> ## Documentation Index
> Fetch the complete documentation index at: https://docs.wandb.ai/llms.txt
> Use this file to discover all available pages before exploring further.
> Importez des fichiers CSV dans W&B en tant que Tables et Artifacts afin de les visualiser, les comparer et les analyser dans des tableaux de bord.
# Suivre des fichiers CSV dans des expériences
Utilisez la bibliothèque Python W\&B pour enregistrer un fichier CSV et le visualiser dans un [tableau de bord W\&B](/fr/models/track/workspaces/). Les tableaux de bord W\&B constituent l’espace central pour organiser et visualiser les résultats de vos modèles de machine learning. Cela est particulièrement utile si vous avez un [fichier CSV contenant des informations sur des expériences de machine learning précédentes](#import-and-log-your-csv-of-experiments) qui ne sont pas enregistrées dans W\&B, ou un [fichier CSV contenant un jeu de données](#import-and-log-your-dataset-csv-file).
## Importez et journalisez votre fichier CSV de jeu de données
Nous vous recommandons d’utiliser W\&B Artifacts pour faciliter la réutilisation du contenu du fichier CSV.
1. Pour commencer, importez votre fichier CSV. Dans l’extrait de code suivant, remplacez le nom de fichier `iris.csv` par celui de votre fichier CSV :
```python theme={null}
import wandb
import pandas as pd
# Lire notre CSV dans un nouveau DataFrame
new_iris_dataframe = pd.read_csv("iris.csv")
```
2. Convertissez le fichier CSV en tableau W\&B afin de l’utiliser dans les [tableaux de bord W\&B](/fr/models/track/workspaces/).
```python theme={null}
# Convertir le DataFrame en tableau W&B
iris_table = wandb.Table(dataframe=new_iris_dataframe)
```
3. Ensuite, créez un artefact W\&B et ajoutez-y le tableau :
```python theme={null}
# Ajouter le tableau à un Artifact pour augmenter la limite
# de lignes à 200000 et faciliter la réutilisation
iris_table_artifact = wandb.Artifact("iris_artifact", type="dataset")
iris_table_artifact.add(iris_table, "iris_table")
# Journaliser le fichier CSV brut dans un Artifact pour conserver nos données
iris_table_artifact.add_file("iris.csv")
```
Pour plus d’informations sur W\&B Artifacts, voir le [chapitre Artifacts](/fr/models/artifacts/).
4. Enfin, démarrez un nouveau Run W\&B pour suivre et journaliser vos expériences dans W\&B avec `wandb.init()` :
```python theme={null}
# Démarrer un run W&B pour journaliser les données
with wandb.init(project="tables-walkthrough") as run:
# Journaliser le tableau pour le visualiser avec un run...
run.log({"iris": iris_table})
# et le journaliser en tant qu'Artifact pour augmenter la limite de lignes disponible !
run.log_artifact(iris_table_artifact)
```
