> ## Documentation Index
> Fetch the complete documentation index at: https://docs.wandb.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# PyTorch
> PyTorch を W&B と統合し、実験管理、データセットのバージョン管理、メトリクス、勾配、モデルをログします。
export const ColabLink = ({url}) =>
Colabで試す
;
## このノートブックで学ぶこと
PyTorchコードにW\&Bを統合し、パイプラインに実験管理を追加する方法を紹介します。
## インストール、インポート、ログイン
```python theme={null}
import os
import random
import numpy as np
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
from tqdm.auto import tqdm
# 決定論的な動作を保証する
torch.backends.cudnn.deterministic = True
random.seed(hash("setting random seeds") % 2**32 - 1)
np.random.seed(hash("improves reproducibility") % 2**32 - 1)
torch.manual_seed(hash("by removing stochasticity") % 2**32 - 1)
torch.cuda.manual_seed_all(hash("so runs are repeatable") % 2**32 - 1)
# デバイスの設定
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# MNISTミラーリストから低速なミラーを削除する
torchvision.datasets.MNIST.mirrors = [mirror for mirror in torchvision.datasets.MNIST.mirrors
if not mirror.startswith("http://yann.lecun.com")]
```
### Step 0: W\&B をインストール
まずはライブラリをインストールしましょう。
`wandb` は `pip` を使って簡単にインストールできます。
```python theme={null}
!pip install wandb onnx -Uq
```
### Step 1: W\&B をインポートしてログイン
W\&B の Web サービスにデータをログするには、
ログインする必要があります。
W\&B を初めて使用する場合は、
表示されるリンクから無料アカウントにサインアップする必要があります。
```
import wandb
wandb.login()
```
## 実験とパイプラインを定義する
### `wandb.init()` でメタデータとハイパーパラメーターをトラッキングする
プログラム上では、まず実験を定義します。
ハイパーパラメーターは何か、この run にはどのようなメタデータが関連付けられているのかを決めます。
この情報は `config` 辞書
(または同様のオブジェクト)
に保存し、
必要に応じて参照するのが一般的なワークフローです。
この例では、変化させるハイパーパラメーターはごく一部だけで、
残りはコードに直接書いています。
ただし、モデルのどの部分でも `config` に含めることができます。
また、いくつかのメタデータも含めています。使用しているのは MNIST データセットと畳み込み
アーキテクチャです。後で、たとえば
同じプロジェクト内で CIFAR 上の全結合アーキテクチャを扱うことになった場合でも、
これによって run を区別しやすくなります。
```python theme={null}
config = dict(
epochs=5,
classes=10,
kernels=[16, 32],
batch_size=128,
learning_rate=0.005,
dataset="MNIST",
architecture="CNN")
```
それでは、全体のパイプラインを定義しましょう。
これはモデルのトレーニングでよく使われる一般的な流れです。
1. まず、モデルとそれに対応するデータ、オプティマイザを `make` し、
2. 次にモデルを `train` して、
3. 最後に `test` し、トレーニングの結果を確認します。
これらの関数は以下で実装します。
```python theme={null}
def model_pipeline(hyperparameters):
# wandb を開始する
with wandb.init(project="pytorch-demo", config=hyperparameters) as run:
