Try in Colab
たった2行で次世代のログ
実験に関連するすべてのプロンプト、ネガティブプロンプト、生成されたメディア、および設定を、たった2行のコードを含めるだけでログできます。ログを始めるためのコードはこちらの2行です: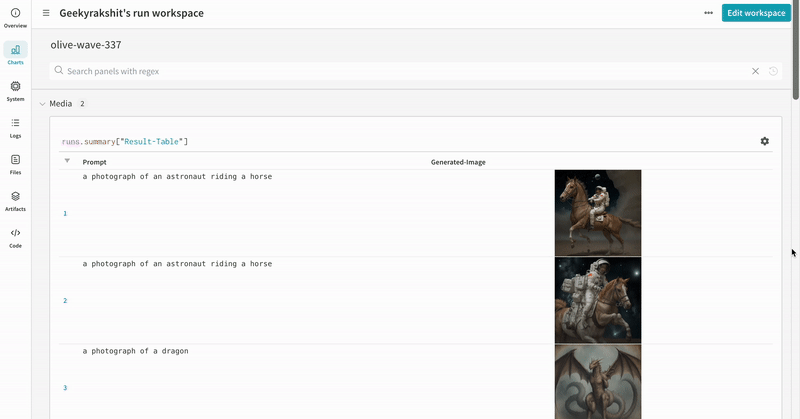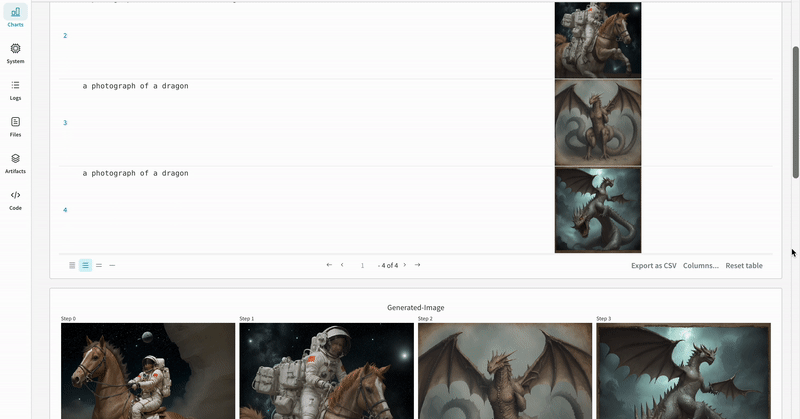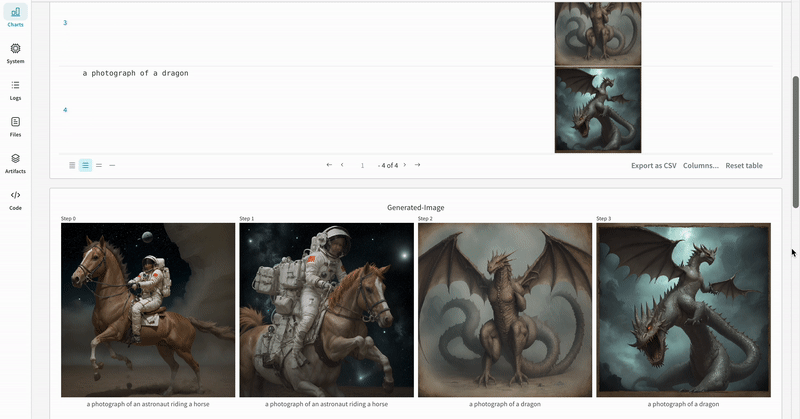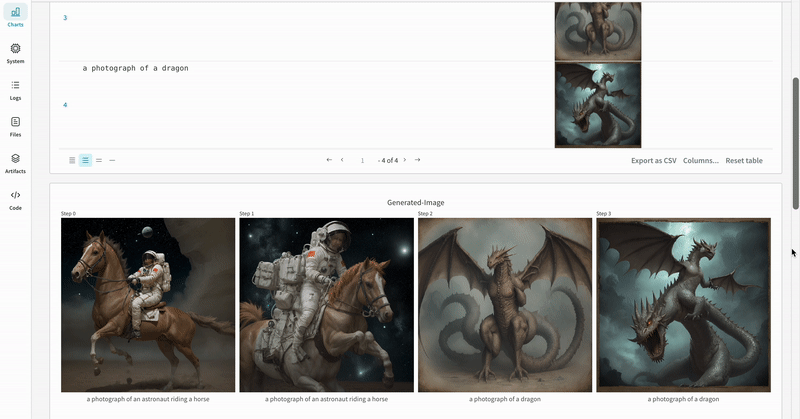
始め方
-
diffusers,transformers,accelerate, およびwandbをインストールします。-
コマンドライン:
-
ノートブック:
-
コマンドライン:
-
autologを使用して Weights & Biases の run を初期化し、すべてのサポートされているパイプライン呼び出しからの入出力を自動的に追跡します。initパラメータを持つautolog()関数を呼び出すことができ、このパラメータはwandb.init()によって要求されるパラメータの辞書が受け入れられます。autolog()を呼び出すと、Weights & Biases の run が初期化され、すべてのサポートされているパイプライン呼び出しからの入力と出力が自動的に追跡されます。- 各パイプライン呼び出しはその run のワークスペース内の独自の table に追跡され、パイプライン呼び出しに関連する設定はその run のワークフローリストに追加されます。
- プロンプト、ネガティブプロンプト、生成されたメディアは
wandb.Tableにログされます。 - シードやパイプライン アーキテクチャーを含む実験に関連するすべての他の設定は、その run の設定セクションに保存されます。
- 各パイプライン呼び出しの生成されたメディアは run の media panels にもログされます。
サポートされているパイプライン呼び出しのリストはこちらから見つけることができます。このインテグレーションの新機能をリクエストしたり、関連するバグを報告したりする場合は、https://github.com/wandb/wandb/issuesで問題をオープンしてください。
例
Autologging
ここでは、autolog の動作を示す簡単なエンドツーエンドの例を示します。- Script
- Notebook
-
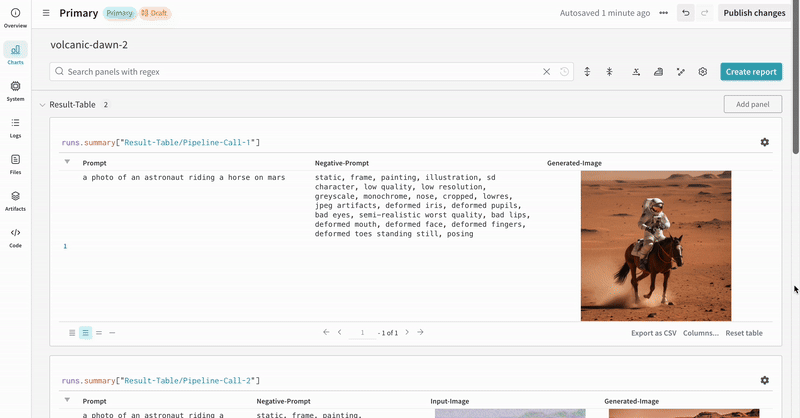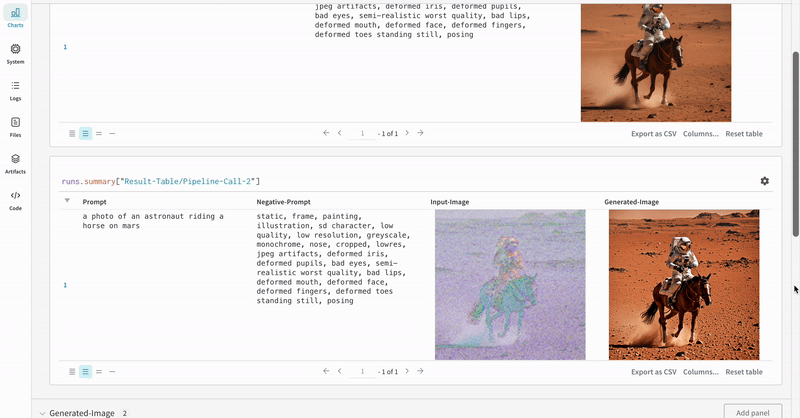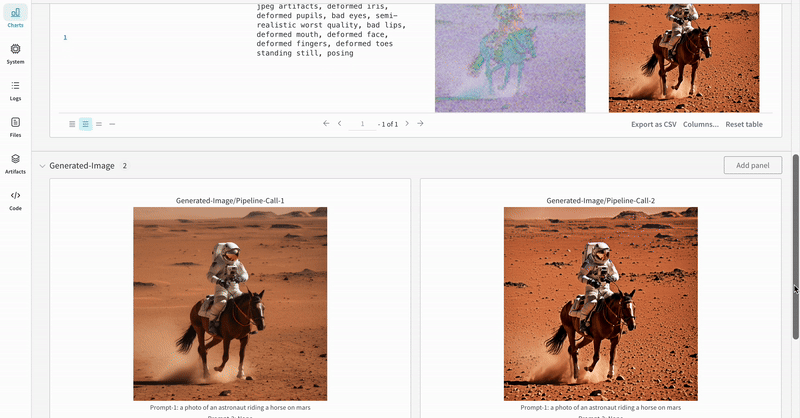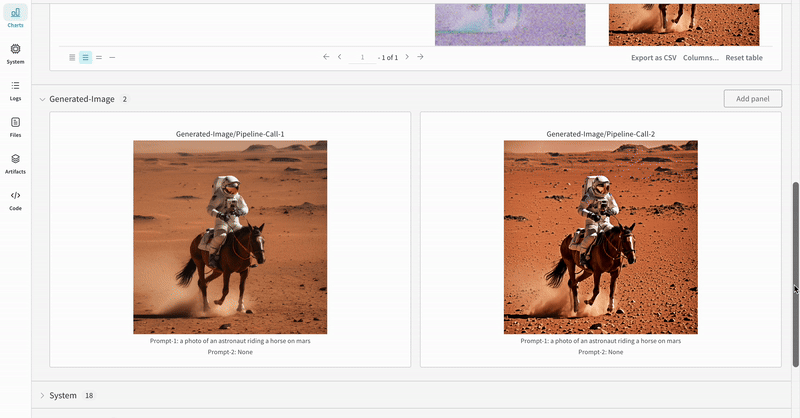
単一の実験の結果:
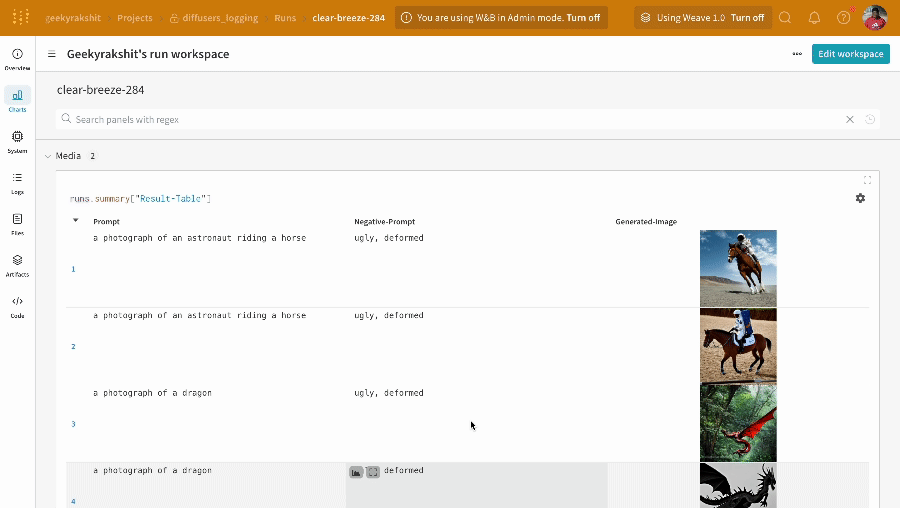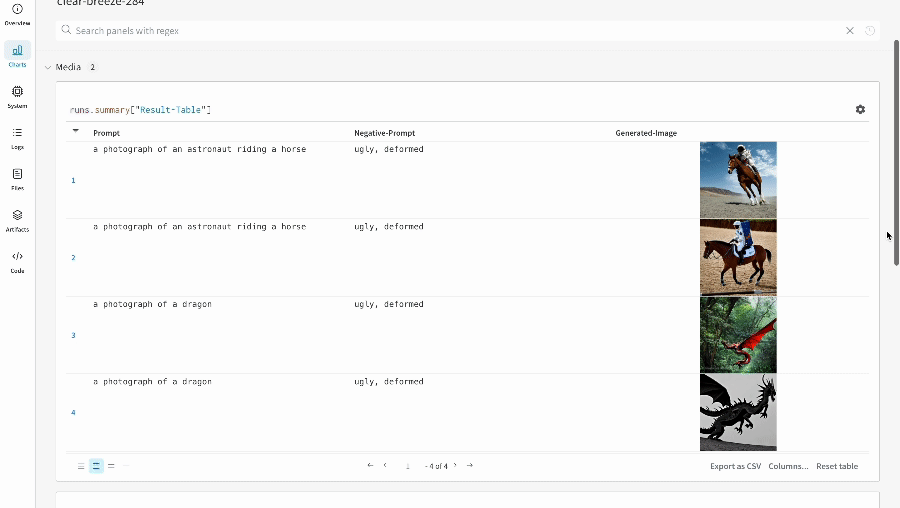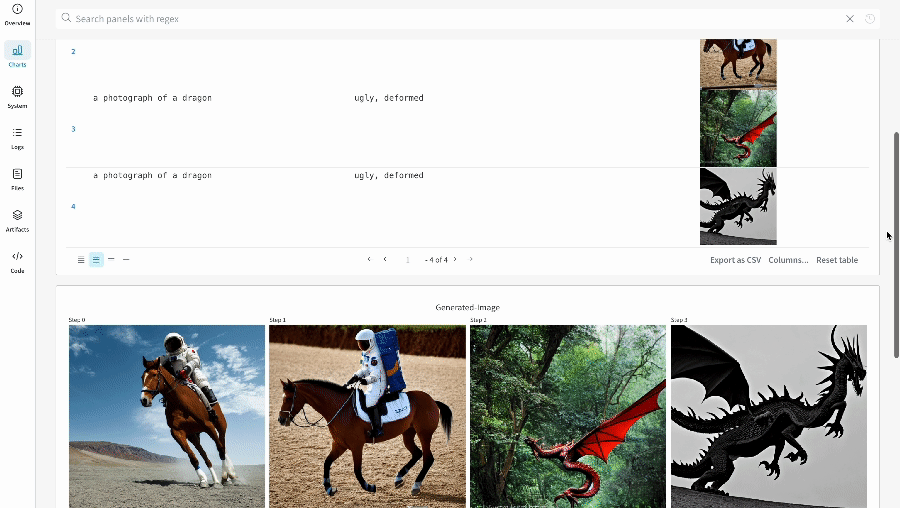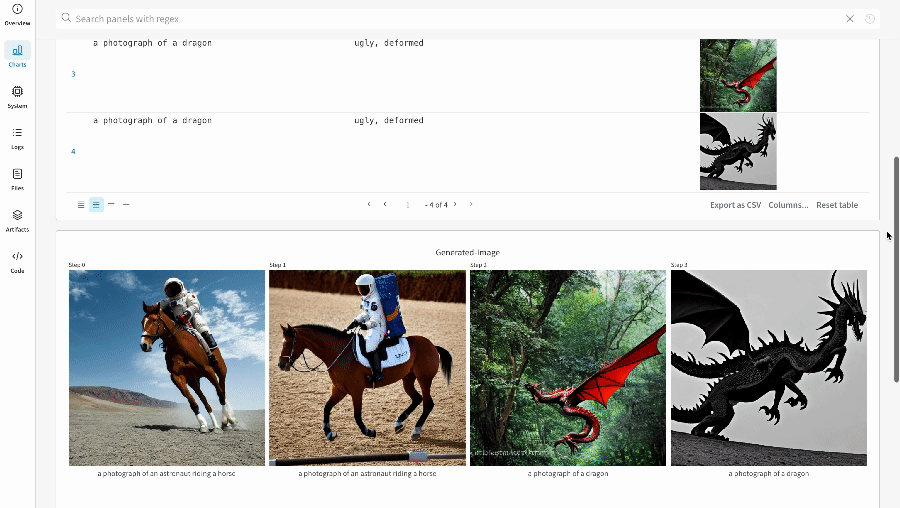
-
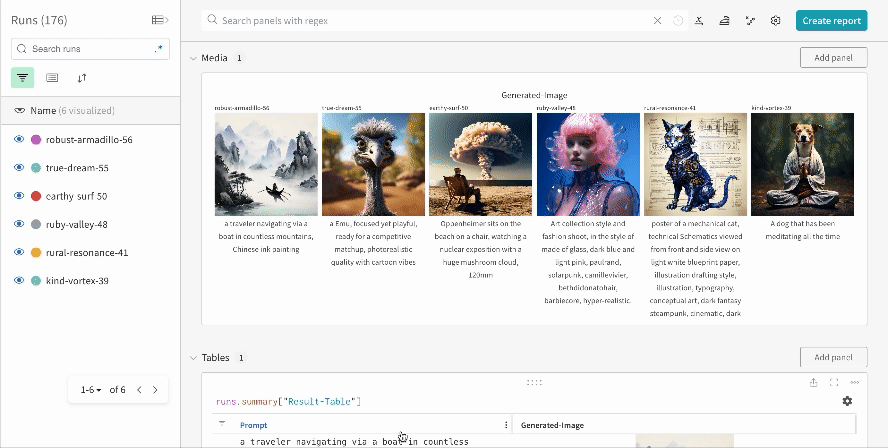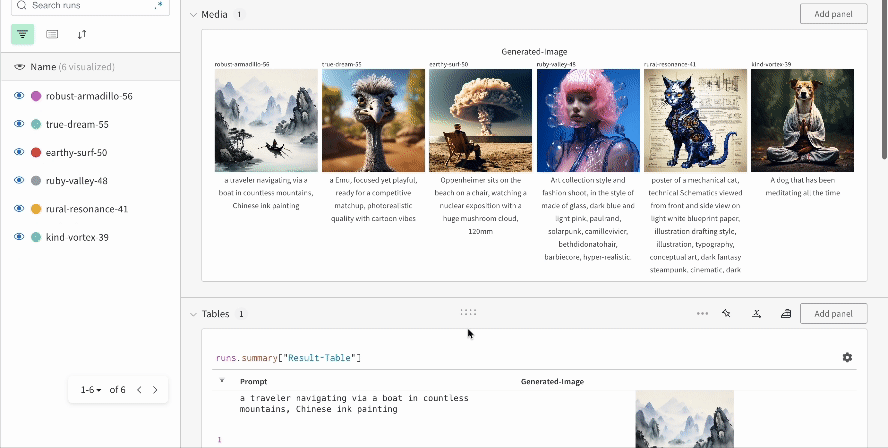