> ## Documentation Index
> Fetch the complete documentation index at: https://docs.wandb.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# LangChain
> Utilisez Weave pour suivre et consigner tous les appels effectués via la bibliothèque Python LangChain
 Weave suit et consigne les appels effectués via la [bibliothèque Python LangChain](https://github.com/langchain-ai/langchain).
Lorsque vous travaillez avec des LLM, le débogage fait partie intégrante du travail. Qu'un appel de modèle échoue, qu'une sortie soit mal formatée ou que des appels de modèle imbriqués sèment la confusion, il peut être difficile d'identifier précisément les problèmes. Les applications LangChain comportent souvent plusieurs étapes et appels LLM. Il est donc utile de comprendre le fonctionnement interne de vos chaînes et de vos agents.
Weave capture automatiquement les traces de vos applications [LangChain](https://docs.langchain.com/oss/python/langchain/overview). Cela vous permet de surveiller et d'analyser les performances de votre application, ce qui facilite le débogage et l'optimisation de vos flux de travail LLM.
Ce guide s'adresse aux développeurs qui créent des applications LangChain et souhaitent y ajouter le tracing, l'évaluation et l'observabilité avec Weave. Il explique comment activer le tracing automatique, associer des métadonnées, contrôler le tracing manuellement et encapsuler des chaînes LangChain en tant que modèles Weave pour l'évaluation.
Weave suit et consigne les appels effectués via la [bibliothèque Python LangChain](https://github.com/langchain-ai/langchain).
Lorsque vous travaillez avec des LLM, le débogage fait partie intégrante du travail. Qu'un appel de modèle échoue, qu'une sortie soit mal formatée ou que des appels de modèle imbriqués sèment la confusion, il peut être difficile d'identifier précisément les problèmes. Les applications LangChain comportent souvent plusieurs étapes et appels LLM. Il est donc utile de comprendre le fonctionnement interne de vos chaînes et de vos agents.
Weave capture automatiquement les traces de vos applications [LangChain](https://docs.langchain.com/oss/python/langchain/overview). Cela vous permet de surveiller et d'analyser les performances de votre application, ce qui facilite le débogage et l'optimisation de vos flux de travail LLM.
Ce guide s'adresse aux développeurs qui créent des applications LangChain et souhaitent y ajouter le tracing, l'évaluation et l'observabilité avec Weave. Il explique comment activer le tracing automatique, associer des métadonnées, contrôler le tracing manuellement et encapsuler des chaînes LangChain en tant que modèles Weave pour l'évaluation.
## Prise en main
Pour commencer, appelez `weave.init()` au début de votre script. L’argument de `weave.init()` est un nom de projet que Weave utilise pour organiser vos traces.
```python lines {6} theme={null}
import weave
from langchain_core.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
# Initialisez Weave avec le nom de votre projet
weave.init("langchain_demo")
llm = ChatOpenAI()
prompt = PromptTemplate.from_template("1 + {number} = ")
llm_chain = prompt | llm
output = llm_chain.invoke({"number": 2})
print(output)
```
## Suivre les métadonnées des appels
Les métadonnées personnalisées vous aident à filtrer et à analyser les traces dans l’interface Weave. Pour suivre les métadonnées de vos appels LangChain, utilisez le gestionnaire de contexte [`weave.attributes`](/fr/weave/reference/python-sdk#function-attributes). Ce gestionnaire de contexte vous permet de définir des métadonnées personnalisées pour un bloc de code précis, comme une chaîne ou une requête unique.
```python lines {6,13} theme={null}
import weave
from langchain_core.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
# Initialiser Weave avec le nom de votre projet
weave.init("langchain_demo")
llm = ChatOpenAI()
prompt = PromptTemplate.from_template("1 + {number} = ")
llm_chain = prompt | llm
with weave.attributes({"my_awesome_attribute": "value"}):
output = llm_chain.invoke()
print(output)
```
Weave suit automatiquement les métadonnées de la trace de l’appel LangChain. Vous pouvez consulter les métadonnées dans l’interface web de Weave.
