> ## Documentation Index
> Fetch the complete documentation index at: https://docs.wandb.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Tracer et évaluer un pipeline de vision par ordinateur avec Weave
> Découvrez comment tracer et évaluer un pipeline de vision par ordinateur avec W&B Weave
Il s'agit d'un notebook interactif. Vous pouvez l'exécuter en local ou utiliser les liens ci-dessous :
* [Open in Google Colab](https://colab.research.google.com/github/wandb/docs/blob/main/weave/cookbooks/source/ocr-pipeline.ipynb)
* [Voir la source sur GitHub](https://github.com/wandb/docs/blob/main/weave/cookbooks/source/ocr-pipeline.ipynb)
Ce tutoriel vous montre comment créer, tracer et évaluer un pipeline de vision par ordinateur qui effectue une reconnaissance d’entités nommées (NER) sur des images d’informations patients manuscrites. À la fin, vous disposerez d’un pipeline opérationnel de reconnaissance optique de caractères (OCR), reposant sur un modèle vision-langage (VLM) et sur une évaluation W\&B Weave, qui mesure la précision avec laquelle le pipeline extrait des champs structurés à partir d’images. Ce guide s’adresse aux développeurs qui souhaitent utiliser Weave pour itérer sur les prompts et mesurer systématiquement la qualité des pipelines d’extraction multimodale.
Les sections suivantes présentent cinq étapes : créer et faire évoluer les prompts, récupérer le jeu de données, construire le pipeline NER, définir les évaluateurs et exécuter une évaluation.
## Prérequis
Avant de commencer, installez et importez les bibliothèques requises, obtenez votre clé API W\&B et initialisez votre projet Weave. Cette étape garantit que votre environnement peut s'authentifier auprès de W\&B et enregistrer des traces dans votre projet Weave.
```python lines theme={null}
# Installer les dépendances requises
!pip install openai weave -q
python
import json
import os
from google.colab import userdata
from openai import OpenAI
import weave
python
# Obtenir les clés API
os.environ["OPENAI_API_KEY"] = userdata.get(
"OPENAI_API_KEY"
) # veuillez définir les clés comme secrets d'environnement Colab depuis le menu à gauche
os.environ["WANDB_API_KEY"] = userdata.get("WANDB_API_KEY")
# Définir le nom du projet
# Remplacez la valeur PROJECT par le nom de votre projet
PROJECT = "vlm-handwritten-ner"
# Initialiser le projet Weave
weave.init(PROJECT)
```
## Créez des prompts et itérez dessus avec Weave
Une bonne ingénierie de prompts est essentielle pour guider le modèle afin qu’il extraie correctement les Entities. Dans cette section, vous rédigez un prompt initial, le publiez dans Weave pour pouvoir suivre ses modifications au fil du temps, puis l’affinez à l’aide de règles de validation plus strictes.
Commencez par créer un prompt de base qui indique au modèle quoi extraire des données d’image et comment le formater. Ensuite, enregistrez le prompt dans Weave pour en assurer le suivi et faciliter l’itération.
````python lines theme={null}
# Créez votre objet prompt avec Weave
prompt = """
Extract all readable text from this image. Format the extracted entities as a valid JSON.
Do not return any extra text, just the JSON. Do not include ```json```
Use the following format:
{"Patient Name": "James James","Date": "4/22/2025","Patient ID": "ZZZZZZZ123","Group Number": "3452542525"}
"""
system_prompt = weave.StringPrompt(prompt)
# Publiez votre prompt sur Weave
weave.publish(system_prompt, name="NER-prompt")
````
Ensuite, améliorez le prompt en ajoutant davantage d'instructions et de règles de validation afin de réduire les erreurs dans le résultat produit. Publier la version révisée sous le même nom permet à Weave de suivre le prompt comme une nouvelle version, afin que vous puissiez comparer les résultats d’une itération à l’autre.
````python lines theme={null}
better_prompt = """
You are a precision OCR assistant. Given an image of patient information, extract exactly these fields into a single JSON object (and nothing else):
- Patient Name
- Date (MM/DD/YYYY)
- Patient ID
- Group Number
Validation rules:
1. Date must match MM/DD/YY; if not, set Date to "".
2. Patient ID must be alphanumeric; if unreadable, set to "".
3. Always zero-pad months and days (e.g. "04/07/25").
4. Omit any markup, commentary, or code fences.
5. Return strictly valid JSON with only those four keys.
Do not return any extra text, just the JSON. Do not include ```json```
Example output:
{"Patient Name":"James James","Date":"04/22/25","Patient ID":"ZZZZZZZ123","Group Number":"3452542525"}
"""
# Modifier le prompt
system_prompt = weave.StringPrompt(better_prompt)
# Publier le prompt modifié dans Weave
weave.publish(system_prompt, name="NER-prompt")
````
## Obtenir le jeu de données
Une fois le prompt défini, vous avez besoin de données d'entrée pour alimenter le pipeline. Récupérez le jeu de données de notes manuscrites qui sert d'entrée au pipeline d'OCR.
Les images du jeu de données sont déjà encodées en `base64`, ce qui signifie que le LLM peut utiliser les données sans aucun prétraitement.
```python lines theme={null}
# Récupérer le jeu de données depuis le projet Weave suivant
dataset = weave.ref(
"weave://wandb-smle/vlm-handwritten-ner/object/NER-eval-dataset:G8MEkqWBtvIxPYAY23sXLvqp8JKZ37Cj0PgcG19dGjw"
).get()
# Accéder à un exemple spécifique dans le jeu de données
example_image = dataset.rows[3]["image_base64"]
# Afficher l'example_image
from IPython.display import HTML, display
html = f' '
display(HTML(html))
```
'
display(HTML(html))
```
## Créer le pipeline NER
Maintenant que vous disposez d’un prompt et d’un jeu de données, créez le pipeline NER qui les relie au VLM. Le pipeline se compose de deux fonctions :
* Une fonction `encode_image` qui prend une image PIL du jeu de données et renvoie une représentation de l’image encodée en `base64`, pouvant être transmise au VLM.
* Une fonction `extract_named_entities_from_image` qui prend une image et un prompt système, puis renvoie les entités extraites de cette image, telles que décrites par le prompt système.
```python lines theme={null}
# Fonction traçable utilisant GPT-4-Vision
def extract_named_entities_from_image(image_base64) -> dict:
# Initialisation du client LLM
client = OpenAI()
# Configuration du prompt d'instruction
# Vous pouvez également utiliser un prompt stocké dans Weave avec weave.ref("weave://wandb-smle/vlm-handwritten-ner/object/NER-prompt:FmCv4xS3RFU21wmNHsIYUFal3cxjtAkegz2ylM25iB8").get().content.strip()
prompt = better_prompt
response = client.responses.create(
model="gpt-4.1",
input=[
{
"role": "user",
"content": [
{"type": "input_text", "text": prompt},
{
"type": "input_image",
"image_url": image_base64,
},
],
}
],
)
return response.output_text
```
Créez maintenant une fonction appelée `named_entity_recognation` qui :
* Envoie les données d’image au pipeline NER.
* Renvoie un JSON correctement formaté avec les résultats.
Utilisez le [décorateur `@weave.op()`](/fr/weave/reference/python-sdk/trace/op) pour suivre et tracer automatiquement l’exécution de la fonction dans l’interface utilisateur de W\&B.
Chaque fois que `named_entity_recognation` s’exécute, les résultats complets de la trace sont visibles dans l’interface Weave. Pour afficher les traces, accédez à l’onglet **Traces** de votre projet Weave.
```python lines theme={null}
# Fonction NER pour les évaluations
@weave.op()
def named_entity_recognation(image_base64, id):
result = {}
try:
# 1) appeler l'op de vision, récupérer une chaîne JSON
output_text = extract_named_entities_from_image(image_base64)
# 2) parser le JSON une seule fois
result = json.loads(output_text)
print(f"Processed: {str(id)}")
except Exception as e:
print(f"Failed to process {str(id)}: {e}")
return result
```
Enfin, exécutez le pipeline sur le jeu de données, puis consultez les résultats. Cette étape produit les résultats du modèle que vous évaluerez dans la section suivante.
Le code suivant parcourt le jeu de données et enregistre les résultats dans un fichier local `processing_results.json`. Les résultats sont également consultables dans l’interface Weave.
