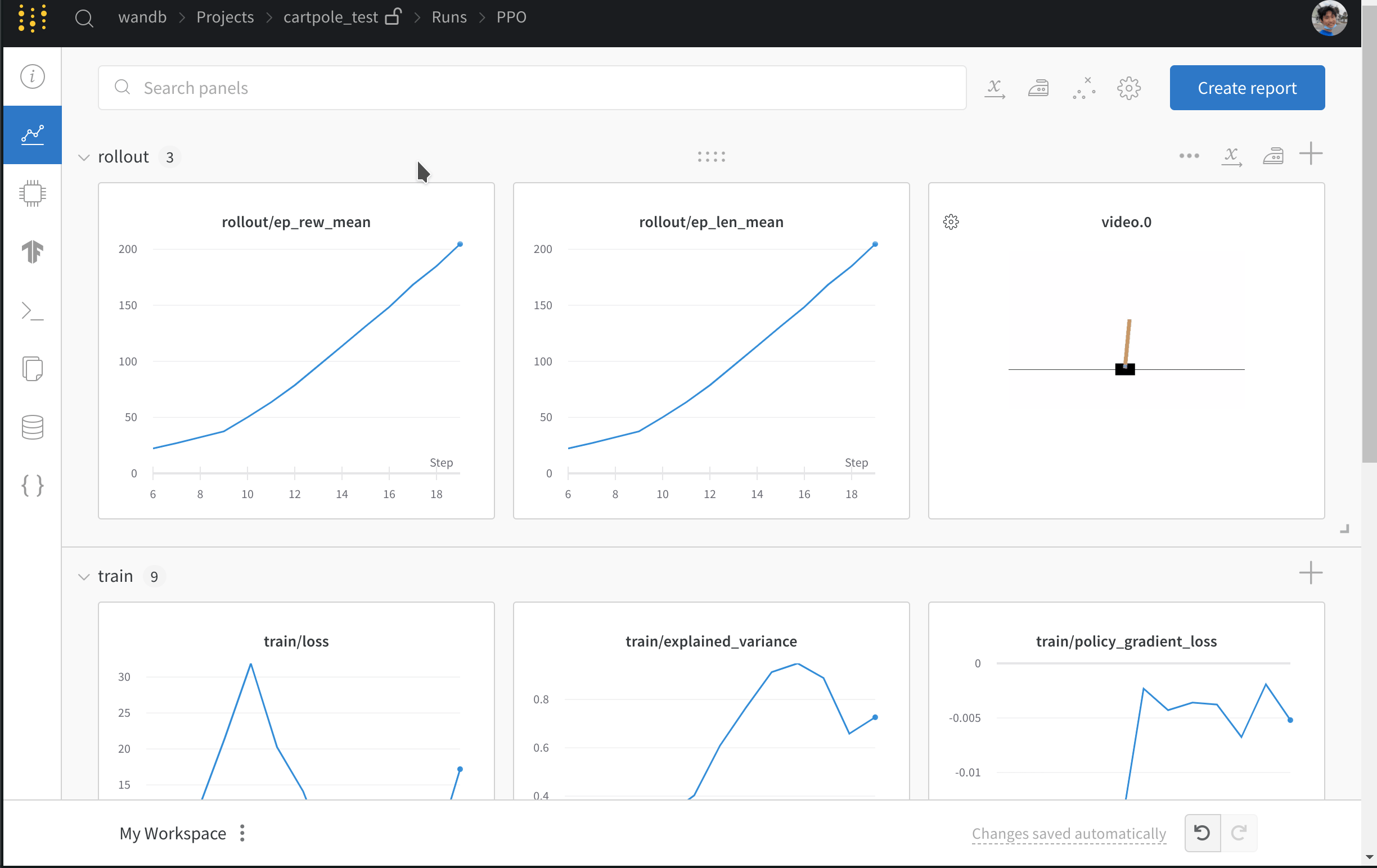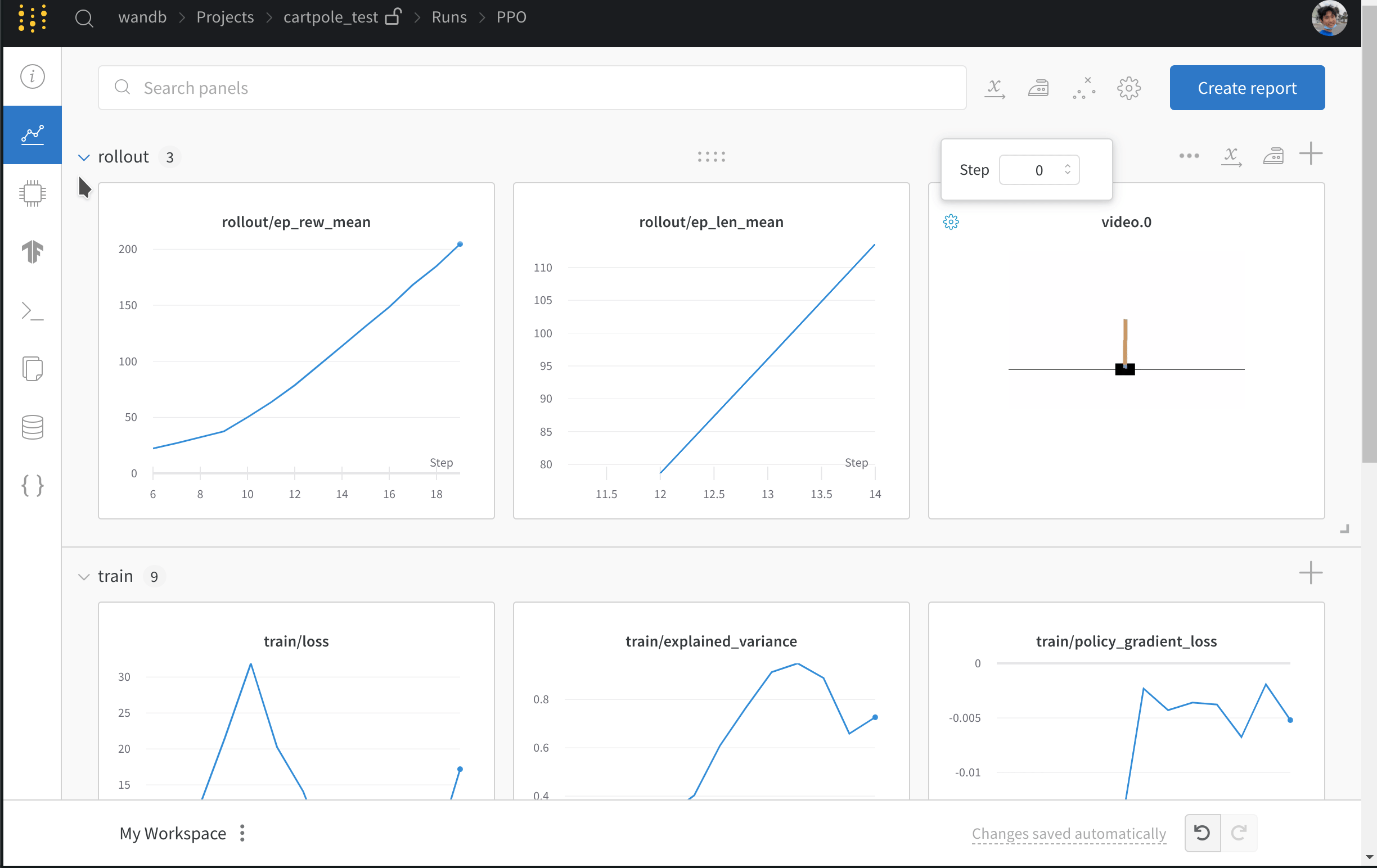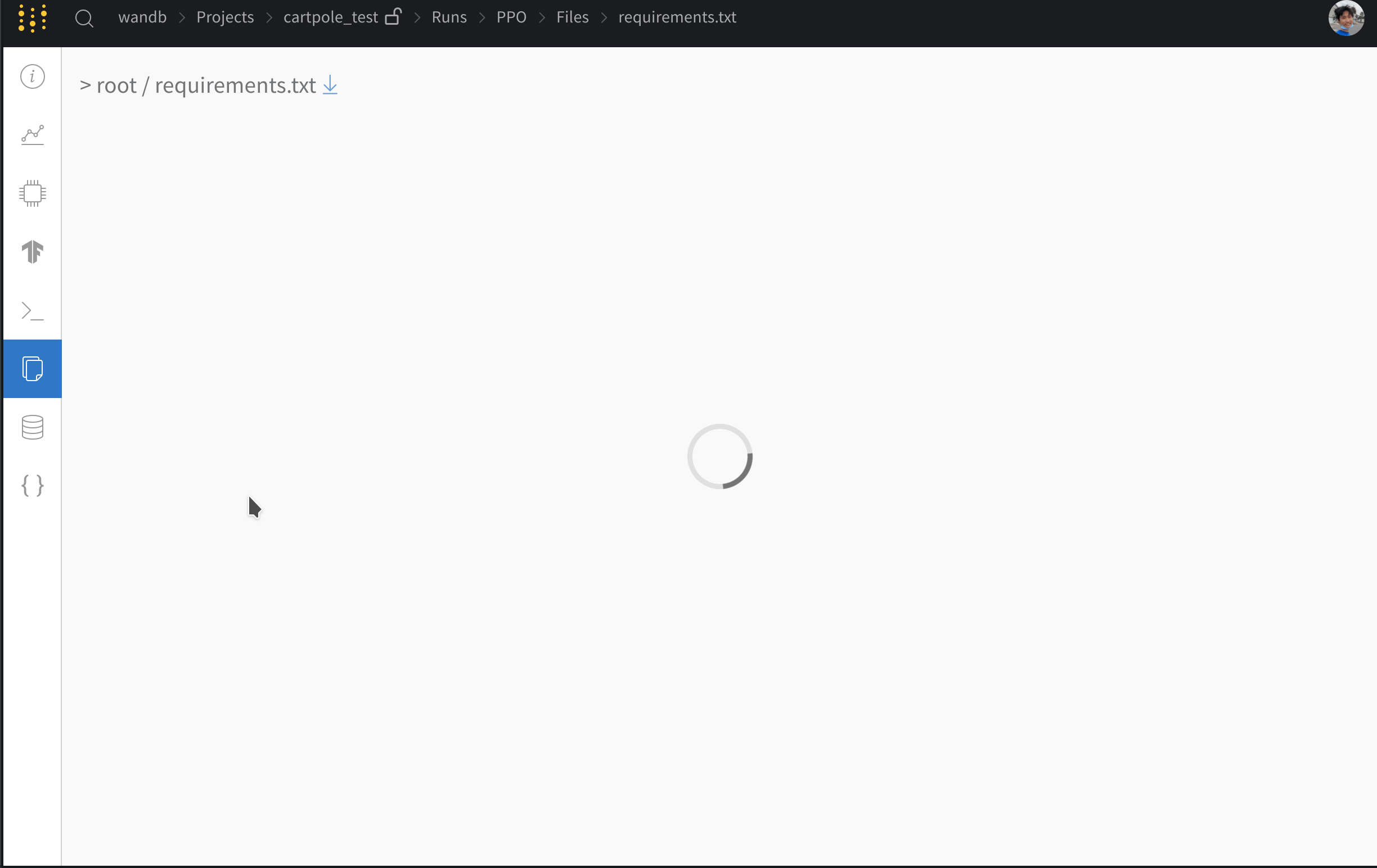