[ ](https://wandb.ai/parambharat/langchain_demo/weave/traces?cols=%7B%22attributes.weave.client_version%22%3Afalse%2C%22attributes.weave.os_name%22%3Afalse%2C%22attributes.weave.os_release%22%3Afalse%2C%22attributes.weave.os_version%22%3Afalse%2C%22attributes.weave.source%22%3Afalse%2C%22attributes.weave.sys_version%22%3Afalse%7D)
](https://wandb.ai/parambharat/langchain_demo/weave/traces?cols=%7B%22attributes.weave.client_version%22%3Afalse%2C%22attributes.weave.os_name%22%3Afalse%2C%22attributes.weave.os_release%22%3Afalse%2C%22attributes.weave.os_version%22%3Afalse%2C%22attributes.weave.source%22%3Afalse%2C%22attributes.weave.sys_version%22%3Afalse%7D)
## Traces
Le stockage des traces des applications LLM dans une base de données centrale aide aussi bien pendant le développement qu’en Production. Ces traces vous fournissent un jeu de données que vous pouvez utiliser pour déboguer et améliorer votre application.
Weave capture automatiquement les traces de vos applications LangChain. Weave suit et consigne les appels effectués via la bibliothèque LangChain, y compris les modèles de prompt, les chaînes, les appels LLM, les outils et les étapes de l’agent. Vous pouvez consulter les traces dans l’interface web de Weave.
[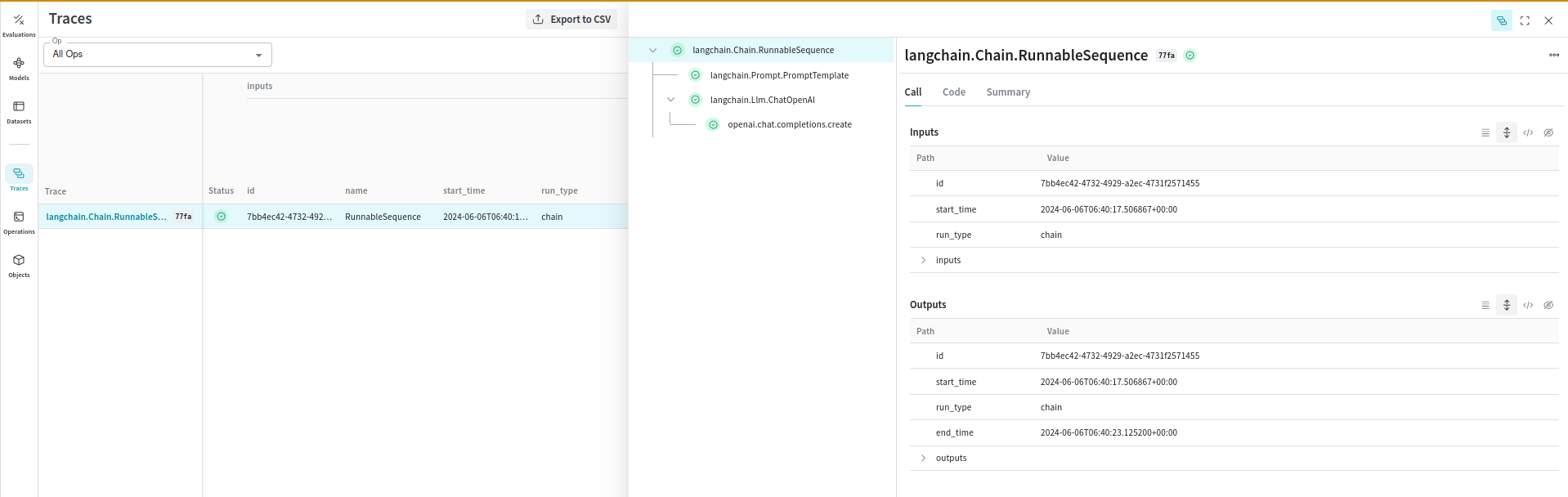 ](https://wandb.ai/parambharat/langchain_demo/weave/calls)
](https://wandb.ai/parambharat/langchain_demo/weave/calls)
## Tracer les appels manuellement
Outre le tracing automatique, vous pouvez tracer manuellement les appels à l’aide du callback `WeaveTracer` ou du gestionnaire de contexte `weave_tracing_enabled`. Ces méthodes s’apparentent à l’utilisation de callbacks de requête dans certaines parties d’une application LangChain. Utilisez-les lorsque vous souhaitez tracer des chaînes ou des invocations spécifiques plutôt que l’ensemble de votre application.
Les sections suivantes décrivent chaque approche.
Remarque : par défaut, Weave trace les `Runnables` LangChain, et ce comportement est activé lorsque vous appelez `weave.init()`. Vous pouvez désactiver ce comportement en définissant la variable d’environnement `WEAVE_TRACE_LANGCHAIN` sur `"false"` avant d’appeler `weave.init()`. Cela vous permet de contrôler le comportement de tracing de chaînes spécifiques, voire de requêtes individuelles dans votre application.
### Utiliser `WeaveTracer`
Vous pouvez transmettre le callback `WeaveTracer` à des composants LangChain spécifiques afin de tracer certaines requêtes.
```python lines {11,13,15,22} theme={null}
import os
os.environ["WEAVE_TRACE_LANGCHAIN"] = "false" # <- désactiver explicitement le tracing global.
from weave.integrations.langchain import WeaveTracer
from langchain_core.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
import weave
# Initialiser Weave avec le nom de votre projet
weave.init("langchain_demo") # <-- le tracing n'est pas activé ici car la variable d'environnement est explicitement définie à `false`
weave_tracer = WeaveTracer()
config = {"callbacks": [weave_tracer]}
llm = ChatOpenAI()
prompt = PromptTemplate.from_template("1 + {number} = ")
llm_chain = prompt | llm
output = llm_chain.invoke({"number": 2}, config=config) # <-- active le tracing uniquement pour cet appel de chaîne.
llm_chain.invoke({"number": 4}) # <-- le tracing ne sera pas activé pour les appels langchain, mais les appels openai seront tout de même tracés
```
### Utilisation du gestionnaire de contexte `weave_tracing_enabled`
Vous pouvez également utiliser le gestionnaire de contexte `weave_tracing_enabled` pour activer le tracing dans des blocs de code spécifiques.
```python lines {11,18} theme={null}
import os
os.environ["WEAVE_TRACE_LANGCHAIN"] = "false" # <- désactive explicitement le tracing global.
from weave.integrations.langchain import weave_tracing_enabled
from langchain_core.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
import weave
# Initialiser Weave avec le nom de votre projet
weave.init("langchain_demo") # <-- le tracing n'est pas activé ici car la variable d'environnement est explicitement définie à `false`
llm = ChatOpenAI()
prompt = PromptTemplate.from_template("1 + {number} = ")
llm_chain = prompt | llm
with weave_tracing_enabled(): # <-- active le tracing uniquement pour cet appel de chaîne.
output = llm_chain.invoke({"number": 2})
llm_chain.invoke({"number": 4}) # <-- le tracing ne sera pas activé pour les appels langchain, mais les appels openai seront toujours tracés
```
## Configuration
Lorsque vous appelez `weave.init()`, Weave active le tracing en définissant la variable d'environnement `WEAVE_TRACE_LANGCHAIN` sur `"true"`. Cela permet à Weave de capturer automatiquement les traces de vos applications LangChain. Pour désactiver ce comportement, définissez la variable d'environnement sur `"false"`.
## Lien avec les callbacks de LangChain
Cette section explique comment le tracing de Weave s’intègre au système de callbacks de LangChain, afin que vous puissiez choisir l’approche la mieux adaptée à votre application.
### Journalisation automatique
La journalisation automatique fournie par `weave.init()` revient à transmettre un callback de constructeur à chaque composant d'une application LangChain. Cela signifie que Weave suit toutes les interactions globalement à l'échelle de toute votre application, y compris les modèles de prompt, les chaînes, les appels LLM, les outils et les étapes de l'agent.
### Journalisation manuelle
Les méthodes de journalisation manuelle (`WeaveTracer` et `weave_tracing_enabled`) sont similaires à l’utilisation de callbacks de requête dans certaines parties d’une application LangChain. Ces méthodes offrent un contrôle plus précis sur les parties de votre application qui font l’objet d’un tracing :
* **Callbacks du constructeur :** appliqués à l’ensemble de la chaîne ou du composant, ils journalisent toutes les interactions de manière cohérente.
* **Callbacks de requête :** appliqués à des requêtes spécifiques, ils permettent un tracing détaillé de certaines invocations.
Lorsque vous intégrez Weave à LangChain, vous bénéficiez de la journalisation et de la surveillance de vos applications LLM, ce qui facilite le débogage et l’optimisation des performances.
Pour plus d'informations, voir la [documentation LangChain](https://python.langchain.com/v0.2/docs/how_to/debugging/#tracing).