```python lines theme={null}
# Résultats de sortie
results = []
# parcourir toutes les images du jeu de données
for row in dataset.rows:
result = named_entity_recognation(row["image_base64"], str(row["id"]))
result["image_id"] = str(row["id"])
results.append(result)
# Enregistrer tous les résultats dans un fichier JSON
output_file = "processing_results.json"
with open(output_file, "w") as f:
json.dump(results, f, indent=2)
print(f"Results saved to: {output_file}")
```
Vous voyez ci-dessous un exemple similaire dans le tableau **Traces** de l’interface Weave.
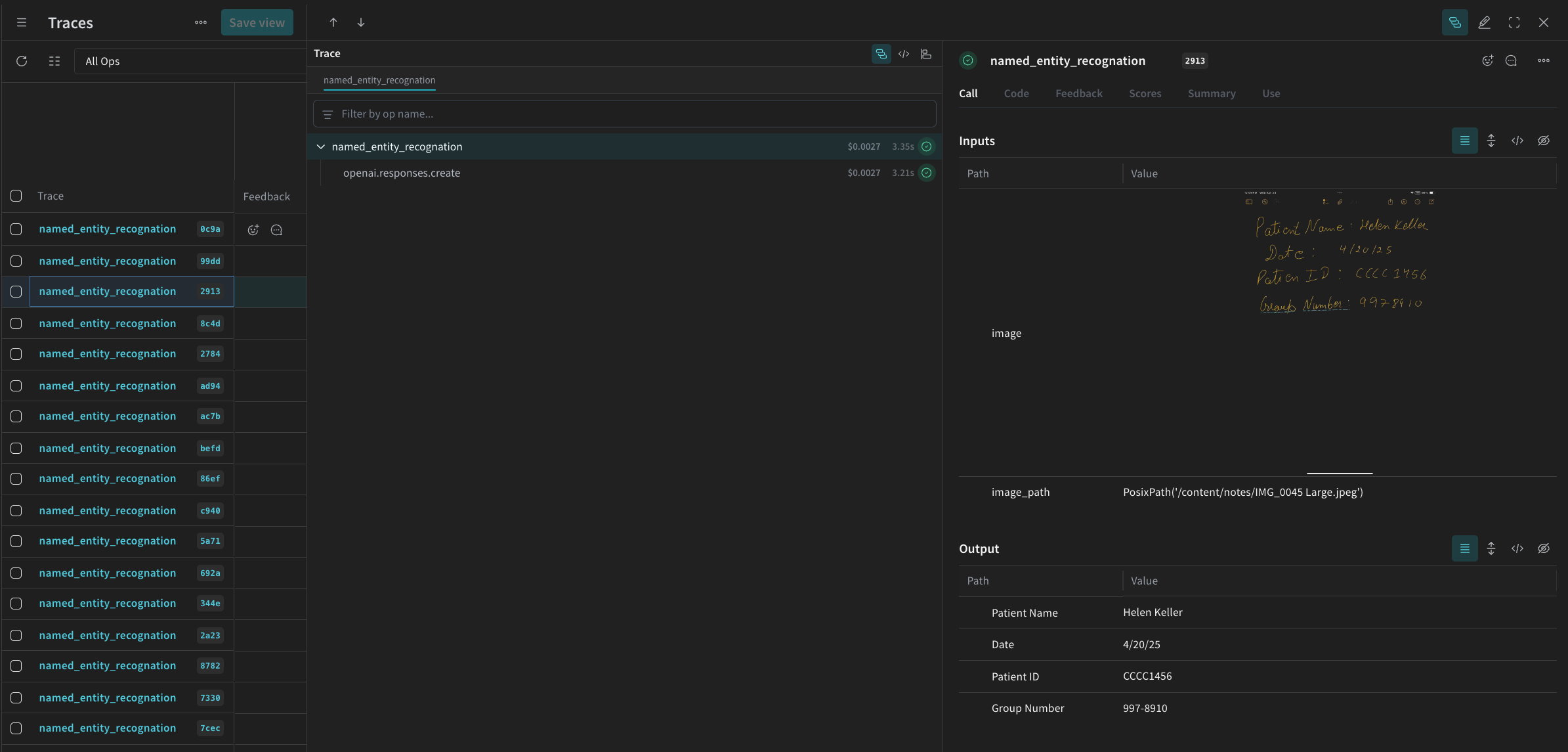
## Évaluer le pipeline avec Weave
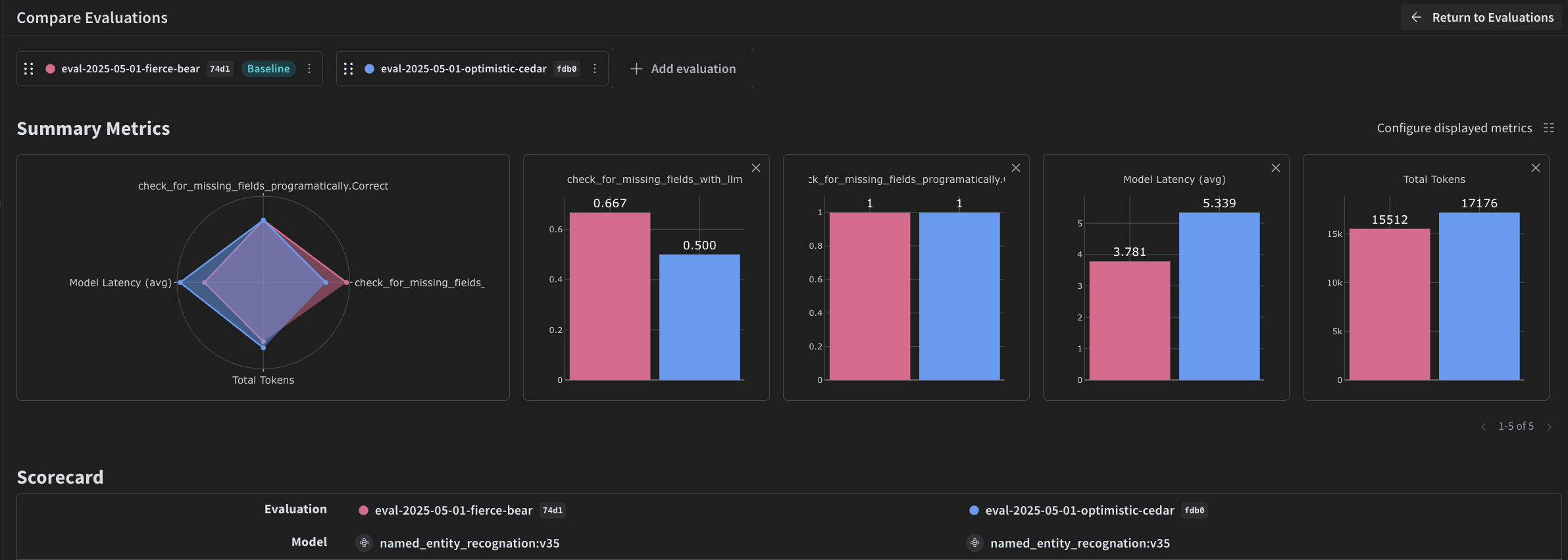
Maintenant que vous avez créé un pipeline pour effectuer de la NER à l’aide d’un VLM, vous pouvez utiliser Weave pour l’évaluer de façon systématique et voir dans quelle mesure il est performant. Évaluer le pipeline vous permet de mesurer la qualité de l’extraction sur l’ensemble du jeu de données plutôt que de vous appuyer sur des vérifications ponctuelles. Pour plus d’informations sur les évaluations dans Weave, consultez [Aperçu des évaluations](/fr/weave/guides/core-types/evaluations).
Un [évaluateur](/fr/weave/guides/evaluation/scorers) constitue un élément fondamental d’une évaluation dans Weave. Les évaluateurs servent à évaluer les sorties de l’IA et à renvoyer des métriques d’évaluation. Ils prennent la sortie de l’IA, l’analysent et renvoient un dictionnaire de résultats. Les évaluateurs peuvent utiliser vos données d’entrée comme référence si nécessaire et peuvent également renvoyer des informations supplémentaires, comme des explications ou le raisonnement issu de l’évaluation.
Dans cette section, vous créez deux évaluateurs pour évaluer le pipeline :
* Évaluateur programmatique.
* Scorer LLM-as-a-judge.
### Évaluateur programmatique
Le premier évaluateur est une vérification déterministe qui s’exécute sans LLM. L’évaluateur programmatique, `check_for_missing_fields_programatically`, prend la sortie du modèle (la sortie de la fonction `named_entity_recognition`) et identifie les `clés` manquantes ou vides dans les résultats.
Cette vérification est utile pour repérer les échantillons pour lesquels le modèle n’a extrait aucun champ.
