### Méthode 2 : Masquer à l’aide de Microsoft Presidio
La méthode suivante consiste à supprimer entièrement les données PII à l’aide de [Microsoft Presidio](https://microsoft.github.io/presidio/). Presidio masque les données PII et les remplace par un espace réservé représentant le type de PII. Par exemple, Presidio remplace `Alex` dans `"My name is Alex"` par `
### Méthode 3 : anonymiser par remplacement à l’aide de Faker et Presidio
Au lieu de masquer le texte, vous pouvez l’anonymiser en utilisant MS Presidio pour remplacer des PII, comme des noms et des numéros de téléphone, par des données factices générées par la bibliothèque Python [Faker](https://faker.readthedocs.io/en/master/). Par exemple, supposons que vous disposiez des données suivantes :
`"My name is Raphael and I like to fish. My phone number is 212-555-5555"`
Après traitement des données par Presidio et Faker, le résultat peut ressembler à ceci :
`"My name is Katherine Dixon and I like to fish. My phone number is 667.431.7379"`
Pour utiliser Presidio et Faker ensemble, vous devez fournir des références à vos opérateurs personnalisés. Ces opérateurs indiquent à Presidio quelles fonctions de Faker doivent remplacer les PII par des données factices.
```python lines theme={null}
from faker import Faker
from presidio_anonymizer import AnonymizerEngine
from presidio_anonymizer.entities import OperatorConfig
fake = Faker()
# Créer des fonctions faker (noter qu'elles doivent recevoir une valeur)
def fake_name(x):
return fake.name()
def fake_number(x):
return fake.phone_number()
# Créer un opérateur personnalisé pour les entités PERSON et PHONE_NUMBER
operators = {
"PERSON": OperatorConfig("custom", {"lambda": fake_name}),
"PHONE_NUMBER": OperatorConfig("custom", {"lambda": fake_number}),
}
text_to_anonymize = (
"My name is Raphael and I like to fish. My phone number is 212-555-5555"
)
# Résultat de l'analyseur
analyzer_results = analyzer.analyze(
text=text_to_anonymize, entities=["PHONE_NUMBER", "PERSON"], language="en"
)
anonymizer = AnonymizerEngine()
# ne pas oublier de transmettre les opérateurs définis ci-dessus à l'anonymiseur
anonymized_results = anonymizer.anonymize(
text=text_to_anonymize, analyzer_results=analyzer_results, operators=operators
)
print(f"Raw text:\n\t{text_to_anonymize}")
print(f"Anonymized text:\n\t{anonymized_results.text}")
```
Pour regrouper le code dans une seule classe et étendre la liste des entités pour y inclure celles supplémentaires identifiées précédemment, exécutez la commande suivante :
```python lines theme={null}
from typing import ClassVar
from faker import Faker
from presidio_anonymizer import AnonymizerEngine
from presidio_anonymizer.entities import OperatorConfig
# Une classe personnalisée pour générer des données fictives qui étend Faker
class MyFaker(Faker):
# Créer des fonctions faker (notez qu'elles doivent recevoir une valeur)
def fake_address(self):
return fake.address()
def fake_ssn(self):
return fake.ssn()
def fake_name(self):
return fake.name()
def fake_number(self):
return fake.phone_number()
def fake_email(self):
return fake.email()
# Créer des opérateurs personnalisés pour les entités
operators: ClassVar[dict[str, OperatorConfig]] = {
"PERSON": OperatorConfig("custom", {"lambda": fake_name}),
"PHONE_NUMBER": OperatorConfig("custom", {"lambda": fake_number}),
"EMAIL_ADDRESS": OperatorConfig("custom", {"lambda": fake_email}),
"LOCATION": OperatorConfig("custom", {"lambda": fake_address}),
"US_SSN": OperatorConfig("custom", {"lambda": fake_ssn}),
}
def redact_and_anonymize_with_faker(self, text):
anonymizer = AnonymizerEngine()
analyzer_results = analyzer.analyze(
text=text,
entities=["PHONE_NUMBER", "PERSON", "LOCATION", "EMAIL_ADDRESS", "US_SSN"],
language="en",
)
anonymized_results = anonymizer.anonymize(
text=text, analyzer_results=analyzer_results, operators=self.operators
)
return anonymized_results.text
```
Pour tester la fonction, exécutez ce qui suit avec un exemple de texte :
```python lines theme={null}
faker = MyFaker()
text_to_anonymize = (
"My name is Raphael and I like to fish. My phone number is 212-555-5555"
)
anonymized_text = faker.redact_and_anonymize_with_faker(text_to_anonymize)
print(f"Raw text:\n\t{text_to_anonymize}")
print(f"Anonymized text:\n\t{anonymized_text}")
```
### Méthode 4 : Utiliser `autopatch_settings`
Vous pouvez utiliser `autopatch_settings` pour configurer la gestion des PII directement lors de l'initialisation pour une ou plusieurs intégrations LLM prises en charge. W\&B recommande cette approche lorsque vous souhaitez une gestion centralisée des PII sur tous les appels d'une intégration donnée. Les avantages de cette méthode sont les suivants :
1. La logique de gestion des PII est centralisée et définie à l'initialisation, ce qui réduit le besoin de logique personnalisée dispersée.
