Try in Colab

이 노트북에서 다루는 내용
Weights & Biases 와 PyTorch 코드를 통합하여 파이프라인에 실험 추적을 추가하는 방법을 보여줍니다.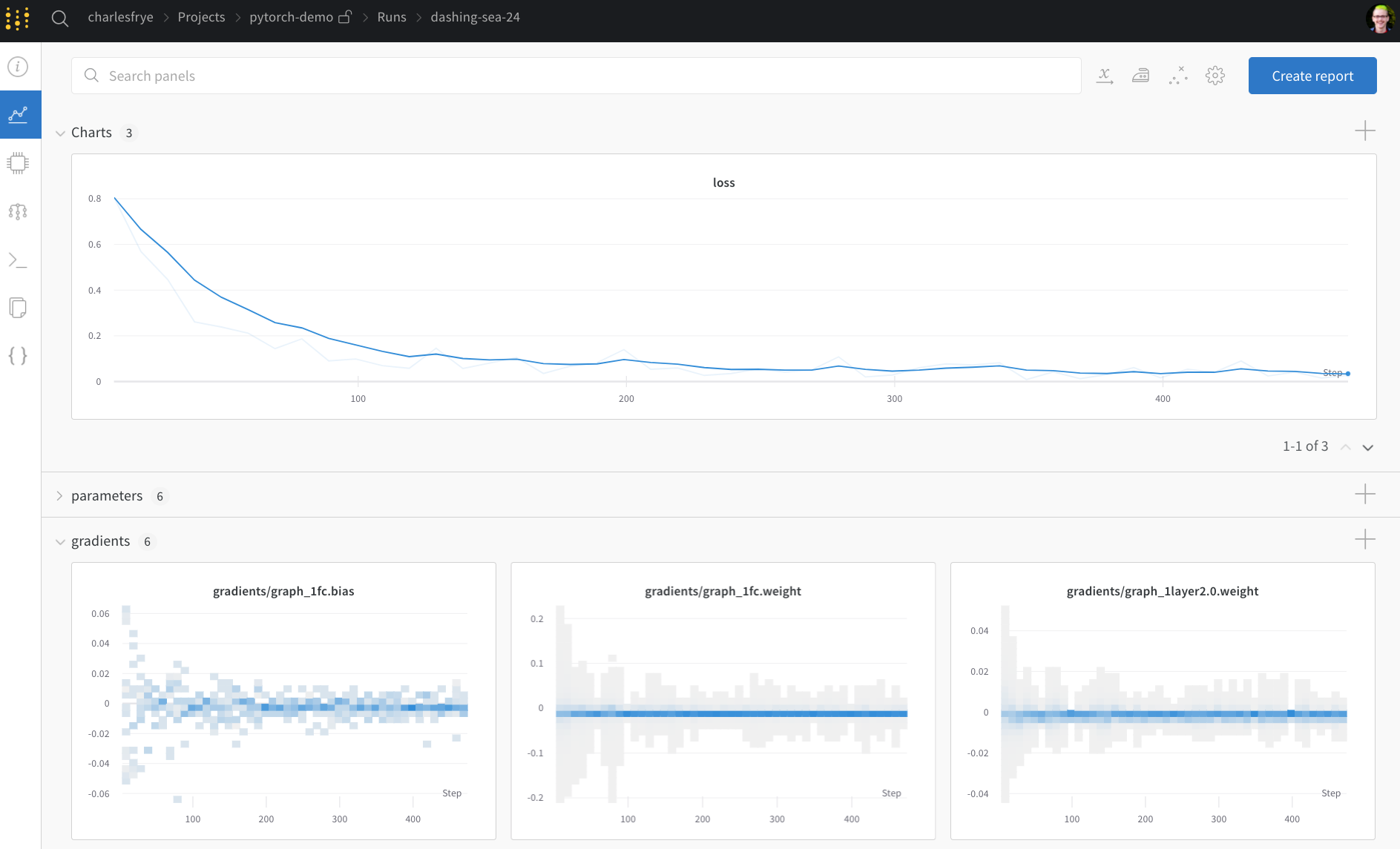
설치, 임포트 및 로그인
0단계: W&B 설치
시작하려면 라이브러리를 가져와야 합니다.wandb 는 pip 를 사용하여 쉽게 설치할 수 있습니다.
1단계: W&B 임포트 및 로그인
웹 서비스에 데이터를 기록하려면 로그인해야 합니다. W&B 를 처음 사용하는 경우 나타나는 링크에서 무료 계정에 가입해야 합니다.실험 및 파이프라인 정의
wandb.init 로 메타데이터 및 하이퍼파라미터 추적
프로그래밍 방식으로 가장 먼저 하는 일은 실험을 정의하는 것입니다.
하이퍼파라미터는 무엇입니까? 이 run 과 연결된 메타데이터는 무엇입니까?
이 정보를 config 사전에 저장하는 것은 매우 일반적인 워크플로우입니다
(또는 유사한 오브젝트)
필요에 따라 엑세스합니다.
이 예에서는 몇 가지 하이퍼파라미터만 변경하고
나머지는 수동으로 코딩합니다.
그러나 모델의 모든 부분이 config 의 일부가 될 수 있습니다.
또한 MNIST 데이터셋과 컨볼루션
아키텍처를 사용하고 있다는 메타데이터도 포함합니다. 나중에 동일한 프로젝트에서 CIFAR 에 대한 완전 연결 아키텍처를 사용하는 경우
run 을 분리하는 데 도움이 됩니다.
- 먼저 모델과 관련 데이터 및 옵티마이저를
make한 다음 - 모델을 적절하게
train하고 마지막으로 test하여 트레이닝이 어떻게 진행되었는지 확인합니다.
wandb.init 의 컨텍스트 내에서 발생한다는 것입니다.
이 함수를 호출하면 코드와 서버 간에 통신 라인이 설정됩니다.
config 사전을 wandb.init 에 전달하면
해당 정보가 즉시 기록되므로
실험에서 사용할 하이퍼파라미터 값을 항상 알 수 있습니다.
선택하고 기록한 값이 항상 모델에서 사용되는지 확인하려면
오브젝트의 wandb.config 사본을 사용하는 것이 좋습니다.
몇 가지 예제를 보려면 아래 make 의 정의를 확인하세요.
참고: 코드를 별도의 프로세스에서 실행하도록 주의합니다.
따라서 당사 측의 문제
(예: 거대한 바다 괴물이 데이터 센터를 공격하는 경우)
코드가 충돌하지 않습니다.
크라켄이 심해로 돌아갈 때와 같이 문제가 해결되면
wandb sync 로 데이터를 기록할 수 있습니다.
데이터 로딩 및 모델 정의
이제 데이터를 로드하는 방법과 모델의 모양을 지정해야 합니다. 이 부분은 매우 중요하지만wandb 가 없으면 달라지지 않으므로
자세히 설명하지 않겠습니다.
wandb 에서는 아무것도 변경되지 않으므로
표준 ConvNet 아키텍처를 고수할 것입니다.
이것저것 만지작거리고 실험을 두려워하지 마세요.
모든 결과는 wandb.ai 에 기록됩니다.
트레이닝 로직 정의
model_pipeline 에서 계속 진행하여 train 방법을 지정할 시간입니다.
여기서 두 개의 wandb 함수가 사용됩니다. watch 와 log 입니다.
wandb.watch 로 그레이디언트를 추적하고 wandb.log 로 다른 모든 것을 추적합니다
wandb.watch 는 트레이닝의 모든 log_freq 단계에서 모델의 그레이디언트와 파라미터를 기록합니다.
트레이닝을 시작하기 전에 호출하기만 하면 됩니다.
나머지 트레이닝 코드는 동일하게 유지됩니다.
에포크와 배치를 반복하고,
forward 및 backward 패스를 실행하고
옵티마이저 를 적용합니다.
wandb.log 에 전달합니다.
wandb.log 는 문자열을 키로 사용하는 사전을 예상합니다.
이러한 문자열은 기록되는 오브젝트를 식별하며, 값을 구성합니다.
선택적으로 트레이닝의 step 을 기록할 수도 있습니다.
참고: 모델이 확인한 예제 수를 사용하는 것을 좋아합니다.
배치 크기 간에 더 쉽게 비교할 수 있기 때문입니다.
하지만 원시 단계 또는 배치 수를 사용할 수 있습니다. 트레이닝 run 이 더 길어지면 에포크 로 기록하는 것이 좋습니다.
테스팅 로직 정의
모델 트레이닝이 완료되면 테스트해야 합니다. 프로덕션의 최신 데이터에 대해 실행하거나 수동으로 큐레이팅된 예제에 적용합니다.(선택 사항) wandb.save 호출
모델 아키텍처를 저장하는 것도 좋은 시기입니다
디스크에 최종 파라미터를 저장합니다.
최대 호환성을 위해 모델을
ONNX (Open Neural Network eXchange) 형식으로 내보냅니다.
해당 파일 이름을 wandb.save 에 전달하면 모델 파라미터가
W&B 서버에 저장됩니다. 더 이상 어떤 .h5 또는 .pb 가
어떤 트레이닝 run 에 해당하는지 추적하지 않아도 됩니다.
모델 저장, 버전 관리 및 배포를 위한 더 고급 wandb 기능은
Artifacts 툴을 확인하세요.
wandb.ai 에서 트레이닝을 실행하고 메트릭을 실시간으로 확인하세요
전체 파이프라인을 정의하고 몇 줄의 W&B 코드를 추가했으므로 완전히 추적된 실험을 실행할 준비가 되었습니다. 몇 가지 링크를 보고합니다. 당사의 설명서, 프로젝트의 모든 run 을 구성하는 프로젝트 페이지, 이 run 의 결과가 저장될 Run 페이지입니다. Run 페이지로 이동하여 다음 탭을 확인하세요.- 차트, 트레이닝 전반에 걸쳐 모델 그레이디언트, 파라미터 값 및 손실이 기록됩니다.
- 시스템, 디스크 I/O 활용률, CPU 및 GPU 메트릭 (온도가 급상승하는 것을 확인하세요) 등을 포함한 다양한 시스템 메트릭이 포함되어 있습니다.
- 로그, 트레이닝 중에 표준 출력으로 푸시된 모든 항목의 사본이 있습니다.
- 파일, 트레이닝이 완료되면
model.onnx를 클릭하여 Netron 모델 뷰어로 네트워크를 볼 수 있습니다.
with wandb.init 블록이 종료될 때 run 이 완료되면
셀 출력에 결과 요약도 인쇄합니다.
