> ## Documentation Index
> Fetch the complete documentation index at: https://docs.wandb.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Chain Of Density
> Mettez en œuvre des techniques de synthèse chain-of-density avec W&B Weave pour la compression itérative de texte et l’évaluation.
Il s’agit d’un notebook interactif. Vous pouvez l’exécuter localement ou utiliser les liens ci-dessous :
* [Ouvrir dans Google Colab](https://colab.research.google.com/github/wandb/docs/blob/main/weave/cookbooks/source/chain_of_density.ipynb)
* [Voir la source sur GitHub](https://github.com/wandb/docs/blob/main/weave/cookbooks/source/chain_of_density.ipynb)
Résumer des documents techniques complexes tout en préservant les détails essentiels est une tâche difficile. La technique de synthèse Chain of Density (CoD) apporte une solution en affinant itérativement les résumés pour les rendre plus concis et plus denses en informations. Ce guide montre comment mettre en œuvre CoD avec Weave pour le suivi et l’évaluation de l’application.
## Qu'est-ce que la synthèse par Chain of Density
[](https://arxiv.org/abs/2309.04269)
La Chain of Density (CoD) est une technique de synthèse itérative qui produit des synthèses de plus en plus concises et riches en informations. Elle fonctionne comme suit :
1. Commencer par une synthèse initiale
2. Affiner la synthèse de manière itérative pour la rendre plus concise tout en préservant les informations clés
3. Augmenter la densité des entités et des détails techniques à chaque itération
Cette approche est particulièrement utile pour synthétiser des articles scientifiques ou des documents techniques lorsque la préservation d'informations détaillées est essentielle.
## Pourquoi utiliser Weave
Dans ce tutoriel, vous utiliserez Weave pour mettre en œuvre et évaluer un pipeline de synthèse Chain of Density pour des articles ArXiv. Vous apprendrez à :
* **Suivre votre pipeline LLM** : utilisez Weave pour enregistrer automatiquement les entrées, les sorties et les étapes intermédiaires de votre processus de synthèse.
* **Évaluer les sorties du LLM** : créez des évaluations cohérentes de vos synthèses à l’aide des outils intégrés de Weave.
* **Créer des opérations composables** : combinez et réutilisez des opérations Weave dans différentes parties de votre pipeline de synthèse.
* **Intégrer à du code existant** : ajoutez Weave à votre code Python existant avec un minimum de surcharge.
À la fin de ce tutoriel, vous aurez créé un pipeline de synthèse CoD qui exploite les fonctionnalités de Weave pour le serving de modèles, l’évaluation et le suivi des résultats.
## Configurer l’environnement
Tout d’abord, configurez l’environnement et importez les bibliothèques nécessaires. Cette étape installe les dépendances nécessaires au pipeline, notamment Weave pour le suivi, Anthropic pour le LLM et PyPDF2 pour lire les PDF d’ArXiv.
```python lines theme={null}
!pip install -qU anthropic weave pydantic requests PyPDF2 set-env-colab-kaggle-dotenv
```
Comme le pipeline fait appel au modèle Claude d'Anthropic, vous aurez besoin d'une clé API Anthropic avant d'exécuter le code suivant.
> Pour obtenir une clé API Anthropic :
>
> 1. Inscrivez-vous et créez un compte sur [https://www.anthropic.com](https://www.anthropic.com).
> 2. Accédez à la section API dans les paramètres de votre compte.
> 3. Générez une nouvelle clé API.
> 4. Stockez la clé API de façon sécurisée dans votre fichier `.env`.
```python lines theme={null}
import io
import os
from datetime import datetime, timezone
import anthropic
import requests
from pydantic import BaseModel
from PyPDF2 import PdfReader
from set_env import set_env
import weave
set_env("WANDB_API_KEY")
set_env("ANTHROPIC_API_KEY")
weave.init("summarization-chain-of-density-cookbook")
anthropic_client = anthropic.Anthropic(api_key=os.getenv("ANTHROPIC_API_KEY"))
```
Ce code utilise Weave pour suivre l’expérience et le modèle Claude d'Anthropic pour la génération de texte. L'appel `weave.init([PROJECT_NAME])` initialise un nouveau projet Weave pour la tâche de synthèse.