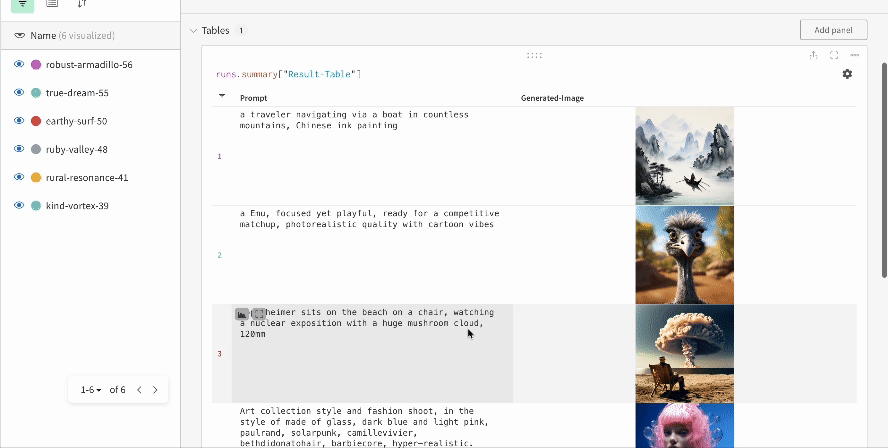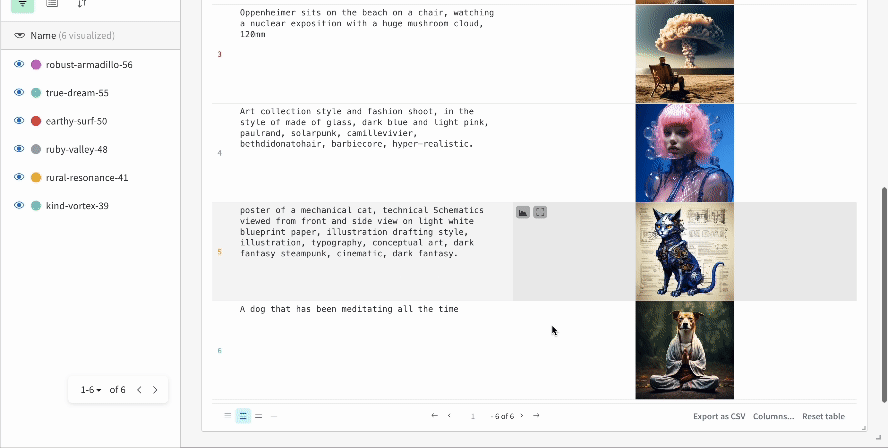
複数の実験の結果:
-
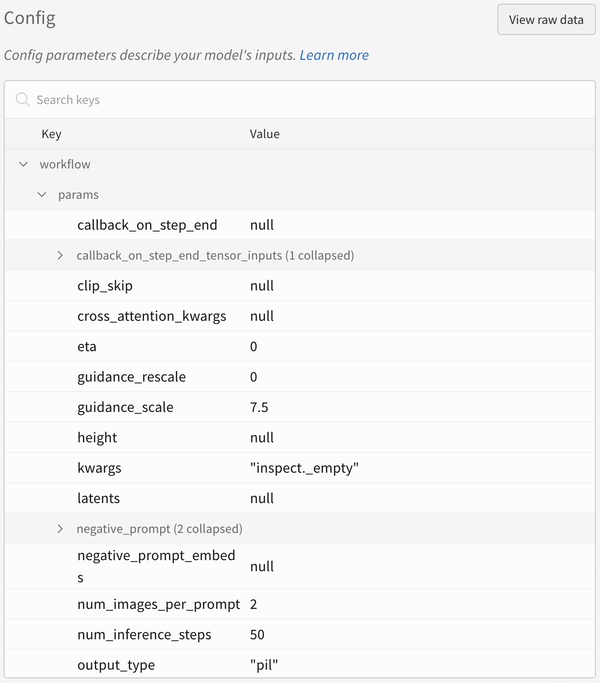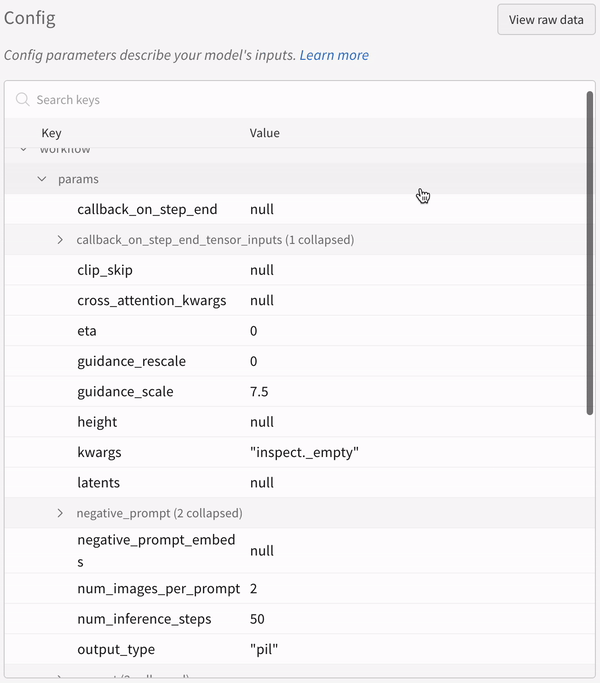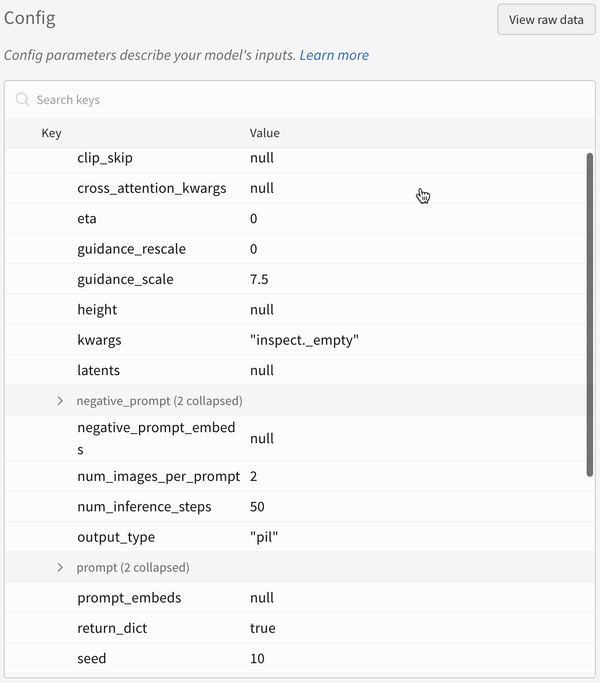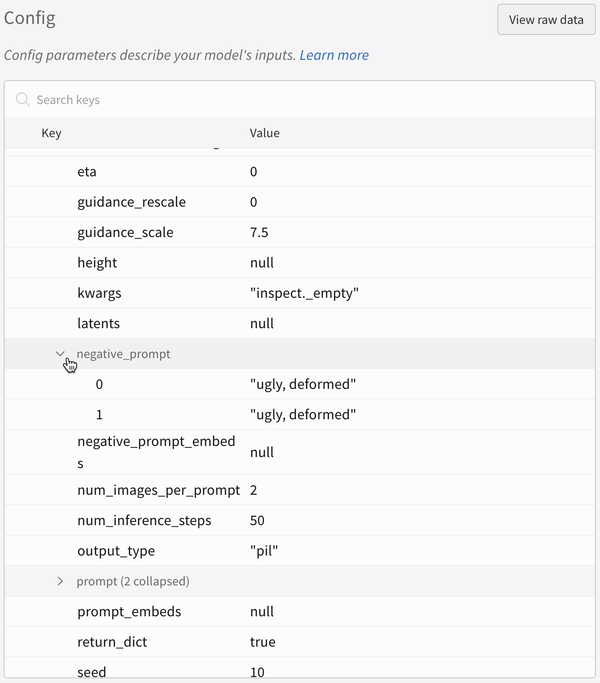
実験の設定:
パイプラインを呼び出した後、IPython ノートブック環境でコードを実行する際には
wandb.finish()を明示的に呼び出す必要があります。Python スクリプトを実行する際は必要ありません。マルチパイプライン ワークフローの追跡
このセクションでは、StableDiffusionXLPipeline で生成された潜在変数が対応するリファイナーによって調整される、典型的なStable Diffusion XL + Refiner ワークフローを使用した autolog のデモンストレーションを行います。
Try in Colab
- Python Script
- Notebook
- Stable Diffusion XL + Refiner の実験の例: