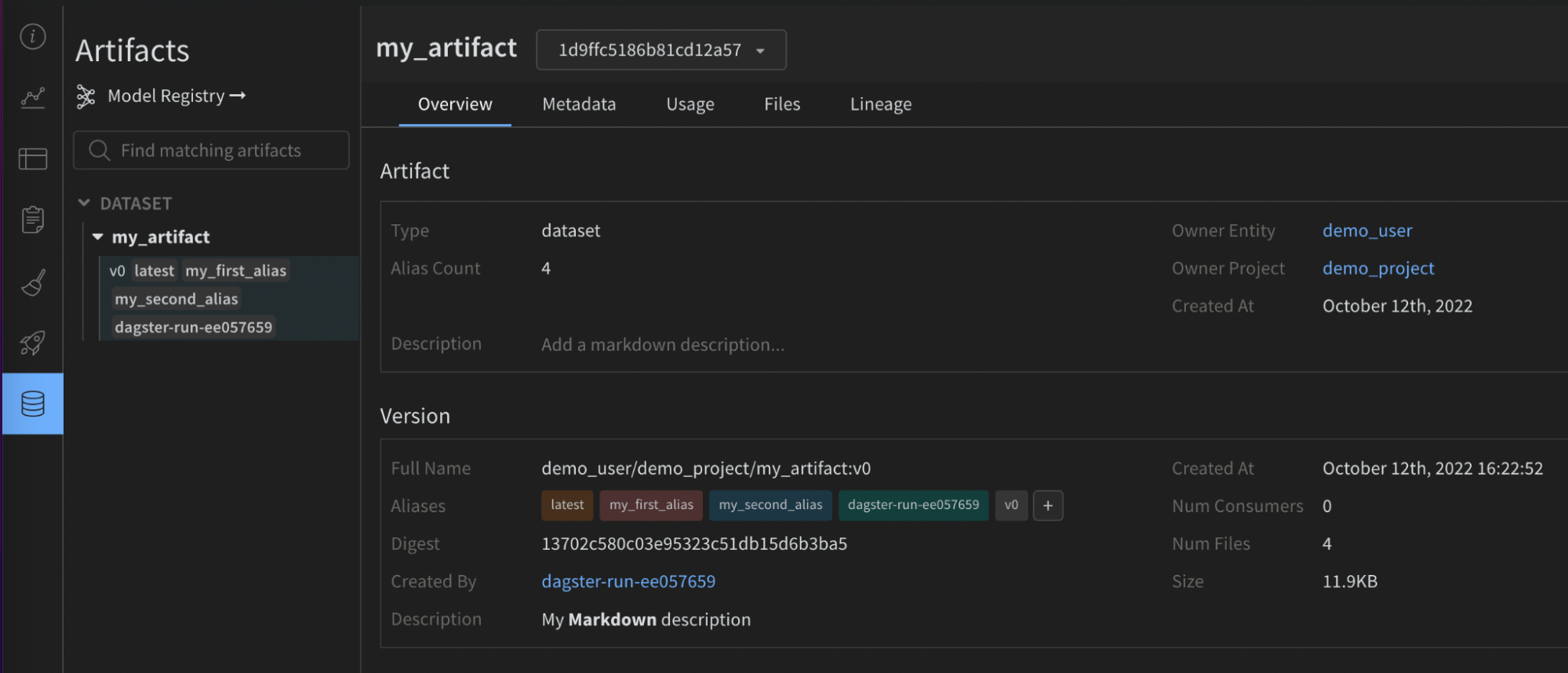
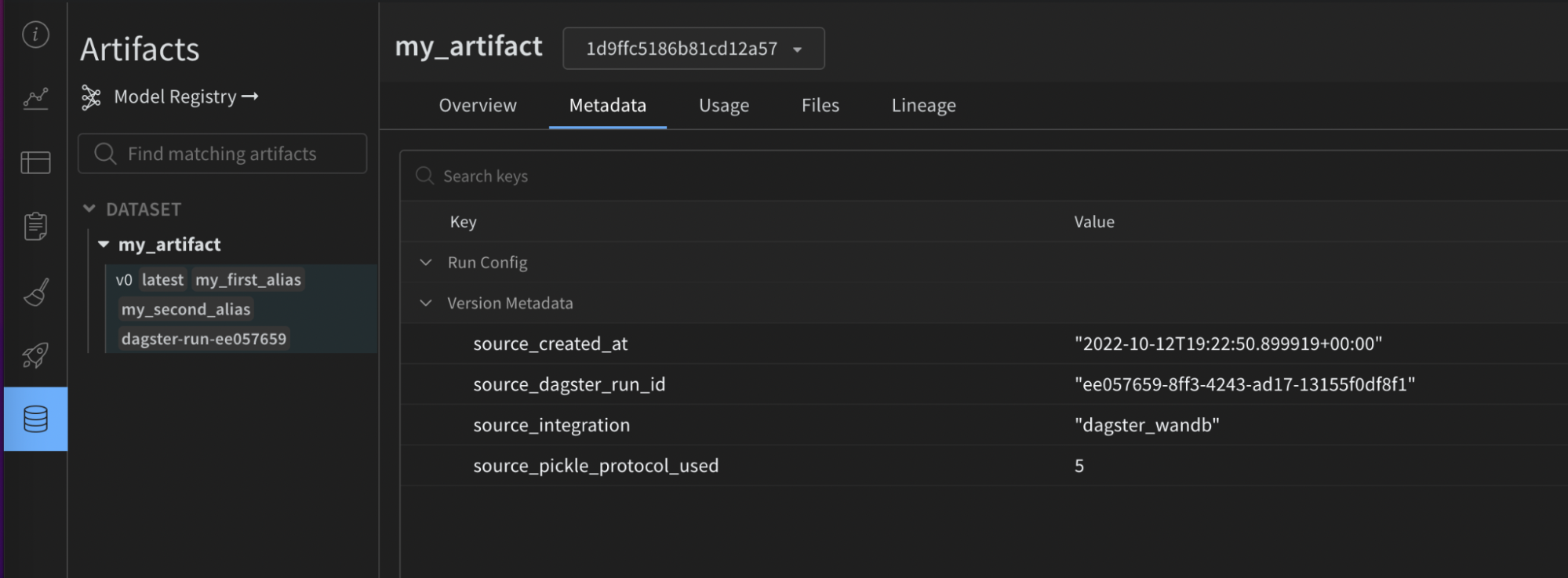
以下の画像は、与えられた設定が W&B アーティファクト上の有用なメタデータでどのように充実されたかを示しています。この情報は、再現性とメンテナンスに役立ちます。インテグレーションがなければ利用できませんでした。
mypy のような静的型チェッカーを使用する場合は、以下の方法で設定タイプ定義オブジェクトをインポートしてください:
from dagster_wandb import WandbArtifactConfiguration
パーティションの利用
インテグレーションはネイティブにDagster パーティションをサポートしています。
以下は DailyPartitionsDefinition を使用したパーティション化の例です。
@asset(
partitions_def=DailyPartitionsDefinition(start_date="2023-01-01", end_date="2023-02-01"),
name="my_daily_partitioned_asset",
compute_kind="wandb",
metadata={
"wandb_artifact_configuration": {
"type": "dataset",
}
},
)
def create_my_daily_partitioned_asset(context):
partition_key = context.asset_partition_key_for_output()
context.log.info(f"Creating partitioned asset for {partition_key}")
return random.randint(0, 100)
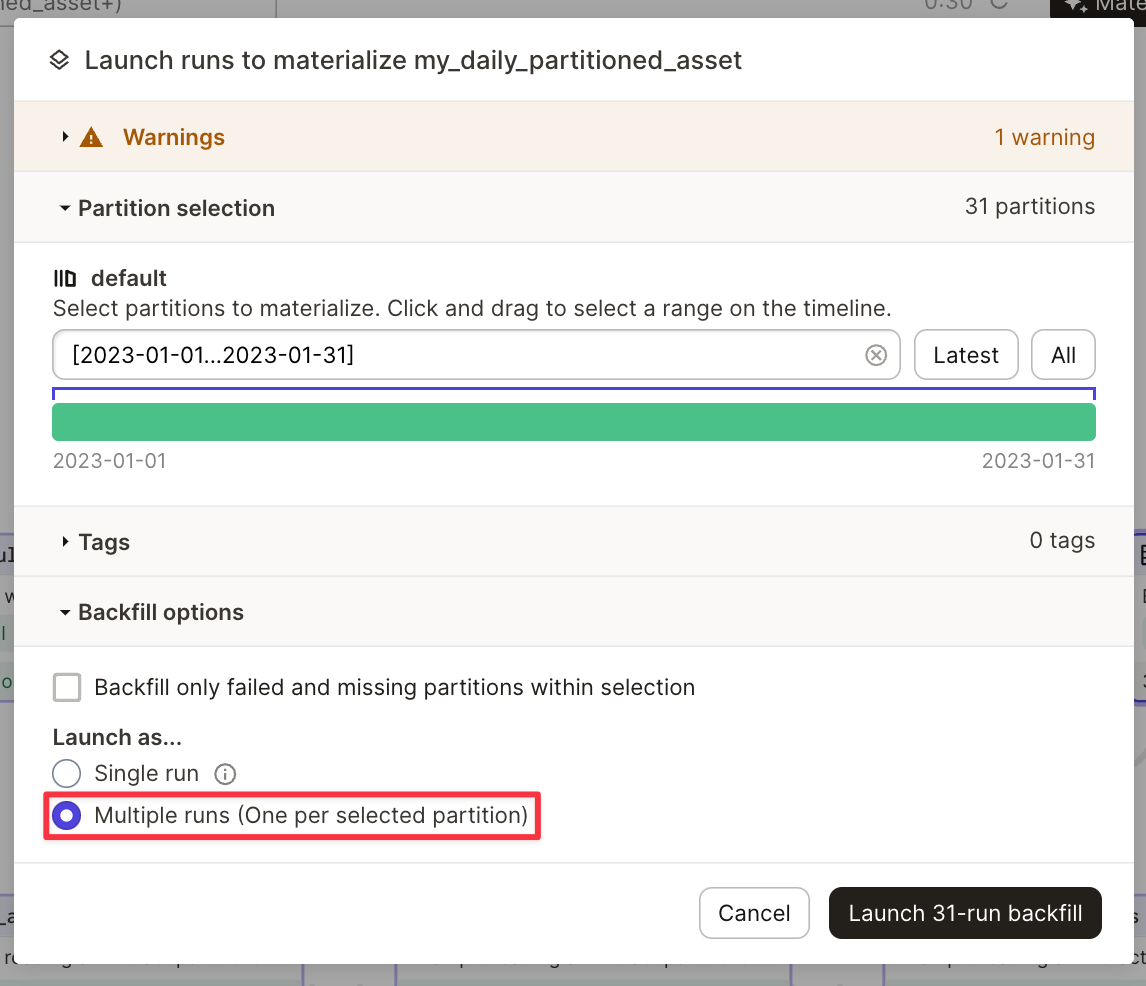
このコードはパーティションごとに一つの W&B Artifact を生成します。アーティファクトは、アセット名の下にパーティションキーを追加して Artifact パネル (UI) で表示されます。例: my_daily_partitioned_asset.2023-01-01、my_daily_partitioned_asset.2023-01-02、または my_daily_partitioned_asset.2023-01-03。複数の次元でパーティション化されたアセットは、次元を点で区切った形式で表示されます。例: my_asset.car.blue。
インテグレーションによって、単一の run で複数のパーティションの実体化を許可することはできません。資産を実体化するためには、複数の run を実行する必要があります。これは、Dagit で資産を実体化するときに行うことができます。
高度な使用法
W&B Artifacts を読み取る
W&B Artifacts の読み取りは、それらを書くのと似ています。@op または @asset に wandb_artifact_configuration と呼ばれる設定辞書を設定することができます。唯一の違いは、その設定を出力ではなく入力に設定する必要がある点です。
@op の場合、In メタデータ引数を介して入力メタデータにあります。Artifact の名前を明示的に渡す必要があります。
@asset の場合、Asset の In メタデータ引数の入力メタデータにあります。親アセットの名前がそれに一致する必要があるため、アーティファクトの名前を渡す必要はありません。
インテグレーションの外部で作成されたアーティファクトに依存関係を持たせたい場合は、SourceAsset を使用する必要があります。それは常にそのアセットの最新バージョンを読み込みます。
次の例は、さまざまな ops から Artifact を読み取る方法を示しています。
@op からアーティファクトを読み取る
@op(
ins={
"artifact": In(
metadata={
"wandb_artifact_configuration": {
"name": "my_artifact",
}
}
)
},
io_manager_key="wandb_artifacts_manager"
)
def read_artifact(context, artifact):
context.log.info(artifact)
別の @asset によって作成されたアーティファクトを読み取る
@asset(
name="my_asset",
ins={
"artifact": AssetIn(
# 入力引数をリネームしたくない場合は 'key' を削除できます
key="parent_dagster_asset_name",
input_manager_key="wandb_artifacts_manager",
)
},
)
def read_artifact(context, artifact):
context.log.info(artifact)
Dagster の外部で作成された Artifact を読み取る:
my_artifact = SourceAsset(
key=AssetKey("my_artifact"), # W&B Artifact の名前
description="Artifact created outside Dagster",
io_manager_key="wandb_artifacts_manager",
)
@asset
def read_artifact(context, my_artifact):
context.log.info(my_artifact)
設定
以下の設定は、IO マネージャーが収集するものを装飾された関数への入力として提供するべきかを示すために使用されます。以下の読み取りパターンがサポートされています。
- アーティファクト内にある名前付きオブジェクトを取得するには、get を使用します:
@asset(
ins={
"table": AssetIn(
key="my_artifact_with_table",
metadata={
"wandb_artifact_configuration": {
"get": "my_table",
}
},
input_manager_key="wandb_artifacts_manager",
)
}
)
def get_table(context, table):
context.log.info(table.get_column("a"))
- アーティファクト内にあるダウンロードされたファイルのローカルパスを取得するには、get_path を使用します:
@asset(
ins={
"path": AssetIn(
key="my_artifact_with_file",
metadata={
"wandb_artifact_configuration": {
"get_path": "name_of_file",
}
},
input_manager_key="wandb_artifacts_manager",
)
}
)
def get_path(context, path):
context.log.info(path)
- アーティファクトオブジェクト全体を取得する(コンテンツをローカルでダウンロードします):
@asset(
ins={
"artifact": AssetIn(
key="my_artifact",
input_manager_key="wandb_artifacts_manager",
)
},
)
def get_artifact(context, artifact):
context.log.info(artifact.name)
サポートされているプロパティ
get: (str) アーティファクト相対の名前にある W&B オブジェクトを取得します。get_path: (str) アーティファクト相対の名前にあるファイルへのパスを取得します。
シリアル化設定
デフォルトでは、インテグレーションは標準の pickle モジュールを使用しますが、一部のオブジェクトはこれと互換性がありません。たとえば、yield を持つ関数はシリアライズしようとした場合にエラーを発生させます。
より多くのピクルスベースのシリアライズモジュール (dill, cloudpickle, joblib) をサポートしています。また、より高度なシリアル化を使用して ONNX または PMML など、シリアル化された文字列を返すか、直接アーティファクトを作成することもできます。あなたのユースケースに最適な選択肢は、利用可能な文献を参考にしてください。
ピクルスベースのシリアル化モジュール
使用するシリアル化を wandb_artifact_configuration 内の serialization_module 辞書を通じて設定することができます。Dagster を実行しているマシンでモジュールが利用可能であることを確認してください。
インテグレーションは、そのアーティファクトを読む際にどのシリアル化モジュールを使用するべきかを自動的に判断します。
現在サポートされているモジュールは pickle、dill、cloudpickle、および joblib です。
こちらが、joblib でシリアル化された「モデル」を作成し、推論に使用する例です。
@asset(
name="my_joblib_serialized_model",
compute_kind="Python",
metadata={
"wandb_artifact_configuration": {
"type": "model",
"serialization_module": {
"name": "joblib"
},
}
},
io_manager_key="wandb_artifacts_manager",
)
def create_model_serialized_with_joblib():
# これは本物の ML モデルではありませんが、pickle モジュールでは不可能であるものです
return lambda x, y: x + y
@asset(
name="inference_result_from_joblib_serialized_model",
compute_kind="Python",
ins={
"my_joblib_serialized_model": AssetIn(
input_manager_key="wandb_artifacts_manager",
)
},
metadata={
"wandb_artifact_configuration": {
"type": "results",
}
},
io_manager_key="wandb_artifacts_manager",
)
def use_model_serialized_with_joblib(
context: OpExecutionContext, my_joblib_serialized_model
):
inference_result = my_joblib_serialized_model(1, 2)
context.log.info(inference_result) # 出力: 3
return inference_result
高度なシリアル化フォーマット (ONNX, PMML)
交換ファイル形式として ONNX や PMML を使用することは一般的です。インテグレーションはこれらの形式をサポートしていますが、Pickle ベースのシリアル化の場合よりも少し多くの作業が必要です。
これらの形式を使用する方法は 2 種類あります。
- モデルを選択した形式に変換してから、通常の Python オブジェクトのようにその形式の文字列表現を返します。インテグレーションはその文字列をピクルスします。それから、その文字列を使用してモデルを再構築することができます。
- シリアル化されたモデルを持つ新しいローカルファイルを作成し、そのファイルをカスタムアーティファクトに追加するために add_file 設定を実行します。
こちらは、Scikit-learn モデルを ONNX を使用してシリアル化する例です。
import numpy
import onnxruntime as rt
from skl2onnx import convert_sklearn
from skl2onnx.common.data_types import FloatTensorType
