
Try in Colab
なぜW&Bを使うべきか?

- 統一されたダッシュボード: モデルのすべてのメトリクスと予測のための中央リポジトリ
- 軽量: Hugging Faceとのインテグレーションにコード変更は不要
- アクセス可能: 個人や学術チームには無料
- セキュア: すべてのプロジェクトはデフォルトでプライベート
- 信頼性: OpenAI、トヨタ、Lyftなどの機械学習チームで使用されている
インストール、インポート、ログイン
このチュートリアルのためにHugging FaceとWeights & Biasesのライブラリ、GLUEデータセット、トレーニングスクリプトをインストールします。- Hugging Face Transformers: 自然言語モデルとデータセット
- Weights & Biases: 実験管理と可視化
- GLUE dataset: 言語理解ベンチマークデータセット
- GLUE script: シーケンス分類用モデルのトレーニングスクリプト
APIキーを入力
サインアップしたら、次のセルを実行してリンクをクリックし、APIキーを取得してこのノートブックを認証してください。モデルをトレーニング
次に、ダウンロードしたトレーニングスクリプト run_glue.py を呼び出し、トレーニングがWeights & Biasesダッシュボードに自動的にトラックされるのを確認します。このスクリプトは、Microsoft Research Paraphrase CorpusでBERTをファインチューンし、意味的に同等であることを示す人間の注釈付きの文のペアを使用します。ダッシュボードで結果を可視化
上記で印刷されたリンクをクリックするか、wandb.ai にアクセスして、結果がリアルタイムでストリームされるのを確認してください。ブラウザでrunを表示するリンクは、すべての依存関係がロードされた後に表示されます。