> ## Documentation Index
> Fetch the complete documentation index at: https://docs.wandb.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# AutoGen
> Utiliser Weave pour suivre et surveiller les agents AutoGen et les systèmes multi-agents
AutoGen est un framework de Microsoft permettant de créer des agents et des applications d'IA. Il simplifie la création de systèmes multi-agents complexes. AutoGen propose des composants pour l'IA conversationnelle (`AgentChat`), les fonctionnalités multi-agents de base (`Core`) et les intégrations avec des services externes (`Extensions`). AutoGen propose également un `Studio` pour le prototypage d'agents sans code. Pour en savoir plus, consultez la [documentation officielle d'AutoGen](https://microsoft.github.io/autogen/stable//index.html).
Ce guide part du principe que vous avez une compréhension de base d'[AutoGen](https://microsoft.github.io/autogen/stable/index.html).
Weave s'intègre à [AutoGen](https://microsoft.github.io/autogen/stable/index.html) pour vous aider à suivre et à visualiser l'exécution de vos applications multi-agents. Lorsque vous initialisez Weave, il suit automatiquement les interactions dans `autogen_agentchat`, `autogen_core` et `autogen_ext`. Ce guide vous explique comment configurer Weave avec AutoGen et présente des exemples détaillés couvrant les clients de modèle, les agents avec outils, les discussions de groupe, la mémoire, les flux de travail RAG, les runtimes d'agents, les flux de travail séquentiels et les exécuteurs de code. À la fin, vous pourrez capturer des traces détaillées de vos applications AutoGen dans Weave afin de déboguer le comportement des agents, de surveiller l'utilisation des LLM et de comprendre comment les agents interagissent dans des flux de travail complexes.
## Prérequis
Avant de commencer, vous devez avoir AutoGen et Weave installés. Vous avez également besoin des SDK des fournisseurs de LLM que vous prévoyez d’utiliser (par exemple, OpenAI ou Anthropic).
```bash theme={null}
pip install autogen_agentchat "autogen_ext[openai,anthropic]" weave
```
Configurez vos clés API sous forme de variables d’environnement afin que les clients de modèles puissent s’authentifier auprès des fournisseurs de LLM utilisés dans les exemples qui suivent :
```python lines theme={null}
import os
os.environ["OPENAI_API_KEY"] = "[YOUR-OPENAI-API-KEY]"
os.environ["ANTHROPIC_API_KEY"] = "[YOUR-ANTHROPIC-API-KEY]"
```
## Configuration de base
Initialisez Weave au début de votre script pour commencer à capturer des traces. Une fois Weave initialisé, il instrumente automatiquement les appels AutoGen dans le reste de votre script.
```python lines {2} theme={null}
import weave
weave.init("autogen-demo")
```
Après avoir exécuté cet extrait, Weave est configuré pour envoyer les traces au projet `autogen-demo` et capture automatiquement toute activité AutoGen ultérieure dans votre script.
## Traces d’un client de modèle
Les sections suivantes décrivent comment Weave trace les appels adressés directement aux clients de modèle dans AutoGen, y compris les appels uniques, les réponses en streaming et les réponses mises en cache.
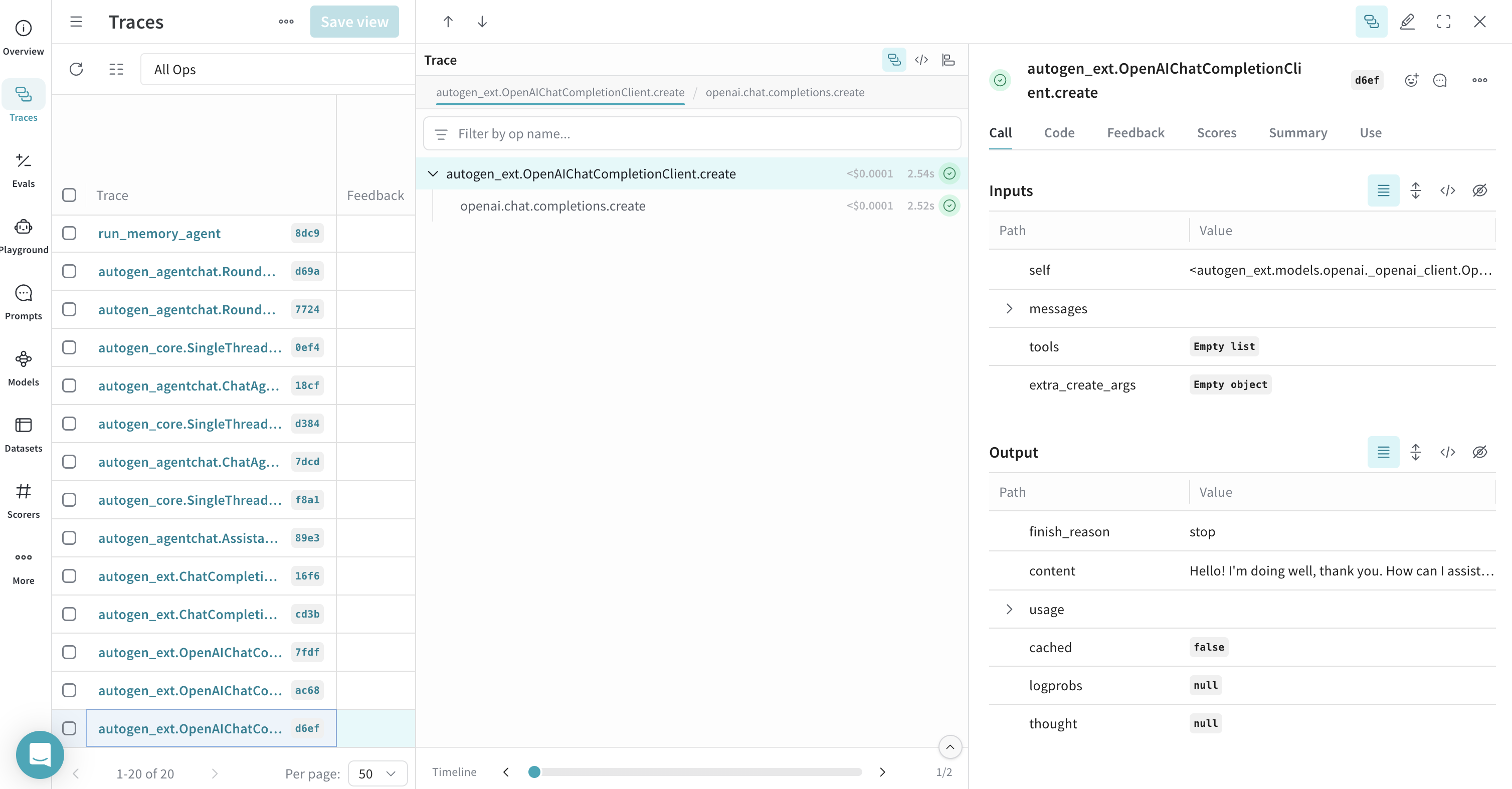
### Traces d’un appel à la méthode `create` du client
Cet exemple montre le tracing d’un appel à un `OpenAIChatCompletionClient`.