## Définir le modèle ArxivPaper
Une fois l’environnement prêt, l’étape suivante consiste à définir la structure de données sur laquelle le pipeline opère. Créez une classe `ArxivPaper` pour représenter les données :
```python lines theme={null}
# Définir le modèle ArxivPaper
class ArxivPaper(BaseModel):
entry_id: str
updated: datetime
published: datetime
title: str
authors: list[str]
summary: str
pdf_url: str
# Créer un exemple d'ArxivPaper
arxiv_paper = ArxivPaper(
entry_id="http://arxiv.org/abs/2406.04744v1",
updated=datetime(2024, 6, 7, 8, 43, 7, tzinfo=timezone.utc),
published=datetime(2024, 6, 7, 8, 43, 7, tzinfo=timezone.utc),
title="CRAG -- Comprehensive RAG Benchmark",
authors=["Xiao Yang", "Kai Sun", "Hao Xin"], # Tronqué par souci de concision
summary="Retrieval-Augmented Generation (RAG) has recently emerged as a promising solution...", # Tronqué
pdf_url="https://arxiv.org/pdf/2406.04744",
)
```
Cette classe encapsule les métadonnées et le contenu d’un article arXiv, qui sert d’entrée au pipeline de synthèse.
## Charger le contenu du PDF
Le modèle `ArxivPaper` contient des métadonnées et l’URL d’un PDF, mais le pipeline de synthèse a besoin du texte complet de l’article. Pour utiliser le contenu complet de l’article, ajoutez une fonction permettant de charger et d’extraire le texte des PDF :
```python lines theme={null}
@weave.op()
def load_pdf(pdf_url: str) -> str:
# Télécharger le PDF
response = requests.get(pdf_url)
pdf_file = io.BytesIO(response.content)
# Lire le PDF
pdf_reader = PdfReader(pdf_file)
# Extraire le texte de toutes les pages
text = ""
for page in pdf_reader.pages:
text += page.extract_text()
return text
```
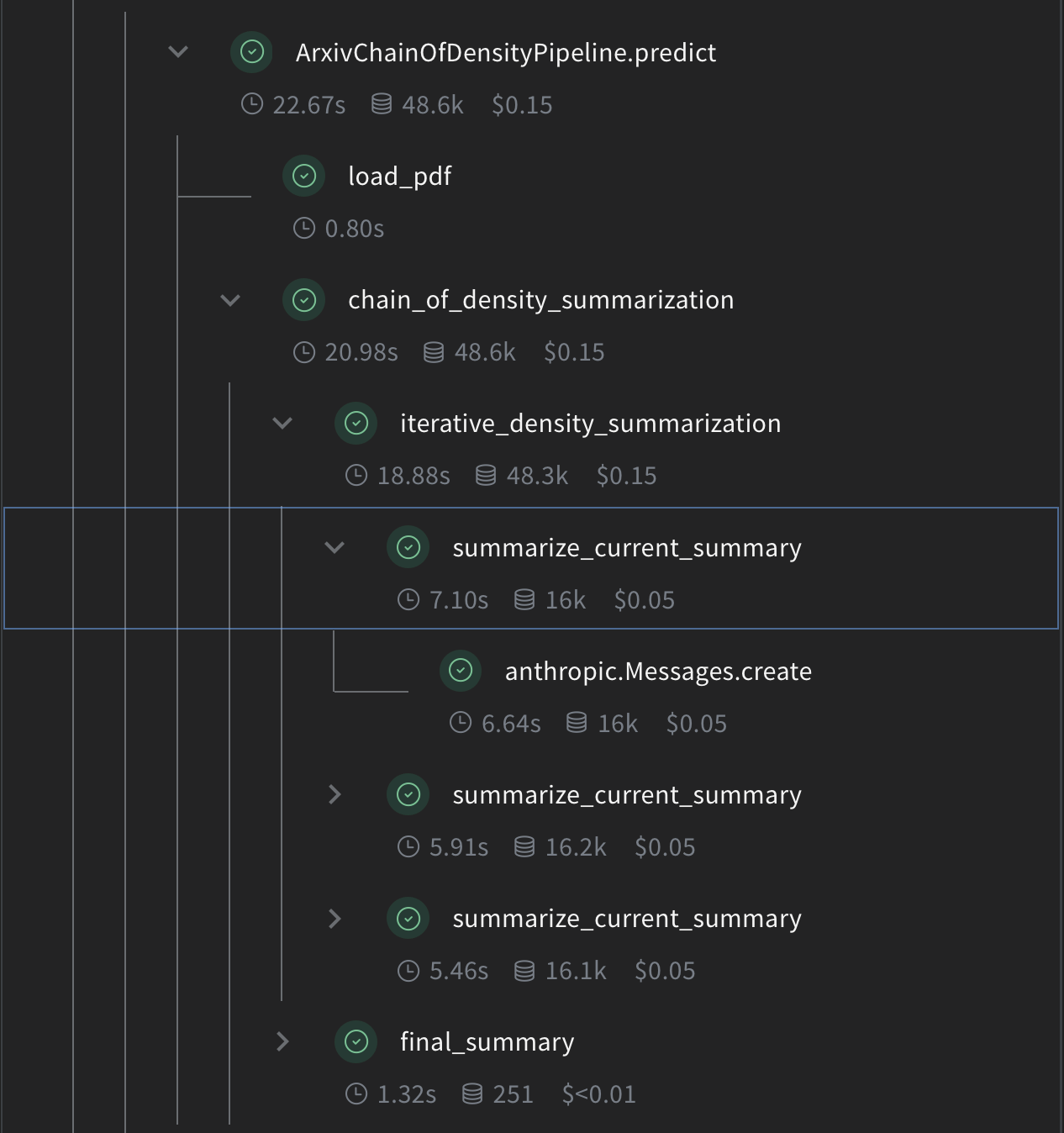
## Implémenter la synthèse par Chain of Density
Implémentez maintenant la logique centrale de la synthèse CoD à l’aide des opérations Weave :
 ```python lines theme={null}
# Chain of Density Summarization
@weave.op()
def summarize_current_summary(
document: str,
instruction: str,
current_summary: str = "",
iteration: int = 1,
model: str = "claude-3-sonnet-20240229",
):
prompt = f"""
Document: {document}
Current summary: {current_summary}
Instruction to focus on: {instruction}
Iteration: {iteration}
Generate an increasingly concise, entity-dense, and highly technical summary from the provided document that specifically addresses the given instruction.
"""
response = anthropic_client.messages.create(
model=model, max_tokens=4096, messages=[{"role": "user", "content": prompt}]
)
return response.content[0].text