2. Vous pouvez personnaliser ou désactiver entièrement les flux de travail de traitement des PII pour des intégrations spécifiques.
Pour utiliser `autopatch_settings` afin de configurer la gestion des PII, définissez `postprocess_inputs` ou `postprocess_output` dans `op_settings` pour l'une des intégrations LLM prises en charge.
```python lines theme={null}
def postprocess(inputs: dict) -> dict:
if "SENSITIVE_KEY" in inputs:
inputs["SENSITIVE_KEY"] = "REDACTED"
return inputs
client = weave.init(
...,
autopatch_settings={
"openai": {
"op_settings": {
"postprocess_inputs": postprocess,
"postprocess_output": ...,
}
},
"anthropic": {
"op_settings": {
"postprocess_inputs": ...,
"postprocess_output": ...,
}
}
},
)
```
## Appliquer les méthodes aux appels Weave
Maintenant que vous avez vu chaque méthode de masquage prise isolément, les exemples suivants montrent comment les intégrer à Weave Models et comment prévisualiser les résultats dans Weave Traces.
Créez d'abord un [Weave Model](https://docs.wandb.ai/weave/guides/core-types/models). Un Weave Model est un ensemble d'informations, comme les paramètres de configuration, les poids du modèle et le code qui définit son fonctionnement.
Le modèle inclut une fonction `predict` dans laquelle l'API Anthropic est appelée. Claude Sonnet d'Anthropic effectue une analyse de sentiment tout en assurant le traçage des appels LLM à l'aide de [Traces](https://docs.wandb.ai/weave/quickstart). Claude Sonnet reçoit un bloc de texte et renvoie l'une des classifications de sentiment suivantes : *positive*, *negative* ou *neutral*. Le modèle inclut également des fonctions de post-traitement pour garantir que les données PII sont masquées ou anonymisées avant d'être envoyées au LLM.
Une fois ce code exécuté, vous obtenez des liens vers la page du projet Weave, ainsi que vers la trace spécifique correspondant aux appels LLM que vous avez exécutés. Utilisez ces liens pour vérifier que les fonctions de post-traitement ont masqué ou anonymisé les données d'entrée comme prévu avant qu'elles n'atteignent le LLM.
