> ## Documentation Index
> Fetch the complete documentation index at: https://docs.wandb.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# DSPy Prompt Optimization
> Learn how to use dspy prompt optimization with W&B Weave
This is an interactive notebook. You can run it locally or use the links below:
* [Open in Google Colab](https://colab.research.google.com/github/wandb/docs/blob/main/weave/cookbooks/source/dspy_prompt_optimization.ipynb)
* [View source on GitHub](https://github.com/wandb/docs/blob/main/weave/cookbooks/source/dspy_prompt_optimization.ipynb)
# Optimizing LLM Workflows Using DSPy and Weave
The [BIG-bench (Beyond the Imitation Game Benchmark)](https://github.com/google/BIG-bench) is a collaborative benchmark intended to probe large language models and extrapolate their future capabilities consisting of more than 200 tasks. The [BIG-Bench Hard (BBH)](https://github.com/suzgunmirac/BIG-Bench-Hard) is a suite of 23 most challenging BIG-Bench tasks that can be quite difficult to be solved using the current generation of language models.
This tutorial demonstrates how we can improve the performance of our LLM workflow implemented on the **causal judgement task** from the BIG-bench Hard benchmark and evaluate our prompting strategies. We will use [DSPy](https://dspy.ai) for implementing our LLM workflow and optimizing our prompting strategy. We will also use [Weave](/weave) to track our LLM workflow and evaluate our prompting strategies.
## Installing the Dependencies
We need the following libraries for this tutorial:
* [DSPy](https://dspy.ai) for building the LLM workflow and optimizing it.
* [Weave](/weave) to track our LLM workflow and evaluate our prompting strategies.
* [datasets](https://huggingface.co/docs/datasets/index) to access the Big-Bench Hard dataset from HuggingFace Hub.
```python lines theme={null}
!pip install -qU dspy weave "datasets<4"
```
Since we'll be using [OpenAI API](https://openai.com/index/openai-api/) as the LLM Vendor, we will also need an OpenAI API key. You can [sign up](https://platform.openai.com/signup) on the OpenAI platform to get your own API key.
```python lines theme={null}
import os
from getpass import getpass
api_key = getpass("Enter you OpenAI API key: ")
os.environ["OPENAI_API_KEY"] = api_key
```
## Enable Tracking using Weave
Weave is currently integrated with DSPy, and including [`weave.init`](/weave/reference/python-sdk/trace/weave_client#method-init) at the start of our code lets us automatically trace our DSPy functions which can be explored in the Weave UI. Check out the [Weave integration docs for DSPy](/weave/guides/integrations/dspy) to learn more.
```python lines theme={null}
import weave
weave.init(project_name="dspy-bigbench-hard")
```
In this tutorial, we use a metadata class inherited from [`weave.Object`](/weave/reference/python-sdk#class-object) to manage our metadata.
```python lines theme={null}
class Metadata(weave.Object):
dataset_address: str = "maveriq/bigbenchhard"
big_bench_hard_task: str = "causal_judgement"
num_train_examples: int = 50
openai_model: str = "gpt-4o-mini"
openai_max_tokens: int = 2048
max_bootstrapped_demos: int = 8
max_labeled_demos: int = 8
metadata = Metadata()
```
**Object Versioning**: The `Metadata` objects are automatically versioned and traced when functions consuming them are traced
## Load the BIG-Bench Hard Dataset
We will load this dataset from HuggingFace Hub, split into training and validation sets, and [publish](/weave/guides/core-types/datasets) them on Weave, this will let us version the datasets, and also use [`weave.Evaluation`](/weave/guides/core-types/evaluations) to evaluate our prompting strategy.
