> ## Documentation Index
> Fetch the complete documentation index at: https://docs.wandb.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# ジョブ入力を管理する
> ハイパーパラメーターやファイルベースの設定など、W&B Launch ジョブの入力をプログラムで管理および設定します。
Launch の中核となる体験は、ハイパーパラメーターやデータセットなどのさまざまなジョブ入力を試し、それらのジョブを適切なハードウェアに振り分けることです。ジョブを作成した後は、元の作成者以外のユーザーも W\&B UI または CLI を通じてこれらの入力を調整できます。CLI または UI から起動する際にジョブ入力をどのように設定するかについては、[ジョブをキューに追加する](./add-job-to-queue) ガイドを参照してください。
このガイドでは、ジョブに対してどの入力を調整可能にするかをプログラムで制御し、エンドユーザーが変更できるパラメーターだけを公開する方法について説明します。
デフォルトでは、W\&B ジョブは `Run.config` 全体をジョブの入力として取得しますが、Launch SDK には、run config 内の特定のキーを制御したり、JSON または YAML ファイルを入力として指定したりするための関数が用意されています。
Launch SDK の関数には `wandb-core` が必要です。詳細については、[`wandb-core` README](https://github.com/wandb/wandb/blob/main/core/README) を参照してください。
## `Run` オブジェクトを再設定する
ジョブ内で `wandb.init()` が返す `Run` オブジェクトは、デフォルトで再設定できます。Launch SDK では、ジョブの起動時に `Run.config` オブジェクトのどの部分を再設定可能にするかをカスタマイズできるため、内部設定を隠しつつ、エンドユーザーにとって重要なパラメーターを公開できます。
```python theme={null}
import wandb
from wandb.sdk import launch
# Launch SDK を使用するために必須。
wandb.require("core")
config = {
"trainer": {
"learning_rate": 0.01,
"batch_size": 32,
"model": "resnet",
"dataset": "cifar10",
"private": {
"key": "value",
},
},
"seed": 42,
}
with wandb.init(config=config):
launch.manage_wandb_config(
include=["trainer"],
exclude=["trainer.private"],
)
# 以下省略。
```
関数 `launch.manage_wandb_config()` は、ジョブが `Run.config` オブジェクトの入力値を受け取れるように設定します。省略可能な `include` オプションと `exclude` オプションには、ネストされた設定オブジェクト内のパスプレフィックスを指定します。これは、たとえばジョブで、エンドユーザーに公開したくないオプションを持つライブラリを使用している場合に便利です。
`include` プレフィックスを指定すると、設定内で `include` プレフィックスに一致するパスだけが入力値を受け取ります。`exclude` プレフィックスを指定すると、`exclude` リストに一致するパスはすべて入力値から除外されます。あるパスが `include` プレフィックスと `exclude` プレフィックスの両方に一致する場合は、`exclude` プレフィックスが優先されます。
前述の例では、パス `["trainer.private"]` は `trainer` オブジェクトから `private` キーを除外し、パス `["trainer"]` は `trainer` オブジェクト配下以外のすべてのキーを除外します。
`\` でエスケープした `.` を使用すると、名前に `.` を含むキーを除外できます。
たとえば、`r"trainer\.private"` は、`trainer` オブジェクト配下の `private` キーではなく、`trainer.private` キーを除外します。
前述の例の `r` プレフィックスは raw string を表します。
前述のコードをパッケージ化してジョブとして実行した場合、ジョブの入力タイプは次のようになります。
```json theme={null}
{
"trainer": {
"learning_rate": "float",
"batch_size": "int",
"model": "str",
"dataset": "str",
},
}
```
W\&B CLI または UI からジョブを起動する場合、上書きできるのは 4 つの `trainer` パラメーターのみです。
### run config の入力 にアクセスする
run config の入力 を指定して起動したジョブでは、`Run.config` を通じて入力値にアクセスできます。ジョブコード内で `wandb.init()` が返す `Run` には、入力値が自動的に設定されます。ジョブコード内のどこからでも run config の入力値を読み込むには、`launch.load_wandb_config()` を使用します:
```python theme={null}
from wandb.sdk import launch
run_config_overrides = launch.load_wandb_config()
```
## ファイルを再設定する
Launch SDK は、ジョブコード内の設定ファイルに保存された入力値を管理することもできます。これは、ディープラーニングや大規模言語モデルの多くのユースケースで一般的なパターンで、たとえばこの [torchtune](https://github.com/meta-pytorch/torchtune/blob/main/recipes/configs/llama3/8B_lora.yaml) の例や、この [Axolotl config](https://github.com/OpenAccess-AI-Collective/axolotl/blob/main/examples/llama-3/qlora-fsdp-70b.yaml) などがあります。
[Launch の Sweeps](/ja/platform/launch/sweeps-on-launch/) では、設定ファイルの入力を sweep パラメーターとして使用することはサポートされていません。sweep パラメーターは `Run.config` オブジェクトで制御する必要があります。
`launch.manage_config_file()` 関数を使用して、設定ファイルを Launch ジョブの入力として追加します。これにより、ジョブの起動時にその設定ファイル内の値を編集できるようになります。
デフォルトでは、`launch.manage_config_file()` を使用しても run config の入力は取り込まれません。`launch.manage_wandb_config()` を呼び出すと、この挙動は上書きされます。
次の例を見てみましょう。
```python theme={null}
import yaml
import wandb
from wandb.sdk import launch
# launch sdk を使用するために必須。
wandb.require("core")
launch.manage_config_file("config.yaml")
with open("config.yaml", "r") as f:
config = yaml.safe_load(f)
with wandb.init(config=config):
# など。
pass
```
同じディレクトリに `config.yaml` ファイルがある状態でコードを実行するとします:
```yaml theme={null}
learning_rate: 0.01
batch_size: 32
model: resnet
dataset: cifar10
```
`launch.manage_config_file()` を呼び出すと、`config.yaml` ファイルがジョブへの入力として追加され、W\&B CLI または UI から起動する際に再設定できるようになります。
`include` および `exclude` キーワード引数を使用して、`launch.manage_wandb_config()` と同様に、設定ファイルで受け付ける入力キーをフィルターします。
### 設定ファイルの入力にアクセスする
Launch によって作成された run で `launch.manage_config_file()` を呼び出すと、`launch` は入力値を使って設定ファイルの内容を書き換えます。書き換え後の設定ファイルはジョブ環境で利用できます。
入力値が確実に使用されるよう、ジョブコードで設定ファイルを読み込む前に `launch.manage_config_file()` を呼び出してください。
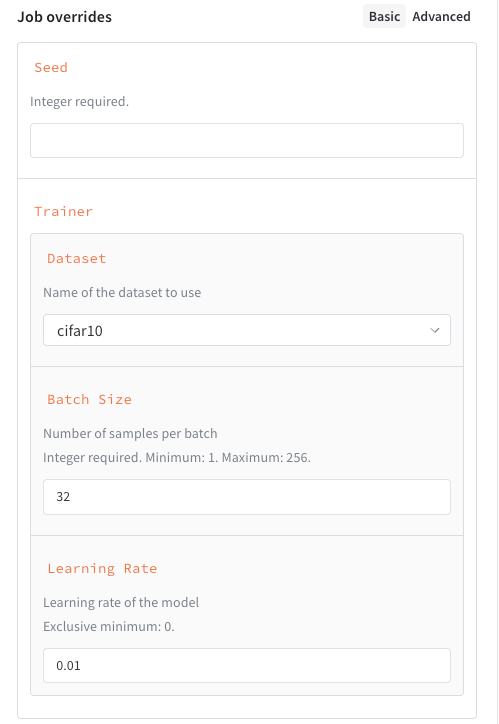
## ジョブの Launch drawer UI をカスタマイズする
公開する入力をフィルターするだけでなく、ジョブの入力スキーマを定義して、ジョブの起動用にカスタム UI を作成することもできます。これにより、自由入力のテキストエントリの代わりに、構造化されたフィールド、検証のヒント、ドロップダウンが Launch drawer に表示されます。ジョブのスキーマを定義するには、`launch.manage_wandb_config()` または `launch.manage_config_file()` の呼び出しにスキーマを含めます。スキーマには、[JSON Schema](https://json-schema.org/understanding-json-schema/reference) 形式の Python の `dict`、または Pydantic のモデルクラスを使用できます。
ジョブ入力スキーマは入力を検証しません。Launch drawer の UI を定義するだけです。
次の例は、以下のプロパティを持つスキーマを示しています。
* `seed`: 整数。
* `trainer`: いくつかのキーが指定された辞書
* `trainer.learning_rate`: 0 より大きい必要がある浮動小数点数。
* `trainer.batch_size`: 16、64、256 のいずれかである必要がある整数。
* `trainer.dataset`: `cifar10` または `cifar100` のいずれかである必要がある文字列。
```python theme={null}
schema = {
"type": "object",
"properties": {
"seed": {
"type": "integer"
}
"trainer": {
"type": "object",
"properties": {
"learning_rate": {
"type": "number",
"description": "Learning rate of the model",
"exclusiveMinimum": 0,
},
"batch_size": {
"type": "integer",
"description": "Number of samples per batch",
"enum": [16, 64, 256]
},
"dataset": {
"type": "string",
"description": "Name of the dataset to use",
"enum": ["cifar10", "cifar100"]
}
}
}
}
}
launch.manage_wandb_config(
include=["seed", "trainer"],
exclude=["trainer.private"],
schema=schema,
)
```
一般に、以下の JSON Schema 属性がサポートされます。
| 属性 | 必須 | メモ |
| ------------------ | --- | ---------------------------------------------------- |
| `type` | はい | `number`、`integer`、`string`、`object` のいずれかである必要があります |
| `title` | いいえ | プロパティの表示名を上書きします |
| `description` | いいえ | プロパティのヘルパーテキストを指定します |
| `enum` | いいえ | 自由入力のテキストエントリの代わりに、ドロップダウン選択を作成します |
| `minimum` | いいえ | `type` が `number` または `integer` の場合にのみ使用できます |
| `maximum` | いいえ | `type` が `number` または `integer` の場合にのみ使用できます |
| `exclusiveMinimum` | いいえ | `type` が `number` または `integer` の場合にのみ使用できます |
| `exclusiveMaximum` | いいえ | `type` が `number` または `integer` の場合にのみ使用できます |
| `properties` | いいえ | `type` が `object` の場合、ネストされた設定を定義するために使用されます |
次の例は、以下のプロパティを持つスキーマを示しています。
* `seed`: 整数。
* `trainer`: いくつかのサブ属性が指定されたスキーマ
* `trainer.learning_rate`: 0 より大きい必要がある浮動小数点数。
* `trainer.batch_size`: 1 から 256 の範囲内 (両端を含む) である必要がある整数。
* `trainer.dataset`: `cifar10` または `cifar100` のいずれかである必要がある文字列。
```python theme={null}
class DatasetEnum(str, Enum):
cifar10 = "cifar10"
cifar100 = "cifar100"
class Trainer(BaseModel):
learning_rate: float = Field(gt=0, description="Learning rate of the model")
batch_size: int = Field(ge=1, le=256, description="Number of samples per batch")
dataset: DatasetEnum = Field(title="Dataset", description="Name of the dataset to use")
class Schema(BaseModel):
seed: int
trainer: Trainer
launch.manage_wandb_config(
include=["seed", "trainer"],
exclude=["trainer.private"],
schema=Schema,
)
```
クラスのインスタンスを使用することもできます。
```python theme={null}
t = Trainer(learning_rate=0.01, batch_size=32, dataset=DatasetEnum.cifar10)
s = Schema(seed=42, trainer=t)
launch.manage_wandb_config(
include=["seed", "trainer"],
exclude=["trainer.private"],
input_schema=s,
)
```
ジョブ入力スキーマを追加すると、ジョブを起動するユーザー向けに Launch drawer に構造化されたフォームが作成されます。