> ## Documentation Index
> Fetch the complete documentation index at: https://docs.wandb.ai/llms.txt
> Use this file to discover all available pages before exploring further.
> Évaluer un modèle d’API hébergé à l’aide d’une infrastructure gérée par CoreWeave
# Évaluer un modèle d’API hébergé
Les jobs d’Évaluation LLM sont en **Aperçu** sur [W\&B Multi-tenant Cloud](/fr/platform/hosting/hosting-options/multi_tenant_cloud). Les ressources de calcul sont gratuites pendant la période d’aperçu. Voir [la tarification des jobs d’Évaluation LLM](/fr/models/launch#pricing) pour plus de détails.
Cette page explique comment utiliser les [LLM Evaluation Jobs](/fr/models/launch) pour exécuter une série de benchmarks d’évaluation sur un modèle d’API hébergé, accessible via une URL publique, à l’aide d’une infrastructure gérée par CoreWeave. L’exécution de ces benchmarks vous aide à comparer les performances du modèle, à valider sa qualité et à publier les résultats dans un classement partagé sans gérer votre propre infrastructure d’évaluation. Pour évaluer un point de contrôle du modèle enregistré en tant qu’artifact dans W\&B Models, consultez plutôt [Évaluer un point de contrôle du modèle](/fr/models/launch/evaluate-model-checkpoint).
## Prérequis
Avant de créer un job d’évaluation, effectuez les opérations suivantes :
1. Consultez les [exigences et limitations](/fr/models/launch#more-details) des LLM Evaluation Jobs.
2. Pour exécuter certains benchmarks, un administrateur d’équipe doit ajouter les clés API requises comme secrets au niveau de l’équipe. Tout membre de l’équipe peut ensuite spécifier le secret lors de la configuration d’un job d’évaluation.
* Une **clé API OpenAI** : utilisée par les benchmarks qui se servent de modèles OpenAI pour attribuer un score. Requise si le champ **clé API du scorer** apparaît après avoir sélectionné un benchmark. Le secret doit être nommé `OPENAI_API_KEY`.
* Un **jeton d’accès utilisateur Hugging Face** : requis pour certains benchmarks comme `lingoly` et `lingoly2`, qui nécessitent l’accès à un ou plusieurs jeux de données Hugging Face à accès restreint. Requis si le champ **jeton Hugging Face** apparaît après la sélection d’un benchmark. La clé API doit donner accès au jeu de données concerné. Voir la documentation Hugging Face sur les [jetons d’accès utilisateur](https://huggingface.co/docs/hub/en/security-tokens) et [l’accès aux jeux de données à accès restreint](https://huggingface.co/docs/hub/en/datasets-gated#access-gated-datasets-as-a-user).
* Pour évaluer un modèle fourni par [Serverless Inference](/fr/inference), un administrateur d’organisation ou d’équipe doit créer `WANDB_API_KEY` avec n’importe quelle valeur. Le secret n’est en réalité pas utilisé pour l’authentification.
3. Le modèle à évaluer doit être disponible à une URL accessible publiquement. Un administrateur d’organisation ou d’équipe doit créer un secret au niveau de l’équipe contenant la clé API d’authentification.
4. Créez un nouveau [projet W\&B](/fr/models/track/project-page) pour les résultats de l’évaluation. Dans la barre latérale du projet, cliquez sur **Create new project**.
5. Consultez la documentation du benchmark concerné pour comprendre son fonctionnement et connaître ses exigences spécifiques. La référence [benchmarks d’évaluation disponibles](/fr/models/launch/evaluations) inclut les liens pertinents.
## Évaluez votre modèle
Suivez ces étapes pour configurer et lancer un job d’évaluation. Une fois l’opération terminée, vos runs de benchmark sont mis en file d’attente sur une infrastructure gérée par CoreWeave, et leurs résultats s’affichent dans le projet W\&B de destination que vous avez spécifié.
1. Connectez-vous à W\&B, puis cliquez sur **Launch** dans la barre latérale du projet. La page **LLM Evaluation Jobs** s’affiche.
