> ## Documentation Index
> Fetch the complete documentation index at: https://docs.wandb.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Journaliser des données d'évaluation depuis votre code
> Façon flexible et incrémentielle de journaliser des données d'évaluation à partir de code Python et TypeScript
Ce guide vous montre comment utiliser `EvaluationLogger` pour enregistrer des prédictions et des scores depuis votre code Python ou TypeScript existant, afin d'évaluer les performances du modèle dans Weave sans devoir d'abord définir un `Dataset` complet et une suite d'évaluateurs.
Cette approche est utile dans les flux de travail complexes où l'ensemble du jeu de données ou tous les évaluateurs ne sont pas forcément définis à l'avance.
Contrairement à l'objet `Evaluation` standard, qui nécessite un `Dataset` prédéfini et une liste d'objets `Scorer`, `EvaluationLogger` vous permet de journaliser des prédictions individuelles et les scores associés de façon incrémentielle, à mesure qu'ils deviennent disponibles.
**Vous préférez une évaluation plus structurée ?**
Si vous préférez un framework d'évaluation plus prescriptif avec des jeux de données et des évaluateurs prédéfinis, Voir [le framework `Evaluation` standard de Weave](../core-types/evaluations).
`EvaluationLogger` offre de la flexibilité, tandis que le framework standard apporte structure et orientation.
## Flux de travail de base
En suivant ces étapes, vous enregistrez une évaluation complète dans Weave, avec des scores par prédiction et une synthèse agrégée que vous pouvez consulter dans l’interface Weave.
1. *Initialisez le logger :* Créez une instance de `EvaluationLogger`, en fournissant éventuellement des métadonnées sur le `modèle` et le `jeu de données`. Weave utilise les valeurs par défaut si vous les omettez.
Pour capturer l’utilisation des jetons et le coût des appels LLM (par exemple, OpenAI), initialisez `EvaluationLogger` avant toute invocation de LLM.
Si vous appelez d’abord votre LLM, puis journalisez les prédictions ensuite, Weave ne capture pas les données de jeton et de coût.
2. *Journalisez les prédictions :* Appelez `log_prediction()` pour chaque paire d’entrée et de sortie de votre système.
3. *Journalisez les scores :* Utilisez le `ScoreLogger` renvoyé pour appeler `log_score()` pour la prédiction. Plusieurs scores par prédiction sont pris en charge.
4. *Terminez la prédiction :* Appelez toujours `finish()` après avoir journalisé les scores d’une prédiction afin de la finaliser.
5. *Journalisez la synthèse :* Une fois toutes les prédictions traitées, appelez `log_summary()` pour agréger les scores et ajouter des métriques personnalisées facultatives.
Après avoir appelé `finish()` sur une prédiction, il n’est plus possible d’y journaliser d’autres scores.
Pour voir un exemple Python illustrant ce flux de travail, consultez le [Exemple de base](#basic-example). Si la sortie et tous les scores sont disponibles immédiatement, les utilisateurs Python peuvent combiner les étapes 2 à 4 en un appel unique à l’aide de [`log_example()`](#simplified-logging-with-log_example).
## Exemple de base
L’exemple suivant montre comment utiliser `EvaluationLogger` pour journaliser les prédictions et les scores directement dans votre code existant.
La fonction de modèle `user_model` est définie puis appliquée à une liste d’entrées. Pour chaque exemple :
* L’entrée et la sortie sont enregistrées à l’aide de `log_prediction`.
* Un score de correction (`correctness_score`) est enregistré via `log_score`.
* `finish()` finalise l’enregistrement pour cette prédiction.
Enfin, `log_summary` enregistre les métriques agrégées et déclenche la synthèse automatique des scores dans Weave.
