> ## Documentation Index
> Fetch the complete documentation index at: https://docs.wandb.ai/llms.txt
> Use this file to discover all available pages before exploring further.
> Utilisez W&B pour consigner des expériences d'entraînement distribué avec plusieurs GPU.
# Consigner des expériences d'entraînement distribué
Pendant une expérience d'entraînement distribué, vous entraînez un modèle à l'aide de plusieurs machines ou clients en parallèle. W\&B peut vous aider à suivre les expériences d'entraînement distribué. Selon votre cas d’utilisation, suivez les expériences d'entraînement distribué à l’aide de l’une des approches suivantes :
* **Suivre un seul processus** : suivez un processus de rang 0 (également appelé « leader » ou « coordinateur ») avec W\&B. Il s'agit d'une solution courante pour consigner des expériences d'entraînement distribué avec la classe [PyTorch Distributed Data Parallel](https://pytorch.org/docs/stable/generated/torch.nn.parallel.DistributedDataParallel.html#torch.nn.parallel.DistributedDataParallel) (DDP).
* **Suivre plusieurs processus** : pour plusieurs processus, vous pouvez soit :
* Suivre chaque processus séparément en utilisant un run par processus. Vous pouvez aussi, si vous le souhaitez, les regrouper dans W\&B App UI.
* Suivre tous les processus dans un seul run.
**Connexions simultanées**
Chaque connexion simultanée consomme des ressources de calcul, de mémoire et de réseau. Même les connexions client vides qui ne consignent pas régulièrement de métriques envoient des mises à jour des métriques système, ce qui ralentit le chargement des graphiques.
W\&B recommande de limiter le nombre maximal de connexions client simultanées en fonction de votre charge de travail et de surveiller l'utilisation des ressources au fil du temps. W\&B a testé une limite stricte de 300 connexions client simultanées dans **Cloud dédié**.
Dans les organisations **Cloud mutualisé**, les connexions client pour l'entraînement distribué sont soumises aux mêmes [limites de débit](/fr/models/track/limits#rate-limits) que les runs d'entraînement classiques. Les utilisateurs des plans [Teams et Enterprise](https://wandb.ai/site/pricing) bénéficient de limites de débit plus élevées que ceux du plan Free.
## Suivre un seul processus
Cette section explique comment suivre les valeurs et les métriques disponibles pour votre processus de rang 0. Utilisez cette approche pour ne suivre que les métriques disponibles depuis un seul processus. Les métriques typiques incluent l’utilisation du GPU/CPU, le comportement sur un ensemble de validation partagé, les gradients et les paramètres, ainsi que les valeurs de perte sur des exemples de données représentatifs.
Dans le processus de rang 0, initialisez un run W\&B avec [`wandb.init()`](/fr/models/ref/python/functions/init) et enregistrez les expériences ([`wandb.Run.log()`](/fr/models/ref/python/experiments/run/#method-runlog)) dans ce run.
L’[exemple de script Python (`log-ddp.py`)](https://github.com/wandb/examples/blob/master/examples/pytorch/pytorch-ddp/log-ddp.py) suivant montre une façon de suivre des métriques sur deux GPU d’une même machine à l’aide de PyTorch DDP. [PyTorch DDP](https://pytorch.org/tutorials/intermediate/ddp_tutorial.html) (`DistributedDataParallel` dans `torch.nn`) est une bibliothèque populaire pour l’entraînement distribué. Les principes de base s’appliquent à toute configuration d’entraînement distribué, mais l’implémentation peut varier.
Le script Python :
1. Démarre plusieurs processus avec `torch.distributed.launch`.
2. Vérifie le rang avec l’argument de ligne de commande `--local_rank`.
3. Si le rang est défini sur 0, configure conditionnellement la journalisation avec `wandb` dans la fonction [`train()`](https://github.com/wandb/examples/blob/master/examples/pytorch/pytorch-ddp/log-ddp.py#L24).
```python theme={null}
if __name__ == "__main__":
# Obtenir les arguments
args = parse_args()
if args.local_rank == 0: # uniquement sur le processus principal
# Initialiser le run wandb
run = wandb.init(
entity=args.entity,
project=args.project,
)
# Entraîner le modèle avec DDP
train(args, run)
else:
train(args)
```
Explorez un [exemple de tableau de bord montrant les métriques relevées à partir d’un seul processus](https://wandb.ai/ayush-thakur/DDP/runs/1s56u3hc/system).
Le tableau de bord affiche les métriques système des deux GPU, comme la température et l’utilisation.
