> ## Documentation Index
> Fetch the complete documentation index at: https://docs.wandb.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# NVIDIA NIM
> Utilisez Weave pour capturer les traces et journaliser les appels LLM effectués via la bibliothèque ChatNVIDIA
Weave assure automatiquement le suivi des appels LLM effectués via la bibliothèque [ChatNVIDIA](https://python.langchain.com/docs/integrations/chat/nvidia_ai_endpoints/) et les journalise une fois `weave.init()` appelé. Ce guide montre aux développeurs Python utilisant ChatNVIDIA comment capturer les traces, encapsuler leurs propres fonctions sous forme d'Ops et organiser des expériences avec la classe `Model` de Weave afin de déboguer, d'itérer et de comparer plus efficacement des applications LLM.
Pour découvrir les derniers tutoriels, consultez [Weights & Biases sur NVIDIA](https://wandb.ai/site/partners/nvidia).
## Tracing
Stocker les traces des applications LLM dans une base de données centrale, aussi bien pendant le développement qu’en production, vous aide à déboguer les problèmes et à constituer un jeu de données d’exemples difficiles sur lequel effectuer des évaluations à mesure que vous améliorez votre application. La section suivante montre comment activer le tracing automatique pour les appels ChatNVIDIA.
Weave peut automatiquement capturer les traces de la [bibliothèque Python ChatNVIDIA](https://python.langchain.com/docs/integrations/chat/nvidia_ai_endpoints/).
Commencez à capturer les traces en appelant `weave.init([PROJECT-NAME])` avec le nom de projet de votre choix.
```python lines {4} theme={null}
from langchain_nvidia_ai_endpoints import ChatNVIDIA
import weave
client = ChatNVIDIA(model="mistralai/mixtral-8x7b-instruct-v0.1", temperature=0.8, max_tokens=64, top_p=1)
weave.init('emoji-bot')
messages=[
{
"role": "system",
"content": "You are AGI. You will be provided with a message, and your task is to respond using emojis only."
}]
response = client.invoke(messages)
```
Après avoir exécuté ce code, Weave capture l’appel ChatNVIDIA sous le nom de projet que vous avez indiqué, où vous pouvez inspecter les entrées, les sorties et les métadonnées.
```plaintext theme={null}
Cette fonctionnalité n’est pas encore disponible en TypeScript, car cette bibliothèque existe uniquement en Python.
```
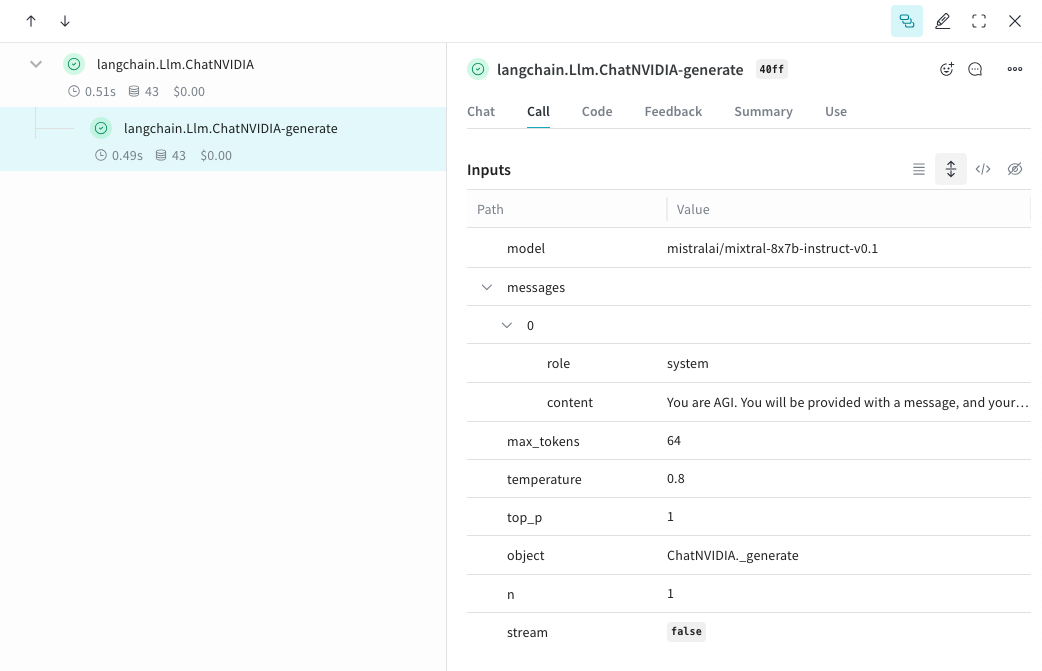
## Suivez vos propres ops
En encapsulant une fonction avec `@weave.op`, vous commencez à capturer les entrées, les sorties et la logique de l’application afin de pouvoir déboguer la façon dont les données circulent dans votre application. Vous pouvez imbriquer des ops en profondeur et créer un arbre de fonctions que vous souhaitez suivre. Cela active également la gestion automatique des versions du code pendant vos expérimentations afin de capturer des détails ad hoc que vous n’avez pas encore validés dans Git.
