> ## Documentation Index
> Fetch the complete documentation index at: https://docs.wandb.ai/llms.txt
> Use this file to discover all available pages before exploring further.
> Evaluate a hosted API model using infrastructure managed by CoreWeave
# Evaluate a hosted API model
LLM Evaluation Jobs is in **Preview** for [W\&B Multi-tenant Cloud](/platform/hosting/hosting-options/multi_tenant_cloud). Compute is free during the preview period. [Learn more](/models/launch#pricing)
This page shows how to use [LLM Evaluation Jobs](/models/launch) to run a series of evaluation benchmarks on a hosted API model at a publicly accessible URL, using infrastructure managed by CoreWeave. Running these benchmarks helps you compare model performance, validate model quality, and publish results to a shared leaderboard without managing your own evaluation infrastructure. To evaluate a model checkpoint saved as an artifact in W\&B Models, see [Evaluate a model checkpoint](/models/launch/evaluate-model-checkpoint) instead.
## Prerequisites
Before you create an evaluation job, complete the following:
1. Review the [requirements and limitations](/models/launch#more-details) for LLM Evaluation Jobs.
2. To run certain benchmarks, a team admin must add the required API keys as team-scoped secrets. Any team member can specify the secret when configuring an evaluation job.
* An **OpenAI API key**: Used by benchmarks that use OpenAI models for scoring. Required if the field **Scorer API key** appears after you select a benchmark. The secret must be named `OPENAI_API_KEY`.
* A **Hugging Face user access token**: Required for certain benchmarks like `lingoly` and `lingoly2` that require access to one or more gated Hugging Face datasets. Required if the field **Hugging Face Token** appears after you select a benchmark. The API key must have access to the relevant dataset. See the Hugging Face documentation for [User access tokens](https://huggingface.co/docs/hub/en/security-tokens) and [accessing gated datasets](https://huggingface.co/docs/hub/en/datasets-gated#access-gated-datasets-as-a-user).
* To evaluate a model provided by [Serverless Inference](/inference), an organization or team admin must create `WANDB_API_KEY` with any value. The secret isn't used for authentication.
3. The model to evaluate must be available at a publicly accessible URL. An organization or team admin must create a team-scoped secret with the API key for authentication.
4. Create a new [W\&B project](/models/track/project-page) for the evaluation results. From the project sidebar, click **Create new project**.
5. Review the documentation for a given benchmark to understand how it works and learn about specific requirements. The [Available evaluation benchmarks](/models/launch/evaluations) reference includes relevant links.
## Evaluate your model
Follow these steps to set up and launch an evaluation job. When you finish, your benchmark runs are queued on CoreWeave-managed infrastructure and their results appear in the destination W\&B project you specify.
1. Log in to W\&B, then click **Launch** in the project sidebar. The **LLM Evaluation Jobs** page displays.
2. Click **Evaluate hosted API model** to set up the evaluation.
3. Select a destination project to save the evaluation results to.
4. In the **Model** section, specify the base URL and model name to evaluate, and select the API key to use for authentication. Provide the model name in OpenAI-compatible format defined by the [AI Security Institute](https://inspect.aisi.org.uk/providers.html#openai-api). For example, specify an OpenAI model in the following syntax, where `[MODEL-NAME]` is the name of the model: `openai/[MODEL-NAME]`. For a list of hosted model providers and models, see [AI Security Institute's model provider reference](https://inspect.aisi.org.uk/providers.html).
* To evaluate a model provided by [Serverless Inference](/inference), set the base URL to `https://api.inference.wandb.ai/v1` and specify the model name in the following syntax, where `[MODEL-ID]` is the model ID: `openai-api/wandb/[MODEL-ID]`. Refer to the [Inference model catalog](/inference/models) for details.
* To use the [OpenRouter](https://inspect.aisi.org.uk/providers.html#openrouter) provider, prefix the model name with `openrouter` in the following syntax, where `[MODEL-NAME]` is the name of the model: `openrouter/[MODEL-NAME]`.
* To evaluate a custom OpenAPI-compliant model, specify the model name in the following syntax, where `[MODEL-NAME]` is the name of the model: `openai-api/wandb/[MODEL-NAME]`.
5. Click **Select evaluations**, then select up to four benchmarks to run.
6. If you select benchmarks that use OpenAI models for scoring, the **Scorer API key** field displays. Click it, then select the `OPENAI_API_KEY` secret. A team admin can create a secret from this drawer by clicking **Create secret**.
7. If you select benchmarks that require access to gated datasets in Hugging Face, a **Hugging Face token** field displays. [Request access to the relevant dataset](https://huggingface.co/docs/hub/en/datasets-gated#access-gated-datasets-as-a-user), then select the secret that contains the Hugging Face user access token.
8. Optional: Set **Sample limit** to a positive integer to limit the maximum number of benchmark samples to evaluate. Otherwise, all samples in the task are included.
9. To create a leaderboard automatically, click **Publish results to leaderboard**. The leaderboard displays all evaluations together in a workspace panel, and you can also share it in a report.
10. Click **Launch** to launch the evaluation job.
11. Click the circular arrow icon at the top of the page to open the recent run modal. Evaluation jobs appear with your other recent runs. Click the name of a finished run to open it in single-run view, or click the **Leaderboard** link to open the leaderboard directly. For details, see [View the results](#view-the-results).
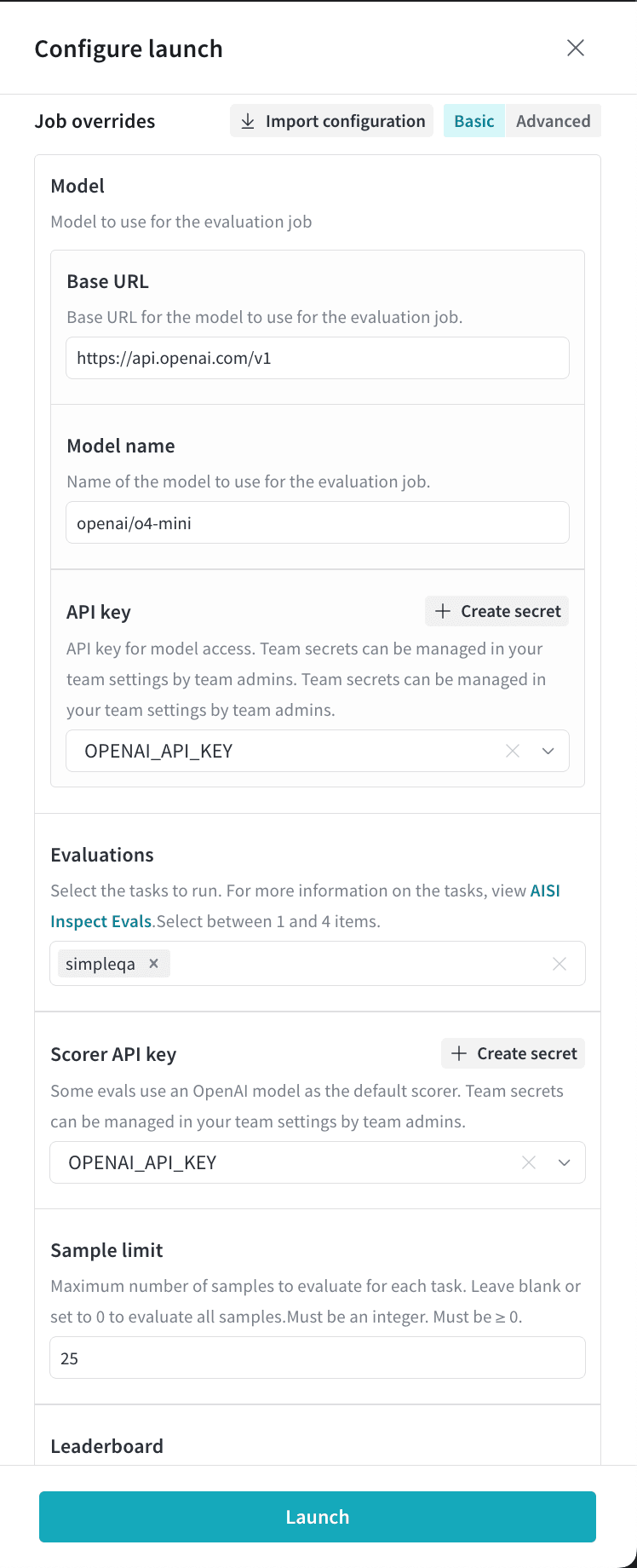
This example job runs the `simpleqa` benchmark against the OpenAI model `o4-mini`:
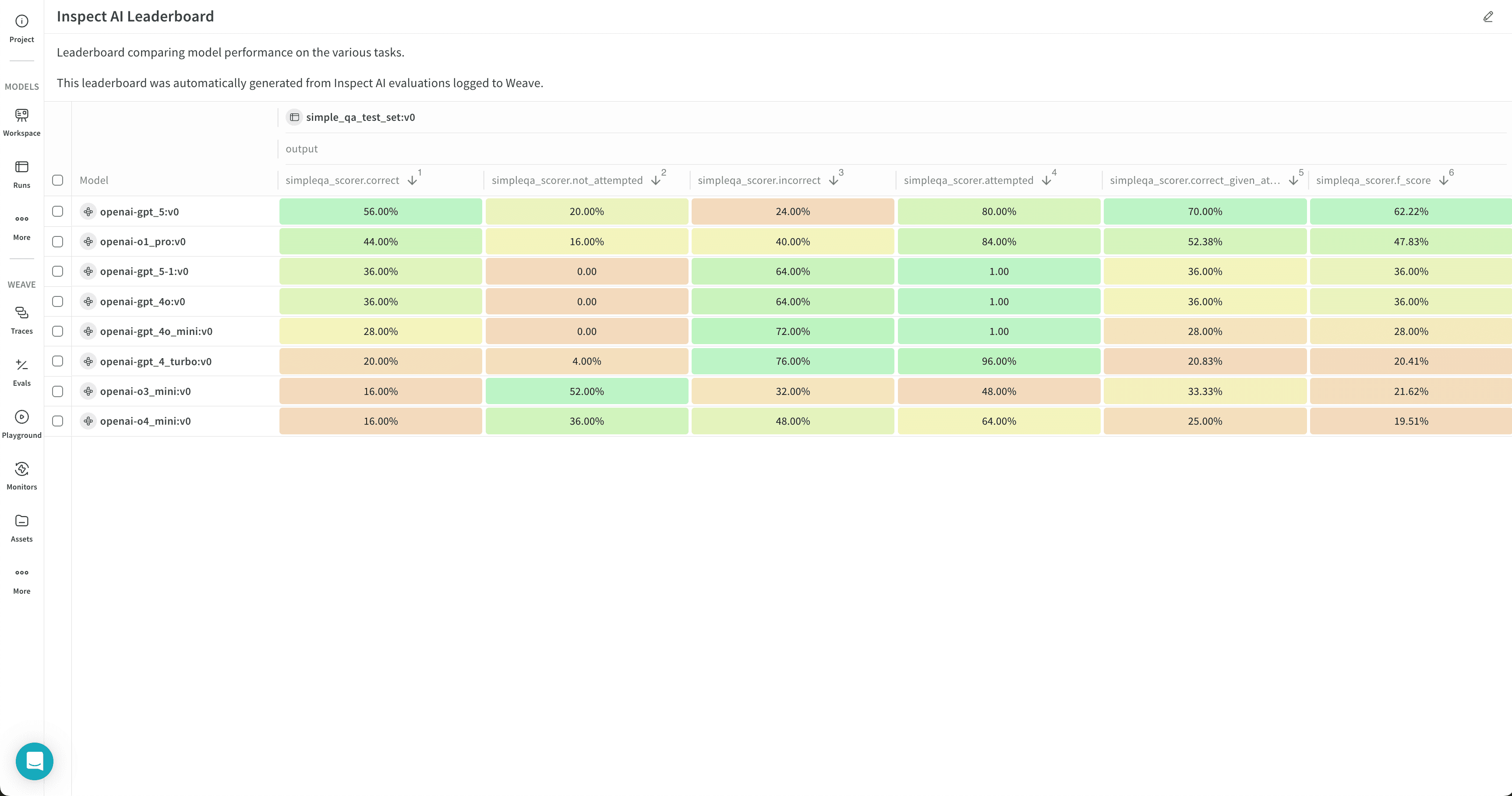
 If you published results to a leaderboard, you can compare evaluations side by side. This example leaderboard visualizes the performance of several OpenAI models together:
If you published results to a leaderboard, you can compare evaluations side by side. This example leaderboard visualizes the performance of several OpenAI models together:
 ## Review evaluation results
Review your evaluation job results in W\&B Models in the destination project's workspace.