```python lines theme={null}
import asyncio
from autogen_core.models import UserMessage
from autogen_ext.models.openai import OpenAIChatCompletionClient
# from autogen_ext.models.anthropic import AnthropicChatCompletionClient
async def simple_client_call(model_name = "gpt-4o"):
model_client = OpenAIChatCompletionClient(
model=model_name,
)
# Vous pouvez également utiliser Anthropic ou d'autres clients de modèle
# model_client = AnthropicChatCompletionClient(
# model="claude-3-haiku-20240307"
# )
response = await model_client.create(
[UserMessage(content="Hello, how are you?", source="user")]
)
print(response)
asyncio.run(simple_client_call())
```
[ ](https://wandb.ai/parambharat/autogen-demo/weave/traces?view=traces_default\&peekPath=%2Fparambharat%2Fautogen-demo%2Fcalls%2F0196ee09-8dcf-7b72-8cdc-7699608cd6ef%3FhideTraceTree%3D0)
](https://wandb.ai/parambharat/autogen-demo/weave/traces?view=traces_default\&peekPath=%2Fparambharat%2Fautogen-demo%2Fcalls%2F0196ee09-8dcf-7b72-8cdc-7699608cd6ef%3FhideTraceTree%3D0)
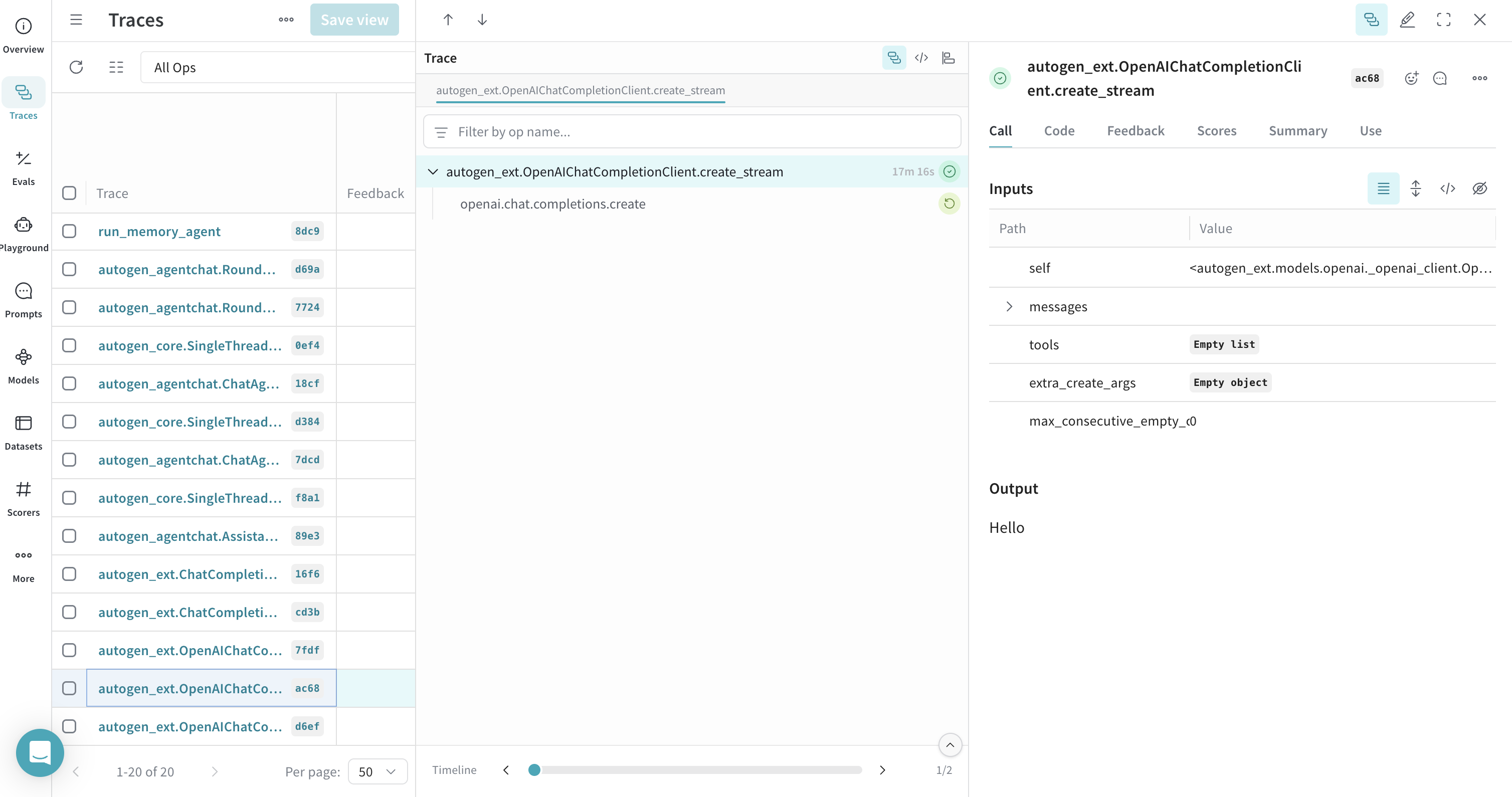
### Traces pour un appel `create` du client avec streaming
Weave prend également en charge le Tracing des réponses en streaming.
```python lines theme={null}
async def simple_client_call_stream(model_name = "gpt-4o"):
openai_model_client = OpenAIChatCompletionClient(model=model_name)
async for item in openai_model_client.create_stream(
[UserMessage(content="Hello, how are you?", source="user")]
):
print(item, flush=True, end="")
asyncio.run(simple_client_call_stream())
```
[ ](https://wandb.ai/parambharat/autogen-demo/weave/traces?view=traces_default\&peekPath=%2Fparambharat%2Fautogen-demo%2Fcalls%2F0196ee0e-24be-7523-b15e-04f87c03ac68%3FhideTraceTree%3D0)
](https://wandb.ai/parambharat/autogen-demo/weave/traces?view=traces_default\&peekPath=%2Fparambharat%2Fautogen-demo%2Fcalls%2F0196ee0e-24be-7523-b15e-04f87c03ac68%3FhideTraceTree%3D0)
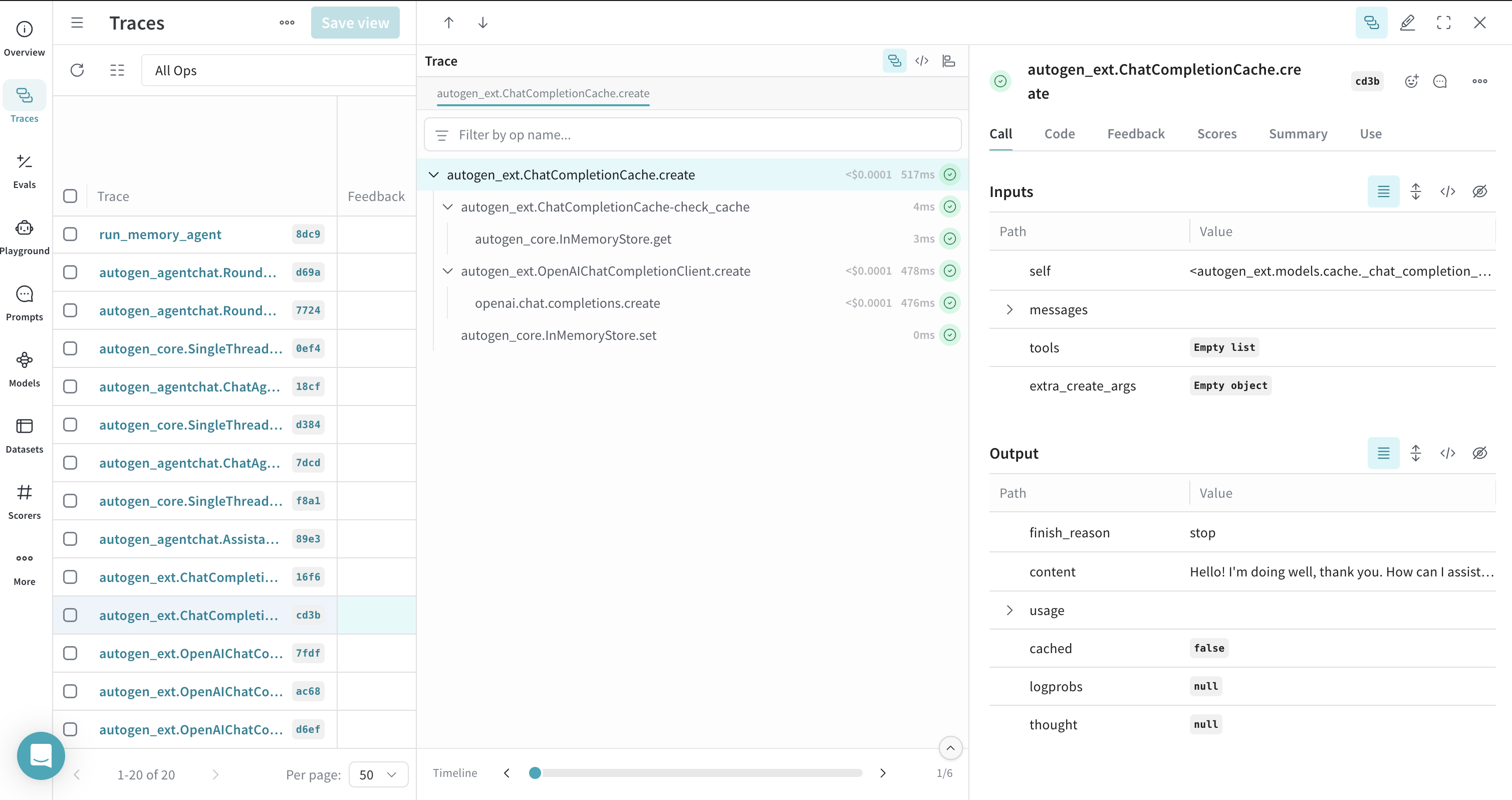
### Traces pour les appels client mis en cache
Vous pouvez utiliser `ChatCompletionCache` d’AutoGen ; Weave trace ces interactions et indique si une réponse provient du cache ou d’un nouvel appel.
