> ## Documentation Index
> Fetch the complete documentation index at: https://docs.wandb.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Bedrock
> Suivez et surveillez les appels LLM Amazon Bedrock avec Weave, en capturant les interactions avec les foundation models et l'utilisation de l'API converse.
Weave suit et journalise automatiquement les appels LLM effectués via Amazon Bedrock, le service géré d'AWS qui donne accès à des foundation models de plusieurs fournisseurs d’IA via une API unifiée. Utilisez cette intégration pour capturer les interactions avec les foundation models de Bedrock et l'utilisation de l'API `converse`, afin de pouvoir déboguer, évaluer et surveiller vos applications basées sur Bedrock.
Vous pouvez journaliser les appels LLM vers Weave depuis Amazon Bedrock de plusieurs façons. Utilisez `weave.op` pour créer des opérations réutilisables afin de suivre tous les appels à un modèle Bedrock. Si vous utilisez des modèles Anthropic, vous pouvez également utiliser l'intégration native de Weave avec Anthropic.
Pour les derniers tutoriels, visitez [W\&B on Amazon Web Services](https://wandb.ai/site/partners/aws/).
## Traces
Weave capture automatiquement les traces des appels à l’API Bedrock une fois que vous avez patché le client. Après avoir initialisé Weave et patché le client, utilisez le client Bedrock comme d’habitude :
```python lines theme={null}
import weave
import boto3
import json
from weave.integrations.bedrock.bedrock_sdk import patch_client
weave.init("my_bedrock_app")
# Créer et patcher le client Bedrock
client = boto3.client("bedrock-runtime")
patch_client(client)
# Utiliser le client comme d'habitude
response = client.invoke_model(
modelId="anthropic.claude-3-5-sonnet-20240620-v1:0",
body=json.dumps({
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 100,
"messages": [
{"role": "user", "content": "What is the capital of France?"}
]
}),
contentType='application/json',
accept='application/json'
)
response_dict = json.loads(response.get('body').read())
print(response_dict["content"][0]["text"])
```
Le même client patché capture également des traces avec l’API `converse` :
```python lines theme={null}
messages = [{"role": "user", "content": [{"text": "What is the capital of France?"}]}]
response = client.converse(
modelId="anthropic.claude-3-5-sonnet-20240620-v1:0",
system=[{"text": "You are a helpful AI assistant."}],
messages=messages,
inferenceConfig={"maxTokens": 100},
)
print(response["output"]["message"]["content"][0]["text"])
```
## Encapsuler les appels dans vos propres ops
Encapsulez les appels Bedrock dans vos propres ops pour regrouper la logique associée, capturer des entrées personnalisées et réutiliser la même fonction suivie dans toute votre application. Créez des opérations réutilisables à l’aide du décorateur `@weave.op()`. Voici un exemple qui montre les API `invoke_model` et `converse` :
```python lines theme={null}
@weave.op
def call_model_invoke(
model_id: str,
prompt: str,
max_tokens: int = 100,
temperature: float = 0.7
) -> dict:
body = json.dumps({
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": max_tokens,
"temperature": temperature,
"messages": [
{"role": "user", "content": prompt}
]
})
response = client.invoke_model(
modelId=model_id,
body=body,
contentType='application/json',
accept='application/json'
)
return json.loads(response.get('body').read())
@weave.op
def call_model_converse(
model_id: str,
messages: str,
system_message: str,
max_tokens: int = 100,
) -> dict:
response = client.converse(
modelId=model_id,
system=[{"text": system_message}],
messages=messages,
inferenceConfig={"maxTokens": max_tokens},
)
return response
```
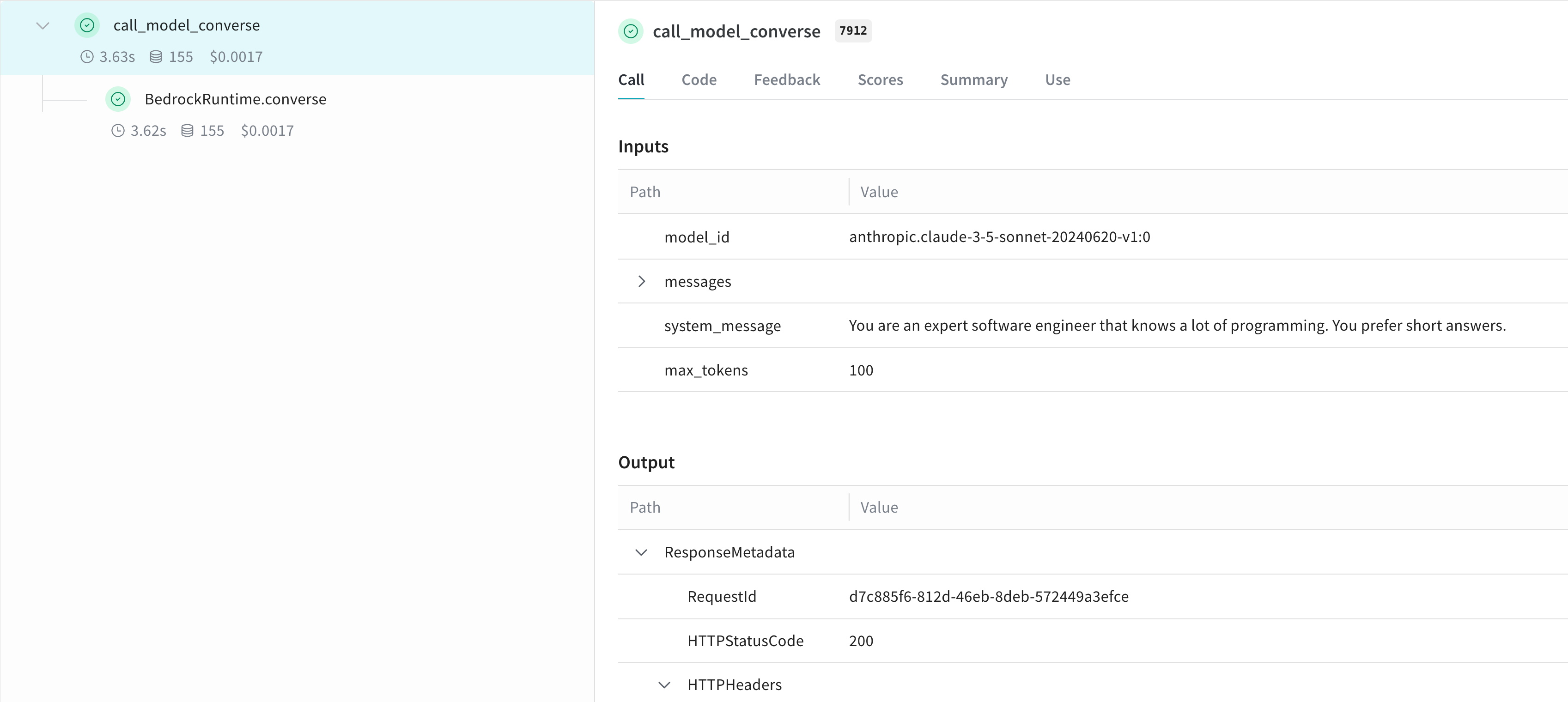
## Créez un `Model` pour expérimenter plus facilement
Un `Model` Weave regroupe la configuration et la logique de prédiction afin que vous puissiez itérer sur les paramètres et comparer les runs côte à côte. Créez un `Model` Weave pour mieux organiser vos expériences et capturer les paramètres. L'exemple suivant utilise l'API `converse` :
```python lines theme={null}
class BedrockLLM(weave.Model):
model_id: str
max_tokens: int = 100
system_message: str = "You are a helpful AI assistant."
@weave.op
def predict(self, prompt: str) -> str:
"Generate a response using Bedrock's converse API"
messages = [{
"role": "user",
"content": [{"text": prompt}]
}]
response = client.converse(
modelId=self.model_id,
system=[{"text": self.system_message}],
messages=messages,
inferenceConfig={"maxTokens": self.max_tokens},
)
return response["output"]["message"]["content"][0]["text"]
# Créer et utiliser le modèle
model = BedrockLLM(
model_id="anthropic.claude-3-5-sonnet-20240620-v1:0",
max_tokens=100,
system_message="You are an expert software engineer that knows a lot of programming. You prefer short answers."
)
result = model.predict("What is the best way to handle errors in Python?")
print(result)
```
Cette approche vous permet de versionner vos expériences et de suivre différentes configurations de votre application basée sur Bedrock.
## En savoir plus
Les ressources suivantes fournissent d’autres moyens d’explorer et d’évaluer Amazon Bedrock avec Weave.
### Essayez Bedrock dans le playground Weave
Pour tester des modèles Amazon Bedrock dans Weave UI sans rien configurer, essayez le [LLM Playground](../tools/playground).
### Rapport : comparer des LLM sur Bedrock pour le résumé de texte avec Weave
Le rapport [Évaluer des LLM sur Amazon Bedrock](https://wandb.ai/byyoung3/ML_NEWS3/reports/Compare-LLMs-on-Amazon-Bedrock-for-text-summarization-with-W-B-Weave--VmlldzoxMDI1MTIzNw) explique comment utiliser Bedrock avec Weave pour évaluer et comparer des LLM pour des tâches de résumé de texte. Le rapport inclut des exemples de code.