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from dagster import AssetIn, AssetOut, asset, multi_asset
@multi_asset(
compute_kind="Python",
outs={
"my_onnx_model": AssetOut(
metadata={
"wandb_artifact_configuration": {
"type": "model",
}
},
io_manager_key="wandb_artifacts_manager",
),
"my_test_set": AssetOut(
metadata={
"wandb_artifact_configuration": {
"type": "test_set",
}
},
io_manager_key="wandb_artifacts_manager",
),
},
group_name="onnx_example",
)
def create_onnx_model():
# https://onnx.ai/sklearn-onnx/ からインスパイアされたサンプル
# モデルのトレーニング
iris = load_iris()
X, y = iris.data, iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y)
clr = RandomForestClassifier()
clr.fit(X_train, y_train)
# ONNX 形式に変換
initial_type = [("float_input", FloatTensorType([None, 4]))]
onx = convert_sklearn(clr, initial_types=initial_type)
# アーティファクトの書き込み(モデル + テストセット)
return onx.SerializeToString(), {"X_test": X_test, "y_test": y_test}
@asset(
name="experiment_results",
compute_kind="Python",
ins={
"my_onnx_model": AssetIn(
input_manager_key="wandb_artifacts_manager",
),
"my_test_set": AssetIn(
input_manager_key="wandb_artifacts_manager",
),
},
group_name="onnx_example",
)
def use_onnx_model(context, my_onnx_model, my_test_set):
# https://onnx.ai/sklearn-onnx/ からインスパイアされたサンプル
# ONNX ランタイムを使用して予測を計算します
sess = rt.InferenceSession(my_onnx_model)
input_name = sess.get_inputs()[0].name
label_name = sess.get_outputs()[0].name
pred_onx = sess.run(
[label_name], {input_name: my_test_set["X_test"].astype(numpy.float32)}
)[0]
context.log.info(pred_onx)
return pred_onx
パーティションの利用
インテグレーションはネイティブにDagster パーティションをサポートしています。
1つ、複数またはすべてのアセットパーティションを選別的に読み取ります。
すべてのパーティションは辞書で提供され、キーと値はそれぞれパーティションキーとアーティファクトコンテンツを表します。
上流の @asset のすべてのパーティションを読み取り、それらは辞書として与えられます。この辞書で、キーはパーティションキー、値はアーティファクトコンテンツに関連しています。
@asset(
compute_kind="wandb",
ins={"my_daily_partitioned_asset": AssetIn()},
output_required=False,
)
def read_all_partitions(context, my_daily_partitioned_asset):
for partition, content in my_daily_partitioned_asset.items():
context.log.info(f"partition={partition}, content={content}")
指定したパーティションを選ぶために AssetIn の partition_mapping 設定を使用します。この例では TimeWindowPartitionMapping を使用しています。
@asset(
partitions_def=DailyPartitionsDefinition(start_date="2023-01-01", end_date="2023-02-01"),
compute_kind="wandb",
ins={
"my_daily_partitioned_asset": AssetIn(
partition_mapping=TimeWindowPartitionMapping(start_offset=-1)
)
},
output_required=False,
)
def read_specific_partitions(context, my_daily_partitioned_asset):
for partition, content in my_daily_partitioned_asset.items():
context.log.info(f"partition={partition}, content={content}")
設定オブジェクト metadata は、プロジェクト内の異なるアーティファクトパーティションと wandb のやり取りを設定するために使用されます。
オブジェクト metadata は、wandb_artifact_configuration というキーを含んでおり、さらに partitions というネストされたオブジェクトを含んでいます。
partitions オブジェクトは、各パーティションの名前とその設定をマッピングします。各パーティションの設定は、データの取得方法を指定でき、それには get、version、および alias のキーを含む場合があります。
設定キー
get:getキーは、データを取得する W&B オブジェクト (テーブル、イメージなど) の名前を指定します。version:versionキーは、特定のバージョンをアーティファクトから取得したいときに使用されます。alias:aliasキーにより、エイリアスによってアーティファクトを取得することができます。
ワイルドカード設定
ワイルドカード "*" は、全ての非設定パーティションを表します。明示的に partitions オブジェクトに記載されていないパーティションに対するデフォルト設定を提供します。
例、
"*": {
"get": "default_table_name",
},
この設定は、明示的に設定されていないすべてのパーティションに対し、データが default_table_name というテーブルから取得されることを意味します。
特定のパーティション設定
ワイルドカード設定を、特定のキーを持つ特定のパーティション設定で上書きできます。
例、
"yellow": {
"get": "custom_table_name",
},
この設定は、yellow という名前のパーティションに対し、データが custom_table_name というテーブルから取得されることを意味し、ワイルドカード設定を上書きします。
バージョニングとエイリアス
バージョニングおよびエイリアスのために、設定で特定の version および alias のキーを指定することができます。
バージョンの場合、
"orange": {
"version": "v0",
},
この設定は、orange アーティファクトパーティションのバージョン v0 からのデータを取得します。
エイリアスの場合、
"blue": {
"alias": "special_alias",
},
この設定は、アーティファクトパーティションのエイリアス special_alias (設定では blue として参照) の default_table_name テーブルからデータを取得します。
高度な使用法
インテグレーションの高度な使用法を確認するには、以下の完全なコード例を参照してください:
W&B Launch の使用
継続する前に、W&B Launch の使用方法について十分な理解を持っていることをお勧めします。Launch のガイドを読むことを検討してください: /guides/launch。
Dagster インテグレーションは以下を補助します:
- Dagster インスタンス内での1つまたは複数の Launch エージェントの実行。
- あなたの Dagster インスタンス内でのローカル Launch ジョブの実行。
- オンプレミスまたはクラウドでのリモート Launch ジョブ。
Launch エージェント
インテグレーションには run_launch_agent というインポート可能な @op が提供されます。この @op は Launch エージェントを起動し、手動で停止されるまで長時間実行プロセスとして実行します。
エージェントは launch キューをポールし、ジョブを(またはそれらを実行するために外部サービスにディスパッチ)発行するプロセスです。
設定については、リファレンスドキュメント を参照してください
Launchingpad で全プロパティに対する有用な説明を見ることもできます。
シンプルな例
# これを config.yaml に追加します
# 代わりに、Dagit's Launchpad または JobDefinition.execute_in_process で設定することもできます
# 参考: https://docs.dagster.io/concepts/configuration/config-schema#specifying-runtime-configuration
resources:
wandb_config:
config:
entity: my_entity # これをあなたの W&B entity に置き換えます
project: my_project # これをあなたの W&B project に置き換えます
ops:
run_launch_agent:
config:
max_jobs: -1
queues:
- my_dagster_queue
from dagster_wandb.launch.ops import run_launch_agent
from dagster_wandb.resources import wandb_resource
from dagster import job, make_values_resource
@job(
resource_defs={
"wandb_config": make_values_resource(
entity=str,
project=str,
),
"wandb_resource": wandb_resource.configured(
{"api_key": {"env": "WANDB_API_KEY"}}
),
},
)
def run_launch_agent_example():
run_launch_agent()
Launch ジョブ
インテグレーションには run_launch_job というインポート可能な @op が提供されます。この @op はあなたの Launch ジョブを実行します。
Launch ジョブは実行されるためにキューに割り当てられます。キューを作成するか、デフォルトのものを使用することができます。キューを監視する有効なエージェントがあることを確認します。あなたの Dagster インスタンス内でエージェントを実行するだけでなく、Kubernetes でデプロイ可能なエージェントを使用することも考慮に入れることができます。
設定については、リファレンスドキュメント を参照してください。
Launchpad では、すべてのプロパティに対する有用な説明も見ることができます。
シンプルな例
