> ## Documentation Index
> Fetch the complete documentation index at: https://docs.wandb.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# LlamaIndex
> Tracez et déboguez les applications LlamaIndex avec Weave, en capturant automatiquement les appels LLM, les pipelines RAG, les étapes d’agent et les évaluations.
Ce guide vous montre comment utiliser Weave pour tracer, déboguer et évaluer des applications [LlamaIndex](https://docs.llamaindex.ai/en/stable/). En le suivant, vous découvrirez comment Weave capture automatiquement les appels effectués via la [bibliothèque Python LlamaIndex](https://github.com/run-llama/llama_index), afin que vous puissiez surveiller les pipelines RAG, les étapes d’agent et les appels LLM sans écrire de code de journalisation personnalisé. Ce guide s’adresse aux développeurs qui créent des applications LLM avec LlamaIndex et souhaitent mieux comprendre leurs flux de travail pour le débogage, l’analyse des performances et l’évaluation.
Lorsque vous travaillez avec des LLM, le débogage est inévitable. Qu’un appel de modèle échoue, qu’une sortie soit mal formatée ou que des appels de modèle imbriqués prêtent à confusion, il peut être difficile d’identifier précisément les problèmes. Les applications LlamaIndex comportent souvent plusieurs étapes et appels LLM, ce qui rend essentielle une bonne compréhension du fonctionnement interne de vos chaînes et de vos agents.
Weave simplifie ce processus en capturant automatiquement les traces de vos applications LlamaIndex. Vous pouvez ainsi surveiller et analyser les performances de votre application, ce qui vous aide à déboguer et à optimiser vos flux de travail LLM. Weave prend également en charge vos flux de travail d’évaluation.
## Premiers pas
Pour commencer, appelez `weave.init()` au début de votre script. Cela initialise Weave et commence à capturer les traces de tous les appels LlamaIndex qui suivent. L'argument de `weave.init()` est un nom de projet qui vous aide à organiser vos traces.
```python lines {5} theme={null}
import weave
from llama_index.core.chat_engine import SimpleChatEngine
# Initialisez Weave avec le nom de votre projet
weave.init("llamaindex_demo")
chat_engine = SimpleChatEngine.from_defaults()
response = chat_engine.chat(
