> ## Documentation Index
> Fetch the complete documentation index at: https://docs.wandb.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# PyTorch Lightning
> Utilisez W&B avec PyTorch Lightning grâce au WandbLogger intégré pour le suivi des expériences et l’enregistrement de points de contrôle du modèle.
export const ColabLink = ({url}) =>
Essayer sur Colab
;
{/* */}
PyTorch Lightning fournit un wrapper léger pour organiser votre code PyTorch et ajouter facilement des fonctionnalités avancées telles que l’entraînement distribué et la précision en 16 bits. W\&B fournit un wrapper léger pour consigner vos expériences de ML. Mais vous n’avez pas besoin de combiner les deux vous-même : W\&B est directement intégré à la bibliothèque PyTorch Lightning via le [`WandbLogger`](https://lightning.ai/docs/pytorch/stable/api/lightning.pytorch.loggers.wandb.html#module-lightning.pytorch.loggers.wandb).
## Intégrer Lightning
```python theme={null}
from lightning.pytorch.loggers import WandbLogger
from lightning.pytorch import Trainer
wandb_logger = WandbLogger(log_model="all")
trainer = Trainer(logger=wandb_logger)
```
**Utilisation de wandb.log() :** Le `WandbLogger` envoie les journaux vers W\&B en utilisant le `global_step` du Trainer. Si vous effectuez des appels supplémentaires à `wandb.log()` directement dans votre code, **n'utilisez pas** l'argument `step` dans `wandb.log()`.
À la place, journalisez le `global_step` du Trainer comme vos autres métriques :
```python theme={null}
wandb.log({"accuracy":0.99, "trainer/global_step": step})
```
```python theme={null}
import lightning as L
from wandb.integration.lightning.fabric import WandbLogger
wandb_logger = WandbLogger(log_model="all")
fabric = L.Fabric(loggers=[wandb_logger])
fabric.launch()
fabric.log_dict({"important_metric": important_metric})
```
```
```
### Inscrivez-vous et créez une clé API
Une clé API permet d’authentifier votre machine auprès de W\&B. Vous pouvez générer une clé API depuis votre profil.
Pour une méthode plus directe, accédez aux [Paramètres utilisateur](https://wandb.ai/settings) et créez une clé API. Copiez immédiatement la clé API et conservez-la dans un endroit sûr, par exemple dans un gestionnaire de mots de passe.
1. Cliquez sur l’icône de votre profil en haut à droite.
2. Sélectionnez **Paramètres utilisateur**, puis faites défiler jusqu’à la section **Clés API**.
### Installez la bibliothèque `wandb` et connectez-vous
Pour installer la bibliothèque `wandb` localement et vous connecter :
1. Définissez la [variable d'environnement](/fr/models/track/environment-variables/) `WANDB_API_KEY` sur votre clé API.
```bash theme={null}
export WANDB_API_KEY=
```
2. Installez la bibliothèque `wandb` et connectez-vous.
```shell theme={null}
pip install wandb
wandb login
```
```bash theme={null}
pip install wandb
```
```python theme={null}
import wandb
wandb.login()
```
```notebook theme={null}
!pip install wandb
import wandb
wandb.login()
```
## Utiliser le `WandbLogger` de PyTorch Lightning
PyTorch Lightning propose plusieurs classes `WandbLogger` pour consigner des métriques, ainsi que les poids du modèle, des médias, et bien plus encore.
* [`PyTorch`](https://lightning.ai/docs/pytorch/stable/api/lightning.pytorch.loggers.wandb.html#module-lightning.pytorch.loggers.wandb)
* [`Fabric`](https://lightning.ai/docs/pytorch/stable/api/lightning.pytorch.loggers.wandb.html#module-lightning.pytorch.loggers.wandb)
Pour l’utiliser avec Lightning, instanciez `WandbLogger`, puis transmettez-le à `Trainer` ou à `Fabric` de Lightning.
```python theme={null}
trainer = Trainer(logger=wandb_logger)
```
```python theme={null}
fabric = L.Fabric(loggers=[wandb_logger])
fabric.launch()
fabric.log_dict({
"important_metric": important_metric
})
```
### Arguments courants du logger
Vous trouverez ci-dessous quelques-uns des paramètres les plus utilisés dans `WandbLogger`. Consultez la documentation de PyTorch Lightning pour en savoir plus sur tous les arguments du logger.
