Try in Colab
- モデルチーム: モデル作成チームは、新しいチャットモデル (Llama 3.2) をファインチューニングし、W&B Models を使用してそれをレジストリに保存します。
- アプリチーム: アプリ開発チームはチャットモデルを取得して、新しいRAGチャットボットを作成および評価するために W&B Weave を使用します。
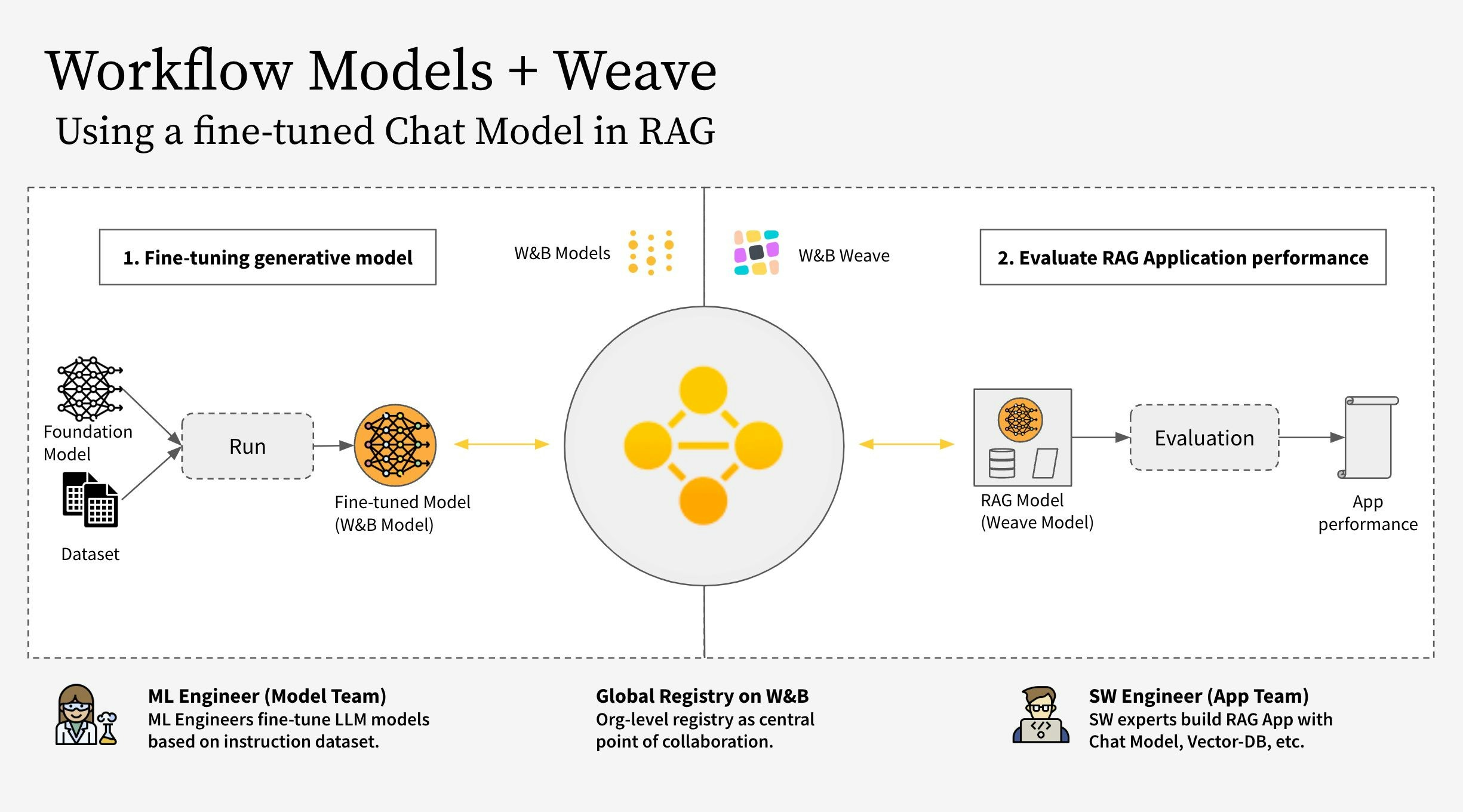
- RAGアプリのコードを W&B Weave で計測する
- LLM(Llama 3.2 など、他のLLMに置き換えることも可能)をファインチューニングし、W&B Models でトラッキングする
- ファインチューニングされたモデルを W&B Registry にログする
- 新しいファインチューニングされたモデルを使用してRAGアプリを実装し、W&B Weave でアプリを評価する
- 結果に満足したら、更新されたRAGアプリの参照を W&B Registry に保存する
RagModel は、完全なRAGアプリと考えられるトップレベルの weave.Model です。これは ChatModel、ベクトルデータベース、プロンプトを含みます。ChatModel もまた別の weave.Model であり、W&B Registry からアーティファクトをダウンロードする機能を持つコードを含んでおり、RagModel の一部として任意の他のチャットモデルをサポートするために変更可能です。詳細は Weaveでの完全なモデル を参照してください。
1. セットアップ
まず、weave と wandb をインストールし、APIキーでログインします。APIキーは https://wandb.ai/settings で作成し、表示できます。
2. アーティファクトに基づく ChatModel を作成する
Registry からファインチューニングされたチャットモデルを取得し、weave.Model を作成して次のステップでRagModelに直接プラグインします。既存の ChatModel と同じパラメータを取りますが、init と predict は変更されます。
unsloth ライブラリを使用して異なる Llama-3.2 モデルをファインチューニングし、より高速にしました。したがって、特殊な unsloth.FastLanguageModel または peft.AutoPeftModelForCausalLM モデルとアダプターを使用してモデルをダウンロードする必要があります。Registry の「使用」タブからロードコードをコピーして model_post_init に貼り付けます。
3. 新しい ChatModel バージョンを RagModel に統合する
ファインチューニングされたチャットモデルを使用してRAGアプリを構築することは、特に会話型AIシステムの性能と多様性を向上させる上でいくつかの利点を提供します。
現在のWeaveプロジェクトから RagModel を取得し、新しい ChatModel に交換します。他のコンポーネント(VDB、プロンプトなど)を変更または再作成する必要はありません!
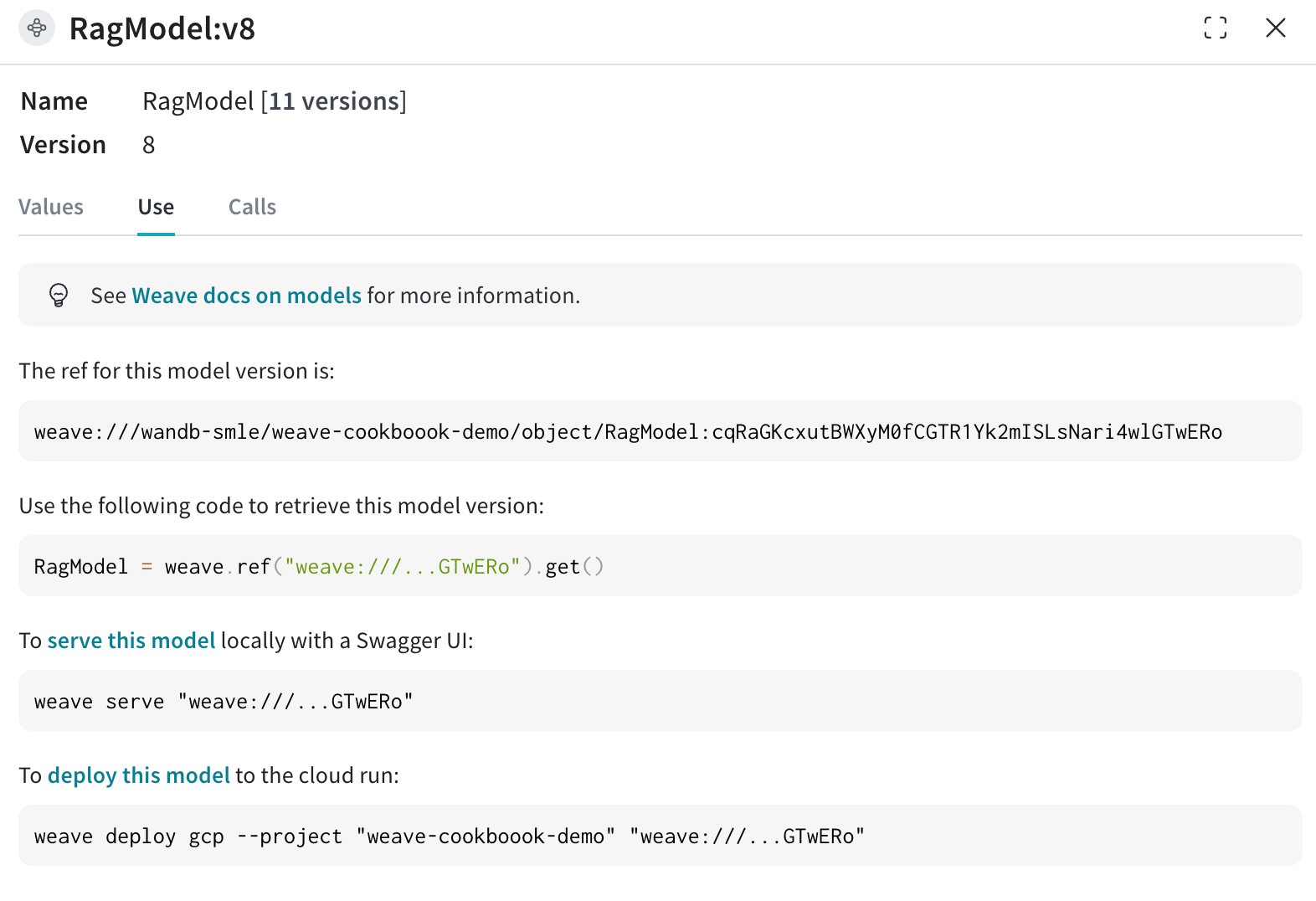
4. 既存のモデルの run に接続する新しい weave.Evaluation を実行する
最後に、既存の weave.Evaluation 上で新しい RagModel を評価します。統合をできるだけシンプルにするために、以下の変更を含みます。
モデルの観点から:
- Registry からモデルを取得すると新しい
wandb.runが作成され、チャットモデルのE2Eリネージの一部になります - 現在の評価IDを持つTrace IDを実行設定に追加し、モデルチームがリンクをクリックして対応する Weave ページに移動できるようにします
- アーティファクト / レジストリリンクを
ChatModel(つまりRagModel)への入力として保存します weave.attributesを使用して run.id をトレースの追加列として保存します