> ## Documentation Index
> Fetch the complete documentation index at: https://docs.wandb.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Évaluer des modèles avec W&B Weave et W&B Tables
> Découvrez comment évaluer des modèles d’apprentissage automatique à l’aide de W&B Weave et de Tables.
## Évaluer des modèles avec Weave
[W\&B Weave](/fr/weave) est une boîte à outils spécialement conçue pour évaluer les LLM et les applications d’IA générative. Elle offre des fonctionnalités d’évaluation complètes, notamment des évaluateurs, des juges et un Tracing détaillé, pour vous aider à comprendre et à améliorer les performances du modèle. Weave s’intègre à W\&B Models, ce qui vous permet d’évaluer les modèles stockés dans votre registre de modèles.
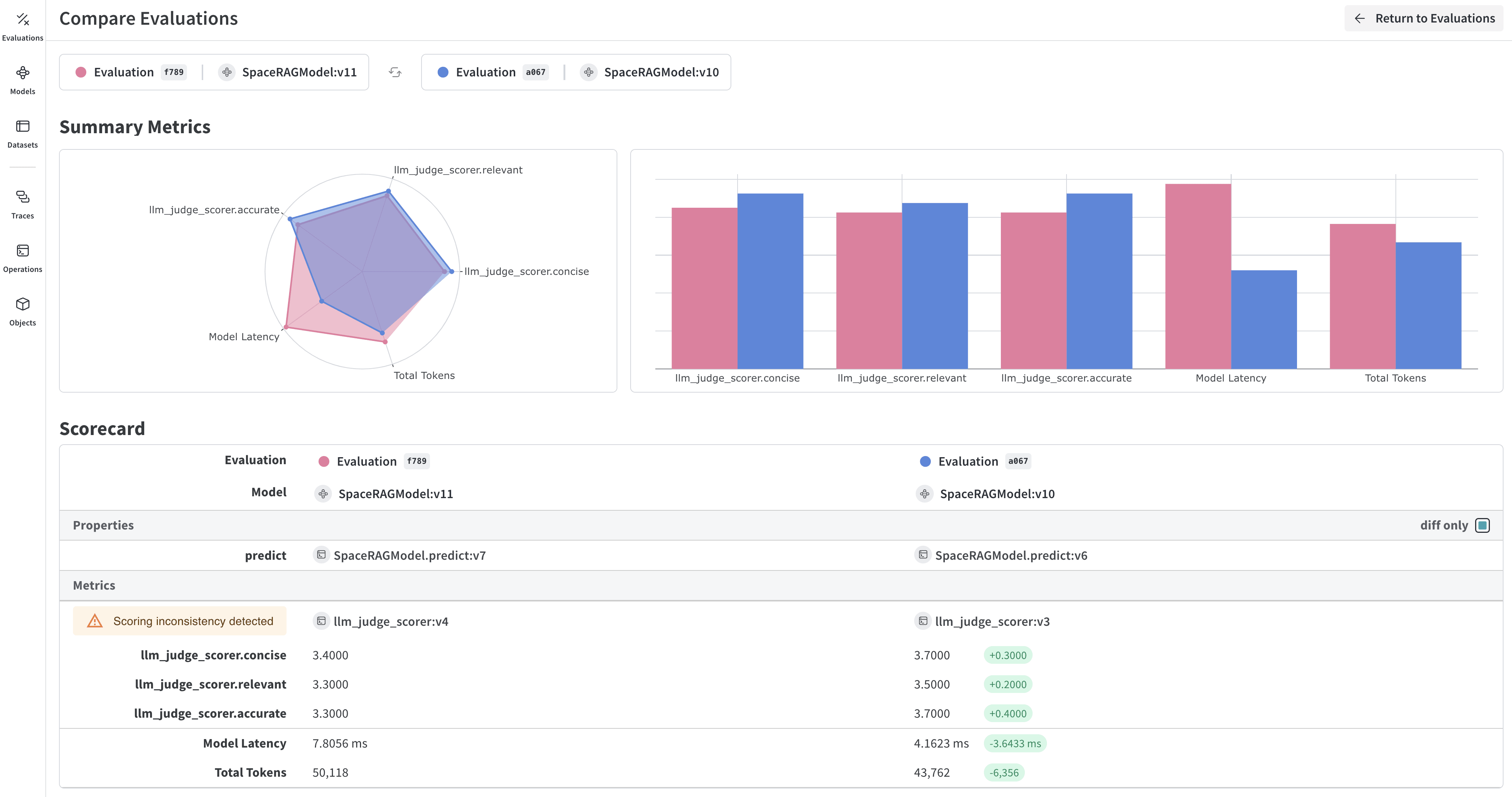
### Fonctionnalités clés pour l’évaluation des modèles
* **Évaluateurs et juges** : Métriques d’évaluation prédéfinies et personnalisées pour l’exactitude, la pertinence, la cohérence, etc.
