> ## Documentation Index
> Fetch the complete documentation index at: https://docs.wandb.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Agrégation des points
> Découvrez les deux modes d’agrégation de points pour les graphiques en courbes W&B : l’échantillonnage par bucket en mode de fidélité totale et l’échantillonnage aléatoire.
Utilisez les méthodes d’agrégation de points dans vos graphiques en courbes pour gagner en précision d’affichage des données et en performances. Cette page explique les deux modes d’agrégation disponibles ainsi que la manière de configurer chacun d’eux, afin que vous puissiez choisir le bon compromis entre le niveau de détail et la vitesse de rendu pour votre espace de travail. Il existe deux modes d’agrégation de points disponibles : la [fidélité totale](#full-fidelity) et l’[échantillonnage aléatoire](#random-sampling). W\&B utilise le mode de fidélité totale par défaut.
## Fidélité totale
La fidélité totale est la méthode d’agrégation par défaut et préserve les valeurs extrêmes dans vos données. Cette section explique comment fonctionne la fidélité totale, ses principaux avantages et comment l’activer pour un seul graphique ou pour un workspace entier.
Lorsque vous utilisez le mode de fidélité totale, W\&B découpe le axe X en buckets dynamiques. Le nombre de points par ligne s'adapte à la taille du graphique et au nombre de runs. Il calcule les valeurs minimale et maximale dans chaque bucket (utilisées pour un ombrage facultatif) et utilise la dernière valeur de chaque bucket (et non la moyenne) pour tracer la ligne principale.
L'utilisation du mode de fidélité totale pour l'agrégation des points présente trois principaux avantages :
* Préserver les valeurs extrêmes et les pics : conservez les valeurs extrêmes et les pics dans vos données.
* Configurer le rendu des points minimum et maximum : utilisez le W\&B App pour choisir de manière interactive si vous souhaitez afficher les valeurs extrêmes (min/max) sous forme de zone ombrée.
* Explorer vos données sans perte de fidélité : W\&B recalcule la taille des buckets du axe X lorsque vous zoomez sur des points de données spécifiques. Cela vous permet d'explorer vos données sans perdre en précision. W\&B met en cache les agrégations précédemment calculées afin de réduire les temps de chargement, ce qui est utile lorsque vous parcourez de grands jeux de données.
### Activer la fidélité totale
W\&B utilise le mode de fidélité totale par défaut. Pour le configurer manuellement, suivez ces étapes :