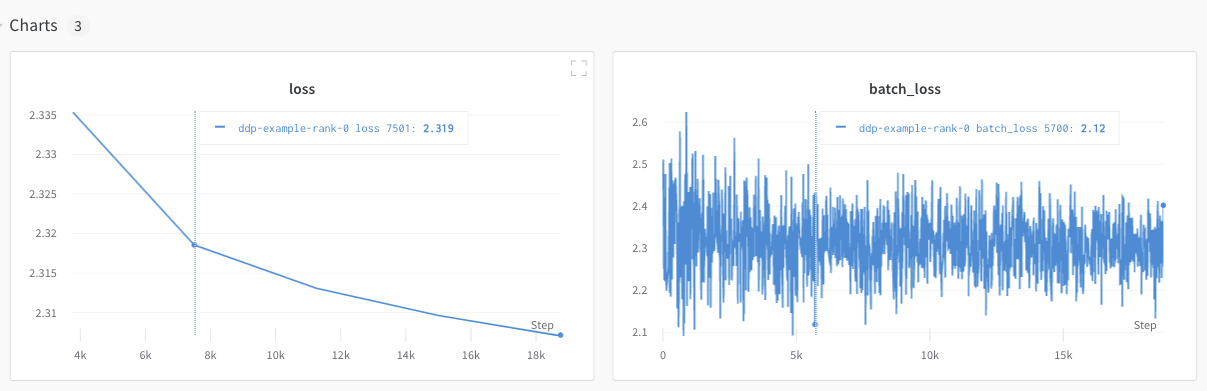
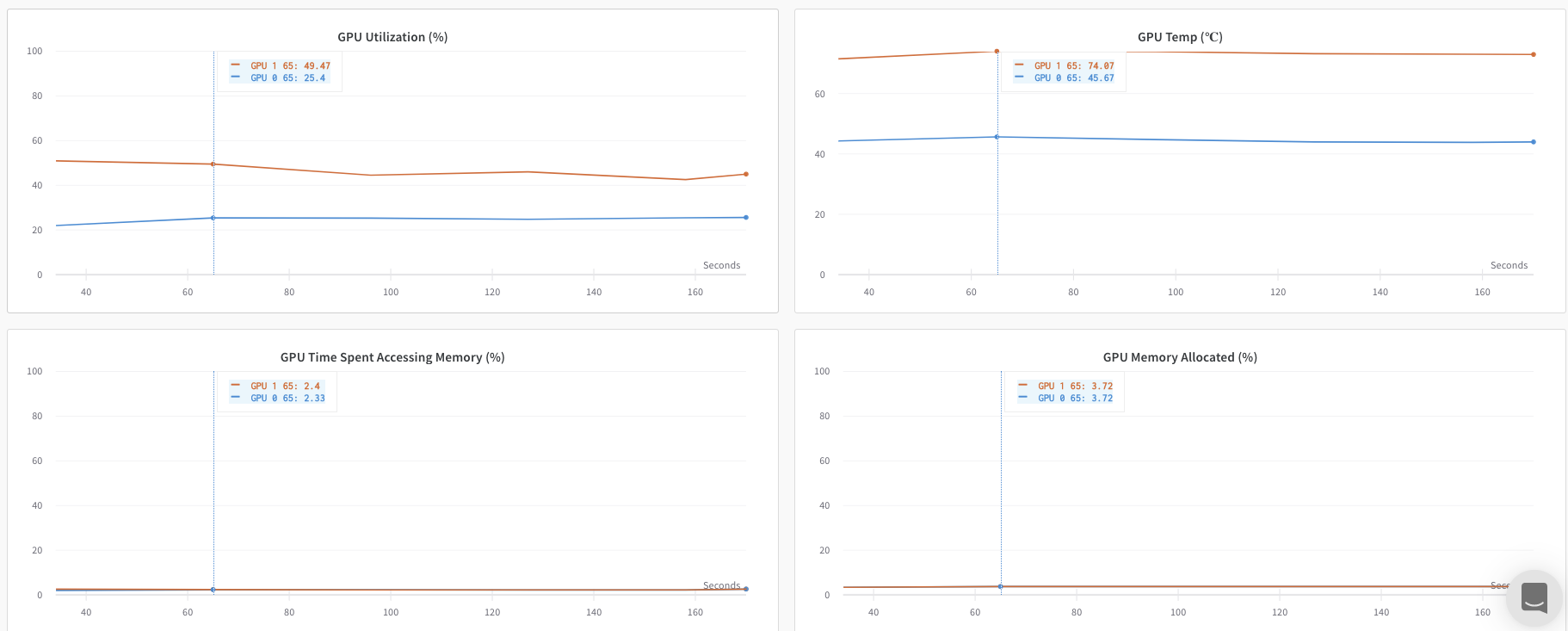 Cependant, les valeurs de perte en fonction de l’époque et de la taille du lot n’ont été enregistrées que depuis un seul GPU.