# これを config.yaml に追加します
# 代わりに、Dagit's Launchpad または JobDefinition.execute_in_process で設定することもできます
# 参考: https://docs.dagster.io/concepts/configuration/config-schema#specifying-runtime-configuration
resources:
wandb_config:
config:
entity: my_entity # これをあなたの W&B entity に置き換えます
project: my_project # これをあなたの W&B project に置き換えます
ops:
my_launched_job:
config:
entry_point:
- python
- train.py
queue: my_dagster_queue
uri: https://github.com/wandb/example-dagster-integration-with-launch
from dagster_wandb.launch.ops import run_launch_job
from dagster_wandb.resources import wandb_resource
from dagster import job, make_values_resource
@job(resource_defs={
"wandb_config": make_values_resource(
entity=str,
project=str,
),
"wandb_resource": wandb_resource.configured(
{"api_key": {"env": "WANDB_API_KEY"}}
),
},
)
def run_launch_job_example():
run_launch_job.alias("my_launched_job")() # 私たちはエイリアスを使ってジョブの名前を変更します。
ベストプラクティス
-
IO マネージャーを使用して Artifacts を読み書きします。
Artifact.download()やRun.log_artifact()を直接使用する必要はありません。これらのメソッドはインテグレーションによって処理されます。Artifacts に保存したいデータを単に返し、インテグレーションに任せてください。これにより W&B での Artifact リネージが改善されます。 -
複雑なユースケースのためにのみ Artifact オブジェクトを自分で構築します。 Python オブジェクトと W&B オブジェクトを ops/assets から返すべきです。インテグレーションは Artifact のバンドルを扱います。 複雑なユースケースに対しては、Dagster ジョブ内で直接 Artifact を構築できます。インテグレーション名とバージョン、使用された Python バージョン、ピクルスプロトコルバージョンなどのメタデータ拡充のために、インテグレーションに Artifact を渡すことをお勧めします。
-
メタデータを介してアーティファクトにファイル、ディレクトリ、外部リファレンスを追加します。 インテグレーション
wandb_artifact_configurationオブジェクトを使用して、任意のファイル、ディレクトリ、外部リファレンス(Amazon S3、GCS、HTTP…)を追加します。詳細については Artifact 設定セクション の高度ない例を参照してください。 -
アーティファクトが生成される場合は、@op より @asset を使用してください。 Artifacts はなんらかのアセットです。Dagster がそのアセットを管理する場合は、アセットを使用することをお勧めします。これにより、Dagit Asset Catalog の可観測性が向上します。
-
Dagster 外部で作成されたアーティファクトを読み取るために SourceAsset を使用してください。 これにより、インテグレーションを活用して外部で作成されたアーティファクトを読むことができます。それ以外の場合、インテグレーションで作成されたアーティファクトのみを使用できます。
-
大規模なモデルのための専用コンピュートでのトレーニングを調整するために W&B Launch を使用してください。 小さなモデルは Dagster クラスター内でトレーニングできますし、GPU ノードを持つ Kubernetes クラスターで Dagster を実行することもできます。W&B Launch を使用して大規模なモデルのトレーニングを行うことをお勧めします。これによりインスタンスの負荷が軽減され、より適切なコンピュートへのアクセスが得られます。
-
Dagster 内で実験管理を行う際は、W&B Run ID を Dagster Run ID の値に設定してください。 Run を再開可能にする ことと、W&B Run ID を Dagster Run ID またはお好みの文字列に設定することの両方をお勧めします。この推奨事項に従うことで、Dagster 内でモデルをトレーニングする際に W&B メトリクスと W&B Artifacts がすべて同じ W&B Run に格納されていることが保証されます。
W&B Run ID を Dagster Run ID に設定するか、
wandb.init(
id=context.run_id,
resume="allow",
...
)
独自の W&B Run ID を選び、それを IO マネージャー設定に渡します。
wandb.init(
id="my_resumable_run_id",
resume="allow",
...
)
@job(
resource_defs={
"io_manager": wandb_artifacts_io_manager.configured(
{"wandb_run_id": "my_resumable_run_id"}
),
}
)
-
大きな W&B Artifacts のために必要なデータだけを get や get_path で収集します。 デフォルトでインテグレーションはアーティファクト全体をダウンロードします。非常に大きなアーティファクトを使用している場合は、特定のファイルやオブジェクトだけを収集することをお勧めします。これにより速度が向上し、リソースの利用が向上します。
-
Python オブジェクトに対してユースケースに合わせてピクルスモジュールを適応させます。 デフォルトで W&Bインテグレーションは標準の pickle モジュールを使用します。しかし、一部のオブジェクトはこれと互換性がありません。例えば、yield を持つ関数はシリアライズしようとするとエラーを発生します。W&B は他のピクルスベースのシリアライズモジュール(dill, cloudpickle, joblib) をサポートしています。
また、ONNX や PMML など、より高度なシリアライズによってシリアライズされた文字列を返すか、直接 Artifact を作成することもできます。適切な選択はユースケースに依存します。このテーマに関しては、利用可能な文献を参考にしてください。
6.2 - Minikube でシングルノード GPU クラスターを起動する
W&B LaunchをMinikubeクラスターにセットアップし、GPU のワークロードをスケジュールして実行できるようにします。
このチュートリアルは、複数のGPUを搭載したマシンへの直接アクセスがあるユーザーを対象としています。このチュートリアルは、クラウドマシンをレンタルしているユーザーには意図されていません。
クラウドマシン上でminikubeクラスターをセットアップしたい場合、W&Bはクラウドプロバイダーを使用したGPU対応のKubernetesクラスターを作成することを推奨します。たとえば、AWS、GCP、Azure、Coreweave、その他のクラウドプロバイダーには、GPU対応のKubernetesクラスターを作成するためのツールがあります。
単一のGPUを搭載したマシンでGPUをスケジュールするためにminikubeクラスターをセットアップしたい場合、W&BはLaunch Dockerキューを使用することを推奨します。このチュートリアルを楽しくフォローすることはできますが、GPUのスケジューリングはあまり役に立たないでしょう。
背景
Nvidia コンテナツールキットのおかげで、DockerでGPUを有効にしたワークフローを簡単に実行できるようになりました。制限の一つに、ボリュームによるGPUのスケジューリングのネイティブなサポートがない点があります。docker run コマンドでGPUを使用したい場合は、特定のGPUをIDでリクエストするか、存在するすべてのGPUをリクエストする必要がありますが、これは多くの分散GPUを有効にしたワークロードを非現実的にします。Kubernetesはボリュームリクエストによるスケジューリングをサポートしていますが、GPUスケジューリングを備えたローカルKubernetesクラスターのセットアップには、最近までかなりの時間と労力がかかっていました。Minikubeは、シングルノードKubernetesクラスターを実行するための最も人気のあるツールの1つであり、最近 GPUスケジューリングのサポート をリリースしました 🎉 このチュートリアルでは、マルチGPUマシンにMinikubeクラスターを作成し、W&B Launchを使用してクラスターに並行して安定的な拡散推論ジョブを起動します 🚀
前提条件
始める前に、次のものが必要です:
- W&Bアカウント。
- 以下がインストールされているLinuxマシン:
- Docker runtime
- 使用したいGPU用のドライバ
- Nvidiaコンテナツールキット
n1-standard-16 Google Cloud Compute Engineインスタンスを使用しました。Launchジョブ用のキューを作成
最初に、launchジョブ用のlaunchキューを作成します。
- wandb.ai/launch(またはプライベートW&Bサーバーを使用している場合は
<your-wandb-url>/launch)に移動します。 - 画面の右上隅にある青い Create a queue ボタンをクリックします。キュー作成のドロワーが画面の右側からスライドアウトします。
- エンティティを選択し、名前を入力し、キューのタイプとして Kubernetes を選択します。
- ドロワーの Config セクションには、launchキュー用のKubernetesジョブ仕様を入力します。このキューから起動されたrunは、このジョブ仕様を使用して作成されるため、必要に応じてジョブをカスタマイズするためにこの設定を変更できます。このチュートリアルでは、下記のサンプル設定をキューの設定にYAMLまたはJSONとしてコピー&ペーストできます:
spec:
template:
spec:
containers:
- image: ${image_uri}
resources:
limits:
cpu: 4
memory: 12Gi
nvidia.com/gpu: '{{gpus}}'
restartPolicy: Never
backoffLimit: 0
{
"spec": {
"template": {
"spec": {
"containers": [
{
"image": "${image_uri}",
"resources": {
"limits": {
"cpu": 4,
"memory": "12Gi",
"nvidia.com/gpu": "{{gpus}}"
}
}
}
],
"restartPolicy": "Never"
}
},
"backoffLimit": 0
}
}
キュー設定の詳細については、 Set up Launch on Kubernetesと Advanced queue setup guide を参照してください。
${image_uri} と {{gpus}} 文字列は、キュー設定で使用できる2種類の変数テンプレートの例です。${image_uri} テンプレートは、エージェントが起動するジョブの画像URIに置き換えられます。{{gpus}} テンプレートは、ジョブを送信する際にlaunch UI、CLI、またはSDKからオーバーライドできるテンプレート変数の作成に使用されます。これらの値はジョブ仕様に配置され、ジョブで使用される画像とGPUリソースを制御する正しいフィールドを変更します。