* **Jeux de données d’évaluation** : Ensembles de test structurés avec des valeurs de référence pour une évaluation systématique
* **Gestion des versions des modèles** : Suivez et comparez différentes versions de vos modèles
* **Tracing détaillé** : Déboguez le comportement du modèle à l’aide de traces d’entrée/sortie complètes
* **Suivi des coûts** : Surveillez les coûts d’API et l’utilisation des tokens sur l’ensemble des évaluations
### Premiers pas : évaluer un modèle à partir du W\&B Registry
Téléchargez un modèle depuis le registre W\&B Models et évaluez-le à l’aide de Weave :
```python theme={null}
import weave
import wandb
from typing import Any
# Initialiser Weave
weave.init("your-entity/your-project")
# Définir un ChatModel qui se charge depuis W&B Registry
class ChatModel(weave.Model):
model_name: str
def model_post_init(self, __context):
# Télécharger le modèle depuis W&B Models Registry
with wandb.init(project="your-project", job_type="model_download") as run:
artifact = run.use_artifact(self.model_name)
self.model_path = artifact.download()
# Initialiser votre modèle ici
@weave.op()
async def predict(self, query: str) -> str:
# Logique d'inférence de votre modèle
return self.model.generate(query)
# Créer le jeu de données d'évaluation
dataset = weave.Dataset(name="eval_dataset", rows=[
{"input": "What is the capital of France?", "expected": "Paris"},
{"input": "What is 2+2?", "expected": "4"},
])
# Définir les évaluateurs
@weave.op()
def exact_match_scorer(expected: str, output: str) -> dict:
return {"correct": expected.lower() == output.lower()}
