> ## Documentation Index
> Fetch the complete documentation index at: https://docs.wandb.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# DSPy 프롬프트 최적화
> W&B Weave를 사용해 dspy 프롬프트 최적화를 수행하는 방법을 알아보세요
이 문서는 대화형 노트북입니다. 로컬에서 실행하거나 다음 링크를 사용할 수 있습니다.
* [Google Colab에서 열기](https://colab.research.google.com/github/wandb/docs/blob/main/weave/cookbooks/source/dspy_prompt_optimization.ipynb)
* [GitHub에서 소스 보기](https://github.com/wandb/docs/blob/main/weave/cookbooks/source/dspy_prompt_optimization.ipynb)
[BIG-bench (Beyond the Imitation Game Benchmark)](https://github.com/google/BIG-bench)는 대규모 언어 모델을 평가하고, 200개가 넘는 작업 전반에서 이들의 미래 역량을 예측하는 협업형 벤치마크입니다. [BIG-Bench Hard (BBH)](https://github.com/suzgunmirac/BIG-Bench-Hard)는 현세대 언어 모델이 해결하기 어려워할 수 있는 BIG-Bench 작업 23개를 모아 놓은 벤치마크 모음입니다.
이 튜토리얼에서는 BIG-bench Hard 벤치마크의 인과 판단 작업을 바탕으로 구현한 LLM 워크플로의 성능을 개선하고, 프롬프팅 전략을 평가하는 방법을 보여줍니다. [DSPy](https://dspy.ai)를 사용해 LLM 워크플로를 구현하고 프롬프팅 전략을 최적화합니다. 또한 [Weave](/ko/weave)를 사용해 LLM 워크플로를 추적하고 프롬프팅 전략을 평가합니다.
이 튜토리얼을 마치면 인과 추론을 위한 베이스라인 DSPy 프로그램을 구축하고, Weave로 이를 평가하고, DSPy 옵티마이저를 적용해 프롬프팅 전략을 개선하고, 최적화된 프로그램을 베이스라인 프로그램과 비교할 수 있게 됩니다. 이 튜토리얼은 자신의 LLM 워크플로에 프롬프트 최적화를 적용하고 Weave로 결과를 추적하고 비교하려는 실무자를 위한 내용입니다.
## 의존성 설치
시작하기 전에 이 튜토리얼 전반에서 사용할 라이브러리를 설치하세요. 이 튜토리얼에서는 다음 라이브러리를 사용합니다:
* [DSPy](https://dspy.ai): LLM 워크플로를 구축하고 최적화하는 데 사용합니다.
* [Weave](/ko/weave): LLM 워크플로를 추적하고 프롬프팅 전략을 평가하는 데 사용합니다.
* [datasets](https://huggingface.co/docs/datasets/index): HuggingFace Hub에서 BIG-Bench Hard 데이터셋에 액세스하는 데 사용합니다.
```python lines theme={null}
!pip install -qU dspy weave "datasets<4"
```
이 튜토리얼에서는 LLM 공급업체로 [OpenAI API](https://openai.com/index/openai-api/)를 사용하므로 OpenAI API 키도 필요합니다. OpenAI 플랫폼에서 [회원가입](https://platform.openai.com/signup)하여 직접 API 키를 발급받을 수 있습니다.
```python lines theme={null}
import os
from getpass import getpass
api_key = getpass("Enter you OpenAI API key: ")
os.environ["OPENAI_API_KEY"] = api_key
```
## Weave를 사용해 추적 활성화
이 섹션에서는 튜토리얼의 이후 DSPy Call이 자동으로 트레이스되고 Weave UI에서 볼 수 있도록 Weave를 구성합니다.
Weave는 DSPy와 통합되어 있습니다. 코드 시작 부분에 [`weave.init`](/ko/weave/reference/python-sdk/trace/weave_client#method-init)을 포함하면 DSPy 함수가 자동으로 트레이스되며, 이후 Weave UI에서 이를 탐색할 수 있습니다. 자세한 내용은 [DSPy용 Weave 인테그레이션 문서](/ko/weave/guides/integrations/dspy)를 확인하세요.
```python lines theme={null}
import weave
weave.init(project_name="dspy-bigbench-hard")
```
이 튜토리얼에서는 [`weave.Object`](/ko/weave/reference/python-sdk#class-object)를 상속한 메타데이터 클래스를 사용해 메타데이터를 관리합니다.
