Try in Colab

early_stopping_rounds が必要でしょうか? ツリーの max_depth はどのくらいにすべきですか?
高次元のハイパーパラメータ空間を検索して最適なモデルを見つけることは非常に困難です。ハイパーパラメーター探索は、モデルのバトルロイヤルを組織的かつ効率的に実施し、勝者を決定する方法を提供します。これにより、ハイパーパラメータの組み合わせを自動的に検索して、最も最適な値を見つけ出すことができます。
このチュートリアルでは、Weights & Biases を使用して XGBoost モデルで洗練されたハイパーパラメーター探索を 3 つの簡単なステップで実行する方法を紹介します。
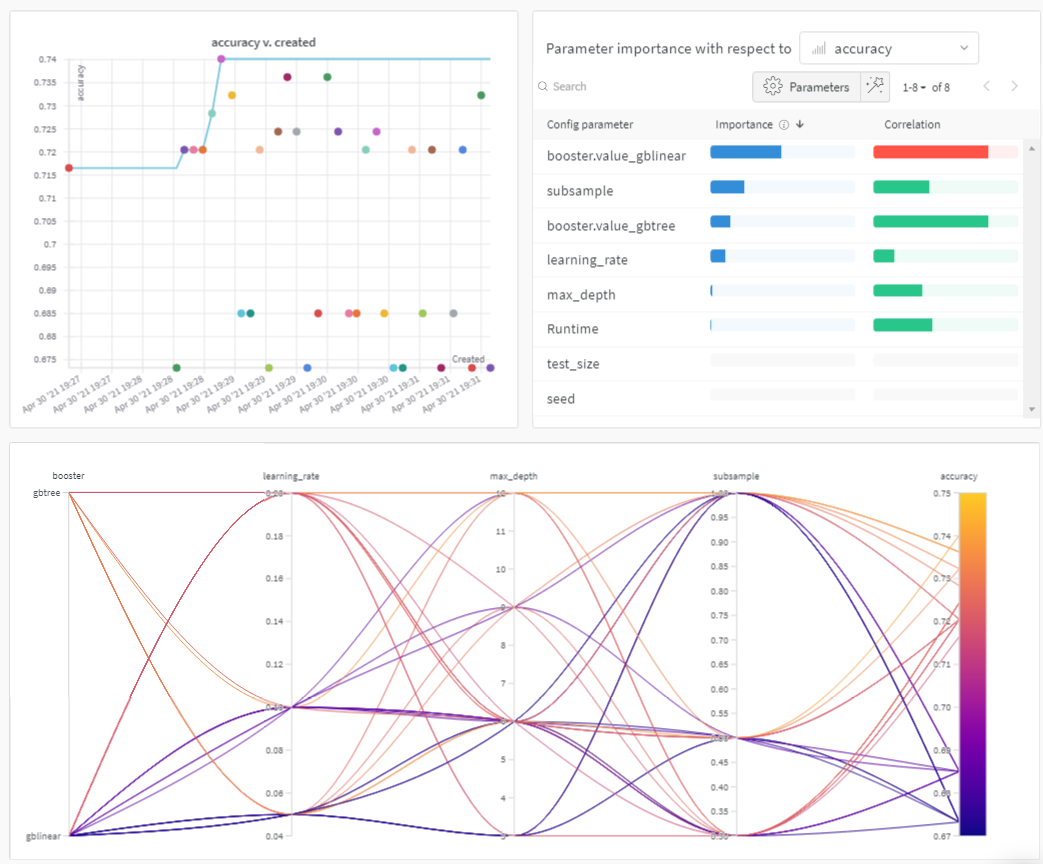
興味を引くために、以下のプロットをチェックしてください:
Sweeps: 概要
Weights & Biases を使ったハイパーパラメーター探索の実行は非常に簡単です。以下の3つのシンプルなステップです:- スイープを定義する: スイープを定義するためには、スイープを構成するパラメータ、使用する検索戦略、最適化するメトリクスを指定する辞書のようなオブジェクトを作成します。
-
スイープを初期化する: 1 行のコードでスイープを初期化し、スイープの設定の辞書を渡します:
sweep_id = wandb.sweep(sweep_config) -
スイープエージェントを実行する: これも 1 行のコードで、
wandb.agent()を呼び出し、sweep_idとモデルアーキテクチャを定義してトレーニングする関数を渡します:wandb.agent(sweep_id, function=train)
リソース
1. スイープを定義する
Weights & Biases の Sweeps は、希望通りにスイープを設定するための強力なレバーを少ないコード行で提供します。スイープの設定は、辞書または YAML ファイルとして定義できます。 それらのいくつかを一緒に見ていきましょう:- メトリック: これは、スイープが最適化しようとしているメトリックです。メトリクスは