### Méthode regex
Pour commencer, vous pouvez utiliser des regex pour identifier et masquer les données PII dans le texte original.
```python lines theme={null}
import json
from typing import Any
import anthropic
import weave
# Définir une fonction de post-traitement des entrées qui applique notre masquage par regex pour la prédiction du modèle Weave Op
def postprocess_inputs_regex(inputs: dict[str, Any]) -> dict:
inputs["text_block"] = redact_with_regex(inputs["text_block"])
return inputs
# Modèle Weave / fonction predict
class SentimentAnalysisRegexPiiModel(weave.Model):
model_name: str
system_prompt: str
temperature: int
@weave.op(
postprocess_inputs=postprocess_inputs_regex,
)
async def predict(self, text_block: str) -> dict:
client = anthropic.AsyncAnthropic()
response = await client.messages.create(
max_tokens=1024,
model=self.model_name,
system=self.system_prompt,
messages=[
{"role": "user", "content": [{"type": "text", "text": text_block}]}
],
)
result = response.content[0].text
if result is None:
raise ValueError("No response from model")
parsed = json.loads(result)
return parsed
```
```python lines theme={null}
# créer notre modèle LLM avec un prompt système
model = SentimentAnalysisRegexPiiModel(
name="claude-3-sonnet",
model_name="claude-3-5-sonnet-20240620",
system_prompt='You are a Sentiment Analysis classifier. You will be classifying text based on their sentiment. Your input will be a block of text. You will answer with one the following rating option["positive", "negative", "neutral"]. Your answer should be one word in json format: {classification}. Ensure that it is valid JSON.',
temperature=0,
)
print("Model: ", model)
# pour chaque bloc de texte, anonymiser d'abord puis prédire
for entry in pii_data:
await model.predict(entry["text"])
```
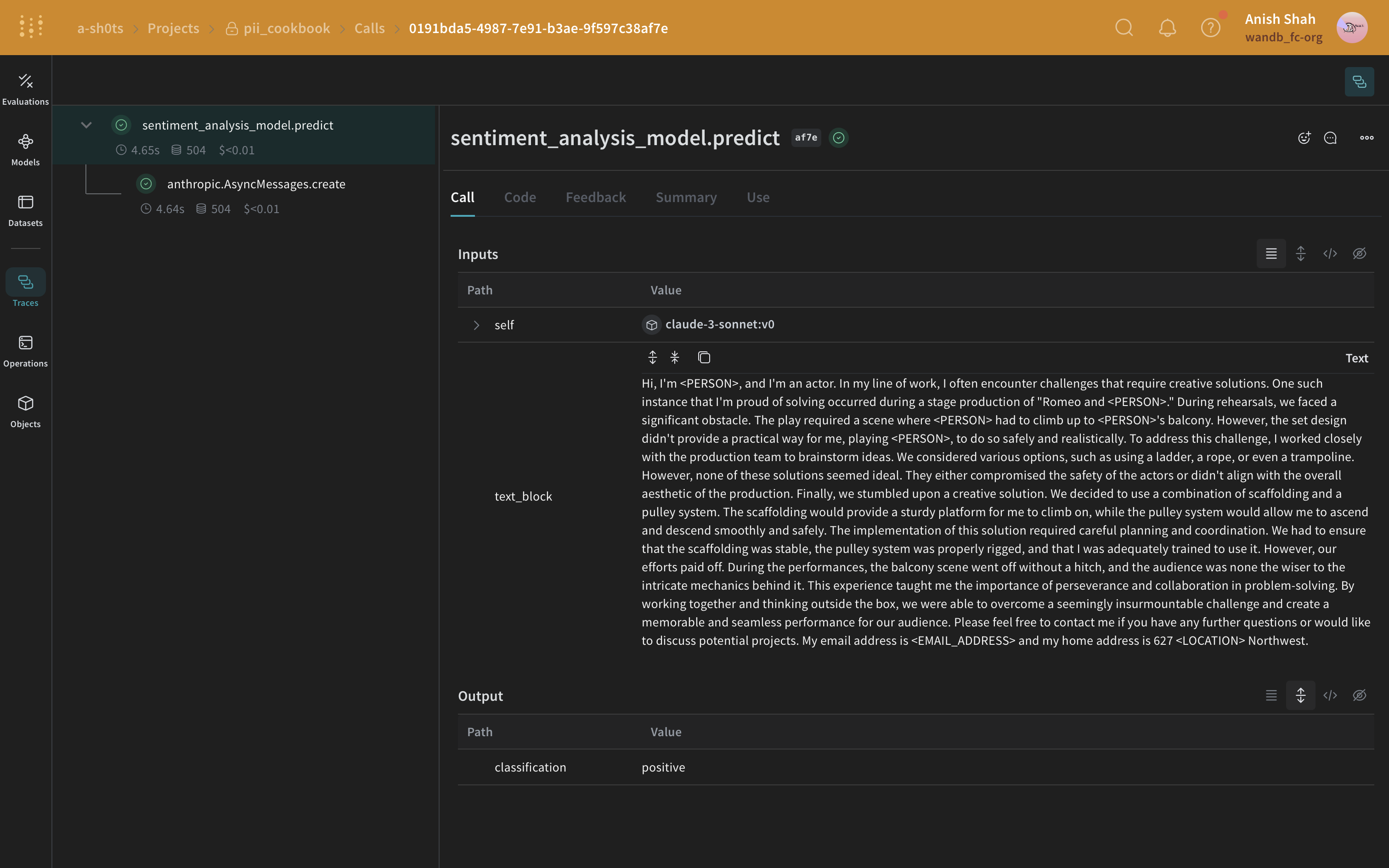
### Méthode de masquage avec Presidio
Ensuite, utilisez Presidio pour identifier et masquer les données PII dans le texte original.
 ```python lines theme={null}
from typing import Any
import weave
# Définir une fonction de post-traitement des entrées qui applique notre masquage Presidio pour le Weave Op de prédiction du modèle
def postprocess_inputs_presidio(inputs: dict[str, Any]) -> dict:
inputs["text_block"] = redact_with_presidio(inputs["text_block"])
return inputs
# Modèle Weave / fonction predict
class SentimentAnalysisPresidioPiiModel(weave.Model):
model_name: str
system_prompt: str
temperature: int
@weave.op(
postprocess_inputs=postprocess_inputs_presidio,
)
async def predict(self, text_block: str) -> dict:
client = anthropic.AsyncAnthropic()
response = await client.messages.create(
max_tokens=1024,
model=self.model_name,
system=self.system_prompt,
messages=[
{"role": "user", "content": [{"type": "text", "text": text_block}]}
],
)
result = response.content[0].text
if result is None:
raise ValueError("No response from model")
parsed = json.loads(result)
return parsed
```
```python lines theme={null}
# créer notre modèle LLM avec un prompt système
model = SentimentAnalysisPresidioPiiModel(
name="claude-3-sonnet",
model_name="claude-3-5-sonnet-20240620",
system_prompt='You are a Sentiment Analysis classifier. You will be classifying text based on their sentiment. Your input will be a block of text. You will answer with one the following rating option["positive", "negative", "neutral"]. Your answer should be one word in json format: {classification}. Ensure that it is valid JSON.',
temperature=0,
)
print("Model: ", model)
# pour chaque bloc de texte, anonymiser d'abord puis prédire
for entry in pii_data:
await model.predict(entry["text"])
```
```python lines theme={null}
from typing import Any
import weave
# Définir une fonction de post-traitement des entrées qui applique notre masquage Presidio pour le Weave Op de prédiction du modèle
def postprocess_inputs_presidio(inputs: dict[str, Any]) -> dict:
inputs["text_block"] = redact_with_presidio(inputs["text_block"])
return inputs
# Modèle Weave / fonction predict
class SentimentAnalysisPresidioPiiModel(weave.Model):
model_name: str
system_prompt: str
temperature: int
@weave.op(
postprocess_inputs=postprocess_inputs_presidio,
)
async def predict(self, text_block: str) -> dict:
client = anthropic.AsyncAnthropic()
response = await client.messages.create(
max_tokens=1024,
model=self.model_name,
system=self.system_prompt,
messages=[