## Models et évaluations
Organiser et évaluer des LLM pour différents cas d'usage devient plus complexe à mesure que vous ajoutez des composants comme les prompts, les configurations de modèle et les paramètres d'inférence. Avec [`weave.Model`](/fr/weave/guides/core-types/models), vous pouvez capturer et organiser des détails expérimentaux, comme les prompts système ou les modèles que vous utilisez, ce qui facilite la comparaison des différentes itérations.
Les sections suivantes montrent comment encapsuler une chaîne LangChain en tant que `weave.Model`, puis l'évaluer.
L'exemple suivant montre comment encapsuler une chaîne LangChain dans un `WeaveModel` :
```python lines {10,12,16} theme={null}
import json
import asyncio
import weave
from langchain_core.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
# Initialiser Weave avec le nom de votre projet
weave.init("langchain_demo")
class ExtractFruitsModel(weave.Model):
model_name: str
prompt_template: str
@weave.op()
async def predict(self, sentence: str) -> dict:
llm = ChatOpenAI(model=self.model_name, temperature=0.0)
prompt = PromptTemplate.from_template(self.prompt_template)
llm_chain = prompt | llm
response = llm_chain.invoke({"sentence": sentence})
result = response.content
if result is None:
raise ValueError("No response from model")
parsed = json.loads(result)
return parsed
model = ExtractFruitsModel(
model_name="gpt-3.5-turbo-1106",
prompt_template='Extract fields ("fruit": , "color": , "flavor": ) from the following text, as json: {sentence}',
)
sentence = "There are many fruits that were found on the recently discovered planet Goocrux. There are neoskizzles that grow there, which are purple and taste like candy."
prediction = asyncio.run(model.predict(sentence))
# si vous utilisez un Jupyter Notebook, exécutez :
# prediction = await model.predict(sentence)
print(prediction)