- Parse configuration ボタンをクリックして
gpusテンプレート変数をカスタマイズし始めます。 - Type を
Integerに設定し、 Default 、 Min 、 Max を選択した値に設定します。このテンプレート変数の制約を違反するrunをこのキューに送信しようとすると、拒否されます。
- Create queue をクリックしてキューを作成します。新しいキューのキューページにリダイレクトされます。
次のセクションでは、作成したキューからジョブをプルして実行できるエージェントをセットアップします。
Docker + NVIDIA CTKのセットアップ
既にマシンでDockerとNvidiaコンテナツールキットを設定している場合は、このセクションをスキップできます。
Dockerのドキュメントを参照して、システム上でのDockerコンテナエンジンのセットアップ手順を確認してください。
Dockerがインストールされたら、その後にNvidiaコンテナツールキットをNvidiaのドキュメント に従ってインストールします。
コンテナランタイムがGPUにアクセスできることを確認するには、次を実行します:
docker run --gpus all ubuntu nvidia-smi
マシンに接続されているGPUを記述する nvidia-smi の出力が表示されるはずです。たとえば、私たちのセットアップでは、出力は次のようになります:
Wed Nov 8 23:25:53 2023
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 525.105.17 Driver Version: 525.105.17 CUDA Version: 12.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla T4 Off | 00000000:00:04.0 Off | 0 |
| N/A 38C P8 9W / 70W | 2MiB / 15360MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| 1 Tesla T4 Off | 00000000:00:05.0 Off | 0 |
| N/A 38C P8 9W / 70W | 2MiB / 15360MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| 2 Tesla T4 Off | 00000000:00:06.0 Off | 0 |
| N/A 40C P8 9W / 70W | 2MiB / 15360MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| 3 Tesla T4 Off | 00000000:00:07.0 Off | 0 |
| N/A 39C P8 9W / 70W | 2MiB / 15360MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
Minikubeの設定
MinikubeのGPUサポートにはバージョンv1.32.0以上が必要です。Minikubeのインストールドキュメント を参照して、最新のインストール方法を確認してください。このチュートリアルでは、次のコマンドを使用して最新のMinikubeリリースをインストールしました:
curl -LO https://storage.googleapis.com/minikube/releases/latest/minikube-linux-amd64
sudo install minikube-linux-amd64 /usr/local/bin/minikube
次のステップは、GPUを使用してminikubeクラスターを開始することです。マシン上で以下を実行します:
minikube start --gpus all
上記のコマンドの出力は、クラスターが正常に作成されたかどうかを示します。
launch エージェントを開始
新しいクラスター向けのlaunchエージェントは、wandb launch-agentを直接呼び出すか、W&Bによって管理されるHelmチャートを使用してlaunchエージェントをデプロイすることによって開始されます。
このチュートリアルでは、エージェントをホストマシンで直接実行します。
エージェントをローカルで実行するには、デフォルトのKubernetes APIコンテキストがMinikubeクラスターを指していることを確認してください。次に、以下を実行してエージェントの依存関係をインストールします:
pip install "wandb[launch]"
エージェントの認証を設定するには、wandb loginを実行するか、WANDB_API_KEY環境変数を設定します。
エージェントを開始するには、次のコマンドを実行します:
wandb launch-agent -j <max-number-concurrent-jobs> -q <queue-name> -e <queue-entity>
ターミナル内でlaunchエージェントがポーリングメッセージを印刷し始めるのを確認できます。
おめでとうございます、launchエージェントがlaunchキューのポーリングを行っています。キューにジョブが追加されると、エージェントがそれを受け取り、Minikubeクラスターで実行するようスケジュールします。
ジョブを起動
エージェントにジョブを送信しましょう。W&Bアカウントにログインしているターミナルから、以下のコマンドで簡単な “hello world” を起動できます:
wandb launch -d wandb/job_hello_world:main -p <target-wandb-project> -q <your-queue-name> -e <your-queue-entity>
好きなジョブやイメージでテストできますが、クラスターがイメージをプルできることを確認してください。追加のガイダンスについては、Minikubeのドキュメントを参照してください。また、私たちの公開ジョブを使用してテストすることもできます。
(オプション) NFSを用いたモデルとデータキャッシング
ML ワークロードのために、複数のジョブが同じデータにアクセスできるようにしたい場合があります。たとえば、大規模なアセット(データセットやモデルの重みなど)の再ダウンロードを避けるために共有キャッシュを持つことができます。Kubernetesは、永続ボリュームと永続ボリュームクレームを通じてこれをサポートしています。永続ボリュームは、Kubernetesワークロードにおいて volumeMounts を作成し、共有キャッシュへの直接ファイルシステムアクセスを提供します。
このステップでは、モデルの重みをキャッシュとして共有するために使用できるネットワークファイルシステム(NFS)サーバーをセットアップします。最初のステップはNFSをインストールし、設定することです。このプロセスはオペレーティングシステムによって異なります。私たちのVMはUbuntuを実行しているので、nfs-kernel-serverをインストールし、/srv/nfs/kubedataでエクスポートを設定しました:
sudo apt-get install nfs-kernel-server
sudo mkdir -p /srv/nfs/kubedata
sudo chown nobody:nogroup /srv/nfs/kubedata
sudo sh -c 'echo "/srv/nfs/kubedata *(rw,sync,no_subtree_check,no_root_squash,no_all_squash,insecure)" >> /etc/exports'
sudo exportfs -ra
sudo systemctl restart nfs-kernel-server
ホストファイルシステムのサーバーのエクスポート先と、NFSサーバーのローカルIPアドレスをメモしておいてください。次のステップでこの情報が必要です。
次に、このNFSの永続ボリュームと永続ボリュームクレームを作成する必要があります。永続ボリュームは非常にカスタマイズ可能ですが、シンプlicityのために、ここではシンプルな設定を使用します。
以下のyamlを nfs-persistent-volume.yaml というファイルにコピーし、希望のボリュームキャパシティとクレームリクエストを記入してください。PersistentVolume.spec.capcity.storage フィールドは、基になるボリュームの最大サイズを制御します。PersistentVolumeClaim.spec.resources.requests.storage は、特定のクレームに割り当てられるボリュームキャパシティを制限するために使用できます。私たちのユースケースでは、それぞれに同じ値を使用するのが理にかなっています。
apiVersion: v1
kind: PersistentVolume
metadata:
name: nfs-pv
spec:
capacity:
storage: 100Gi # あなたの希望の容量に設定してください。
accessModes:
- ReadWriteMany
nfs:
server: <your-nfs-server-ip> # TODO: ここを記入してください。
path: '/srv/nfs/kubedata' # またはあなたのカスタムパス
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: nfs-pvc
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 100Gi # あなたの希望の容量に設定してください。
storageClassName: ''
volumeName: nfs-pv
以下のコマンドでクラスターにリソースを作成します:
kubectl apply -f nfs-persistent-volume.yaml
私たちのrunがこのキャッシュを使用できるようにするためには、launchキューの設定に volumes と volumeMounts を追加する必要があります。launchの設定を編集するには、再び wandb.ai/launch(またはwandbサーバー上のユーザーの場合は<your-wandb-url>/launch)に戻り、キューを見つけ、キューページに移動し、その後、Edit config タブをクリックします。元の設定を次のように変更できます:
spec:
template:
spec:
containers:
- image: ${image_uri}
resources:
limits:
cpu: 4
memory: 12Gi
nvidia.com/gpu: "{{gpus}}"
volumeMounts:
- name: nfs-storage
mountPath: /root/.cache
restartPolicy: Never
volumes:
- name: nfs-storage
persistentVolumeClaim:
claimName: nfs-pvc
backoffLimit: 0
{
"spec": {
"template": {
"spec": {
"containers": [
{
"image": "${image_uri}",
"resources": {
"limits": {
"cpu": 4,
"memory": "12Gi",
"nvidia.com/gpu": "{{gpus}}"
},
"volumeMounts": [
{
"name": "nfs-storage",
"mountPath": "/root/.cache"
}
]
}
}
],
"restartPolicy": "Never",
"volumes": [
{
"name": "nfs-storage",
"persistentVolumeClaim": {
"claimName": "nfs-pvc"
}
}
]
}
},
"backoffLimit": 0
}
}
これで、NFSはジョブを実行しているコンテナの /root/.cache にマウントされます。コンテナが root 以外のユーザーとして実行される場合、マウントパスは調整が必要です。HuggingfaceのライブラリとW&B Artifactsは、デフォルトで $HOME/.cache/ を利用しているため、ダウンロードは一度だけ行われるはずです。
