필수 조건 설치
autotrain-advanced 및 wandb를 설치합니다.
- 커맨드라인
- 노트북
pass@1로 SoTA 결과를 달성합니다.
데이터셋 준비
Hugging Face AutoTrain은 제대로 작동하기 위해 CSV 커스텀 데이터셋에 특정 형식이 필요합니다.-
트레이닝 파일에는 트레이닝에 사용되는
text열이 있어야 합니다. 최상의 결과를 얻으려면text열의 데이터가### Human: Question?### Assistant: Answer.형식을 준수해야 합니다.timdettmers/openassistant-guanaco에서 훌륭한 예를 검토하십시오. 그러나 MetaMathQA 데이터셋에는query,response및type열이 포함되어 있습니다. 먼저 이 데이터셋을 전처리합니다.type열을 제거하고query및response열의 내용을### Human: Query?### Assistant: Response.형식의 새text열로 결합합니다. 트레이닝은 결과 데이터셋인rishiraj/guanaco-style-metamath를 사용합니다.
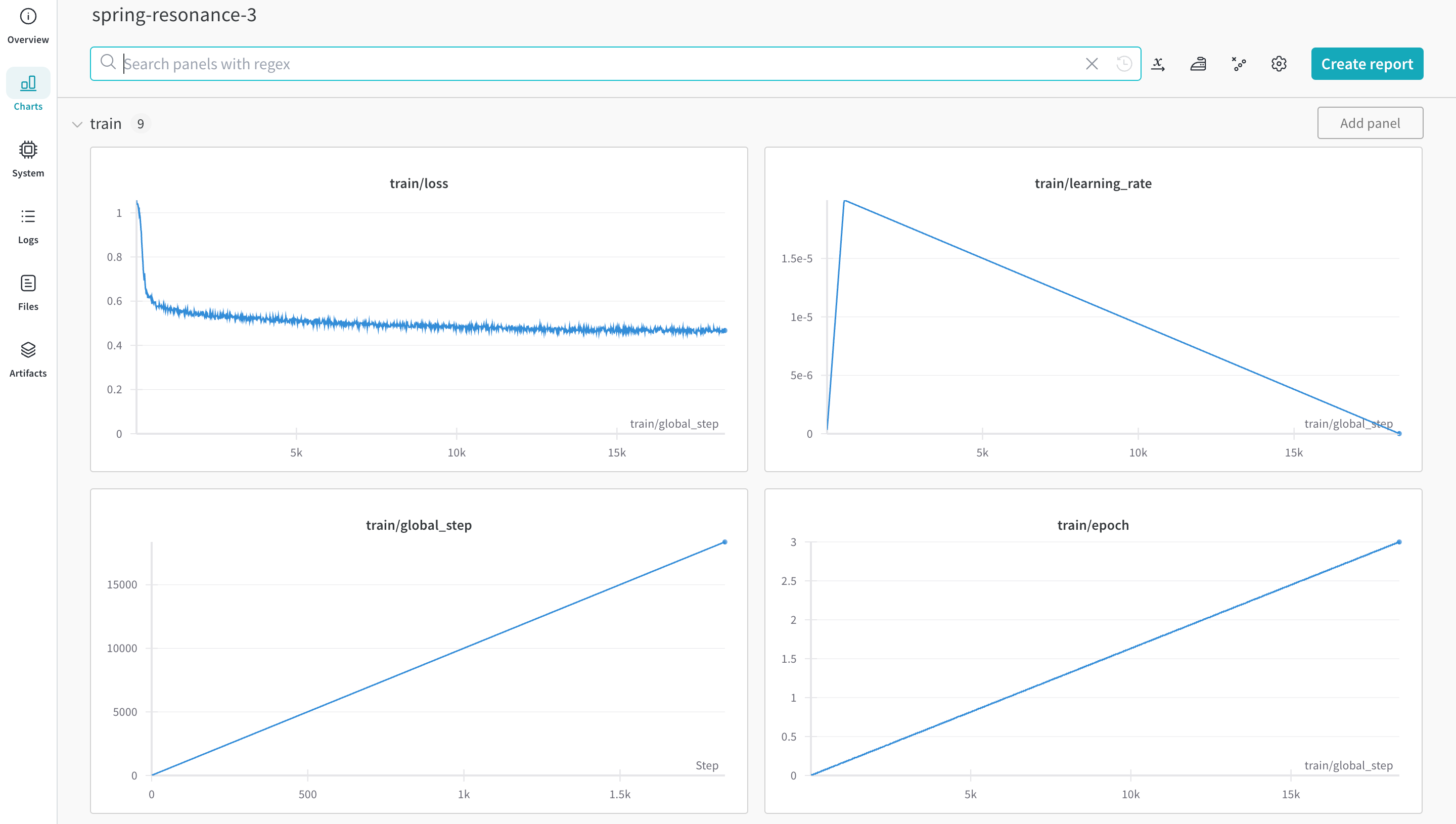
autotrain을 사용하여 트레이닝
커맨드 라인 또는 노트북에서 autotrain advanced를 사용하여 트레이닝을 시작할 수 있습니다. --log 인수를 사용하거나 --log wandb를 사용하여 결과를 W&B run에 기록합니다.
- 커맨드라인
- 노트북