wandb==0.12.11 で有効になり、kfp<2.0.0 が必要です。
登録してAPIキーを作成する
APIキーは、あなたのマシンをW&Bに認証します。APIキーは、ユーザープロファイルから生成できます。より効率的な方法として、https://wandb.ai/authorize に直接行ってAPIキーを生成することができます。表示されたAPIキーをコピーし、パスワードマネージャーなどの安全な場所に保存してください。
- 右上隅のユーザープロファイルアイコンをクリックします。
- User Settings を選択し、API Keys セクションまでスクロールします。
- Reveal をクリックします。表示されたAPIキーをコピーします。APIキーを隠すには、ページをリロードしてください。
wandb ライブラリをインストールしてログイン
ローカルに wandb ライブラリをインストールしてログインするには:
- Command Line
- Python
- Python notebook
-
WANDB_API_KEY環境変数 をAPIキーに設定します。 -
wandbライブラリをインストールしてログインします。
コンポーネントをデコレートする
@wandb_log デコレーターを追加し、通常通りコンポーネントを作成します。これにより、パイプラインを実行するたびに入力/出力パラメータとArtifactsがW&Bに自動的にログされます。
環境変数をコンテナに渡す
環境変数をコンテナに明示的に渡す必要があるかもしれません。双方向リンクのためには、WANDB_KUBEFLOW_URL 環境変数をKubeflow Pipelinesインスタンスの基本URLに設定する必要があります。例えば、https://kubeflow.mysite.comです。
データへのプログラムによるアクセス
Kubeflow Pipelines UI から