安定拡散と遊ぶ
新しいシステムをテストするために、安定的な拡散の推論パラメータを実験します。 デフォルトのプロンプトと常識的なパラメータでシンプルな安定的拡散推論ジョブを実行するには、次のコマンドを実行します:
wandb launch -d wandb/job_stable_diffusion_inference:main -p <target-wandb-project> -q <your-queue-name> -e <your-queue-entity>
上記のコマンドは、あなたのキューに wandb/job_stable_diffusion_inference:main コンテナイメージを送信します。
エージェントがジョブを受け取り、クラスターで実行するためにスケジュールするとき、接続に依存してイメージがプルされるまで時間がかかることがあります。
ジョブのステータスはwandb.ai/launch(またはwandbサーバー上のユーザーの場合の<your-wandb-url>/launch)キューページで確認できます。
runが終了すると、指定したプロジェクトにジョブアーティファクトがあるはずです。
プロジェクトのジョブページ (<project-url>/jobs) にアクセスしてジョブアーティファクトを見つけることができます。デフォルトの名前は job-wandb_job_stable_diffusion_inference ですが、ジョブのページでジョブ名の横にある鉛筆アイコンをクリックして好きなように変更できます。
このジョブを使って、クラスター上でさらに安定的な拡散推論を実行することができます。 ジョブページから、右上隅にある Launch ボタンをクリックして新しい推論ジョブを設定し、キューに送信します。ジョブの設定ページは、元のrunからのパラメータで自動的に入力されますが、 Overrides セクションで値を変更することで好きなように変更できます。
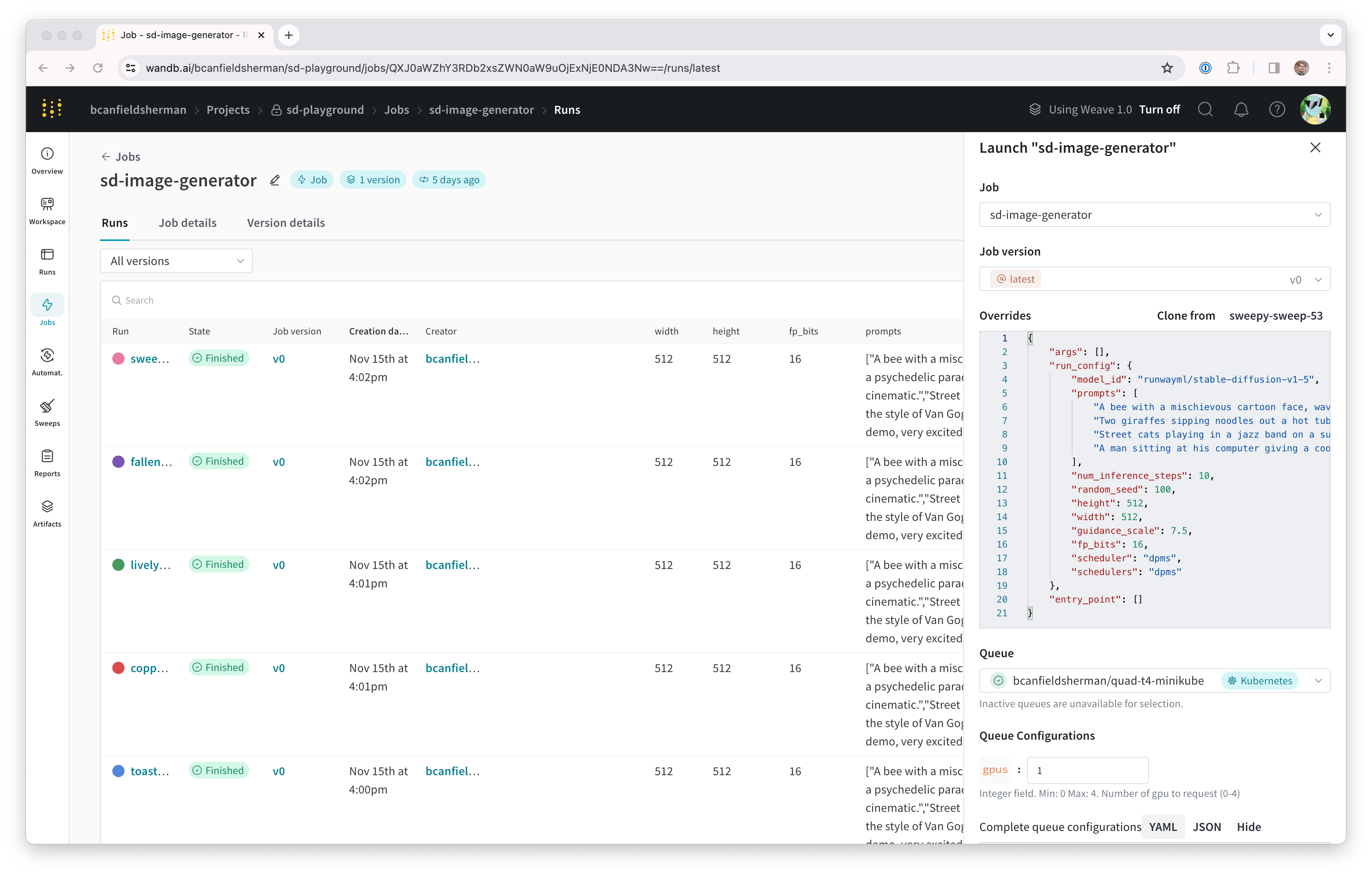
6.3 - NVIDIA NeMo 推論マイクロサービスデプロイジョブ
モデルアーティファクトを W&B から NVIDIA NeMo Inference Microservice にデプロイします。これを行うには、W&B Launch を使用します。W&B Launch はモデルアーティファクトを NVIDIA NeMo Model に変換し、稼働中の NIM/Triton サーバーにデプロイします。
W&B Launch は現在、以下の互換性のあるモデルタイプを受け入れています:
a2-ultragpu-1g で約1分かかります。クイックスタート
-
launch キューを作成する まだ持っていない場合は、以下に例としてキュー設定を示します。
net: host gpus: all # 特定の GPU セットまたは `all` を使用してすべてを使うこともできます runtime: nvidia # nvidia コンテナランタイムも必要です volume: - model-store:/model-store/
-
プロジェクトにこのジョブを作成します:
wandb job create -n "deploy-to-nvidia-nemo-inference-microservice" \ -e $ENTITY \ -p $PROJECT \ -E jobs/deploy_to_nvidia_nemo_inference_microservice/job.py \ -g andrew/nim-updates \ git https://github.com/wandb/launch-jobs -
GPU マシンでエージェントを起動します:
wandb launch-agent -e $ENTITY -p $PROJECT -q $QUEUE -
希望する設定でデプロイメントローンチジョブを Launch UI から送信します。
- CLI から送信することもできます:
wandb launch -d gcr.io/playground-111/deploy-to-nemo:latest \ -e $ENTITY \ -p $PROJECT \ -q $QUEUE \ -c $CONFIG_JSON_FNAME
- CLI から送信することもできます:
-
Launch UI でデプロイメントプロセスを追跡できます。
-
完了すると、すぐにエンドポイントに curl してモデルをテストできます。モデル名は常に
ensembleです。#!/bin/bash curl -X POST "http://0.0.0.0:9999/v1/completions" \ -H "accept: application/json" \ -H "Content-Type: application/json" \ -d '{ "model": "ensemble", "prompt": "Tell me a joke", "max_tokens": 256, "temperature": 0.5, "n": 1, "stream": false, "stop": "string", "frequency_penalty": 0.0 }'
6.4 - Volcano でマルチノードジョブをローンチする
このチュートリアルでは、Kubernetes上でW&BとVolcanoを使用してマルチノードトレーニングのジョブをローンチするプロセスを説明します。
概要
このチュートリアルでは、W&B Launchを使用してKubernetes上でマルチノードジョブを実行する方法を学びます。私たちが従うステップは以下の通りです:
- Weights & BiasesのアカウントとKubernetesクラスターを確認する。
- Volcanoジョブ用のローンチキューを作成する。
- KubernetesクラスターにLaunchエージェントをデプロイする。
- 分散トレーニングジョブを作成する。
- 分散トレーニングをローンチする。
必要条件
開始する前に必要なもの:
- Weights & Biasesアカウント
- Kubernetesクラスター
ローンチキューを作成する
最初のステップはローンチキューを作成することです。wandb.ai/launchにアクセスし、画面の右上隅にある青いCreate a queueボタンを押します。右側からキュー作成ドロワーがスライドアウトします。エンティティを選択し、名前を入力し、キューのタイプとしてKubernetesを選択します。
設定セクションで、volcanoのジョブのテンプレートを入力します。このキューからローンチされたすべてのrunはこのジョブ仕様を使用して作成されるため、ジョブをカスタマイズしたい場合はこの設定を変更できます。
この設定ブロックには、Kubernetesジョブ仕様、volcanoジョブ仕様、または他のカスタムリソース定義(CRD)をローンチするために使用することができます。設定ブロック内のマクロを利用して、この仕様の内容を動的に設定することができます。
このチュートリアルでは、volcanoのpytorchプラグインを利用したマルチノードpytorchトレーニングの設定を使用します。以下の設定をYAMLまたはJSONとしてコピーして貼り付けることができます:
kind: Job
spec:
tasks:
- name: master
policies:
- event: TaskCompleted
action: CompleteJob
replicas: 1
template:
spec:
containers:
- name: master
image: ${image_uri}
imagePullPolicy: IfNotPresent
restartPolicy: OnFailure
- name: worker
replicas: 1
template:
spec:
containers:
- name: worker
image: ${image_uri}
workingDir: /home
imagePullPolicy: IfNotPresent
restartPolicy: OnFailure
plugins:
pytorch:
- --master=master
- --worker=worker
- --port=23456
minAvailable: 1
schedulerName: volcano
metadata:
name: wandb-job-${run_id}
labels:
wandb_entity: ${entity_name}
wandb_project: ${project_name}
namespace: wandb
apiVersion: batch.volcano.sh/v1alpha1
{
"kind": "Job",
"spec": {
"tasks": [
{
"name": "master",
"policies": [
{
"event": "TaskCompleted",
"action": "CompleteJob"
}
],
"replicas": 1,
"template": {
"spec": {
"containers": [
{
"name": "master",
"image": "${image_uri}",
"imagePullPolicy": "IfNotPresent"
}
],
"restartPolicy": "OnFailure"
}
}
},
{
"name": "worker",
"replicas": 1,
"template": {
"spec": {
"containers": [
{
"name": "worker",
"image": "${image_uri}",
"workingDir": "/home",
"imagePullPolicy": "IfNotPresent"
}
],
"restartPolicy": "OnFailure"
}
}
}
],
"plugins": {
"pytorch": [
"--master=master",
"--worker=worker",
"--port=23456"
]
},
"minAvailable": 1,
"schedulerName": "volcano"
},
"metadata": {
"name": "wandb-job-${run_id}",
"labels": {
"wandb_entity": "${entity_name}",
"wandb_project": "${project_name}"
},
"namespace": "wandb"
},
"apiVersion": "batch.volcano.sh/v1alpha1"
}
ドロワーの下部にあるCreate queueボタンをクリックしてキューの作成を完了します。
Volcanoをインストールする
KubernetesクラスターにVolcanoをインストールするには、公式インストールガイドに従ってください。
ローンチエージェントをデプロイする
キューを作成した後は、キューからジョブを引き出して実行するためにローンチエージェントをデプロイする必要があります。これを行う最も簡単な方法は、W&Bの公式helm-chartsリポジトリからlaunch-agentチャートを使用することです。READMEに記載された指示に従って、Kubernetesクラスターにチャートをインストールし、エージェントが先ほど作成したキューをポーリングするように設定してください。
トレーニングジョブを作成する
Volcanoのpytorchプラグインは、pytorch DPPが機能するために必要な環境変数(MASTER_ADDR、RANK、WORLD_SIZEなど)を自動で設定します。ただし、pytorchコードがDDPを正しく使用している場合に限ります。カスタムのPythonコードでDDPを使用する方法の詳細については、pytorchのドキュメントを参照してください。
Trainerを使用したマルチノードトレーニングとも互換性があります。ローンチ 🚀
キューとクラスターのセットアップが完了したので、分散トレーニングを開始する時がきました。最初に、Volcanoのpytorchプラグインを使用してランダムデータ上でシンプルなマルチレイヤパーセプトロンをトレーニングするa jobを使用します。このジョブのソースコードはこちらで見つけることができます。
このジョブをローンチするには、ジョブのページにアクセスし、画面の右上にあるLaunchボタンをクリックします。ジョブをローンチするキューを選択するように促されます。