次のような出力を探します: “wandb: 🚀 View run at [URL to your unique run]” モデルのパフォーマンスを可視化 数十の実験管理を一目で確認し、興味深い学びにズームインし、高次元のデータを可視化するのは簡単です。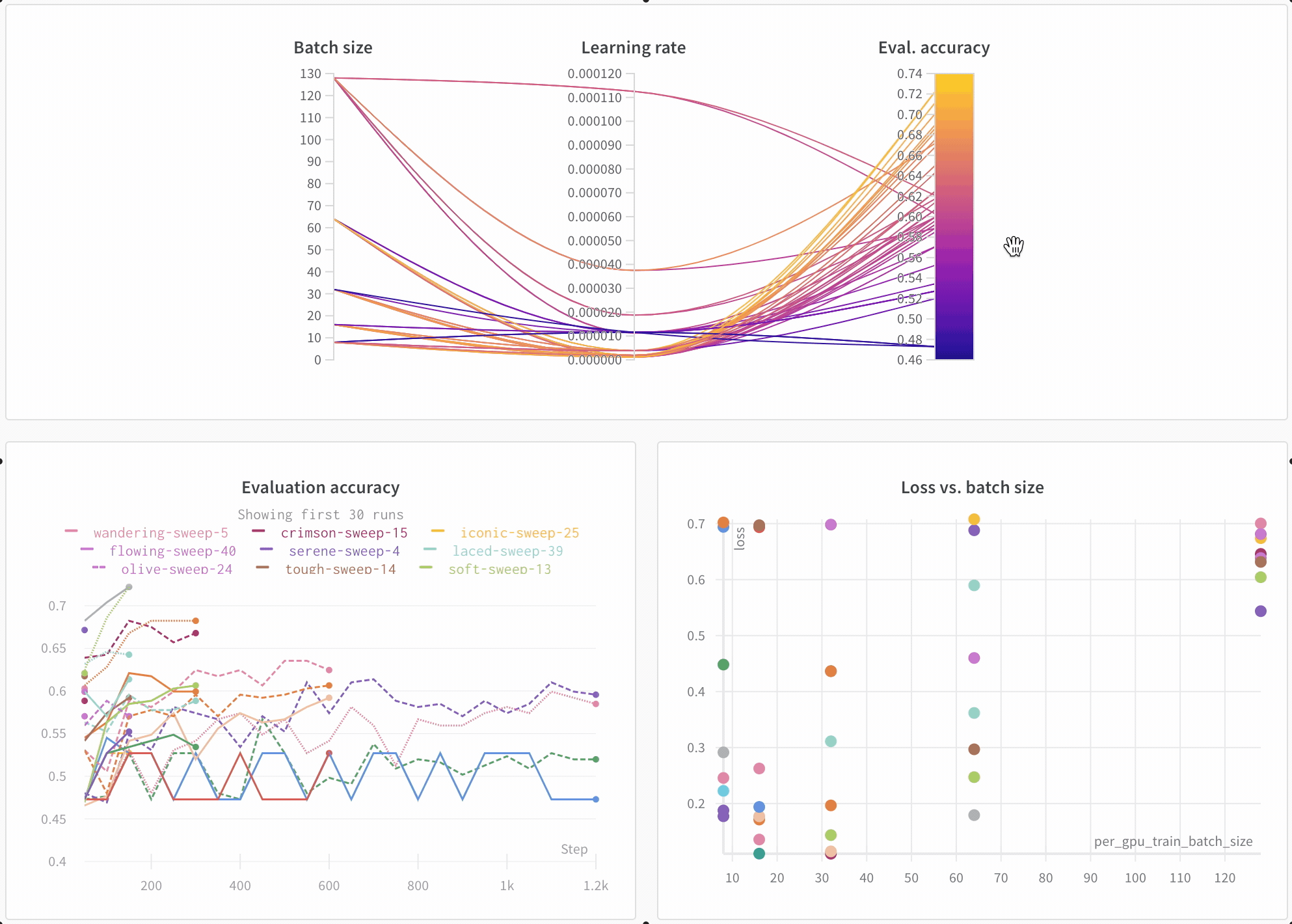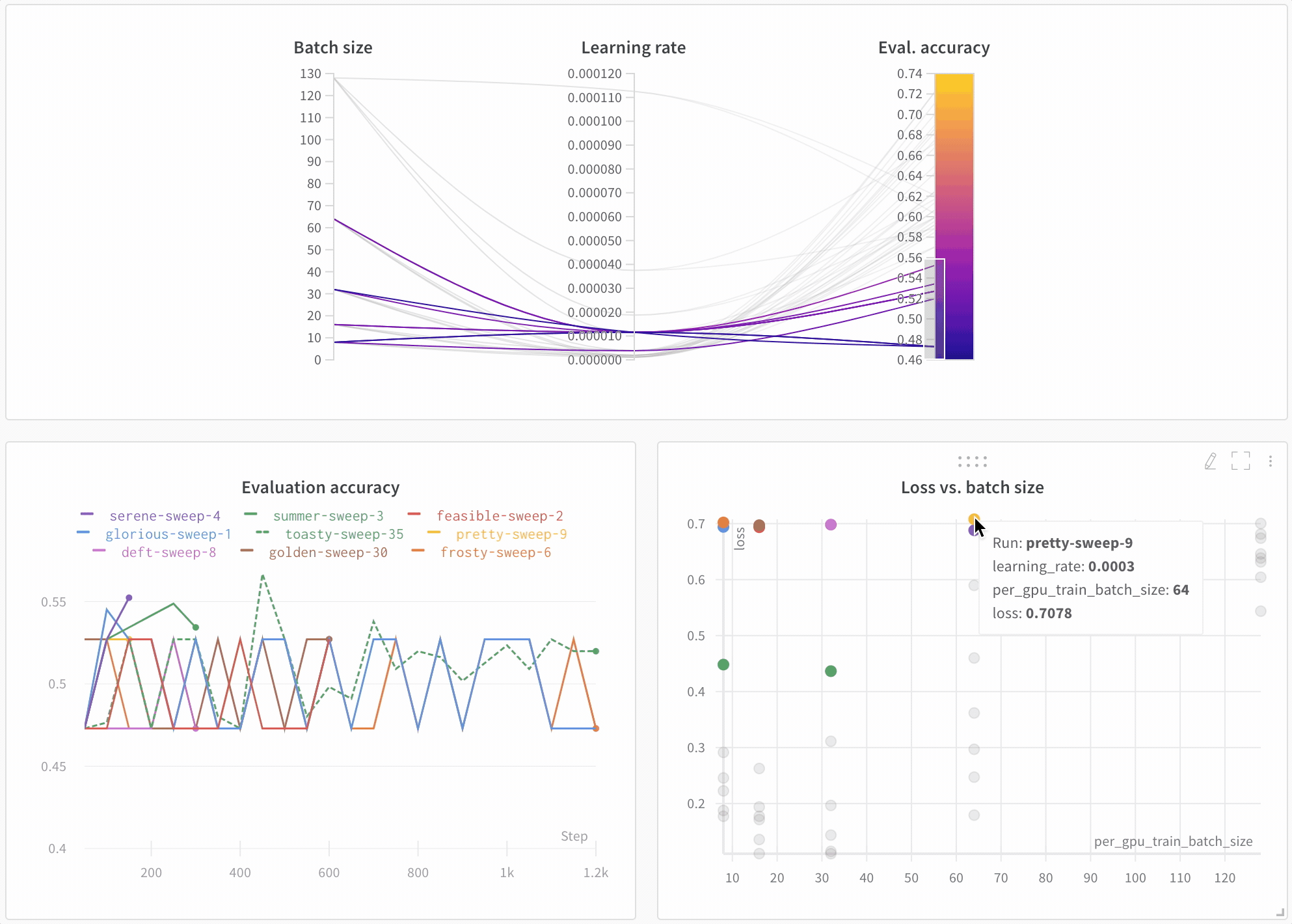