> ## Documentation Index
> Fetch the complete documentation index at: https://docs.wandb.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# LiteLLM
> Suivre et consigner automatiquement les appels LLM effectués via LiteLLM
 Weave suit et consigne automatiquement les appels LLM effectués via LiteLLM, une fois `weave.init()` exécuté. Ce guide explique comment utiliser Weave avec LiteLLM pour capturer les traces, encapsuler les appels dans des ops versionnées, organiser les expériences avec un `Model` et suivre le comportement des appels de fonction. Utilisez-le lorsque vous développez des applications LLM et souhaitez une observabilité sur les multiples fournisseurs de modèles pris en charge par LiteLLM.
Weave suit et consigne automatiquement les appels LLM effectués via LiteLLM, une fois `weave.init()` exécuté. Ce guide explique comment utiliser Weave avec LiteLLM pour capturer les traces, encapsuler les appels dans des ops versionnées, organiser les expériences avec un `Model` et suivre le comportement des appels de fonction. Utilisez-le lorsque vous développez des applications LLM et souhaitez une observabilité sur les multiples fournisseurs de modèles pris en charge par LiteLLM.
## Traces
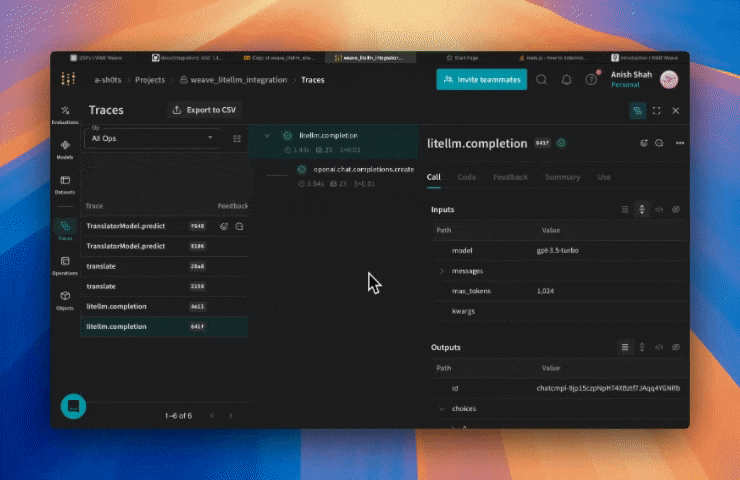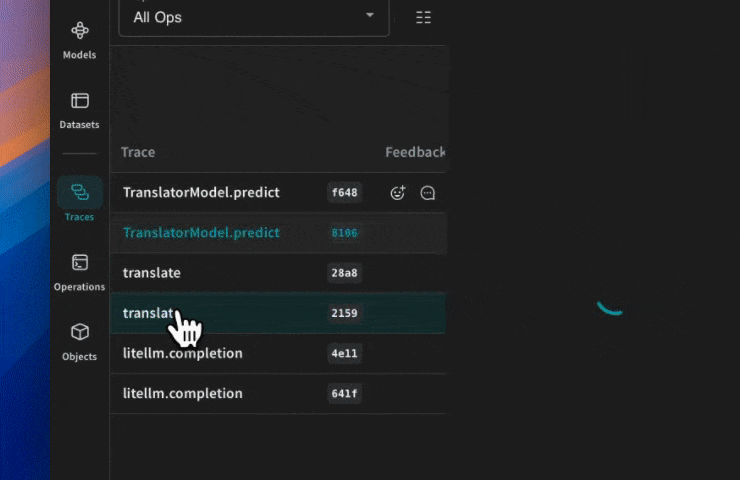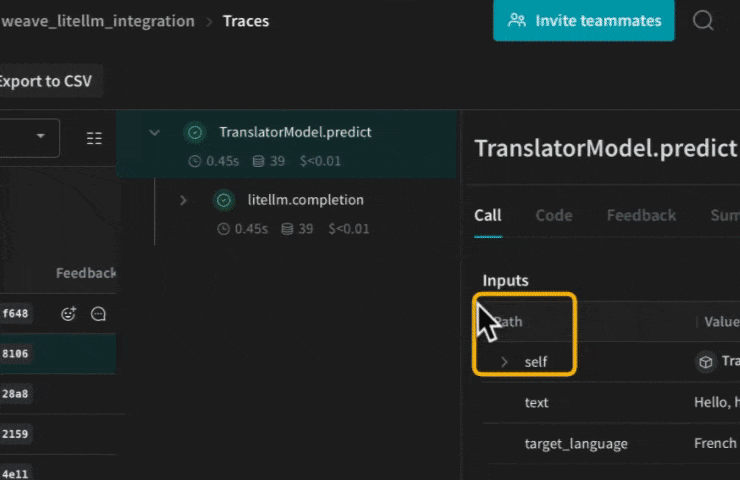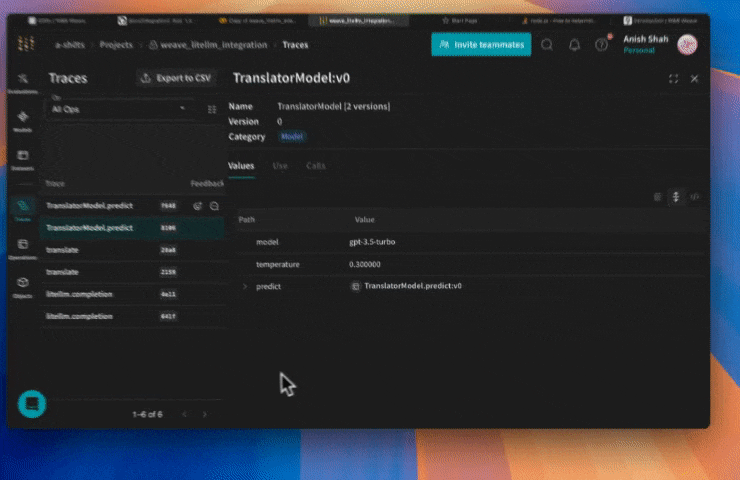
Il est important de stocker les traces des applications LLM dans une base de données centrale, aussi bien pendant le développement qu’en Production. Vous utilisez ces traces pour le débogage, ainsi que comme jeu de données pour vous aider à améliorer votre application.