# run.config を通じてすべてのハイパーパラメーターにアクセスし、ログと実行を一致させる
config = run.config
# モデル、データ、最適化問題を作成する
model, train_loader, test_loader, criterion, optimizer = make(config)
print(model)
# それらを使ってモデルをトレーニングする
train(model, train_loader, criterion, optimizer, config)
# 最終的なパフォーマンスをテストする
test(model, test_loader)
return model
```
ここで標準的なパイプラインと異なる唯一の点は、
すべてが `wandb.init()` のコンテキスト内で行われることです。
この関数を呼び出すと、
コードと W\&B のサーバーの間の通信が確立されます。
`config` 辞書を `wandb.init()` に渡すと、
その情報はすぐにすべてログされるため、
実験で使用するよう設定した
ハイパーパラメーターの値をいつでも把握できます。
選択してログした値が常に実際にモデルで使われる値になるよう、
オブジェクトの `run.config` コピーを使用することをおすすめします。
いくつか例を示すので、以下の `make` の定義を確認してください。
> *補足*: W\&B ではコードを別プロセスで実行するようにしているため、
> こちら側で問題が発生しても
> (たとえば巨大な海の怪物がデータセンターを襲ったとしても)
> あなたのコードがクラッシュすることはありません。
> 問題が解決したら、たとえばクラーケンが深海に戻ったあとで、
> `wandb sync` を使ってデータをログできます。
```python theme={null}
def make(config):
# データを作成する
train, test = get_data(train=True), get_data(train=False)
train_loader = make_loader(train, batch_size=config.batch_size)
test_loader = make_loader(test, batch_size=config.batch_size)
# モデルを作成する
model = ConvNet(config.kernels, config.classes).to(device)
# 損失関数とオプティマイザを作成する
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(
model.parameters(), lr=config.learning_rate)
return model, train_loader, test_loader, criterion, optimizer
```
### データの読み込みとモデルを定義する
次に、データの読み込み方法と、モデルをどのように構成するかを指定します。
この部分は非常に重要ですが、`wandb` を
使わない場合と変わらないため、
ここでは詳しくは扱いません。
```python theme={null}
def get_data(slice=5, train=True):
full_dataset = torchvision.datasets.MNIST(root=".",
train=train,
transform=transforms.ToTensor(),
download=True)
# [::slice] でのスライスと同等
sub_dataset = torch.utils.data.Subset(
full_dataset, indices=range(0, len(full_dataset), slice))
return sub_dataset
def make_loader(dataset, batch_size):
loader = torch.utils.data.DataLoader(dataset=dataset,
batch_size=batch_size,
shuffle=True,
pin_memory=True, num_workers=2)
return loader
```
モデルを定義するのは、たいてい楽しい部分です。
ただし、`wandb` を使ってもここは特に変わらないので、
標準的な ConvNet アーキテクチャをそのまま使います。
いろいろ試したり、実験してみたりすることをためらわないでください --
結果はすべて [wandb.ai](https://wandb.ai) にログされます。
```python theme={null}
# 標準的な畳み込みニューラルネットワーク
class ConvNet(nn.Module):
def __init__(self, kernels, classes=10):