# Lancer l'évaluation
model = ChatModel(model_name="wandb-entity/registry-name/model:version")
evaluation = weave.Evaluation(
dataset=dataset,
scorers=[exact_match_scorer]
)
results = await evaluation.evaluate(model)
```
### Intégrer les évaluations Weave à W\&B Models
La [démo d’intégration Models and Weave](/fr/weave/cookbooks/Models_and_Weave_Integration_Demo) présente le flux de travail complet pour :
1. **Charger des modèles depuis le registre** : téléchargez des modèles affinés stockés dans le registre de W\&B Models
2. **Créer des pipelines d’évaluation** : créez des évaluations complètes avec des évaluateurs personnalisés
3. **Consigner les résultats dans W\&B** : associez les métriques d’évaluation aux runs de vos modèles
4. **Versionner les modèles évalués** : enregistrez les modèles améliorés dans le registre
Consignez les résultats d’évaluation à la fois dans Weave et W\&B Models :
```python theme={null}
# Lancer l'évaluation avec le suivi W&B
with weave.attributes({"wandb-run-id": wandb.run.id}):
summary, call = await evaluation.evaluate.call(evaluation, model)
# Consigner des métriques dans W&B Models
wandb.run.log(summary)
wandb.run.config.update({
"weave_eval_url": f"https://wandb.ai/{entity}/{project}/r/call/{call.id}"
})
```
### Fonctionnalités avancées de Weave
#### Évaluateurs et juges personnalisés
Créez des métriques d’évaluation sophistiquées adaptées à votre cas d’utilisation :
```python theme={null}
@weave.op()
def llm_judge_scorer(expected: str, output: str, judge_model) -> dict:
prompt = f"Is this answer correct? Expected: {expected}, Got: {output}"
judgment = await judge_model.predict(prompt)
return {"judge_score": judgment}
```
#### Évaluations par lot
Évaluez plusieurs versions de modèle ou plusieurs configurations :
```python theme={null}
models = [
ChatModel(model_name="model:v1"),
ChatModel(model_name="model:v2"),
]
for model in models:
results = await evaluation.evaluate(model)
print(f"{model.model_name}: {results}")
```
### Étapes suivantes
* [Tutoriel complet sur l’évaluation avec Weave](/fr/weave/tutorial-eval/)
* [Exemple d’intégration entre Models et Weave](/fr/weave/cookbooks/Models_and_Weave_Integration_Demo)
## Évaluer des modèles avec W\&B Tables
Utilisez W\&B Tables pour :
* **Comparer les prédictions des modèles** : affichez côte à côte les performances de différents modèles sur le même jeu de test
* **Suivre l’évolution des prédictions** : observez comment les prédictions changent au fil des époques d’entraînement ou des versions du modèle
* **Analyser les erreurs** : filtrez et lancez des requêtes pour trouver les exemples fréquemment mal classés et les schémas d’erreur
* **Visualiser des médias enrichis** : affichez des images, de l’Audio, du texte et d’autres types de médias à côté des prédictions et des métriques
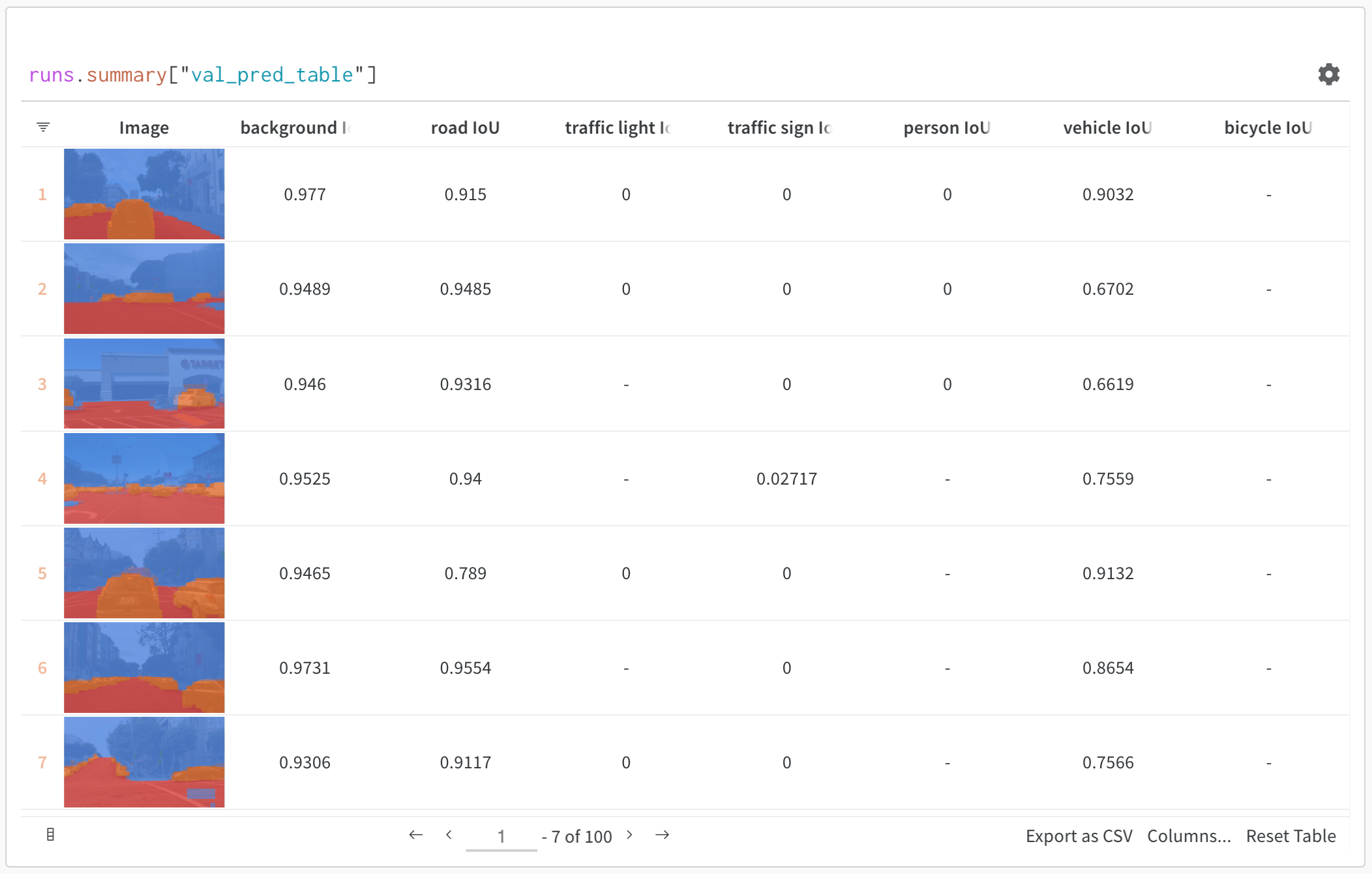
### Exemple de base : journaliser les résultats d’évaluation
```python theme={null}
import wandb
# Initialiser un run
run = wandb.init(project="model-evaluation")
# Créer un tableau avec les résultats d'évaluation
columns = ["id", "input", "ground_truth", "prediction", "confidence", "correct"]
eval_table = wandb.Table(columns=columns)
# Ajouter les données d'évaluation
for idx, (input_data, label) in enumerate(test_dataset):
prediction = model(input_data)
confidence = prediction.max()
predicted_class = prediction.argmax()
eval_table.add_data(
idx,
wandb.Image(input_data), # Enregistrer des images ou d'autres médias
label,
predicted_class,
confidence,
label == predicted_class
)
# Enregistrer le tableau
run.log({"evaluation_results": eval_table})
```
### Flux de travail avancés avec les tableaux
#### Comparer plusieurs modèles
Enregistrez les tableaux d’Évaluation de différents modèles avec la même clé afin de les comparer directement :
```python theme={null}
# Évaluation du modèle A
with wandb.init(project="model-comparison", name="model_a") as run:
eval_table_a = create_eval_table(model_a, test_data)
run.log({"test_predictions": eval_table_a})
# Évaluation du modèle B
with wandb.init(project="model-comparison", name="model_b") as run:
eval_table_b = create_eval_table(model_b, test_data)
run.log({"test_predictions": eval_table_b})
```
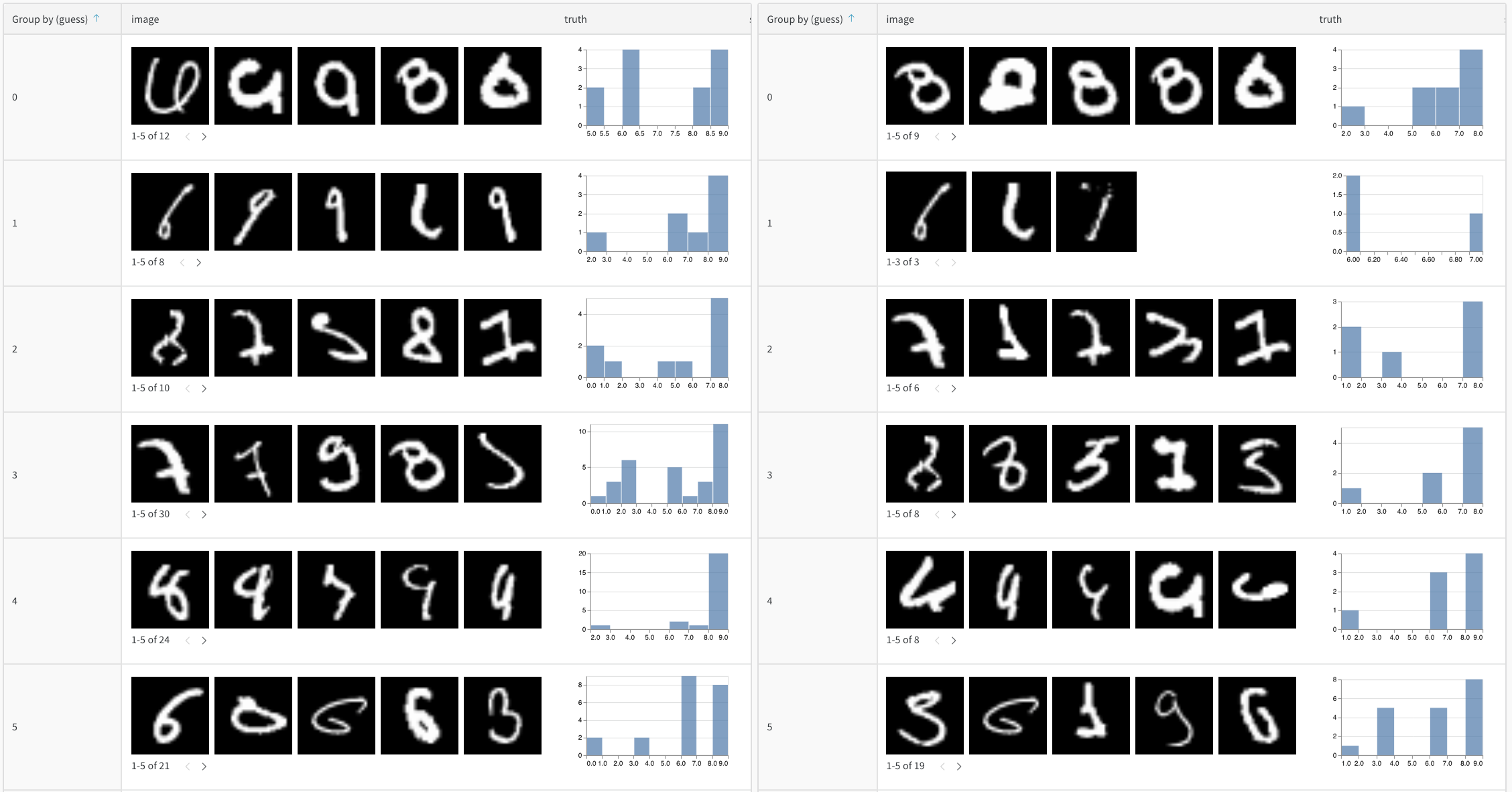
#### Suivre les prédictions au fil du temps
Enregistrez des tableaux dans le journal à différentes époques d'entraînement pour visualiser les améliorations :
```python theme={null}
for epoch in range(num_epochs):
train_model(model, train_data)
# Évaluer et enregistrer les prédictions pour cette époque
eval_table = wandb.Table(columns=["image", "truth", "prediction"])
for image, label in test_subset:
pred = model(image)
eval_table.add_data(wandb.Image(image), label, pred.argmax())