```
Ce code crée un modèle que vous pouvez visualiser dans l’interface Weave :
[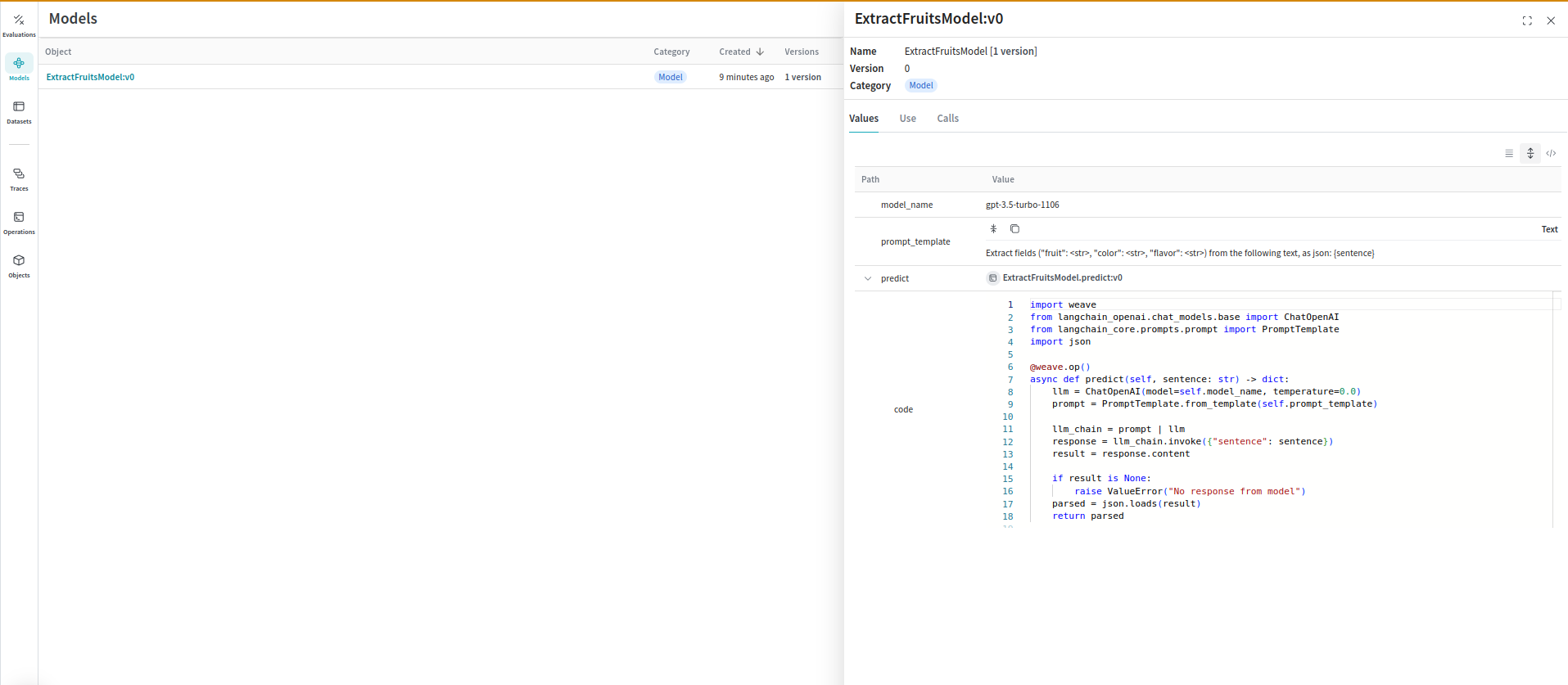 ](https://wandb.ai/parambharat/langchain_demo/weave/object-versions?filter=%7B%22baseObjectClass%22%3A%22Model%22%7D\&peekPath=%2Fparambharat%2Flangchain_demo%2Fobjects%2FExtractFruitsModel%2Fversions%2FBeoL6WuCH8wgjy6HfmuBMyKzArETg1oAFpYaXZSq1hw%3F%26)
Vous pouvez également utiliser Weave Models avec `serve` ainsi qu’avec les [`Évaluations`](/fr/weave/guides/core-types/evaluations).
](https://wandb.ai/parambharat/langchain_demo/weave/object-versions?filter=%7B%22baseObjectClass%22%3A%22Model%22%7D\&peekPath=%2Fparambharat%2Flangchain_demo%2Fobjects%2FExtractFruitsModel%2Fversions%2FBeoL6WuCH8wgjy6HfmuBMyKzArETg1oAFpYaXZSq1hw%3F%26)
Vous pouvez également utiliser Weave Models avec `serve` ainsi qu’avec les [`Évaluations`](/fr/weave/guides/core-types/evaluations).
### Évaluations
Les évaluations vous aident à mesurer les performances de vos modèles. La classe [`weave.Evaluation`](/fr/weave/guides/core-types/evaluations) permet de capturer les performances de votre modèle sur des tâches ou des jeux de données spécifiques. Cela facilite la comparaison entre différents modèles et les différentes itérations de votre application. L'exemple suivant montre comment évaluer le modèle précédent :
```python lines theme={null}
from weave.scorers import MultiTaskBinaryClassificationF1
sentences = [
"There are many fruits that were found on the recently discovered planet Goocrux. There are neoskizzles that grow there, which are purple and taste like candy.",
"Pounits are a bright green color and are more savory than sweet.",
"Finally, there are fruits called glowls, which have a very sour and bitter taste which is acidic and caustic, and a pale orange tinge to them.",
]
labels = [