```python lines theme={null}
class Metadata(weave.Object):
dataset_address: str = "maveriq/bigbenchhard"
big_bench_hard_task: str = "causal_judgement"
num_train_examples: int = 50
openai_model: str = "gpt-4o-mini"
openai_max_tokens: int = 2048
max_bootstrapped_demos: int = 8
max_labeled_demos: int = 8
metadata = Metadata()
```
객체 버전 관리: `Metadata` 객체를 사용하는 함수가 트레이스되면, 해당 객체도 자동으로 버전 관리되고 트레이스됩니다.
## BIG-Bench Hard 데이터셋 불러오기
Weave 추적을 활성화했다면, 다음 단계는 DSPy 프로그램을 트레이닝하고 평가하는 데 사용할 데이터를 준비하는 것입니다.
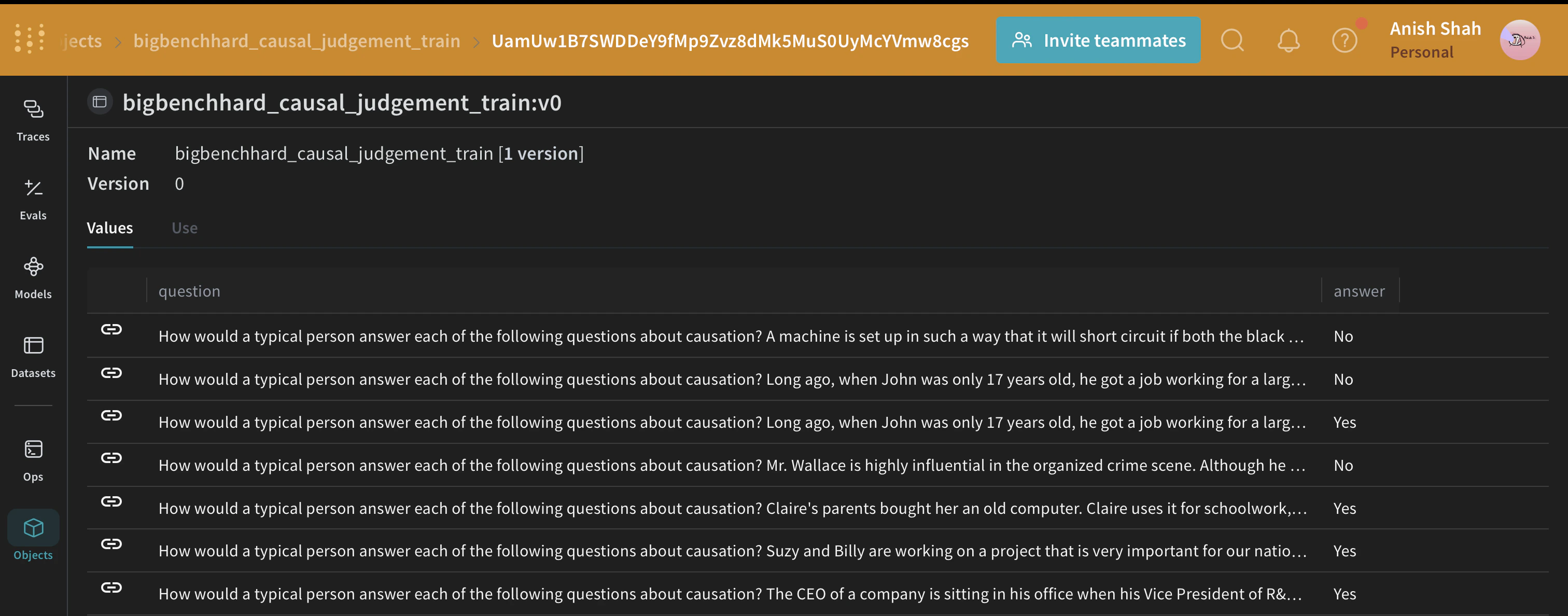
이 데이터셋을 HuggingFace Hub에서 불러와 트레이닝 세트와 검증 세트로 나눈 뒤 Weave에 [게시](/ko/weave/guides/core-types/datasets)합니다. 이렇게 하면 데이터셋 버전을 관리할 수 있고, [`weave.Evaluation`](/ko/weave/guides/core-types/evaluations)을 사용해 프롬프팅 전략도 평가할 수 있습니다.