```python lines theme={null}
from autogen_ext.models.cache import ChatCompletionCache
async def run_cache_client(model_name = "gpt-4o"):
openai_model_client = OpenAIChatCompletionClient(model=model_name)
cache_client = ChatCompletionCache(openai_model_client,)
response = await cache_client.create(
[UserMessage(content="Hello, how are you?", source="user")]
)
print(response) # Doit afficher la réponse d'OpenAI
response = await cache_client.create(
[UserMessage(content="Hello, how are you?", source="user")]
)
print(response) # Doit afficher la réponse mise en cache
asyncio.run(run_cache_client())
```
[ ](https://wandb.ai/parambharat/autogen-demo/weave/traces?view=traces_default\&peekPath=%2Fparambharat%2Fautogen-demo%2Fcalls%2F0196ee11-fded-72c2-baaa-7c0ba2a7cd3b%3FhideTraceTree%3D0)
](https://wandb.ai/parambharat/autogen-demo/weave/traces?view=traces_default\&peekPath=%2Fparambharat%2Fautogen-demo%2Fcalls%2F0196ee11-fded-72c2-baaa-7c0ba2a7cd3b%3FhideTraceTree%3D0)
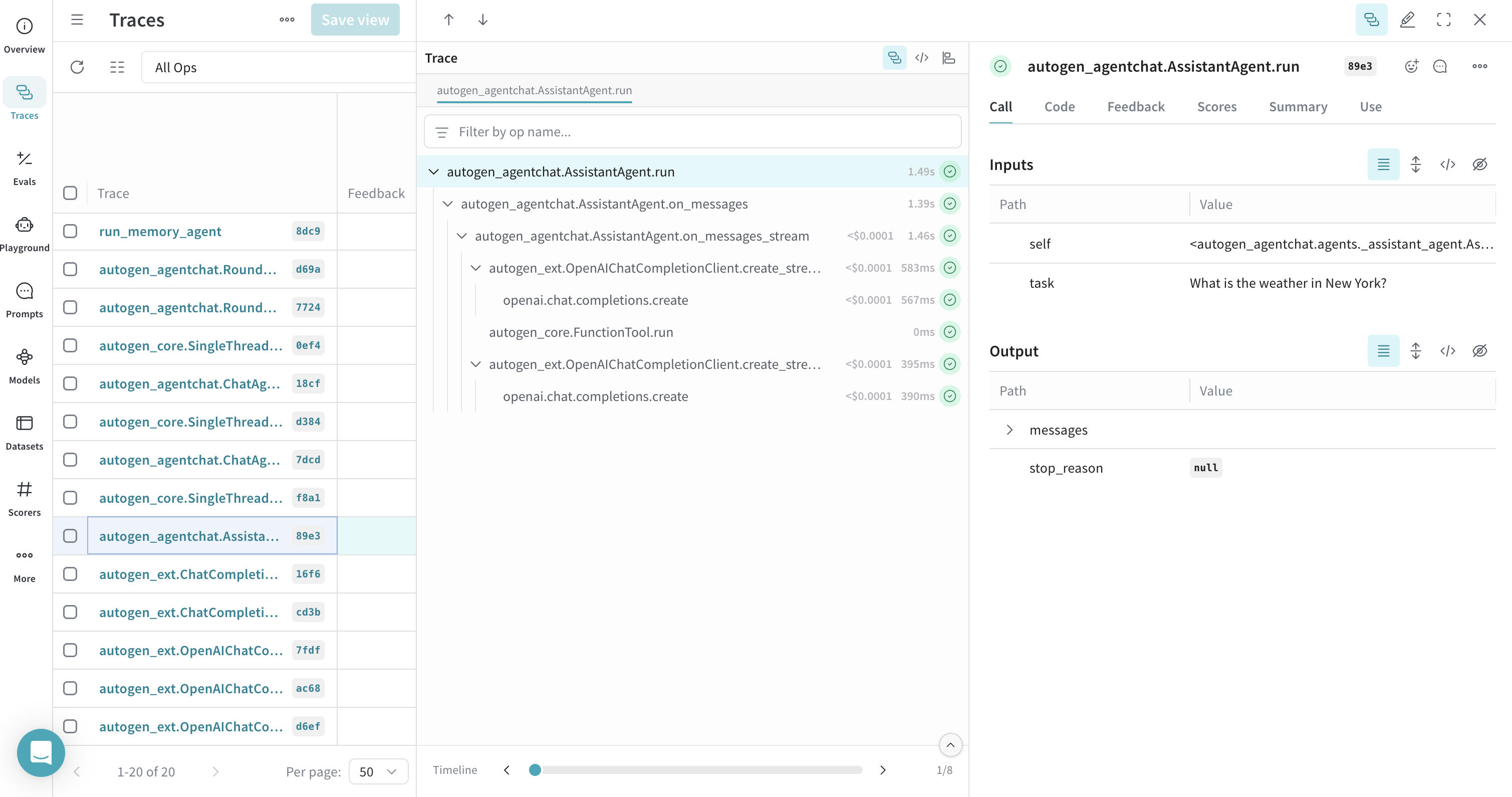
## Traces pour un agent avec des appels d’outils
Cette section montre comment Weave assure le tracing des agents et de leur utilisation des outils, ce qui permet de voir comment les agents sélectionnent et exécutent les outils. L’exemple suivant définit un outil de météo et l’associe à un `AssistantAgent`.
```python lines theme={null}
from autogen_agentchat.agents import AssistantAgent
async def get_weather(city: str) -> str:
return f"The weather in {city} is 73 degrees and Sunny."
async def run_agent_with_tools(model_name = "gpt-4o"):
model_client = OpenAIChatCompletionClient(model=model_name)
agent = AssistantAgent(
name="weather_agent",
model_client=model_client,
tools=[get_weather],
system_message="You are a helpful assistant.",
reflect_on_tool_use=True,
)
# Pour afficher la sortie en streaming dans la console :
# await Console(agent.run_stream(task="What is the weather in New York?"))
res = await agent.run(task="What is the weather in New York?")
print(res)
await model_client.close()
asyncio.run(run_agent_with_tools())
```
[ ](https://wandb.ai/parambharat/autogen-demo/weave/traces?view=traces_default\&peekPath=%2Fparambharat%2Fautogen-demo%2Fcalls%2F0196ee13-e5ca-72a1-b7b6-4b263fad89e3%3FhideTraceTree%3D0)
](https://wandb.ai/parambharat/autogen-demo/weave/traces?view=traces_default\&peekPath=%2Fparambharat%2Fautogen-demo%2Fcalls%2F0196ee13-e5ca-72a1-b7b6-4b263fad89e3%3FhideTraceTree%3D0)
## Traces pour un GroupChat round robin
Weave trace les interactions au sein des discussions de groupe, comme `RoundRobinGroupChat`, afin que vous puissiez suivre le fil de la conversation entre les agents. Pour regrouper tous les tours de conversation des agents sous une trace parente unique afin de faciliter l’inspection, encapsulez la fonction de discussion de groupe avec `@weave.op`. Cette étape est facultative, mais recommandée.
```python lines theme={null}
from autogen_agentchat.conditions import TextMentionTermination
from autogen_agentchat.teams import RoundRobinGroupChat
# nous ajoutons cet op weave ici car nous voulons tracer l'intégralité du group chat
# c'est entièrement facultatif mais fortement recommandé
@weave.op
async def run_round_robin_group_chat(model_name="gpt-4o"):
model_client = OpenAIChatCompletionClient(model=model_name)
primary_agent = AssistantAgent(
"primary",
model_client=model_client,
system_message="You are a helpful AI assistant.",
)
critic_agent = AssistantAgent(
"critic",
model_client=model_client,
system_message="Provide constructive feedback. Respond with 'APPROVE' to when your feedbacks are addressed.",
)
text_termination = TextMentionTermination("APPROVE")
team = RoundRobinGroupChat(
[primary_agent, critic_agent], termination_condition=text_termination
)
await team.reset()
# Pour diffuser la sortie vers la console :
# await Console(team.run_stream(task="Write a short poem about the fall season."))
result = await team.run(task="Write a short poem about the fall season.")