```python lines theme={null}
import weave
from openai import OpenAI
from weave import EvaluationLogger
weave.init('your-team/your-project')
# Initialiser EvaluationLogger AVANT d'appeler le modèle pour garantir le suivi des jetons
eval_logger = EvaluationLogger(
model="my_model",
dataset="my_dataset"
)
# Exemple de données d'entrée (peut être n'importe quelle structure de données)
eval_samples = [
{'inputs': {'a': 1, 'b': 2}, 'expected': 3},
{'inputs': {'a': 2, 'b': 3}, 'expected': 5},
{'inputs': {'a': 3, 'b': 4}, 'expected': 7},
]
# Exemple de logique de modèle avec OpenAI
@weave.op
def user_model(a: int, b: int) -> int:
oai = OpenAI()
response = oai.chat.completions.create(
messages=[{"role": "user", "content": f"What is {a}+{b}?"}],
model="gpt-4o-mini"
)
# Utiliser la réponse d'une façon ou d'une autre (ici on retourne simplement a + b pour simplifier)
return a + b
# Itérer sur les exemples, effectuer des prédictions et journaliser
for sample in eval_samples:
inputs = sample["inputs"]
model_output = user_model(**inputs) # Passer les entrées en tant que kwargs
# Journaliser l'entrée et la sortie de la prédiction
pred_logger = eval_logger.log_prediction(
inputs=inputs,
output=model_output
)
# Calculer et journaliser un score pour cette prédiction
expected = sample["expected"]
correctness_score = model_output == expected
pred_logger.log_score(
scorer="correctness", # Nom simple du scorer sous forme de chaîne
score=correctness_score
)
# Finaliser la journalisation pour cette prédiction spécifique
pred_logger.finish()
# Journaliser une synthèse finale pour l'ensemble de l'évaluation.
# Weave agrège automatiquement les scores 'correctness' journalisés ci-dessus.
summary_stats = {"subjective_overall_score": 0.8}
eval_logger.log_summary(summary_stats)
print("Evaluation logging complete. View results in the Weave UI.")
```
Le SDK TypeScript propose deux modèles d’API :
* **API fire-and-forget (recommandée dans la plupart des cas)** : utilisez `logPrediction()` sans `await` pour une journalisation synchrone et non bloquante.
* **API avec attente** : utilisez `logPredictionAsync()` avec `await` lorsque vous devez vous assurer que les opérations sont terminées avant de continuer.
Utilisez fire-and-forget dans les cas suivants :
* **Débit élevé** : traitez plusieurs prédictions en parallèle sans attendre chaque opération de journalisation.
* **Modification minimale du code** : ajoutez la journalisation de l’évaluation sans restructurer votre flux async/await existant.
* **Simplicité** : moins de code passe-partout et une syntaxe plus claire pour la plupart des scénarios d’évaluation.
Le modèle fire-and-forget est sûr, car `logSummary()` attend automatiquement la fin de toutes les opérations en attente avant d’agréger les résultats.
L’exemple suivant évalue les prédictions d’un modèle avec le modèle fire-and-forget. Il configure un journal d’évaluation, exécute un modèle sur trois échantillons de test, puis journalise la prédiction sans utiliser await :
```typescript twoslash lines {36,50} theme={null}
// @noErrors
import weave, {EvaluationLogger} from 'weave';
import OpenAI from 'openai';
await weave.init('your-team/your-project');
// Initialiser EvaluationLogger AVANT d'appeler le modèle pour garantir le suivi des jetons
const evalLogger = new EvaluationLogger({
name: 'my-eval',
model: 'my_model',
dataset: 'my_dataset'
});
// Exemples de données d'entrée
const evalSamples = [
{inputs: {a: 1, b: 2}, expected: 3},
{inputs: {a: 2, b: 3}, expected: 5},
{inputs: {a: 3, b: 4}, expected: 7},
];
// Exemple de logique de modèle avec OpenAI
const userModel = weave.op(async function userModel(a: number, b: number): Promise {
const oai = new OpenAI();
const response = await oai.chat.completions.create({
messages: [{role: 'user', content: `What is ${a}+${b}?`}],
model: 'gpt-4o-mini'
});
return a + b;
});
// Itérer sur les exemples, effectuer des prédictions et journaliser avec le modèle fire-and-forget
for (const sample of evalSamples) {
const {inputs} = sample;
const modelOutput = await userModel(inputs.a, inputs.b);
// Fire-and-forget : aucun await nécessaire pour logPrediction
const scoreLogger = evalLogger.logPrediction(inputs, modelOutput);
// Calculer et journaliser un score pour cette prédiction
const correctnessScore = modelOutput === sample.expected;
// Fire-and-forget : aucun await nécessaire pour logScore
scoreLogger.logScore('correctness', correctnessScore);
// Fire-and-forget : aucun await nécessaire pour finish
scoreLogger.finish();
}
// logSummary attend en interne la fin de toutes les opérations en attente
const summaryStats = {subjective_overall_score: 0.8};
await evalLogger.logSummary(summaryStats);
console.log('Evaluation logging complete. View results in the Weave UI.');
```
Utilisez l’API awaitable lorsque vous devez vous assurer que chaque opération est terminée avant de continuer, par exemple pour la gestion des erreurs ou des dépendances séquentielles.