{"role": "user", "content": [{"type": "text", "text": text_block}]}
],
)
result = response.content[0].text
if result is None:
raise ValueError("No response from model")
parsed = json.loads(result)
return parsed
```
```python lines theme={null}
# créer notre modèle LLM avec un prompt système
model = SentimentAnalysisPresidioPiiModel(
name="claude-3-sonnet",
model_name="claude-3-5-sonnet-20240620",
system_prompt='You are a Sentiment Analysis classifier. You will be classifying text based on their sentiment. Your input will be a block of text. You will answer with one the following rating option["positive", "negative", "neutral"]. Your answer should be one word in json format: {classification}. Ensure that it is valid JSON.',
temperature=0,
)
print("Model: ", model)
# pour chaque bloc de texte, anonymiser d'abord puis prédire
for entry in pii_data:
await model.predict(entry["text"])
```
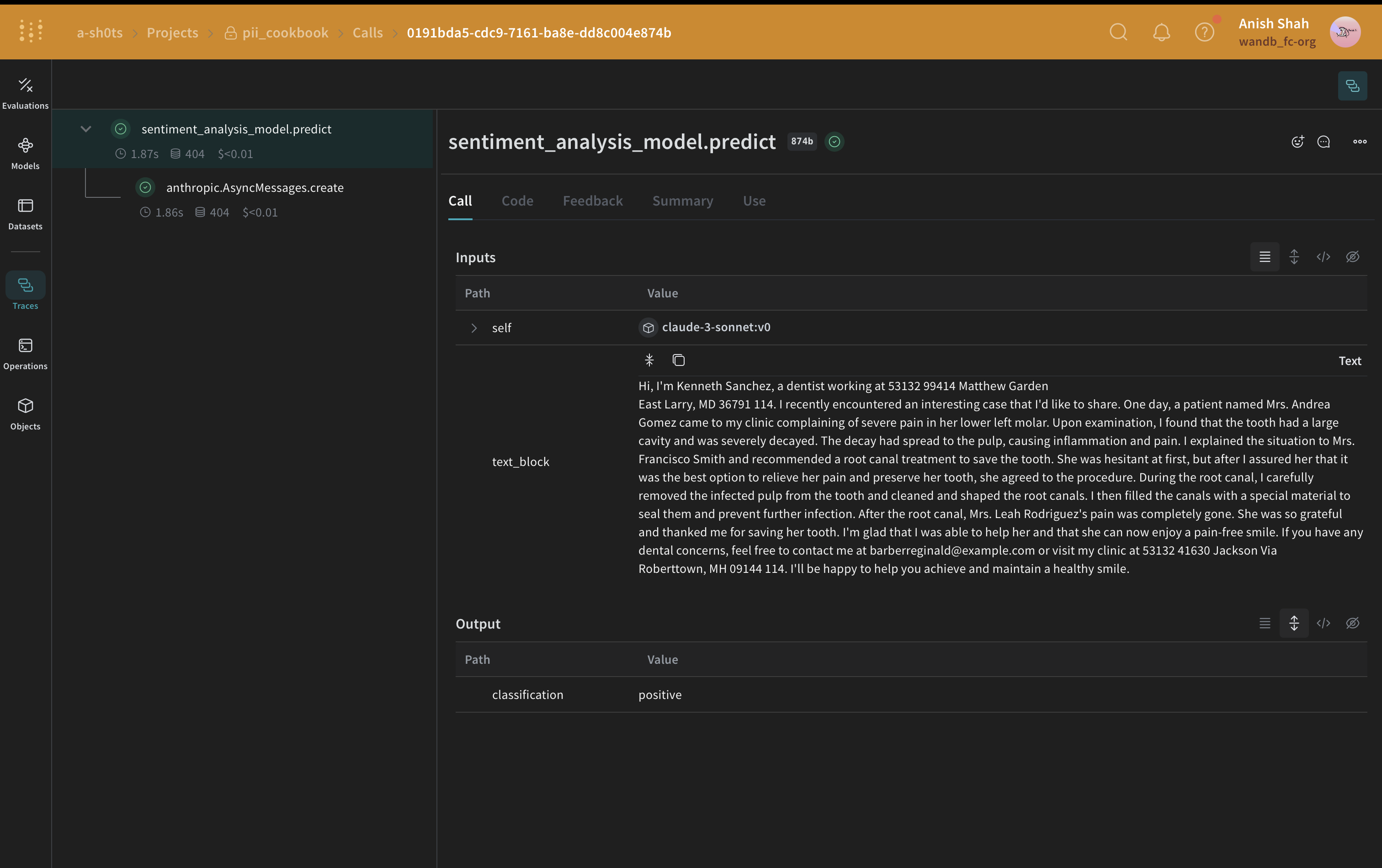
### Méthode de remplacement avec Faker et Presidio
Dans cet exemple, vous utilisez Faker pour générer des données PII de remplacement anonymisées, puis Presidio pour identifier et remplacer les données PII dans le texte d’origine.
 ```python lines theme={null}
from typing import Any
import weave
# Définir une fonction de post-traitement des entrées qui applique l'anonymisation Faker et le masquage Presidio pour la prédiction du modèle Weave Op
faker = MyFaker()
def postprocess_inputs_faker(inputs: dict[str, Any]) -> dict:
inputs["text_block"] = faker.redact_and_anonymize_with_faker(inputs["text_block"])
return inputs
# Modèle Weave / fonction predict
class SentimentAnalysisFakerPiiModel(weave.Model):
model_name: str
system_prompt: str
temperature: int
@weave.op(
postprocess_inputs=postprocess_inputs_faker,
)
async def predict(self, text_block: str) -> dict:
client = anthropic.AsyncAnthropic()
response = await client.messages.create(
max_tokens=1024,
model=self.model_name,
system=self.system_prompt,
messages=[
{"role": "user", "content": [{"type": "text", "text": text_block}]}
],
)
result = response.content[0].text
if result is None:
raise ValueError("No response from model")
parsed = json.loads(result)
return parsed
```
```python lines theme={null}
# créer notre modèle LLM avec un prompt système
model = SentimentAnalysisFakerPiiModel(
name="claude-3-sonnet",
model_name="claude-3-5-sonnet-20240620",