print(result)
await model_client.close()
asyncio.run(run_round_robin_group_chat())
```
[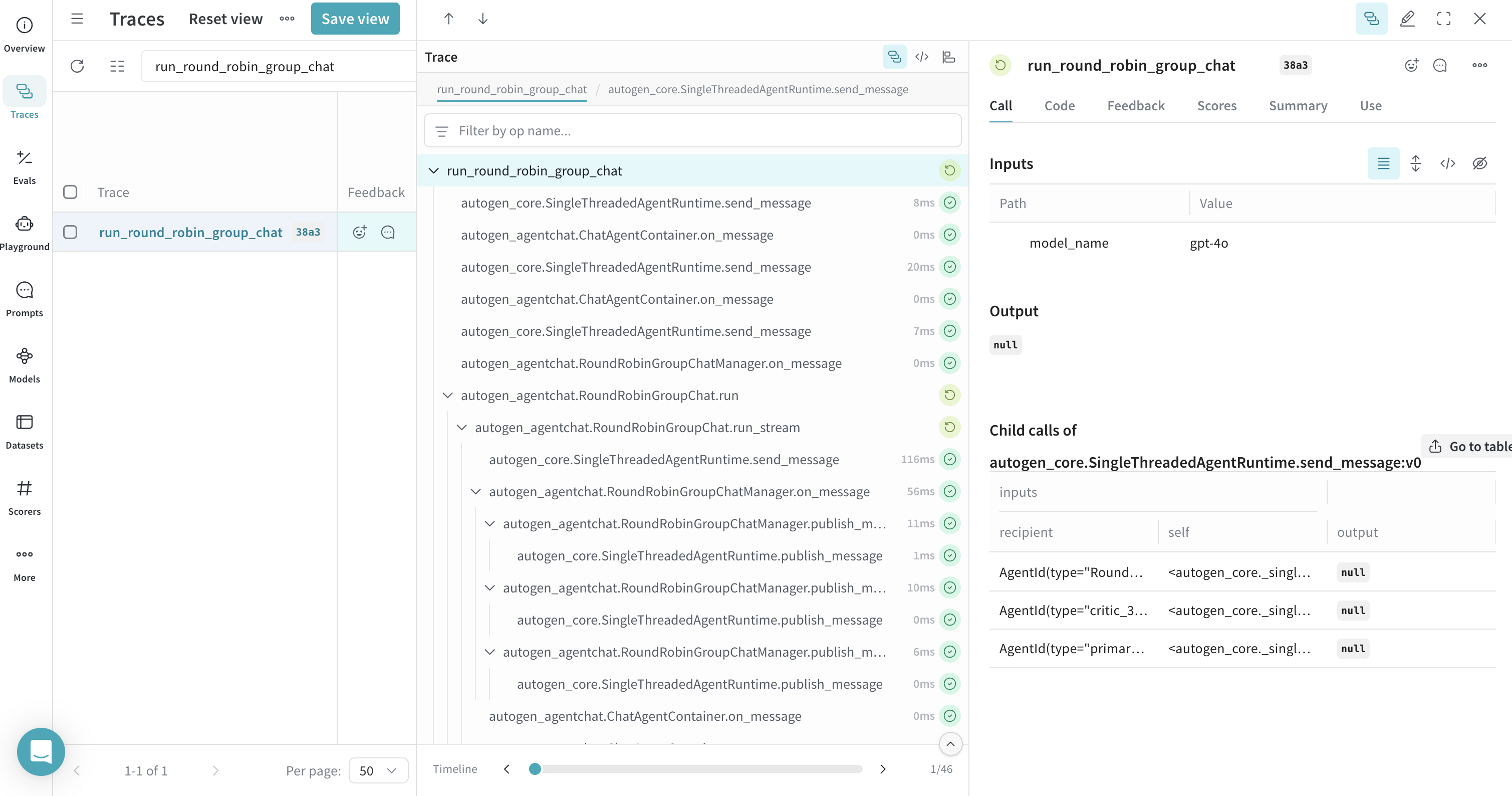 ](https://wandb.ai/parambharat/autogen-demo/weave/traces?filter=%7B%22opVersionRefs%22%3A%5B%22weave%3A%2F%2F%2Fparambharat%2Fautogen-demo%2Fop%2Frun_round_robin_group_chat%3A*%22%5D%7D\&peekPath=%2Fparambharat%2Fautogen-demo%2Fcalls%2F0196f16c-26ce-7b32-8f0c-2366d29038a3%3FdescendentCallId%3D0196f16c-26ce-7b32-8f0c-2366d29038a3%26hideTraceTree%3D0)
](https://wandb.ai/parambharat/autogen-demo/weave/traces?filter=%7B%22opVersionRefs%22%3A%5B%22weave%3A%2F%2F%2Fparambharat%2Fautogen-demo%2Fop%2Frun_round_robin_group_chat%3A*%22%5D%7D\&peekPath=%2Fparambharat%2Fautogen-demo%2Fcalls%2F0196f16c-26ce-7b32-8f0c-2366d29038a3%3FdescendentCallId%3D0196f16c-26ce-7b32-8f0c-2366d29038a3%26hideTraceTree%3D0)
## Traces pour la mémoire
Weave peut tracer les composants de mémoire d’AutoGen. Utilisez `@weave.op()` pour regrouper les opérations de mémoire dans une même trace afin d’en améliorer la lisibilité, de sorte que les appels d’ajout en mémoire ainsi que les appels de récupération en mémoire apparaissent avec l’exécution de l’agent qui les utilise.
```python lines theme={null}
from autogen_core.memory import ListMemory, MemoryContent, MemoryMimeType
# Nous ajoutons cet op weave ici car nous souhaitons tracer
# les appels d'ajout en mémoire ainsi que les appels de récupération en mémoire sous une seule trace
# c'est entièrement facultatif mais fortement recommandé de l'utiliser
@weave.op
async def run_memory_agent(model_name="gpt-4o"):
user_memory = ListMemory()
await user_memory.add(
MemoryContent(
content="The weather should be in metric units",
mime_type=MemoryMimeType.TEXT,
)
)
await user_memory.add(
MemoryContent(
content="Meal recipe must be vegan", mime_type=MemoryMimeType.TEXT
)
)
async def get_weather(city: str, units: str = "imperial") -> str:
if units == "imperial":
return f"The weather in {city} is 73 °F and Sunny."
elif units == "metric":
return f"The weather in {city} is 23 °C and Sunny."
else:
return f"Sorry, I don't know the weather in {city}."
model_client = OpenAIChatCompletionClient(model=model_name)
assistant_agent = AssistantAgent(
name="assistant_agent",
model_client=model_client,
tools=[get_weather],
memory=[user_memory],
)
# Pour diffuser la sortie vers la console :
# stream = assistant_agent.run_stream(task="What is the weather in New York?")
# await Console(stream)
result = await assistant_agent.run(task="What is the weather in New York?")
print(result)
await model_client.close()
asyncio.run(run_memory_agent())
```
[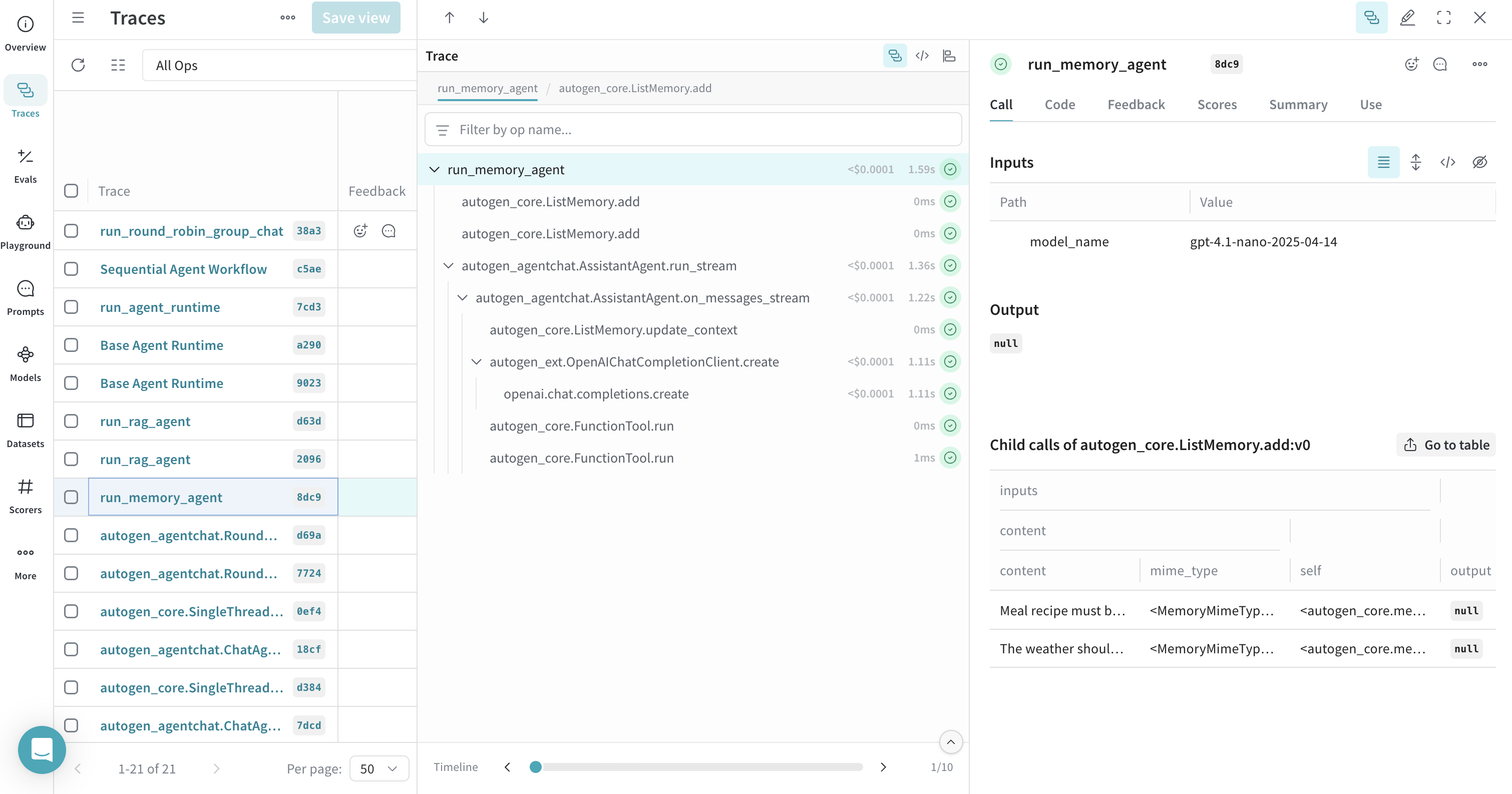 ](https://wandb.ai/parambharat/autogen-demo/weave/traces?view=traces_default\&peekPath=%2Fparambharat%2Fautogen-demo%2Fcalls%2F0196ee18-28b6-7063-90df-77aaedf88dc9%3FhideTraceTree%3D0)
](https://wandb.ai/parambharat/autogen-demo/weave/traces?view=traces_default\&peekPath=%2Fparambharat%2Fautogen-demo%2Fcalls%2F0196ee18-28b6-7063-90df-77aaedf88dc9%3FhideTraceTree%3D0)
## Traces pour les flux de travail RAG
Weave peut tracer les flux de travail de Retrieval Augmented Generation (RAG), y compris l’indexation et la récupération de documents avec des systèmes de mémoire comme `ChromaDBVectorMemory`. Pour visualiser l’ensemble du flux afin que l’indexation, la récupération et l’appel LLM qui en résulte apparaissent ensemble dans une seule trace, ajoutez le décorateur `@weave.op()` au processus RAG.