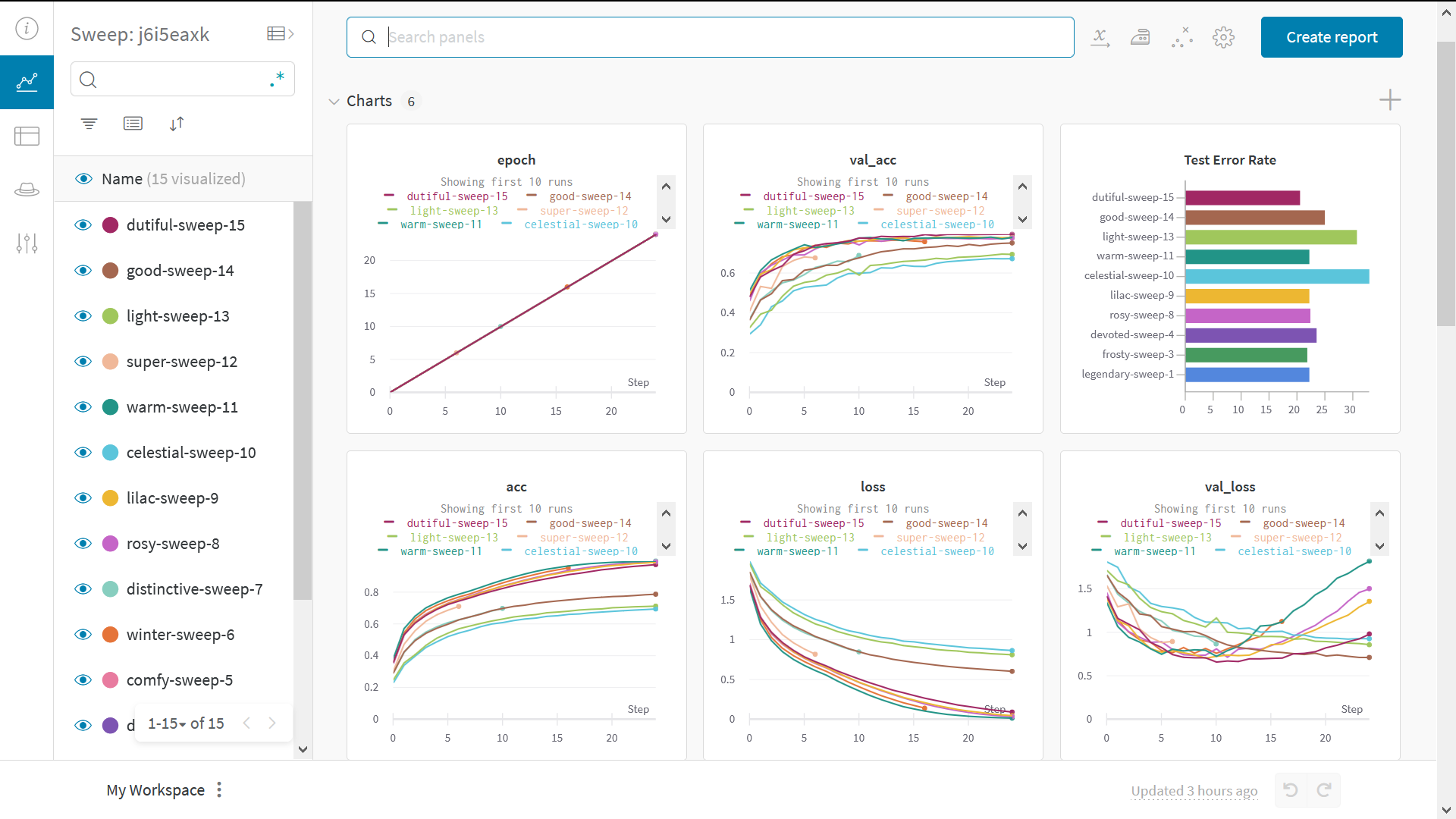
Sweeps 로 하이퍼파라미터 테스트
이 예에서는 하이퍼파라미터의 단일 세트만 살펴보았습니다. 그러나 대부분의 ML 워크플로우에서 중요한 부분은 여러 하이퍼파라미터를 반복하는 것입니다. Weights & Biases Sweeps 를 사용하여 하이퍼파라미터 테스팅을 자동화하고 가능한 모델 및 최적화 전략 공간을 탐색할 수 있습니다.W&B Sweeps 를 사용하여 PyTorch 에서 하이퍼파라미터 최적화 확인
Weights & Biases 로 하이퍼파라미터 스윕을 실행하는 것은 매우 쉽습니다. 다음과 같은 3가지 간단한 단계가 있습니다.- 스윕 정의: 검색할 파라미터, 검색 전략, 최적화 메트릭 등을 지정하는 사전 또는 YAML 파일을 만들어 이 작업을 수행합니다.
-
스윕 초기화:
sweep_id = wandb.sweep(sweep_config) -
스윕 에이전트 실행:
wandb.agent(sweep_id, function=train)