```python lines theme={null}
# Ajouter weave.op() pour suivre l'exécution du scorer
@weave.op()
def check_for_missing_fields_programatically(model_output):
# Clés requises pour chaque entrée
required_fields = {"Patient Name", "Date", "Patient ID", "Group Number"}
for key in required_fields:
if (
key not in model_output
or model_output[key] is None
or str(model_output[key]).strip() == ""
):
return False # Cette entrée contient un champ manquant ou vide
return True # Tous les champs requis sont présents et non vides
```
### Évaluateur LLM-as-a-judge
Comme l’évaluateur programmatique ne détecte que les champs manquants ou vides, vous avez besoin d’un second évaluateur pour vérifier si les valeurs extraites correspondent bien à ce qui apparaît dans l’image. À cette étape de l’évaluation, vous fournissez à la fois les données de l’image et la sortie du modèle afin de garantir que l’évaluation reflète les performances réelles du système de NER. Le contenu de l’image est référencé explicitement, et pas seulement la sortie du modèle.
L’évaluateur utilisé pour cette étape, `check_for_missing_fields_with_llm`, utilise un LLM pour effectuer le scoring (plus précisément le modèle `gpt-4o` d’OpenAI). Comme l’indique le contenu de `eval_prompt`, `check_for_missing_fields_with_llm` produit une valeur `Boolean`. Si tous les champs correspondent aux informations de l’image et que le formatage est correct, l’évaluateur renvoie `true`. Si un champ est manquant, vide, incorrect ou ne correspond pas, le résultat est `false`, et l’évaluateur renvoie également un message expliquant le problème.
```python lines theme={null}
# Le prompt système pour le LLM-as-a-judge
eval_prompt = """
You are an OCR validation system. Your role is to assess whether the structured text extracted from an image accurately reflects the information in that image.
Only validate the structured text and use the image as your source of truth.
Expected input text format:
{"Patient Name": "First Last", "Date": "04/23/25", "Patient ID": "131313JJH", "Group Number": "35453453"}
Evaluation criteria:
- All four fields must be present.
- No field should be empty or contain placeholder/malformed values.
- The "Date" should be in MM/DD/YY format (e.g., "04/07/25") (zero padding the date is allowed)
Scoring:
- Return: {"Correct": true, "Reason": ""} if **all fields** match the information in the image and formatting is correct.
- Return: {"Correct": false, "Reason": "EXPLANATION"} if **any** field is missing, empty, incorrect, or mismatched.
Output requirements:
- Respond with a valid JSON object only.
- "Correct" must be a JSON boolean: true or false (not a string or number).
- "Reason" must be a short, specific string indicating all the problem — e.g., "Patient Name mismatch", "Date not zero-padded", or "Missing Group Number".
- Do not return any additional explanation or formatting.
Your response must be exactly one of the following:
{"Correct": true, "Reason": null}
OR
{"Correct": false, "Reason": "EXPLANATION_HERE"}
"""
# Ajouter weave.op() pour suivre l'exécution du Scorer
@weave.op()
def check_for_missing_fields_with_llm(model_output, image_base64):
client = OpenAI()
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "developer", "content": [{"text": eval_prompt, "type": "text"}]},
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": image_base64,
},
},
{"type": "text", "text": str(model_output)},
],
},
],
response_format={"type": "json_object"},
)
response = json.loads(response.choices[0].message.content)
return response
```
## Lancer l’évaluation
Une fois les deux évaluateurs définis, vous pouvez maintenant lancer l’évaluation. Définissez un appel d’évaluation qui parcourt automatiquement le `dataset` transmis et enregistre les résultats dans l’interface Weave.
Le code suivant lance l’évaluation et applique les deux évaluateurs à chaque sortie du pipeline NER. Les résultats sont visibles dans l’onglet **Evals** de l’interface Weave.
```python lines theme={null}
evaluation = weave.Evaluation(
dataset=dataset,
scorers=[
check_for_missing_fields_with_llm,
check_for_missing_fields_programatically,
],
name="Evaluate_4.1_NER",
)
print(await evaluation.evaluate(named_entity_recognation))
```
Lorsque le code précédent s’exécute, un lien vers le tableau d'Évaluation dans l’interface Weave est généré. Suivez ce lien pour afficher les résultats et comparer différentes itérations du pipeline sur les modèles, prompts et jeux de données de votre choix. L’interface Weave crée automatiquement une visualisation comme la suivante pour votre équipe.