Créez une fonction décorée avec [`@weave.op`](/fr/weave/guides/tracking/ops) qui appelle la [bibliothèque Python ChatNVIDIA](https://python.langchain.com/docs/integrations/chat/nvidia_ai_endpoints/).
Dans l’exemple suivant, deux fonctions sont encapsulées avec `op`. Cela montre comment des étapes intermédiaires, comme l’étape de récupération dans une application RAG, influencent le comportement de votre application.
```python lines {1,9,11,29,31,33} theme={null}
import weave
from langchain_nvidia_ai_endpoints import ChatNVIDIA
import requests, random
PROMPT="""Emulate the Pokedex from early Pokémon episodes. State the name of the Pokemon and then describe it.
Your tone is informative yet sassy, blending factual details with a touch of dry humor. Be concise, no more than 3 sentences. """
POKEMON = ['pikachu', 'charmander', 'squirtle', 'bulbasaur', 'jigglypuff', 'meowth', 'eevee']
client = ChatNVIDIA(model="mistralai/mixtral-8x7b-instruct-v0.1", temperature=0.7, max_tokens=100, top_p=1)
@weave.op
def get_pokemon_data(pokemon_name):
# Il s’agit d’une étape de votre application, comme l’étape de récupération dans une application RAG
url = f"https://pokeapi.co/api/v2/pokemon/{pokemon_name}"
response = requests.get(url)
if response.status_code == 200:
data = response.json()
name = data["name"]
types = [t["type"]["name"] for t in data["types"]]
species_url = data["species"]["url"]
species_response = requests.get(species_url)
evolved_from = "Unknown"
if species_response.status_code == 200:
species_data = species_response.json()
if species_data["evolves_from_species"]:
evolved_from = species_data["evolves_from_species"]["name"]
return {"name": name, "types": types, "evolved_from": evolved_from}
else:
return None
@weave.op
def pokedex(name: str, prompt: str) -> str:
# Il s’agit de votre op racine, qui appelle d’autres ops
data = get_pokemon_data(name)
if not data: return "Error: Unable to fetch data"
messages=[
{"role": "system","content": prompt},
{"role": "user", "content": str(data)}
]
response = client.invoke(messages)
return response.content
weave.init('pokedex-nvidia')
# Obtenir les données d’un Pokémon spécifique
pokemon_data = pokedex(random.choice(POKEMON), PROMPT)
```
Accédez à Weave et cliquez sur `get_pokemon_data` dans l’interface utilisateur pour voir les entrées et les sorties de cette étape.
```plaintext theme={null}
Cette fonctionnalité n’est pas encore disponible en TypeScript, car cette bibliothèque n’existe qu’en Python.
```
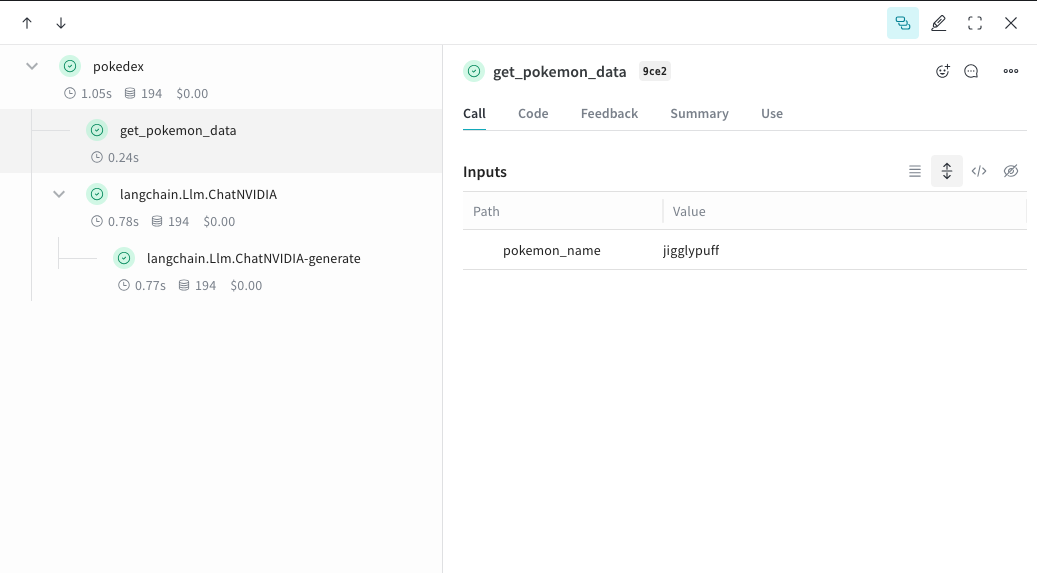
## Créer un `Model` pour expérimenter plus facilement
Il est difficile d’organiser une expérimentation lorsqu’il y a de nombreux éléments à prendre en compte. En utilisant la classe [`Model`](/fr/weave/guides/core-types/models), vous pouvez capturer et organiser les détails expérimentaux de votre application, comme le prompt système ou le modèle que vous utilisez. Cela vous aide à structurer et comparer les différentes itérations de votre application.
En plus de la gestion des versions du code et de la capture des entrées et des sorties, les [`Model`](/fr/weave/guides/core-types/models) capturent des paramètres structurés qui contrôlent le comportement de votre application, ce qui permet d’identifier facilement les paramètres les plus efficaces. Vous pouvez également utiliser les Weave Models avec `serve` et les [`Evaluation`](/fr/weave/guides/core-types/evaluations).
Dans l’exemple suivant, vous pouvez expérimenter avec `model` et `system_message`. Chaque fois que vous en modifiez un, vous obtenez une nouvelle *version* de `GrammarCorrectorModel`.
```python lines theme={null}
import weave
from langchain_nvidia_ai_endpoints import ChatNVIDIA
weave.init('grammar-nvidia')
class GrammarCorrectorModel(weave.Model): # Remplacez par `weave.Model`
system_message: str
@weave.op()
def predict(self, user_input): # Remplacez par `predict`
client = ChatNVIDIA(model="mistralai/mixtral-8x7b-instruct-v0.1", temperature=0, max_tokens=100, top_p=1)
messages=[
{
"role": "system",
"content": self.system_message
},
{
"role": "user",
"content": user_input
}
]
response = client.invoke(messages)
return response.content
corrector = GrammarCorrectorModel(
system_message = "You are a grammar checker, correct the following user input.")
result = corrector.predict("That was so easy, it was a piece of pie!")
print(result)
```
```plaintext theme={null}
Cette fonctionnalité n’est pas encore disponible en TypeScript, car cette bibliothèque n’existe qu’en Python.
```
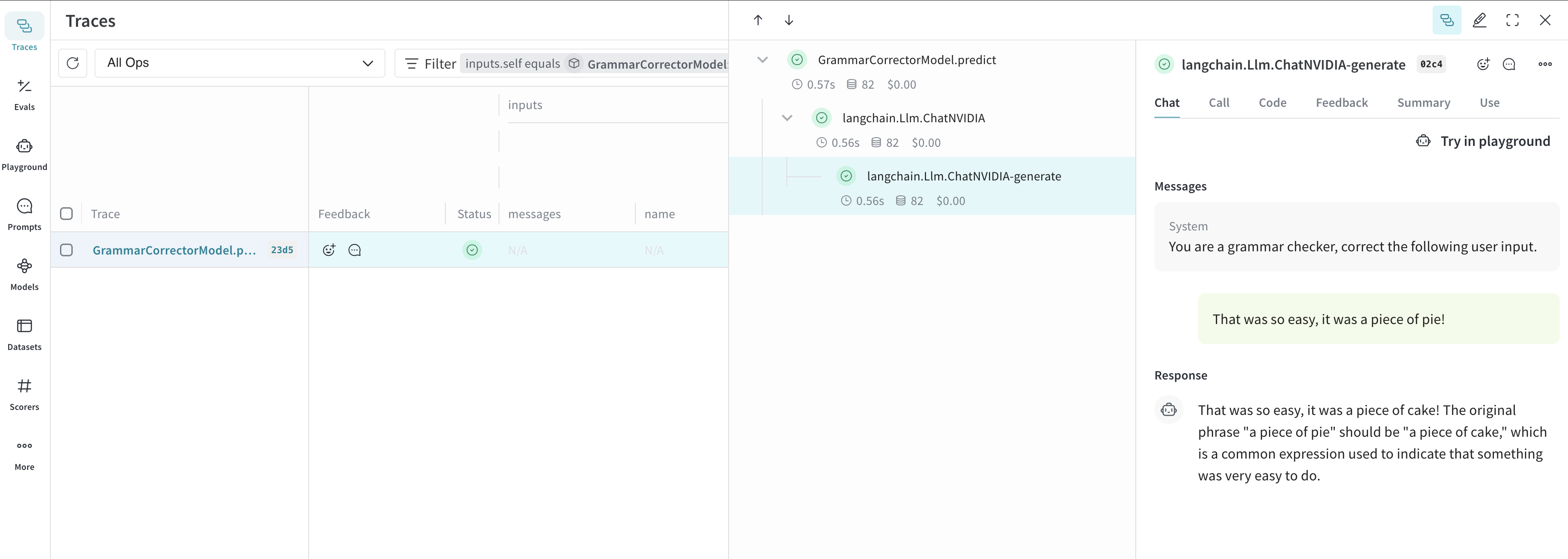
## Informations d’utilisation
Les notes suivantes décrivent les fonctionnalités prises en charge par l’intégration ChatNVIDIA.
L’intégration ChatNVIDIA prend en charge `invoke`, `stream` et leurs variantes asynchrones. Elle prend également en charge l’utilisation d’outils.
Comme ChatNVIDIA est conçu pour être utilisé avec de nombreux types de modèles, il ne prend pas en charge les appels de fonction.