system_prompt='You are a Sentiment Analysis classifier. You will be classifying text based on their sentiment. Your input will be a block of text. You will answer with one the following rating option["positive", "negative", "neutral"]. Your answer should be one word in json format: {classification}. Ensure that it is valid JSON.',
temperature=0,
)
print("Model: ", model)
# pour chaque bloc de texte, anonymiser d'abord puis prédire
for entry in pii_data:
await model.predict(entry["text"])
```
```python lines theme={null}
from typing import Any
import weave
# Définir une fonction de post-traitement des entrées qui applique l'anonymisation Faker et le masquage Presidio pour la prédiction du modèle Weave Op
faker = MyFaker()
def postprocess_inputs_faker(inputs: dict[str, Any]) -> dict:
inputs["text_block"] = faker.redact_and_anonymize_with_faker(inputs["text_block"])
return inputs
# Modèle Weave / fonction predict
class SentimentAnalysisFakerPiiModel(weave.Model):
model_name: str
system_prompt: str
temperature: int
@weave.op(
postprocess_inputs=postprocess_inputs_faker,
)
async def predict(self, text_block: str) -> dict:
client = anthropic.AsyncAnthropic()
response = await client.messages.create(
max_tokens=1024,
model=self.model_name,
system=self.system_prompt,
messages=[
{"role": "user", "content": [{"type": "text", "text": text_block}]}
],
)
result = response.content[0].text
if result is None:
raise ValueError("No response from model")
parsed = json.loads(result)
return parsed
```
```python lines theme={null}
# créer notre modèle LLM avec un prompt système
model = SentimentAnalysisFakerPiiModel(
name="claude-3-sonnet",
model_name="claude-3-5-sonnet-20240620",
system_prompt='You are a Sentiment Analysis classifier. You will be classifying text based on their sentiment. Your input will be a block of text. You will answer with one the following rating option["positive", "negative", "neutral"]. Your answer should be one word in json format: {classification}. Ensure that it is valid JSON.',
temperature=0,
)
print("Model: ", model)
# pour chaque bloc de texte, anonymiser d'abord puis prédire
for entry in pii_data:
await model.predict(entry["text"])
```
### méthode `autopatch_settings`
Dans l'exemple suivant, `postprocess_inputs` pour `anthropic` est défini avec la fonction `postprocess_inputs_regex()` lors de l'initialisation. La fonction `postprocess_inputs_regex` applique la méthode `redact_with_regex` définie dans [Méthode 1 : Filtrage à l'aide d'expressions régulières](#method-1-filter-using-regular-expressions). Par conséquent, `redact_with_regex` est appliquée à toutes les entrées de tous les modèles `anthropic`.