* [`PyTorch`](https://lightning.ai/docs/pytorch/stable/api/lightning.pytorch.loggers.wandb.html#module-lightning.pytorch.loggers.wandb)
* [`Fabric`](https://lightning.ai/docs/pytorch/stable/api/lightning.pytorch.loggers.wandb.html#module-lightning.pytorch.loggers.wandb)
| Paramètre | Description |
| ----------- | --------------------------------------------------------------------------------------------------- |
| `project` | Définit dans quel projet wandb journaliser |
| `name` | Donne un nom à votre run wandb |
| `log_model` | Journalise tous les modèles si `log_model="all"`, ou à la fin de l'entraînement si `log_model=True` |
| `save_dir` | Chemin où les données sont enregistrées |
## Journaliser des paramètres de configuration supplémentaires
```python theme={null}
# ajouter un paramètre
wandb_logger.experiment.config["key"] = value
# ajouter plusieurs paramètres
wandb_logger.experiment.config.update({key1: val1, key2: val2})
# utiliser directement le module wandb
wandb.config["key"] = value
wandb.config.update()
```
## Journaliser les gradients, l’histogramme des paramètres et la topologie du modèle
Vous pouvez passer l’objet de votre modèle à `wandblogger.watch()` pour surveiller les gradients et les paramètres de votre modèle pendant l’entraînement. Voir la documentation de `WandbLogger` pour PyTorch Lightning
## Journaliser des métriques
Vous pouvez journaliser vos métriques dans W\&B lorsque vous utilisez `WandbLogger` en appelant `self.log('my_metric_name', metric_vale)` dans votre `LightningModule`, par exemple dans les méthodes `training_step` ou `validation_step`.
L’extrait de code ci-dessous montre comment définir votre `LightningModule` pour journaliser vos métriques ainsi que les hyperparamètres de votre `LightningModule`. Cet exemple utilise la bibliothèque [`torchmetrics`](https://github.com/Lightning-AI/torchmetrics) pour calculer vos métriques.
```python theme={null}
import torch
from torch.nn import Linear, CrossEntropyLoss, functional as F
from torch.optim import Adam
from torchmetrics.functional import accuracy
from lightning.pytorch import LightningModule
class My_LitModule(LightningModule):
def __init__(self, n_classes=10, n_layer_1=128, n_layer_2=256, lr=1e-3):
"""méthode utilisée pour définir les paramètres du modèle"""
super().__init__()
# les images MNIST ont la forme (1, 28, 28) (canaux, largeur, hauteur)
self.layer_1 = Linear(28 * 28, n_layer_1)
self.layer_2 = Linear(n_layer_1, n_layer_2)
self.layer_3 = Linear(n_layer_2, n_classes)
self.loss = CrossEntropyLoss()
self.lr = lr
# enregistrer les hyperparamètres dans self.hparams (journalisés automatiquement par W&B)
self.save_hyperparameters()
def forward(self, x):
"""méthode utilisée pour l’inférence, de l’entrée à la sortie"""
# (b, 1, 28, 28) -> (b, 1*28*28)
batch_size, channels, width, height = x.size()
x = x.view(batch_size, -1)
# effectuons 3 x (linear + relu)
x = F.relu(self.layer_1(x))
x = F.relu(self.layer_2(x))
x = self.layer_3(x)
return x
def training_step(self, batch, batch_idx):
"""doit renvoyer une perte à partir d’un seul lot"""
_, loss, acc = self._get_preds_loss_accuracy(batch)
# Journaliser la perte et la métrique
self.log("train_loss", loss)
self.log("train_accuracy", acc)
return loss
def validation_step(self, batch, batch_idx):
"""utilisée pour journaliser des métriques"""
preds, loss, acc = self._get_preds_loss_accuracy(batch)
# Journaliser la perte et la métrique
self.log("val_loss", loss)
self.log("val_accuracy", acc)
return preds
def configure_optimizers(self):
"""définit l’optimiseur du modèle"""
return Adam(self.parameters(), lr=self.lr)
def _get_preds_loss_accuracy(self, batch):
"""fonction utilitaire, car les étapes d’entraînement, de validation et de test sont similaires"""
x, y = batch
logits = self(x)
preds = torch.argmax(logits, dim=1)
loss = self.loss(logits, y)
acc = accuracy(preds, y)
return preds, loss, acc
```
```python theme={null}
import lightning as L
import torch
import torchvision as tv
from wandb.integration.lightning.fabric import WandbLogger
import wandb
fabric = L.Fabric(loggers=[wandb_logger])
fabric.launch()
model = tv.models.resnet18()
optimizer = torch.optim.SGD(model.parameters(), lr=lr)
model, optimizer = fabric.setup(model, optimizer)
train_dataloader = fabric.setup_dataloaders(
torch.utils.data.DataLoader(train_dataset, batch_size=batch_size)
)
model.train()
for epoch in range(num_epochs):
for batch in train_dataloader:
optimizer.zero_grad()
loss = model(batch)
loss.backward()
optimizer.step()
fabric.log_dict({"loss": loss})
```
```
```
## Journaliser les valeurs min/max d’une métrique
Avec la fonction [`define_metric`](/fr/models/ref/python/experiments/run#define_metric) de wandb, vous pouvez définir si vous souhaitez que votre métrique de synthèse W\&B affiche la valeur minimale, maximale, moyenne ou la meilleure valeur pour cette métrique. Si `define`\_`metric` \_ n’est pas utilisé, la dernière valeur journalisée apparaîtra dans vos métriques de synthèse. Voir la [documentation de référence de `define_metric` ici](/fr/models/ref/python/experiments/run#define_metric) et le [guide ici](/fr/models/track/log/customize-logging-axes/) pour en savoir plus.