super(ConvNet, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1, kernels[0], kernel_size=5, stride=1, padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.layer2 = nn.Sequential(
nn.Conv2d(16, kernels[1], kernel_size=5, stride=1, padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.fc = nn.Linear(7 * 7 * kernels[-1], classes)
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = out.reshape(out.size(0), -1)
out = self.fc(out)
return out
```
### トレーニングロジックを定義する
`model_pipeline` を進めていき、次は `train` をどのように行うかを指定します。
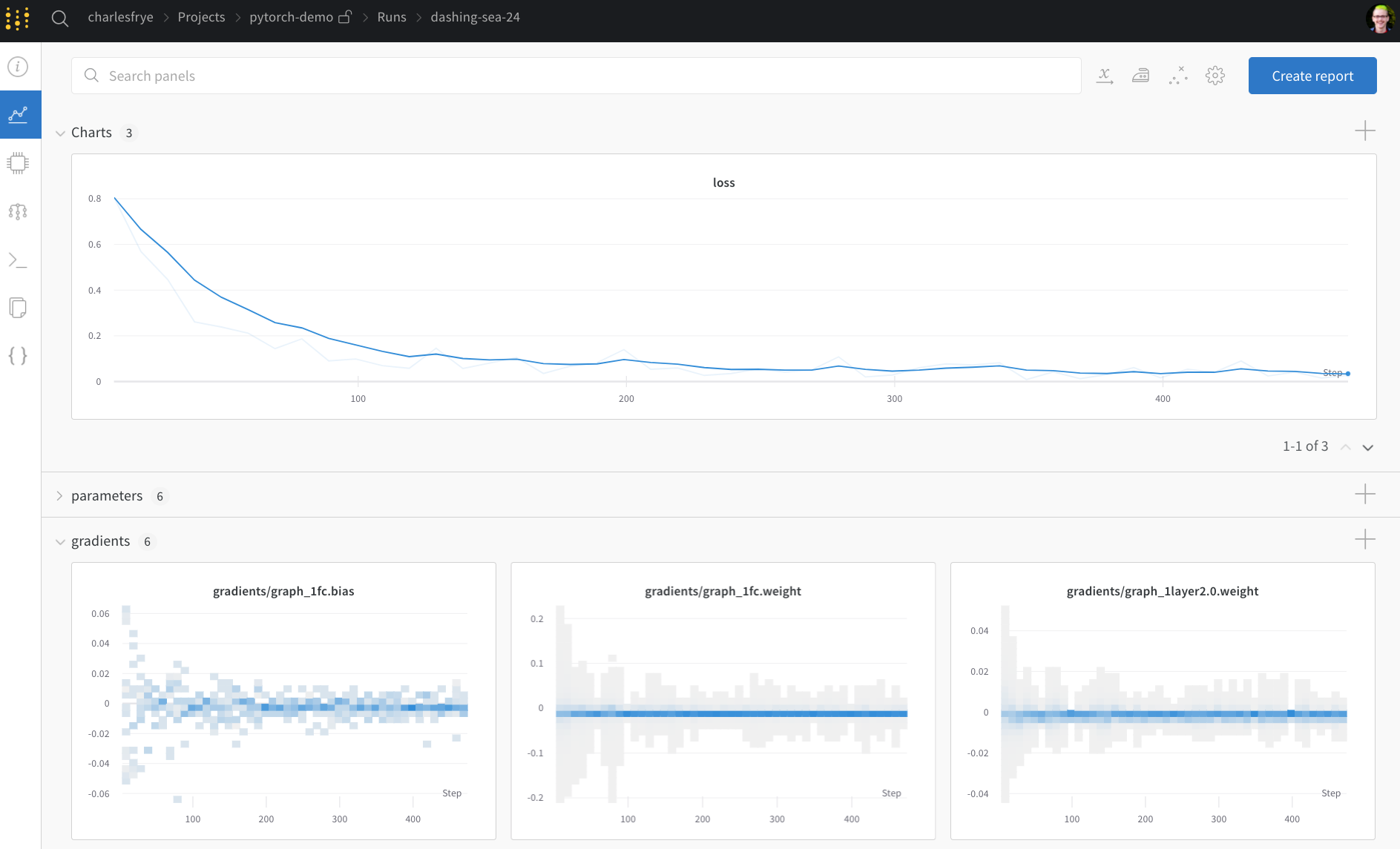
ここでは、`wandb` の 2 つの関数 `watch` と `log` を使います。
## 勾配は `run.watch()` でトラッキングし、それ以外はすべて `run.log()` でログする
`run.watch()` は、トレーニング中 `log_freq` step ごとに、
モデルの勾配とパラメーターをログします。
トレーニングを始める前に `run.watch()` を呼び出してください。ログモード、複数のモデル、パフォーマンスのヒントについては、[wandb.watch で勾配とモデルの重みをログするにはどうすればよいですか?](/ja/support/models/articles/how-do-i-log-gradients-and-model-weights-with-wandb-watch) を参照してください。
それ以外のトレーニングコードはそのままです。
エポックとバッチを繰り返し処理し、
フォワードパスとバックワードパスを実行して
`optimizer` を適用します。
```python theme={null}
def train(model, loader, criterion, optimizer, config):
# wandb にモデルの動作(勾配、重みなど)を監視させる。
run = wandb.init(project="pytorch-demo", config=config)
run.watch(model, criterion, log="all", log_freq=10)
# トレーニングを実行し、wandb でトラッキングする
total_batches = len(loader) * config.epochs
example_ct = 0 # これまでに見たサンプル数
batch_ct = 0
for epoch in tqdm(range(config.epochs)):
for _, (images, labels) in enumerate(loader):
loss = train_batch(images, labels, model, optimizer, criterion)
example_ct += len(images)
batch_ct += 1
# 25 バッチごとにメトリクスを報告する
if ((batch_ct + 1) % 25) == 0:
train_log(loss, example_ct, epoch)
def train_batch(images, labels, model, optimizer, criterion):
images, labels = images.to(device), labels.to(device)
# フォワードパス ➡
outputs = model(images)
loss = criterion(outputs, labels)
# バックワードパス ⬅
optimizer.zero_grad()
loss.backward()
# オプティマイザーで step を実行する
optimizer.step()
return loss
```
唯一の違いは、ログ用のコードです。
以前はメトリクスをターミナルに出力して報告していたかもしれませんが、
今は同じ情報を `run.log()` に渡します。
`run.log()` には、キーが文字列の辞書を渡します。
これらの文字列は、ログするオブジェクトを識別する名前で、対応する値がその内容になります。
さらに、トレーニングのどの `step` にいるかを任意でログすることもできます。
> *補足*: 私は、モデルがこれまでに見たサンプル数を使うのが好きです。
> そのほうが、バッチサイズが違っても比較しやすいからです。
> もちろん、単純な step 数やバッチ数を使用してもかまいません。トレーニング run が長い場合は、`epoch` ごとにログするのも合理的です。