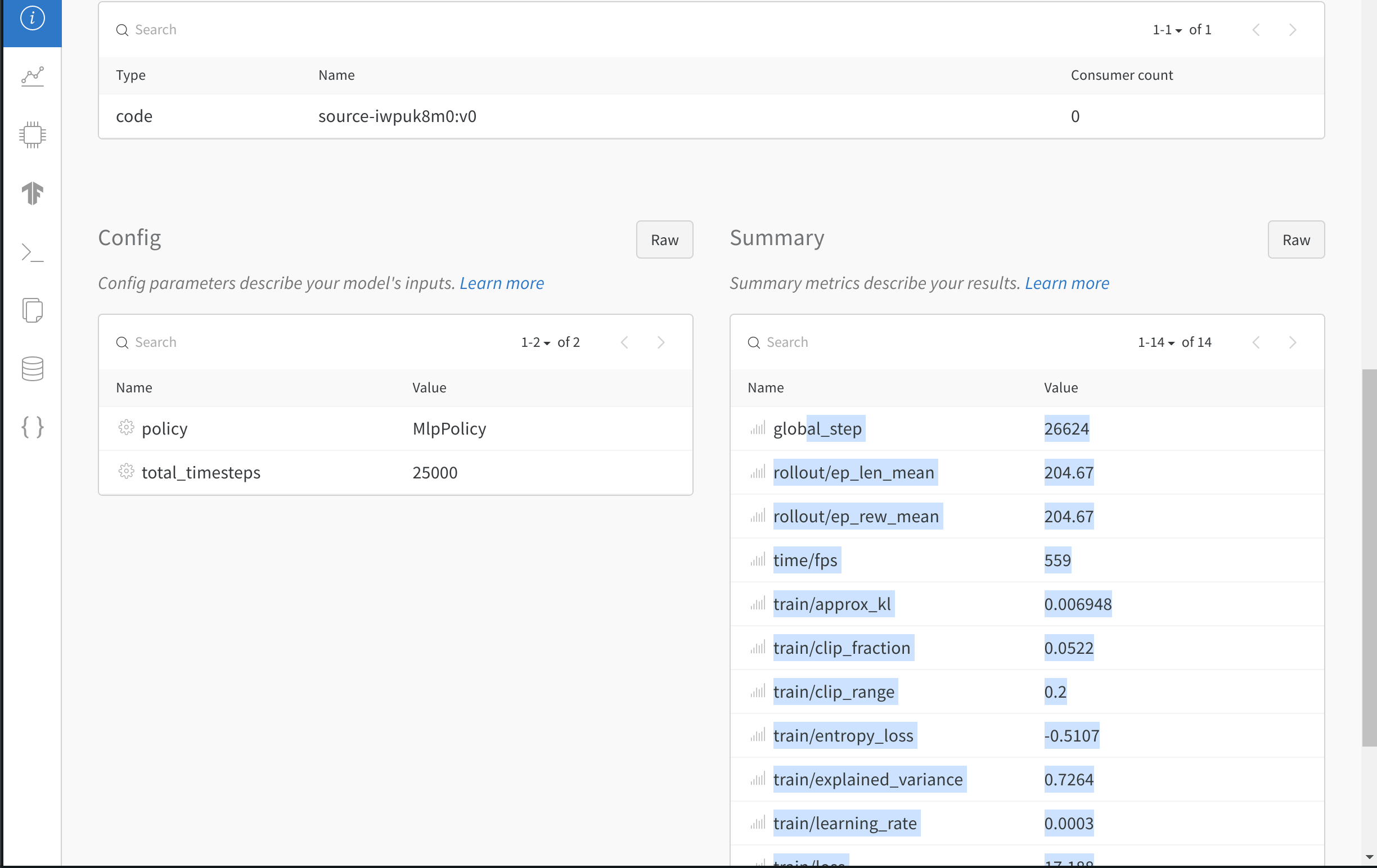
- 손실 및 에피소드별 반환과 같은 메트릭을 기록합니다.
- 에이전트가 게임을 플레이하는 비디오를 업로드합니다.
- 트레이닝된 모델을 저장합니다.
- 모델의 하이퍼파라미터를 기록합니다.
- 모델 그래디언트 히스토그램을 기록합니다.
SB3 Experiments 기록
WandbCallback 인수
| 인수 | 사용법 |
|---|---|
verbose | sb3 출력의 상세 정도 |
model_save_path | 모델이 저장될 폴더 경로. 기본값은 `None`이며, 모델은 기록되지 않습니다 |
model_save_freq | 모델 저장 빈도 |
gradient_save_freq | 그래디언트를 기록하는 빈도. 기본값은 0이며, 그래디언트는 기록되지 않습니다 |