Pour indiquer à W\&B de suivre la précision de validation maximale dans la métrique de synthèse W\&B, appelez `wandb.define_metric()` une seule fois, au début de l’entraînement :
```python theme={null}
class My_LitModule(LightningModule):
...
def validation_step(self, batch, batch_idx):
if trainer.global_step == 0:
wandb.define_metric("val_accuracy", summary="max")
preds, loss, acc = self._get_preds_loss_accuracy(batch)
# Journaliser la perte et la métrique
self.log("val_loss", loss)
self.log("val_accuracy", acc)
return preds
```
```python theme={null}
wandb.define_metric("val_accuracy", summary="max")
fabric = L.Fabric(loggers=[wandb_logger])
fabric.launch()
fabric.log_dict({"val_accuracy": val_accuracy})
```
## Créer un point de contrôle d’un modèle
Pour enregistrer des points de contrôle du modèle en tant qu’Artifacts W\&B [Artifacts](/fr/models/artifacts/),
utilisez le callback Lightning [`ModelCheckpoint`](https://lightning.ai/docs/pytorch/stable/api/lightning.pytorch.callbacks.ModelCheckpoint.html) et définissez l’argument `log_model` dans `WandbLogger`.
```python theme={null}
trainer = Trainer(logger=wandb_logger, callbacks=[checkpoint_callback])
```
```python theme={null}
fabric = L.Fabric(loggers=[wandb_logger], callbacks=[checkpoint_callback])
```
Les alias *latest* et *best* sont automatiquement définis pour vous permettre de récupérer facilement un point de contrôle du modèle depuis un [Artifact](/fr/models/artifacts/) W\&B :
```python theme={null}
# la référence peut être récupérée dans le panneau des artifacts
# "VERSION" peut être une version (ex : "v2") ou un alias ("latest" ou "best")
checkpoint_reference = "USER/PROJECT/MODEL-RUN_ID:VERSION"
```
```python theme={null}
# télécharger le point de contrôle en local (s'il n'est pas déjà en cache)
wandb_logger.download_artifact(checkpoint_reference, artifact_type="model")
```
```python theme={null}
# télécharger le point de contrôle en local (s'il n'est pas déjà en cache)
run = wandb.init(project="MNIST")
artifact = run.use_artifact(checkpoint_reference, type="model")
artifact_dir = artifact.download()
```
```python theme={null}
# charger le point de contrôle
model = LitModule.load_from_checkpoint(Path(artifact_dir) / "model.ckpt")
```
```python theme={null}
# récupérer le point de contrôle brut
full_checkpoint = fabric.load(Path(artifact_dir) / "model.ckpt")
model.load_state_dict(full_checkpoint["model"])
optimizer.load_state_dict(full_checkpoint["optimizer"])
```
Les points de contrôle de modèle que vous journalisez sont visibles dans l'UI [W\&B Artifacts](/fr/models/artifacts/) et incluent la traçabilité complète du modèle (voir un exemple de point de contrôle de modèle dans l'UI [ici](https://wandb.ai/wandb/arttest/artifacts/model/iv3_trained/5334ab69740f9dda4fed/lineage?_gl=1*yyql5q*_ga*MTQxOTYyNzExOS4xNjg0NDYyNzk1*_ga_JH1SJHJQXJ*MTY5MjMwNzI2Mi4yNjkuMS4xNjkyMzA5NjM2LjM3LjAuMA..)).
Pour mettre vos meilleurs points de contrôle de modèle en favoris et les centraliser pour votre équipe, vous pouvez les lier au [registre de modèles W\&B](/fr/models).
Vous pouvez y organiser vos meilleurs modèles par tâche, gérer le cycle de vie des modèles, faciliter leur suivi et leur audit tout au long du cycle de vie du ML, et [automatiser](/fr/models/automations/) les actions en aval avec des webhooks ou des jobs.