L’exemple RAG nécessite `chromadb`. Installez-le avec `pip install chromadb`.
```python lines {1,65} theme={null}
# !pip install -q chromadb
# Assurez-vous que chromadb est installé dans votre environnement : `pip install chromadb`
import re
from typing import List
import os
from pathlib import Path
import aiofiles
import aiohttp
from autogen_core.memory import Memory, MemoryContent, MemoryMimeType
from autogen_ext.memory.chromadb import (
ChromaDBVectorMemory,
PersistentChromaDBVectorMemoryConfig,
)
class SimpleDocumentIndexer:
def __init__(self, memory: Memory, chunk_size: int = 1500) -> None:
self.memory = memory
self.chunk_size = chunk_size
async def _fetch_content(self, source: str) -> str:
if source.startswith(("http://", "https://")):
async with aiohttp.ClientSession() as session:
async with session.get(source) as response:
return await response.text()
else:
async with aiofiles.open(source, "r", encoding="utf-8") as f:
return await f.read()
def _strip_html(self, text: str) -> str:
text = re.sub(r"<[^>]*>", " ", text)
text = re.sub(r"\\s+", " ", text)
return text.strip()
def _split_text(self, text: str) -> List[str]:
chunks: list[str] = []
for i in range(0, len(text), self.chunk_size):
chunk = text[i : i + self.chunk_size]
chunks.append(chunk.strip())
return chunks
async def index_documents(self, sources: List[str]) -> int:
total_chunks = 0
for source in sources:
try:
content = await self._fetch_content(source)
if "<" in content and ">" in content:
content = self._strip_html(content)
chunks = self._split_text(content)
for i, chunk in enumerate(chunks):
await self.memory.add(
MemoryContent(
content=chunk,
mime_type=MemoryMimeType.TEXT,
metadata={"source": source, "chunk_index": i},
)
)
total_chunks += len(chunks)
except Exception as e:
print(f"Error indexing {source}: {str(e)}")
return total_chunks
@weave.op
async def run_rag_agent(model_name="gpt-4o"):
rag_memory = ChromaDBVectorMemory(
config=PersistentChromaDBVectorMemoryConfig(
collection_name="autogen_docs",
persistence_path=os.path.join(str(Path.home()), ".chromadb_autogen_weave"),
k=3,
score_threshold=0.4,
)
)
# await rag_memory.clear() # Décommentez pour effacer la mémoire existante si nécessaire
async def index_autogen_docs() -> None:
indexer = SimpleDocumentIndexer(memory=rag_memory)
sources = [
"https://raw.githubusercontent.com/microsoft/autogen/main/README.md",
"https://microsoft.github.io/autogen/dev/user-guide/agentchat-user-guide/tutorial/agents.html",
]
chunks: int = await indexer.index_documents(sources)
print(f"Indexed {chunks} chunks from {len(sources)} AutoGen documents")
# N'indexez que si la collection est vide ou si vous souhaitez réindexer
# À des fins de démonstration, vous pouvez indexer à chaque fois ou vérifier si l'indexation a déjà été effectuée.
# Cet exemple tentera d'indexer à chaque exécution. Envisagez d'ajouter une vérification.
await index_autogen_docs()
model_client = OpenAIChatCompletionClient(model=model_name)
rag_assistant = AssistantAgent(
name="rag_assistant",
model_client=model_client,
memory=[rag_memory],
)
# Pour diffuser la sortie vers la console :
# stream = rag_assistant.run_stream(task="What is AgentChat?")
# await Console(stream)
result = await rag_assistant.run(task="What is AgentChat?")
print(result)
await rag_memory.close()
await model_client.close()
asyncio.run(run_rag_agent())
```
[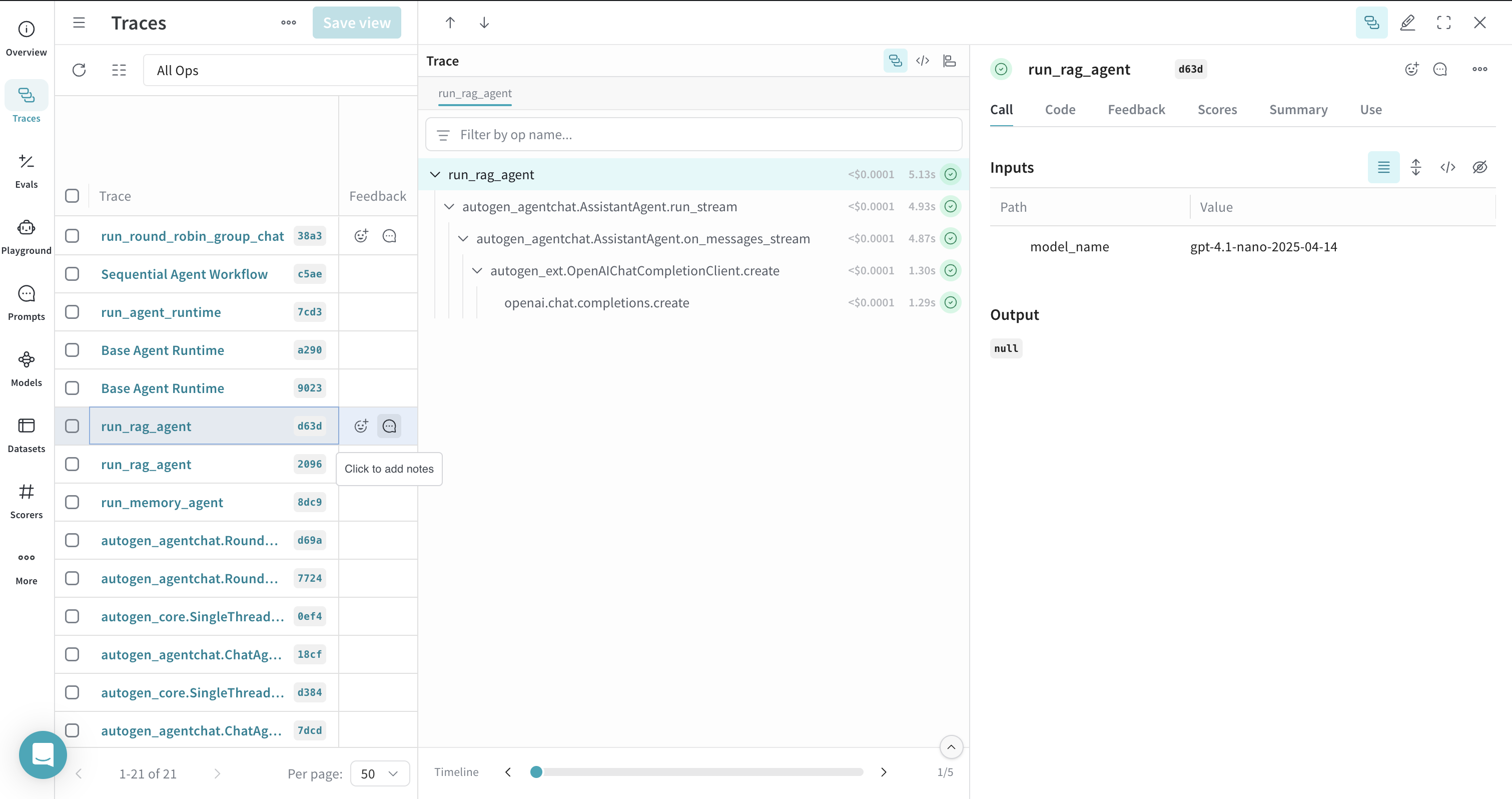 ](https://wandb.ai/parambharat/autogen-demo/weave/traces?view=traces_default\&peekPath=%2Fparambharat%2Fautogen-demo%2Fcalls%2F0196ee1b-bac5-7b80-8be7-6e6ea7d1d63d%3FhideTraceTree%3D0)
](https://wandb.ai/parambharat/autogen-demo/weave/traces?view=traces_default\&peekPath=%2Fparambharat%2Fautogen-demo%2Fcalls%2F0196ee1b-bac5-7b80-8be7-6e6ea7d1d63d%3FhideTraceTree%3D0)
## Traces pour les runtimes d’agent
Weave peut tracer des opérations dans les runtimes d’agent d’AutoGen, comme `SingleThreadedAgentRuntime`. Encapsulez la fonction d’exécution du runtime avec `@weave.op()` pour regrouper les traces liées, afin de voir la séquence complète des gestionnaires de messages qui se déclenchent pendant l’exécution du runtime.