```python lines theme={null}
import dspy
from datasets import load_dataset
@weave.op()
def get_dataset(metadata: Metadata):
# load the BIG-Bench Hard dataset corresponding to the task from Huggingface Hug
dataset = load_dataset(metadata.dataset_address, metadata.big_bench_hard_task)[
"train"
]
# create the training and validation datasets
rows = [{"question": data["input"], "answer": data["target"]} for data in dataset]
train_rows = rows[0 : metadata.num_train_examples]
val_rows = rows[metadata.num_train_examples :]
# create the training and validation examples consisting of `dspy.Example` objects
dspy_train_examples = [
dspy.Example(row).with_inputs("question") for row in train_rows
]
dspy_val_examples = [dspy.Example(row).with_inputs("question") for row in val_rows]
# publish the datasets to the Weave, this would let us version the data and use for evaluation
weave.publish(
weave.Dataset(
name=f"bigbenchhard_{metadata.big_bench_hard_task}_train", rows=train_rows
)
)
weave.publish(
weave.Dataset(
name=f"bigbenchhard_{metadata.big_bench_hard_task}_val", rows=val_rows
)
)
return dspy_train_examples, dspy_val_examples
dspy_train_examples, dspy_val_examples = get_dataset(metadata)
```
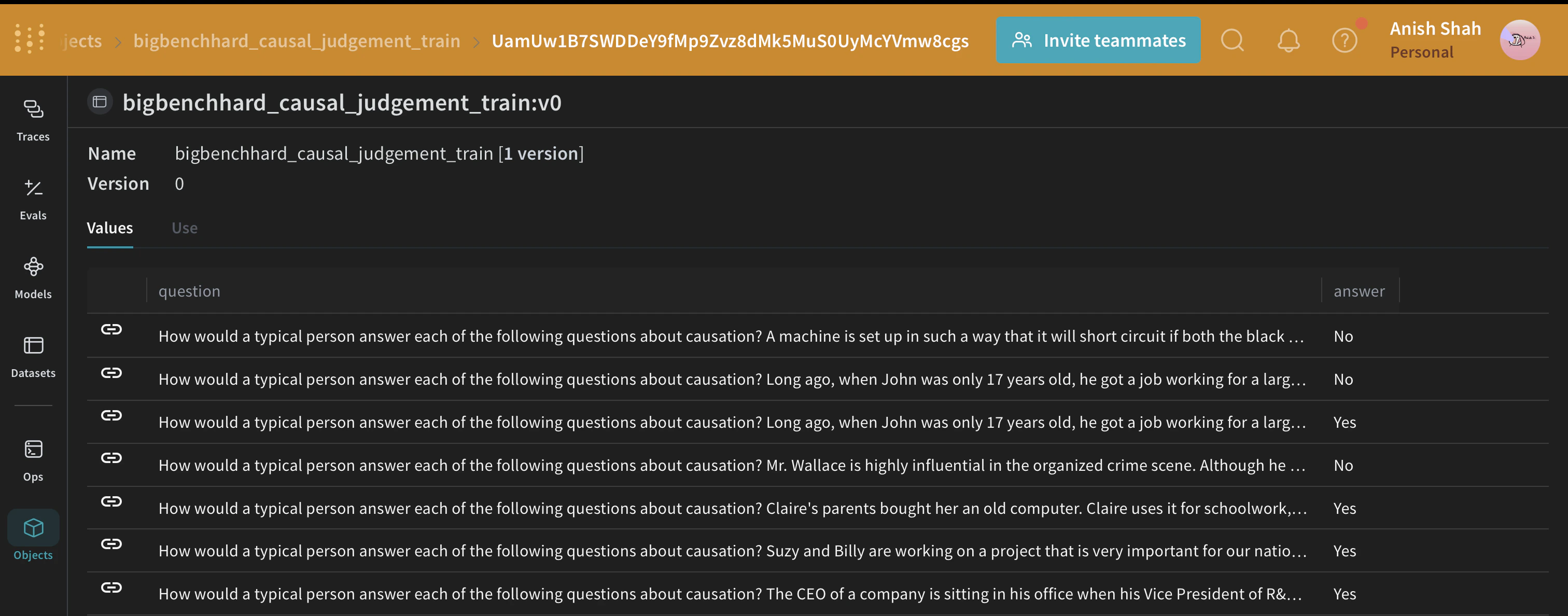 ## The DSPy Program
[DSPy](https://dspy.ai) is a framework that pushes building new LM pipelines away from manipulating free-form strings and closer to programming (composing modular operators to build text transformation graphs) where a compiler automatically generates optimized LM invocation strategies and prompts from a program.
