例: ブログ & Colab
PaddleOCRでICDAR2015データセットを使ってモデルをトレーニングする方法を知るには、こちらをお読みください。さらにGoogle Colabも提供されており、対応するライブW&Bダッシュボードはこちらで利用できます。このブログの中国語バージョンもこちらで利用できます: W&B对您的OCR模型进行训练和调试サインアップしてAPIキーを作成する
APIキーは、W&Bへの認証に使われます。APIキーはユーザーのプロファイルから生成できます。よりスムーズな方法として、直接https://wandb.ai/authorizeにアクセスしてAPIキーを生成することができます。表示されたAPIキーをコピーし、パスワードマネージャーなどの安全な場所に保存してください。
- 右上のユーザープロファイルアイコンをクリックします。
- User Settingsを選択し、API Keysセクションまでスクロールします。
- Revealをクリックします。表示されたAPIキーをコピーします。APIキーを非表示にするには、ページを再読み込みします。
wandbライブラリをインストールしてログインする
wandbライブラリをローカルにインストールしてログインするには:
- Command Line
- Python
- Python notebook
-
WANDB_API_KEY環境変数を自分のAPIキーに設定します。 -
wandbライブラリをインストールしてログインします。
config.ymlファイルにwandbを追加する
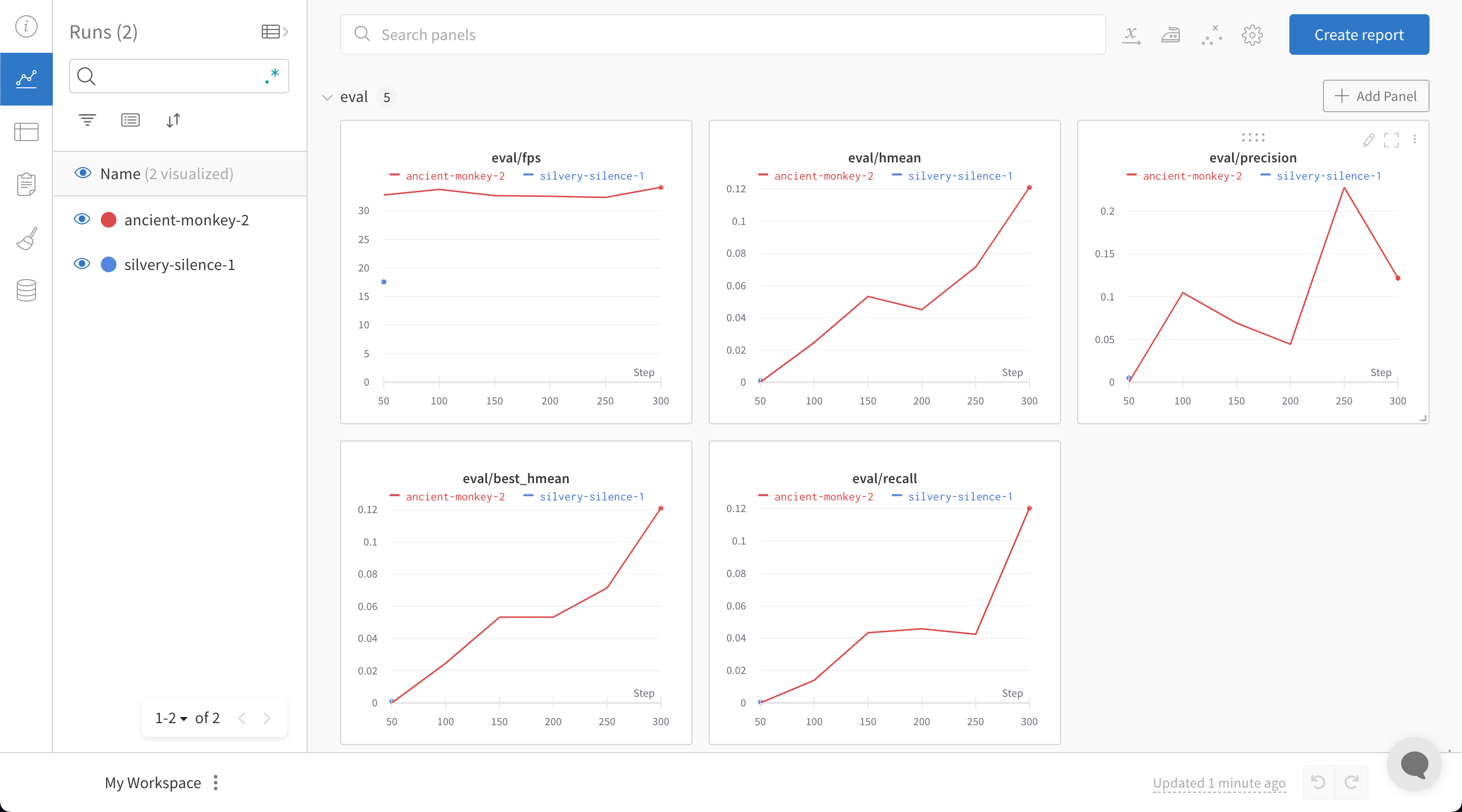
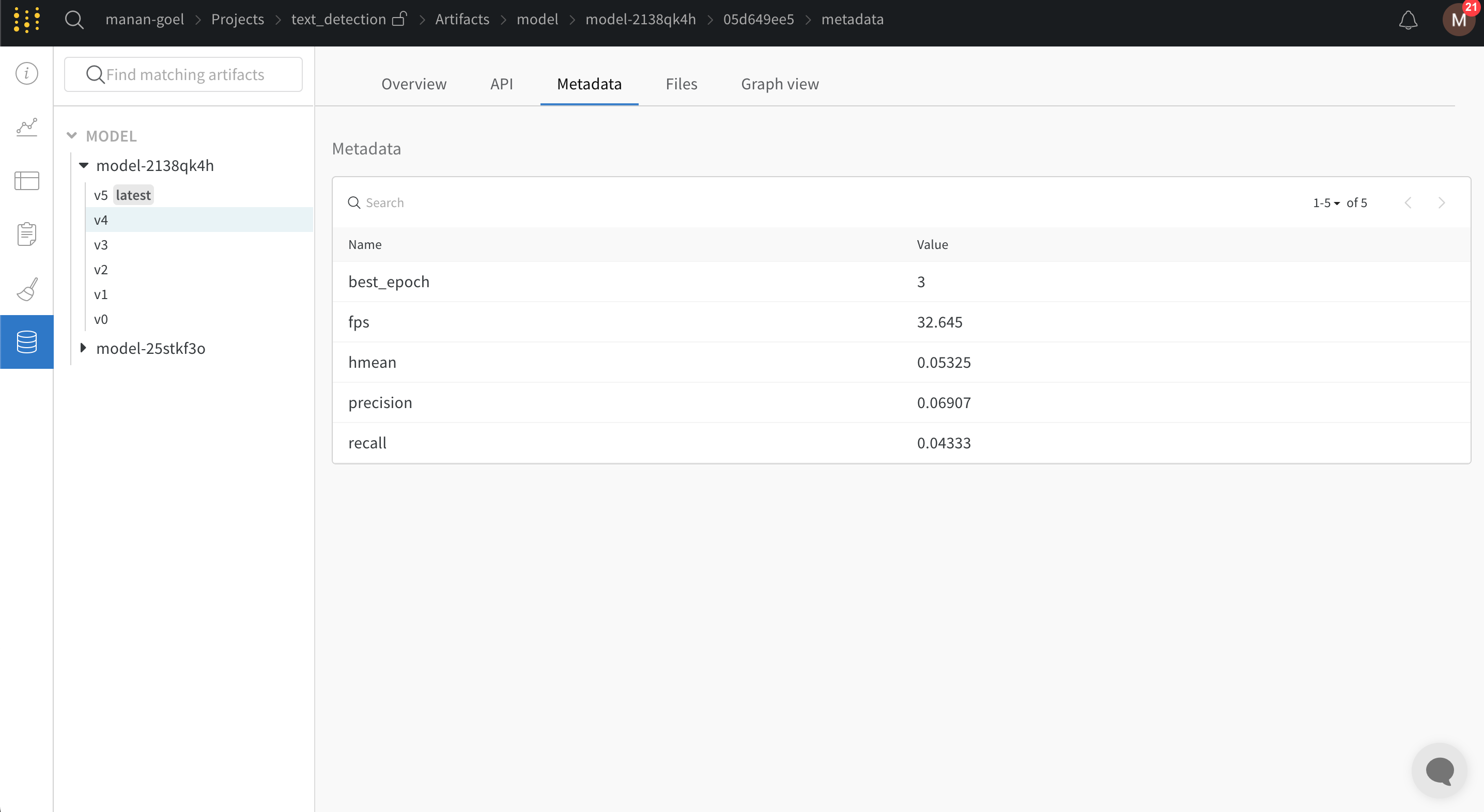
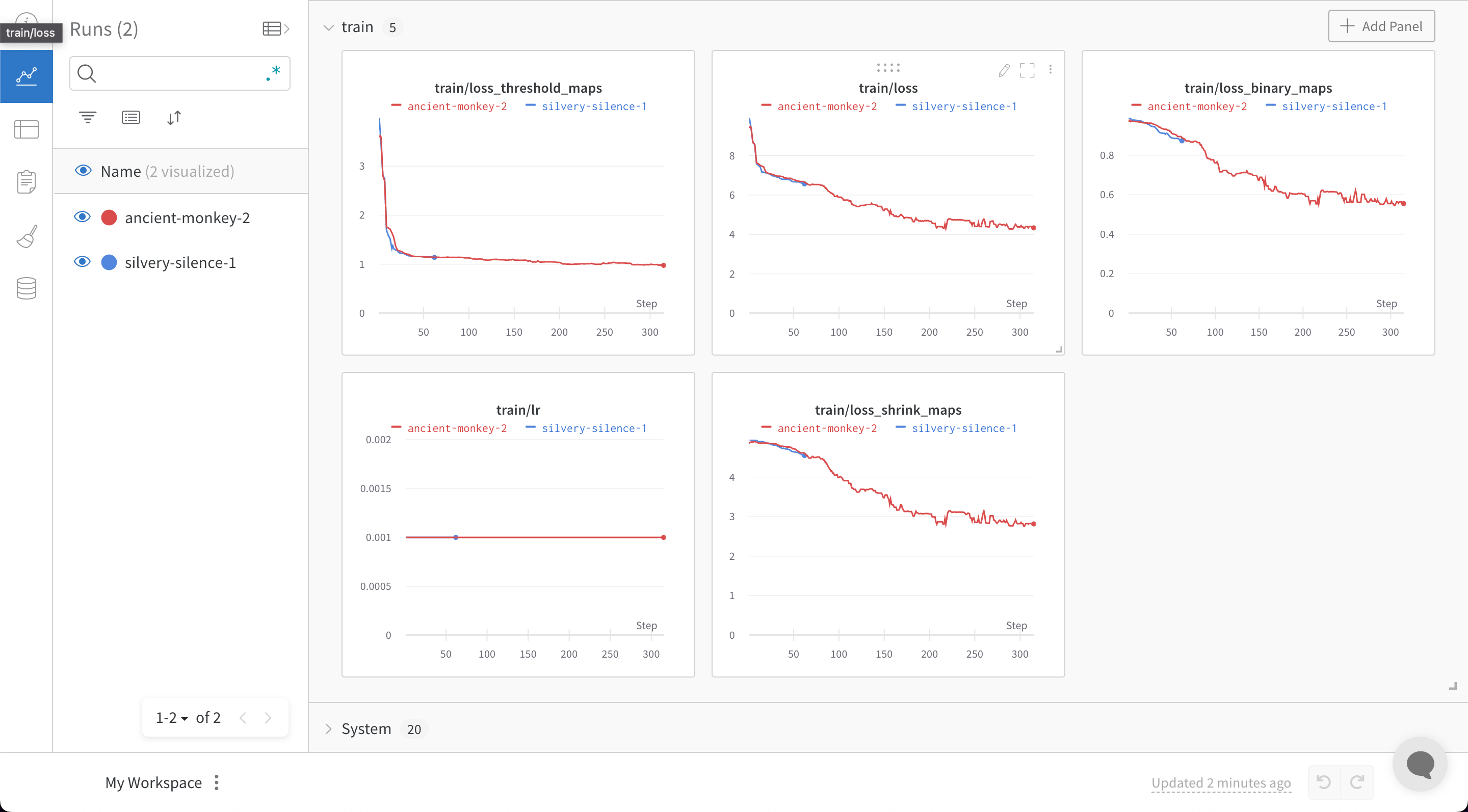
PaddleOCRでは設定変数をyamlファイルで提供する必要があります。設定yamlファイルの最後に次のスニペットを追加することで、すべてのトレーニングおよびバリデーションメトリクスをW&Bダッシュボードに自動的にログ記録するとともに、モデルのチェックポイントも保存されます:
wandb.initに渡したい追加の任意の引数は、yamlファイルのwandbヘッダーの下に追加することもできます:
config.ymlファイルをtrain.pyに渡す
yamlファイルは、PaddleOCRリポジトリ内で利用可能なトレーニングスクリプトへの引数として提供されます。
train.pyファイルを実行するとき、W&Bダッシュボードへのリンクが生成されます: