> ## Documentation Index
> Fetch the complete documentation index at: https://docs.wandb.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Smolagents
> Suivez les applications Smolagents avec le traçage automatique de Weave, en capturant les appels d'outils, les inférences de modèle et les flux de travail d'agent en plusieurs étapes.
Tous les exemples de code présentés sur cette page sont en Python.
Cette page explique comment intégrer [Smolagents](https://huggingface.co/docs/smolagents/en/index) à W\&B Weave pour suivre et analyser vos applications agentiques. Elle s’adresse aux développeurs qui créent des flux de travail agentiques et qui souhaitent mieux comprendre leurs appels de modèle et d’outils. Vous apprendrez à journaliser les inférences de modèle, à surveiller les appels de fonction et à organiser les Experiments à l'aide des fonctionnalités de traçage et de gestion des versions de Weave. En suivant les exemples fournis, vous pourrez obtenir des informations précieuses, déboguer efficacement vos applications et comparer différentes configurations de modèle (le tout dans l'interface web de Weave).
## Aperçu
Smolagents est un framework qui offre un minimum d’abstractions pour créer des applications agentiques. Il prend en charge plusieurs fournisseurs de LLM, comme OpenAI, Hugging Face Transformers et Anthropic.
Weave capture automatiquement les traces de [Smolagents](https://huggingface.co/docs/smolagents/en/index). Pour commencer le suivi, appelez `weave.init()` et utilisez la bibliothèque comme d’habitude.
## Prérequis
Avant de commencer, vous devez installer les bibliothèques requises et configurer l’accès au fournisseur de LLM de votre choix.
1. Avant de pouvoir utiliser Smolagents avec Weave, vous devez installer les bibliothèques requises ou les mettre à jour vers leur dernière version. La commande suivante installe ou met à jour `smolagents`, `openai` et `weave`, et masque la sortie :
```bash theme={null}
pip install -U smolagents openai weave -qqq
```
2. Smolagents prend en charge plusieurs fournisseurs de LLM, comme OpenAI, Hugging Face Transformers et Anthropic. Définissez la clé API du fournisseur de votre choix afin que Smolagents puisse s’authentifier lors de l’appel du modèle. Définissez la variable d’environnement correspondante :
```python lines theme={null}
import os
import getpass
os.environ["OPENAI_API_KEY"] = getpass.getpass("Enter your OpenAI API key: ")
```
## Traçage de base
Cette section montre comment Weave capture automatiquement les traces d’un flux de travail Smolagents de base.
Stocker les traces des applications de modèles de langage dans un emplacement central est essentiel, aussi bien pendant le développement qu’en production. Ces traces facilitent le débogage et servent de jeux de données pour améliorer votre application.
Weave capture automatiquement les traces pour [Smolagents](https://huggingface.co/docs/smolagents/en/index). Pour commencer le suivi, initialisez Weave en appelant `weave.init()`, puis utilisez la bibliothèque comme d’habitude.
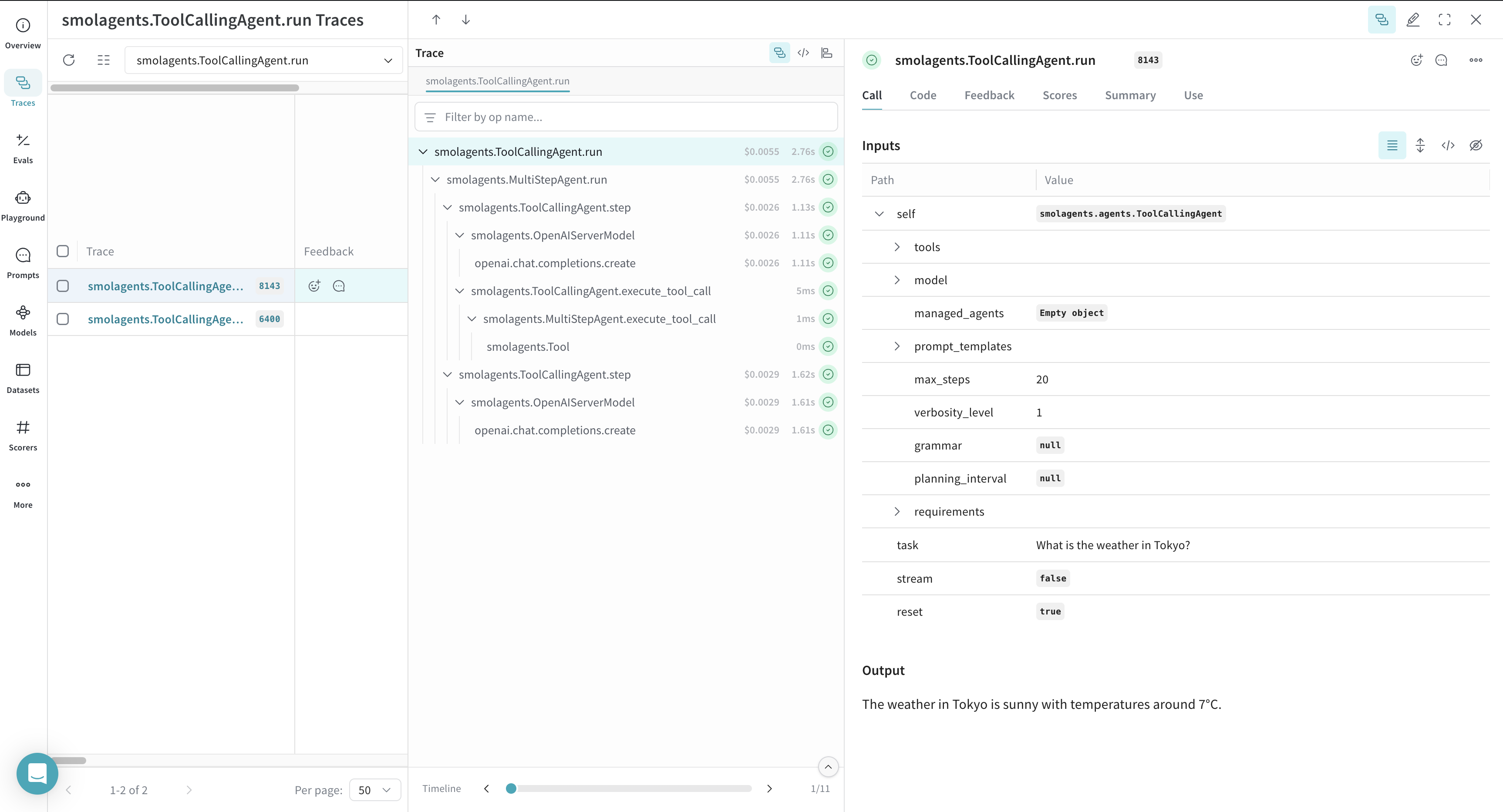
L’exemple suivant montre comment journaliser les appels d’Inférence d’un agent LLM utilisant des outils avec Weave. Dans ce scénario :
* Vous définissez un modèle de langage (le `gpt-4o` d’OpenAI) à l’aide de `OpenAIServerModel` de Smolagents.
* Vous configurez un outil de recherche (`DuckDuckGoSearchTool`) que l’agent peut invoquer si nécessaire.
* Vous créez un `ToolCallingAgent` en lui passant l’outil et le modèle.
* Vous exécutez une requête via l’agent, ce qui déclenche l’outil de recherche.
* Weave journalise chaque appel de fonction et de modèle, puis les rend disponibles pour inspection dans son interface web.
```python lines theme={null}
import weave
from smolagents import DuckDuckGoSearchTool, OpenAIServerModel, ToolCallingAgent
# Initialiser Weave
weave.init(project_name="smolagents")
# Définir votre fournisseur LLM pris en charge par Smolagents
model = OpenAIServerModel(model_id="gpt-4o")
# Définir un outil de recherche web DuckDuckGo basé sur votre requête
search_tool = DuckDuckGoSearchTool()
# Définir un agent appelant des outils
agent = ToolCallingAgent(tools=[search_tool], model=model)
answer = agent.run(
"Get me just the title of the page at url 'https://wandb.ai/geekyrakshit/story-illustration/reports/Building-a-GenAI-assisted-automatic-story-illustrator--Vmlldzo5MTYxNTkw'?"
)
```
Une fois l’exemple de code exécuté, accédez au tableau de bord de votre projet Weave pour consulter les traces.
## Traçage des outils personnalisés
En plus des outils intégrés, vous pouvez étendre vos agents avec des outils personnalisés, et Weave peut également tracer ces appels.
Vous pouvez déclarer des outils personnalisés pour vos flux de travail agentiques en décorant une fonction avec `@tool` de `smolagents` ou en héritant de la classe `smolagents.Tool`.