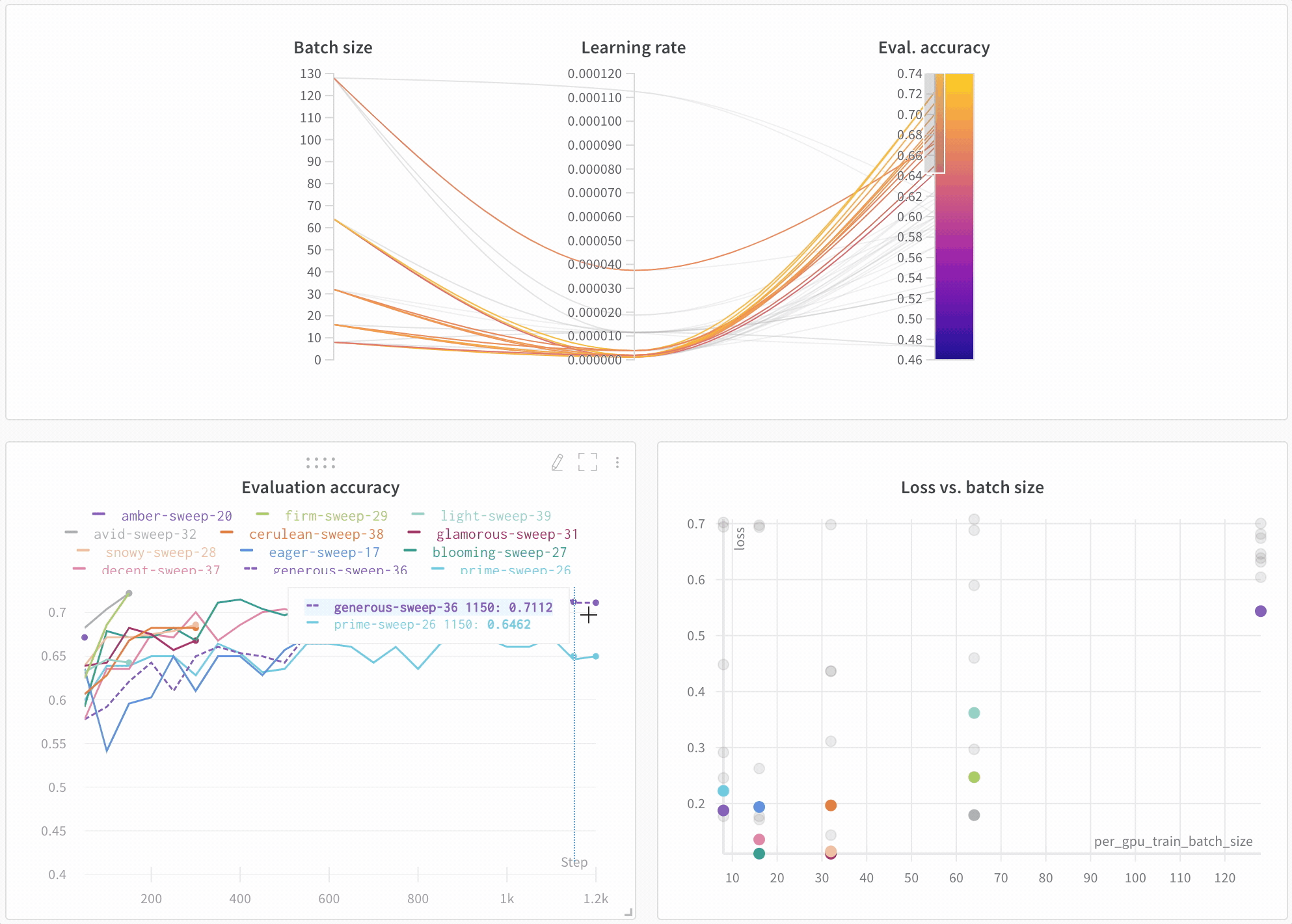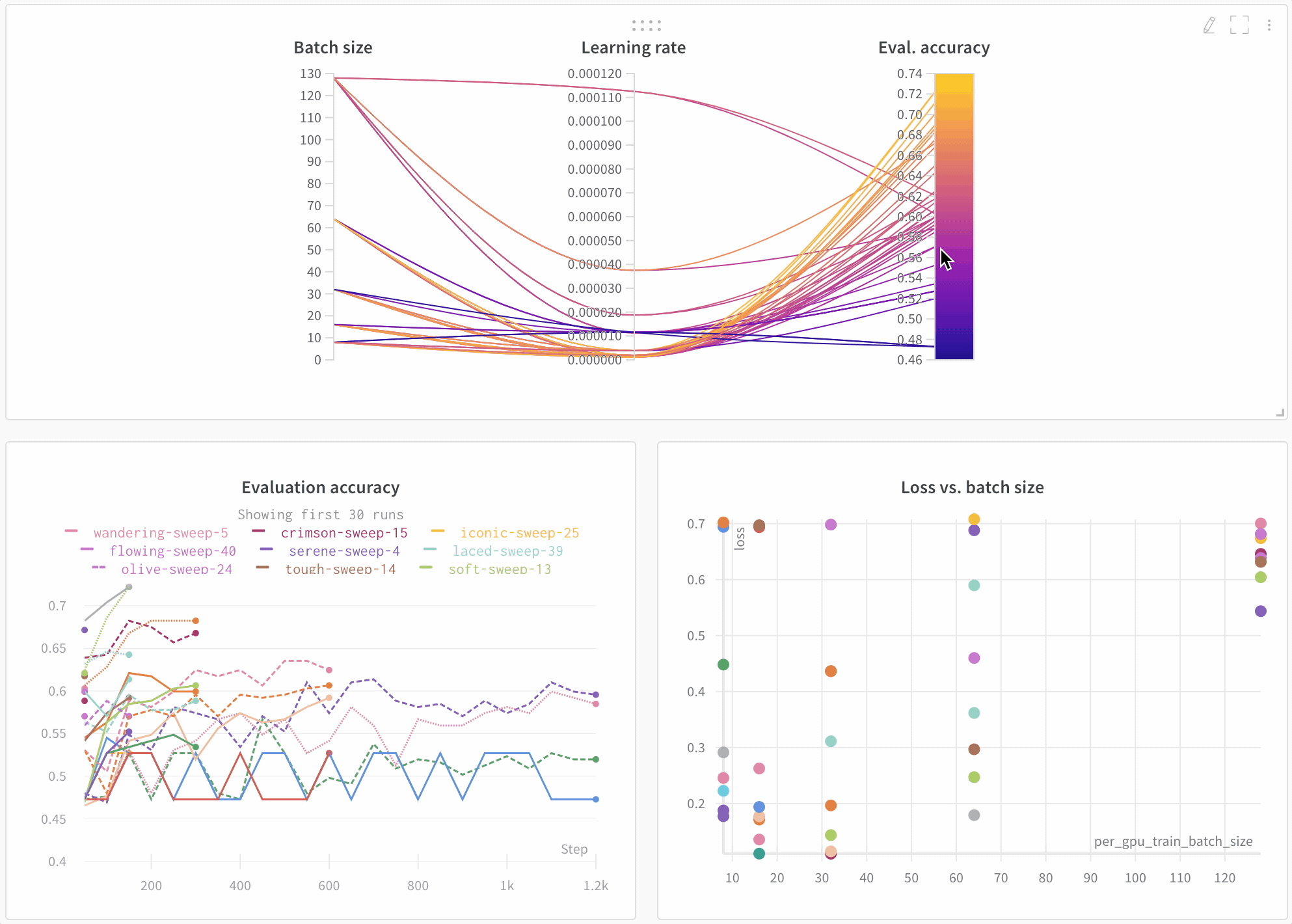
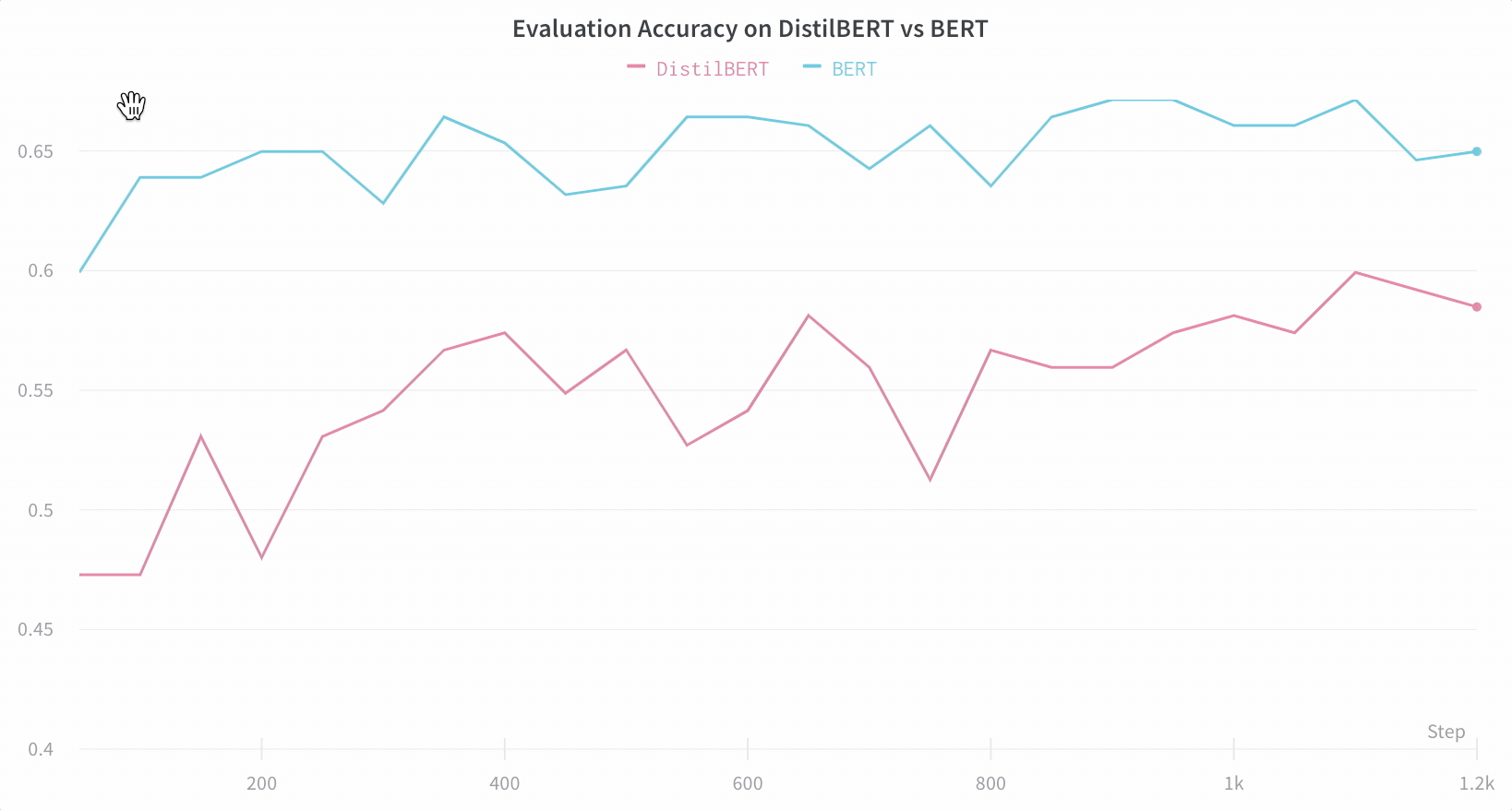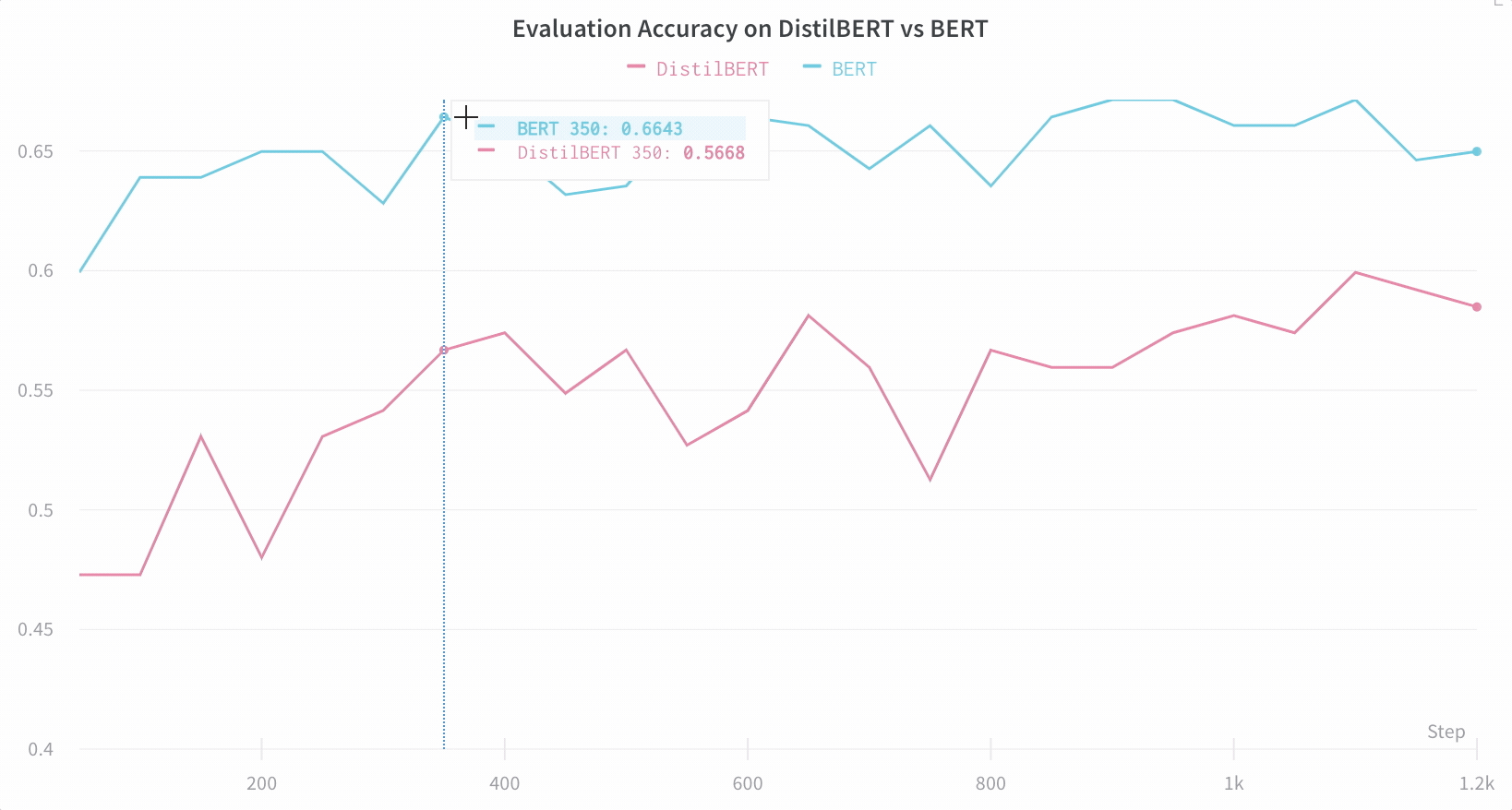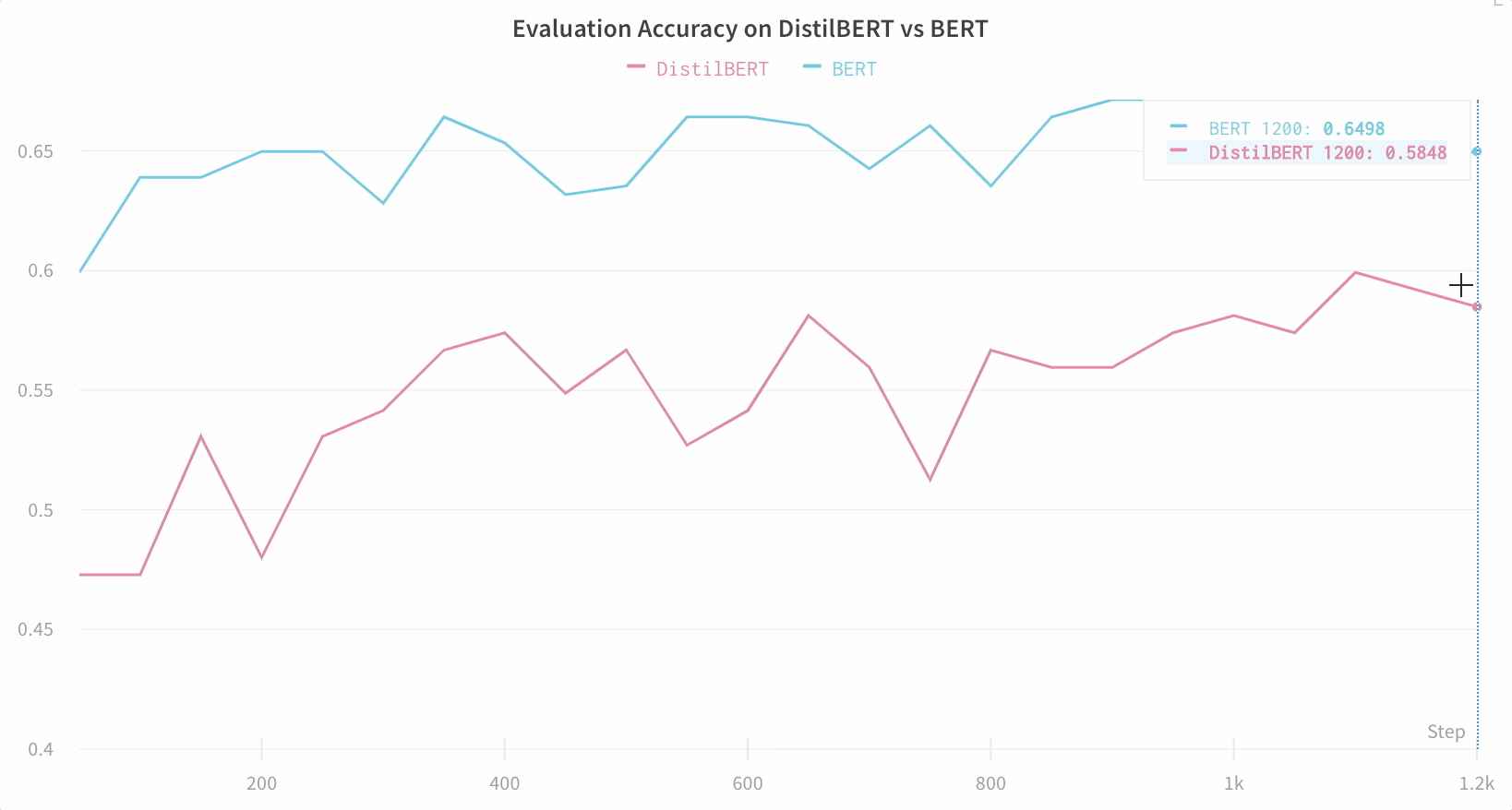