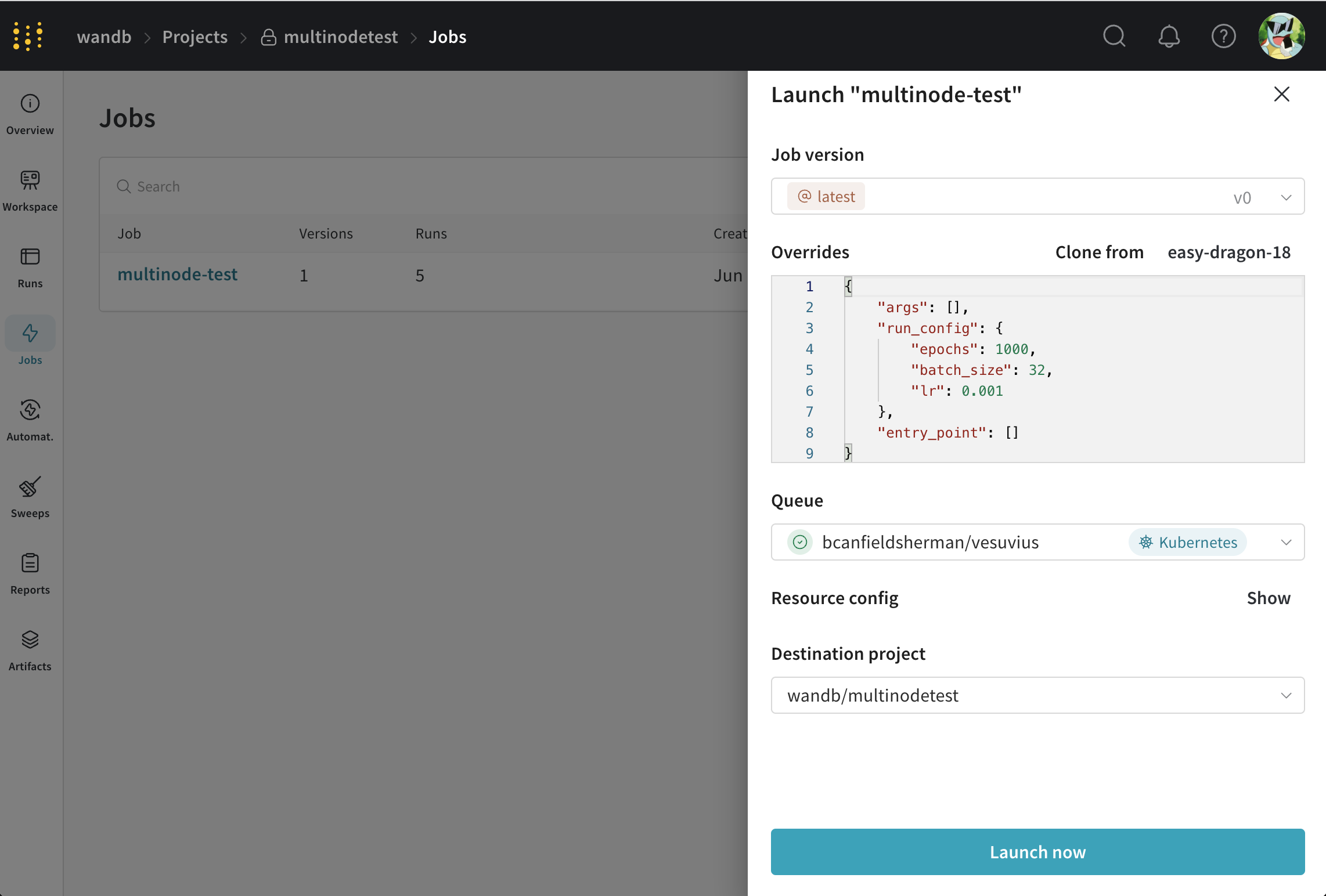
- ジョブのパラメータを好きなように設定し、
- 先ほど作成したキューを選択します。
- Resource configセクションでVolcanoジョブを変更してジョブのパラメータを変更します。例えば、
workerタスクのreplicasフィールドを変更することによってワーカーの数を変更できます。 - Launchをクリック 🚀
W&B UIからジョブの進捗をモニターし、必要に応じてジョブを停止できます。
7 - ジョブを作成してデプロイする
7.1 - ローンンチ ジョブを表示する
以下のページでは、キューに追加されたローンンチジョブの情報を表示する方法を説明します。
ジョブの表示
W&B アプリケーションを使用してキューに追加されたジョブを表示します。
- https://wandb.ai/home にある W&B アプリケーションにアクセスします。
- 左側のサイドバーにある Applications セクション内の Launch を選択します。
- All entities ドロップダウンを選択し、ローンンチジョブが所属するエンティティを選択します。
- Launch Application ページから折りたたみ可能なUIを展開し、その特定のキューに追加されたジョブのリストを表示します。
例えば、次の画像は、job-source-launch_demo-canonicalというジョブから作成された2つのrunを示しています。このジョブは Start queue というキューに追加されました。キューにリストされている最初のrunは resilient-snowball と呼ばれ、2番目のrunは earthy-energy-165 と呼ばれます。
W&B アプリケーションUI内で、ローンンチジョブから作成されたrunに関する次のような追加情報を見つけることができます:
- Run: そのジョブに割り当てられた W&B run の名前。
- Job ID: ジョブの名前。
- Project: runが所属するプロジェクトの名前。
- Status: キューに入れられたrunのステータス。
- Author: run を作成した W&B エンティティ。
- Creation date: キューが作成されたタイムスタンプ。
- Start time: ジョブが開始されたタイムスタンプ。
- Duration: ジョブのrunを完了するのにかかった時間(秒単位)。
ジョブのリスト
プロジェクト内に存在するジョブのリストを W&B CLI を使用して表示します。W&B job list コマンドを使用し、--project および --entity フラグにローンンチジョブが所属するプロジェクト名とエンティティ名を指定します。
wandb job list --entity your-entity --project project-name
ジョブのステータスを確認する
次の表は、キューに入れられたrunが持つ可能性のあるステータスを定義しています:
| ステータス | 説明 |
|---|---|
| Idle | runはアクティブなエージェントのないキューにあります。 |
| Queued | runはエージェントが処理するのを待っているキューにあります。 |
| Pending | run はエージェントによって取得されましたが、まだ開始されていません。これはクラスターでリソースが利用できないことが原因である可能性があります。 |
| Running | run は現在実行中です。 |
| Killed | ジョブはユーザーによって終了されました。 |
| Crashed | run はデータの送信を停止したか、正常に開始しませんでした。 |
| Failed | run は非ゼロの終了コードで終了したか、run の開始に失敗しました。 |
| Finished | ジョブは正常に完了しました。 |
7.2 - ローンンチキューを監視する
Use the interactive キュー監視ダッシュボード を使用して、launch キューが混雑しているかアイドル状態かを表示し、実行中のワークロードを視覚化し、非効率なジョブを見つけます。launch キューのダッシュボードは、計算ハードウェアやクラウドリソースを効果的に使用しているかどうかを判断するのに特に役立ちます。
詳細な分析を行うには、ページから W&B の実験管理ワークスペースや Datadog、NVIDIA Base Command、クラウドコンソールなどの外部インフラストラクチャーモニタリングプロバイダーへのリンクを利用します。
ダッシュボードとプロット
Monitor タブを使用して、過去 7 日間に発生したキューの活動を表示します。左側のパネルを使用して、時間範囲、グループ化、およびフィルターを制御します。
ダッシュボードには、パフォーマンスと効率性に関するよくある質問に対する答えが表示されるいくつかのプロットが含まれています。以下のセクションでは、キューダッシュボードの UI 要素について説明します。
ジョブステータス
ジョブステータス プロットは、各時間間隔において何件のジョブが実行中、保留中、キュー中、または完了済みであるかを示します。この ジョブステータス プロットを使用して、キューのアイドル期間を特定します。
例えば、固定リソース (たとえば、DGX BasePod) を持っているとします。固定リソースを使用しているキューがアイドル状態であることを観察した場合、低優先度の先取可能 launch ジョブ (例えば Sweeps) を実行する機会があるかもしれません。
一方、クラウドリソースを使用しており、定期的な活動の急増を観察した場合、それは特定の時間帯にリソースを予約してお金を節約する機会を示すかもしれません。
プロットの右側には、launch ジョブのステータス を示す色が表示されるキーがあります。
Queued 項目は、ワークロードを他のキューにシフトする機会を示すかもしれません。失敗の急増は、launch ジョブの設定で助けが必要なユーザーを特定するのに役立ちます。キュー時間
キュー時間 プロットは、特定の日付または時間範囲で launch ジョブがキュー上にあった時間(秒数)を表示します。
x 軸は指定した時間枠を、y 軸は launch ジョブが launch キュー上にあった時間(秒数)を示します。例えば、ある日に 10 件の launch ジョブがキューに入っていると仮定します。それら 10 件の launch ジョブがそれぞれ平均 60 秒待機する場合、キュー時間 プロットは 600 秒を表示します。
左バーの Grouping コントロールを使用して、各ジョブの色をカスタマイズします。
特に、ユーザーとジョブが限られたキュー容量にどの程度影響を受けているかを特定するのに役立ちます。
ジョブ実行
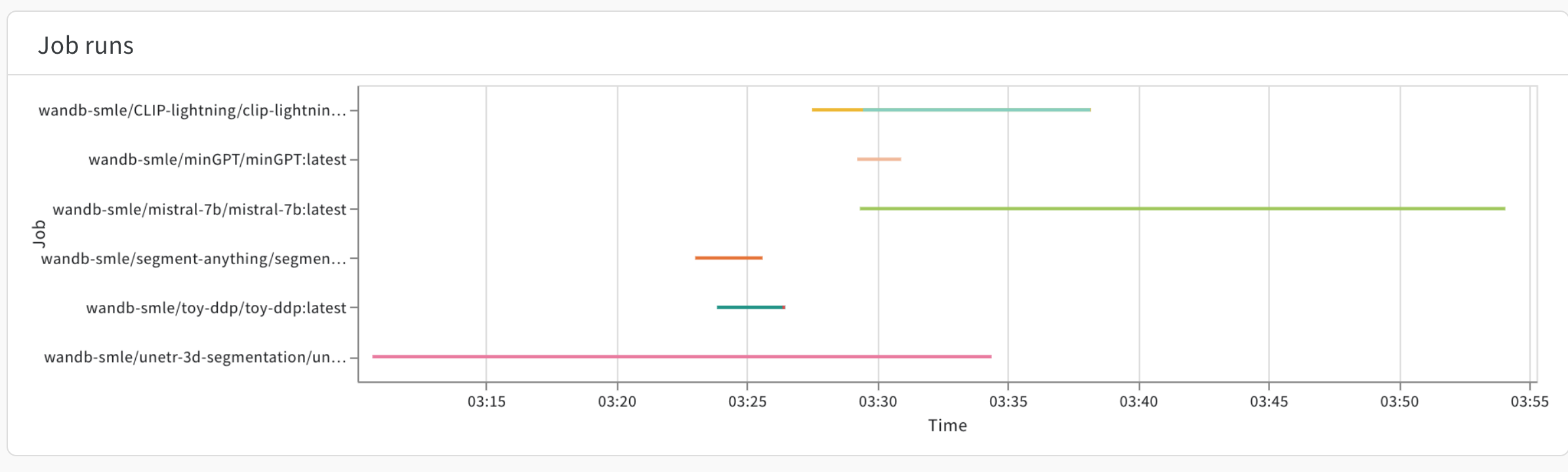
このプロットは、指定した期間に実行されたジョブの開始と終了を、各 run ごとに異なる色で示しています。これにより、指定した時間にキューがどのワークロードを処理していたかを一目で確認できます。
パネルの右下にある Select ツールを使用して、ジョブをブラシオーバーして下のテーブルに詳細を表示します。
CPU と GPU の使用
ジョブによる GPU の使用、ジョブによる CPU の使用、ジョブによる GPU メモリ、ジョブによるシステムメモリ を使用して、launch ジョブの効率性を確認します。
例えば、ジョブによる GPU メモリ を使用して、W&B run が完了するのに長い時間を要し、CPU コアの使用率が低かったかどうかを確認できます。
各プロットの x 軸は W&B run (launch ジョブによって作成された) の期間を秒単位で示しています。データポイントにマウスを重ねて、W&B run の情報(run ID、run の属するプロジェクト、W&B run を作成した launch ジョブなど)を確認します。
エラー
エラーパネル は、特定の launch キューで発生したエラーを表示します。より具体的には、エラーパネルはエラーが発生したタイムスタンプ、エラーが発生した launch ジョブの名前、および作成されたエラーメッセージを示します。デフォルトでは、エラーは最新のものから古いものの順に並べられます。
エラーパネル を使用してユーザーを特定し、ブロックを解除します。
外部リンク
キューの可観測性ダッシュボードのビューはすべてのキュータイプで一貫していますが、多くの場合、環境固有のモニタに直接ジャンプすることが有用です。これを達成するために、コンソールからキューの可観測性ダッシュボードに直接リンクを追加します。
ページの下部で Manage Links をクリックしてパネルを開きます。必要なページの完全な URL を追加します。次にラベルを追加します。追加したリンクは External Links セクションに表示されます。
7.3 - ローンンチジョブを作成する
Launch ジョブは、W&B Runs を再現するための設計図です。ジョブは、ワークロードを実行するために必要なソースコード、依存関係、および入力をキャプチャする W&B Artifacts です。
wandb launch コマンドでジョブを作成して実行します。
wandb job create コマンドを使用します。詳細については、コマンドリファレンスドキュメント を参照してください。Git ジョブ
W&B Launch を使って、ソースコードや他の追跡されたアセットをリモート git リポジトリの特定のコミット、ブランチ、またはタグからクローンする Git ベースのジョブを作成できます。--uri または -u フラグを使用して、コードを含む URI を指定し、オプションとして --build-context フラグを使用してサブディレクトリーを指定します。
次のコマンドを使用して git リポジトリから “hello world” ジョブを実行します:
wandb launch --uri "https://github.com/wandb/launch-jobs.git" --build-context jobs/hello_world --dockerfile Dockerfile.wandb --project "hello-world" --job-name "hello-world" --entry-point "python job.py"
このコマンドは次のことを行います:
- W&B Launch ジョブリポジトリ を一時ディレクトリーにクローンします。
- hello プロジェクト内に hello-world-git という名前のジョブを作成します。このジョブはリポジトリのデフォルトブランチのトップにあるコミットに関連付けられています。
jobs/hello_worldディレクトリーとDockerfile.wandbからコンテナイメージをビルドします。- コンテナを開始し、
python job.pyを実行します。
特定のブランチまたはコミットハッシュからジョブをビルドするには、-g、--git-hash 引数を追加します。引数の完全なリストについては、wandb launch --help を実行してください。
リモート URL 形式
Launch ジョブに関連付けられた git リモートは、HTTPS または SSH URL のいずれかを使用できます。URL タイプは、ジョブのソースコードを取得するために使用されるプロトコルを決定します。
| リモート URL タイプ | URL 形式 | アクセスと認証の要件 |
|---|---|---|
| https | https://github.com/organization/repository.git |
git リモートでの認証用のユーザー名とパスワード |
| ssh | git@github.com:organization/repository.git |
git リモートでの認証用の SSH キー |
正確な URL 形式はホスティングプロバイダーによって異なることに注意してください。wandb launch --uri で作成されたジョブは、指定された --uri で指定された転送プロトコルを使用します。
コードアーティファクトジョブ
ジョブは、任意のソースコードから W&B Artifact に保存して作成できます。ローカルディレクトリーを --uri または -u 引数で使用して、新しいコードアーティファクトとジョブを作成します。