"Say something profound and romantic about fourth of July"
)
print(response)
```
L’exemple précédent crée un moteur de conversation LlamaIndex de base qui, en interne, effectue un appel à OpenAI. Après avoir exécuté ce code, Weave capture une trace de l’exécution du moteur de conversation, que vous pouvez examiner dans l’interface web de Weave. Voir la trace suivante :
[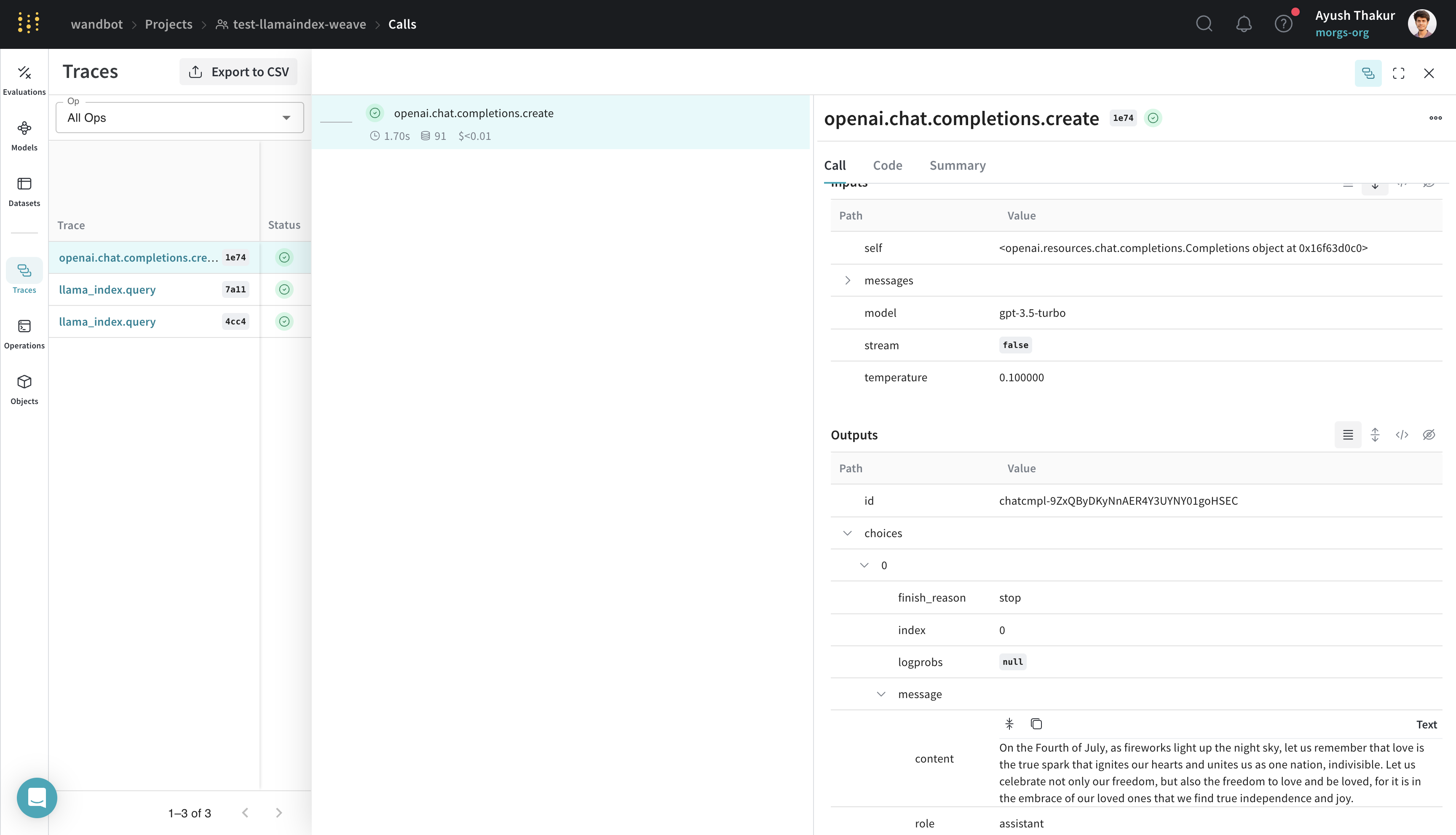 ](https://wandb.ai/wandbot/test-llamaindex-weave/weave/calls/b6b5d898-2df8-4e14-b553-66ce84661e74)
](https://wandb.ai/wandbot/test-llamaindex-weave/weave/calls/b6b5d898-2df8-4e14-b553-66ce84661e74)
## Traces
Cette section explique comment Weave capture des flux de travail LlamaIndex en plusieurs étapes, comme les pipelines RAG.
LlamaIndex est connu pour sa facilité à connecter des données à des LLM. Une application RAG simple nécessite une étape d'embedding, une étape de récupération et une étape de synthèse de la réponse. À mesure que la complexité augmente, il devient important de stocker, dans une base de données centrale, les traces de chaque étape, aussi bien en développement qu'en production.
Ces traces sont essentielles pour déboguer et améliorer votre application. Weave suit automatiquement tous les appels effectués via la bibliothèque LlamaIndex, y compris les modèles de prompt, les appels LLM, les outils et les étapes de l'agent. Vous pouvez consulter les traces dans l'interface web de Weave.
L'exemple suivant montre un pipeline RAG de base tiré du [Tutoriel de démarrage (OpenAI)](https://docs.llamaindex.ai/en/stable/getting_started/starter_example/) de LlamaIndex :
```python lines {5} theme={null}
import weave
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
# Initialiser Weave avec le nom de votre projet
weave.init("llamaindex_demo")
# En supposant que vous ayez un fichier `.txt` dans le répertoire `data`
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine()
response = query_engine.query("What did the author do growing up?")
print(response)
```
La chronologie de la trace capture non seulement les "événements", mais aussi le temps d'exécution, le coût et le nombre de tokens, le cas échéant. Explorez la trace en détail pour voir les entrées et les sorties de chaque étape.
[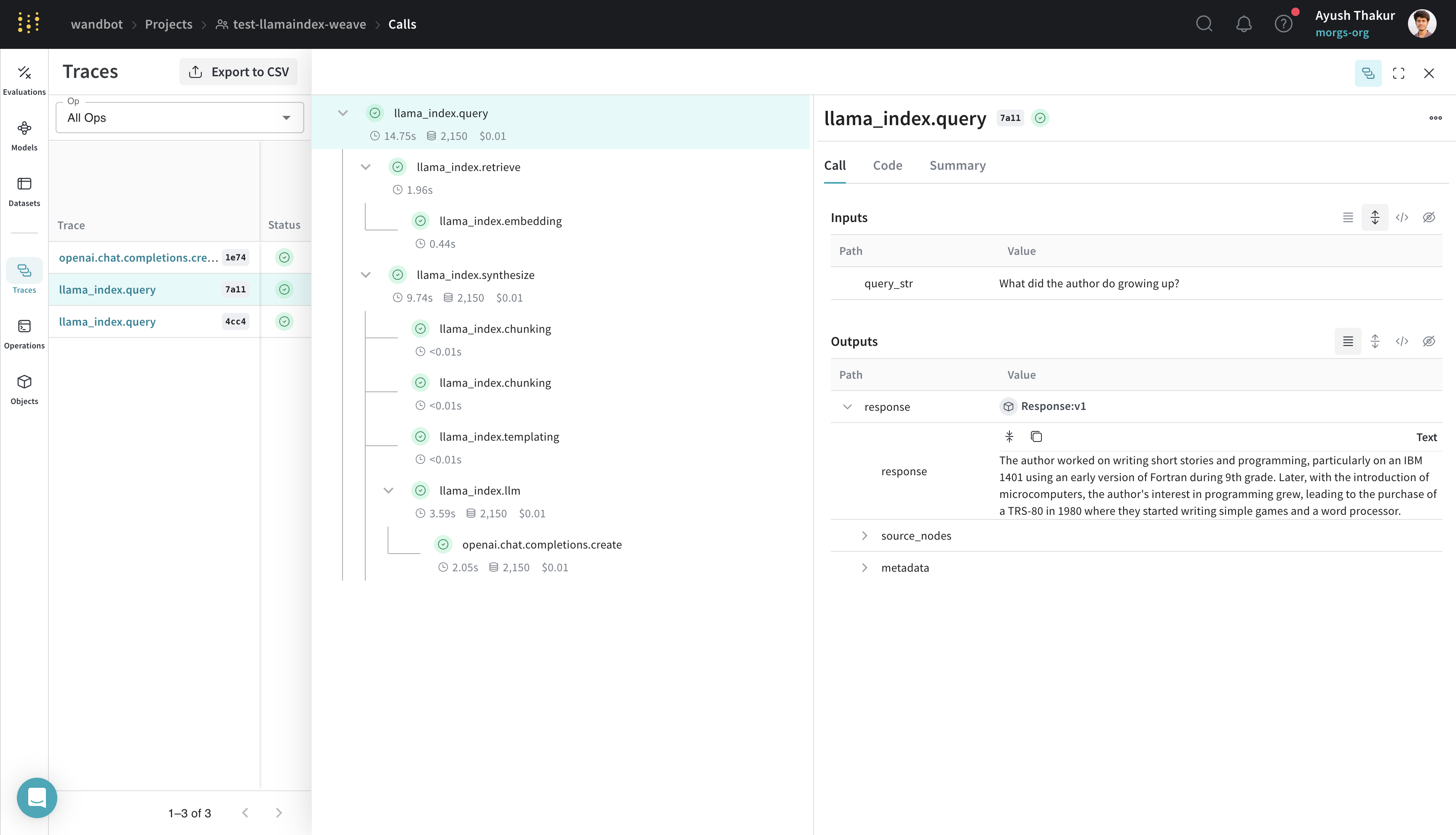 ](https://wandb.ai/wandbot/test-llamaindex-weave/weave/calls?filter=%7B%22traceRootsOnly%22%3Atrue%7D\&peekPath=%2Fwandbot%2Ftest-llamaindex-weave%2Fcalls%2F6ac53407-1bb7-4c38-b5a3-c302bd877a11%3Ftracetree%3D1)
](https://wandb.ai/wandbot/test-llamaindex-weave/weave/calls?filter=%7B%22traceRootsOnly%22%3Atrue%7D\&peekPath=%2Fwandbot%2Ftest-llamaindex-weave%2Fcalls%2F6ac53407-1bb7-4c38-b5a3-c302bd877a11%3Ftracetree%3D1)
## Observabilité en un clic
Cette section explique comment l’intégration Weave s’insère dans le système d’observabilité intégré de LlamaIndex, afin que vous n’ayez pas à configurer manuellement les gestionnaires.
LlamaIndex propose une [observabilité en un clic](https://docs.llamaindex.ai/en/stable/module_guides/observability/) pour vous permettre de créer des applications LLM rigoureuses en production.
L’intégration Weave exploite cette fonctionnalité de LlamaIndex et affecte automatiquement [`WeaveCallbackHandler()`](https://github.com/wandb/weave/blob/master/weave/integrations/llamaindex/llamaindex.py) à `llama_index.core.global_handler`. Ainsi, si vous utilisez LlamaIndex et Weave, il vous suffit d’initialiser un run Weave avec `weave.init([NAME_OF_PROJECT])`.
## Créez un `Model` pour faciliter l’expérimentation
Organiser et évaluer des LLM dans des applications pour divers cas d’usage peut s’avérer difficile lorsque vous avez plusieurs composants, tels que des prompts, des configurations de modèle et des paramètres d’inférence. Avec [`weave.Model`](/fr/weave/guides/core-types/models), vous pouvez capturer et organiser des détails expérimentaux, comme les prompts système ou les modèles que vous utilisez, ce qui vous aide à comparer différentes itérations.
L’exemple suivant montre comment créer un moteur de requête LlamaIndex dans un `WeaveModel`, à l’aide de données que vous pouvez trouver dans le dossier [weave/data](https://github.com/wandb/weave/tree/master/data) :
```python lines {16,52,61} theme={null}
import weave
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
from llama_index.core.node_parser import SentenceSplitter
from llama_index.llms.openai import OpenAI
from llama_index.core import PromptTemplate
PROMPT_TEMPLATE = """
You are given with relevant information about Paul Graham. Answer the user query only based on the information provided. Don't make up stuff.
User Query: {query_str}
Context: {context_str}
Answer:
"""
class SimpleRAGPipeline(weave.Model):
chat_llm: str = "gpt-4"
temperature: float = 0.1
similarity_top_k: int = 2
chunk_size: int = 256
chunk_overlap: int = 20
prompt_template: str = PROMPT_TEMPLATE
def get_llm(self):
return OpenAI(temperature=self.temperature, model=self.chat_llm)
def get_template(self):
return PromptTemplate(self.prompt_template)
def load_documents_and_chunk(self, data):
documents = SimpleDirectoryReader(data).load_data()
splitter = SentenceSplitter(
chunk_size=self.chunk_size,
chunk_overlap=self.chunk_overlap,
)
nodes = splitter.get_nodes_from_documents(documents)
return nodes
def get_query_engine(self, data):
nodes = self.load_documents_and_chunk(data)
index = VectorStoreIndex(nodes)
llm = self.get_llm()
prompt_template = self.get_template()
return index.as_query_engine(
similarity_top_k=self.similarity_top_k,
llm=llm,
text_qa_template=prompt_template,
)
@weave.op()
def predict(self, query: str):
query_engine = self.get_query_engine(
# Ces données sont disponibles dans le dépôt weave sous data/paul_graham
"data/paul_graham",
)
response = query_engine.query(query)
return {"response": response.response}
weave.init("test-llamaindex-weave")
rag_pipeline = SimpleRAGPipeline()
response = rag_pipeline.predict("What did the author do growing up?")
print(response)
```
La classe `SimpleRAGPipeline`, qui hérite de `weave.Model`, organise les paramètres importants de ce pipeline RAG. Décorer la méthode `query` avec `weave.op()` permet le traçage. Une fois cette structure en place, vous pouvez désormais versionner, comparer et évaluer différentes configurations de votre pipeline RAG dans Weave.
