### Définir `wandb` comme dépendance facultative
Si vous souhaitez rendre `wandb` facultatif pour les utilisateurs de votre bibliothèque, vous pouvez soit :
* Définir une option `wandb`, par exemple :
## Définir une configuration de run
Fournissez un dictionnaire de configuration lorsque vous initialisez votre run afin d’enregistrer les hyperparamètres et d’autres métadonnées dans W\&B.
Utilisez l’application W\&B pour comparer les runs en fonction de leurs paramètres de configuration et les filtrer dans le tableau Runs. Vous pouvez également utiliser ces paramètres pour regrouper des runs dans l’application W\&B.
Par exemple, dans l’image suivante, la taille de lot (bathch\_size) a été définie comme paramètre de configuration et est visible (voir la première colonne) dans le tableau Runs. Cela permet aux utilisateurs de filtrer et de comparer les runs en fonction de leur taille de lot :
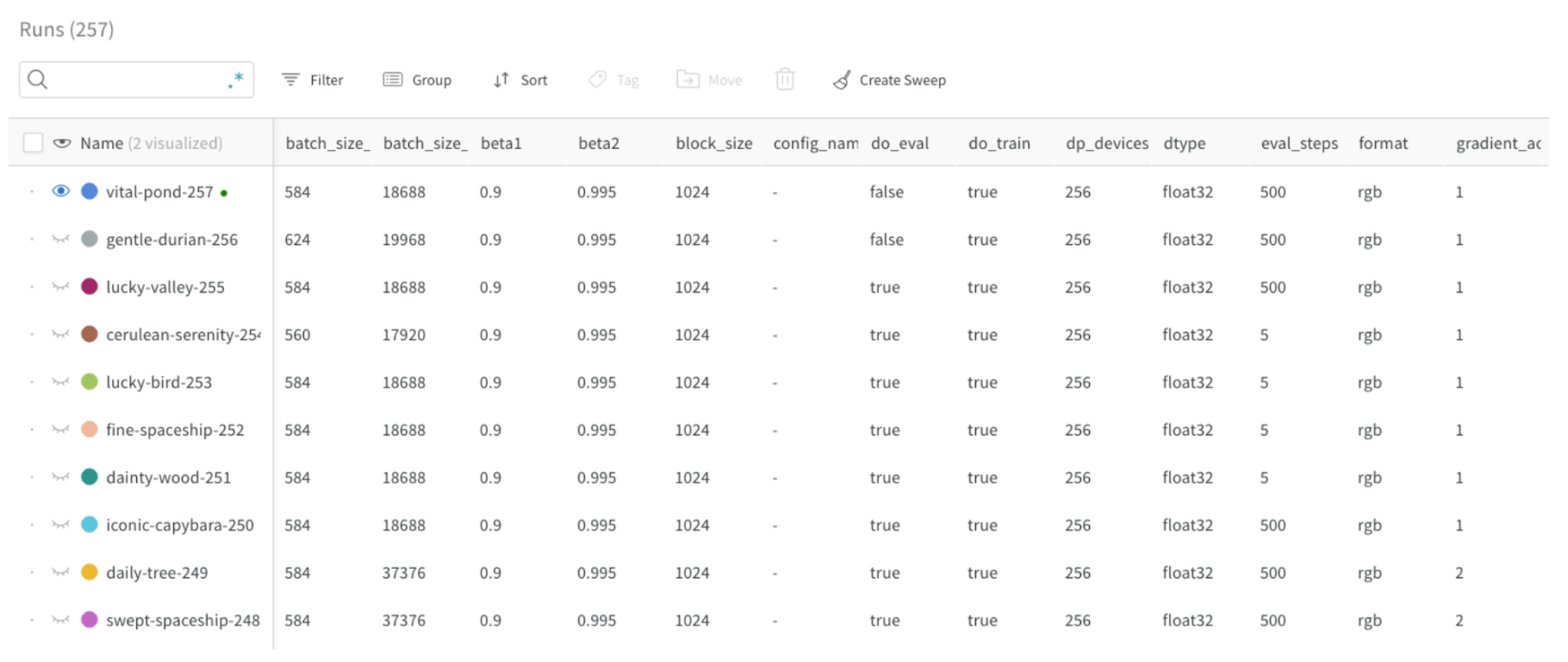 Les valeurs typiques des paramètres de configuration incluent :
* Le nom du modèle, sa version, les paramètres d’architecture et les hyperparamètres.
* Le nom du jeu de données, sa version, le nombre d’exemples d’entraînement ou de validation.
* Les paramètres d’entraînement tels que le taux d’apprentissage, la taille de lot et l’optimiseur.
L’extrait de code suivant montre comment enregistrer une configuration :
```python theme={null}
config = {"batch_size": 32, ...}
with wandb.init(..., config=config) as run:
...
```
Les valeurs typiques des paramètres de configuration incluent :
* Le nom du modèle, sa version, les paramètres d’architecture et les hyperparamètres.
* Le nom du jeu de données, sa version, le nombre d’exemples d’entraînement ou de validation.
* Les paramètres d’entraînement tels que le taux d’apprentissage, la taille de lot et l’optimiseur.
L’extrait de code suivant montre comment enregistrer une configuration :
```python theme={null}
config = {"batch_size": 32, ...}
with wandb.init(..., config=config) as run:
...
```
### Mettre à jour la configuration de run
Si certaines valeurs ne sont pas disponibles au moment de l’initialisation, mettez à jour la configuration plus tard avec `wandb.Run.config.update`. Par exemple, il se peut que vous souhaitiez ajouter les paramètres d’un modèle après son instanciation :
```python theme={null}
with wandb.init(...) as run:
model = MyModel(...)
run.config.update({"model_parameters": 3500})
```
Pour plus de détails, voir [Configurer Experiments](/fr/models/track/config/).
## Journaliser les métriques et les données
### Journaliser des métriques
Créez un dictionnaire dans lequel la clé correspond au nom de la métrique. Passez ce dictionnaire à [`wandb.Run.log()`](/fr/models/ref/python/experiments/run#method-run-log) pour le journaliser dans W\&B :
```python theme={null}
NUM_EPOCHS = 10
for epoch in range(NUM_EPOCHS):
for input, ground_truth in data:
prediction = model(input)
loss = loss_fn(prediction, ground_truth)
metrics = { "loss": loss }
run.log(metrics)
```
Utilisez des préfixes de noms de métriques pour regrouper les métriques associées dans l’application W\&B. Les préfixes courants incluent `train/` et `val/` pour les métriques d'entraînement et de validation, respectivement, mais vous pouvez utiliser n'importe quel préfixe adapté à votre cas d'usage.
Cela créera des sections distinctes dans l’espace de travail de votre projet pour vos métriques d'entraînement et de validation, ou pour d'autres types de métriques que vous souhaitez séparer :
```python theme={null}
with wandb.init(...) as run:
metrics = {
"train/loss": 0.4,
"train/learning_rate": 0.4,
"val/loss": 0.5,
"val/accuracy": 0.7
}
run.log(metrics)
```
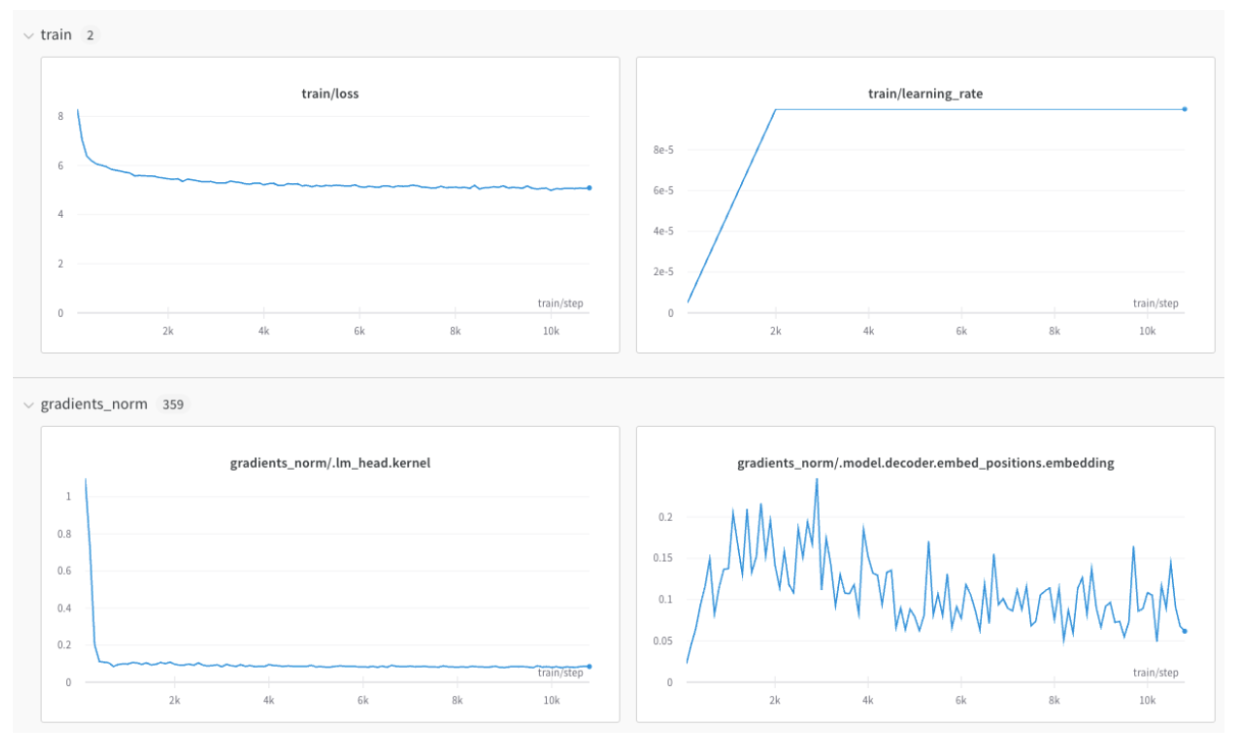 Voir [`wandb.Run.log()`](/fr/models/ref/python/experiments/run#method-run-log) pour en savoir plus.
Voir [`wandb.Run.log()`](/fr/models/ref/python/experiments/run#method-run-log) pour en savoir plus.
### Contrôler l’axe x
Si vous effectuez plusieurs appels à `wandb.Run.log()` pour la même étape d’entraînement, le SDK wandb incrémente un compteur interne à chaque appel à `wandb.Run.log()`. Ce compteur peut ne pas correspondre à l’étape d’entraînement de votre boucle d’entraînement.
Pour éviter cette situation, définissez explicitement l’étape de l’axe x avec `wandb.Run.define_metric()`, une seule fois, immédiatement après avoir appelé `wandb.init()` :
```python theme={null}
with wandb.init(...) as run:
run.define_metric("*", step_metric="global_step")
```
Le motif glob `*` signifie que chaque métrique utilisera `global_step` sur l’axe des x de vos graphiques. Si vous souhaitez que seules certaines métriques soient journalisées en fonction de `global_step`, vous pouvez les spécifier à la place :
```python theme={null}
run.define_metric("train/loss", step_metric="global_step")
```
À présent, journalisez vos métriques, votre métrique `step` et votre `global_step` chaque fois que vous appelez `wandb.Run.log()` :
```python theme={null}
for step, (input, ground_truth) in enumerate(data):
...
run.log({"global_step": step, "train/loss": 0.1})
run.log({"global_step": step, "eval/loss": 0.2})
```
Si vous n’avez pas accès à la variable d’étape indépendante, par exemple si "global\_step" n’est pas disponible pendant votre boucle de validation, la valeur précédemment journalisée pour "global\_step" est automatiquement utilisée par wandb. Dans ce cas, assurez-vous de journaliser une valeur initiale pour la métrique afin qu’elle soit définie au moment voulu.
### Journaliser des médias et des données structurées
Outre les scalaires, vous pouvez consigner des images, des tableaux, du texte, de l’audio, de la vidéo, etc.
Voici quelques points à prendre en compte lorsque vous enregistrez des données :
* À quelle fréquence la métrique doit-elle être enregistrée ? Doit-elle être facultative ?
* Quel type de données peut être utile pour la visualisation ?
* Pour les images, vous pouvez enregistrer des exemples de prédictions, des masques de segmentation, etc., afin d’observer leur évolution au fil du temps.
* Pour le texte, vous pouvez enregistrer des tableaux d’exemples de prédictions pour les explorer plus tard.
Voir [Journaliser des objets et des médias](/fr/models/track/log) pour des exemples.
## Prise en charge de l’entraînement distribué
Pour les frameworks compatibles avec les environnements distribués, vous pouvez adapter l’un des flux de travail suivants :
* Journalisez uniquement depuis le processus principal (recommandé).
* Journalisez depuis chaque processus et regroupez les runs à l’aide d’un nom `group` partagé.
Voir [Journaliser des Experiments d’entraînement distribué](/fr/models/track/log/distributed-training/) pour plus de détails.
## Suivre les modèles et les Datasets avec Artifacts
Utilisez [W\&B Artifacts](/fr/models/artifacts/) pour suivre les modèles et les Datasets et en assurer la gestion des versions. Artifacts fournissent le stockage et la gestion des versions des ressources de machine learning, et assurent automatiquement la traçabilité afin de montrer comment les données et les modèles sont liés.
 Tenez compte des points suivants lorsque vous intégrez Artifacts à votre bibliothèque :
* Déterminez s'il faut journaliser les points de contrôle du modèle ou les Datasets en tant qu'Artifacts (si vous souhaitez rendre cela facultatif).
* Références d'entrée d'Artifacts (par exemple, `entity/project/artifact`).
* Fréquence de journalisation des points de contrôle du modèle ou des Datasets. Par exemple, à chaque époque, toutes les 500 étapes, etc.
Tenez compte des points suivants lorsque vous intégrez Artifacts à votre bibliothèque :
* Déterminez s'il faut journaliser les points de contrôle du modèle ou les Datasets en tant qu'Artifacts (si vous souhaitez rendre cela facultatif).
* Références d'entrée d'Artifacts (par exemple, `entity/project/artifact`).
* Fréquence de journalisation des points de contrôle du modèle ou des Datasets. Par exemple, à chaque époque, toutes les 500 étapes, etc.
### Journaliser les points de contrôle du modèle
Journalisez les points de contrôle du modèle dans W\&B. Une approche courante consiste à journaliser les points de contrôle comme des artifacts, en utilisant le run ID unique généré par W\&B dans le nom de l'artifact.
```python theme={null}
metadata = {"eval/accuracy": 0.8, "train/steps": 800}
artifact = wandb.Artifact(
name=f"model-{run.id}",
metadata=metadata,
type="model"
)
artifact.add_dir("output_model") # répertoire local où les poids du modèle sont stockés
aliases = ["best", "epoch_10"]
run.log_artifact(artifact, aliases=aliases)
```
L’extrait de code précédent montre comment journaliser un point de contrôle du modèle en tant qu’artifact et ajouter des métadonnées telles que la précision de l’évaluation et les étapes d’entraînement. L’artifact se voit attribuer un nom qui inclut le run ID unique, et il est étiqueté avec des [alias personnalisés](/fr/models/artifacts/create-a-custom-alias/) pour s’y référer facilement.
### Journaliser les artifacts en entrée
Journalisez les Datasets ou les modèles préentraînés utilisés en entrée :
```python theme={null}
dataset = wandb.Artifact(name="flowers", type="dataset")
dataset.add_file("flowers.npy")
run.use_artifact(dataset)
```
L’extrait de code précédent crée un artifact pour un jeu de données nommé "flowers" et y ajoute un fichier. L’artifact est ensuite associé au run en cours à l’aide de `run.use_artifact()`, ce qui permet à W\&B de suivre la traçabilité du jeu de données utilisé dans le run.
### Télécharger des Artifacts
Téléchargez des Artifacts déjà enregistrés dans W\&B afin de les utiliser dans votre code d’entraînement ou d’inférence.
Si vous disposez d’un contexte de run, utilisez [`wandb.Run.use_artifact()`](/fr/models/ref/python/experiments/run) pour faire référence à un artifact dans W\&B, puis appelez [`wandb.Artifact.download()`](/fr/models/ref/python/experiments/artifact) pour le télécharger dans un répertoire local.
```python theme={null}
with wandb.init(...) as run:
artifact = run.use_artifact("user/project/artifact:latest")
local_path = artifact.download()
```
Utilisez l’[API publique W\&B](/fr/models/ref/python/public-api/) pour référencer et télécharger un artifact sans initialiser un run. C’est utile dans des scénarios tels que les environnements distribués ou les workflows d’inférence, lorsque vous ne souhaitez pas créer de nouveau run.
```python theme={null}
import wandb
artifact = wandb.Api().artifact("user/project/artifact:latest")
local_path = artifact.download()
```
Voir [Télécharger et utiliser des Artifacts](/fr/models/artifacts/download-and-use-an-artifact/) pour en savoir plus.
## Ajuster les hyperparamètres
Si votre bibliothèque prend en charge l’ajustement des hyperparamètres, vous pouvez intégrer [W\&B Sweeps](/fr/models/sweeps/) pour gérer et visualiser les expériences.