```python lines theme={null}
from typing import Any
import weave
client = weave.init(
...,
autopatch_settings={
"anthropic": {
"op_settings": {
"postprocess_inputs": postprocess_inputs_regex,
}
}
},
)
# Définir une fonction de post-traitement des entrées qui applique notre masquage par regex pour la prédiction du modèle Weave Op
def postprocess_inputs_regex(inputs: dict[str, Any]) -> dict:
inputs["text_block"] = redact_with_regex(inputs["text_block"])
return inputs
# Modèle Weave / fonction predict
class SentimentAnalysisRegexPiiModel(weave.Model):
model_name: str
system_prompt: str
temperature: int
async def predict(self, text_block: str) -> dict:
client = anthropic.AsyncAnthropic()
response = await client.messages.create(
max_tokens=1024,
model=self.model_name,
system=self.system_prompt,
messages=[
{"role": "user", "content": [{"type": "text", "text": text_block}]}
],
)
result = response.content[0].text
if result is None:
raise ValueError("No response from model")
parsed = json.loads(result)
return parsed
```
```python lines theme={null}
# créer notre modèle LLM avec un prompt système
model = SentimentAnalysisRegexPiiModel(
name="claude-3-sonnet",
model_name="claude-3-5-sonnet-20240620",
system_prompt='You are a Sentiment Analysis classifier. You will be classifying text based on their sentiment. Your input will be a block of text. You will answer with one the following rating option["positive", "negative", "neutral"]. Your answer should be one word in json format: {classification}. Ensure that it is valid JSON.',
temperature=0,
)
print("Model: ", model)
# pour chaque bloc de texte, anonymiser d'abord puis prédire
for entry in pii_data:
await model.predict(entry["text"])
```
### Facultatif : Chiffrez vos données
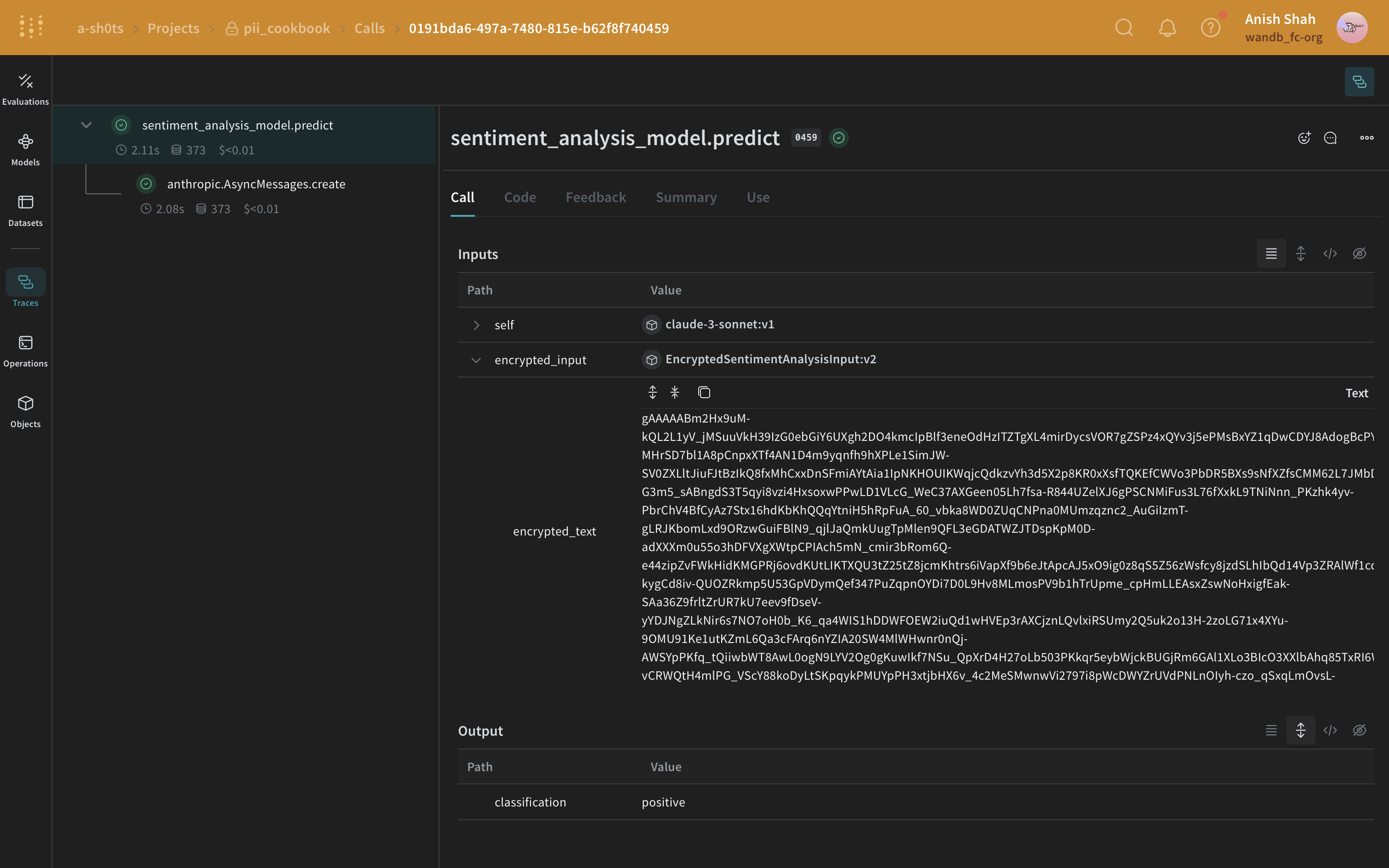 En plus d’anonymiser les PII, vous pouvez ajouter une couche de sécurité supplémentaire en chiffrant vos données avec le chiffrement symétrique [Fernet](https://cryptography.io/en/latest/fernet/) de la bibliothèque `cryptography`. Cette approche garantit que, même si les données anonymisées sont interceptées, elles restent illisibles sans la clé de chiffrement. L’exemple suivant montre comment chiffrer le texte d’entrée avant son enregistrement, puis le déchiffrer dans la méthode `predict` du modèle.