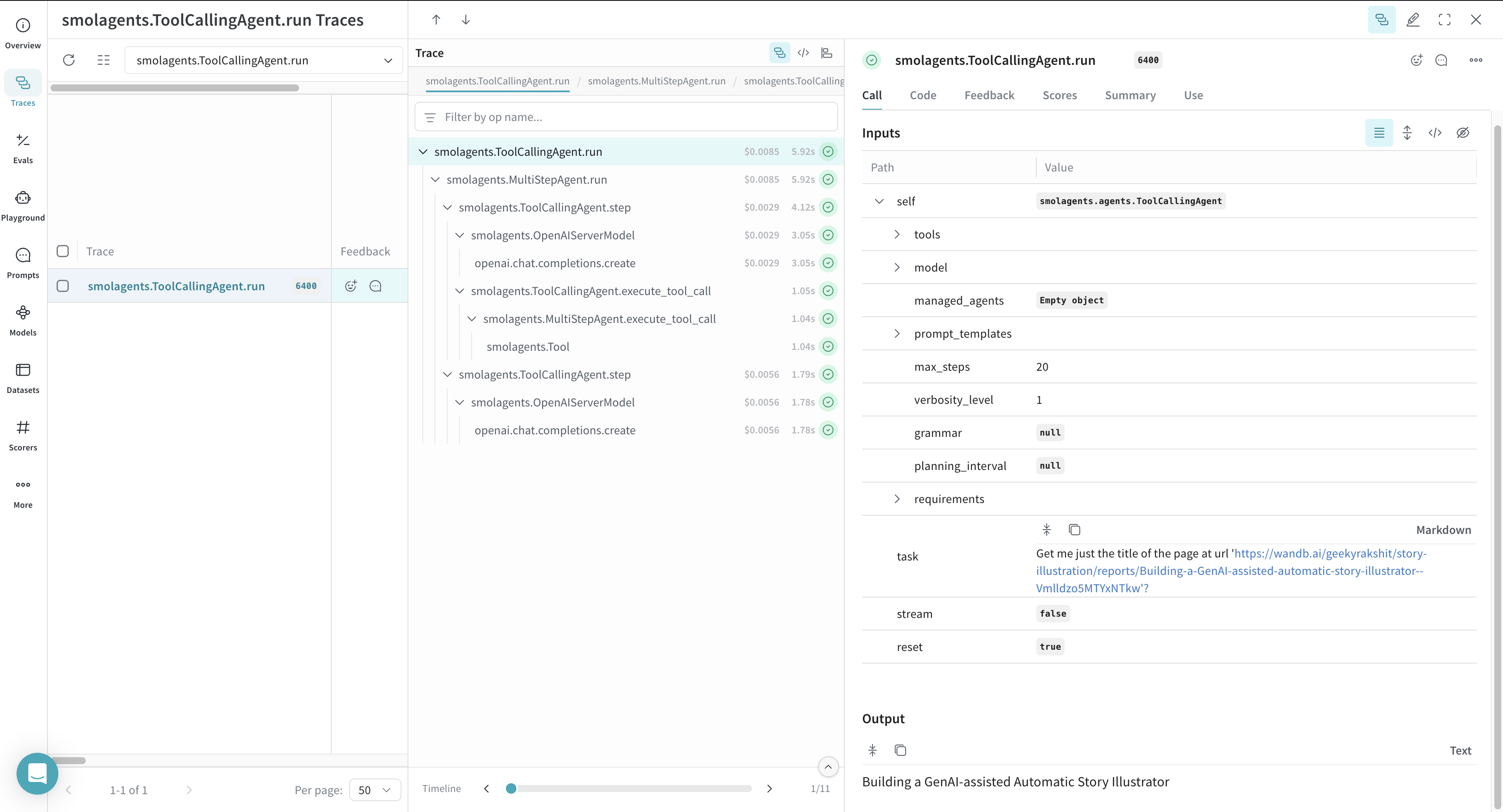
Weave assure automatiquement le suivi des appels d’outil personnalisés pour vos flux de travail `smolagents`. L’exemple suivant montre comment journaliser un appel d’outil personnalisé `smolagents` avec Weave :
* Vous définissez une fonction personnalisée `get_weather` et la décorez avec `@tool` de Smolagents, ce qui permet à l’agent de l’appeler dans le cadre de son processus de raisonnement.
* La fonction accepte un emplacement ainsi qu’un indicateur facultatif pour renvoyer la température en Celsius.
* Vous instanciez un modèle de langage à l’aide de `OpenAIServerModel`.
* Vous créez un `ToolCallingAgent` avec l’outil personnalisé et le modèle.
* Lorsque l’agent exécute la requête, il sélectionne et appelle l’outil `get_weather`.
* Weave journalise à la fois l’inférence du modèle et l’appel à l’outil personnalisé, y compris les arguments et les valeurs de retour.
```python lines theme={null}
from typing import Optional
import weave
from smolagents import OpenAIServerModel, ToolCallingAgent, tool
weave.init(project_name="smolagents")
@tool
def get_weather(location: str, celsius: Optional[bool] = False) -> str:
"""
Get the weather in the next few days for a given location.
Args:
location: The location.
celsius: Whether to use Celsius for temperature.
"""
return f"The weather in {location} is sunny with temperatures around 7°C."
model = OpenAIServerModel(model_id="gpt-4o")
agent = ToolCallingAgent(tools=[get_weather], model=model)
answer = agent.run("What is the weather in Tokyo?")
```
Après avoir exécuté l’exemple de code, accédez au tableau de bord de votre projet Weave pour consulter les traces.