1. Click the circular arrow icon at the top of the page to open the recent run modal, where evaluation jobs appear with other runs in the project. If the evaluation job has a leaderboard, click **Leaderboard** to open the leaderboard in full screen, or click a run name to open it in the project in single-run view.
2. View the evaluation job's traces in the **Evaluations** section of a workspace or in the **Traces** tab of the **Weave** sidebar panel.
3. Click the **Overview** tab to view detailed information about the evaluation job, including its configuration and summary metrics.
4. Click the **Logs** tab to view, search, or download the evaluation job's debug logs.
5. Click the **Files** tab to browse, view, or download the evaluation job's files, including code, log, configuration, and other output files.
## Customize a leaderboard
The leaderboard shows results for all evaluation jobs sent to a given project, with one row per benchmark per evaluation job. Columns display details like the trace, input values, and output values for the evaluation job. For more information about leaderboards, see [Leaderboards in Weave](/weave/guides/core-types/leaderboards).
To give feedback about a result from the leaderboard, click the emoji icon or the chat icon in the **Feedback** column.
* By default, all evaluation jobs are displayed. Filter or search for an evaluation job using the run selector at the left.
* By default, evaluation jobs are ungrouped. To group by one or more columns, click the **Group** icon. You can show or hide a group, or expand a group to view its runs.
* By default, all operations are displayed. To display only a single operation, click **All ops** and select an operation.
* To sort by a column, click the column heading. To customize the display of columns, click **Columns**.
* By default, headers are organized in a single level. You can increase the header depth to organize related headers together.
* Select or deselect individual columns to show or hide them, or show or hide all columns with a click.
* Pin columns to display them before unpinned columns.
## Export a leaderboard
To export a leaderboard:
1. Click the download icon, located near the **Columns** button.
2. To optimize the export size, only the trace roots are exported by default. To export full traces, turn off **Trace roots only**.
3. To optimize the export size, feedback and costs are not exported by default. To include them in the export, toggle **Feedback** or **Costs**.
4. By default, the export is in JSONL format. To customize the format, click **Export to file** and select a format.
5. To export the leaderboard in your browser, click **Export**.
6. To export the leaderboard programmatically, select **Python** or **cURL**, then click **Copy** and run the script or command.
## Re-run an evaluation job
Depending on your situation, there are multiple ways to re-run an evaluation job or view its configuration.
* To re-run the last evaluation job again, follow the steps in [Evaluate your model](#evaluate-your-model). Select the destination project, then the model artifact details and the selected benchmarks you selected last time are populated automatically. Optionally, make adjustments, then launch the evaluation job.
* To re-run an evaluation job from the project's **Runs** tab or run selector, hover over the run name and click the play icon. The job configuration drawer displays with the settings pre-populated. Optionally adjust the settings, then click **Launch**.