2. Cliquez sur **Évaluer un modèle d’API hébergé** pour configurer l’évaluation.
3. Sélectionnez un projet de destination dans lequel enregistrer les résultats de l’évaluation.
4. Dans la section **Model**, indiquez l’URL de base et le nom du modèle à évaluer, puis sélectionnez la clé API à utiliser pour l’authentification. Fournissez le nom du modèle au format compatible OpenAI défini par l’[AI Security Institute](https://inspect.aisi.org.uk/providers.html#openai-api). Par exemple, indiquez un modèle OpenAI avec la syntaxe suivante, où `[MODEL-NAME]` est le nom du modèle : `openai/[MODEL-NAME]`. Pour obtenir la liste des fournisseurs de modèles hébergés et des modèles disponibles, consultez la [référence des fournisseurs de modèles de l’AI Security Institute](https://inspect.aisi.org.uk/providers.html).
* Pour évaluer un modèle fourni par [Serverless Inference](/fr/inference), définissez l’URL de base sur `https://api.inference.wandb.ai/v1` et indiquez le nom du modèle avec la syntaxe suivante, où `[MODEL-ID]` est l’ID du modèle : `openai-api/wandb/[MODEL-ID]`. Consultez le [catalogue des modèles Inference](/fr/inference/models) pour plus de détails.
* Pour utiliser le fournisseur [OpenRouter](https://inspect.aisi.org.uk/providers.html#openrouter), ajoutez le préfixe `openrouter` au nom du modèle avec la syntaxe suivante, où `[MODEL-NAME]` est le nom du modèle : `openrouter/[MODEL-NAME]`.
* Pour évaluer un modèle personnalisé conforme à OpenAPI, indiquez le nom du modèle avec la syntaxe suivante, où `[MODEL-NAME]` est le nom du modèle : `openai-api/wandb/[MODEL-NAME]`.
5. Cliquez sur **Select evaluations**, puis sélectionnez jusqu’à quatre benchmarks à exécuter.
6. Si vous sélectionnez des benchmarks qui utilisent des modèles OpenAI pour le scoring, le champ **clé API du scorer** s’affiche. Cliquez dessus, puis sélectionnez le secret `OPENAI_API_KEY`. Un administrateur de l’équipe peut créer un secret depuis ce volet latéral en cliquant sur **Create secret**.
7. Si vous sélectionnez des benchmarks qui nécessitent l’accès à des jeux de données à accès restreint dans Hugging Face, un champ **jeton Hugging Face** s’affiche. [Demandez l’accès au jeu de données concerné](https://huggingface.co/docs/hub/en/datasets-gated#access-gated-datasets-as-a-user), puis sélectionnez le secret qui contient le jeton d’accès utilisateur Hugging Face.
8. Facultatif : définissez **Sample limit** sur un entier positif afin de limiter le nombre maximum d’échantillons de benchmark à évaluer. Sinon, tous les échantillons de la tâche sont inclus.
9. Pour créer automatiquement un classement, cliquez sur **Publish results to leaderboard**. Le classement affiche toutes les évaluations côte à côte dans un panneau de workspace, et vous pouvez aussi le partager dans un rapport.
10. Cliquez sur **Launch** pour lancer le job d’évaluation.
11. Cliquez sur l’icône en forme de flèche circulaire en haut de la page pour ouvrir la fenêtre modale des runs récents. Les jobs d’évaluation apparaissent avec vos autres runs récents. Cliquez sur le nom d’un run terminé pour l’ouvrir dans la vue run unique, ou cliquez sur le lien **Leaderboard** pour ouvrir directement le classement. Pour plus de détails, voir [Afficher les résultats](#view-the-results).