> **Remarque :** Lorsque vous utilisez LiteLLM, veillez à importer la bibliothèque avec `import litellm` et à appeler la fonction de complétion avec `litellm.completion()` plutôt que `from litellm import completion`. Cela garantit que toutes les fonctions et tous les paramètres sont correctement référencés.
Weave capture automatiquement les traces pour LiteLLM. Utilisez la bibliothèque comme d’habitude et commencez par appeler `weave.init()` :
```python lines {4} theme={null}
import litellm
import weave
weave.init("weave_litellm_integration")
openai_response = litellm.completion(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": "Translate 'Hello, how are you?' to French"}],
max_tokens=1024
)
print(openai_response.choices[0].message.content)
claude_response = litellm.completion(
model="claude-3-5-sonnet-20240620",
messages=[{"role": "user", "content": "Translate 'Hello, how are you?' to French"}],
max_tokens=1024
)
print(claude_response.choices[0].message.content)
```
Weave va désormais suivre et consigner tous les appels LLM effectués via LiteLLM. Vous pouvez consulter les traces dans l’interface web de Weave. Une fois le tracing de base en place, la section suivante montre comment encapsuler les appels LiteLLM dans vos propres ops Weave afin d’obtenir un suivi plus fin et versionné de la logique de votre application.
## Utiliser vos propres ops
Les ops Weave rendent les résultats reproductibles grâce à la gestion automatique des versions du code au fil de vos expériences, et elles capturent leurs entrées et sorties. Créez une fonction décorée avec `@weave.op()` qui appelle la fonction de complétion de LiteLLM, et Weave suit pour vous les entrées et les sorties. Voici un exemple :
```python lines {4,6} theme={null}
import litellm
import weave
weave.init("weave_litellm_integration")
@weave.op()
def translate(text: str, target_language: str, model: str) -> str:
response = litellm.completion(
model=model,
messages=[{"role": "user", "content": f"Translate '{text}' to {target_language}"}],
max_tokens=1024
)
return response.choices[0].message.content
print(translate("Hello, how are you?", "French", "gpt-3.5-turbo"))
print(translate("Hello, how are you?", "Spanish", "claude-3-5-sonnet-20240620"))
```
## Créez un `Model` pour expérimenter plus facilement
Il est difficile d’organiser ses expérimentations lorsque de nombreux éléments évoluent simultanément. En utilisant la classe `Model`, vous pouvez capturer et structurer les détails expérimentaux de votre application, comme le prompt système ou le modèle que vous utilisez. Cela vous aide à organiser et à comparer les différentes itérations de votre application.
En plus de la gestion des versions du code et de la capture des entrées et des sorties, les Models capturent des paramètres structurés qui contrôlent le comportement de votre application, ce qui vous aide à trouver quels paramètres fonctionnent le mieux. Vous pouvez également utiliser les Weave Models avec `serve` et les Évaluations.
Dans l’exemple suivant, vous pouvez tester différents modèles et différentes températures :
```python lines {4,6,10} theme={null}
import litellm
import weave
weave.init('weave_litellm_integration')
class TranslatorModel(weave.Model):
model: str
temperature: float
@weave.op()
def predict(self, text: str, target_language: str):
response = litellm.completion(
model=self.model,
messages=[
{"role": "system", "content": f"You are a translator. Translate the given text to {target_language}."},
{"role": "user", "content": text}
],
max_tokens=1024,
temperature=self.temperature
)
return response.choices[0].message.content
# Créer des instances avec différents modèles
gpt_translator = TranslatorModel(model="gpt-3.5-turbo", temperature=0.3)
claude_translator = TranslatorModel(model="claude-3-5-sonnet-20240620", temperature=0.1)
# Utiliser différents modèles pour la traduction
english_text = "Hello, how are you today?"
print("GPT-3.5 Translation to French:")
print(gpt_translator.predict(english_text, "French"))
print("\nClaude-3.5 Sonnet Translation to Spanish:")
print(claude_translator.predict(english_text, "Spanish"))
```
## Appels de fonction
LiteLLM prend en charge les appels de fonction pour les modèles compatibles. Weave suit automatiquement ces appels de fonction afin que vous puissiez inspecter les fonctions, les arguments et les réponses avec vos autres traces.
```python lines {4} theme={null}
import litellm
import weave
weave.init("weave_litellm_integration")
response = litellm.completion(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": "Translate 'Hello, how are you?' to French"}],
functions=[
{
"name": "translate",
"description": "Translate text to a specified language",
"parameters": {
"type": "object",
"properties": {
"text": {
"type": "string",
"description": "The text to translate",
},
"target_language": {
"type": "string",
"description": "The language to translate to",
}
},
"required": ["text", "target_language"],
},
},
],
)
print(response)
```
Weave capture automatiquement les fonctions que vous utilisez dans le prompt et en conserve les différentes versions.
[ ](https://wandb.ai/a-sh0ts/weave_litellm_integration/weave/calls)
](https://wandb.ai/a-sh0ts/weave_litellm_integration/weave/calls)