```python lines theme={null}
import dspy
from datasets import load_dataset
@weave.op()
def get_dataset(metadata: Metadata):
# Huggingface Hub에서 태스크에 해당하는 BIG-Bench Hard 데이터셋 불러오기
dataset = load_dataset(metadata.dataset_address, metadata.big_bench_hard_task)[
"train"
]
# 트레이닝 및 검증 데이터셋 생성
rows = [{"question": data["input"], "answer": data["target"]} for data in dataset]
train_rows = rows[0 : metadata.num_train_examples]
val_rows = rows[metadata.num_train_examples :]
# `dspy.Example` 객체로 구성된 트레이닝 및 검증 예시 생성
dspy_train_examples = [
dspy.Example(row).with_inputs("question") for row in train_rows
]
dspy_val_examples = [dspy.Example(row).with_inputs("question") for row in val_rows]
# Weave에 데이터셋 게시 - 데이터 버전 관리 및 평가에 활용 가능
weave.publish(
weave.Dataset(
name=f"bigbenchhard_{metadata.big_bench_hard_task}_train", rows=train_rows
)
)
weave.publish(
weave.Dataset(
name=f"bigbenchhard_{metadata.big_bench_hard_task}_val", rows=val_rows
)
)
return dspy_train_examples, dspy_val_examples
dspy_train_examples, dspy_val_examples = get_dataset(metadata)
```
## DSPy 프로그램
데이터셋을 Weave에 게시했으므로, 이제 나중에 평가하고 최적화할 베이스라인 DSPy 프로그램을 정의할 수 있습니다.
[DSPy](https://dspy.ai)는 자유 형식 문자열을 직접 조작하는 방식에서 벗어나, 프로그래밍(모듈식 Operator를 조합해 텍스트 변환 그래프를 구성하는 방식)에 더 가깝게 새로운 LM 파이프라인을 구축하도록 돕는 프레임워크입니다. 여기서 컴파일러는 프로그램으로부터 최적화된 LM 호출 전략과 프롬프트를 자동으로 생성합니다.
언어 모델을 설정하려면 [`dspy.LM`](https://dspy.ai/learn/programming/language_models)을 사용하고, 이를 기본값으로 설정하려면 [`dspy.configure`](https://dspy.ai/api/utils/configure/)를 사용하세요.
```python lines theme={null}
llm = dspy.LM("openai/gpt-4o-mini")
dspy.configure(lm=llm)
```
### 인과 추론 시그니처 작성하기
[시그니처](https://dspy.ai/learn/programming/signatures)는 [DSPy 모듈](https://dspy.ai/learn/programming/modules)의 입력/출력 동작을 선언적으로 정의하는 명세입니다. DSPy 모듈은 작업에 맞게 적응하는 컴포넌트로, 신경망의 계층과 유사하며 특정 텍스트 변환을 추상화합니다.
```python lines theme={null}
class CausalReasoning(dspy.Signature):
"""You are an expert in causal reasoning. Analyze the given question carefully
and answer Yes or No. Provide a detailed explanation justifying your answer."""
question: str = dspy.InputField(desc="The question to be answered")
answer: str = dspy.OutputField(desc="Yes or No")
confidence: float = dspy.OutputField(desc="Confidence score between 0 and 1")
explanation: str = dspy.OutputField(desc="Detailed explanation for the answer")
class CausalReasoningModule(dspy.Module):
def __init__(self):
self.prog = dspy.Predict(CausalReasoning)
@weave.op()
def forward(self, question: str) -> dict:
result = self.prog(question=question)
return {
"answer": result.answer,
"confidence": result.confidence,
"explanation": result.explanation,
}
```
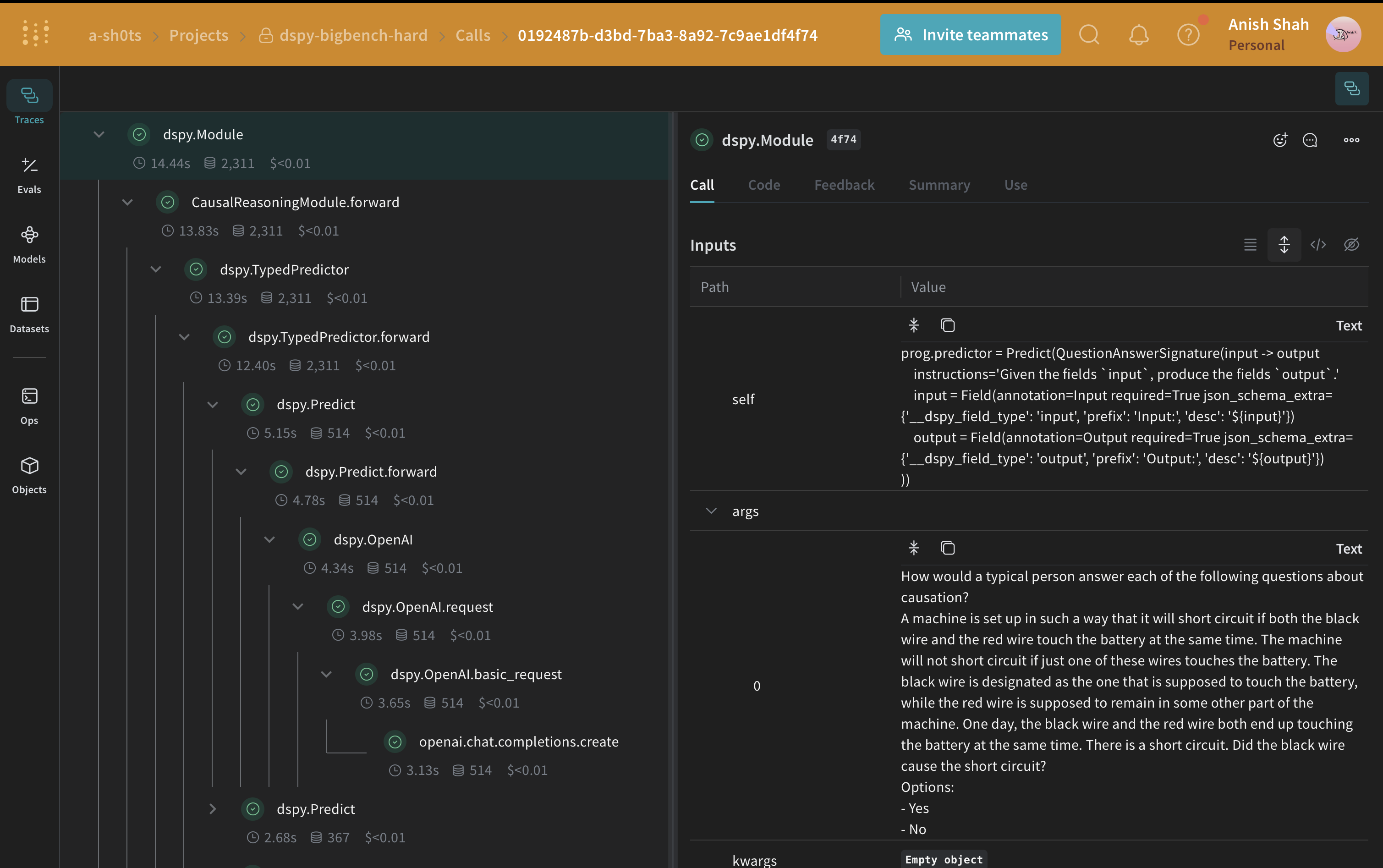
BIG-Bench Hard의 인과 추론 하위 집합에 있는 예시 항목으로 LLM 워크플로(즉, `CausalReasoningModule`)를 테스트하세요.