Dans l’exemple suivant, au lieu d’appeler `logPrediction()` sans `await`, on utilise `logPredictionAsync()` avec `await` pour s’assurer que chaque opération est terminée avant de passer à la suivante :
```typescript twoslash lines theme={null}
// @noErrors
// Utiliser logPredictionAsync à la place de logPrediction
const scoreLogger = await evalLogger.logPredictionAsync(inputs, modelOutput);
// Attendre chaque opération
await scoreLogger.logScore('correctness', correctnessScore);
await scoreLogger.finish();
```
## Journalisation simplifiée avec `log_example()`
Utilisez `log_example()` pour journaliser des entrées, une sortie et des scores en un seul appel. Cette méthode pratique combine `log_prediction()`, `log_score()` et `finish()` en une seule étape. Elle est utile lorsque vous disposez déjà des entrées, des sorties du modèle et des scores à journaliser, par exemple lors d'évaluations par lot ou hors ligne.
```python lines theme={null}
import weave
from weave import EvaluationLogger
weave.init('your-team-name/your-project-name')
eval_logger = EvaluationLogger(
model="my_model",
dataset="my_dataset"
)
eval_samples = [
{'inputs': {'a': 1, 'b': 2}, 'expected': 3},
{'inputs': {'a': 2, 'b': 3}, 'expected': 5},
{'inputs': {'a': 3, 'b': 4}, 'expected': 7},
]
for sample in eval_samples:
inputs = sample['inputs']
output = inputs['a'] + inputs['b']
eval_logger.log_example(
inputs=inputs,
output=output,
scores={"correctness": output == sample['expected']}
)
eval_logger.log_summary({"avg_score": 1.0})
```
L’appel précédent à `log_example()` équivaut à :
```python theme={null}
pred = eval_logger.log_prediction(inputs=inputs, output=output)
pred.log_score(scorer="correctness", score=output == sample['expected'])
pred.finish()
```
`log_example()` n’est pas disponible pour le SDK TypeScript de Weave. Les utilisateurs de TypeScript doivent utiliser l’approche `logPrediction()` et `logScore()` présentée dans l’[exemple de base](#basic-example).
## Utilisation avancée
`EvaluationLogger` offre des modes d’utilisation flexibles au-delà du flux de travail de base pour répondre à des scénarios d’évaluation plus complexes. Les sections suivantes décrivent des techniques avancées, notamment comment utiliser des gestionnaires de contexte pour la gestion automatique des ressources, séparer l’exécution du modèle de la journalisation, utiliser des données de médias enrichis et comparer côte à côte plusieurs évaluations de modèles.
### Utiliser des gestionnaires de contexte
`EvaluationLogger` prend en charge les gestionnaires de contexte (instructions `with`) pour les prédictions comme pour les scores. Cela permet d'obtenir un code plus propre, un nettoyage automatique des ressources et un meilleur suivi des opérations imbriquées, comme les appels à un juge LLM.