```python theme={null}
def train_log(loss, example_ct, epoch):
with wandb.init(project="pytorch-demo") as run:
# 損失とエポック番号をログします
# ここでメトリクスを W&B にログします
run.log({"epoch": epoch, "loss": loss}, step=example_ct)
print(f"Loss after {str(example_ct).zfill(5)} examples: {loss:.3f}")
```
### テスト方法を定義する
モデルのトレーニングが完了したら、テストを行います。
たとえば、本番環境の新しいデータで実行したり、
あるいは手作業で厳選したサンプルに適用したりします。
## (任意) `run.save()` を呼び出す
ここで、モデルのアーキテクチャと
最終的なパラメーターをディスクに保存しておくのもよいでしょう。
互換性を最大限に確保するため、モデルは
[Open Neural Network eXchange (ONNX) 形式](https://onnx.ai/)で `export` します。
そのファイル名を `run.save()` に渡すことで、モデルのパラメーターが
W\&B のサーバーにも保存されます。これで、どの `.h5` や `.pb` が
どのトレーニング run に対応しているのか分からなくなることはありません。
モデルの保存、バージョン管理、配布に関する、より高度な `wandb` の機能については、
[Artifacts tools](https://www.wandb.com/artifacts) を参照してください。
```python theme={null}
def test(model, test_loader):
model.eval()
with wandb.init(project="pytorch-demo") as run:
# テスト用のサンプルでモデルを実行する
with torch.no_grad():
correct, total = 0, 0
for images, labels in test_loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f"Accuracy of the model on the {total} " +
f"test images: {correct / total:%}")
run.log({"test_accuracy": correct / total})
# 交換可能な ONNX 形式でモデルを保存する
torch.onnx.export(model, images, "model.onnx")
run.save("model.onnx")
```
### トレーニングを実行し、wandb.ai でメトリクスをライブで確認する
これでパイプライン全体を定義し、
数行の W\&B コードを差し込んだので、
完全にトラッキングされた実験を実行する準備が整いました。
いくつかのリンクが表示されます:
ドキュメント、
プロジェクト内のすべての run を整理するプロジェクトページ、そして
この run の結果が保存される Run ページです。
Run ページにアクセスして、次のタブを確認してください:
1. **Charts**。ここでは、トレーニング全体を通してモデルの勾配、パラメーターの値、損失がログされます
2. **System**。ここには、ディスク I/O 使用率、CPU と GPU のメトリクス (温度が急上昇する様子にも注目です) など、さまざまなシステムメトリクスが含まれます
3. **Logs**。ここには、トレーニング中に標準出力に出力された内容のコピーがあります
4. **Files**。ここでは、トレーニング完了後に `model.onnx` をクリックすると、[Netron model viewer](https://github.com/lutzroeder/netron) でネットワークを表示できます。
run が完了し、`with wandb.init()` ブロックを抜けると、
セルの出力にも結果の概要が表示されます。
```python theme={null}
# パイプラインでモデルをビルド、トレーニング、分析する
model = model_pipeline(config)
```
### Sweeps でハイパーパラメーターを試す
この例では、1組のハイパーパラメーターだけを扱ってきました。
しかし、ほとんどの ML ワークフローでは、
複数のハイパーパラメーターを繰り返し試すことが重要です。
W\&B Sweeps を使用すると、ハイパーパラメーターのテストを自動化し、考えられるモデルや最適化戦略の探索ができます。
[W\&B Sweeps を使用したハイパーパラメーター最適化を実演する Colab ノートブック](https://wandb.me/sweeps-colab)をご覧ください。