Cependant, les valeurs de perte en fonction de l’époque et de la taille du lot n’ont été enregistrées que depuis un seul GPU.
## Suivre plusieurs processus
Suivez plusieurs processus avec W\&B à l’aide de l’une des approches suivantes :
* [Suivre chaque processus séparément](/fr/models/track/log/distributed-training/#track-each-process-separately) en créant un run pour chaque processus.
* [Suivre tous les processus dans un seul run](/fr/models/track/log/distributed-training/#track-all-processes-to-a-single-run).
### Suivre chaque processus séparément
Cette section explique comment suivre chaque processus séparément en créant un run pour chacun. Dans chaque run, vous consignez des métriques, des Artifacts, etc., dans le run correspondant. Appelez `wandb.Run.finish()` à la fin de l’entraînement pour indiquer que le run est terminé, afin que tous les processus se ferment correctement.
Il peut être difficile de suivre les runs dans plusieurs expériences. Pour y remédier, fournissez une valeur au paramètre `group` lorsque vous initialisez W\&B (`wandb.init(group='group-name')`) afin d’identifier à quelle expérience appartient chaque run. Pour plus d’informations sur le suivi des Runs W\&B d’entraînement et d’évaluation dans les expériences, voir [Group Runs](/fr/models/runs/grouping/).
**Utilisez cette approche si vous souhaitez suivre les métriques de chaque processus individuellement**. Les exemples typiques incluent les données et les prédictions sur chaque nœud (pour déboguer la distribution des données), ainsi que les métriques sur
des lots individuels en dehors du nœud principal. Cette approche n’est pas nécessaire pour obtenir les métriques système de tous les nœuds ni les statistiques récapitulatives disponibles sur le nœud principal.
L’extrait de code Python suivant montre comment définir le paramètre `group` lorsque vous initialisez W\&B :
```python theme={null}
if __name__ == "__main__":
# Obtenir les arguments
args = parse_args()
# Initialiser le run
run = wandb.init(
entity=args.entity,
project=args.project,
group="DDP", # tous les runs de l'expérience dans un seul groupe
)
# Entraîner le modèle avec DDP
train(args, run)
run.finish() # marquer le run comme terminé
```
Explorez W\&B App UI pour voir un [exemple de tableau de bord](https://wandb.ai/ayush-thakur/DDP?workspace=user-noahluna) des métriques suivies sur plusieurs processus. Notez que deux W\&B Runs sont regroupés dans la barre latérale gauche. Cliquez sur un groupe pour afficher la page du groupe dédiée à l’expérience. Cette page affiche séparément les métriques de chaque processus.