```python lines {50} theme={null}
from dataclasses import dataclass
from typing import Callable
from autogen_core import (
DefaultTopicId,
MessageContext,
RoutedAgent,
default_subscription,
message_handler,
AgentId,
SingleThreadedAgentRuntime
)
@dataclass
class Message:
content: int
@default_subscription
class Modifier(RoutedAgent):
def __init__(self, modify_val: Callable[[int], int]) -> None:
super().__init__("A modifier agent.")
self._modify_val = modify_val
@message_handler
async def handle_message(self, message: Message, ctx: MessageContext) -> None:
val = self._modify_val(message.content)
print(f"{'-'*80}\\nModifier:\\nModified {message.content} to {val}")
await self.publish_message(Message(content=val), DefaultTopicId())
@default_subscription
class Checker(RoutedAgent):
def __init__(self, run_until: Callable[[int], bool]) -> None:
super().__init__("A checker agent.")
self._run_until = run_until
@message_handler
async def handle_message(self, message: Message, ctx: MessageContext) -> None:
if not self._run_until(message.content):
print(f"{'-'*80}\\nChecker:\\n{message.content} passed the check, continue.")
await self.publish_message(
Message(content=message.content), DefaultTopicId()
)
else:
print(f"{'-'*80}\\nChecker:\\n{message.content} failed the check, stopping.")
# nous ajoutons cet op weave ici car nous souhaitons tracer
# l'intégralité de l'appel du runtime de l'agent dans une seule trace
# c'est entièrement facultatif mais fortement recommandé
@weave.op
async def run_agent_runtime() -> None:
runtime = SingleThreadedAgentRuntime()
await Modifier.register(
runtime,
"modifier",
lambda: Modifier(modify_val=lambda x: x - 1),
)
await Checker.register(
runtime,
"checker",
lambda: Checker(run_until=lambda x: x <= 1),
)
runtime.start()
await runtime.send_message(Message(content=3), AgentId("checker", "default"))
await runtime.stop_when_idle()
asyncio.run(run_agent_runtime())
```
[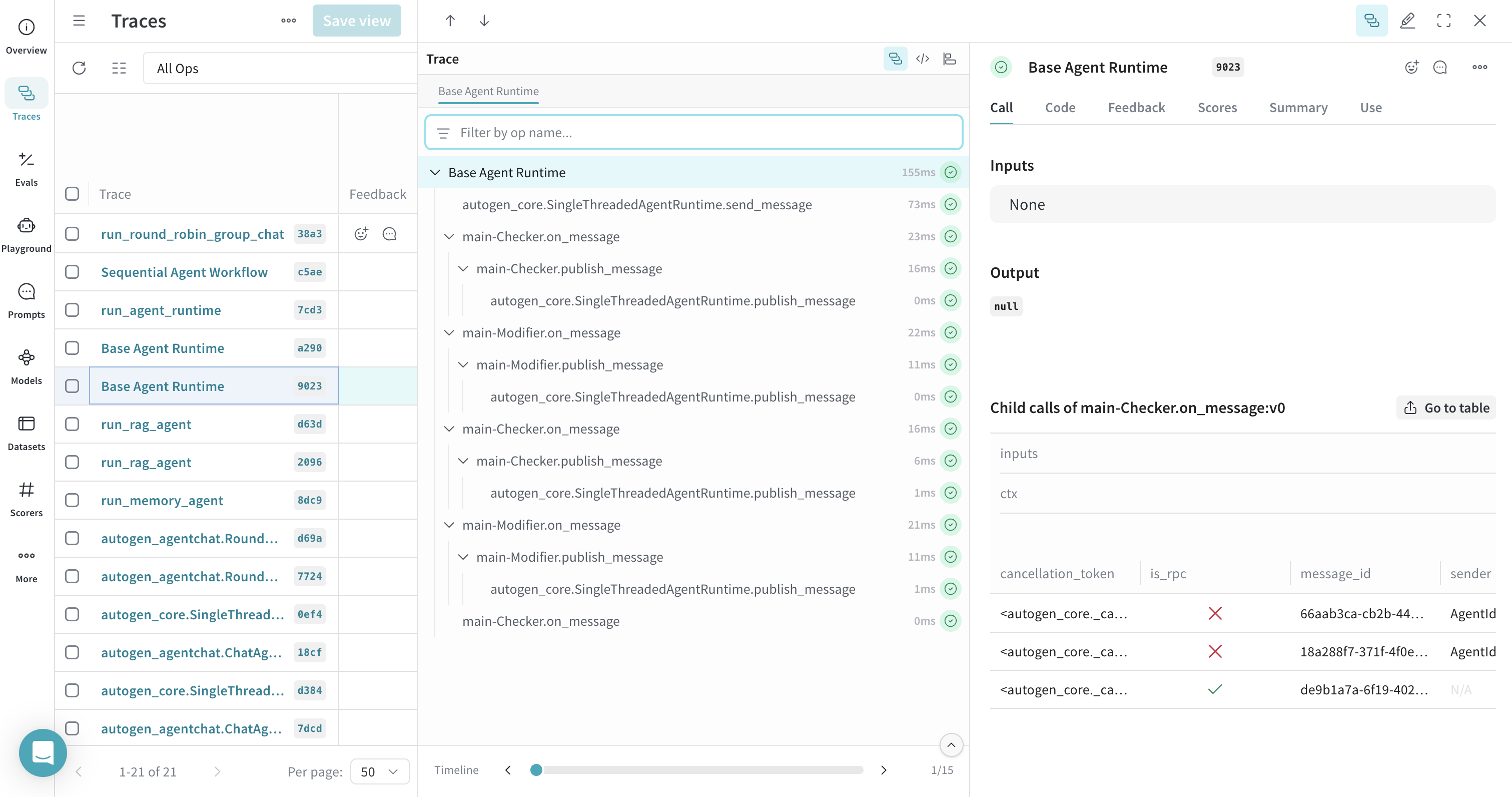 ](https://wandb.ai/parambharat/autogen-demo/weave/traces?view=traces_default\&peekPath=%2Fparambharat%2Fautogen-demo%2Fcalls%2F0196ee1d-6246-7f11-afb1-3a1874f79023%3FhideTraceTree%3D0)
](https://wandb.ai/parambharat/autogen-demo/weave/traces?view=traces_default\&peekPath=%2Fparambharat%2Fautogen-demo%2Fcalls%2F0196ee1d-6246-7f11-afb1-3a1874f79023%3FhideTraceTree%3D0)
## Traces pour les flux de travail séquentiels
Vous pouvez tracer des flux de travail d’agents complexes qui définissent des séquences d’interactions entre agents. Utilisez `@weave.op()` pour fournir une trace de haut niveau de l’ensemble du flux de travail afin que la contribution de chaque agent soit imbriquée sous un appel parent unique. L’exemple suivant enchaîne un extracteur de concepts, un rédacteur, un agent de mise en forme et de relecture, ainsi qu’un agent utilisateur pour produire un texte marketing soigné.
```python lines {108} theme={null}
from autogen_core import TopicId, type_subscription
from autogen_core.models import ChatCompletionClient, SystemMessage, UserMessage
@dataclass
class WorkflowMessage:
content: str
concept_extractor_topic_type = "ConceptExtractorAgent"
writer_topic_type = "WriterAgent"
format_proof_topic_type = "FormatProofAgent"
user_topic_type = "User"
@type_subscription(topic_type=concept_extractor_topic_type)
class ConceptExtractorAgent(RoutedAgent):
def __init__(self, model_client: ChatCompletionClient) -> None:
super().__init__("Un agent extracteur de concepts.")
self._system_message = SystemMessage(
content=(
"You are a marketing analyst. Given a product description, identify:\n"
"- Fonctionnalités clés\n"
"- Public cible\n"
"- Points de vente uniques\n\n"
)
)
self._model_client = model_client
@message_handler
async def handle_user_description(self, message: WorkflowMessage, ctx: MessageContext) -> None:
prompt = f"Description du produit : {message.content}"
llm_result = await self._model_client.create(
messages=[self._system_message, UserMessage(content=prompt, source=self.id.key)],
cancellation_token=ctx.cancellation_token,
)
response = llm_result.content
assert isinstance(response, str)
print(f"{'-'*80}\\n{self.id.type}:\\n{response}")
await self.publish_message(
WorkflowMessage(response), topic_id=TopicId(writer_topic_type, source=self.id.key)
)
@type_subscription(topic_type=writer_topic_type)
class WriterAgent(RoutedAgent):
def __init__(self, model_client: ChatCompletionClient) -> None:
super().__init__("Un agent rédacteur.")
self._system_message = SystemMessage(
content=(
"You are a marketing copywriter. Given a block of text describing features, audience, and USPs, "
"compose a compelling marketing copy (like a newsletter section) that highlights these points. "
"Output should be short (around 150 words), output just the copy as a single text block."