```python lines theme={null}
import rich
baseline_module = CausalReasoningModule()
prediction = baseline_module(dspy_train_examples[0]["question"])
rich.print(prediction)
```
## DSPy 프로그램 평가하기
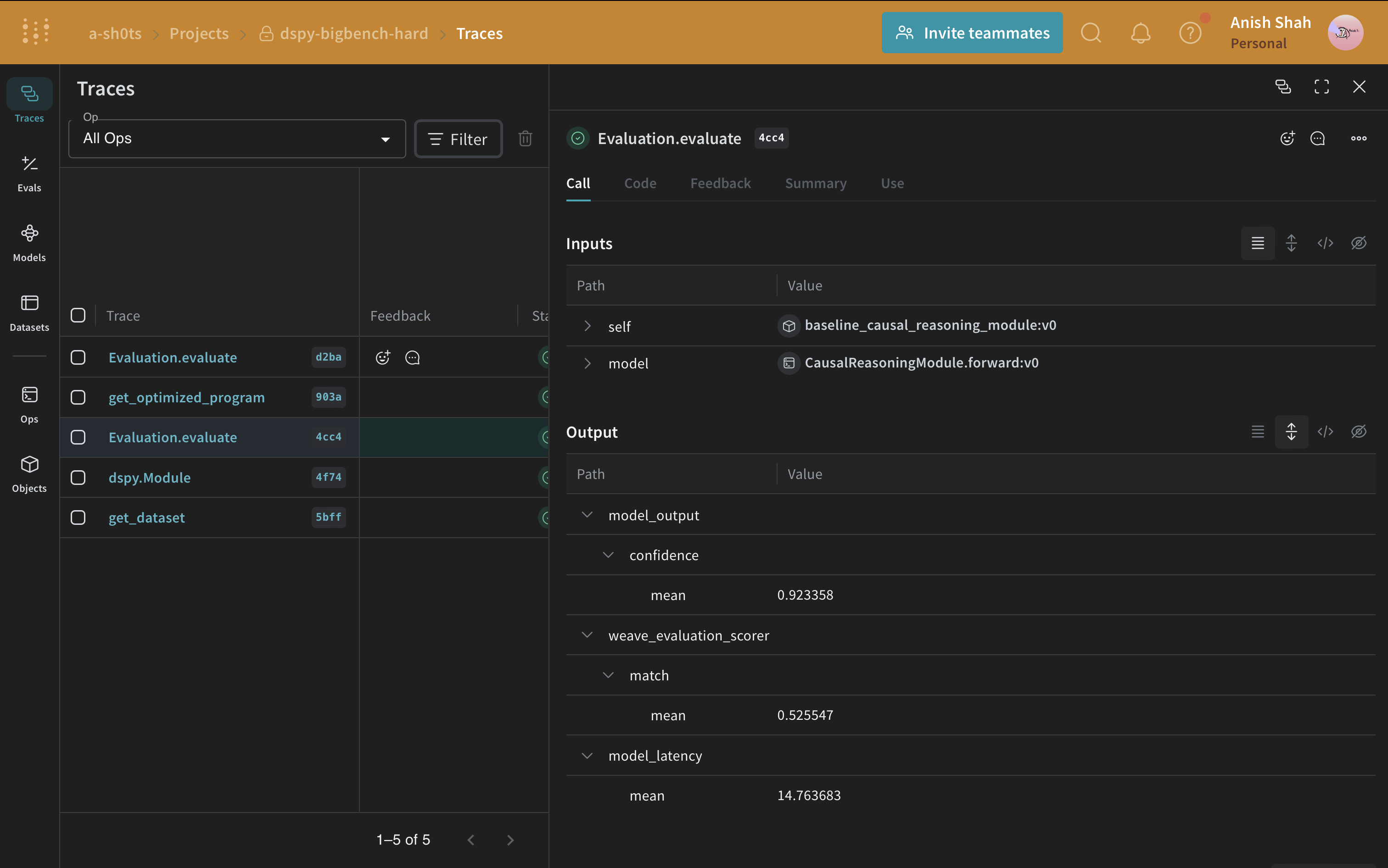
이제 베이스라인 프롬프팅 전략이 있으므로, 예측된 답변이 정답과 일치하는 메트릭과 함께 [`weave.Evaluation`](/ko/weave/guides/core-types/evaluations)을 사용해 검증 세트에서 평가하세요. Weave는 각 예시를 가져와 애플리케이션에 전달한 다음, 여러 맞춤형 채점 함수로 출력을 평가합니다. 이렇게 하면 애플리케이션의 성능을 보여주는 뷰를 얻을 수 있고, 개별 출력과 점수를 자세히 살펴볼 수 있는 풍부한 UI도 활용할 수 있습니다.
먼저 예측된 답변이 정답과 일치하는지 판별하는 채점 함수를 만드세요. Weave 채점 함수는 모델의 반환 값을 `output`으로 받고, 데이터셋 예시의 일치하는 키를 추가 인수로 받습니다. 여기서 `answer`는 데이터셋에서 오고, `output`은 `CausalReasoningModule.forward`가 반환한 dict입니다.