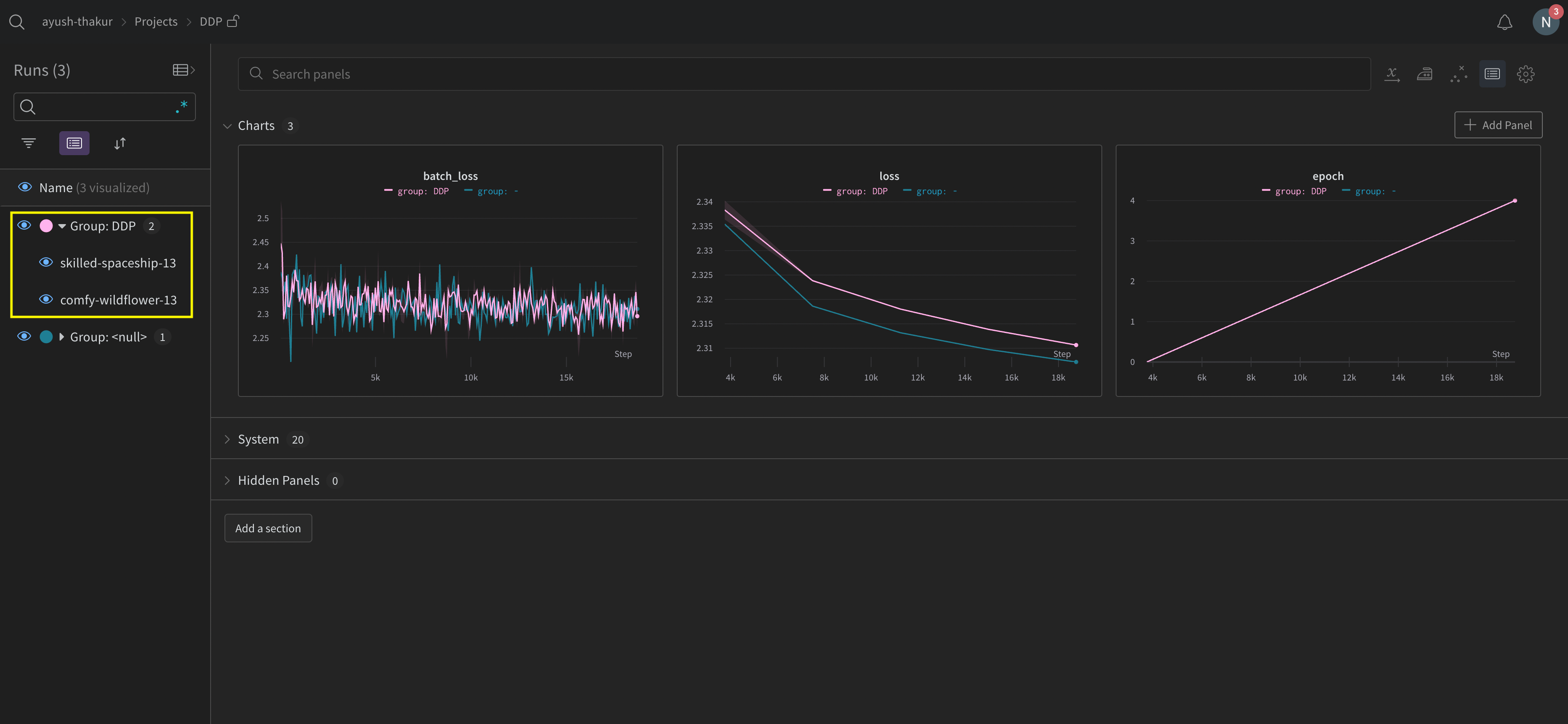 L’image précédente montre le tableau de bord de W\&B App UI. Dans la barre latérale, on voit deux expériences. L’une est intitulée 'null' et la seconde (encadrée en jaune) s’appelle 'DPP'. Si vous développez le groupe (sélectionnez le menu déroulant Group), vous verrez les W\&B Runs associés à cette expérience.
L’image précédente montre le tableau de bord de W\&B App UI. Dans la barre latérale, on voit deux expériences. L’une est intitulée 'null' et la seconde (encadrée en jaune) s’appelle 'DPP'. Si vous développez le groupe (sélectionnez le menu déroulant Group), vous verrez les W\&B Runs associés à cette expérience.
### Organiser les runs distribués
Définissez le paramètre `job_type` lors de l’initialisation de W\&B (`wandb.init(job_type='type-name')`) afin de classer vos nœuds selon leur rôle. Par exemple, vous pouvez avoir un nœud coordinateur principal et plusieurs nœuds workers chargés du reporting. Vous pouvez définir `job_type` sur `main` pour le nœud coordinateur principal et sur `worker` pour les nœuds workers chargés du reporting :
```python theme={null}
# Nœud coordinateur principal
with wandb.init(project="", job_type="main", group="experiment_1") as run:
# Code d'entraînement
# Nœuds workers chargés du reporting
with wandb.init(project="", job_type="worker", group="experiment_1") as run:
# Code d'entraînement
```
Une fois que vous avez défini le `job_type` pour vos nœuds, vous pouvez créer des [vues enregistrées](/fr/models/track/workspaces/#create-a-new-saved-workspace-view) dans votre Workspace pour organiser vos runs. Cliquez sur le menu **action ()** en haut à droite, puis sur **Enregistrer comme nouvelle vue**.
Par exemple, vous pourriez créer les vues enregistrées suivantes :
* **Vue par défaut** : Masquer les nœuds worker pour réduire le bruit
* Cliquez sur **Filtre**, puis définissez **Job Type** sur `worker`.
* Affiche uniquement vos nœuds de reporting
* **Vue de débogage** : Se concentrer sur les nœuds worker pour le dépannage
* Cliquez sur **Filtre**, puis définissez **Job Type** sur `==` `worker` et **State** sur `IN` `crashed`.
* Affiche uniquement les nœuds worker qui ont planté ou sont dans des états d’erreur
* **Vue de tous les nœuds** : Tout voir en un seul endroit
* Aucun filtre
* Utile pour une surveillance complète
Pour ouvrir une vue enregistrée, cliquez sur **Workspaces** dans la barre latérale du projet, puis cliquez sur le menu. Les Workspaces apparaissent en haut de la liste et les vues enregistrées en bas.
### Suivre tous les processus dans un seul run
Les paramètres préfixés par `x_` (comme `x_label`) sont en préversion publique. Créez une [issue GitHub dans le dépôt W\&B](https://github.com/wandb/wandb) pour nous faire part de vos retours.
**Prérequis**
Pour suivre plusieurs processus dans un seul run, vous devez disposer de :
* la version `v0.19.9` ou ultérieure du W\&B Python SDK.
* de W\&B Server v0.68 ou ultérieure.
Dans cette approche, vous utilisez un nœud principal et un ou plusieurs nœuds workers. Sur le nœud principal, vous initialisez un run W\&B. Pour chaque nœud worker, initialisez un run en utilisant l’ID du run du nœud principal. Pendant l’entraînement, chaque nœud worker consigne ses données dans le même ID de run que le nœud principal. W\&B agrège les métriques de tous les nœuds et les affiche dans la W\&B App UI.
Sur le nœud principal, initialisez un run W\&B avec [`wandb.init()`](/fr/models/ref/python/functions/init). Passez un objet `wandb.Settings` au paramètre `settings` (`wandb.init(settings=wandb.Settings()`) avec les éléments suivants :
1. Le paramètre `mode` défini sur `"shared"` pour activer le mode partagé.
2. Un libellé unique pour [`x_label`](https://github.com/wandb/wandb/blob/main/wandb/sdk/wandb_settings.py#L638). La valeur spécifiée pour `x_label` permet d’identifier de quel nœud proviennent les données dans les journaux et les métriques système de la W\&B App UI. S’il n’est pas spécifié, W\&B crée un libellé à partir du nom d’hôte et d’un hachage aléatoire.
3. Définissez le paramètre [`x_primary`](https://github.com/wandb/wandb/blob/main/wandb/sdk/wandb_settings.py#L660) sur `True` pour indiquer qu’il s’agit du nœud principal.
4. Vous pouvez éventuellement fournir une liste d’index GPU (\[0,1,2]) à `x_stats_gpu_device_ids` pour préciser les GPU dont W\&B doit suivre les métriques. Si vous ne fournissez pas de liste, W\&B suit les métriques de tous les GPU de la machine.
Notez l’ID du run du nœud principal. Chaque nœud worker en a besoin.
`x_primary=True` permet de distinguer un nœud principal des nœuds workers. Les nœuds principaux sont les seuls à téléverser les fichiers partagés entre les nœuds, comme les fichiers de configuration, la télémétrie, etc. Les nœuds workers ne téléversent pas ces fichiers.
Pour chaque nœud worker, initialisez un run W\&B avec [`wandb.init()`](/fr/models/ref/python/functions/init) et fournissez les éléments suivants :
1. Un objet `wandb.Settings` au paramètre `settings` (`wandb.init(settings=wandb.Settings()`) avec :
* Le paramètre `mode` défini sur `"shared"` pour activer le mode partagé.
* Un libellé unique pour `x_label`. La valeur spécifiée pour `x_label` permet d’identifier de quel nœud proviennent les données dans les journaux et les métriques système de la W\&B App UI. S’il n’est pas spécifié, W\&B crée un libellé à partir du nom d’hôte et d’un hachage aléatoire.
* Définissez le paramètre `x_primary` sur `False` pour indiquer qu’il s’agit d’un nœud worker.
2. Passez l’ID du run du nœud principal au paramètre `id`.
3. Définissez éventuellement [`x_update_finish_state`](https://github.com/wandb/wandb/blob/main/wandb/sdk/wandb_settings.py#L772) sur `False`. Cela empêche les nœuds non principaux de mettre prématurément à jour l’[état du run](/fr/models/runs/run-states#run-states) vers `finished`, afin de garantir que l’état du run reste cohérent et géré par le nœud principal.
* Utilisez la même entité et le même projet pour tous les nœuds. Cela permet de s’assurer que le bon ID de run est trouvé.
* Vous pouvez envisager de définir une variable d’environnement sur chaque nœud worker pour définir l’ID du run du nœud principal.
L’exemple de code suivant illustre les exigences générales pour suivre plusieurs processus dans un seul run :
```python theme={null}
import wandb
entity = ""
project = ""
# Initialiser un run dans le nœud principal
run = wandb.init(
entity=entity,
project=project,
settings=wandb.Settings(
x_label="rank_0",
mode="shared",
x_primary=True,
x_stats_gpu_device_ids=[0, 1], # (Facultatif) Suivre uniquement les métriques pour les GPU 0 et 1
)
)
# Noter l'ID du run du nœud principal.
# Chaque nœud worker a besoin de cet ID de run.
run_id = run.id
# Initialiser un run dans un nœud worker en utilisant l'ID du run du nœud principal
run = wandb.init(
entity=entity, # Utiliser la même entité que le nœud principal
project=project, # Utiliser le même project que le nœud principal
settings=wandb.Settings(x_label="rank_1", mode="shared", x_primary=False),
id=run_id,
)
# Initialiser un run dans un nœud worker en utilisant l'ID du run du nœud principal
run = wandb.init(
entity=entity, # Utiliser la même entité que le nœud principal
project=project, # Utiliser le même project que le nœud principal
settings=wandb.Settings(x_label="rank_2", mode="shared", x_primary=False),
id=run_id,
)
```
Dans un cas réel, chaque nœud worker peut se trouver sur une machine distincte.
Voir le report [Distributed Training with Shared Mode](https://wandb.ai/dimaduev/simple-cnn-ddp/reports/Distributed-Training-with-Shared-Mode--VmlldzoxMTI0NTE1NA) pour un exemple de bout en bout montrant comment entraîner
un modèle sur un cluster Kubernetes multi-nœuds et multi-GPU dans GKE.
Affichez les journaux de console des processus multi-nœuds dans le projet dans lequel le run journalise :
1. Accédez au projet qui contient le run.
2. Cliquez sur l’onglet **Runs** dans la barre latérale du projet.
3. Cliquez sur le run que vous souhaitez afficher.
4. Cliquez sur l’onglet **Logs** dans la barre latérale du projet.
Vous pouvez filtrer les journaux de console en fonction des libellés que vous fournissez pour `x_label` dans la barre de recherche de l’UI située en haut de la page des journaux de console. Par exemple, l’image suivante montre les options disponibles pour filtrer le journal de console si les valeurs `rank0`, `rank1`, `rank2`, `rank3`, `rank4`, `rank5` et `rank6` sont fournies à `x_label`.
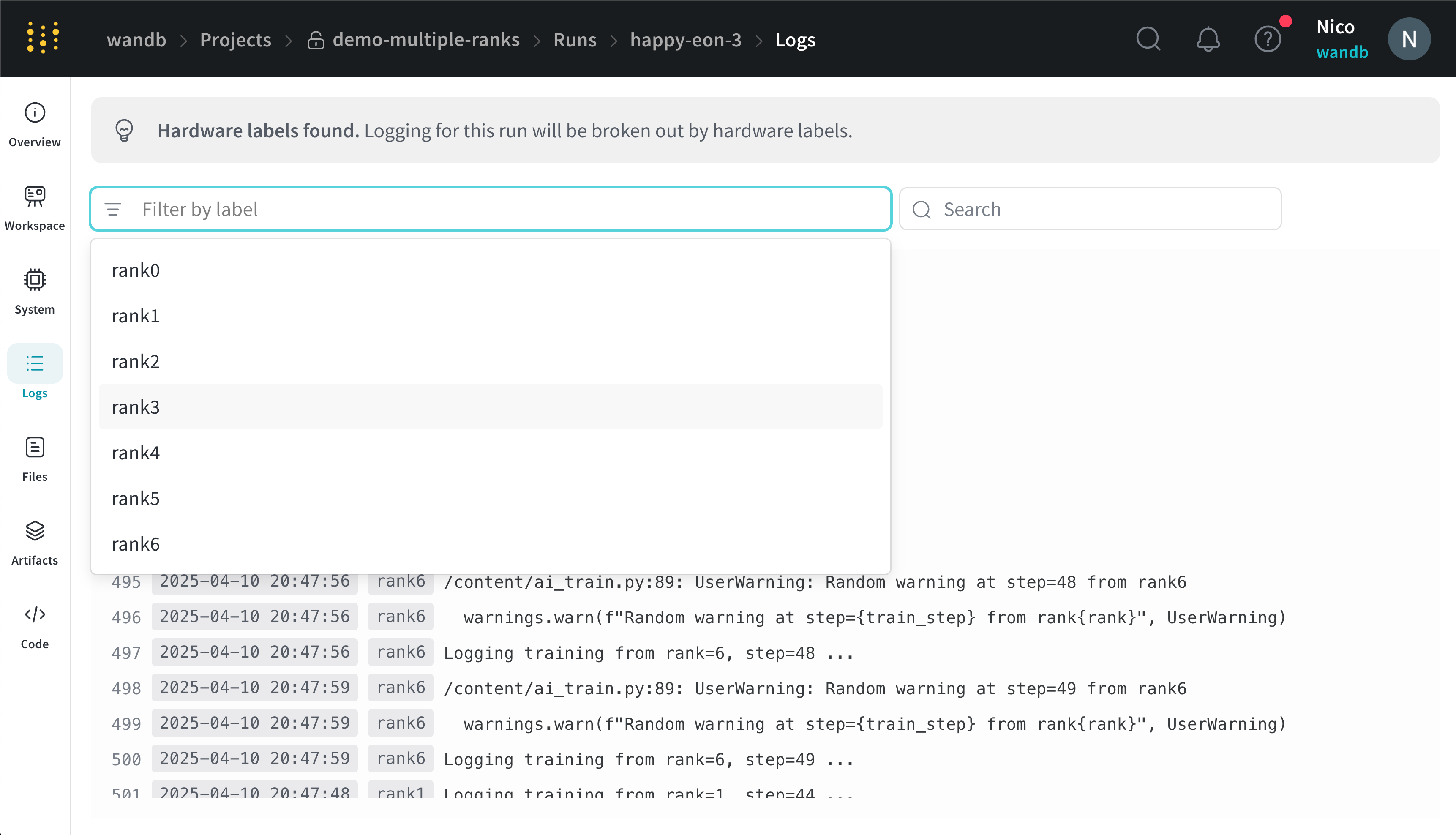 Voir [Journaux de console](/fr/models/app/console-logs/) pour plus d’informations.