)
)
self._model_client = model_client
@message_handler
async def handle_intermediate_text(self, message: WorkflowMessage, ctx: MessageContext) -> None:
prompt = f"Voici les informations sur le produit :\\n\\n{message.content}"
llm_result = await self._model_client.create(
messages=[self._system_message, UserMessage(content=prompt, source=self.id.key)],
cancellation_token=ctx.cancellation_token,
)
response = llm_result.content
assert isinstance(response, str)
print(f"{'-'*80}\\n{self.id.type}:\\n{response}")
await self.publish_message(
WorkflowMessage(response), topic_id=TopicId(format_proof_topic_type, source=self.id.key)
)
@type_subscription(topic_type=format_proof_topic_type)
class FormatProofAgent(RoutedAgent):
def __init__(self, model_client: ChatCompletionClient) -> None:
super().__init__("Un agent de mise en forme et de relecture.")
self._system_message = SystemMessage(
content=(
"You are an editor. Given the draft copy, correct grammar, improve clarity, ensure consistent tone, "
"give format and make it polished. Output the final improved copy as a single text block."
)
)
self._model_client = model_client
@message_handler
async def handle_intermediate_text(self, message: WorkflowMessage, ctx: MessageContext) -> None:
prompt = f"Brouillon :\\n{message.content}."
llm_result = await self._model_client.create(
messages=[self._system_message, UserMessage(content=prompt, source=self.id.key)],
cancellation_token=ctx.cancellation_token,
)
response = llm_result.content
assert isinstance(response, str)
print(f"{'-'*80}\\n{self.id.type}:\\n{response}")
await self.publish_message(
WorkflowMessage(response), topic_id=TopicId(user_topic_type, source=self.id.key)
)
@type_subscription(topic_type=user_topic_type)
class UserAgent(RoutedAgent):
def __init__(self) -> None:
super().__init__("Un agent utilisateur qui transmet la version finale à l'utilisateur.")
@message_handler
async def handle_final_copy(self, message: WorkflowMessage, ctx: MessageContext) -> None:
print(f"\\n{'-'*80}\\n{self.id.type} a reçu la version finale :\\n{message.content}")
# nous ajoutons cet op Weave ici car nous voulons tracer
# l'intégralité du flux de travail des agents sous une seule trace
# c'est entièrement facultatif, mais fortement recommandé
@weave.op(call_display_name="Sequential Agent Workflow")
async def run_agent_workflow(model_name="gpt-4o"):
model_client = OpenAIChatCompletionClient(model=model_name)
runtime = SingleThreadedAgentRuntime()
await ConceptExtractorAgent.register(runtime, type=concept_extractor_topic_type, factory=lambda: ConceptExtractorAgent(model_client=model_client))
await WriterAgent.register(runtime, type=writer_topic_type, factory=lambda: WriterAgent(model_client=model_client))
await FormatProofAgent.register(runtime, type=format_proof_topic_type, factory=lambda: FormatProofAgent(model_client=model_client))
await UserAgent.register(runtime, type=user_topic_type, factory=lambda: UserAgent())
runtime.start()
await runtime.publish_message(
WorkflowMessage(
content="Une gourde en acier inoxydable écologique qui maintient les boissons froides pendant 24 heures"
),
topic_id=TopicId(concept_extractor_topic_type, source="default"),
)
await runtime.stop_when_idle()
await model_client.close()
asyncio.run(run_agent_workflow())
```
[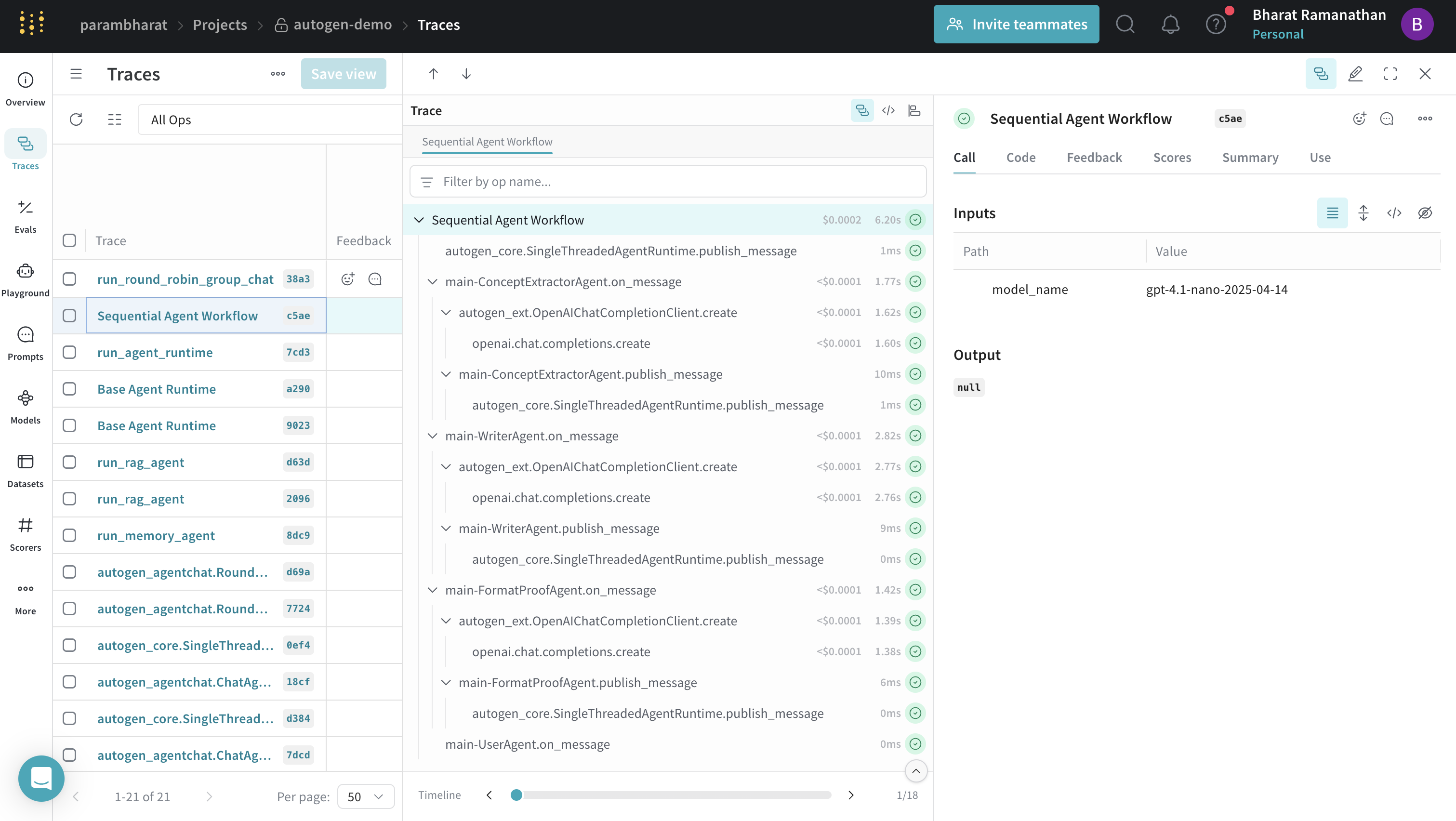 ](https://wandb.ai/parambharat/autogen-demo/weave/traces?view=traces_default\&peekPath=%2Fparambharat%2Fautogen-demo%2Fcalls%2F0196ee1f-dd53-73f2-9119-2a44da92c5ae%3FhideTraceTree%3D0)
](https://wandb.ai/parambharat/autogen-demo/weave/traces?view=traces_default\&peekPath=%2Fparambharat%2Fautogen-demo%2Fcalls%2F0196ee1f-dd53-73f2-9119-2a44da92c5ae%3FhideTraceTree%3D0)
## Traces pour les exécuteurs de code
**Docker requis**
Cet exemple implique l'exécution de code avec Docker et peut ne pas fonctionner dans tous les environnements (par exemple, directement dans Colab). Assurez-vous que Docker est en cours d'exécution en local si vous essayez cet exemple.