L'utilisation des instructions `with` dans ce contexte offre les avantages suivants :
* Appels automatiques à `finish()` à la sortie du contexte.
* Meilleur suivi des jetons et des coûts pour les appels LLM imbriqués.
* Définition de la sortie après l'exécution du modèle dans le contexte de prédiction.
```python lines {16,24,31,40} theme={null}
import openai
import weave
weave.init("nested-evaluation-example")
oai = openai.OpenAI()
# Initialiser le logger
ev = weave.EvaluationLogger(
model="gpt-4o-mini",
dataset="joke_dataset"
)
user_prompt = "Tell me a joke"
# Utiliser un gestionnaire de contexte pour la prédiction - inutile d'appeler finish()
with ev.log_prediction(inputs={"user_prompt": user_prompt}) as pred:
# Effectuez votre appel au modèle dans ce contexte
result = oai.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": user_prompt}],
)
# Définir la sortie après l'appel au modèle
pred.output = result.choices[0].message.content
# Journaliser des scores simples
pred.log_score("correctness", 1.0)
pred.log_score("ambiguity", 0.3)
# Utiliser un gestionnaire de contexte imbriqué pour les scores qui nécessitent des appels LLM
with pred.log_score("llm_judge") as score:
judge_result = oai.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": "Rate how funny the joke is from 1-5"},
{"role": "user", "content": pred.output},
],
)
# Définir la valeur du score après le calcul
score.value = judge_result.choices[0].message.content
# finish() est automatiquement appelé à la sortie du bloc 'with'
ev.log_summary({"avg_score": 1.0})
```
Cette approche garantit que toutes les opérations imbriquées sont suivies et attribuées à la prédiction parente, ce qui vous fournit des données précises sur l'utilisation des jetons et les coûts dans l'interface Weave.
TypeScript ne dispose pas du modèle d'instruction `with` de Python pour les gestionnaires de contexte. Utilisez plutôt l’approche fire-and-forget avec des appels explicites à `finish()`.
L'exemple suivant journalise une prédiction, ajoute des scores et un score de juge LLM, puis finalise la prédiction avec `finish()` :
```typescript twoslash lines {43} theme={null}
// @noErrors
import weave from 'weave';
import OpenAI from 'openai';
import {EvaluationLogger} from 'weave/evaluationLogger';
await weave.init('your-team/your-project');
const oai = new OpenAI();
// Initialiser le logger
const ev = new EvaluationLogger({
name: 'joke-eval',
model: 'gpt-4o-mini',
dataset: 'joke_dataset',
});
const userPrompt = 'Tell me a joke';
// Obtenir la sortie du modèle
const result = await oai.chat.completions.create({
model: 'gpt-4o-mini',
messages: [{role: 'user', content: userPrompt}],
});
const modelOutput = result.choices[0].message.content;
// Journaliser la prédiction avec la sortie
const pred = ev.logPrediction({user_prompt: userPrompt}, modelOutput);
// Journaliser des scores simples
pred.logScore('correctness', 1.0);
pred.logScore('ambiguity', 0.3);
// Pour les scores de juge LLM, effectuez l'appel et journalisez le résultat
const judgeResult = await oai.chat.completions.create({
model: 'gpt-4o-mini',
messages: [
{role: 'system', content: 'Rate how funny the joke is from 1-5'},
{role: 'user', content: modelOutput || ''},
],
});
pred.logScore('llm_judge', judgeResult.choices[0].message.content);
// Appeler explicitement finish une fois l'évaluation terminée
pred.finish();
await ev.logSummary({avg_score: 1.0});
```
Bien que TypeScript ne dispose pas de nettoyage automatique avec les gestionnaires de contexte, `logSummary()` finalise automatiquement toutes les prédictions inachevées avant d'agréger les résultats. Vous pouvez vous appuyer sur ce comportement si vous préférez ne pas appeler `finish()` explicitement.