W\&B agrège les métriques système de tous les nœuds et les affiche dans W\&B App UI. Par exemple, l’image suivante montre un exemple de tableau de bord avec des métriques système provenant de plusieurs nœuds. Chaque nœud possède un libellé unique (`rank_0`, `rank_1`, `rank_2`) que vous spécifiez dans le paramètre `x_label`.
Voir [Journaux de console](/fr/models/app/console-logs/) pour plus d’informations.
W\&B agrège les métriques système de tous les nœuds et les affiche dans W\&B App UI. Par exemple, l’image suivante montre un exemple de tableau de bord avec des métriques système provenant de plusieurs nœuds. Chaque nœud possède un libellé unique (`rank_0`, `rank_1`, `rank_2`) que vous spécifiez dans le paramètre `x_label`.
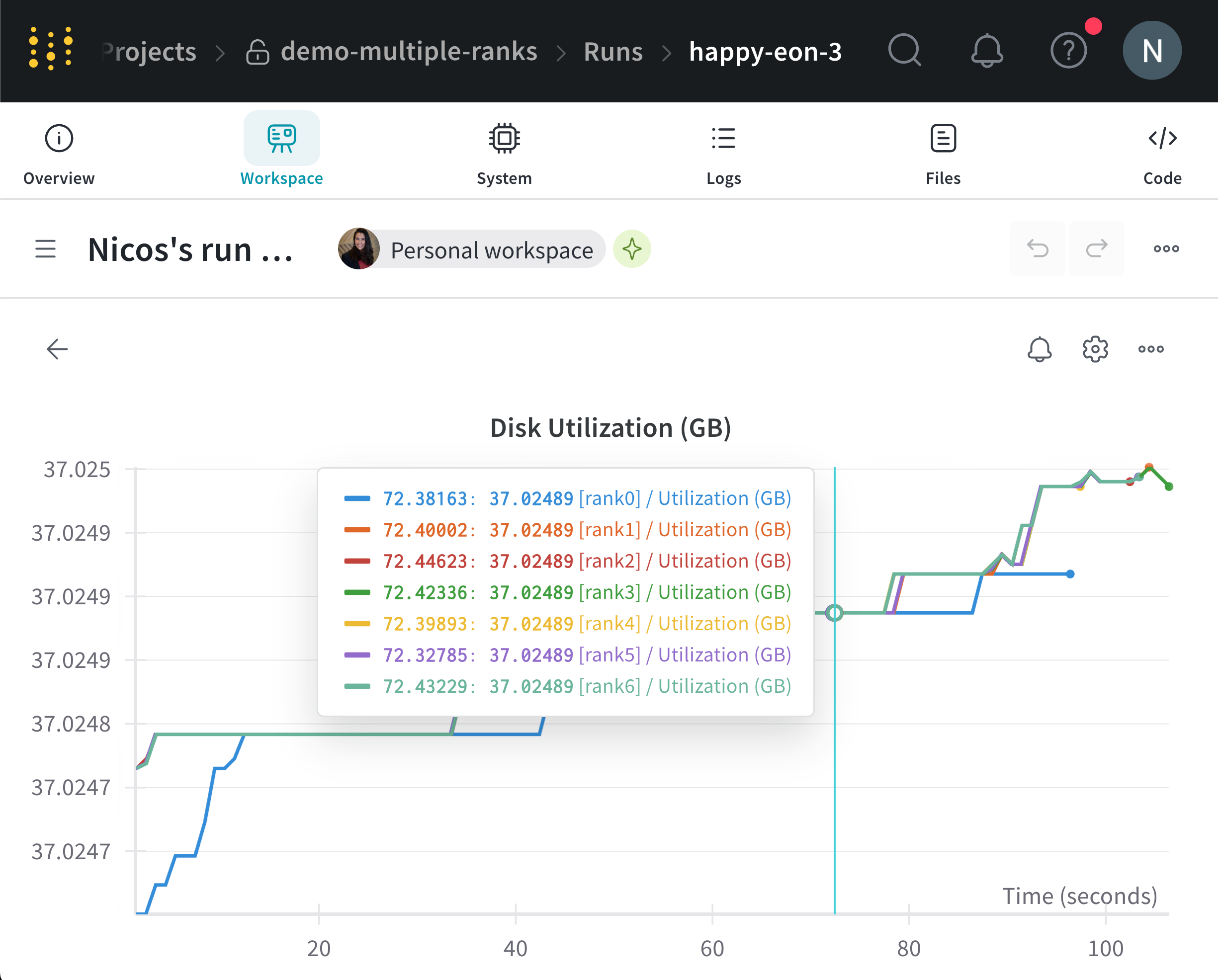 Voir [Graphiques en courbes](/fr/models/app/features/panels/line-plot/) pour savoir comment personnaliser les panneaux de graphique en courbes.