Cet exemple de job exécute le benchmark `simpleqa` sur le modèle OpenAI `o4-mini` :
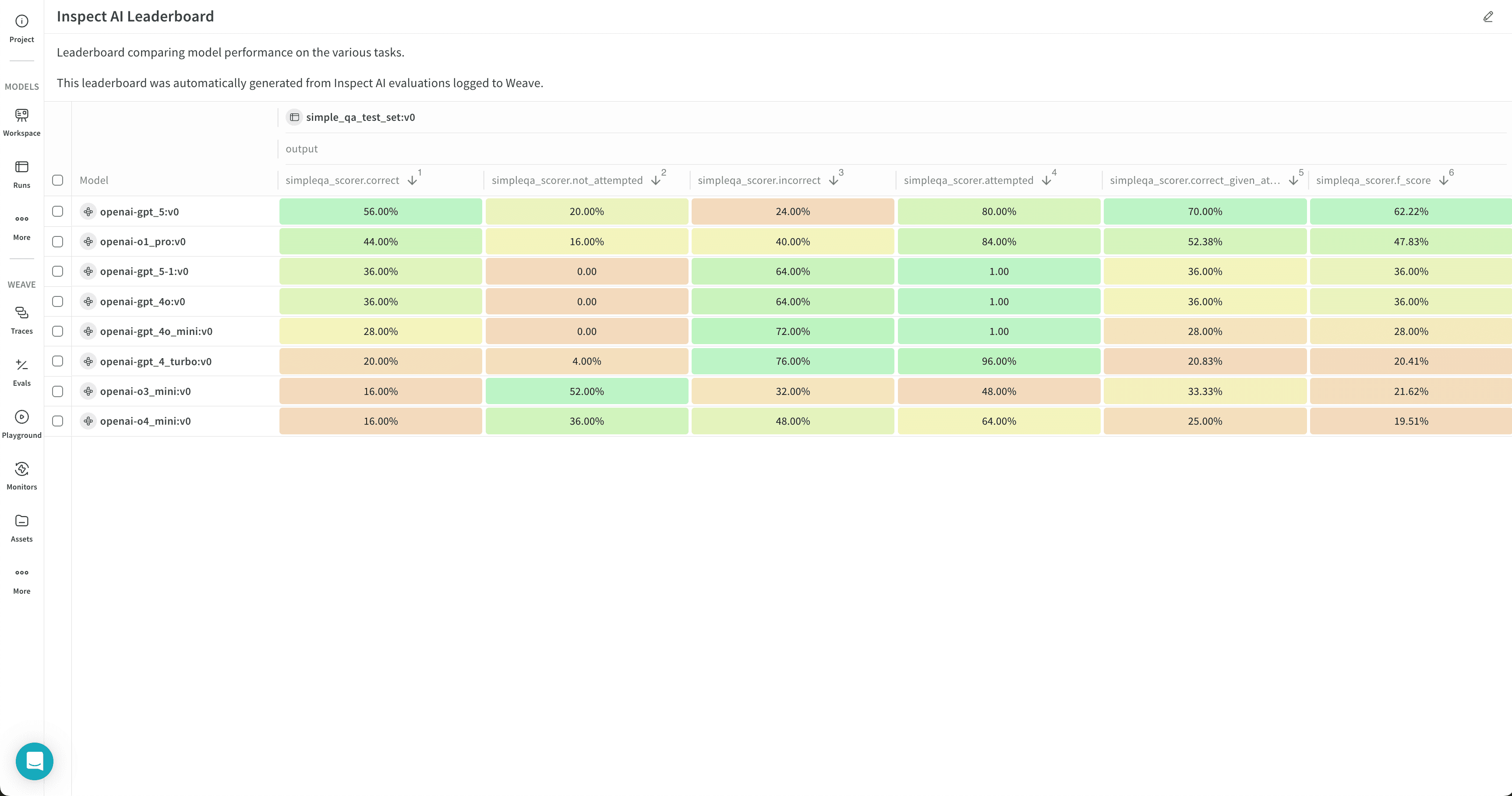
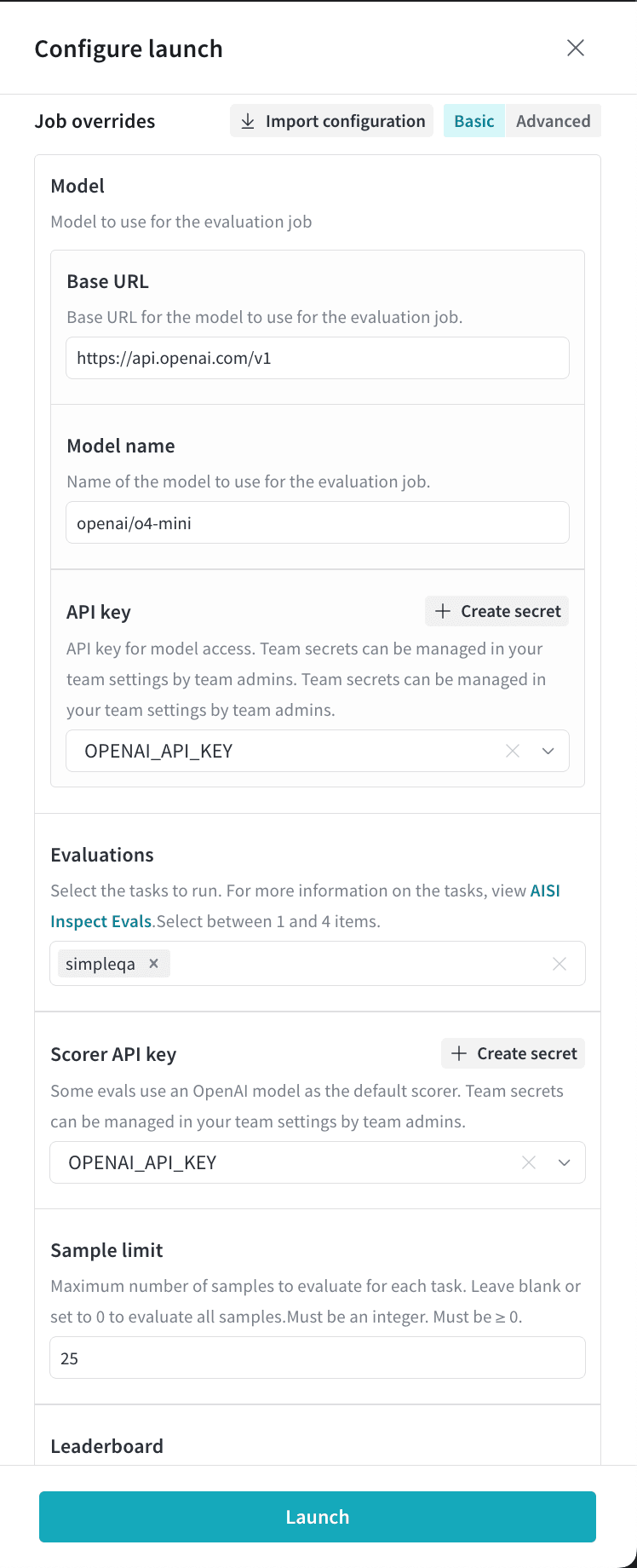 Si vous avez publié les résultats dans un classement, vous pouvez comparer les évaluations côte à côte. Cet exemple de classement visualise les performances de plusieurs modèles OpenAI :
Si vous avez publié les résultats dans un classement, vous pouvez comparer les évaluations côte à côte. Cet exemple de classement visualise les performances de plusieurs modèles OpenAI :
## Consulter les résultats de l'évaluation
Consultez les résultats de votre job d'évaluation dans W\&B Models, dans le Workspace du projet de destination.
1. Cliquez sur l'icône en forme de flèche circulaire en haut de la page pour ouvrir la fenêtre modale des runs récents, où les jobs d'évaluation apparaissent avec les autres Runs du projet. Si le job d'évaluation comporte un leaderboard, cliquez sur **Leaderboard** pour l'ouvrir en plein écran, ou cliquez sur un nom de run pour l'ouvrir dans le projet en vue d'exécution unique.
2. Consultez les traces du job d'évaluation dans la section **Évaluations** d'un Workspace ou dans l'onglet **Traces** du panneau latéral **Weave**.
3. Cliquez sur l'onglet **Aperçu** pour afficher des informations détaillées sur le job d'évaluation, notamment sa configuration et ses métriques récapitulatives.
4. Cliquez sur l'onglet **Logs** pour afficher, rechercher ou télécharger les journaux de débogage du job d'évaluation.
5. Cliquez sur l'onglet **Files** pour parcourir, afficher ou télécharger les fichiers du job d'évaluation, y compris le code, les journaux, la configuration et d'autres fichiers de sortie.
## Personnaliser un leaderboard
Le leaderboard affiche les résultats de tous les jobs d'évaluation envoyés à un projet donné, avec une ligne par benchmark et par job d'évaluation. Les colonnes affichent des détails tels que la trace, les valeurs d'entrée et les valeurs de sortie du job d'évaluation. Pour en savoir plus sur les leaderboards, voir [Leaderboards dans Weave](/fr/weave/guides/core-types/leaderboards).