W\&B でハイパーパラメーター sweep を実行するのは非常に簡単です。必要なのは、次の 3 つの簡単な step だけです。
1. **sweep を定義する:** 検索対象のパラメーター、検索戦略、最適化メトリクスなどを指定する辞書または [YAML ファイル](/ja/models/sweeps/define-sweep-configuration/) を作成します。
2. **sweep を初期化する:**
`sweep_id = wandb.sweep(sweep_config)`
3. **sweep agent を実行する:**
`wandb.agent(sweep_id, function=train)`
ハイパーパラメーター sweep の実行に必要なのはこれだけです。
## サンプルギャラリー
W\&B でトラッキングされ、可視化されたプロジェクトの実例は、[Gallery →](https://app.wandb.ai/gallery)でご覧いただけます。
## 高度な設定
1. [環境変数](/ja/platform/hosting/env-vars/): 環境変数にAPIキーを設定して、マネージドクラスターでトレーニングを実行できます。
2. [オフラインモード](/ja/support/models/articles/how-do-i-run-wandb-offline): `dryrun` モードを使用してオフラインでトレーニングし、後で結果をSyncします。
3. [オンプレミス](/ja/platform/hosting/hosting-options/self-managed): 自社のインフラストラクチャー内のプライベートクラウドやエアギャップ環境のサーバーにW\&Bをインストールします。研究用途からエンタープライズチームまで、幅広いユーザー向けにローカル導入オプションを提供しています。
4. [Sweeps](/ja/models/sweeps/): 軽量なチューニングツールを使って、ハイパーパラメーター探索をすばやく設定できます。

 ```python theme={null}
# ライブラリをインポートする
import wandb
# config にハイパーパラメーターの辞書を設定する
config = {
"learning_rate": 0.001,
"epochs": 100,
"batch_size": 128
}
# 新しい実験を開始する
with wandb.init(project="new-sota-model", config=config) as run:
# モデルとデータを準備する
model, dataloader = get_model(), get_data()
# 任意: 勾配をトラッキングする
run.watch(model)
for batch in dataloader:
metrics = model.training_step()
# トレーニングループ内でメトリクスをログして、モデル性能を可視化する
run.log(metrics)
# 任意: 最後にモデルを保存する
model.to_onnx()
run.save("model.onnx")
```
[動画チュートリアル](https://wandb.me/pytorch-video)を見ながら進めてください。
**注**: *Step* で始まるセクションだけで、既存のパイプラインに W\&B を統合できます。それ以外の部分では、データの読み込みとモデルの定義を行います。
```python theme={null}
# ライブラリをインポートする
import wandb
# config にハイパーパラメーターの辞書を設定する
config = {
"learning_rate": 0.001,
"epochs": 100,
"batch_size": 128
}
# 新しい実験を開始する
with wandb.init(project="new-sota-model", config=config) as run:
# モデルとデータを準備する
model, dataloader = get_model(), get_data()
# 任意: 勾配をトラッキングする
run.watch(model)
for batch in dataloader:
metrics = model.training_step()
# トレーニングループ内でメトリクスをログして、モデル性能を可視化する
run.log(metrics)
# 任意: 最後にモデルを保存する
model.to_onnx()
run.save("model.onnx")
```
[動画チュートリアル](https://wandb.me/pytorch-video)を見ながら進めてください。
**注**: *Step* で始まるセクションだけで、既存のパイプラインに W\&B を統合できます。それ以外の部分では、データの読み込みとモデルの定義を行います。