### Lier à un jeu de données existant
Lorsque vous passez des jeux de données bruts comme `inputs` à `log_prediction`, Weave réimporte les données à chaque run d’évaluation. Cela stocke des données en double, ce qui peut gaspiller de l’espace si le jeu de données est volumineux ou si de nombreuses évaluations le réutilisent.
Pour éviter cette duplication, publiez votre jeu de données vers Weave avant d’exécuter des évaluations, puis passez les lignes du jeu de données publié comme `inputs`. Weave résout les références aux lignes publiées à l’aide de références internes au lieu de réimporter les données. Cette technique vous offre la même expérience de liaison que le [framework `Evaluation` standard](../core-types/evaluations), où chaque prédiction renvoie à une ligne précise du jeu de données dans l’interface Weave.
L’exemple suivant publie un jeu de données et y crée un lien dans `EvaluationLogger`, avant de le récupérer et de le parcourir comme n’importe quel autre jeu de données.
```python theme={null}
import weave
from weave import EvaluationLogger
weave.init("your-team-name/your-project-name")
# Publier le jeu de données (à faire une seule fois)
dataset = weave.Dataset(
name="my_eval_dataset",
rows=[
{"question": "What is the capitol of France?", "expected": "Paris"},
{"question": "What U.S. state is Seattle in?", "expected": "Washington"},
{"question": "In what country is Mount Fuji located in?", "expected": "Japan"},
],
)
weave.publish(dataset)
# Récupérer le jeu de données publié
dataset = weave.ref("my_eval_dataset").get()
```
```typescript twoslash theme={null}
// @noErrors
import weave, {EvaluationLogger, Dataset} from 'weave';
await weave.init('your-team-name/your-project-name');
// Publier le jeu de données (à faire une seule fois)
const dataset = new Dataset({
name: 'my_eval_dataset',
rows: [
{"question": "What is the capitol of France?", "expected": "Paris"},
{"question": "What U.S. state is Seattle in?", "expected": "Washington"},
{"question": "In what country is Mount Fuji located in?", "expected": "Japan"},
],
});
const datasetRef = await dataset.save();
// Récupérer le jeu de données publié
const published = await datasetRef.get();
```
### Obtenir les sorties avant la journalisation
Vous pouvez d’abord calculer les sorties de votre modèle, puis journaliser séparément les prédictions et les scores. Cela sépare la logique d’évaluation de celle de la journalisation, ce qui peut faciliter les tests et la maintenance du code lorsque différentes parties de votre système gèrent la génération des prédictions et l’attribution des scores.
```python lines theme={null}
# Initialiser EvaluationLogger AVANT d'appeler le modèle afin de garantir le suivi des jetons
ev = EvaluationLogger(
model="example_model",
dataset="example_dataset"
)
# Les sorties du modèle (par ex. des appels OpenAI) doivent être générées après l'initialisation du logger pour le suivi des jetons
outputs = [your_output_generator(**inputs) for inputs in your_dataset]
preds = [ev.log_prediction(inputs, output) for inputs, output in zip(your_dataset, outputs)]
for pred, output in zip(preds, outputs):
pred.log_score(scorer="greater_than_5_scorer", score=output > 5)
pred.log_score(scorer="greater_than_7_scorer", score=output > 7)
pred.finish()
ev.log_summary()
```
L’approche fire-and-forget est particulièrement efficace lorsque vous traitez plusieurs prédictions en parallèle.
L’exemple suivant traite des évaluations par lot en parallèle en créant plusieurs instances simultanées de `EvaluationLogger` :
```typescript twoslash lines theme={null}
// @noErrors
// Initialiser EvaluationLogger AVANT d'appeler le modèle afin de garantir le suivi des jetons
const ev = new EvaluationLogger({
name: 'parallel-eval',
model: 'example_model',
dataset: 'example_dataset'
});
// Les sorties du modèle, comme les appels OpenAI, doivent être générées après l'initialisation du logger pour le suivi des jetons
const outputs = await Promise.all(
yourDataset.map(inputs => yourOutputGenerator(inputs))
);
// Fire-and-forget : traiter toutes les prédictions sans attendre
const preds = yourDataset.map((inputs, i) =>
ev.logPrediction(inputs, outputs[i])
);
preds.forEach((pred, i) => {
const output = outputs[i];
// Fire-and-forget : aucun await nécessaire
pred.logScore('greater_than_5_scorer', output > 5);
pred.logScore('greater_than_7_scorer', output > 7);
pred.finish();
});
// logSummary attend toutes les opérations en attente
await ev.logSummary();
```
Vous pouvez utiliser l’approche fire-and-forget pour traiter autant d’évaluations en parallèle que vos ressources de calcul le permettent.
### Journaliser des médias enrichis
Les entrées, les sorties et les scores peuvent inclure des médias enrichis, comme des images, des vidéos, des fichiers audio ou des tableaux structurés. La journalisation de médias enrichis vous permet d’inspecter le contenu réel à côté des scores dans l’interface Weave, ce qui est utile pour l’analyse qualitative des modèles multimodaux. Passez un dictionnaire ou un objet média aux méthodes `log_prediction` ou `log_score`.
```python lines theme={null}
import io
import wave
import struct
from PIL import Image
import random
from typing import Any
import weave
def generate_random_audio_wave_read(duration=2, sample_rate=44100):
n_samples = duration * sample_rate
amplitude = 32767 # amplitude maximale sur 16 bits
buffer = io.BytesIO()
# Écrire les données wave dans le tampon
with wave.open(buffer, 'wb') as wf:
wf.setnchannels(1)
wf.setsampwidth(2) # 16 bits
wf.setframerate(sample_rate)
for _ in range(n_samples):
sample = random.randint(-amplitude, amplitude)
wf.writeframes(struct.pack(' dict[str, Any]:
return {
"result": random.randint(0, 10),
"image": image,
"audio": audio,
}
ev = EvaluationLogger(model="example_model", dataset="example_dataset")
for inputs in rich_media_dataset:
output = your_output_generator(**inputs)
pred = ev.log_prediction(inputs, output)
pred.log_score(scorer="greater_than_5_scorer", score=output["result"] > 5)
pred.log_score(scorer="greater_than_7_scorer", score=output["result"] > 7)
ev.log_summary()
```
Le SDK TypeScript prend en charge la journalisation d’images et de données audio à l’aide des fonctions `weaveImage` et `weaveAudio`. L’exemple suivant charge des fichiers image et audio, les traite avec un modèle, puis journalise les résultats avec leurs scores.
```typescript twoslash lines theme={null}
// @noErrors
import weave, {EvaluationLogger} from 'weave';
import * as fs from 'fs';
await weave.init('your-team/your-project');
// Charger des images et des fichiers audio depuis des fichiers
const richMediaDataset = [
{
image: weave.weaveImage({data: fs.readFileSync('sample1.png')}),
audio: weave.weaveAudio({data: fs.readFileSync('sample1.wav')}),
},
{
image: weave.weaveImage({data: fs.readFileSync('sample2.png')}),
audio: weave.weaveAudio({data: fs.readFileSync('sample2.wav')}),
},
];
// Modèle qui traite les médias et renvoie les résultats
const yourOutputGenerator = weave.op(
async (inputs: {image: any; audio: any}) => {
const result = Math.floor(Math.random() * 10);
return {
result,
image: inputs.image,
audio: inputs.audio,
};
},
{name: 'yourOutputGenerator'}
);
const ev = new EvaluationLogger({
name: 'rich-media-eval',
model: 'example_model',
dataset: 'example_dataset',
});
for (const inputs of richMediaDataset) {
const output = await yourOutputGenerator(inputs);
// Journaliser la prédiction avec des médias enrichis dans les entrées comme dans les sorties
const pred = ev.logPrediction(inputs, output);
pred.logScore('greater_than_5_scorer', output.result > 5);
pred.logScore('greater_than_7_scorer', output.result > 7);
pred.finish();
}
await ev.logSummary();
```
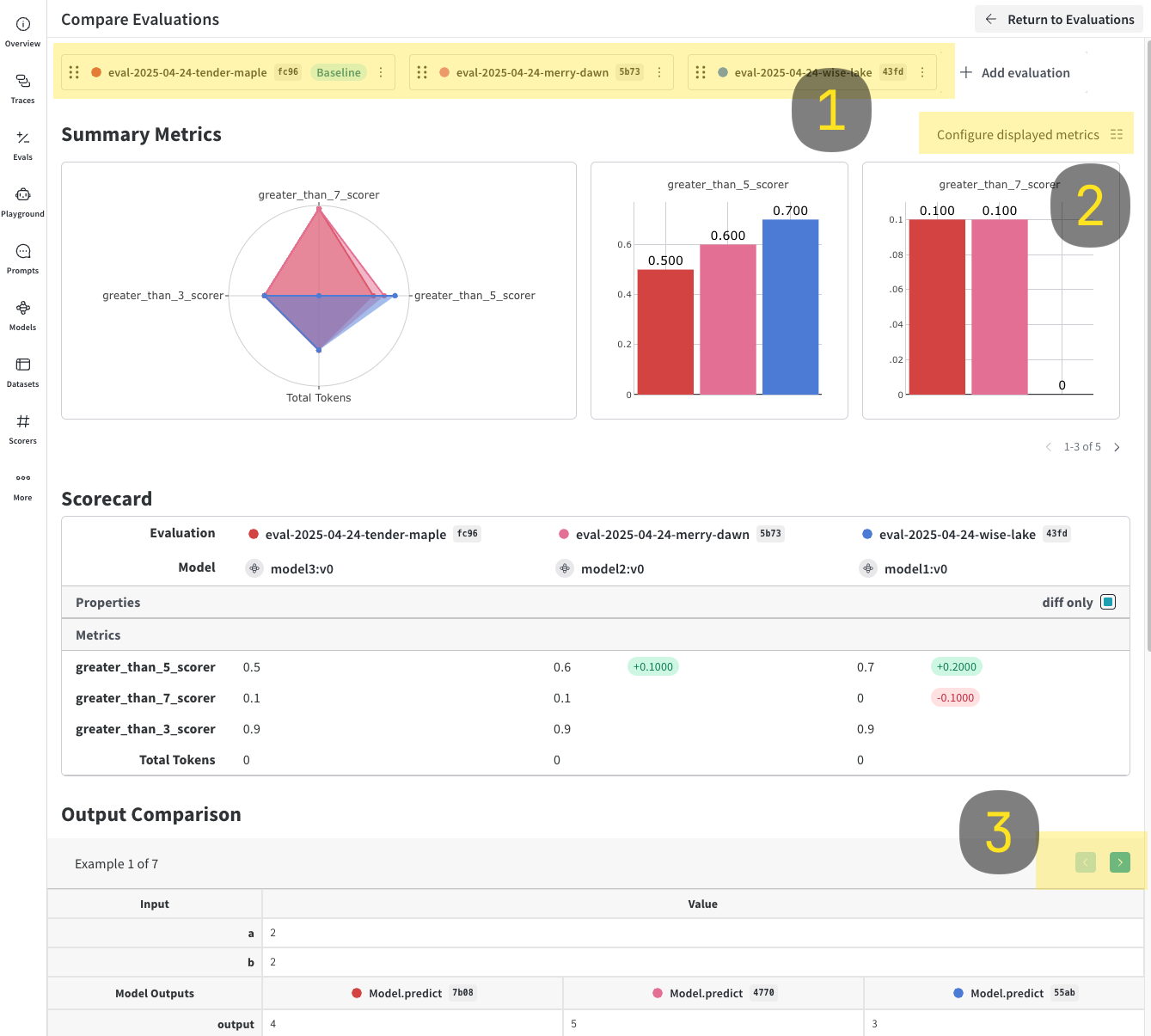
### Journaliser et comparer plusieurs évaluations
Avec `EvaluationLogger`, vous pouvez journaliser et comparer plusieurs évaluations côte à côte dans l’interface Weave. Cela est utile pour évaluer les performances de différents modèles sur le même jeu de données.