1. Accédez à votre Workspace.
2. Sélectionnez l’icône d’engrenage dans le coin supérieur droit de l’écran, à gauche du bouton **Add panels**.
3. Dans le panneau de l’interface qui s’affiche, sélectionnez **graphique en courbes**.
4. Choisissez **fidélité totale** dans la section **agrégation des points**.
5. Configurez l’algorithme et les paramètres de **lissage**.
6. Réglez **Aggregation** sur **Mean**, **Min** ou **Max**.
7. Cliquez sur **Apply**.
1. Accédez à votre Workspace.
2. Sélectionnez l’icône **Workspace** dans l’onglet de gauche.
3. Survolez le panneau de graphique linéaire que vous souhaitez configurer, puis cliquez sur l’icône d’engrenage.
4. Dans la fenêtre modale qui s’affiche, définissez **Méthode d’agrégation des points** sur **fidélité totale**.
5. Configurez l’algorithme et les paramètres de **lissage**.
6. Cliquez sur **Apply**.
### Configurer l’ombrage
L’ombrage visualise la variabilité au sein de chaque bucket afin de vous permettre de voir dans quelle mesure les points s’écartent autour de la ligne. Les zones ombrées d’un graphique en courbes en fidélité totale peuvent afficher :
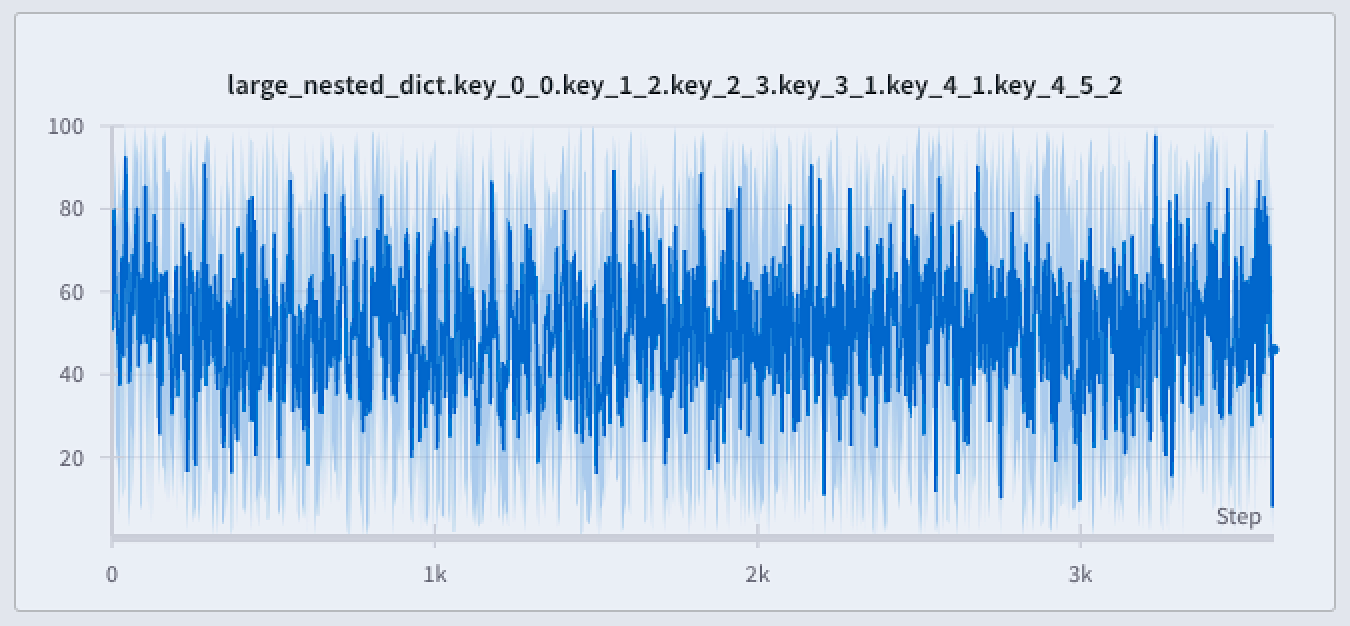
* **Min/Max** : pour chaque point de l’axe X, la zone comprise entre les valeurs minimale et maximale est ombrée. La zone ombrée montre tous les points, de la valeur la plus faible à la plus élevée, dans chaque bucket :
```math theme={null}
\text{Min/Max Range} = [\min(x_1, x_2, \ldots, x_n),\ \max(x_1, x_2, \ldots, x_n)]
```
où $x_1, x_2, \ldots, x_n$ sont les valeurs d’un bucket donné.
* **Standard deviation** : pour chaque point de l’axe X, calculez la variabilité des valeurs à l’aide de l’écart type, puis ombrez la zone obtenue.
```math theme={null}
SD = \sqrt{\frac{1}{n}\sum_{i=1}^{n}(x_i - \overline{x})^2}
```
* **Standard error** : pour chaque point de l’axe X, calculez l’erreur standard en divisant l’écart type par la racine carrée de la taille de l’échantillon :
```math theme={null}
SE = \frac{SD}{\sqrt{n}}
```
* **None** : aucun ombrage (par défaut).
L’image suivante montre un graphique en courbes bleu. La zone ombrée bleu clair représente les valeurs minimale et maximale pour chaque bucket.
 Pour configurer l’ombrage :
1. Accédez à votre Workspace.
2. Survolez un graphique en courbes, puis cliquez sur l’icône d’engrenage.
3. Dans l’onglet **Data**, définissez **agrégation des points** sur **fidélité totale** si nécessaire, puis configurez l’algorithme de lissage.
4. Dans l’onglet **Grouping**, activez **Group runs**. Si vous le souhaitez, définissez **Group by** sur un attribut de run.