L’API `wandb.init()` lance un nouveau processus en arrière-plan pour journaliser des données dans un Run et synchronise les données avec wandb.ai (par défaut). Consultez des visualisations en direct dans le tableau de bord de votre Workspace W\&B. L’image suivante illustre le résultat obtenu avec l’extrait de code.
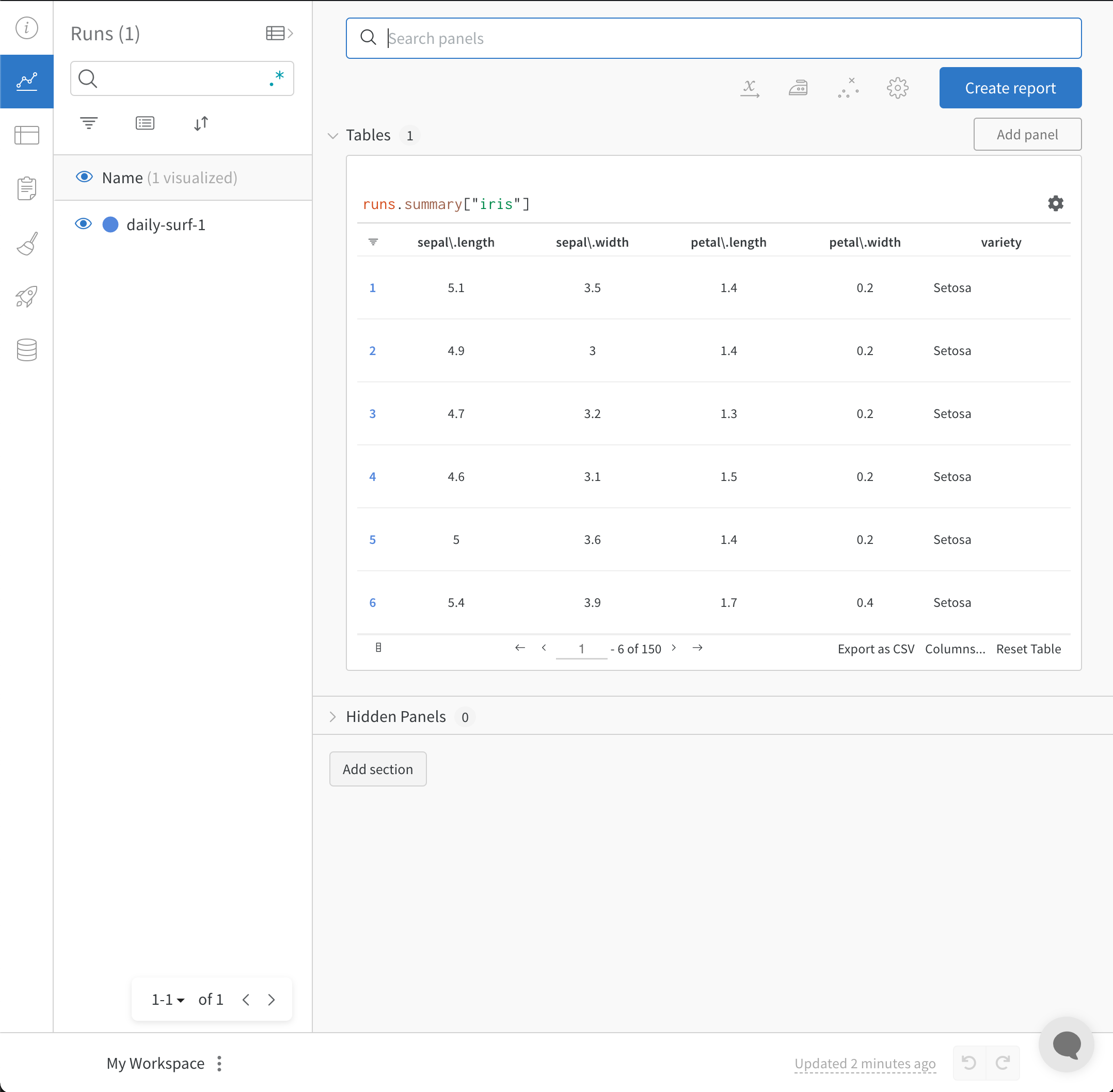 Le script complet contenant les extraits de code ci-dessus se trouve ci-dessous :
```python theme={null}
import wandb
import pandas as pd
# Lire notre CSV dans un nouveau DataFrame
new_iris_dataframe = pd.read_csv("iris.csv")
# Convertir le DataFrame en tableau W&B
iris_table = wandb.Table(dataframe=new_iris_dataframe)
# Ajouter le tableau à un Artifact pour augmenter la limite
# de lignes à 200000 et faciliter sa réutilisation
iris_table_artifact = wandb.Artifact("iris_artifact", type="dataset")
iris_table_artifact.add(iris_table, "iris_table")
# Journaliser le fichier CSV brut dans un Artifact pour conserver nos données
iris_table_artifact.add_file("iris.csv")
# Démarrer un run W&B pour journaliser les données
with wandb.init(project="tables-walkthrough") as run:
# Journaliser le tableau pour le visualiser avec un run...
run.log({"iris": iris_table})
# et le journaliser en tant qu'Artifact pour augmenter la limite de lignes disponible !
run.log_artifact(iris_table_artifact)
```
Le script complet contenant les extraits de code ci-dessus se trouve ci-dessous :
```python theme={null}
import wandb
import pandas as pd
# Lire notre CSV dans un nouveau DataFrame
new_iris_dataframe = pd.read_csv("iris.csv")
# Convertir le DataFrame en tableau W&B
iris_table = wandb.Table(dataframe=new_iris_dataframe)
# Ajouter le tableau à un Artifact pour augmenter la limite
# de lignes à 200000 et faciliter sa réutilisation
iris_table_artifact = wandb.Artifact("iris_artifact", type="dataset")
iris_table_artifact.add(iris_table, "iris_table")
# Journaliser le fichier CSV brut dans un Artifact pour conserver nos données
iris_table_artifact.add_file("iris.csv")
# Démarrer un run W&B pour journaliser les données
with wandb.init(project="tables-walkthrough") as run:
# Journaliser le tableau pour le visualiser avec un run...
run.log({"iris": iris_table})
# et le journaliser en tant qu'Artifact pour augmenter la limite de lignes disponible !
run.log_artifact(iris_table_artifact)
```
## Importez et consignez votre fichier CSV d'Experiments
Dans certains cas, les détails de votre expérience peuvent se trouver dans un fichier CSV. Voici quelques informations couramment présentes dans ce type de fichier :
* Un nom pour le run de l’expérience
* Des [notes](/fr/models/runs/#add-a-note-to-a-run) initiales
* Des [tags](/fr/models/runs/tags/) pour différencier les expériences
* Les configurations nécessaires à votre expérience (avec l’avantage supplémentaire de pouvoir utiliser notre fonctionnalité de [réglage des hyperparamètres Sweeps](/fr/models/sweeps/)).
| Expérience | Nom du modèle | Notes | Tags | Nb de couches | Acc. finale entraînement | Acc. finale val. | Pertes d’entraînement |
| ------------ | ---------------- | ----------------------------------------------------------------------- | ------------- | ------------- | ------------------------ | ---------------- | ------------------------------------- |
| Expérience 1 | mnist-300-layers | Surapprentissage beaucoup trop important sur les données d’entraînement | \[latest] | 300 | 0.99 | 0.90 | \[0.55, 0.45, 0.44, 0.42, 0.40, 0.39] |
| Expérience 2 | mnist-250-layers | Meilleur modèle actuel | \[prod, best] | 250 | 0.95 | 0.96 | \[0.55, 0.45, 0.44, 0.42, 0.40, 0.39] |
| Expérience 3 | mnist-200-layers | Résultats inférieurs à ceux du modèle de référence. Débogage nécessaire | \[debug] | 200 | 0.76 | 0.70 | \[0.55, 0.45, 0.44, 0.42, 0.40, 0.39] |
| ... | ... | ... | ... | ... | ... | ... | |
| Expérience N | mnist-X-layers | NOTES | ... | ... | ... | ... | \[..., ...] |
W\&B peut prendre des fichiers CSV d’expériences et les convertir en runs d’expérience W\&B. Les extraits de code et le script suivants montrent comment importer et journaliser votre fichier CSV d’expériences :
1. Pour commencer, lisez votre fichier CSV et convertissez-le en DataFrame Pandas. Remplacez `"experiments.csv"` par le nom de votre fichier CSV :
```python theme={null}
import wandb
import pandas as pd
FILENAME = "experiments.csv"
loaded_experiment_df = pd.read_csv(FILENAME)
PROJECT_NAME = "Converted Experiments"
EXPERIMENT_NAME_COL = "Experiment"
NOTES_COL = "Notes"
TAGS_COL = "Tags"
CONFIG_COLS = ["Num Layers"]
SUMMARY_COLS = ["Final Train Acc", "Final Val Acc"]
METRIC_COLS = ["Training Losses"]
# Formater le DataFrame Pandas pour faciliter la manipulation des données
for i, row in loaded_experiment_df.iterrows():
run_name = row[EXPERIMENT_NAME_COL]
notes = row[NOTES_COL]
tags = row[TAGS_COL]
config = {}
for config_col in CONFIG_COLS:
config[config_col] = row[config_col]
metrics = {}
for metric_col in METRIC_COLS:
metrics[metric_col] = row[metric_col]
summaries = {}
for summary_col in SUMMARY_COLS:
summaries[summary_col] = row[summary_col]
```
2. Ensuite, démarrez une nouvelle exécution W\&B pour suivre et consigner vos données dans W\&B à l’aide de [`wandb.init()`](/fr/models/ref/python/functions/init) :
```python theme={null}
with wandb.init(
project=PROJECT_NAME, name=run_name, tags=tags, notes=notes, config=config
) as run:
```
Pendant l’exécution d’une expérience, vous souhaiterez peut-être consigner chaque valeur de vos métriques afin de pouvoir les consulter, les interroger et les analyser dans W\&B. Utilisez la commande [`run.log()`](/fr/models/ref/python/experiments/run/#method-runlog) pour ce faire :
```python theme={null}
run.log({key: val})
```
Vous pouvez facultativement journaliser une métrique de synthèse finale pour définir le résultat du run à l’aide de l’API [`define_metric`](/fr/models/ref/python/experiments/run#define_metric). Cet exemple ajoute les métriques de synthèse à notre run avec `run.summary.update()`:
```python theme={null}
run.summary.update(summaries)
```
Pour plus d’informations sur les métriques de synthèse, voir [Log Summary Metrics](./log-summary).
Vous trouverez ci-dessous le script d’exemple complet qui convertit l’exemple de tableau ci-dessus en [tableau de bord W\&B](/fr/models/track/workspaces/) :
```python theme={null}
FILENAME = "experiments.csv"
loaded_experiment_df = pd.read_csv(FILENAME)
PROJECT_NAME = "Converted Experiments"
EXPERIMENT_NAME_COL = "Experiment"
NOTES_COL = "Notes"
TAGS_COL = "Tags"
CONFIG_COLS = ["Num Layers"]
SUMMARY_COLS = ["Final Train Acc", "Final Val Acc"]
METRIC_COLS = ["Training Losses"]
for i, row in loaded_experiment_df.iterrows():
run_name = row[EXPERIMENT_NAME_COL]
notes = row[NOTES_COL]
tags = row[TAGS_COL]
config = {}
for config_col in CONFIG_COLS:
config[config_col] = row[config_col]
metrics = {}
for metric_col in METRIC_COLS:
metrics[metric_col] = row[metric_col]
summaries = {}
for summary_col in SUMMARY_COLS:
summaries[summary_col] = row[summary_col]
with wandb.init(
project=PROJECT_NAME, name=run_name, tags=tags, notes=notes, config=config
) as run:
for key, val in metrics.items():
if isinstance(val, list):
for _val in val:
run.log({key: _val})
else:
run.log({key: val})
run.summary.update(summaries)
```