{"fruit": "neoskizzles", "color": "purple", "flavor": "candy"},
{"fruit": "pounits", "color": "bright green", "flavor": "savory"},
{"fruit": "glowls", "color": "pale orange", "flavor": "sour and bitter"},
]
examples = [
{"id": "0", "sentence": sentences[0], "target": labels[0]},
{"id": "1", "sentence": sentences[1], "target": labels[1]},
{"id": "2", "sentence": sentences[2], "target": labels[2]},
]
@weave.op()
def fruit_name_score(target: dict, output: dict) -> dict:
return {"correct": target["fruit"] == output["fruit"]}
evaluation = weave.Evaluation(
dataset=examples,
scorers=[
MultiTaskBinaryClassificationF1(class_names=["fruit", "color", "flavor"]),
fruit_name_score,
],
)
scores = asyncio.run(evaluation.evaluate(model)))
# si vous utilisez un Jupyter Notebook, exécutez :
# scores = await evaluation.evaluate(model)
print(scores)
```
Ce code génère une trace d’évaluation que vous pouvez visualiser dans l’interface Weave :
[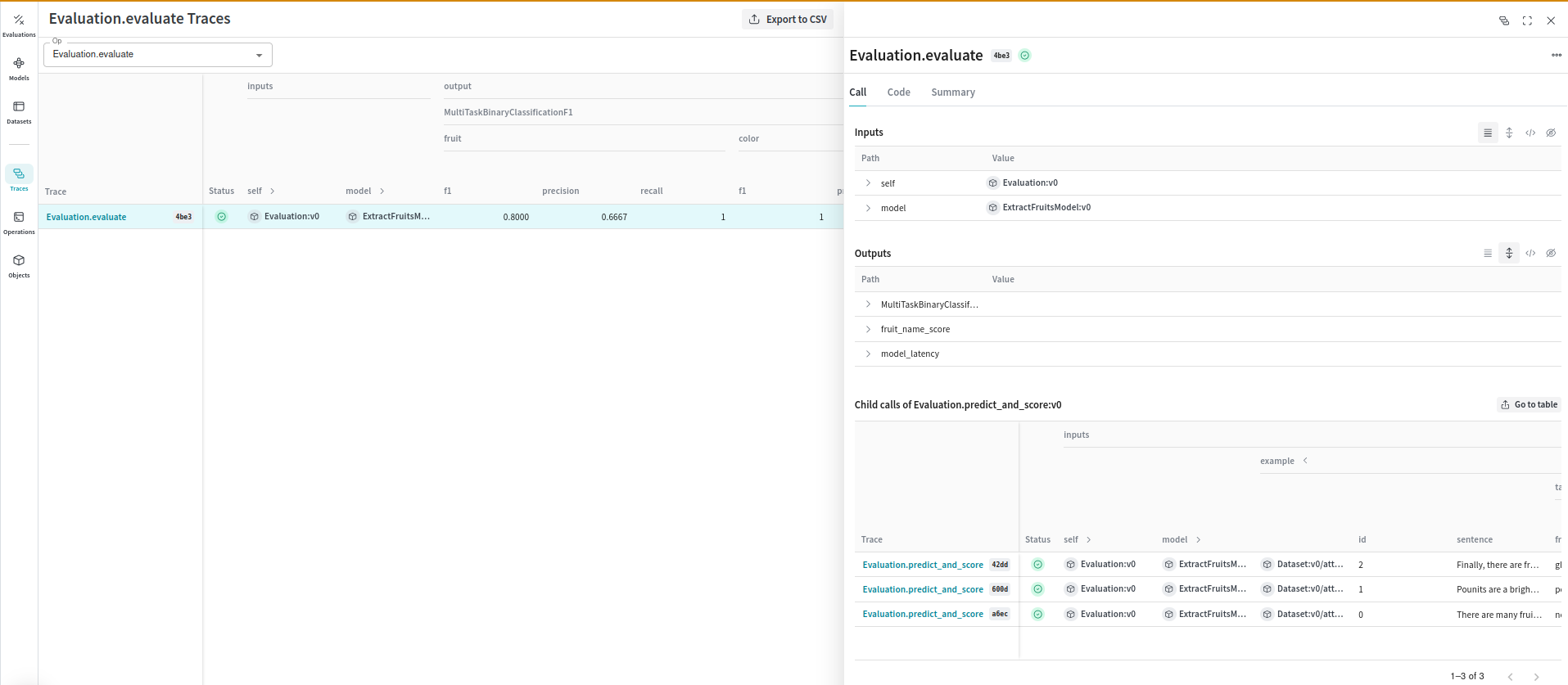 ](https://wandb.ai/parambharat/langchain_demo/weave/calls?filter=%7B%22traceRootsOnly%22%3Atrue%7D\&peekPath=%2Fparambharat%2Flangchain_demo%2Fcalls%2F44c3f26c-d9d3-423e-b434-651ea5174be3)
](https://wandb.ai/parambharat/langchain_demo/weave/calls?filter=%7B%22traceRootsOnly%22%3Atrue%7D\&peekPath=%2Fparambharat%2Flangchain_demo%2Fcalls%2F44c3f26c-d9d3-423e-b434-651ea5174be3)
## Problèmes connus
**Tracing des appels asynchrones** : un bug dans l’implémentation de `AsyncCallbackManager` dans LangChain fait que les appels asynchrones ne sont pas tracés dans le bon ordre. Weave a soumis une [PR](https://github.com/langchain-ai/langchain/pull/23909) pour corriger ce problème. Par conséquent, l’ordre des appels dans la trace peut ne pas être correct lorsque vous utilisez les méthodes `ainvoke`, `astream` et `abatch` dans les `Runnables` de LangChain.