5. Définissez **Agg** sur **Mean** (par défaut), **Min** ou **Max**.
6. Définissez **Range** sur **Min/Max**, **Std Dev**, **Std Err** ou **None**.
7. Cliquez sur **Apply**.
Pour configurer l’ombrage :
1. Accédez à votre Workspace.
2. Survolez un graphique en courbes, puis cliquez sur l’icône d’engrenage.
3. Dans l’onglet **Data**, définissez **agrégation des points** sur **fidélité totale** si nécessaire, puis configurez l’algorithme de lissage.
4. Dans l’onglet **Grouping**, activez **Group runs**. Si vous le souhaitez, définissez **Group by** sur un attribut de run.
5. Définissez **Agg** sur **Mean** (par défaut), **Min** ou **Max**.
6. Définissez **Range** sur **Min/Max**, **Std Dev**, **Std Err** ou **None**.
7. Cliquez sur **Apply**.
### Explorez vos données sans perdre en fidélité des données
Analysez des zones spécifiques du jeu de données sans passer à côté de points critiques, comme les valeurs extrêmes ou les pics. Lorsque vous zoomez sur un graphique en courbes, W\&B ajuste la taille des buckets utilisés pour calculer les valeurs minimale, maximale et la dernière valeur de chaque bucket.
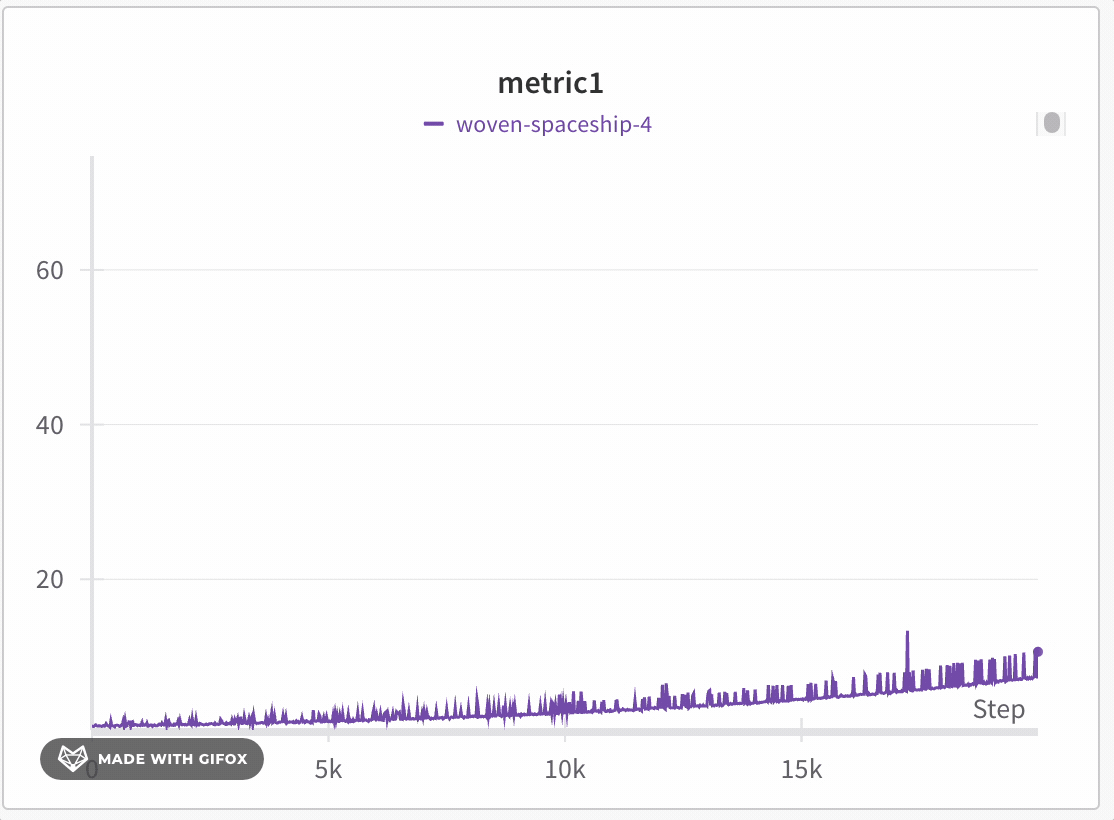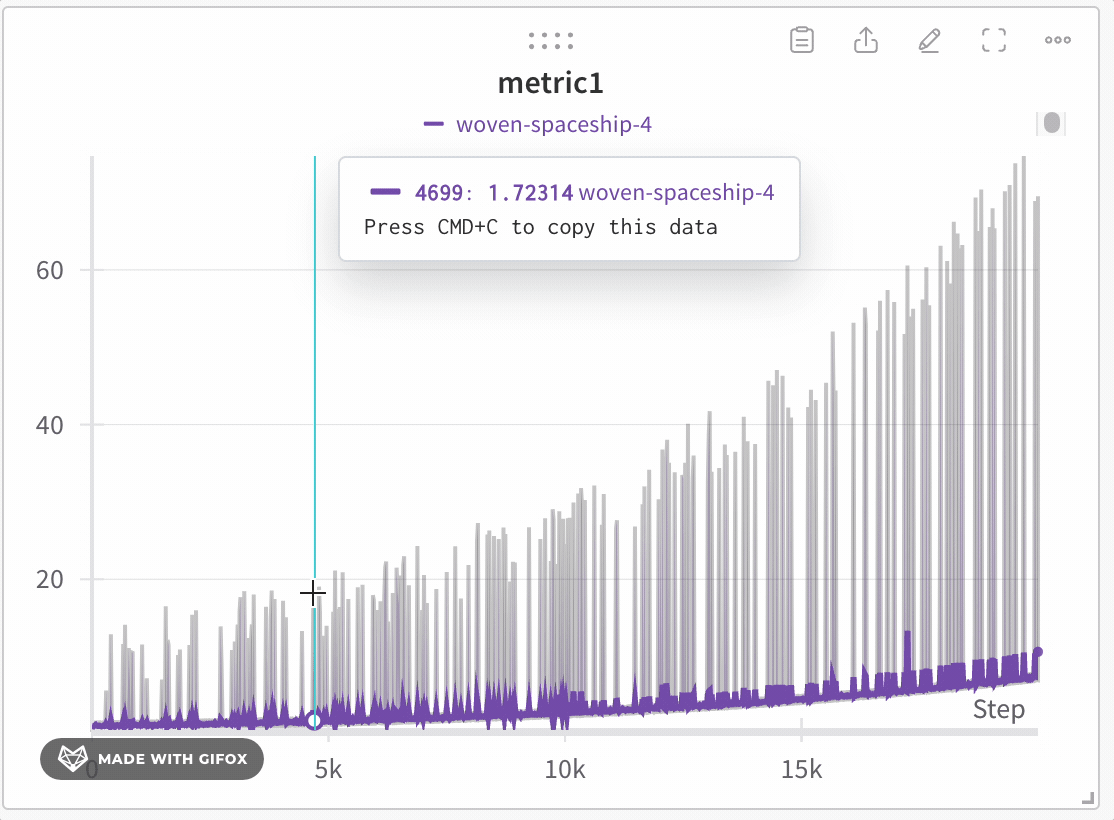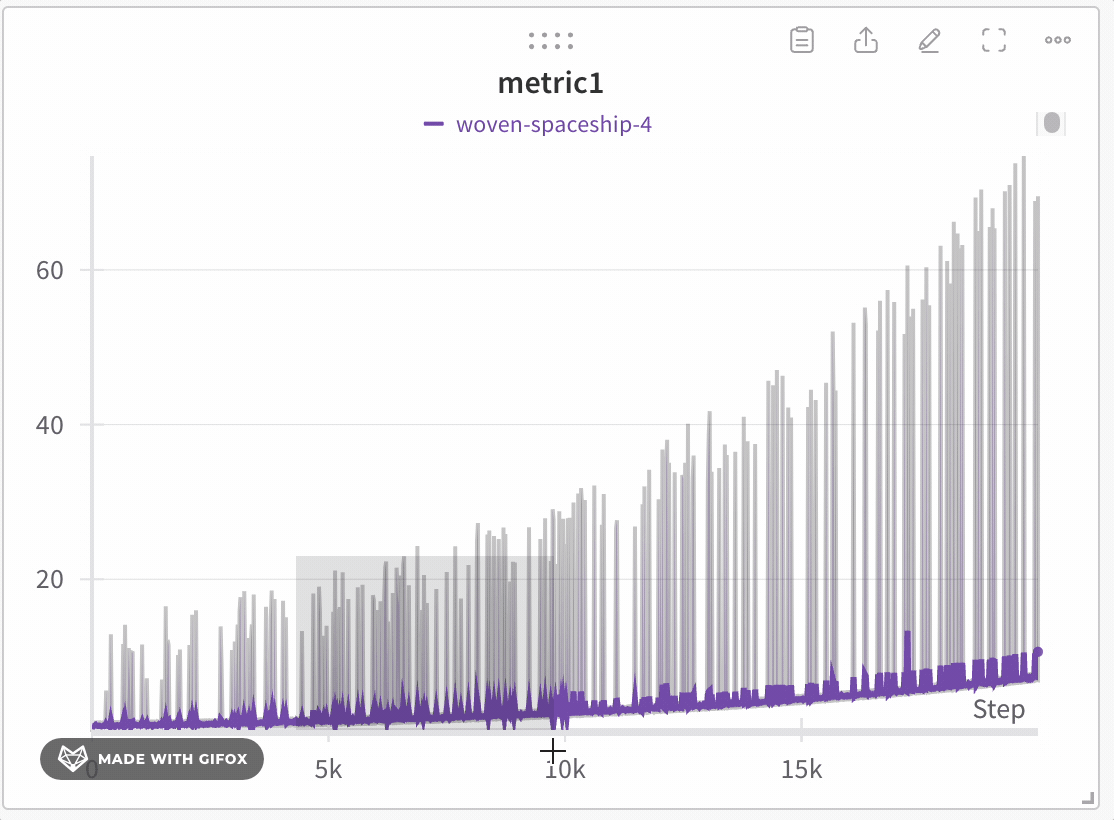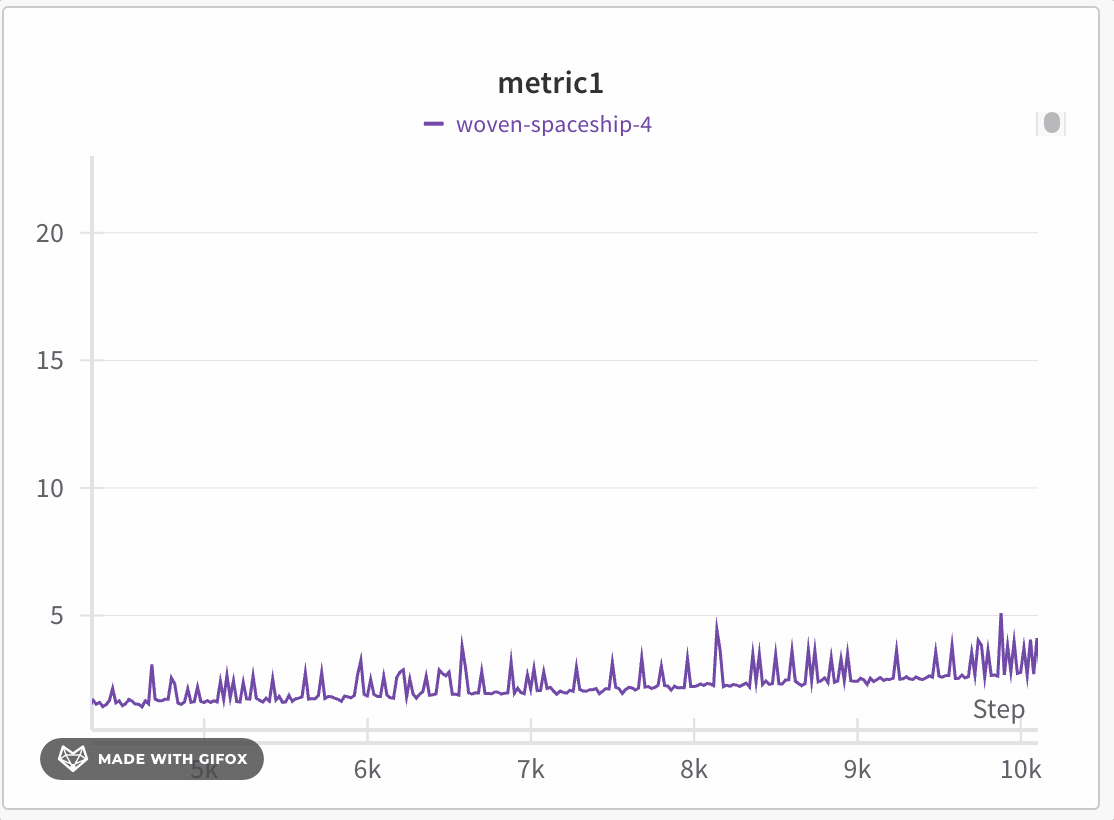 W\&B utilise un partitionnement dynamique pour diviser l’axe X en buckets. Le nombre de points affichés par ligne s’adapte à la taille du graphique et au nombre de Runs : des dimensions de graphique plus petites ou un plus grand nombre de Runs peuvent réduire le nombre de points par ligne afin que le graphique reste réactif et puisse afficher davantage de lignes. Pour chaque bucket, W\&B calcule les valeurs suivantes :
* **Minimum** : la valeur la plus basse de ce bucket (utilisée pour l’ombrage).
* **Maximum** : la valeur la plus élevée de ce bucket (utilisée pour l’ombrage).
* **Line value** : la dernière valeur de ce bucket, utilisée pour tracer la ligne.
W\&B trace les valeurs par bucket de manière à préserver une représentation complète des données et à inclure les valeurs extrêmes dans chaque graphique. La ligne est tracée à partir de la dernière valeur de chaque