```python lines theme={null}
@weave.op()
def weave_evaluation_scorer(answer: str, output: dict) -> dict:
return {"match": int(answer.lower() == output["answer"].lower())}
```
다음으로, `weave.Evaluation`이 호출할 수 있는 트레이스 함수로 모듈을 감쌉니다. 래퍼의 인수 이름은 모델이 사용하는 데이터셋 열 이름과 일치해야 합니다.
```python lines theme={null}
@weave.op()
def predict(question: str) -> dict:
return baseline_module(question=question)
```
이제 평가를 정의하고 실행할 수 있습니다.
```python lines theme={null}
validation_dataset = weave.ref(
f"bigbenchhard_{metadata.big_bench_hard_task}_val:v0"
).get()
evaluation = weave.Evaluation(
name="baseline_causal_reasoning_module",
dataset=validation_dataset,
scorers=[weave_evaluation_scorer],
)
await evaluation.evaluate(predict)
```
 Python 스크립트에서 실행하는 경우, 다음 코드를 사용해 평가를 실행할 수 있습니다.
```python lines theme={null}
import asyncio
asyncio.run(evaluation.evaluate(predict))
```
인과 추론 데이터셋으로 평가를 실행하면 OpenAI 크레딧이 약 \$0.24 소요됩니다.
Python 스크립트에서 실행하는 경우, 다음 코드를 사용해 평가를 실행할 수 있습니다.
```python lines theme={null}
import asyncio
asyncio.run(evaluation.evaluate(predict))
```
인과 추론 데이터셋으로 평가를 실행하면 OpenAI 크레딧이 약 \$0.24 소요됩니다.
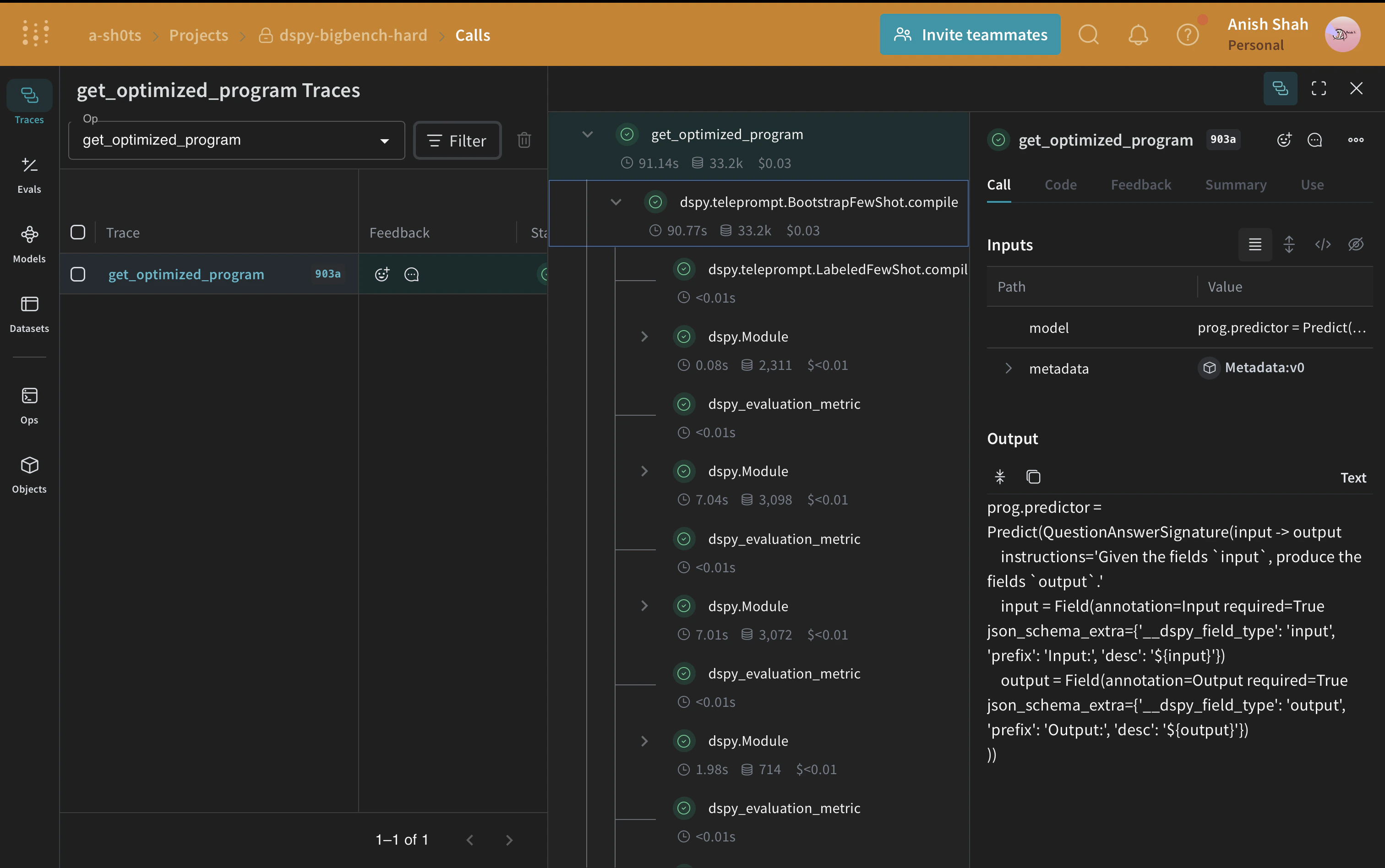
## DSPy 프로그램 최적화하기
베이스라인 성능을 측정했으므로, 이제 DSPy optimizer를 적용하고 그 결과를 베이스라인과 비교할 수 있습니다.