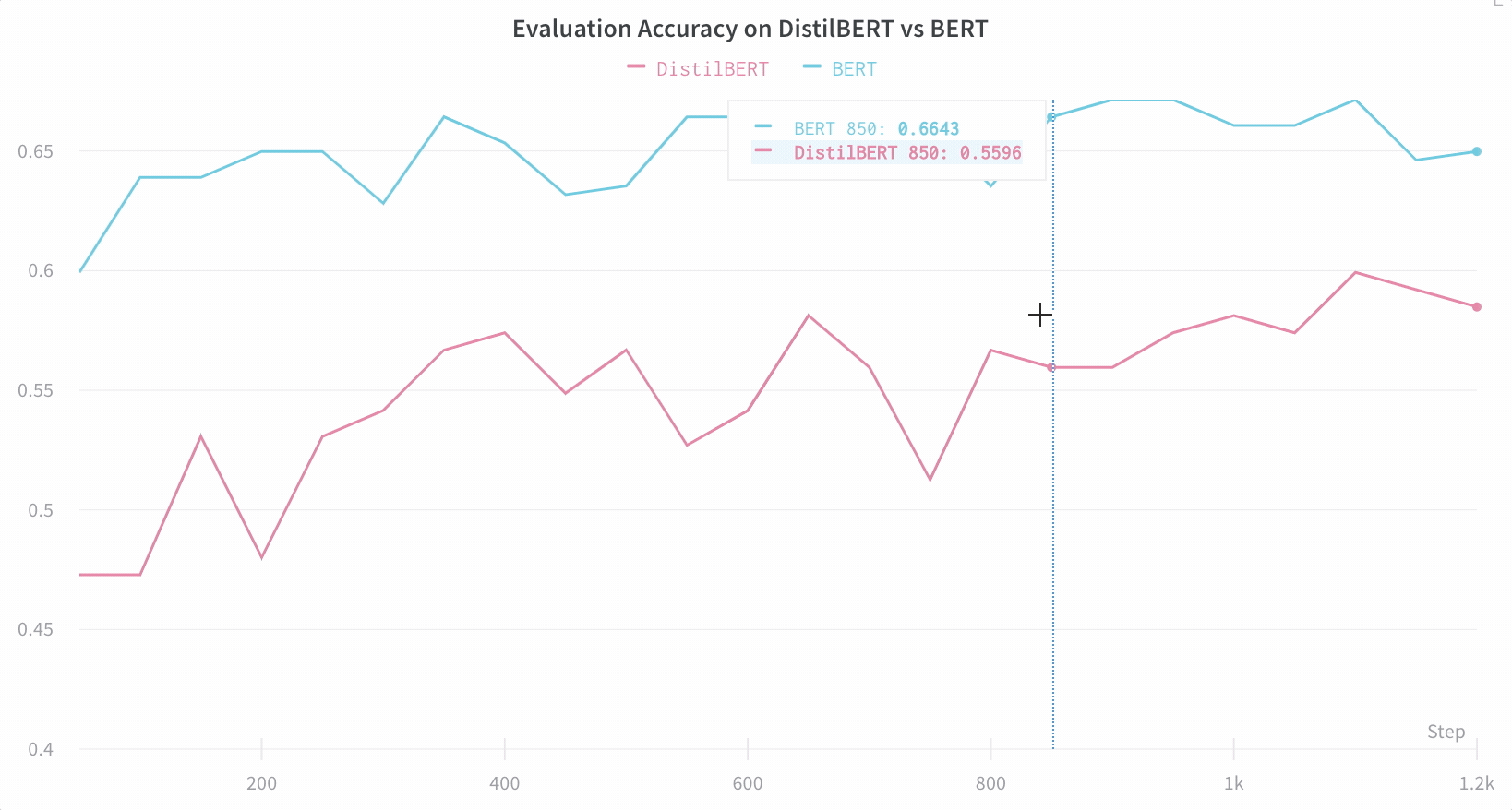
重要な情報をデフォルトで簡単にトラック
Weights & Biasesは、各実験で新しいrunを保存します。デフォルトで保存される情報は次の通りです:- ハイパーパラメーター: モデルの設定がConfigに保存されます
- モデルメトリクス: ストリーミングメトリクスの時系列データはLogに保存されます
- ターミナルログ: コマンドラインの出力は保存され、タブで利用可能です
- システムメトリクス: GPUとCPUの使用率、メモリ、温度など
詳しく知る
- ドキュメント: Weights & BiasesとHugging Faceのインテグレーションに関するドキュメント
- ビデオ: YouTubeチャンネルでのチュートリアル、実務者とのインタビュー、その他
- お問い合わせ: contact@wandb.com までご質問をお寄せください