1. Exécutez l’exemple de code suivant.
2. Dans l’interface Weave, accédez à l’onglet `Evals`.
3. Sélectionnez les evals que vous souhaitez comparer.
4. Cliquez sur le bouton **Compare**. Dans la vue de comparaison, vous pouvez :
* Choisir quelles evals ajouter ou supprimer.
* Choisir quelles métriques afficher ou masquer.
* Parcourir des exemples précis pour voir comment différents modèles se sont comportés pour la même entrée dans un jeu de données donné.
Pour plus d’informations sur les comparaisons, voir [Comparisons](../tools/comparison).
```python lines theme={null}
import weave
models = [
"model1",
"model2",
{"name": "model3", "metadata": {"coolness": 9001}}
]
for model in models:
# EvalLogger doit être initialisé avant les appels de modèle pour capturer les jetons
ev = EvaluationLogger(
name="comparison-eval",
model=model,
dataset="example_dataset",
scorers=["greater_than_3_scorer", "greater_than_5_scorer", "greater_than_7_scorer"],
eval_attributes={"experiment_id": "exp_123"}
)
for inputs in your_dataset:
output = your_output_generator(**inputs)
pred = ev.log_prediction(inputs=inputs, output=output)
pred.log_score(scorer="greater_than_3_scorer", score=output > 3)
pred.log_score(scorer="greater_than_5_scorer", score=output > 5)
pred.log_score(scorer="greater_than_7_scorer", score=output > 7)
pred.finish()
ev.log_summary()
```
```typescript twoslash lines theme={null}
// @noErrors
import weave from 'weave';
import {EvaluationLogger} from 'weave/evaluationLogger';
import {WeaveObject} from 'weave/weaveObject';
await weave.init('your-team/your-project');
const models = [
'model1',
'model2',
new WeaveObject({name: 'model3', metadata: {coolness: 9001}})
];
for (const model of models) {
// EvalLogger doit être initialisé avant les appels de modèle pour capturer les jetons
const ev = new EvaluationLogger({
name: 'comparison-eval',
model: model,
dataset: 'example_dataset',
description: 'Évaluation de comparaison de modèles',
scorers: ['greater_than_3_scorer', 'greater_than_5_scorer', 'greater_than_7_scorer'],
attributes: {experiment_id: 'exp_123'}
});
for (const inputs of yourDataset) {
const output = await yourOutputGenerator(inputs);
// Approche fire-and-forget pour une journalisation simple et efficace
const pred = ev.logPrediction(inputs, output);
pred.logScore('greater_than_3_scorer', output > 3);
pred.logScore('greater_than_5_scorer', output > 5);
pred.logScore('greater_than_7_scorer', output > 7);
pred.finish();
}
await ev.logSummary();
}
```
## Conseils d’utilisation
Les conseils suivants vous aident à tirer le meilleur parti de `EvaluationLogger` :
* Appelez `finish()` rapidement après chaque prédiction.
* Utilisez `log_summary` pour enregistrer des métriques qui ne sont pas liées à une prédiction individuelle (par exemple, la latence globale).
* La journalisation des médias enrichis est utile pour l’analyse qualitative.
* **Comportement de fin automatique** : Bien que nous recommandions d’appeler explicitement `finish()` pour chaque prédiction par souci de clarté, `logSummary()` termine automatiquement toutes les prédictions non terminées. En revanche, une fois que le script a appelé `finish()`, il ne peut plus enregistrer de scores.
* **Options de configuration** : Utilisez les options de configuration, notamment `name`, `description`, `dataset`, `model`, `scorers` et `attributes`, pour organiser et filtrer vos évaluations dans l’interface Weave.