bucket. Lorsque vous zoomez suffisamment, le mode de fidélité totale peut effectuer le rendu de chaque point de données sans agrégation supplémentaire. Le seuil exact dépend des dimensions actuelles du graphique et du nombre de Runs.
Pour zoomer sur un graphique en courbes, suivez ces étapes :
1. Accédez à votre projet W\&B.
2. Sélectionnez l’icône **Workspace** dans l’onglet de gauche.
3. Si vous le souhaitez, ajoutez un panneau de graphique linéaire à votre Workspace ou accédez à un panneau de graphique linéaire existant.
4. Cliquez et faites glisser pour sélectionner une zone spécifique sur laquelle zoomer.
**Regroupement de graphiques en courbes et expressions**
Lorsque vous utilisez le regroupement de graphiques en courbes, W\&B applique les éléments suivants selon le mode sélectionné :
* **Échantillonnage sans fenêtrage (regroupement)** : aligne les points entre les Runs sur l’axe X. Une moyenne est calculée si plusieurs points partagent la même valeur x ; sinon, ils apparaissent comme des points distincts.
* **Échantillonnage fenêtré (regroupement et expressions)** : divise l’axe X soit en 250 buckets, soit selon le nombre de points de la ligne la plus longue (la plus petite des deux valeurs étant retenue). W\&B calcule la moyenne des points dans chaque bucket.
* **Fidélité totale (regroupement et expressions)** : similaire à l’échantillonnage sans fenêtrage, mais récupère jusqu’à 500 points par run afin d’équilibrer les performances et le niveau de détail.
W\&B utilise un partitionnement dynamique pour diviser l’axe X en buckets. Le nombre de points affichés par ligne s’adapte à la taille du graphique et au nombre de Runs : des dimensions de graphique plus petites ou un plus grand nombre de Runs peuvent réduire le nombre de points par ligne afin que le graphique reste réactif et puisse afficher davantage de lignes. Pour chaque bucket, W\&B calcule les valeurs suivantes :
* **Minimum** : la valeur la plus basse de ce bucket (utilisée pour l’ombrage).
* **Maximum** : la valeur la plus élevée de ce bucket (utilisée pour l’ombrage).
* **Line value** : la dernière valeur de ce bucket, utilisée pour tracer la ligne.
W\&B trace les valeurs par bucket de manière à préserver une représentation complète des données et à inclure les valeurs extrêmes dans chaque graphique. La ligne est tracée à partir de la dernière valeur de chaque bucket. Lorsque vous zoomez suffisamment, le mode de fidélité totale peut effectuer le rendu de chaque point de données sans agrégation supplémentaire. Le seuil exact dépend des dimensions actuelles du graphique et du nombre de Runs.
Pour zoomer sur un graphique en courbes, suivez ces étapes :
1. Accédez à votre projet W\&B.
2. Sélectionnez l’icône **Workspace** dans l’onglet de gauche.
3. Si vous le souhaitez, ajoutez un panneau de graphique linéaire à votre Workspace ou accédez à un panneau de graphique linéaire existant.
4. Cliquez et faites glisser pour sélectionner une zone spécifique sur laquelle zoomer.
**Regroupement de graphiques en courbes et expressions**
Lorsque vous utilisez le regroupement de graphiques en courbes, W\&B applique les éléments suivants selon le mode sélectionné :
* **Échantillonnage sans fenêtrage (regroupement)** : aligne les points entre les Runs sur l’axe X. Une moyenne est calculée si plusieurs points partagent la même valeur x ; sinon, ils apparaissent comme des points distincts.
* **Échantillonnage fenêtré (regroupement et expressions)** : divise l’axe X soit en 250 buckets, soit selon le nombre de points de la ligne la plus longue (la plus petite des deux valeurs étant retenue). W\&B calcule la moyenne des points dans chaque bucket.
* **Fidélité totale (regroupement et expressions)** : similaire à l’échantillonnage sans fenêtrage, mais récupère jusqu’à 500 points par run afin d’équilibrer les performances et le niveau de détail.
## Échantillonnage aléatoire
L’échantillonnage aléatoire est une méthode d’agrégation alternative qui privilégie la vitesse de rendu au détriment de la fidélité des données. Utilisez-la lorsque vous avez besoin de graphiques plus rapides et qu’il n’est pas nécessaire de conserver chaque valeur extrême.
L’échantillonnage aléatoire utilise 1 500 points sélectionnés aléatoirement pour le rendu des graphiques en courbes. Comme l’échantillonnage supprime des points, il devient plus difficile de repérer les valeurs aberrantes ou les pics.
L’échantillonnage aléatoire est non déterministe. Par conséquent, il exclut parfois des valeurs aberrantes ou des pics dans les données, ce qui réduit la précision des données.
### Activer l’échantillonnage aléatoire
Par défaut, W\&B utilise le mode de fidélité totale. Pour activer l’échantillonnage aléatoire, suivez ces étapes :
1. Accédez à votre projet W\&B.
2. Sélectionnez l’icône **Workspace** dans l’onglet de gauche.
3. Sélectionnez l’icône d’engrenage dans le coin supérieur droit de l’écran, à gauche du bouton **Add panels**.
4. Dans le volet qui s’affiche, sélectionnez **Graphiques en courbes**.
5. Choisissez **Échantillonnage aléatoire** dans la section **Agrégation des points**.
1. Accédez à votre projet W\&B.
2. Sélectionnez l’icône **Workspace** dans l’onglet de gauche.
3. Sélectionnez le panneau de graphique linéaire pour lequel vous souhaitez activer l’échantillonnage aléatoire.
4. Dans la fenêtre modale qui s’affiche, sélectionnez **Échantillonnage aléatoire** dans la section **Méthode d’agrégation des points**.
### Accéder aux données non échantillonnées
Si l’échantillonnage aléatoire supprime des points dont vous avez besoin, vous pouvez quand même accéder par programmation à l’historique complet des métriques non échantillonnées. Vous pouvez accéder à l’historique complet des métriques enregistrées au cours d’un run à l’aide de la [W\&B Run API](/fr/models/ref/python/public-api/runs). L’exemple suivant montre comment récupérer et traiter les valeurs de perte d’un run spécifique :
```python theme={null}
# Initialiser la W&B API
run = api.run("l2k2/examples-numpy-boston/i0wt6xua")
# Récupérer l'historique de la métrique 'Loss'
history = run.scan_history(keys=["Loss"])
# Extraire les valeurs de perte de l'historique
losses = [row["Loss"] for row in history]
```