이제 베이스라인 DSPy 프로그램이 있으니, 지정된 메트릭을 최대화하도록 DSPy 프로그램의 매개변수를 조정할 수 있는 [BootstrapFewShot](https://dspy.ai/api/optimizers/BootstrapFewShot/) optimizer를 사용해 인과 추론 성능을 개선해 보세요.
```python lines theme={null}
from dspy.teleprompt import BootstrapFewShot
@weave.op()
def get_optimized_program(model: dspy.Module, metadata: Metadata) -> dspy.Module:
@weave.op()
def dspy_evaluation_metric(true, prediction, trace=None):
return prediction["answer"].lower() == true.answer.lower()
teleprompter = BootstrapFewShot(
metric=dspy_evaluation_metric,
max_bootstrapped_demos=metadata.max_bootstrapped_demos,
max_labeled_demos=metadata.max_labeled_demos,
)
return teleprompter.compile(model, trainset=dspy_train_examples)
optimized_module = get_optimized_program(baseline_module, metadata)
```
 인과 추론 평가 데이터셋을 실행하는 데는 OpenAI 크레딧이 약 \$0.04 정도 사용됩니다.
이제 최적화된 프로그램(즉, 최적화된 프롬프팅 전략)이 있으니, 검증 세트에서 다시 평가해 베이스라인 DSPy 프로그램과 비교하세요.
```python lines theme={null}
@weave.op()
def predict_optimized(question: str) -> dict:
return optimized_module(question=question)
evaluation = weave.Evaluation(
name="optimized_causal_reasoning_module",
dataset=validation_dataset,
scorers=[weave_evaluation_scorer],
)
await evaluation.evaluate(predict_optimized)
```
인과 추론 평가 데이터셋을 실행하는 데는 OpenAI 크레딧이 약 \$0.04 정도 사용됩니다.
이제 최적화된 프로그램(즉, 최적화된 프롬프팅 전략)이 있으니, 검증 세트에서 다시 평가해 베이스라인 DSPy 프로그램과 비교하세요.