```python lines theme={null}
import os
from cryptography.fernet import Fernet
from pydantic import BaseModel, ValidationInfo, model_validator
def get_fernet_key():
# Vérifier si la clé existe dans les variables d'environnement
key = os.environ.get('FERNET_KEY')
if key is None:
# Si la clé n'existe pas, en générer une nouvelle
key = Fernet.generate_key()
# Enregistrer la clé dans une variable d'environnement
os.environ['FERNET_KEY'] = key.decode()
else:
# Si la clé existe, s'assurer qu'elle est en bytes
key = key.encode()
return key
cipher_suite = Fernet(get_fernet_key())
class EncryptedSentimentAnalysisInput(BaseModel):
encrypted_text: str = None
@model_validator(mode="before")
def encrypt_fields(cls, values):
if "text" in values and values["text"] is not None:
values["encrypted_text"] = cipher_suite.encrypt(values["text"].encode()).decode()
del values["text"]
return values
@property
def text(self):
if self.encrypted_text:
return cipher_suite.decrypt(self.encrypted_text.encode()).decode()
return None
@text.setter
def text(self, value):
self.encrypted_text = cipher_suite.encrypt(str(value).encode()).decode()
@classmethod
def encrypt(cls, text: str):
return cls(text=text)
def decrypt(self):
return self.text
# sentiment_analysis_model modifié pour utiliser le nouveau EncryptedSentimentAnalysisInput
class sentiment_analysis_model(weave.Model):
model_name: str
system_prompt: str
temperature: int
@weave.op()
async def predict(self, encrypted_input: EncryptedSentimentAnalysisInput) -> dict:
client = AsyncAnthropic()
decrypted_text = encrypted_input.decrypt() # On utilise la classe personnalisée pour déchiffrer le texte
response = await client.messages.create(
max_tokens=1024,
model=self.model_name,
system=self.system_prompt,
messages=[
{ "role": "user",
"content":[
{
"type": "text",
"text": decrypted_text
}
]
}
]
)
result = response.content[0].text
if result is None:
raise ValueError("No response from model")
parsed = json.loads(result)
return parsed
model = sentiment_analysis_model(
name="claude-3-sonnet",
model_name="claude-3-5-sonnet-20240620",
system_prompt="You are a Sentiment Analysis classifier. You will be classifying text based on their sentiment. Your input will be a block of text. You will answer with one the following rating option[\"positive\", \"negative\", \"neutral\"]. Your answer should one word in json format dict where the key is classification.",
temperature=0
)
for entry in pii_data:
encrypted_input = EncryptedSentimentAnalysisInput.encrypt(entry["text"])
await model.predict(encrypted_input)
```
En plus d’anonymiser les PII, vous pouvez ajouter une couche de sécurité supplémentaire en chiffrant vos données avec le chiffrement symétrique [Fernet](https://cryptography.io/en/latest/fernet/) de la bibliothèque `cryptography`. Cette approche garantit que, même si les données anonymisées sont interceptées, elles restent illisibles sans la clé de chiffrement. L’exemple suivant montre comment chiffrer le texte d’entrée avant son enregistrement, puis le déchiffrer dans la méthode `predict` du modèle.
```python lines theme={null}
import os
from cryptography.fernet import Fernet
from pydantic import BaseModel, ValidationInfo, model_validator
def get_fernet_key():
# Vérifier si la clé existe dans les variables d'environnement
key = os.environ.get('FERNET_KEY')
if key is None:
# Si la clé n'existe pas, en générer une nouvelle
key = Fernet.generate_key()
# Enregistrer la clé dans une variable d'environnement
os.environ['FERNET_KEY'] = key.decode()
else:
# Si la clé existe, s'assurer qu'elle est en bytes
key = key.encode()
return key
cipher_suite = Fernet(get_fernet_key())
class EncryptedSentimentAnalysisInput(BaseModel):
encrypted_text: str = None
@model_validator(mode="before")
def encrypt_fields(cls, values):
if "text" in values and values["text"] is not None:
values["encrypted_text"] = cipher_suite.encrypt(values["text"].encode()).decode()
del values["text"]
return values
@property
def text(self):
if self.encrypted_text:
return cipher_suite.decrypt(self.encrypted_text.encode()).decode()
return None
@text.setter
def text(self, value):
self.encrypted_text = cipher_suite.encrypt(str(value).encode()).decode()
@classmethod
def encrypt(cls, text: str):
return cls(text=text)
def decrypt(self):
return self.text
# sentiment_analysis_model modifié pour utiliser le nouveau EncryptedSentimentAnalysisInput
class sentiment_analysis_model(weave.Model):
model_name: str
system_prompt: str
temperature: int
@weave.op()
async def predict(self, encrypted_input: EncryptedSentimentAnalysisInput) -> dict:
client = AsyncAnthropic()
decrypted_text = encrypted_input.decrypt() # On utilise la classe personnalisée pour déchiffrer le texte
response = await client.messages.create(
max_tokens=1024,
model=self.model_name,
system=self.system_prompt,
messages=[
{ "role": "user",
"content":[
{
"type": "text",
"text": decrypted_text
}
]
}
]
)
result = response.content[0].text
if result is None:
raise ValueError("No response from model")
parsed = json.loads(result)
return parsed
model = sentiment_analysis_model(
name="claude-3-sonnet",
model_name="claude-3-5-sonnet-20240620",
system_prompt="You are a Sentiment Analysis classifier. You will be classifying text based on their sentiment. Your input will be a block of text. You will answer with one the following rating option[\"positive\", \"negative\", \"neutral\"]. Your answer should one word in json format dict where the key is classification.",
temperature=0
)
for entry in pii_data:
encrypted_input = EncryptedSentimentAnalysisInput.encrypt(entry["text"])
await model.predict(encrypted_input)
```