Pour donner votre avis sur un résultat depuis le leaderboard, cliquez sur l'icône emoji ou sur l'icône de discussion dans la colonne **Feedback**.
* Par défaut, tous les jobs d'évaluation sont affichés. Filtrez ou recherchez un job d'évaluation à l'aide du sélecteur de run à gauche.
* Par défaut, les jobs d'évaluation ne sont pas regroupés. Pour regrouper par une ou plusieurs colonnes, cliquez sur l'icône **Group**. Vous pouvez afficher ou masquer un groupe, ou développer un groupe pour voir ses Runs.
* Par défaut, toutes les opérations sont affichées. Pour n'afficher qu'une seule opération, cliquez sur **All ops** et sélectionnez une opération.
* Pour trier par une colonne, cliquez sur l'en-tête de la colonne. Pour personnaliser l'affichage des colonnes, cliquez sur **Colonne**.
* Par défaut, les en-têtes sont organisés sur un seul niveau. Vous pouvez augmenter la profondeur des en-têtes pour regrouper les en-têtes associés.
* Sélectionnez ou désélectionnez des colonnes individuelles pour les afficher ou les masquer, ou affichez ou masquez toutes les colonnes en un clic.
* Épinglez des colonnes pour les afficher avant les colonnes non épinglées.
## Exporter un leaderboard
Pour exporter un leaderboard :
1. Cliquez sur l’icône de téléchargement, située à côté du bouton **Colonnes**.
2. Pour réduire la taille de l’export, W\&B exporte uniquement les racines de trace par défaut. Pour exporter des traces complètes, désactivez **Racines de trace uniquement**.
3. Pour réduire la taille de l’export, W\&B n’exporte pas le feedback ni les coûts par défaut. Pour les inclure dans l’export, activez **Feedback** ou **Coûts**.
4. Par défaut, l’export est au format JSONL. Pour personnaliser le format, cliquez sur **Exporter vers un fichier** et sélectionnez un format.
5. Pour exporter le leaderboard depuis votre navigateur, cliquez sur **Exporter**.
6. Pour exporter le leaderboard par code, sélectionnez **Python** ou **cURL**, puis cliquez sur **Copier** et exécutez le script ou la commande.
## Relancer un job d’évaluation
Une fois un job d’évaluation terminé, vous souhaiterez peut-être le relancer avec les mêmes paramètres ou des paramètres modifiés, ou réutiliser sa configuration comme point de départ pour un nouveau job. Selon votre situation, il existe plusieurs façons de relancer un job d’évaluation ou d’en afficher la configuration.
* Pour relancer le dernier job d’évaluation, suivez les étapes de [Évaluer votre modèle](#evaluate-your-model). Sélectionnez le projet de destination ; les détails de l’artifact de modèle et les benchmarks sélectionnés la dernière fois sont alors renseignés automatiquement. Au besoin, apportez des ajustements, puis lancez le job d’évaluation.
* Pour relancer un job d’évaluation depuis l’onglet **Runs** du projet ou le sélecteur de run, survolez le nom du run et cliquez sur l’icône **lecture**. Le volet de configuration du job s’affiche avec les paramètres préremplis. Au besoin, ajustez les paramètres, puis cliquez sur **Launch**.
* Pour relancer un job d’évaluation depuis un autre projet, importez sa configuration :
1. Suivez les étapes de [Évaluer votre modèle](#evaluate-your-model). Après avoir sélectionné le projet de destination, cliquez sur **Importer la configuration**.
2. Sélectionnez le projet qui contient le job d’évaluation à importer, puis sélectionnez le run correspondant. Le volet de configuration du job s’affiche avec les paramètres préremplis.
3. Au besoin, ajustez la configuration.
4. Cliquez sur **Launch**.
## Exporter la configuration d’un job d’évaluation
Pour enregistrer une copie locale du `config.yaml` d’un job d’évaluation afin de la réutiliser ou de vous y référer, exportez la configuration depuis l’onglet **Files** du run :
1. Ouvrez le run dans la vue de run unique.
2. Dans le run, sélectionnez **Files**.
3. À côté de `config.yaml`, sélectionnez le bouton de téléchargement.