[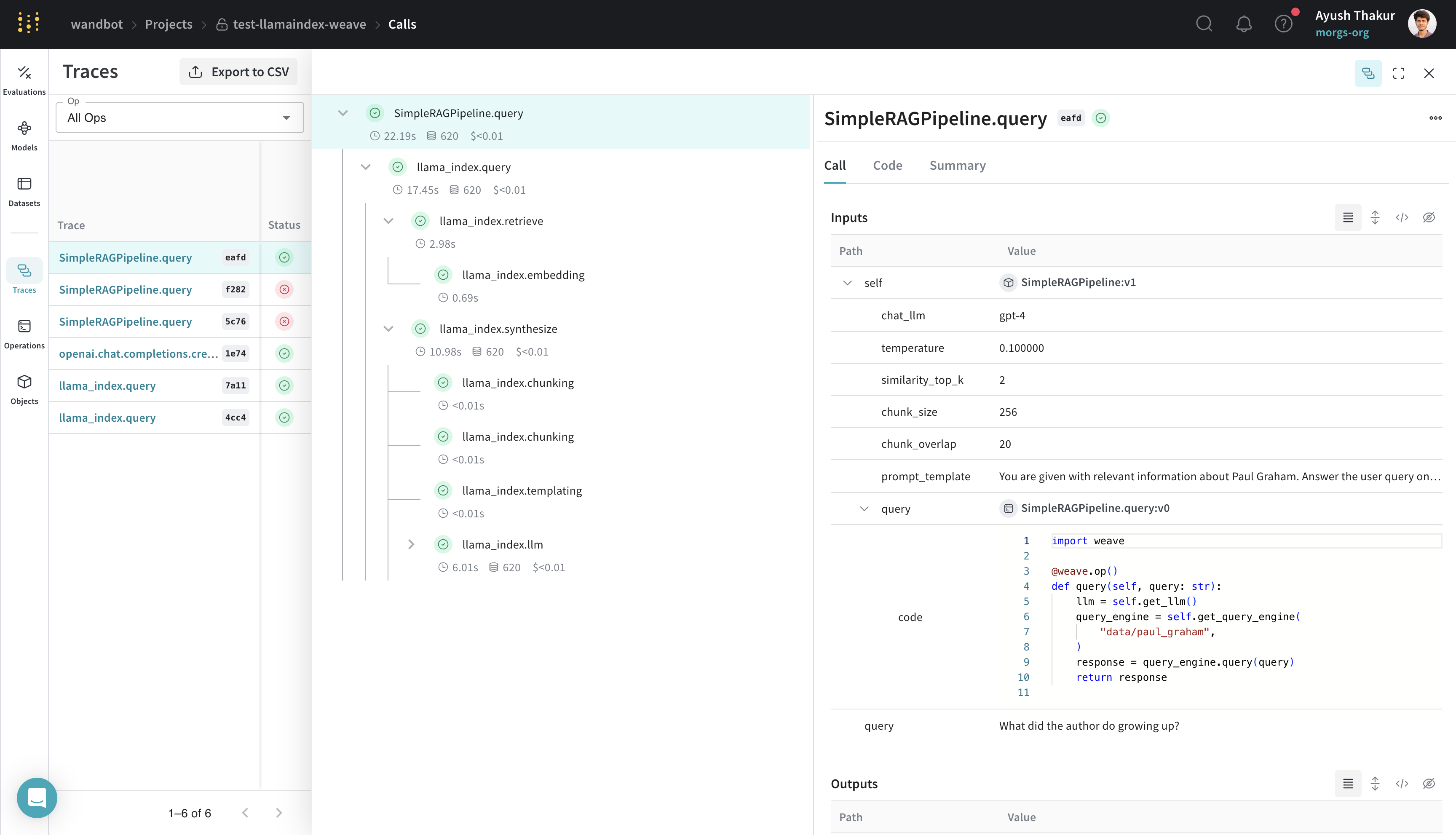 ](https://wandb.ai/wandbot/test-llamaindex-weave/weave/calls?filter=%7B%22traceRootsOnly%22%3Atrue%7D\&peekPath=%2Fwandbot%2Ftest-llamaindex-weave%2Fcalls%2Fa82afbf4-29a5-43cd-8c51-603350abeafd%3Ftracetree%3D1)
](https://wandb.ai/wandbot/test-llamaindex-weave/weave/calls?filter=%7B%22traceRootsOnly%22%3Atrue%7D\&peekPath=%2Fwandbot%2Ftest-llamaindex-weave%2Fcalls%2Fa82afbf4-29a5-43cd-8c51-603350abeafd%3Ftracetree%3D1)
## Évaluer avec `weave.Evaluation`
Cette section montre comment mesurer les performances de votre modèle sur un jeu de données fixe afin de pouvoir comparer quantitativement les itérations.