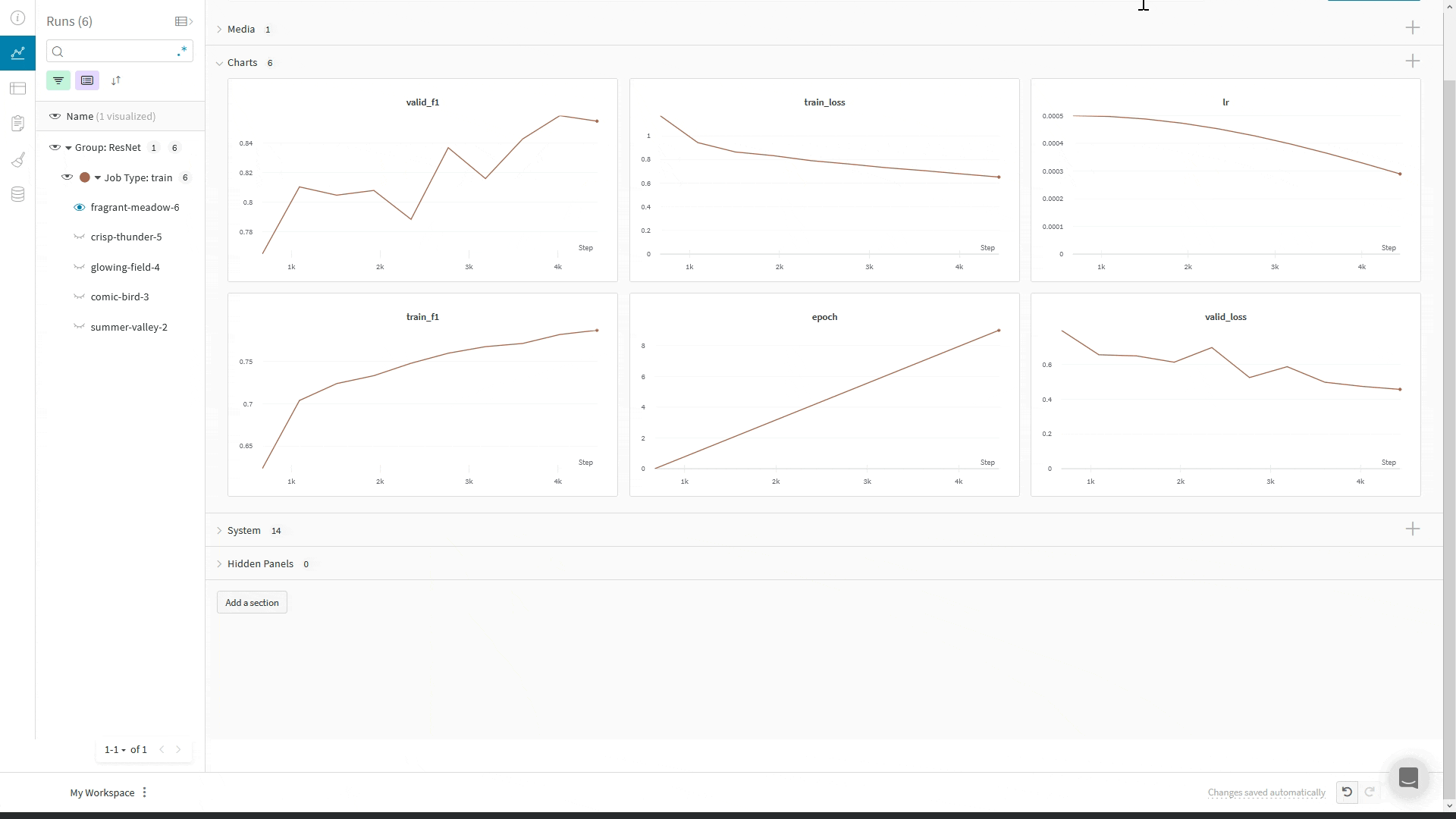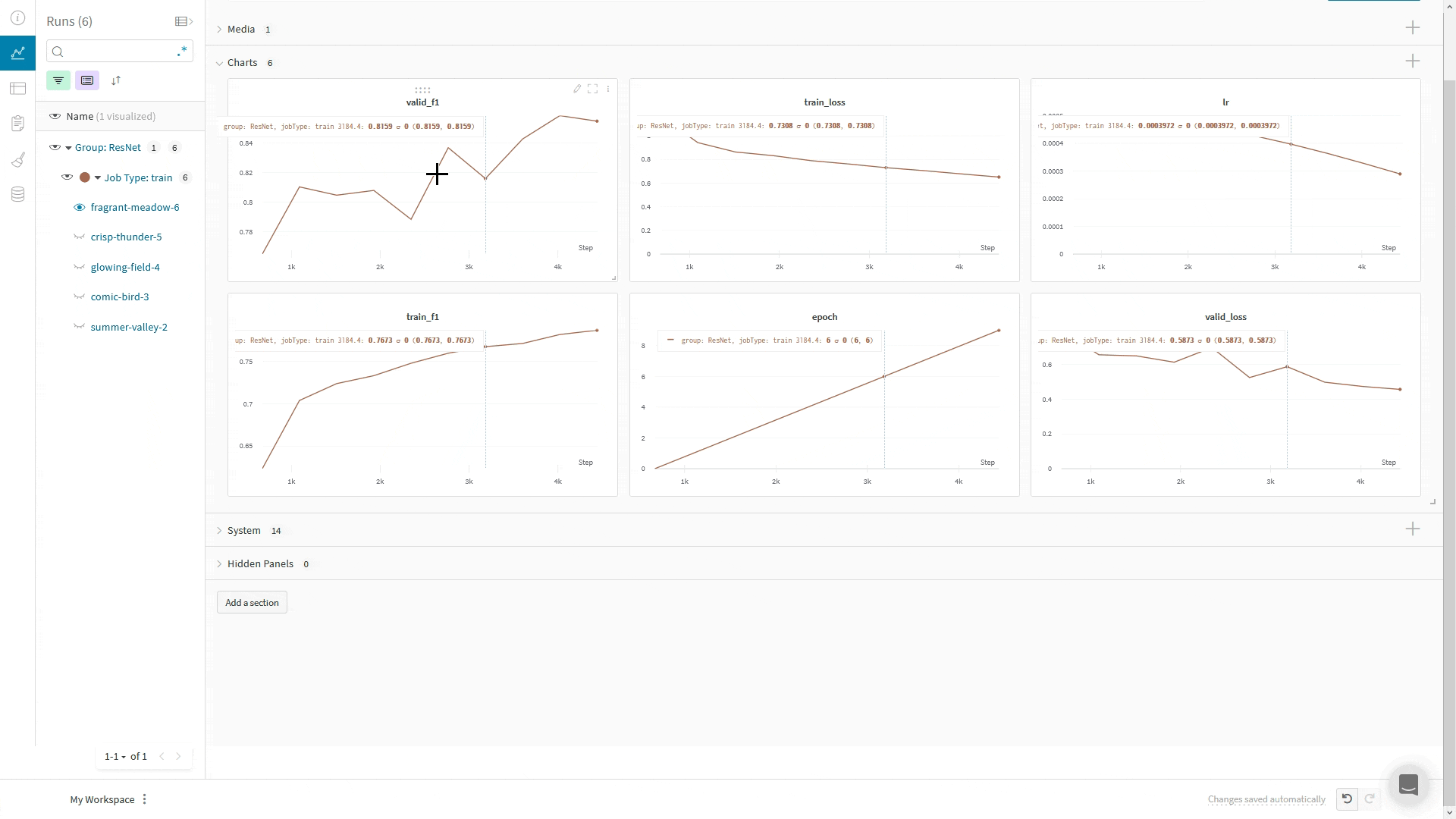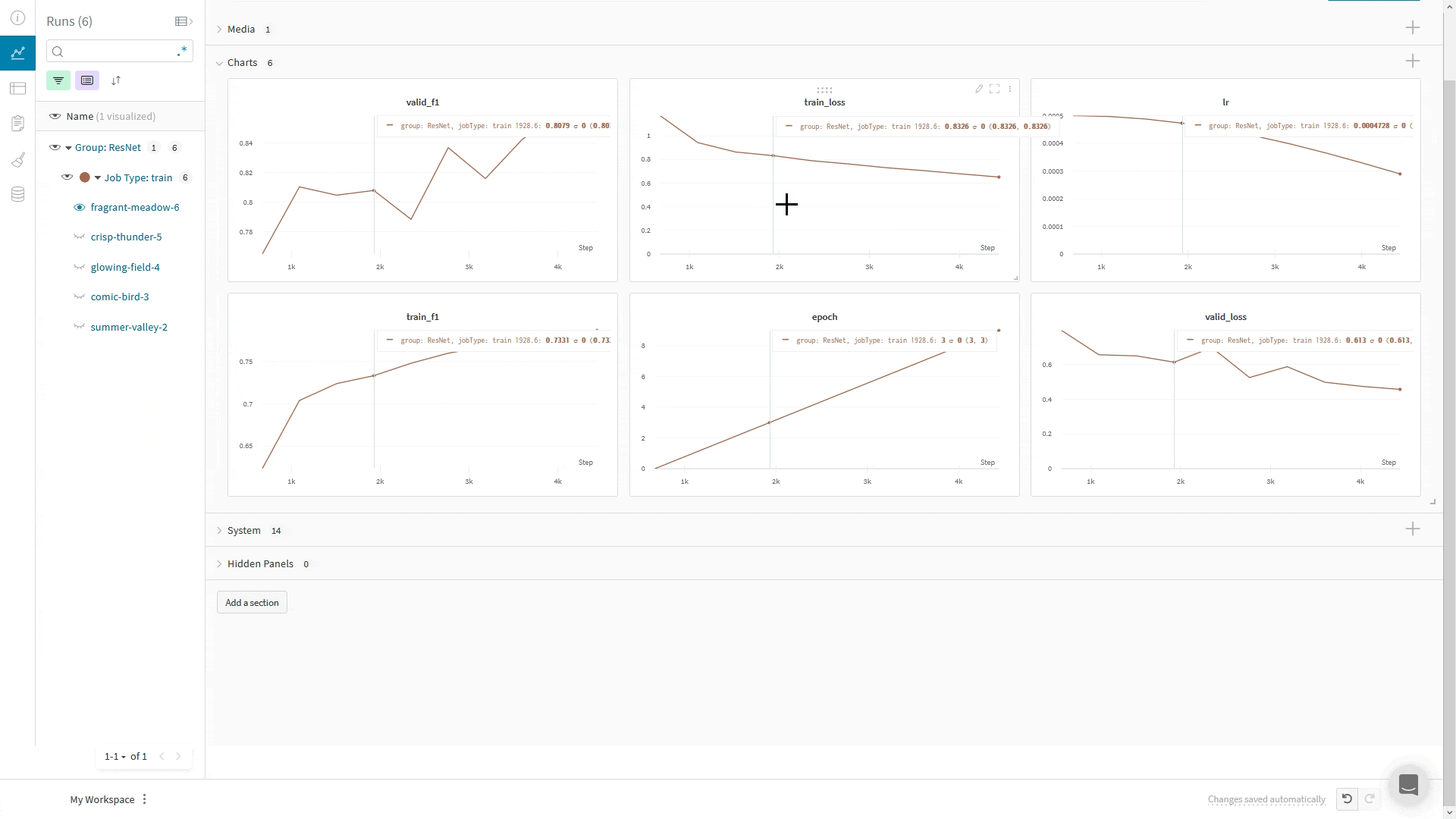