Voir [Graphiques en courbes](/fr/models/app/features/panels/line-plot/) pour savoir comment personnaliser les panneaux de graphique en courbes.
## Exemples de cas d’utilisation
Les extraits de code suivants présentent des scénarios courants pour des cas d’utilisation avancés en environnement distribué.
### Processus enfant
Utilisez la méthode `wandb.setup()` dans votre fonction principale si vous lancez un run dans un processus enfant :
```python theme={null}
import multiprocessing as mp
def do_work(n):
with wandb.init(config=dict(n=n)) as run:
run.log(dict(this=n * n))
def main():
wandb.setup()
pool = mp.Pool(processes=4)
pool.map(do_work, range(4))
if __name__ == "__main__":
main()
```
### Partager un run
Transmettez un objet run en argument pour partager des runs entre processus :
```python theme={null}
def do_work(run):
with wandb.init() as run:
run.log(dict(this=1))
def main():
run = wandb.init()
p = mp.Process(target=do_work, kwargs=dict(run=run))
p.start()
p.join()
run.finish() # marquer le run comme terminé
if __name__ == "__main__":
main()
```
W\&B ne peut pas garantir l’ordre de journalisation. La synchronisation doit être assurée par l’auteur du script.
## Dépannage
Vous pouvez rencontrer deux problèmes courants lorsque vous utilisez W\&B avec l'entraînement distribué :
1. **Blocage au début de l'entraînement** - Un processus `wandb` peut se bloquer si le multiprocessing de `wandb` interfère avec celui de l'entraînement distribué.
2. **Blocage à la fin de l'entraînement** - Une tâche d'entraînement peut se bloquer si le processus `wandb` ne sait pas quand il doit s'arrêter. Appelez l'API `wandb.Run.finish()` à la fin de votre script Python pour indiquer à W\&B que le run est terminé. L'API `wandb.Run.finish()` terminera l'envoi des données et entraînera l'arrêt de W\&B.
W\&B recommande d'utiliser la commande `wandb service` pour améliorer la fiabilité de vos jobs distribués. Ces deux problèmes d'entraînement surviennent fréquemment dans les versions du SDK W\&B où `wandb service` n'est pas disponible.
### Activer W\&B Service
Selon la version du SDK W\&B que vous utilisez, il se peut que W\&B Service soit déjà activé par défaut.
#### SDK W\&B 0.13.0 et versions ultérieures
W\&B Service est activé par défaut à partir de la version `0.13.0` du SDK W\&B.
#### W\&B SDK 0.12.5 et versions ultérieures
Modifiez votre script Python pour activer W\&B Service avec le SDK W\&B version 0.12.5 et les versions ultérieures. Utilisez la méthode `wandb.require()` et transmettez la chaîne `"service"` dans votre fonction principale :
```python theme={null}
if __name__ == "__main__":
main()
def main():
wandb.require("service")
# le-reste-de-votre-script-va-ici
```
Pour une expérience optimale, nous vous recommandons de passer à la version la plus récente.
**SDK W\&B 0.12.4 et versions antérieures**
Si vous utilisez le SDK W\&B 0.12.4 ou une version antérieure, définissez la variable d'environnement `WANDB_START_METHOD` sur `"thread"` pour utiliser le multithreading à la place.