Les évaluations vous aident à mesurer les performances de vos applications. Avec la classe [`weave.Evaluation`](/fr/weave/guides/core-types/evaluations), vous pouvez capturer les performances de votre modèle sur des tâches ou des jeux de données spécifiques, ce qui vous aide à comparer différents modèles et différentes itérations de votre application. L'exemple suivant montre comment évaluer le modèle créé dans la section précédente :
```python lines {25,32,36} theme={null}
import asyncio
from llama_index.core.evaluation import CorrectnessEvaluator
eval_examples = [
{
"id": "0",
"query": "What programming language did Paul Graham learn to teach himself AI when he was in college?",
"ground_truth": "Paul Graham learned Lisp to teach himself AI when he was in college.",
},
{
"id": "1",
"query": "What was the name of the startup Paul Graham co-founded that was eventually acquired by Yahoo?",
"ground_truth": "The startup Paul Graham co-founded that was eventually acquired by Yahoo was called Viaweb.",
},
{
"id": "2",
"query": "What is the capital city of France?",
"ground_truth": "I cannot answer this question because no information was provided in the text.",
},
]
llm_judge = OpenAI(model="gpt-4", temperature=0.0)
evaluator = CorrectnessEvaluator(llm=llm_judge)
@weave.op()
def correctness_evaluator(query: str, ground_truth: str, output: dict):
result = evaluator.evaluate(
query=query, reference=ground_truth, response=output["response"]
)
return {"correctness": float(result.score)}
evaluation = weave.Evaluation(dataset=eval_examples, scorers=[correctness_evaluator])
rag_pipeline = SimpleRAGPipeline()
asyncio.run(evaluation.evaluate(rag_pipeline))
```