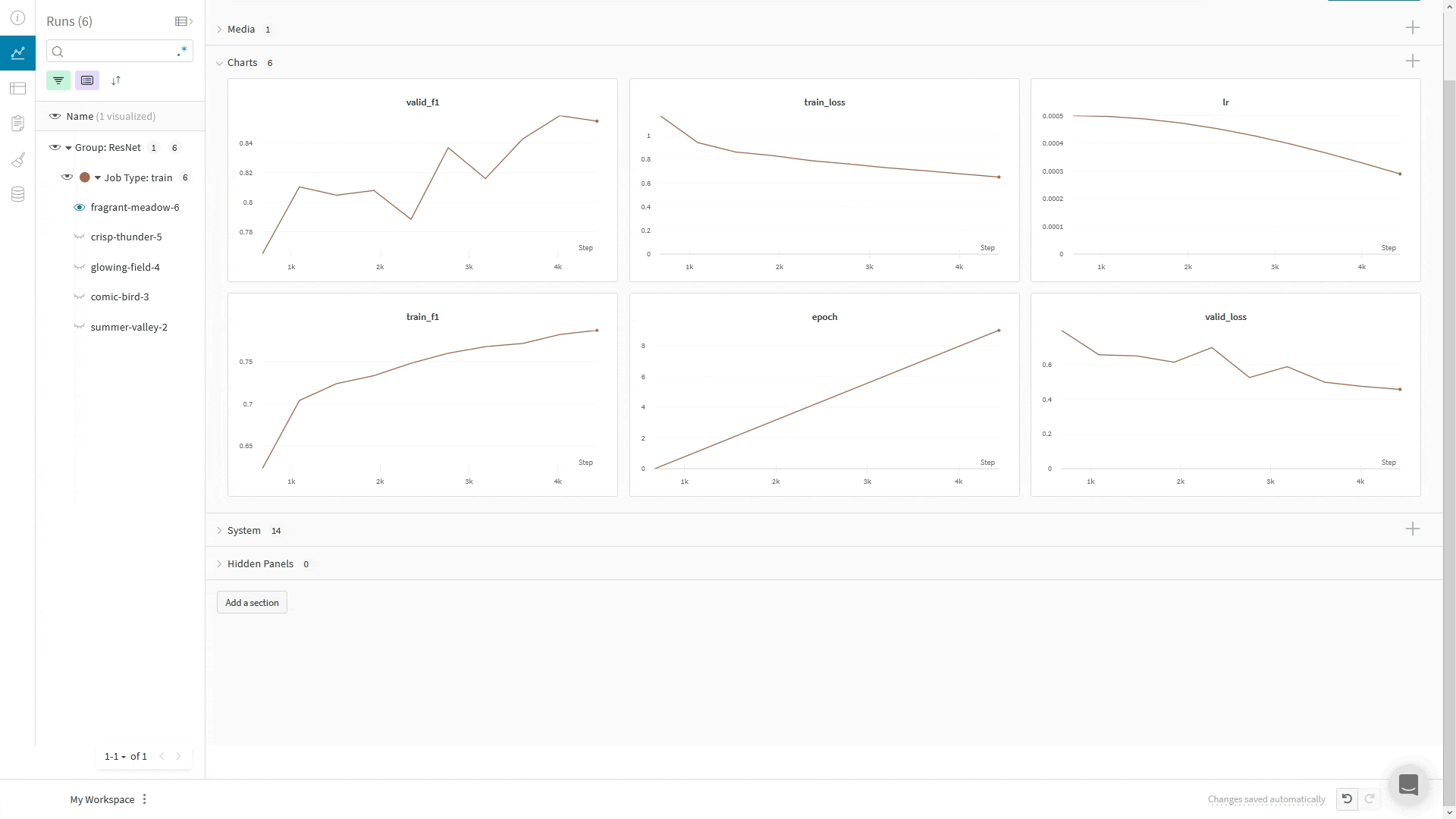
## Journaliser des images, du texte et plus encore
Le `WandbLogger` fournit les méthodes `log_image`, `log_text` et `log_table` pour la journalisation de médias.