```python lines theme={null}
@weave.op()
def predict_optimized(question: str) -> dict:
return optimized_module(question=question)
evaluation = weave.Evaluation(
name="optimized_causal_reasoning_module",
dataset=validation_dataset,
scorers=[weave_evaluation_scorer],
)
await evaluation.evaluate(predict_optimized)
```
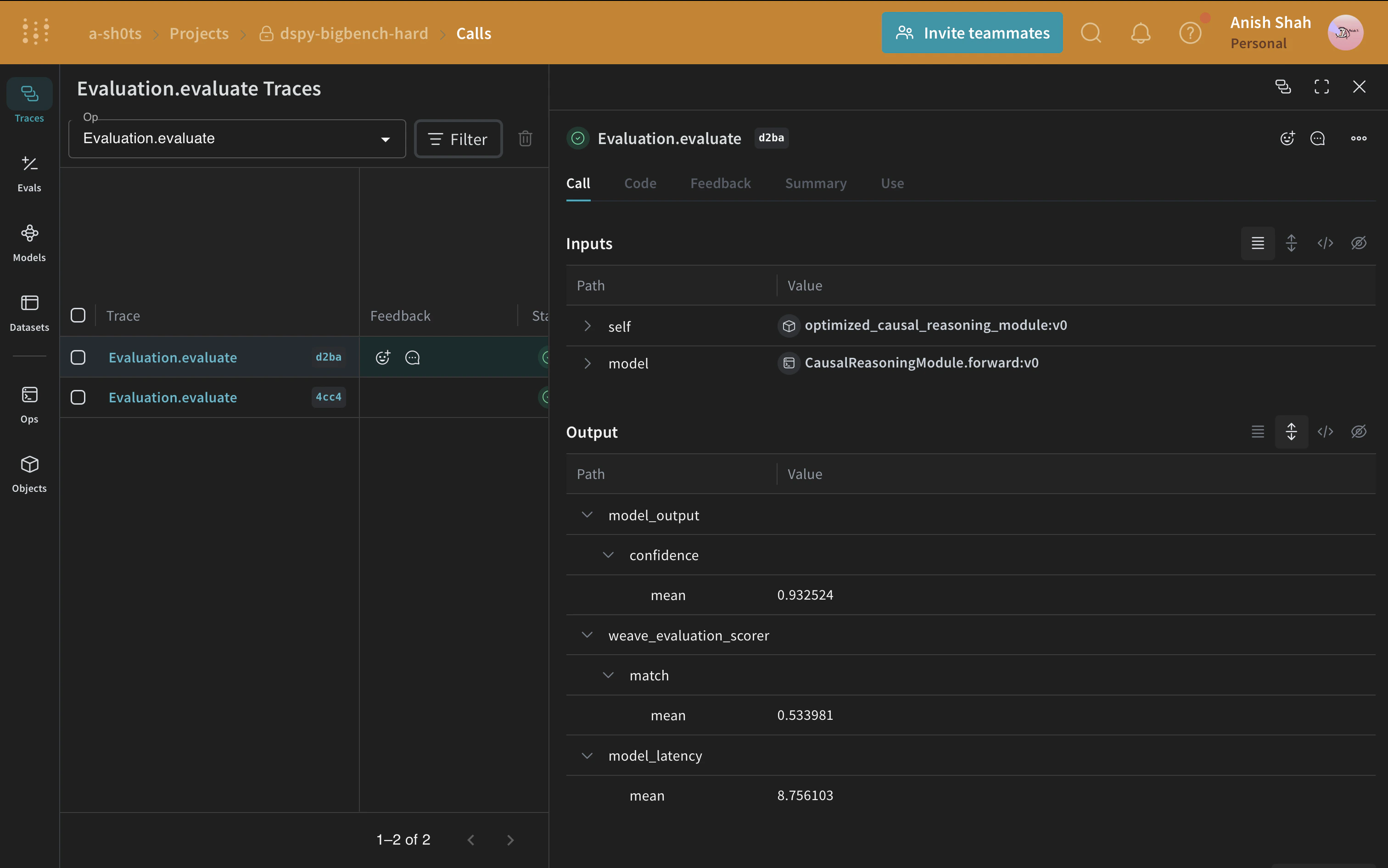 베이스라인 프로그램과 최적화된 프로그램의 평가를 비교해 보면, 최적화된 프로그램이 인과 추론 질문에 더 정확하게 답한다는 것을 알 수 있습니다.
베이스라인 프로그램과 최적화된 프로그램의 평가를 비교해 보면, 최적화된 프로그램이 인과 추론 질문에 더 정확하게 답한다는 것을 알 수 있습니다.
## 결론
이 튜토리얼에서는 원본 프로그램과 최적화된 프로그램을 비교하기 위해 프롬프트 최적화에는 DSPy를, 추적 및 평가에는 Weave를 활용하는 방법을 알아보셨습니다.