Cette évaluation s’appuie sur l’exemple de la section précédente. Pour évaluer avec `weave.Evaluation`, vous avez besoin d’un jeu de données d’évaluation, d’une fonction de scorer et d’un `weave.Model`. Ces exigences s’appliquent à trois composants clés :
* Les clés des `dict` d’échantillons d’évaluation doivent correspondre aux arguments de la fonction de scorer et de la méthode `predict` du `weave.Model`.
* Le `weave.Model` doit avoir une méthode nommée `predict`, `infer` ou `forward`. Vous devez décorer cette méthode avec `weave.op()` pour le traçage.
* La fonction de scorer doit être décorée avec `weave.op()` et doit avoir `output` comme argument nommé.
[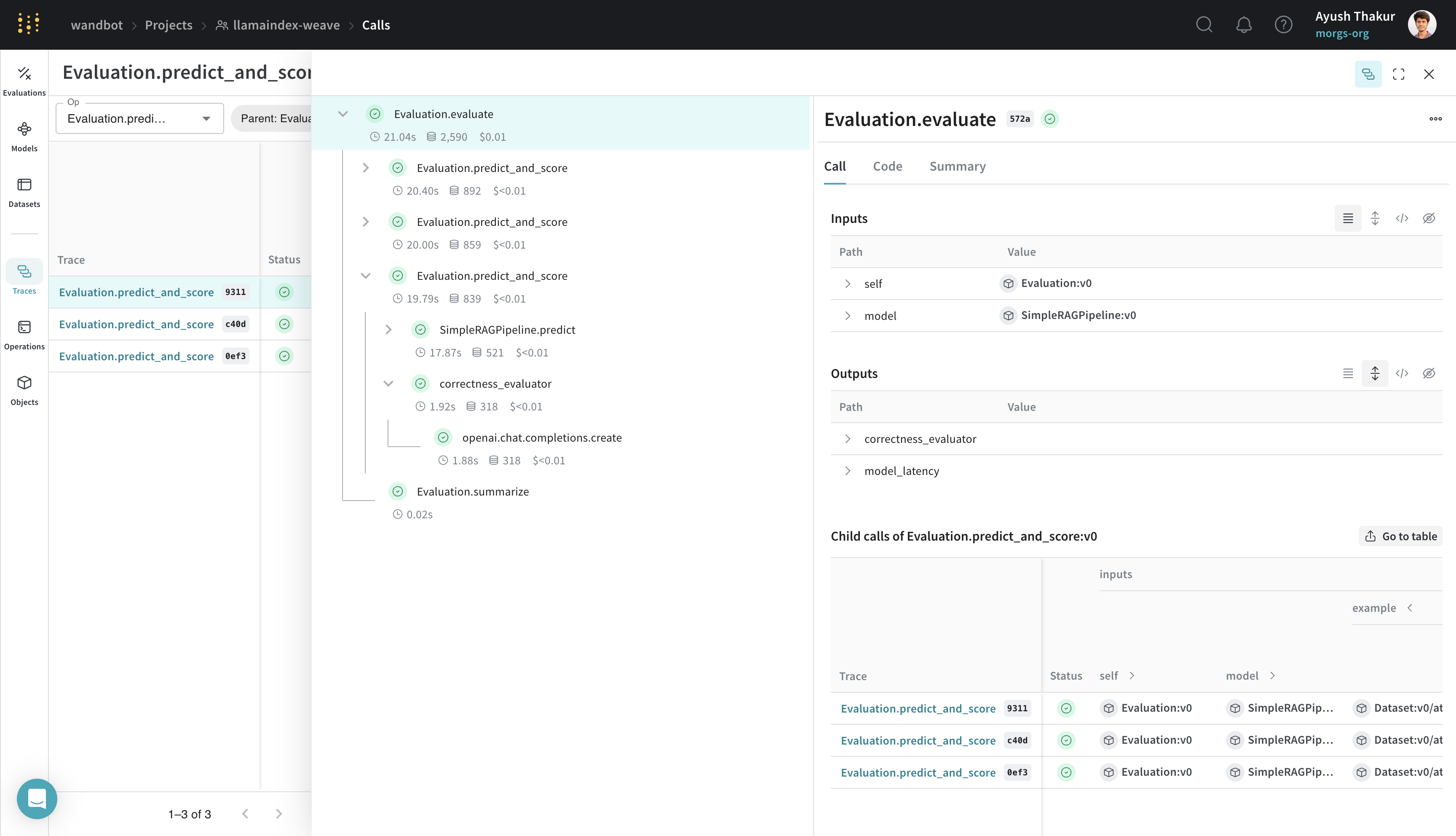 ](https://wandb.ai/wandbot/llamaindex-weave/weave/calls?filter=%7B%22opVersionRefs%22%3A%5B%22weave%3A%2F%2F%2Fwandbot%2Fllamaindex-weave%2Fop%2FEvaluation.predict_and_score%3ANmwfShfFmgAhDGLXrF6Xn02T9MIAsCXBUcifCjyKpOM%22%5D%2C%22parentId%22%3A%2233491e66-b580-47fa-9d43-0cd6f1dc572a%22%7D\&peekPath=%2Fwandbot%2Fllamaindex-weave%2Fcalls%2F33491e66-b580-47fa-9d43-0cd6f1dc572a%3Ftracetree%3D1)
En intégrant Weave à LlamaIndex, vous pouvez assurer une journalisation et une surveillance complètes de vos applications LLM, ce qui rationalise le débogage et l’optimisation des performances grâce à l’évaluation.
](https://wandb.ai/wandbot/llamaindex-weave/weave/calls?filter=%7B%22opVersionRefs%22%3A%5B%22weave%3A%2F%2F%2Fwandbot%2Fllamaindex-weave%2Fop%2FEvaluation.predict_and_score%3ANmwfShfFmgAhDGLXrF6Xn02T9MIAsCXBUcifCjyKpOM%22%5D%2C%22parentId%22%3A%2233491e66-b580-47fa-9d43-0cd6f1dc572a%22%7D\&peekPath=%2Fwandbot%2Fllamaindex-weave%2Fcalls%2F33491e66-b580-47fa-9d43-0cd6f1dc572a%3Ftracetree%3D1)
En intégrant Weave à LlamaIndex, vous pouvez assurer une journalisation et une surveillance complètes de vos applications LLM, ce qui rationalise le débogage et l’optimisation des performances grâce à l’évaluation.