Weave trace la génération et l'exécution du code par les agents AutoGen. Vous pouvez inspecter à la fois le code produit par un agent assistant et la sortie renvoyée par un agent exécuteur lorsque ce code est exécuté.
````python lines {69} theme={null}
import tempfile
from autogen_core import DefaultTopicId
from autogen_core.code_executor import CodeBlock, CodeExecutor
from autogen_core.models import (
AssistantMessage,
ChatCompletionClient,
LLMMessage,
SystemMessage,
UserMessage,
)
from autogen_ext.code_executors.docker import DockerCommandLineCodeExecutor
@dataclass
class CodeGenMessage:
content: str
@default_subscription
class Assistant(RoutedAgent):
def __init__(self, model_client: ChatCompletionClient) -> None:
super().__init__("An assistant agent.")
self._model_client = model_client
self._chat_history: List[LLMMessage] = [
SystemMessage(
content="""Write Python script in markdown block, and it will be executed.
Always save figures to file in the current directory. Do not use plt.show(). All code required to complete this task must be contained within a single response.""",
)
]
@message_handler
async def handle_message(self, message: CodeGenMessage, ctx: MessageContext) -> None:
self._chat_history.append(UserMessage(content=message.content, source="user"))
result = await self._model_client.create(self._chat_history)
print(f"\\n{'-'*80}\\nAssistant:\\n{result.content}")
self._chat_history.append(AssistantMessage(content=result.content, source="assistant"))
await self.publish_message(CodeGenMessage(content=result.content), DefaultTopicId())
def extract_markdown_code_blocks(markdown_text: str) -> List[CodeBlock]:
pattern = re.compile(r"```(?:\\s*([\\w\\+\\-]+))?\\n([\\s\\S]*?)```")
matches = pattern.findall(markdown_text)
code_blocks: List[CodeBlock] = []
for match in matches:
language = match[0].strip() if match[0] else ""
code_content = match[1]
code_blocks.append(CodeBlock(code=code_content, language=language))
return code_blocks
@default_subscription
class Executor(RoutedAgent):
def __init__(self, code_executor: CodeExecutor) -> None:
super().__init__("An executor agent.")
self._code_executor = code_executor
@message_handler
async def handle_message(self, message: CodeGenMessage, ctx: MessageContext) -> None:
code_blocks = extract_markdown_code_blocks(message.content)
if code_blocks:
result = await self._code_executor.execute_code_blocks(
code_blocks, cancellation_token=ctx.cancellation_token
)
print(f"\\n{'-'*80}\\nExecutor:\\n{result.output}")
await self.publish_message(CodeGenMessage(content=result.output), DefaultTopicId())
# nous ajoutons cet op weave ici car nous souhaitons tracer
# l'ensemble du flux de travail de génération de code sous une seule trace
# c'est entièrement facultatif mais fortement recommandé de l'utiliser
@weave.op(call_display_name="CodeGen Agent Workflow")
async def run_codegen(model_name="gpt-4o"): # Modèle mis à jour
work_dir = tempfile.mkdtemp()
runtime = SingleThreadedAgentRuntime()
# Vérifier que Docker est en cours d'exécution pour cet exemple
try:
async with DockerCommandLineCodeExecutor(work_dir=work_dir) as executor:
model_client = OpenAIChatCompletionClient(model=model_name)
await Assistant.register(runtime, "assistant", lambda: Assistant(model_client=model_client))
await Executor.register(runtime, "executor", lambda: Executor(executor))
runtime.start()
await runtime.publish_message(
CodeGenMessage(content="Create a plot of NVDA vs TSLA stock returns YTD from 2024-01-01."),
DefaultTopicId(),
)
await runtime.stop_when_idle()
await model_client.close()
except Exception as e:
print(f"Could not run Docker code executor example: {e}")
print("Please ensure Docker is installed and running.")
finally:
import shutil
shutil.rmtree(work_dir)
asyncio.run(run_codegen())
````
[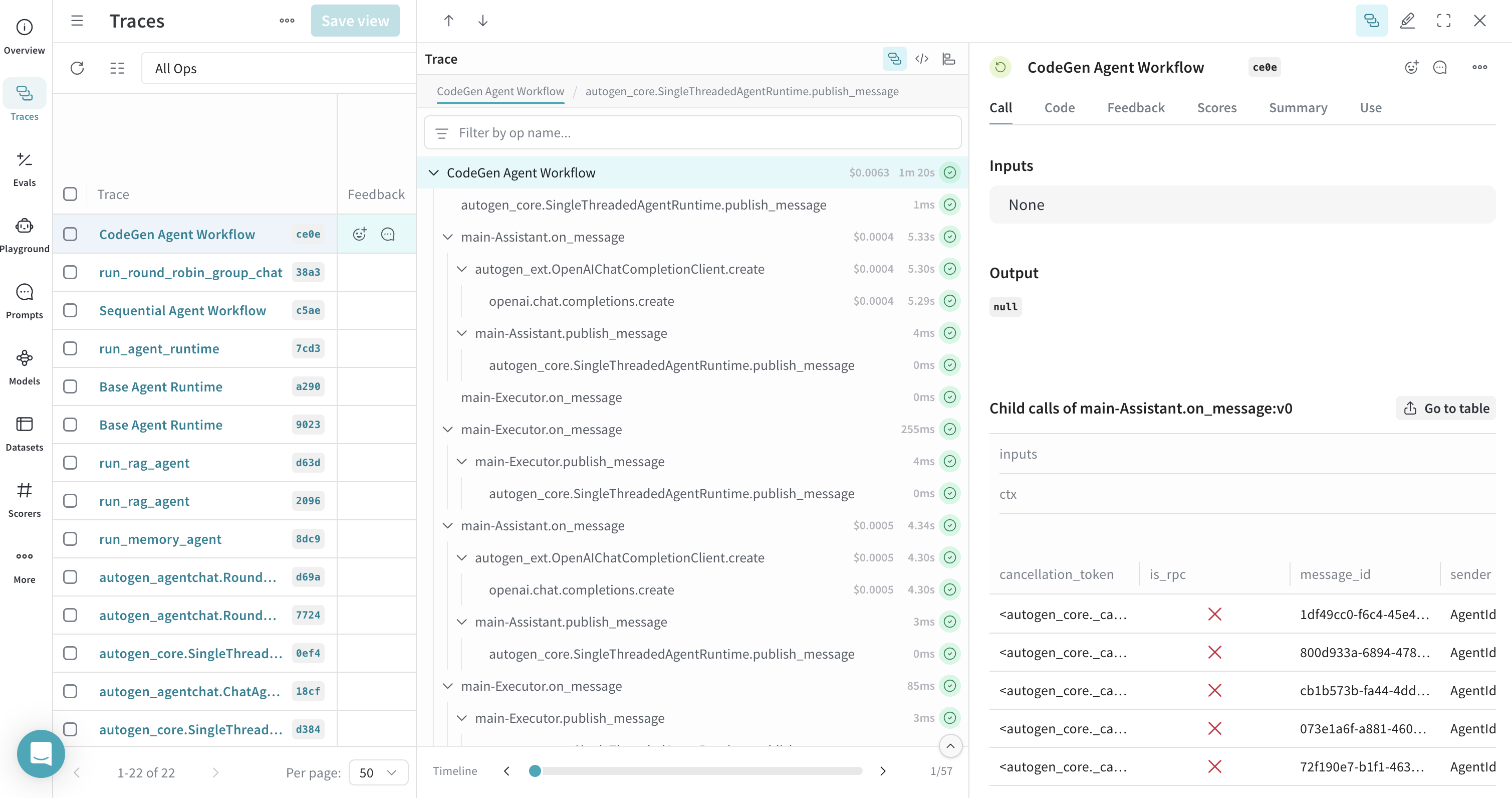 ](https://wandb.ai/parambharat/autogen-demo/weave/traces?view=traces_default\&peekPath=%2Fparambharat%2Fautogen-demo%2Fcalls%2F0196f173-21c2-7540-9dc7-fbab0b94ce0e%3FhideTraceTree%3D0)
](https://wandb.ai/parambharat/autogen-demo/weave/traces?view=traces_default\&peekPath=%2Fparambharat%2Fautogen-demo%2Fcalls%2F0196f173-21c2-7540-9dc7-fbab0b94ce0e%3FhideTraceTree%3D0)
## En savoir plus
Consultez les guides suivants pour mieux comprendre le Tracing et les opérations de Weave.
* **Weave**:
* [Guide du Tracing](/fr/weave/guides/tracking/tracing)
* [Décorateur op](/fr/weave/guides/tracking/ops)
* **AutoGen**:
* [Documentation officielle](https://microsoft.github.io/autogen/stable//index.html)
* [GitHub AutoGen](https://github.com/microsoft/autogen)
Ce guide constitue un point de départ pour intégrer Weave à AutoGen. Explorez le Weave UI pour consulter des traces détaillées des interactions de votre agent, des appels au modèle et de l’utilisation des outils.