まず、空のディレクトリーを作成し、次の内容を持つ Python スクリプト main.py を追加します:
import wandb
with wandb.init() as run:
run.log({"metric": 0.5})
次の内容を持つファイル requirements.txt を追加します:
wandb>=0.17.1
ディレクトリーをコードアーティファクトとして記録し、次のコマンドでジョブを起動します:
wandb launch --uri . --job-name hello-world-code --project launch-quickstart --entry-point "python main.py"
前のコマンドは次のことを行います:
- 現在のディレクトリーを
hello-world-codeという名前のコードアーティファクトとして記録します。 launch-quickstartプロジェクト内にhello-world-codeという名前のジョブを作成します。- 現在のディレクトリーと Launch のデフォルトの Dockerfile からコンテナイメージをビルドします。デフォルトの Dockerfile は
requirements.txtファイルをインストールし、エントリーポイントをpython main.pyに設定します。
イメージジョブ
別の方法として、事前に作成された Docker イメージからジョブを構築することもできます。これは、すでに ML コード用の確立されたビルドシステムを持っている場合や、ジョブのコードや要件を調整することはほとんどなく、ハイパーパラメーターや異なるインフラストラクチャー規模で実験したい場合に役立ちます。
イメージは Docker レジストリから取得され、指定されたエントリーポイントまたは指定されていない場合はデフォルトのエントリーポイントで実行されます。Docker イメージからジョブを作成して実行するには、--docker-image オプションに完全なイメージタグを渡します。
事前に作成されたイメージからシンプルなジョブを実行するには、次のコマンドを使用します:
wandb launch --docker-image "wandb/job_hello_world:main" --project "hello-world"
自動ジョブ作成
W&B は、追跡されたソースコードを持つ任意の Run に対してジョブを自動的に作成して追跡します。この Run が Launch で作成されていなくてもです。Run が追跡されたソースコードを持つと見なされる条件は次の3つのうちのいずれかを満たした場合です:
- Run に関連付けられた git リモートとコミットハッシュがある
- Run がコードアーティファクトを記録した (詳細については
Run.log_codeを参照) - Run が
WANDB_DOCKER環境変数をイメージタグに設定した Docker コンテナで実行された
Git リモート URL は、W&B Run によって自動的に作成された Launch ジョブの場合、ローカルの git リポジトリから推測されます。
Launch ジョブ名
デフォルトでは、W&B はジョブ名を自動的に生成します。名前は、ジョブの作成方法 (GitHub、コードアーティファクト、Docker イメージ) によって生成されます。別の方法として、環境変数または W&B Python SDK で Launch ジョブの名前を定義できます。
次の表は、ジョブソースに基づくデフォルトのジョブの命名規則について説明しています:
| ソース | 命名規則 |
|---|---|
| GitHub | job-<git-remote-url>-<path-to-script> |
| Code artifact | job-<code-artifact-name> |
| Docker image | job-<image-name> |
W&B 環境変数または W&B Python SDK でジョブに名前を付けます
WANDB_JOB_NAME 環境変数を希望のジョブ名に設定します。例:
WANDB_JOB_NAME=awesome-job-name
wandb.Settings でジョブの名前を定義します。そして、このオブジェクトを使用して W&B を wandb.init で初期化する際に渡します。例:
settings = wandb.Settings(job_name="my-job-name")
wandb.init(settings=settings)
コンテナ化
ジョブはコンテナ内で実行されます。イメージジョブは事前構築された Docker イメージを使用し、Git およびコードアーティファクトジョブはコンテナビルドステップが必要です。
ジョブのコンテナ化は、wandb launch の引数やジョブソースコード内のファイルでカスタマイズできます。
ビルドコンテキスト
ビルドコンテキストとは、コンテナイメージをビルドするために Docker デーモンに送信されるファイルとディレクトリーのツリーを指します。デフォルトでは、Launch はジョブソースコードのルートをビルドコンテキストとして使用します。サブディレクトリーをビルドコンテキストとして指定するには、ジョブを作成して起動する際に wandb launch の --build-context 引数を使用します。
--build-context 引数は、複数のプロジェクトを含むモノレポを参照する Git ジョブで作業する際に特に便利です。サブディレクトリーをビルドコンテキストとして指定することで、モノレポ内の特定のプロジェクト用のコンテナイメージをビルドできます。
この引数を公式の W&B Launch ジョブリポジトリで使用する方法については、上記の例をご覧ください。
Dockerfile
Dockerfile は、Docker イメージをビルドするための命令を含むテキストファイルです。デフォルトでは、Launch は requirements.txt ファイルをインストールするデフォルトの Dockerfile を使用します。カスタム Dockerfile を使用するには、wandb launch の --dockerfile 引数でファイルのパスを指定します。
Dockerfile のパスはビルドコンテキストに相対的に指定されます。たとえば、ビルドコンテキストが jobs/hello_world で、Dockerfile が jobs/hello_world ディレクトリーにある場合、--dockerfile 引数は Dockerfile.wandb に設定されるべきです。この引数を公式の W&B Launch ジョブリポジトリで使用する方法については、上記の例をご覧ください。
要件ファイル
カスタム Dockerfile が提供されていない場合、Launch は Python の依存関係をインストールするためにビルドコンテキストを調べます。ビルドコンテキストのルートに requirements.txt ファイルが見つかった場合、Launch はファイルにリストされた依存関係をインストールします。それ以外の場合、pyproject.toml ファイルが見つかれば、project.dependencies セクションから依存関係をインストールします。
7.4 - キューにジョブを追加
次のページでは、ローンチキューにローンチジョブを追加する方法について説明しています。
キューにジョブを追加する
W&B Appを使用してインタラクティブに、またはW&B CLIを使用してプログラム的にキューにジョブを追加します。
W&B Appを使用してプログラム的にキューにジョブを追加します。
- W&B Project Pageに移動します。
- 左のパネルで Jobs アイコンを選択します:
- Jobs ページには、以前に実行されたW&B runsから作成されたW&Bローンチジョブのリストが表示されます。
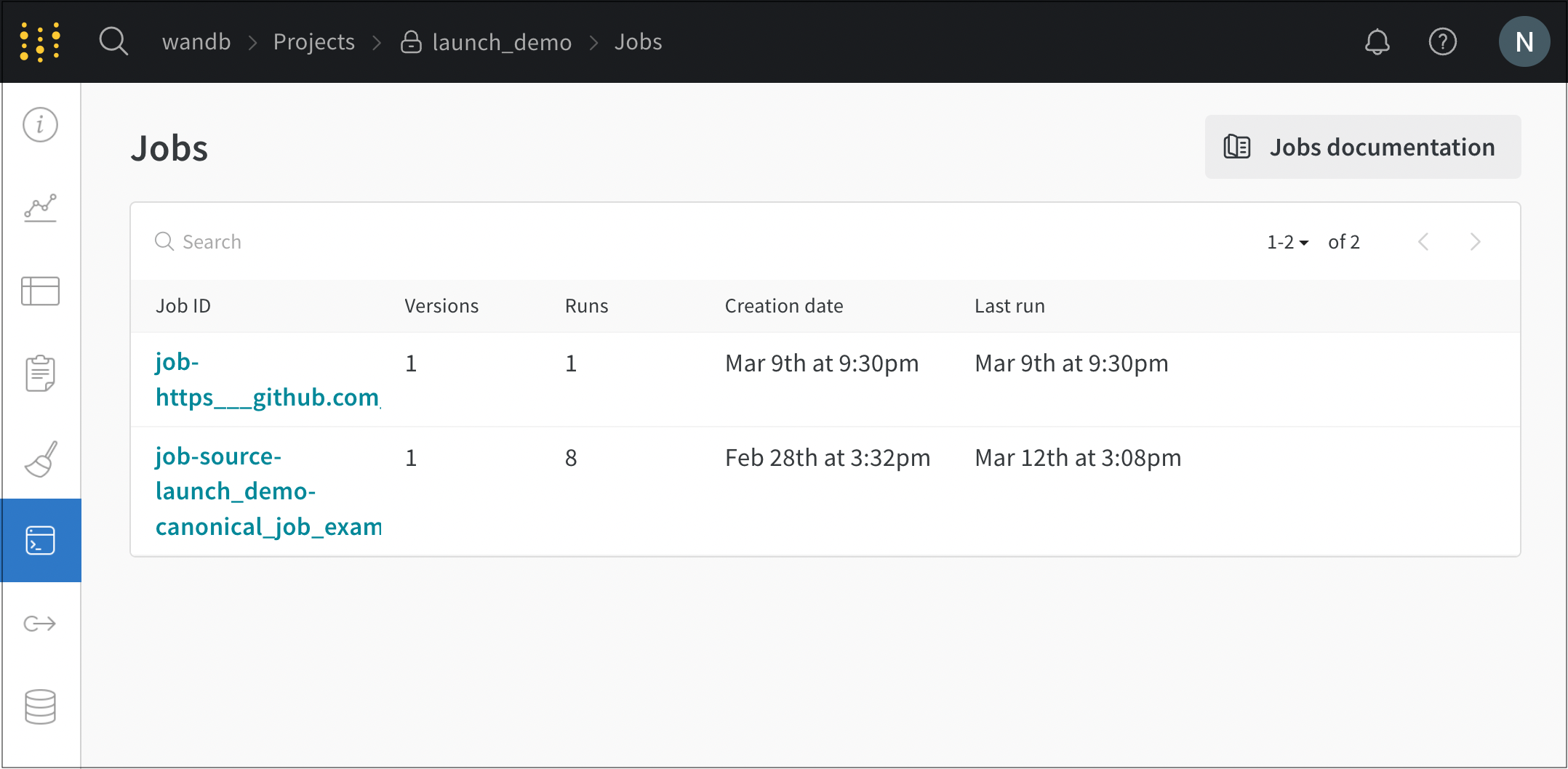
- ジョブ名の横にある Launch ボタンを選択します。ページの右側にモーダルが表示されます。
- Job version ドロップダウンから使用するローンチジョブのバージョンを選択します。ローンチジョブは他の W&B Artifact と同様にバージョン管理されます。ソフトウェアの依存関係やジョブを実行するために使用されるソースコードに変更を加えると、同じローンチジョブの異なるバージョンが作成されます。
- Overrides セクションで、ローンチジョブに設定された入力の新しい値を提供します。一般的なオーバーライドには、新しいエントリーポイントコマンド、引数、または新しいW&B runの
wandb.config内の値が含まれます。
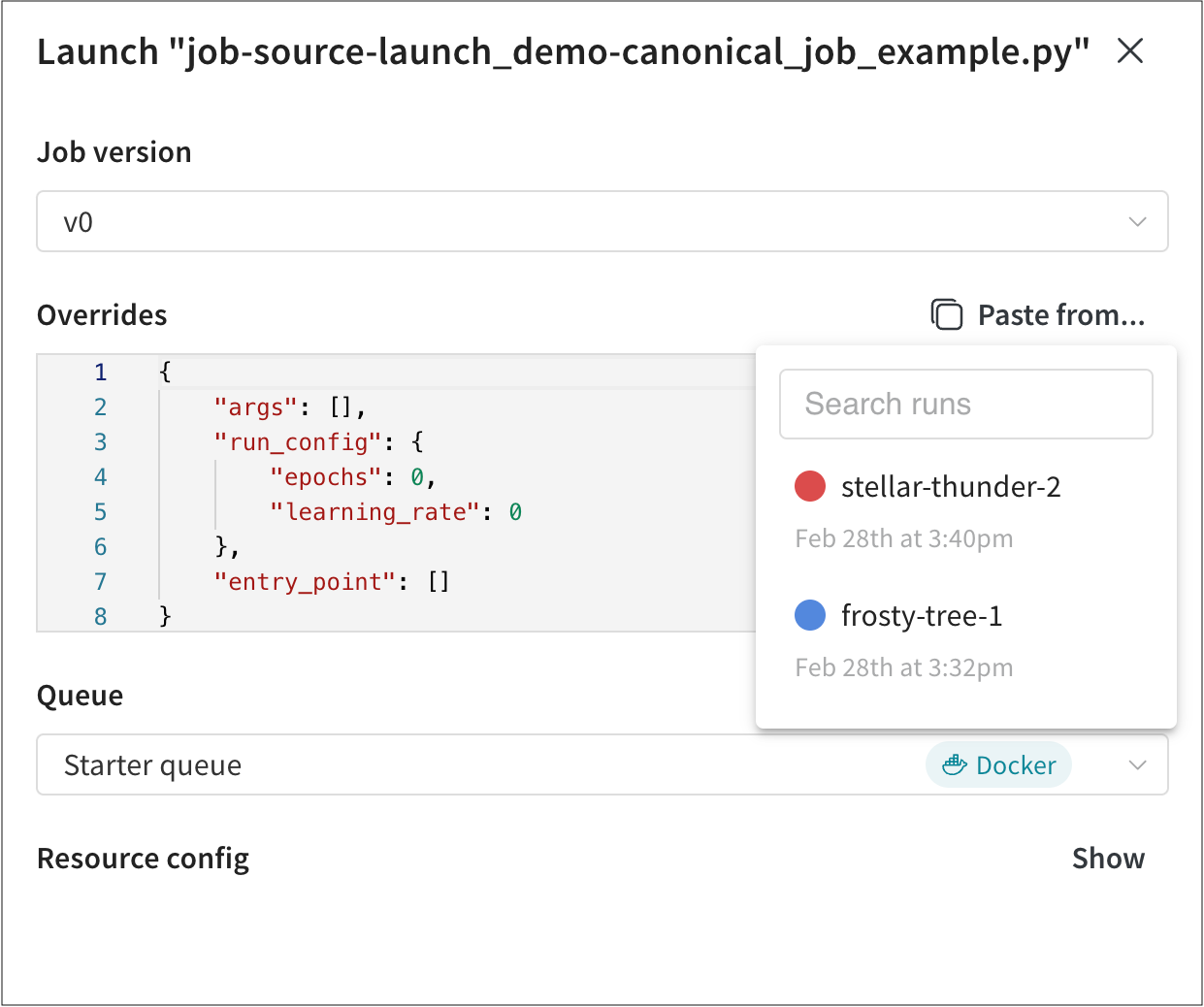 Paste from… ボタンをクリックして、ローンチジョブで使用された他のW&B runsから値をコピーして貼り付けることができます。
Paste from… ボタンをクリックして、ローンチジョブで使用された他のW&B runsから値をコピーして貼り付けることができます。 - Queue ドロップダウンから、ローンチジョブを追加するローンチキューの名前を選択します。
- Job Priority ドロップダウンを使用して、ローンチジョブの優先度を指定します。ローンチキューが優先度をサポートしていない場合は、ローンチジョブの優先度は「Medium」に設定されます。
- (オプション) この手順は、キュー設定テンプレートがチーム管理者によって作成されている場合にのみ従ってください
Queue Configurations フィールド内で、チームの管理者によって作成された設定オプションに対する値を提供します。
例えば、次の例では、チーム管理者がチームが使用できるAWSインスタンスタイプを設定しました。この場合、チームメンバーはml.m4.xlargeまたはml.p3.xlargeのいずれかのコンピュートインスタンスタイプを選択してモデルをトレーニングできます。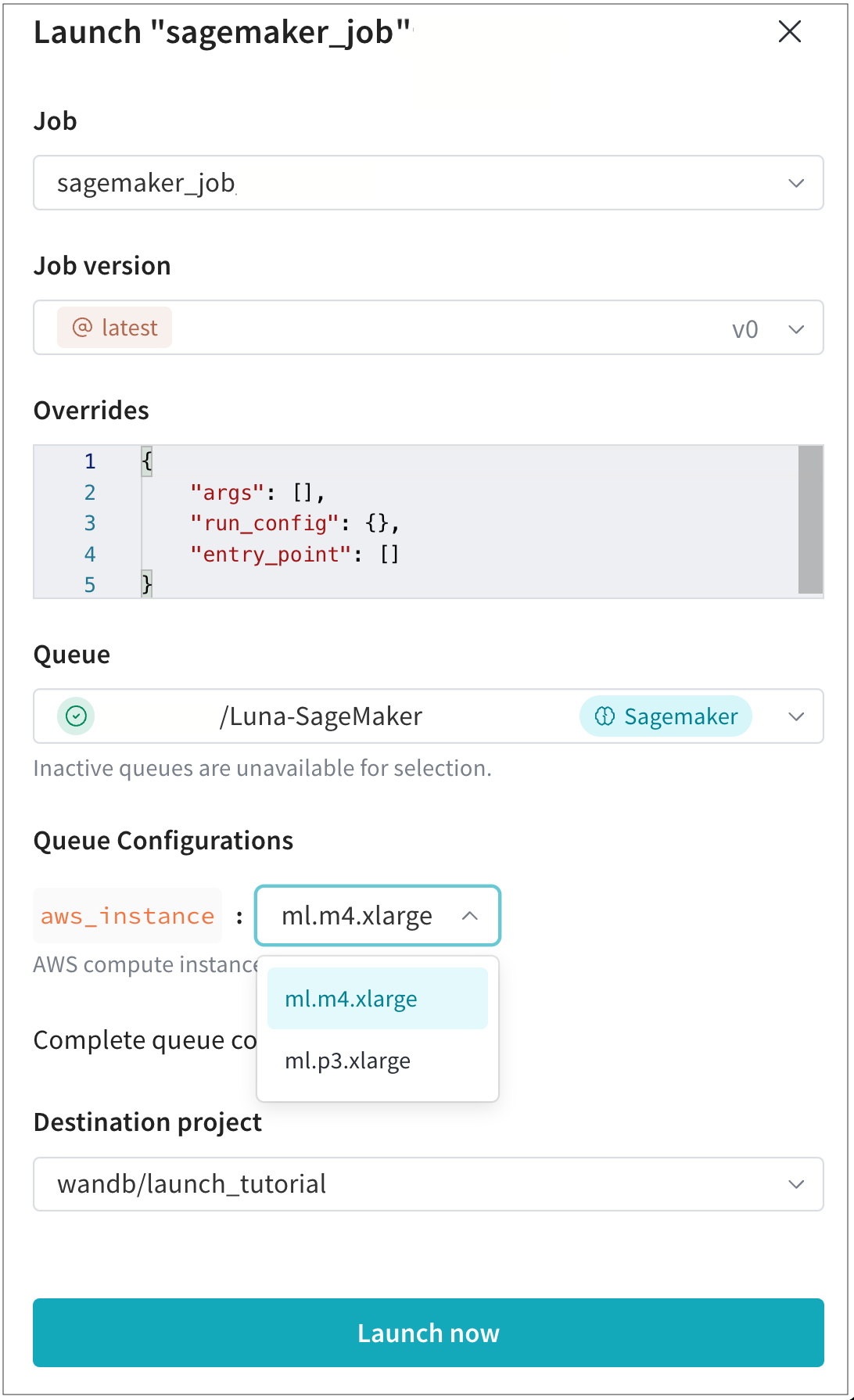
- Destination project を選択して、結果として生成されるrunが表示されるプロジェクトを指定します。このプロジェクトは、キューと同じエンティティに属している必要があります。
- Launch now ボタンを選択します。
wandb launch コマンドを使用して、キューにジョブを追加します。ハイパーパラメーターオーバーライドを含むJSON設定を作成します。例えば、クイックスタート ガイドのスクリプトを使用して、以下のオーバーライドを含むJSONファイルを作成します。
{
"overrides": {
"args": [],
"run_config": {
"learning_rate": 0,
"epochs": 0
},
"entry_point": []
}
}
キューの設定をオーバーライドする場合、またはローンチキューに設定リソースが定義されていない場合、config.json ファイルで resource_args キーを指定できます。例えば、上記の例を続けると、config.json ファイルは次のようになります。
{
"overrides": {
"args": [],
"run_config": {
"learning_rate": 0,
"epochs": 0
},
"entry_point": []
},
"resource_args": {
"<resource-type>" : {
"<key>": "<value>"
}
}
}
<> 内の値を独自の値に置き換えてください。
queue(-q)フラグにはキューの名前を、job(-j)フラグにはジョブの名前を、config(-c)フラグには設定ファイルのパスを指定してください。
wandb launch -j <job> -q <queue-name> \
-e <entity-name> -c path/to/config.json
W&B Team内で作業する場合は、entity フラグ(-e)を指定して、キューが使用するエンティティを示すことをお勧めします。
7.5 - ジョブ入力を管理する
Launch のコア体験は、ハイパーパラメーターやデータセットのような異なるジョブの入力を簡単に実験し、それらのジョブを適切なハードウェアにルーティングすることです。一度ジョブが作成されると、元の作成者以外のユーザーも W&B GUI または CLI を介してこれらの入力を調整できます。CLI または UI からジョブ入力を設定する方法については、Enqueue jobs ガイドを参照してください。