wandb.log({f"predictions_epoch_{epoch}": eval_table})
```
### Analyse interactive dans l’interface W\&B
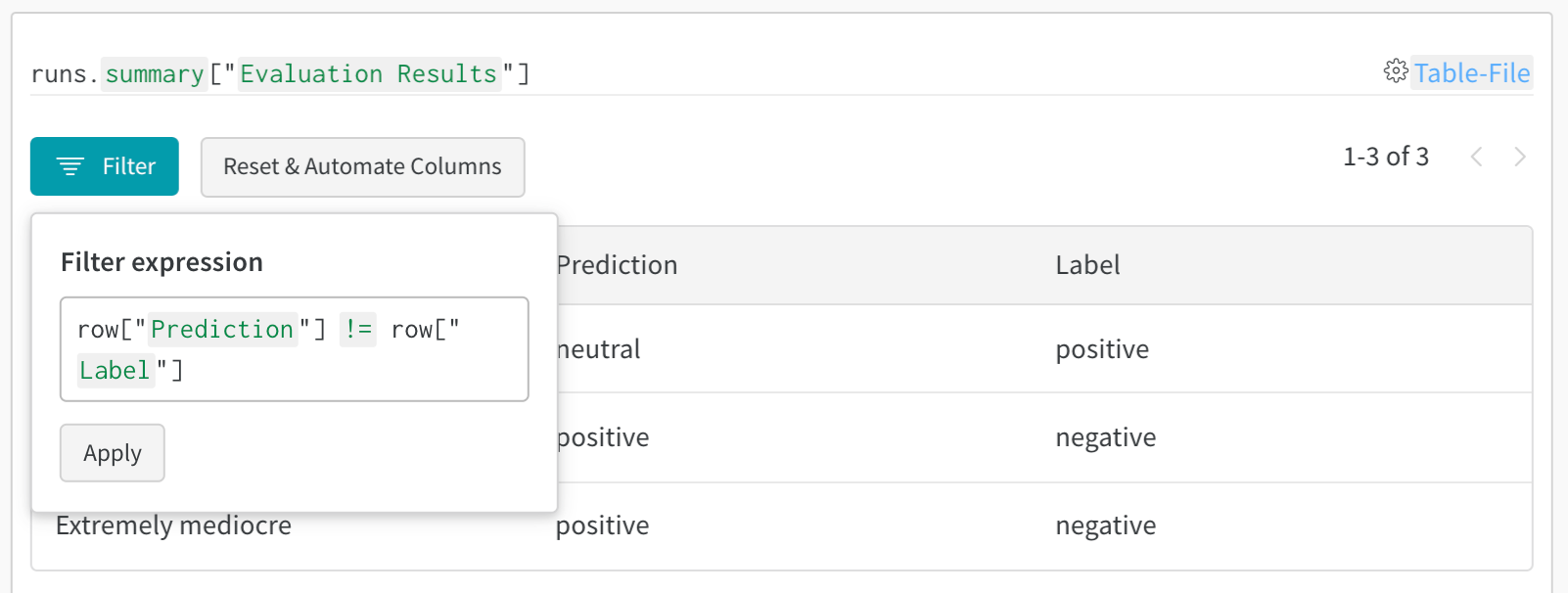
Une fois les résultats enregistrés, vous pouvez :
1. **Filtrer les résultats** : cliquez sur les en-têtes de colonne pour filtrer selon la précision des prédictions, les seuils de confiance ou des classes spécifiques
2. **Comparer des tables** : sélectionnez plusieurs versions de table pour afficher des comparaisons côte à côte
3. **Interroger les données** : utilisez la barre de requête pour trouver des motifs précis (par exemple, `"correct" = false AND "confidence" > 0.8`)
4. **Grouper et agréger** : regroupez par classe prédite pour voir les métriques de précision par classe
### Exemple : analyse des erreurs avec des Tables enrichies
```python theme={null}
# Créer un tableau mutable pour ajouter des colonnes d'analyse
eval_table = wandb.Table(
columns=["id", "image", "label", "prediction"],
log_mode="MUTABLE" # Permet d'ajouter des colonnes ultérieurement
)
# Prédictions initiales
for idx, (img, label) in enumerate(test_data):
pred = model(img)
eval_table.add_data(idx, wandb.Image(img), label, pred.argmax())
run.log({"eval_analysis": eval_table})
# Ajouter des scores de confiance pour l'analyse des erreurs
confidences = [model(img).max() for img, _ in test_data]
eval_table.add_column("confidence", confidences)
# Ajouter les types d'erreurs
error_types = classify_errors(eval_table.get_column("label"),
eval_table.get_column("prediction"))
eval_table.add_column("error_type", error_types)
run.log({"eval_analysis": eval_table})
```