@weave.op()
def iterative_density_summarization(
document: str,
instruction: str,
current_summary: str,
density_iterations: int,
model: str = "claude-3-sonnet-20240229",
):
iteration_summaries = []
for iteration in range(1, density_iterations + 1):
current_summary = summarize_current_summary(
document, instruction, current_summary, iteration, model
)
iteration_summaries.append(current_summary)
return current_summary, iteration_summaries
@weave.op()
def final_summary(
instruction: str, current_summary: str, model: str = "claude-3-sonnet-20240229"
):
prompt = f"""
Given this summary: {current_summary}
And this instruction to focus on: {instruction}
Create an extremely dense, final summary that captures all key technical information in the most concise form possible, while specifically addressing the given instruction.
"""
return (
anthropic_client.messages.create(
model=model, max_tokens=4096, messages=[{"role": "user", "content": prompt}]
)
.content[0]
.text
)
@weave.op()
def chain_of_density_summarization(
document: str,
instruction: str,
current_summary: str = "",
model: str = "claude-3-sonnet-20240229",
density_iterations: int = 2,
):
current_summary, iteration_summaries = iterative_density_summarization(
document, instruction, current_summary, density_iterations, model
)
final_summary_text = final_summary(instruction, current_summary, model)
return {
"final_summary": final_summary_text,
"accumulated_summary": current_summary,
"iteration_summaries": iteration_summaries,
}
```
Voici le rôle de chaque fonction :
* `summarize_current_summary` : génère une unique itération de synthèse à partir de l’état actuel.
* `iterative_density_summarization` : applique la technique CoD en appelant `summarize_current_summary` plusieurs fois.
* `chain_of_density_summarization` : orchestre l’ensemble du processus de synthèse et renvoie les résultats.
Les décorateurs `@weave.op()` permettent à Weave de suivre les entrées, les sorties et l’exécution de ces fonctions.
```python lines theme={null}
# Chain of Density Summarization
@weave.op()
def summarize_current_summary(
document: str,
instruction: str,
current_summary: str = "",
iteration: int = 1,
model: str = "claude-3-sonnet-20240229",
):
prompt = f"""
Document: {document}
Current summary: {current_summary}
Instruction to focus on: {instruction}
Iteration: {iteration}
Generate an increasingly concise, entity-dense, and highly technical summary from the provided document that specifically addresses the given instruction.