W&Bでログされた任意の Run を Kubeflow Pipelines UI でクリックします。Input/OutputとML Metadataタブで入力と出力の詳細を見つけます。VisualizationsタブからW&Bウェブアプリを表示します。
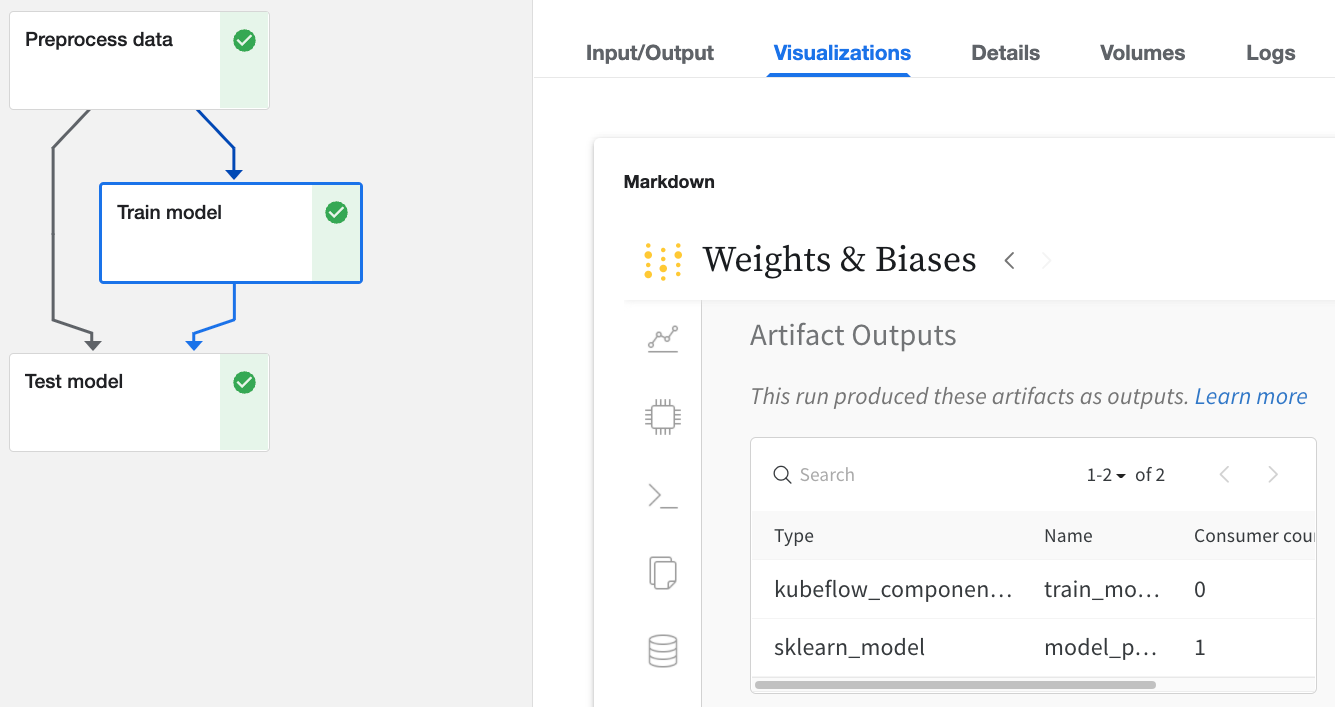
ウェブアプリ UI から
ウェブアプリ UI は Kubeflow Pipelines のVisualizations タブと同じコンテンツを持っていますが、より多くのスペースがあります。ここでウェブアプリ UI についてもっと学びましょう。
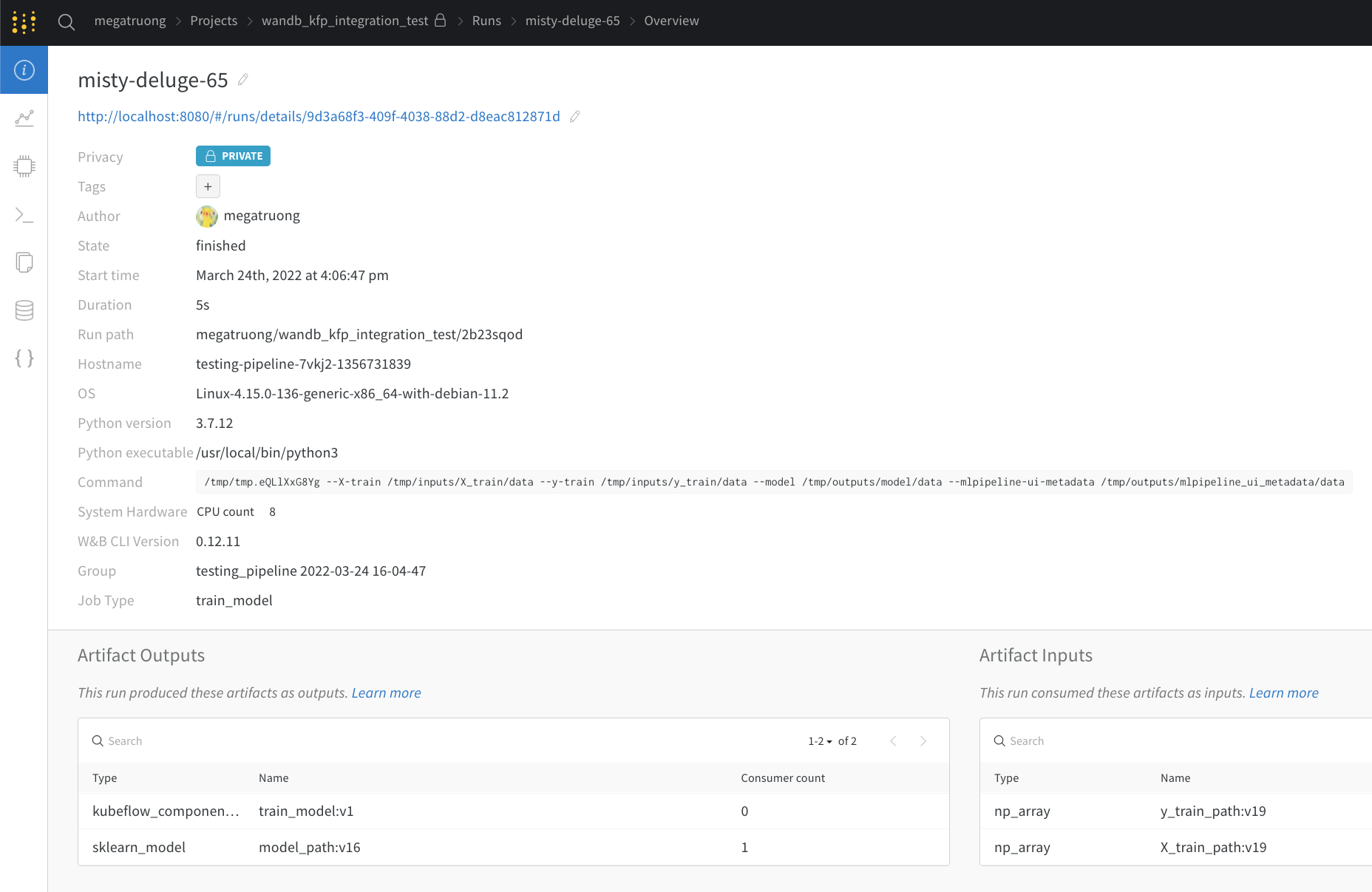
公開APIを通じて(プログラムによるアクセス)
- プログラムによるアクセスのために、私たちの公開APIをご覧ください。
Kubeflow Pipelines と W&B の概念マッピング
ここに、Kubeflow Pipelines の概念を W&B にマッピングしたものがあります。| Kubeflow Pipelines | W&B | W&B 内の場所 |
|---|---|---|
| Input Scalar | config | Overview tab |
| Output Scalar | summary | Overview tab |
| Input Artifact | Input Artifact | Artifacts tab |
| Output Artifact | Output Artifact | Artifacts tab |
細かいログ
ログのコントロールを細かくしたい場合は、コンポーネントにwandb.log と wandb.log_artifact の呼び出しを追加できます。
明示的な wandb.log_artifacts 呼び出しと共に
以下の例では、モデルをトレーニングしています。@wandb_log デコレーターは関連する入力と出力を自動的に追跡します。トレーニングプロセスをログに追加したい場合は、以下のようにそのログを明示的に追加できます。