name(トレーニングスクリプトでログされるべきメトリック名) とgoal(maximizeかminimize) を取ることができます。 - 検索戦略:
"method"キーを使用して指定されます。スイープでは、いくつかの異なる検索戦略をサポートしています。 - グリッド検索: ハイパーパラメーター値のすべての組み合わせを反復します。
- ランダム検索: ランダムに選ばれたハイパーパラメーター値の組み合わせを反復します。
- ベイズ探索: ハイパーパラメーターをメトリクススコアの確率とマッピングする確率モデルを作成し、メトリクスを改善する高い確率のパラメータを選択します。ベイズ最適化の目的は、ハイパーパラメーター値の選択に時間をかけることですが、その代わりにより少ないハイパーパラメーター値を試すことを試みます。
- パラメータ: ハイパーパラメータ名、離散値、範囲、または各反復で値を取り出す分布を含む辞書です。
2. スイープを初期化する
wandb.sweep を呼び出すとスイープコントローラー、つまり parameters の設定を問い合わせるすべての者に提供し、metrics のパフォーマンスを wandb ログを介して返すことを期待する集中プロセスが開始されます。
トレーニングプロセスを定義する
スイープを実行する前に、モデルを作成してトレーニングする関数を定義する必要があります。 この関数は、ハイパーパラメーター値を取り込み、メトリクスを出力するものです。 また、スクリプト内にwandb を統合する必要があります。
主なコンポーネントは3つです:
wandb.init(): 新しい W&B run を初期化します。各 run はトレーニングスクリプトの単一の実行です。wandb.config: すべてのハイパーパラメーターを設定 オブジェクトに保存します。これにより、私たちのアプリを使用して、ハイパーパラメーター値ごとに run をソートおよび比較することができます。wandb.log(): 画像、ビデオ、オーディオファイル、HTML、プロット、またはポイントクラウドなどのメトリクスとカスタムオブジェクトをログします。