"""
response = anthropic_client.messages.create(
model=model, max_tokens=4096, messages=[{"role": "user", "content": prompt}]
)
return response.content[0].text
@weave.op()
def iterative_density_summarization(
document: str,
instruction: str,
current_summary: str,
density_iterations: int,
model: str = "claude-3-sonnet-20240229",
):
iteration_summaries = []
for iteration in range(1, density_iterations + 1):
current_summary = summarize_current_summary(
document, instruction, current_summary, iteration, model
)
iteration_summaries.append(current_summary)
return current_summary, iteration_summaries
@weave.op()
def final_summary(
instruction: str, current_summary: str, model: str = "claude-3-sonnet-20240229"
):
prompt = f"""
Given this summary: {current_summary}
And this instruction to focus on: {instruction}
Create an extremely dense, final summary that captures all key technical information in the most concise form possible, while specifically addressing the given instruction.
"""
return (
anthropic_client.messages.create(
model=model, max_tokens=4096, messages=[{"role": "user", "content": prompt}]
)
.content[0]
.text
)
@weave.op()
def chain_of_density_summarization(
document: str,
instruction: str,
current_summary: str = "",
model: str = "claude-3-sonnet-20240229",
density_iterations: int = 2,
):
current_summary, iteration_summaries = iterative_density_summarization(
document, instruction, current_summary, density_iterations, model
)
final_summary_text = final_summary(instruction, current_summary, model)
return {
"final_summary": final_summary_text,
"accumulated_summary": current_summary,
"iteration_summaries": iteration_summaries,
}
```
Voici le rôle de chaque fonction :
* `summarize_current_summary` : génère une unique itération de synthèse à partir de l’état actuel.
* `iterative_density_summarization` : applique la technique CoD en appelant `summarize_current_summary` plusieurs fois.
* `chain_of_density_summarization` : orchestre l’ensemble du processus de synthèse et renvoie les résultats.
Les décorateurs `@weave.op()` permettent à Weave de suivre les entrées, les sorties et l’exécution de ces fonctions.
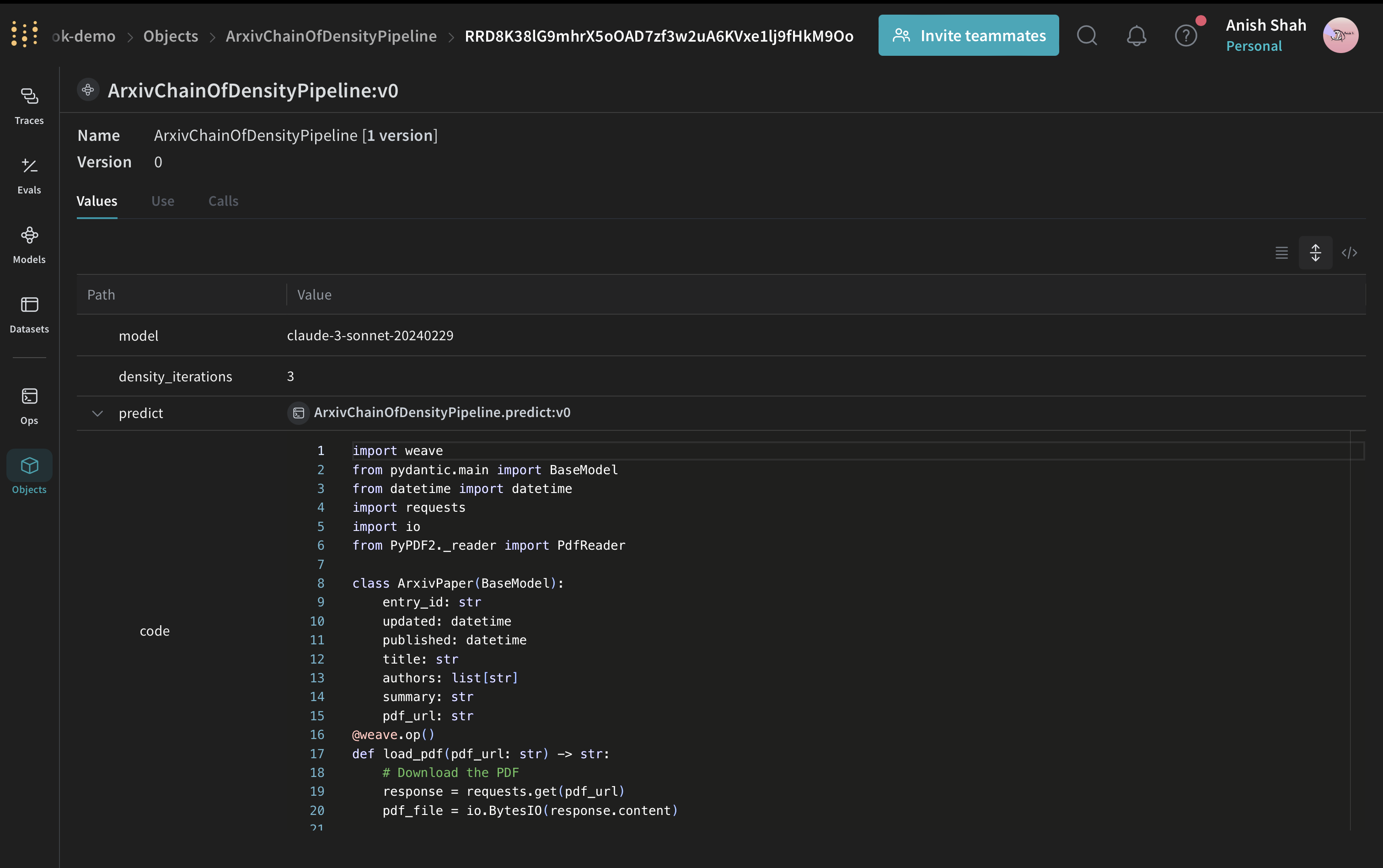
## Créer un modèle Weave
Une fois les fonctions de synthèse en place, l’étape suivante consiste à les empaqueter sous la forme d’un modèle Weave afin que les exécutions, les paramètres et les versions soient suivis ensemble. Encapsulons maintenant notre pipeline de synthèse dans un modèle Weave :
 ```python lines theme={null}
# Weave Model
class ArxivChainOfDensityPipeline(weave.Model):
model: str = "claude-3-sonnet-20240229"
density_iterations: int = 3
@weave.op()
def predict(self, paper: ArxivPaper, instruction: str) -> dict:
text = load_pdf(paper.pdf_url)
result = chain_of_density_summarization(
text,
instruction,
model=self.model,
density_iterations=self.density_iterations,
)
return result
```
Cette classe `ArxivChainOfDensityPipeline` encapsule la logique de synthèse sous la forme d’un modèle Weave, avec plusieurs avantages clés :
* Suivi automatique des expériences : Weave capture les entrées, les sorties et les paramètres de chaque exécution du modèle.
* Gestion des versions : Les modifications apportées aux attributs ou au code du modèle sont automatiquement versionnées, ce qui crée un historique clair de l’évolution de votre pipeline de synthèse au fil du temps.
* Reproductibilité : La gestion des versions et le suivi vous permettent de reproduire tout résultat ou toute configuration antérieurs de votre pipeline de synthèse.
* Gestion des hyperparamètres : Les attributs du modèle (comme `model` et `density_iterations`) sont clairement définis et suivis d’une exécution à l’autre, ce qui facilite l’expérimentation.
* Intégration avec l’écosystème Weave : L’utilisation de `weave.Model` fonctionne avec d’autres outils Weave, comme les évaluations et les fonctionnalités de serving.
```python lines theme={null}
# Weave Model
class ArxivChainOfDensityPipeline(weave.Model):
model: str = "claude-3-sonnet-20240229"
density_iterations: int = 3
@weave.op()
def predict(self, paper: ArxivPaper, instruction: str) -> dict:
text = load_pdf(paper.pdf_url)
result = chain_of_density_summarization(
text,
instruction,
model=self.model,
density_iterations=self.density_iterations,
)
return result
```
Cette classe `ArxivChainOfDensityPipeline` encapsule la logique de synthèse sous la forme d’un modèle Weave, avec plusieurs avantages clés :
* Suivi automatique des expériences : Weave capture les entrées, les sorties et les paramètres de chaque exécution du modèle.
* Gestion des versions : Les modifications apportées aux attributs ou au code du modèle sont automatiquement versionnées, ce qui crée un historique clair de l’évolution de votre pipeline de synthèse au fil du temps.
* Reproductibilité : La gestion des versions et le suivi vous permettent de reproduire tout résultat ou toute configuration antérieurs de votre pipeline de synthèse.
* Gestion des hyperparamètres : Les attributs du modèle (comme `model` et `density_iterations`) sont clairement définis et suivis d’une exécution à l’autre, ce qui facilite l’expérimentation.
* Intégration avec l’écosystème Weave : L’utilisation de `weave.Model` fonctionne avec d’autres outils Weave, comme les évaluations et les fonctionnalités de serving.
## Implémenter des métriques d’évaluation
Maintenant que le pipeline produit des résumés, vous avez besoin d’un moyen de mesurer systématiquement leur qualité. Pour évaluer la qualité des résumés, mettez en œuvre des métriques d’évaluation simples :
```python lines theme={null}
import json
@weave.op()
def evaluate_summary(
summary: str, instruction: str, model: str = "claude-3-sonnet-20240229"
) -> dict:
prompt = f"""
Summary: {summary}
Instruction: {instruction}
Evaluate the summary based on the following criteria:
1. Relevance (1-5): How well does the summary address the given instruction?
2. Conciseness (1-5): How concise is the summary while retaining key information?
3. Technical Accuracy (1-5): How accurately does the summary convey technical details?
Your response MUST be in the following JSON format:
{{
"relevance": {{
"score": ,
"explanation": ""
}},
"conciseness": {{
"score": ,
"explanation": ""
}},
"technical_accuracy": {{
"score": ,
"explanation": ""
}}
}}
Ensure that the scores are integers between 1 and 5, and that the explanations are concise.
"""
response = anthropic_client.messages.create(
model=model, max_tokens=1000, messages=[{"role": "user", "content": prompt}]
)
print(response.content[0].text)
eval_dict = json.loads(response.content[0].text)
return {
"relevance": eval_dict["relevance"]["score"],
"conciseness": eval_dict["conciseness"]["score"],
"technical_accuracy": eval_dict["technical_accuracy"]["score"],
"average_score": sum(eval_dict[k]["score"] for k in eval_dict) / 3,
"evaluation_text": response.content[0].text,
}
```
Ces fonctions d’évaluation utilisent le modèle Claude pour évaluer la qualité des résumés générés selon leur pertinence, leur concision et leur précision technique.
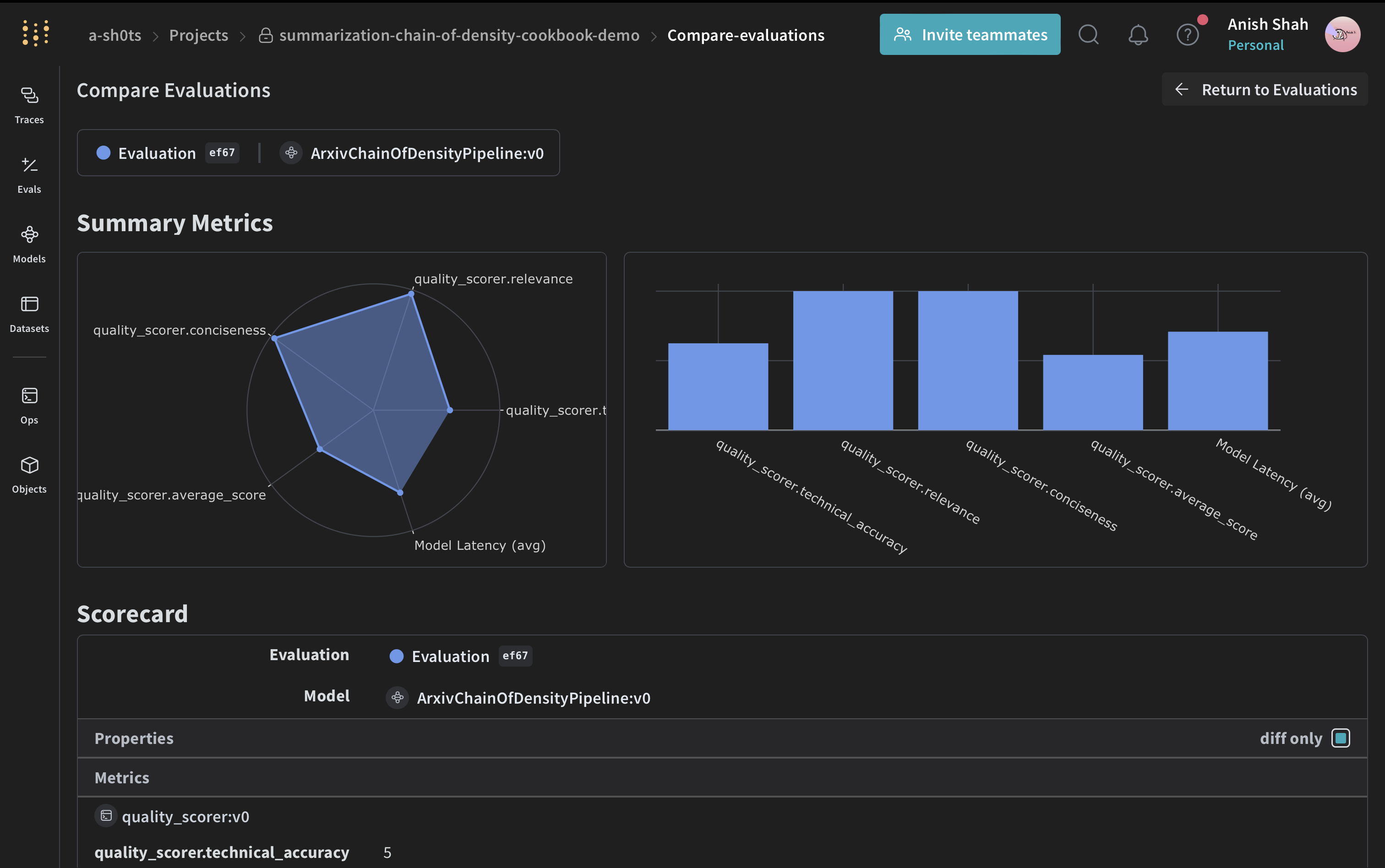
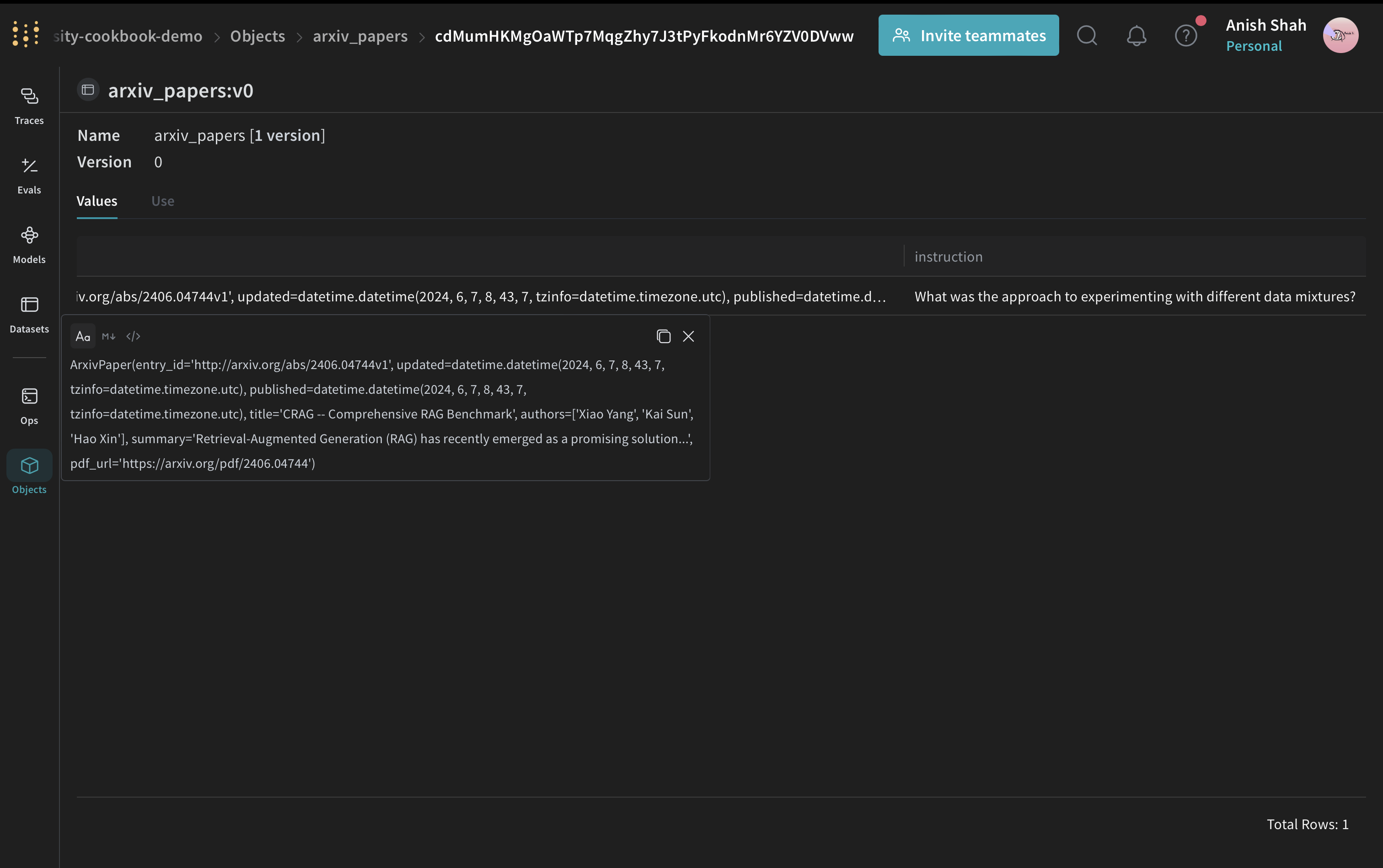
## Créer un dataset Weave et lancer l’évaluation
Maintenant que la fonction de score est définie, la dernière étape consiste à l’appliquer à des exemples d’entrée et à lancer l’évaluation. Pour évaluer le pipeline, créez un dataset Weave et lancez une évaluation :
 ```python lines theme={null}
# Créer un Weave Dataset
dataset = weave.Dataset(
name="arxiv_papers",
rows=[
{
"paper": arxiv_paper,
"instruction": "What was the approach to experimenting with different data mixtures?",
},
],
)
weave.publish(dataset)
```
Pour l’évaluation, utilisez une approche de type LLM-as-a-judge. Cette technique consiste à utiliser un modèle de langage pour évaluer la qualité des résultats générés par un autre modèle ou système. Elle exploite les capacités de compréhension et de raisonnement du LLM pour fournir des évaluations nuancées, en particulier pour les tâches où les métriques traditionnelles peuvent s’avérer insuffisantes.
[](https://arxiv.org/abs/2306.05685)
```python lines theme={null}
# Définir la fonction scorer
@weave.op()
def quality_scorer(instruction: str, output: dict) -> dict:
result = evaluate_summary(output["final_summary"], instruction)
return result
```
```python lines theme={null}
# Exécuter l'évaluation
evaluation = weave.Evaluation(dataset=dataset, scorers=[quality_scorer])
arxiv_chain_of_density_pipeline = ArxivChainOfDensityPipeline()
results = await evaluation.evaluate(arxiv_chain_of_density_pipeline)
```
Ce code crée un dataset à partir d’un exemple d’article ArXiv, définit un scorer de qualité et lance une évaluation du pipeline de synthèse.
```python lines theme={null}
# Créer un Weave Dataset
dataset = weave.Dataset(
name="arxiv_papers",
rows=[
{
"paper": arxiv_paper,
"instruction": "What was the approach to experimenting with different data mixtures?",
},
],
)
weave.publish(dataset)
```
Pour l’évaluation, utilisez une approche de type LLM-as-a-judge. Cette technique consiste à utiliser un modèle de langage pour évaluer la qualité des résultats générés par un autre modèle ou système. Elle exploite les capacités de compréhension et de raisonnement du LLM pour fournir des évaluations nuancées, en particulier pour les tâches où les métriques traditionnelles peuvent s’avérer insuffisantes.
[](https://arxiv.org/abs/2306.05685)
```python lines theme={null}
# Définir la fonction scorer
@weave.op()
def quality_scorer(instruction: str, output: dict) -> dict:
result = evaluate_summary(output["final_summary"], instruction)
return result
```
```python lines theme={null}
# Exécuter l'évaluation
evaluation = weave.Evaluation(dataset=dataset, scorers=[quality_scorer])
arxiv_chain_of_density_pipeline = ArxivChainOfDensityPipeline()
results = await evaluation.evaluate(arxiv_chain_of_density_pipeline)
```
Ce code crée un dataset à partir d’un exemple d’article ArXiv, définit un scorer de qualité et lance une évaluation du pipeline de synthèse.
## Conclusion
Cet exemple a montré comment mettre en place un pipeline de synthèse Chain of Density pour des articles ArXiv avec Weave. Vous avez appris à :
* Créer des opérations Weave pour chaque étape du processus de synthèse
* Encapsuler le pipeline dans un modèle Weave pour le suivi et l’évaluation
* Mettre en œuvre des métriques d’évaluation personnalisées à l’aide des opérations Weave
* Créer un dataset et exécuter une évaluation du pipeline
Weave suit les entrées, les sorties et les étapes intermédiaires tout au long du processus de synthèse, ce qui facilite le débogage, l’optimisation et l’évaluation de votre application LLM.
Vous pouvez étendre cet exemple pour traiter des datasets plus volumineux, mettre en œuvre des métriques d’évaluation plus sophistiquées ou l’intégrer à d’autres flux de travail LLM.
Consulter le rapport complet sur W\&B