* To re-run an evaluation job from a different project, import its configuration:
1. Follow the steps in [Evaluate your model](#evaluate-your-model). After you select the destination project, click **Import configuration**.
2. Select the project that contains the evaluation job to import, then select the evaluation job run. The job configuration drawer displays with the settings pre-populated.
3. Optionally adjust the configuration.
4. Click **Launch**.
## Export an evaluation job configuration
Export an evaluation job's configuration from the run's **Files** tab.
1. Open the run in single-run view.
2. Click the **Files** tab.
3. Click the download button next to `config.yaml` to download it locally.
## Review evaluation results
Review your evaluation job results in W\&B Models in the destination project's workspace.
1. Click the circular arrow icon at the top of the page to open the recent run modal, where evaluation jobs appear with other runs in the project. If the evaluation job has a leaderboard, click **Leaderboard** to open the leaderboard in full screen, or click a run name to open it in the project in single-run view.
2. View the evaluation job's traces in the **Evaluations** section of a workspace or in the **Traces** tab of the **Weave** sidebar panel.
3. Click the **Overview** tab to view detailed information about the evaluation job, including its configuration and summary metrics.
4. Click the **Logs** tab to view, search, or download the evaluation job's debug logs.
5. Click the **Files** tab to browse, view, or download the evaluation job's files, including code, log, configuration, and other output files.
## Customize a leaderboard
The leaderboard shows results for all evaluation jobs sent to a given project, with one row per benchmark per evaluation job. Columns display details like the trace, input values, and output values for the evaluation job. For more information about leaderboards, see [Leaderboards in Weave](/weave/guides/core-types/leaderboards).
To give feedback about a result from the leaderboard, click the emoji icon or the chat icon in the **Feedback** column.
* By default, all evaluation jobs are displayed. Filter or search for an evaluation job using the run selector at the left.
* By default, evaluation jobs are ungrouped. To group by one or more columns, click the **Group** icon. You can show or hide a group, or expand a group to view its runs.
* By default, all operations are displayed. To display only a single operation, click **All ops** and select an operation.
* To sort by a column, click the column heading. To customize the display of columns, click **Columns**.
* By default, headers are organized in a single level. You can increase the header depth to organize related headers together.
* Select or deselect individual columns to show or hide them, or show or hide all columns with a click.
* Pin columns to display them before unpinned columns.
## Export a leaderboard
To export a leaderboard:
1. Click the download icon, located near the **Columns** button.
2. To optimize the export size, only the trace roots are exported by default. To export full traces, turn off **Trace roots only**.
3. To optimize the export size, feedback and costs are not exported by default. To include them in the export, toggle **Feedback** or **Costs**.
4. By default, the export is in JSONL format. To customize the format, click **Export to file** and select a format.
5. To export the leaderboard in your browser, click **Export**.
6. To export the leaderboard programmatically, select **Python** or **cURL**, then click **Copy** and run the script or command.
## Re-run an evaluation job
Depending on your situation, there are multiple ways to re-run an evaluation job or view its configuration.
* To re-run the last evaluation job again, follow the steps in [Evaluate your model](#evaluate-your-model). Select the destination project, then the model artifact details and the selected benchmarks you selected last time are populated automatically. Optionally, make adjustments, then launch the evaluation job.
* To re-run an evaluation job from the project's **Runs** tab or run selector, hover over the run name and click the play icon. The job configuration drawer displays with the settings pre-populated. Optionally adjust the settings, then click **Launch**.
* To re-run an evaluation job from a different project, import its configuration:
1. Follow the steps in [Evaluate your model](#evaluate-your-model). After you select the destination project, click **Import configuration**.
2. Select the project that contains the evaluation job to import, then select the evaluation job run. The job configuration drawer displays with the settings pre-populated.
3. Optionally adjust the configuration.
4. Click **Launch**.
## Export an evaluation job configuration
Export an evaluation job's configuration from the run's **Files** tab.
1. Open the run in single-run view.
2. Click the **Files** tab.
3. Click the download button next to `config.yaml` to download it locally.