3. エージェントでスイープを実行する
次に、wandb.agent を呼び出してスイープを起動します。
wandb.agent は W&B にログインしているすべてのマシンで呼び出すことができ、
sweep_id- データセットと
train関数
注意:randomスイープはデフォルトでは永遠に実行され、新しいパラメータの組み合わせを試し続けます。しかし、それはアプリの UI からスイープをオフにするまでです。完了する run の合計countをagentに指定することで、この動作を防ぐことができます。
結果を可視化する
スイープが終了したら、結果を確認します。 Weights & Biases は、あなたのために便利なプロットをいくつか自動的に生成します。パラレル座標プロット
このプロットは、ハイパーパラメーター値をモデルのメトリクスにマッピングします。最良のモデルパフォーマンスをもたらしたハイパーパラメーターの組み合わせに焦点を当てるのに役立ちます。 このプロットは、単純な線形モデルを学習者として使用するよりも、ツリーを学習者として使用する方がやや優れていることを示しているようです。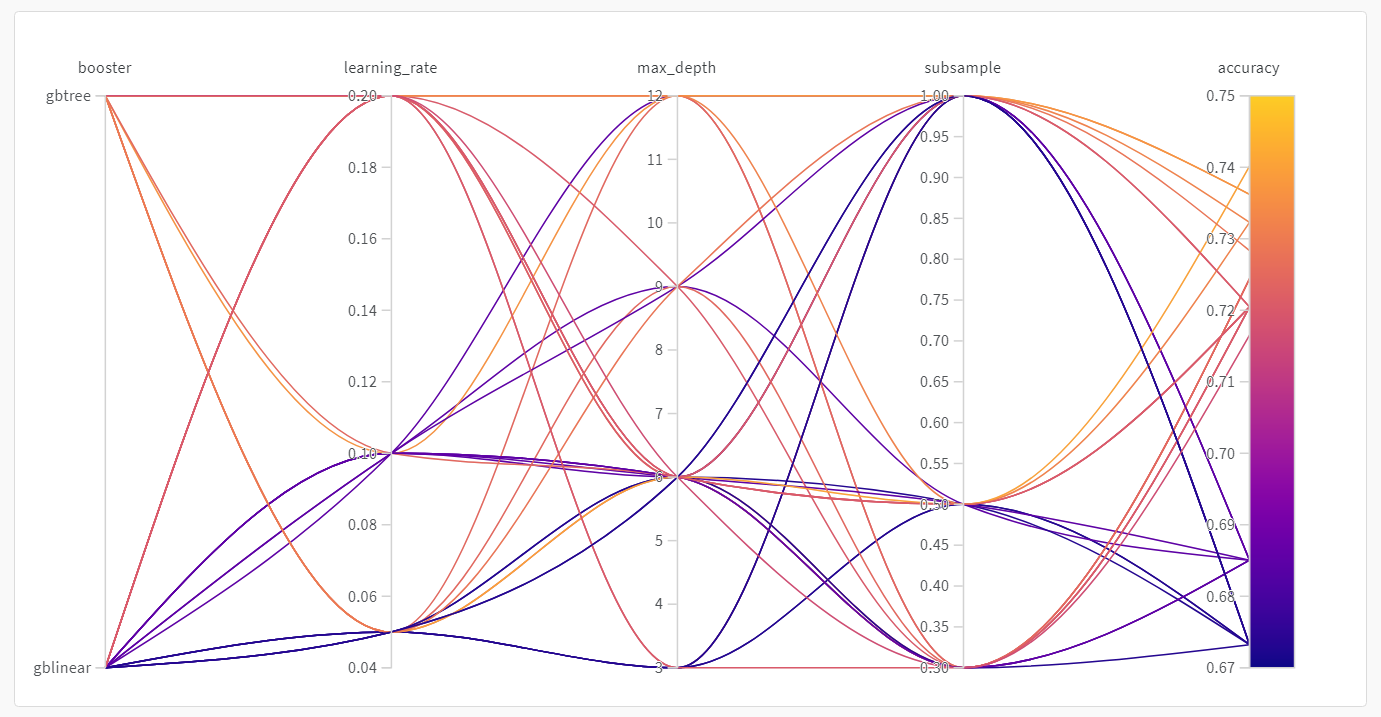
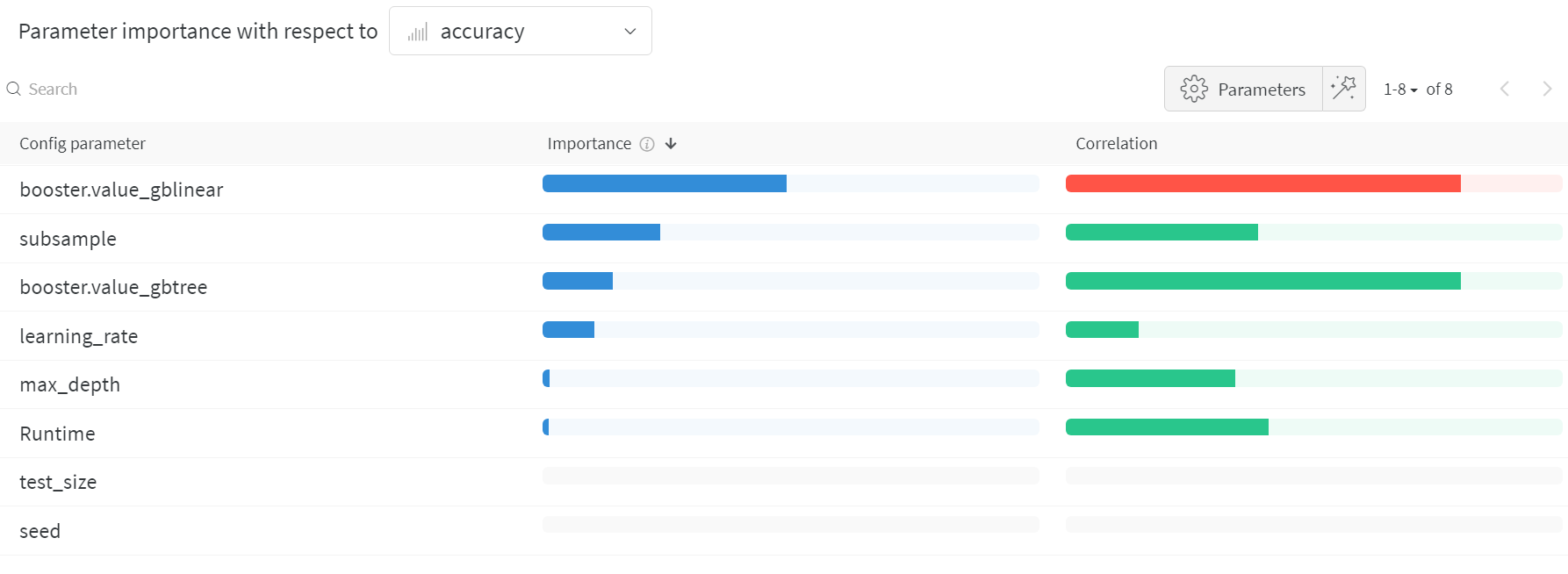
ハイパーパラメーターの重要度プロット
ハイパーパラメーターの重要度プロットは、メトリクスに最も大きな影響を与えたハイパーパラメーター値を示しています。 相関関係(線形予測子として扱う)と特徴量の重要性(結果に基づいてランダムフォレストをトレーニングした後) の両方を報告しますので、どのパラメータが最も大きな影響を与えたか、そしてその影響がどちらの方向であったかを確認できます。 このチャートを読むと、上記のパラレル座標チャートで気づいた傾向の定量的な確認が得られます。検証精度に最大の影響を与えたのは学習者の選択であり、gblinear 学習者は一般的に gbtree 学習者よりも劣っていました。