このセクションでは、プログラム的にジョブの調整可能な入力を制御する方法を説明します。
デフォルトでは、W&B ジョブは Run.config 全体をジョブの入力としてキャプチャしますが、Launch SDK は run config の選択したキーを制御したり、JSON または YAML ファイルを入力として指定するための機能を提供します。
wandb-core を必要とします。詳細については、wandb-core README を参照してください。Run オブジェクトの再設定
ジョブ内の wandb.init によって返される Run オブジェクトは、デフォルトで再設定可能です。Launch SDK は、ジョブの Launch 時に Run.config オブジェクトのどの部分が再設定可能かをカスタマイズする方法を提供します。
import wandb
from wandb.sdk import launch
# Launch SDK の使用に必要
wandb.require("core")
config = {
"trainer": {
"learning_rate": 0.01,
"batch_size": 32,
"model": "resnet",
"dataset": "cifar10",
"private": {
"key": "value",
},
},
"seed": 42,
}
with wandb.init(config=config):
launch.manage_wandb_config(
include=["trainer"],
exclude=["trainer.private"],
)
# 等
関数 launch.manage_wandb_config は、Run.config オブジェクトに対する入力値をジョブに受け入れるように設定します。オプションの include および exclude オプションは、ネストされた config オブジェクト内のパスプレフィクスを取ります。例えば、ジョブがエンドユーザーに公開したくないオプションを持つライブラリを使用している場合に役立ちます。
include プレフィクスが提供されている場合、config 内で include プレフィクスと一致するパスのみが入力値を受け入れます。exclude プレフィクスが提供されている場合、exclude リストと一致するパスは入力値からフィルタリングされません。あるパスが include および exclude プレフィクスの両方に一致する場合、exclude プレフィクスが優先されます。
前述の例では、パス ["trainer.private"] は trainer オブジェクトから private キーをフィルタリングし、パス ["trainer"] は trainer オブジェクト下のすべてのキー以外をフィルタリングします。
名前に . を含むキーをフィルタリングするには、\-エスケープされた . を使用します。
例えば、r"trainer\.private" は trainer オブジェクト下の private キーではなく trainer.private キーをフィルタリングします。
上記の r プレフィクスは生文字列を示すことに注意してください。
上記のコードがパッケージ化され、ジョブとして実行される場合、ジョブの入力タイプは次のようになります:
{
"trainer": {
"learning_rate": "float",
"batch_size": "int",
"model": "str",
"dataset": "str",
},
}
W&B CLI または UI からジョブをローンチする際、ユーザーは 4 つの trainer パラメーターのみを上書きできます。
run config の入力へのアクセス
run config の入力でローンチされたジョブは、Run.config を通じて入力値にアクセスできます。ジョブ コード内で wandb.init によって返された Run は、入力値を自動的に設定します。ジョブ コードのどこでも run config の入力値をロードするには、次を使用します:
from wandb.sdk import launch
run_config_overrides = launch.load_wandb_config()
ファイルの再設定
Launch SDK はまた、ジョブ コードで設定ファイルに格納された入力値を管理する方法も提供します。これは、多くのディープラーニングや大規模な言語モデルのユースケースで一般的なパターンであり、例えばこの torchtune の例やこの Axolotl config などがあります。
Run.config オブジェクトで制御する必要があります。launch.manage_config_file 関数を使用して、設定ファイルを Launch ジョブの入力として追加し、ジョブをローンチする際に設定ファイル内の値の編集アクセスを提供します。
デフォルトでは、launch.manage_config_file が使用されると run config 入力はキャプチャされません。launch.manage_wandb_config を呼び出すことで、この振る舞いを上書きします。
以下の例を考えてみましょう:
import yaml
import wandb
from wandb.sdk import launch
# Launch SDK の使用に必要
wandb.require("core")
launch.manage_config_file("config.yaml")
with open("config.yaml", "r") as f:
config = yaml.safe_load(f)
with wandb.init(config=config):
# 等
pass
コードが隣接するファイル config.yaml と一緒に実行されていると想像してください:
learning_rate: 0.01
batch_size: 32
model: resnet
dataset: cifar10
launch.manage_config_file の呼び出しは、config.yaml ファイルをジョブの入力として追加し、W&B CLI または UI からローンチする際に再設定可能にします。
launch.manage_wandb_config と同じようにして、設定ファイルに対する許容入力キーをフィルタリングするために include と exclude のキーワード引数を使用できます。
設定ファイルの入力へのアクセス
Launch によって作成された run で launch.manage_config_file が呼び出されると、launch は設定ファイルの内容を入力値でパッチします。修正された設定ファイルはジョブ 環境で利用可能です。
launch.manage_config_file を呼び出すことで、入力値が使用されることを確実にします。ジョブの launch ドロワー UI のカスタマイズ
ジョブの入力スキーマを定義することで、ジョブをローンチするためのカスタム UI を作成できます。ジョブのスキーマを定義するには、launch.manage_wandb_config または launch.manage_config_file の呼び出しにそれを含めます。スキーマは、JSON Schema の形での Python 辞書または Pydantic モデル クラスのいずれかです。
次の例は、以下のプロパティを持つスキーマを示しています:
seed, 整数trainer, いくつかのキーが指定された辞書:trainer.learning_rate, ゼロより大きくなければならない浮動小数点数trainer.batch_size, 16, 64, 256 のいずれかでなければならない整数trainer.dataset,cifar10またはcifar100のいずれかでなければならない文字列
schema = {
"type": "object",
"properties": {
"seed": {
"type": "integer"
},
"trainer": {
"type": "object",
"properties": {
"learning_rate": {
"type": "number",
"description": "モデルの学習率",
"exclusiveMinimum": 0,
},
"batch_size": {
"type": "integer",
"description": "バッチごとのサンプル数",
"enum": [16, 64, 256]
},
"dataset": {
"type": "string",
"description": "使用するデータセットの名前",
"enum": ["cifar10", "cifar100"]
}
}
}
}
}
launch.manage_wandb_config(
include=["seed", "trainer"],
exclude=["trainer.private"],
schema=schema,
)
一般的に、以下の JSON Schema 属性がサポートされています:
| 属性 | 必須 | 注釈 |
|---|---|---|
type |
Yes | number, integer, string, object のいずれかでなければなりません |
title |
No | プロパティの表示名を上書きします |
description |
No | プロパティのヘルプテキストを提供します |
enum |
No | フリーフォームのテキスト入力の代わりにドロップダウン選択を作成します |
minimum |
No | type が number または integer のときのみ許可されます |
maximum |
No | type が number または integer のときのみ許可されます |
exclusiveMinimum |
No | type が number または integer のときのみ許可されます |
exclusiveMaximum |
No | type が number または integer のときのみ許可されます |
properties |
No | type が object のとき、ネストされた設定を定義するために使用します |
次の例は、以下のプロパティを持つスキーマを示しています:
seed, 整数trainer, いくつかのサブ属性が指定されたスキーマ:trainer.learning_rate, ゼロより大きくなければならない浮動小数点数trainer.batch_size, 1 から 256 までの範囲でなければならない整数trainer.dataset,cifar10またはcifar100のいずれかでなければならない文字列
class DatasetEnum(str, Enum):
cifar10 = "cifar10"
cifar100 = "cifar100"
class Trainer(BaseModel):
learning_rate: float = Field(gt=0, description="モデルの学習率")
batch_size: int = Field(ge=1, le=256, description="バッチごとのサンプル数")
dataset: DatasetEnum = Field(title="Dataset", description="使用するデータセットの名前")
class Schema(BaseModel):
seed: int
trainer: Trainer
launch.manage_wandb_config(
include=["seed", "trainer"],
exclude=["trainer.private"],
schema=Schema,
)
クラスのインスタンスを使用することもできます:
t = Trainer(learning_rate=0.01, batch_size=32, dataset=DatasetEnum.cifar10)
s = Schema(seed=42, trainer=t)
launch.manage_wandb_config(
include=["seed", "trainer"],
exclude=["trainer.private"],
input_schema=s,
)
ジョブ入力スキーマを追加すると、launch ドロワーに構造化されたフォームが作成され、ジョブのローンチが容易になります。