예제 블로그 & Colab
ICDAR2015 데이터셋에서 PaddleOCR로 모델을 트레이닝하는 방법은 여기 에서 확인하세요. Google Colab 도 함께 제공되며, 해당 라이브 W&B 대시보드는 여기 에서 확인할 수 있습니다. 이 블로그의 중국어 버전은 W&B对您的OCR模型进行训练和调试 에서 확인할 수 있습니다.가입하고 API 키 만들기
API 키는 사용자의 머신을 W&B에 인증합니다. 사용자 프로필에서 API 키를 생성할 수 있습니다.보다 간소화된 접근 방식을 위해 https://wandb.ai/authorize 로 직접 이동하여 API 키를 생성할 수 있습니다. 표시된 API 키를 복사하여 비밀번호 관리자와 같은 안전한 위치에 저장하세요.
- 오른쪽 상단에서 사용자 프로필 아이콘을 클릭합니다.
- User Settings를 선택한 다음 API Keys 섹션으로 스크롤합니다.
- Reveal을 클릭합니다. 표시된 API 키를 복사합니다. API 키를 숨기려면 페이지를 새로 고칩니다.
wandb 라이브러리 설치 및 로그인
wandb 라이브러리를 로컬에 설치하고 로그인하려면 다음을 수행합니다.
- Command Line
- Python
- Python notebook
-
WANDB_API_KEY환경 변수 를 API 키로 설정합니다. -
wandb라이브러리를 설치하고 로그인합니다.
config.yml 파일에 wandb 추가
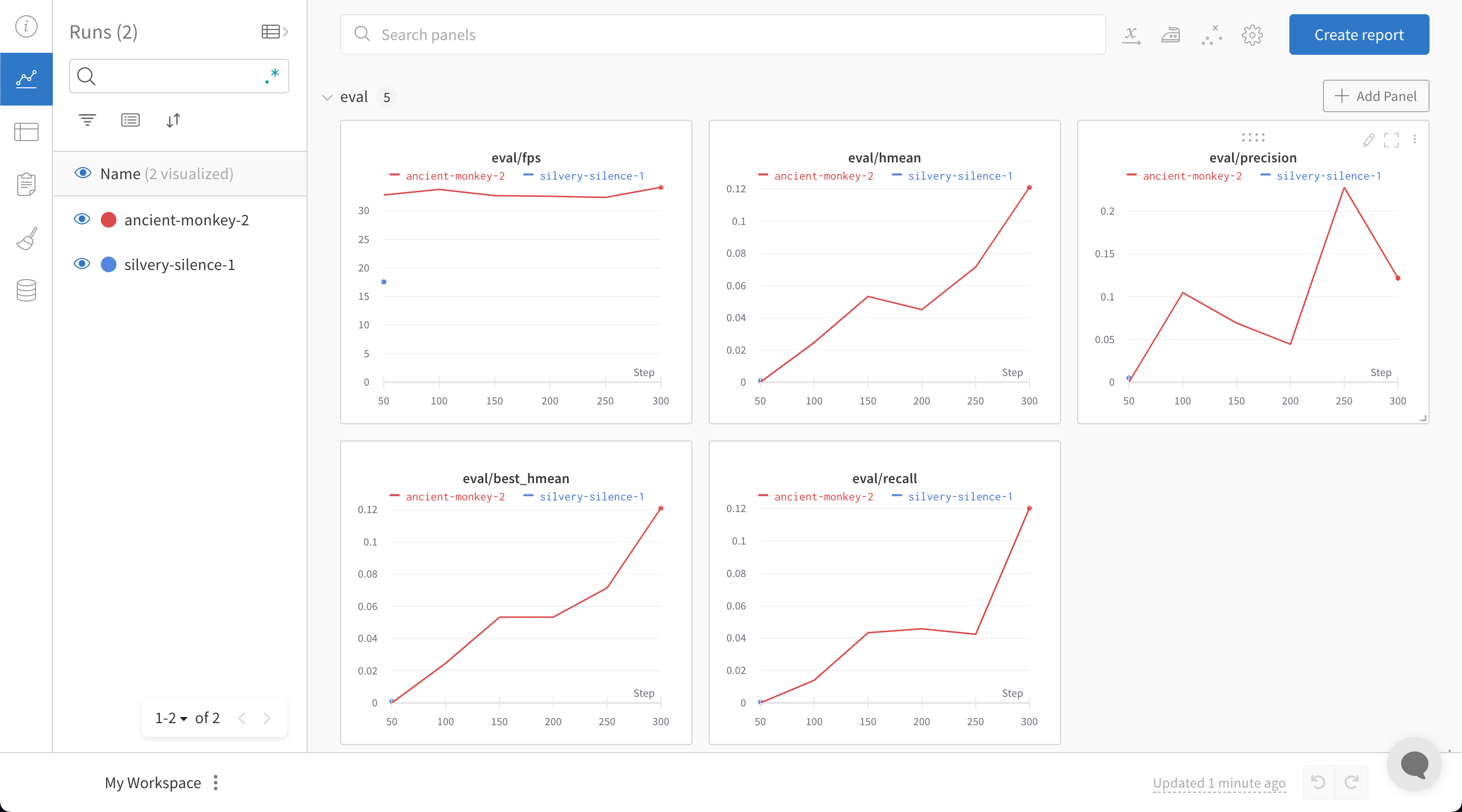
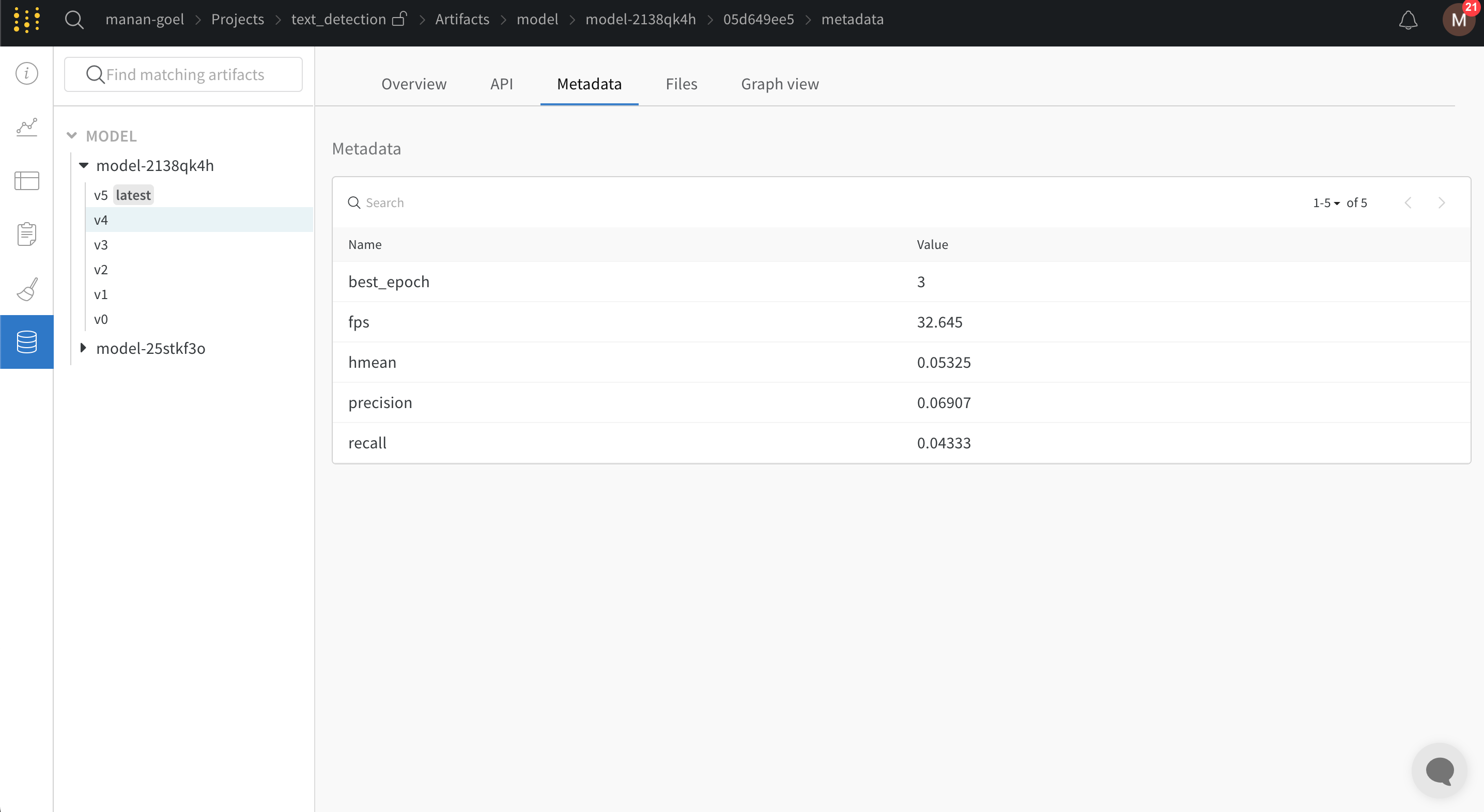