Vous pouvez aussi appeler directement `wandb.log()` ou `trainer.logger.experiment.log()` pour journaliser d'autres types de médias, comme Audio, des molécules, des nuages de points, des objets 3D, et bien plus encore.
```python theme={null}
# utiliser des tenseurs, des tableaux NumPy ou des images PIL
wandb_logger.log_image(key="samples", images=[img1, img2])
# ajouter des légendes
wandb_logger.log_image(key="samples", images=[img1, img2], caption=["tree", "person"])
# utiliser un chemin de fichier
wandb_logger.log_image(key="samples", images=["img_1.jpg", "img_2.jpg"])
# utiliser .log dans le trainer
trainer.logger.experiment.log(
{"samples": [wandb.Image(img, caption=caption) for (img, caption) in my_images]},
step=current_trainer_global_step,
)
```
```python theme={null}
# les données doivent être une liste de listes
columns = ["input", "label", "prediction"]
my_data = [["cheese", "english", "english"], ["fromage", "french", "spanish"]]
# utiliser les colonnes et les données
wandb_logger.log_text(key="my_samples", columns=columns, data=my_data)
# utiliser un DataFrame pandas
wandb_logger.log_text(key="my_samples", dataframe=my_dataframe)
```
```python theme={null}
# journaliser un tableau W&B contenant une légende textuelle, une image et de l'audio
columns = ["caption", "image", "sound"]
# les données doivent être une liste de listes
my_data = [
["cheese", wandb.Image(img_1), wandb.Audio(snd_1)],
["wine", wandb.Image(img_2), wandb.Audio(snd_2)],
]
# journaliser le tableau
wandb_logger.log_table(key="my_samples", columns=columns, data=data)
```
Vous pouvez utiliser le système de callbacks de Lightning pour contrôler quand vous journalisez vers W\&B via `WandbLogger` ; dans cet exemple, nous journalisons un échantillon de nos images de validation et de nos prédictions :
```python theme={null}
import torch
import wandb
import lightning.pytorch as pl
from lightning.pytorch.loggers import WandbLogger
# ou
# from wandb.integration.lightning.fabric import WandbLogger
class LogPredictionSamplesCallback(Callback):
def on_validation_batch_end(
self, trainer, pl_module, outputs, batch, batch_idx, dataloader_idx
):
"""Called when the validation batch ends."""
# `outputs` provient de `LightningModule.validation_step`
# ce qui correspond aux prédictions de notre modèle dans ce cas
# Journalisons 20 exemples de prédictions d'images du premier batch
if batch_idx == 0:
n = 20
x, y = batch
images = [img for img in x[:n]]
captions = [
f"Ground Truth: {y_i} - Prediction: {y_pred}"
for y_i, y_pred in zip(y[:n], outputs[:n])
]
# Option 1 : journaliser les images avec `WandbLogger.log_image`
wandb_logger.log_image(key="sample_images", images=images, caption=captions)
# Option 2 : journaliser les images et les prédictions sous forme de W&B Table
columns = ["image", "ground truth", "prediction"]
data = [
[wandb.Image(x_i), y_i, y_pred] or x_i,
y_i,
y_pred in list(zip(x[:n], y[:n], outputs[:n])),
]
wandb_logger.log_table(key="sample_table", columns=columns, data=data)
trainer = pl.Trainer(callbacks=[LogPredictionSamplesCallback()])
```
## Utiliser plusieurs GPU avec Lightning et W\&B
PyTorch Lightning prend en charge le multi-GPU via son interface DDP. Cependant, la conception de PyTorch Lightning exige que vous fassiez attention à la façon dont vous instanciez vos GPU.
Lightning part du principe que chaque GPU (ou rang) dans votre boucle d’entraînement doit être instancié exactement de la même manière, avec les mêmes conditions initiales. Cependant, seul le processus de rang 0 a accès à l’objet `wandb.run`, et pour les processus de rang non nul : `wandb.run = None`. Cela peut faire échouer vos processus non nuls. Une telle situation peut vous placer dans un **interblocage**, car le processus de rang 0 attendra que les processus de rang non nul le rejoignent, alors qu’ils ont déjà planté.
Pour cette raison, faites attention à la façon dont vous configurez votre code d’entraînement. La méthode recommandée consiste à rendre votre code indépendant de l’objet `wandb.run`.
```python theme={null}
class MNISTClassifier(pl.LightningModule):
def __init__(self):
super(MNISTClassifier, self).__init__()
self.model = nn.Sequential(
nn.Flatten(),
nn.Linear(28 * 28, 128),
nn.ReLU(),
nn.Linear(128, 10),
)
self.loss = nn.CrossEntropyLoss()
def forward(self, x):
return self.model(x)
def training_step(self, batch, batch_idx):
x, y = batch
y_hat = self.forward(x)
loss = self.loss(y_hat, y)
self.log("train/loss", loss)
return {"train_loss": loss}
def validation_step(self, batch, batch_idx):
x, y = batch
y_hat = self.forward(x)
loss = self.loss(y_hat, y)
self.log("val/loss", loss)
return {"val_loss": loss}
def configure_optimizers(self):
return torch.optim.Adam(self.parameters(), lr=0.001)
def main():
# Définir toutes les graines aléatoires sur la même valeur.
# C'est important dans un contexte d'entraînement distribué.
# Chaque rang obtiendra son propre ensemble de poids initiaux.
# S'ils ne correspondent pas, les gradients ne correspondront pas non plus,
# ce qui risque de mener à un entraînement qui ne converge pas.
pl.seed_everything(1)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True, num_workers=4)
val_loader = DataLoader(val_dataset, batch_size=64, shuffle=False, num_workers=4)
model = MNISTClassifier()
wandb_logger = WandbLogger(project="")
callbacks = [
ModelCheckpoint(
dirpath="checkpoints",
every_n_train_steps=100,
),
]
trainer = pl.Trainer(
max_epochs=3, gpus=2, logger=wandb_logger, strategy="ddp", callbacks=callbacks
)
trainer.fit(model, train_loader, val_loader)
```
## Exemples
Vous pouvez suivre ce tutoriel dans une [vidéo avec un notebook Colab](https://wandb.me/lit-colab).
## Foire aux questions
### Comment W\&B s’intègre-t-il à Lightning ?
L’intégration principale s’appuie sur l’API [Lightning `loggers`](https://lightning.ai/docs/pytorch/stable/extensions/logging.html), qui vous permet d’écrire une grande partie de votre code de journalisation de manière indépendante du framework. Les `Logger` sont transmis au [Lightning `Trainer`](https://lightning.ai/docs/pytorch/stable/common/trainer.html) et sont déclenchés par le riche [système de hooks et de callbacks](https://lightning.ai/docs/pytorch/stable/extensions/callbacks.html) de cette API. Cela permet de bien séparer votre code de recherche du code d’ingénierie et de journalisation.
### Que journalise l’intégration sans code supplémentaire ?
Nous enregistrerons les points de contrôle du modèle dans W\&B, où vous pourrez les consulter ou les télécharger pour les utiliser dans de futurs runs. Nous capturerons également les [métriques système](/fr/models/ref/python/experiments/system-metrics), comme l’utilisation du GPU et les entrées/sorties réseau, des informations sur l’environnement, comme les caractéristiques du matériel et du système d’exploitation, l’[état du code](/fr/models/app/features/panels/code/) (y compris le commit git et le patch diff, le contenu du notebook et l’historique de la session), ainsi que tout ce qui est affiché dans la sortie standard.
### Que faire si j’ai besoin d’utiliser `wandb.run` dans ma configuration d’entraînement ?
Vous devez vous-même élargir la portée de la variable à laquelle vous souhaitez accéder. En d’autres termes, veillez à ce que les conditions initiales soient identiques dans tous les processus.
```python theme={null}
if os.environ.get("LOCAL_RANK", None) is None:
os.environ["WANDB_DIR"] = wandb.run.dir
```
Si c’est le cas, vous pouvez utiliser `os.environ["WANDB_DIR"]` pour configurer le répertoire des points de contrôle du modèle. Ainsi, tout processus de rang non nul peut accéder à `wandb.run.dir`.
 ```
```
```
```