## Premiers pas : suivre les expériences
### Inscrivez-vous et créez une clé API
Une clé API permet d'authentifier votre machine auprès de W\&B. Vous pouvez générer une clé API depuis votre profil.
### Installez la bibliothèque `wandb` et connectez-vous
Pour installer la bibliothèque `wandb` localement et vous connecter :
### Nommez le projet
Un projet W\&B est l’endroit où sont stockés tous les graphiques, les données et les modèles enregistrés à partir de runs liés. Donner un nom à votre projet vous aide à organiser votre travail et à regrouper au même endroit toutes les informations relatives à un même projet.
Pour ajouter un run à un projet, définissez simplement la variable d’environnement `WANDB_PROJECT` sur le nom de votre projet. Le `WandbCallback` récupérera cette variable d’environnement et l’utilisera lors de la configuration de votre run.
### Enregistrez vos runs d'entraînement dans W\&B
Lorsque vous définissez les arguments d'entraînement de votre `Trainer`, dans votre code ou en ligne de commande, **l'étape la plus importante** consiste à définir `report_to` sur `"wandb"` afin d'activer la journalisation avec W\&B.
L'argument `logging_steps` dans `TrainingArguments` contrôle la fréquence à laquelle les métriques d'entraînement sont envoyées à W\&B pendant l'entraînement. Vous pouvez aussi donner un nom au run d'entraînement dans W\&B à l'aide de l'argument `run_name`.
C'est tout. Désormais, vos modèles journaliseront les pertes, les métriques d'évaluation, l'architecture du modèle et les gradients dans W\&B pendant leur entraînement.
### Activez l'enregistrement des points de contrôle du modèle
Avec [Artifacts](/fr/models/artifacts/), vous pouvez stocker gratuitement jusqu'à 100 Go de modèles et de jeux de données, puis utiliser le [registre W\&B](/fr/models/registry/). Avec le registre, vous pouvez enregistrer des modèles pour les explorer et les évaluer, les préparer pour la préproduction ou les déployer dans votre environnement de production.
Pour journaliser les points de contrôle de votre modèle Hugging Face dans Artifacts, définissez la variable d'environnement `WANDB_LOG_MODEL` sur *l'une* des valeurs suivantes :
* **`checkpoint`**: Téléverse un point de contrôle tous les `args.save_steps` à partir de [`TrainingArguments`](https://huggingface.co/docs/transformers/main/en/main_classes/trainer#transformers.TrainingArguments).
* **`end`**: Téléverse le modèle à la fin de l'entraînement, si `load_best_model_at_end` est également défini.
* **`false`**: Ne téléverse pas le modèle.
#### W\&B registre
Une fois vos point de contrôle du modèle enregistrés dans Artifacts, vous pouvez enregistrer les point de contrôle du modèle de vos meilleurs modèles et les centraliser au sein de votre équipe avec [registre](/fr/models/registry/). Avec le registre, vous pouvez organiser vos meilleurs modèles par tâche, gérer le cycle de vie des modèles, suivre et auditer l'ensemble du cycle de vie du machine learning, et [automatiser](/fr/models/automations/) les actions en aval.
Pour lier un Artifact de modèle, reportez-vous à [registre](/fr/models/registry/).
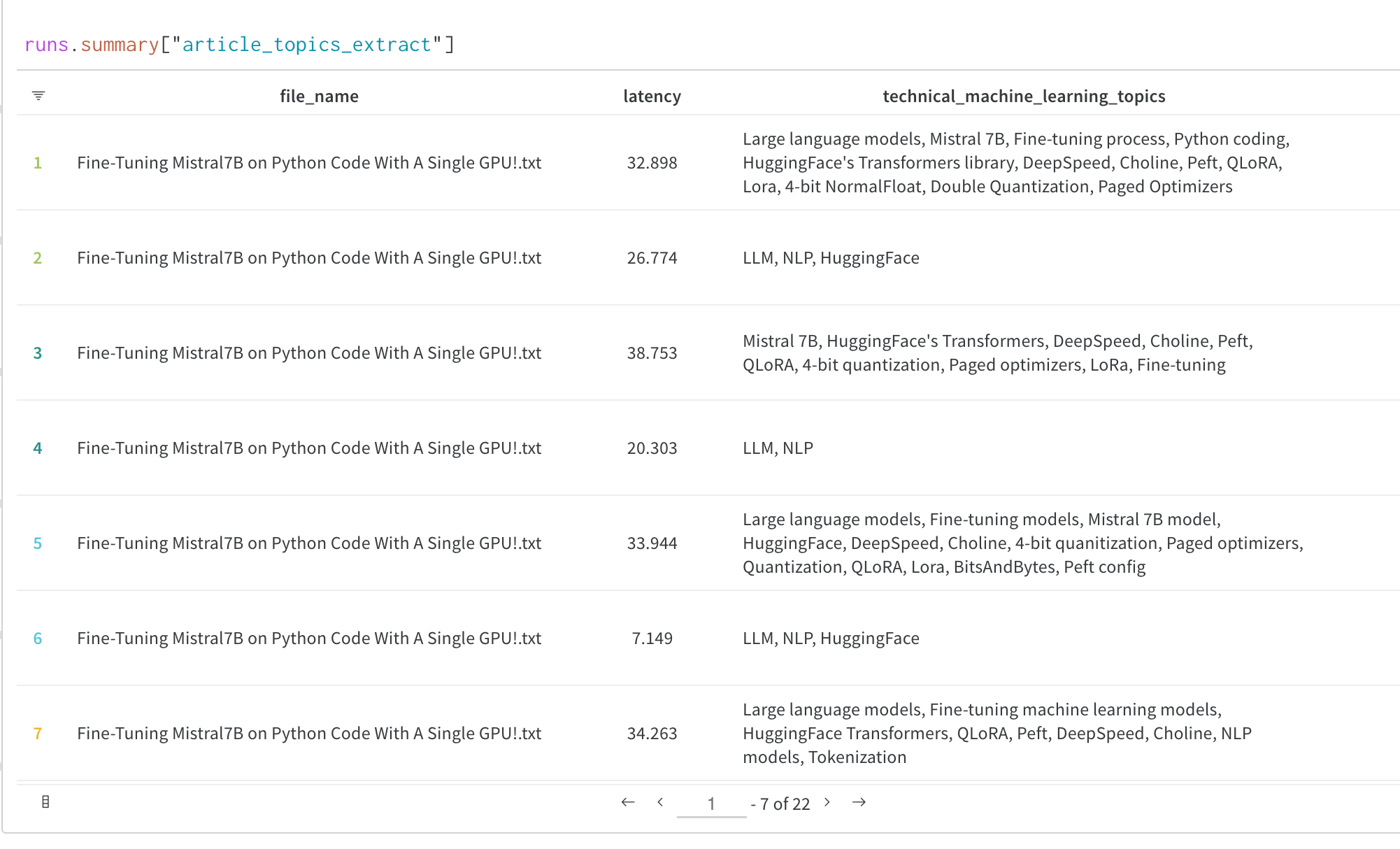
### Visualiser les sorties d’évaluation pendant l’entraînement
Visualiser les sorties de votre modèle pendant l’entraînement ou l’évaluation est souvent essentiel pour bien comprendre comment votre modèle s’entraîne.
En utilisant le système de callbacks du Transformers Trainer, vous pouvez journaliser dans W\&B des données supplémentaires utiles, comme les sorties de génération de texte de vos modèles ou d’autres prédictions, dans W\&B Tables.
Voir la [section de journalisation personnalisée](#custom-logging-log-and-view-evaluation-samples-during-training) ci-dessous pour un guide complet expliquant comment journaliser les sorties d’évaluation pendant l’entraînement dans W\&B Tables, comme ceci :
### Terminez votre run W\&B (Notebook uniquement)
Si votre entraînement est encapsulé dans un script Python, le run W\&B se terminera à la fin de l’exécution du script.
Si vous utilisez un notebook Jupyter ou Google Colab, vous devrez nous indiquer que l’entraînement est terminé en appelant `run.finish()`.
```python theme={null}
run = wandb.init()
trainer.train() # démarrer l'entraînement et la journalisation vers W&B
# analyse post-entraînement, tests, autre code enregistré
run.finish()
```
### Visualisez vos résultats
Une fois les résultats de votre entraînement enregistrés, vous pouvez les explorer de façon dynamique dans le [tableau de bord W\&B](/fr/models/track/workspaces/). Vous pouvez facilement comparer des dizaines de runs à la fois, zoomer sur des résultats intéressants et tirer des enseignements de données complexes grâce à des visualisations flexibles et interactives.
## Fonctionnalités avancées et FAQ
### Comment puis-je enregistrer le meilleur modèle ?
Si vous transmettez `TrainingArguments` avec `load_best_model_at_end=True` à votre `Trainer`, W\&B enregistre le point de contrôle du modèle le plus performant dans Artifacts.
Si vous enregistrez les points de contrôle de votre modèle dans Artifacts, vous pouvez les promouvoir vers le [registre](/fr/models/registry/). Dans le registre, vous pouvez :
* Organiser les versions de votre meilleur modèle par tâche de ML.
* Centraliser les modèles et les partager avec votre équipe.
* Préparer les modèles pour la production ou les marquer pour une évaluation plus approfondie.
* Déclencher des processus CI/CD en aval.
### Comment puis-je charger un modèle enregistré ?
Si vous avez enregistré votre modèle dans W\&B Artifacts avec `WANDB_LOG_MODEL`, vous pouvez télécharger les poids de votre modèle pour poursuivre l’entraînement ou effectuer de l’inférence. Il vous suffit ensuite de les recharger dans la même architecture Hugging Face que celle utilisée précédemment.
```python theme={null}
# Créer un nouveau run
with wandb.init(project="amazon_sentiment_analysis") as run:
# Indiquer le nom et la version de l'Artifact
my_model_name = "model-bert-base-high-lr:latest"
my_model_artifact = run.use_artifact(my_model_name)
# Télécharger les poids du modèle dans un dossier et retourner le chemin
model_dir = my_model_artifact.download()
# Charger votre modèle Hugging Face depuis ce dossier
# en utilisant la même classe de modèle
model = AutoModelForSequenceClassification.from_pretrained(
model_dir, num_labels=num_labels
)
# Effectuer un entraînement supplémentaire ou exécuter l'inférence
```
### Comment puis-je reprendre l’entraînement à partir d’un point de contrôle ?
Si vous avez défini `WANDB_LOG_MODEL='checkpoint'`, vous pouvez également reprendre l’entraînement en utilisant `model_dir` comme valeur de l’argument `model_name_or_path` dans vos `TrainingArguments`, puis en passant `resume_from_checkpoint=True` à `Trainer`.
```python theme={null}
last_run_id = "xxxxxxxx" # récupérez le run_id depuis votre workspace wandb
# reprendre le run wandb à partir du run_id
with wandb.init(
project=os.environ["WANDB_PROJECT"],
id=last_run_id,
resume="must",
) as run:
# Connecter un Artifact au run
my_checkpoint_name = f"checkpoint-{last_run_id}:latest"
my_checkpoint_artifact = run.use_artifact(my_model_name)
# Télécharger le point de contrôle dans un dossier et retourner le chemin
checkpoint_dir = my_checkpoint_artifact.download()
# réinitialiser votre modèle et votre trainer
model = AutoModelForSequenceClassification.from_pretrained(
"
### Comment puis-je journaliser et afficher des échantillons d’évaluation pendant l’entraînement
La journalisation dans W\&B via le `Trainer` de Transformers est assurée par le [`WandbCallback`](https://huggingface.co/transformers/main_classes/callback.html#transformers.integrations.WandbCallback) de la bibliothèque Transformers. Si vous devez personnaliser votre journalisation Hugging Face, vous pouvez modifier ce callback en créant une sous-classe de `WandbCallback` et en ajoutant des fonctionnalités supplémentaires qui s’appuient sur d’autres méthodes de la classe Trainer.
Vous trouverez ci-dessous le schéma général pour ajouter ce nouveau callback au Trainer HF, puis plus bas un exemple de code complet pour journaliser les sorties d’évaluation dans un tableau W\&B :
```python theme={null}
# Instancier le Trainer normalement
trainer = Trainer()
# Instancier le nouveau callback de journalisation en lui passant l'objet Trainer
evals_callback = WandbEvalsCallback(trainer, tokenizer, ...)
# Ajouter le callback au Trainer
trainer.add_callback(evals_callback)
# Lancer l'entraînement du Trainer normalement
trainer.train()
```
#### Afficher des échantillons d’évaluation pendant l’entraînement
La section suivante montre comment personnaliser le `WandbCallback` pour exécuter les prédictions du modèle et journaliser des échantillons d’évaluation dans un tableau W\&B pendant l’entraînement. Nous le faisons tous les `eval_steps` en utilisant la méthode `on_evaluate` du callback du `Trainer`.
Ici, nous avons écrit une fonction `decode_predictions` pour décoder les prédictions et les labels à partir de la sortie du modèle à l’aide du tokenizer.
Ensuite, nous créons un dataframe pandas à partir des prédictions et des labels, puis nous ajoutons une colonne `epoch` au dataframe.
Enfin, nous créons un `wandb.Table` à partir du dataframe et le journalisons dans wandb.
De plus, nous pouvons contrôler la fréquence de la journalisation en journalisant les prédictions toutes les `freq` époques.
**Remarque** : contrairement au `WandbCallback` standard, ce callback personnalisé doit être ajouté au trainer **après** l’instanciation du `Trainer`, et non pendant l’initialisation du `Trainer`.
Cela s’explique par le fait que l’instance `Trainer` est transmise au callback lors de l’initialisation.
```python theme={null}
from transformers.integrations import WandbCallback
import pandas as pd
def decode_predictions(tokenizer, predictions):
labels = tokenizer.batch_decode(predictions.label_ids)
logits = predictions.predictions.argmax(axis=-1)
prediction_text = tokenizer.batch_decode(logits)
return {"labels": labels, "predictions": prediction_text}
class WandbPredictionProgressCallback(WandbCallback):
"""Custom WandbCallback to log model predictions during training.
This callback logs model predictions and labels to a wandb.Table at each
logging step during training. It allows to visualize the
model predictions as the training progresses.
Attributes:
trainer (Trainer): The Hugging Face Trainer instance.
tokenizer (AutoTokenizer): The tokenizer associated with the model.
sample_dataset (Dataset): A subset of the validation dataset
for generating predictions.
num_samples (int, optional): Number of samples to select from
the validation dataset for generating predictions. Defaults to 100.
freq (int, optional): Frequency of logging. Defaults to 2.
"""
def __init__(self, trainer, tokenizer, val_dataset, num_samples=100, freq=2):
"""Initializes the WandbPredictionProgressCallback instance.
Args:
trainer (Trainer): The Hugging Face Trainer instance.
tokenizer (AutoTokenizer): The tokenizer associated
with the model.
val_dataset (Dataset): The validation dataset.
num_samples (int, optional): Number of samples to select from
the validation dataset for generating predictions.
Defaults to 100.
freq (int, optional): Frequency of logging. Defaults to 2.
"""
super().__init__()
self.trainer = trainer
self.tokenizer = tokenizer
self.sample_dataset = val_dataset.select(range(num_samples))
self.freq = freq
def on_evaluate(self, args, state, control, **kwargs):
super().on_evaluate(args, state, control, **kwargs)
# contrôler la fréquence de journalisation en journalisant les prédictions
# toutes les `freq` époques
if state.epoch % self.freq == 0:
# générer les prédictions
predictions = self.trainer.predict(self.sample_dataset)
# décoder les prédictions et les labels
predictions = decode_predictions(self.tokenizer, predictions)
# ajouter les prédictions à un wandb.Table
predictions_df = pd.DataFrame(predictions)
predictions_df["epoch"] = state.epoch
records_table = self._wandb.Table(dataframe=predictions_df)
# journaliser le tableau dans wandb
self._wandb.log({"sample_predictions": records_table})
# D'abord, instancier le Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=lm_datasets["train"],
eval_dataset=lm_datasets["validation"],
)
# Instancier le WandbPredictionProgressCallback
progress_callback = WandbPredictionProgressCallback(
trainer=trainer,
tokenizer=tokenizer,
val_dataset=lm_dataset["validation"],
num_samples=10,
freq=2,
)
# Ajouter le callback au trainer
trainer.add_callback(progress_callback)
```
Pour un exemple plus détaillé, veuillez vous référer à ce [colab](https://colab.research.google.com/github/wandb/examples/blob/master/colabs/huggingface/Custom_Progress_Callback.ipynb)
### Quels paramètres W\&B supplémentaires sont disponibles ?
Vous pouvez affiner la configuration de ce qui est enregistré avec `Trainer` en définissant des variables d'environnement. Une liste complète des variables d'environnement W\&B [est disponible ici](/fr/platform/hosting/env-vars).
| Variable d'environnement | Utilisation |
| ------------------------ | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `WANDB_PROJECT` | Donnez un nom à votre projet (`huggingface` par défaut) |
| `WANDB_LOG_MODEL` | Enregistre le point de contrôle du modèle en tant qu'Artifact W\&B (`false` par défaut)
false(par défaut) : aucun point de contrôle du modèlecheckpoint: un point de contrôle sera téléversé tous les args.save\_steps (défini dans les TrainingArguments de Trainer).end: le point de contrôle final du modèle sera téléversé à la fin de l'entraînement.
Définit si vous souhaitez enregistrer, pour vos modèles, les gradients, les paramètres ou aucun des deux
false(par défaut) : aucune journalisation des gradients ni des paramètresgradients: enregistre des histogrammes des gradientsall: enregistre des histogrammes des gradients et des paramètres
### Comment puis-je personnaliser `wandb.init()`?
Le `WandbCallback` utilisé par `Trainer` appelle `wandb.init()` en interne lors de l'initialisation de `Trainer`. Vous pouvez aussi configurer vos runs manuellement en appelant `wandb.init()` avant l'initialisation de `Trainer`. Cela vous donne un contrôle total sur la configuration de votre run W\&B.
Voici un exemple de ce que vous pouvez passer à `init`. Pour plus de détails sur `wandb.init()`, voir la [`référence \`wandb.init()\`\`](/fr/models/ref/python/functions/init).
```python theme={null}
wandb.init(
project="amazon_sentiment_analysis",
name="bert-base-high-lr",
tags=["baseline", "high-lr"],
group="bert",
)
```
## Ressources supplémentaires
Voici 6 articles liés à Transformers et à W\&B qui pourraient vous intéresser
Optimisation des hyperparamètres pour Hugging Face Transformers
* Trois stratégies d'optimisation des hyperparamètres pour Hugging Face Transformers sont comparées : la recherche sur grille, l'optimisation bayésienne et le Population Based Training. * Nous utilisons un modèle BERT standard en minuscules de Hugging Face Transformers, et nous voulons effectuer un Fine-tuning sur le jeu de données RTE du benchmark SuperGLUE. * Les résultats montrent que le Population Based Training est l'approche la plus efficace pour optimiser les hyperparamètres de notre modèle Transformer Hugging Face. Lisez le [rapport Hyperparameter Optimization for Hugging Face Transformers](https://wandb.ai/amogkam/transformers/reports/Hyperparameter-Optimization-for-Hugging-Face-Transformers--VmlldzoyMTc2ODI).Hugging Tweets : entraîner un modèle pour générer des tweets
* Dans cet article, l'auteur montre comment effectuer le Fine-tuning d'un modèle Transformer GPT-2 préentraîné de Hugging Face sur les tweets de n'importe quelle personne en cinq minutes. * Le modèle suit le pipeline suivant : téléchargement des tweets, optimisation du jeu de données, expériences initiales, comparaison des pertes entre Users, Fine-tuning du modèle. Lisez le rapport complet [ici](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).Classification de phrases avec Hugging Face BERT et WB
* Dans cet article, nous allons créer un classifieur de phrases en tirant parti des avancées récentes en traitement du langage naturel, en nous concentrant sur une application de l'apprentissage par transfert au NLP. * Nous utiliserons le jeu de données The Corpus of Linguistic Acceptability (CoLA) pour la classification de phrases isolées. Il s'agit d'un ensemble de phrases étiquetées comme grammaticalement correctes ou incorrectes, publié pour la première fois en mai 2018. * Nous utiliserons le BERT de Google pour créer des modèles très performants avec un minimum d'effort sur un large éventail de tâches NLP. Lisez le rapport complet [ici](https://wandb.ai/cayush/bert-finetuning/reports/Sentence-Classification-With-Huggingface-BERT-and-W-B--Vmlldzo4MDMwNA).Guide étape par étape pour suivre les performances des modèles Hugging Face
* Nous utilisons W\&B et Hugging Face Transformers pour entraîner DistilBERT, un Transformer 40 % plus petit que BERT mais qui conserve 97 % de la précision de BERT, sur le benchmark GLUE. * Le benchmark GLUE est une collection de neuf jeux de données et tâches pour entraîner des modèles NLP. Lisez le rapport complet [ici](https://wandb.ai/jxmorris12/huggingface-demo/reports/A-Step-by-Step-Guide-to-Tracking-HuggingFace-Model-Performance--VmlldzoxMDE2MTU).Exemples d'arrêt anticipé dans HuggingFace
* Le Fine-tuning d'un Transformer Hugging Face à l'aide de la régularisation par arrêt anticipé peut être effectué nativement dans PyTorch ou TensorFlow. * L'utilisation du callback EarlyStopping dans TensorFlow est simple avec le callback `tf.keras.callbacks.EarlyStopping`. * Dans PyTorch, il n'existe pas de méthode d'arrêt anticipé prête à l'emploi, mais un hook d'arrêt anticipé fonctionnel est disponible dans un GitHub Gist. Lisez le rapport complet [ici](https://wandb.ai/ayush-thakur/huggingface/reports/Early-Stopping-in-HuggingFace-Examples--Vmlldzo0MzE2MTM).Comment effectuer le Fine-tuning de Hugging Face Transformers sur un jeu de données personnalisé
Nous effectuons le Fine-tuning d'un Transformer DistilBERT pour l'analyse de sentiment (classification binaire) sur un jeu de données IMDB personnalisé. Lisez le rapport complet [ici](https://wandb.ai/ayush-thakur/huggingface/reports/How-to-Fine-Tune-HuggingFace-Transformers-on-a-Custom-Dataset--Vmlldzo0MzQ2MDc).
## Obtenir de l'aide ou suggérer des fonctionnalités
Pour tout problème, toute question ou toute demande de fonctionnalité concernant l'intégration W\&B de Hugging Face, n'hésitez pas à publier dans [ce fil de discussion sur les forums Hugging Face](https://discuss.huggingface.co/t/logging-experiment-tracking-with-w-b/498) ou à ouvrir une issue dans le [dépôt GitHub Transformers](https://github.com/huggingface/transformers) de Hugging Face.