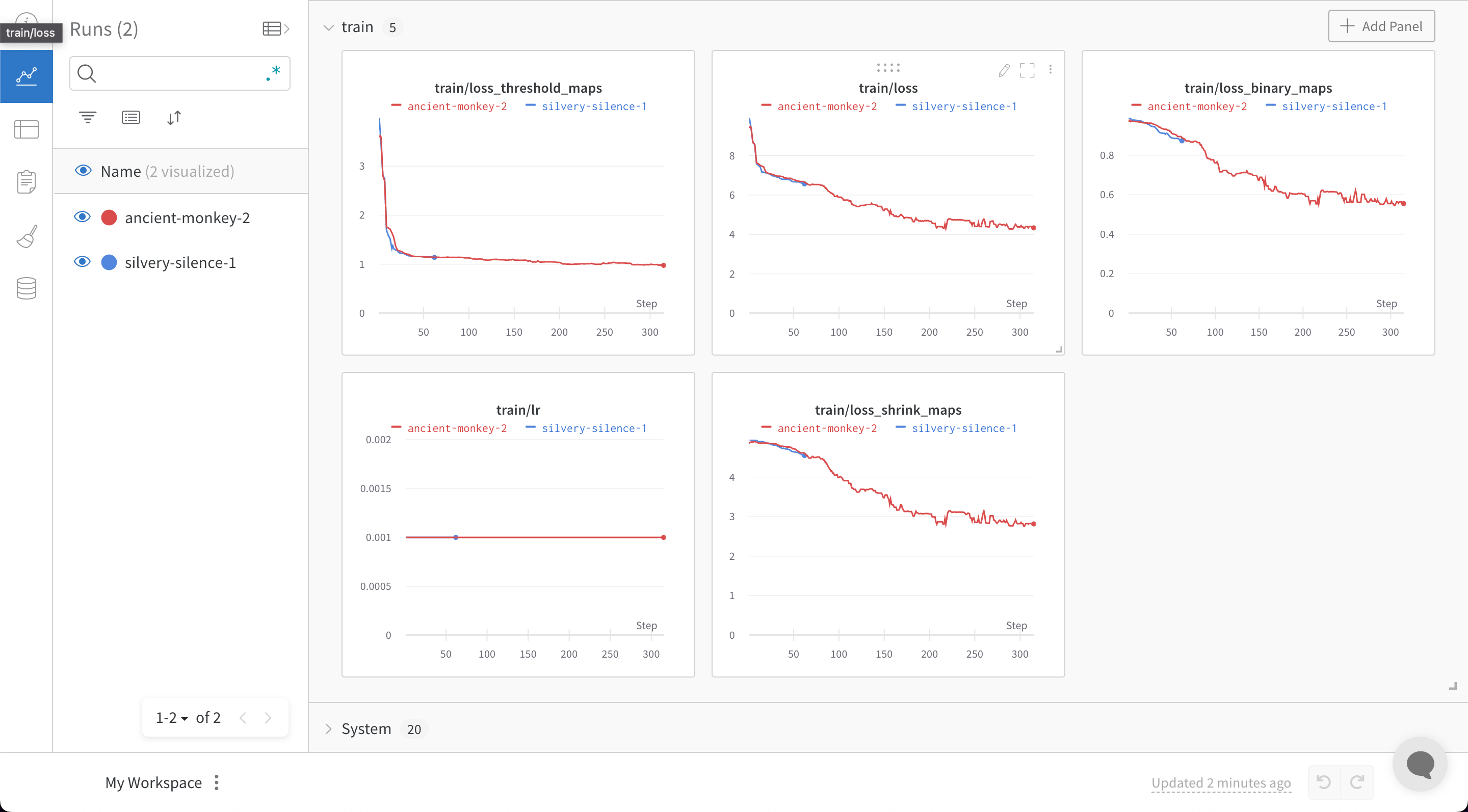
PaddleOCR은 yaml 파일을 사용하여 구성 변수를 제공해야 합니다. 구성 yaml 파일의 끝에 다음 스니펫을 추가하면 모든 트레이닝 및 유효성 검사 메트릭이 모델 체크포인트와 함께 W&B 대시보드에 자동으로 기록됩니다.
wandb.init 에 전달하려는 추가적인 선택적 인수는 yaml 파일의 wandb 헤더 아래에 추가할 수도 있습니다.
config.yml 파일을 train.py 에 전달
그런 다음 yaml 파일은 PaddleOCR 저장소에서 사용할 수 있는 트레이닝 스크립트 에 인수로 제공됩니다.
train.py 파일을 실행하면 W&B 대시보드로 이동하는 링크가 생성됩니다.