We will use [`dspy.LM`](https://dspy.ai/learn/programming/language_models) to configure our language model and [`dspy.configure`](https://dspy.ai/api/utils/configure/) to set it as the default.
```python lines theme={null}
llm = dspy.LM("openai/gpt-4o-mini")
dspy.configure(lm=llm)
```
### Writing the causal reasoning signature
A [signature](https://dspy.ai/learn/programming/signatures) is a declarative specification of input/output behavior of a [DSPy module](https://dspy.ai/learn/programming/modules) which are task-adaptive components—akin to neural network layers—that abstract any particular text transformation.
```python lines theme={null}
class CausalReasoning(dspy.Signature):
"""You are an expert in causal reasoning. Analyze the given question carefully
and answer Yes or No. Provide a detailed explanation justifying your answer."""
question: str = dspy.InputField(desc="The question to be answered")
answer: str = dspy.OutputField(desc="Yes or No")
confidence: float = dspy.OutputField(desc="Confidence score between 0 and 1")
explanation: str = dspy.OutputField(desc="Detailed explanation for the answer")
class CausalReasoningModule(dspy.Module):
def __init__(self):
self.prog = dspy.Predict(CausalReasoning)
@weave.op()
def forward(self, question: str) -> dict:
result = self.prog(question=question)
return {
"answer": result.answer,
"confidence": result.confidence,
"explanation": result.explanation,
}
```
Let's test our LLM workflow, that is, the `CausalReasoningModule` on an example from the causal reasoning subset of Big-Bench Hard.
```python lines theme={null}
import rich
baseline_module = CausalReasoningModule()
prediction = baseline_module(dspy_train_examples[0]["question"])
rich.print(prediction)
```
## The DSPy Program
[DSPy](https://dspy.ai) is a framework that pushes building new LM pipelines away from manipulating free-form strings and closer to programming (composing modular operators to build text transformation graphs) where a compiler automatically generates optimized LM invocation strategies and prompts from a program.
We will use [`dspy.LM`](https://dspy.ai/learn/programming/language_models) to configure our language model and [`dspy.configure`](https://dspy.ai/api/utils/configure/) to set it as the default.
```python lines theme={null}
llm = dspy.LM("openai/gpt-4o-mini")
dspy.configure(lm=llm)
```
### Writing the causal reasoning signature
A [signature](https://dspy.ai/learn/programming/signatures) is a declarative specification of input/output behavior of a [DSPy module](https://dspy.ai/learn/programming/modules) which are task-adaptive components—akin to neural network layers—that abstract any particular text transformation.
```python lines theme={null}
class CausalReasoning(dspy.Signature):
"""You are an expert in causal reasoning. Analyze the given question carefully
and answer Yes or No. Provide a detailed explanation justifying your answer."""
question: str = dspy.InputField(desc="The question to be answered")
answer: str = dspy.OutputField(desc="Yes or No")
confidence: float = dspy.OutputField(desc="Confidence score between 0 and 1")
explanation: str = dspy.OutputField(desc="Detailed explanation for the answer")
class CausalReasoningModule(dspy.Module):
def __init__(self):
self.prog = dspy.Predict(CausalReasoning)
@weave.op()
def forward(self, question: str) -> dict:
result = self.prog(question=question)
return {
"answer": result.answer,
"confidence": result.confidence,
"explanation": result.explanation,
}
```
Let's test our LLM workflow, that is, the `CausalReasoningModule` on an example from the causal reasoning subset of Big-Bench Hard.
```python lines theme={null}
import rich
baseline_module = CausalReasoningModule()
prediction = baseline_module(dspy_train_examples[0]["question"])
rich.print(prediction)
```
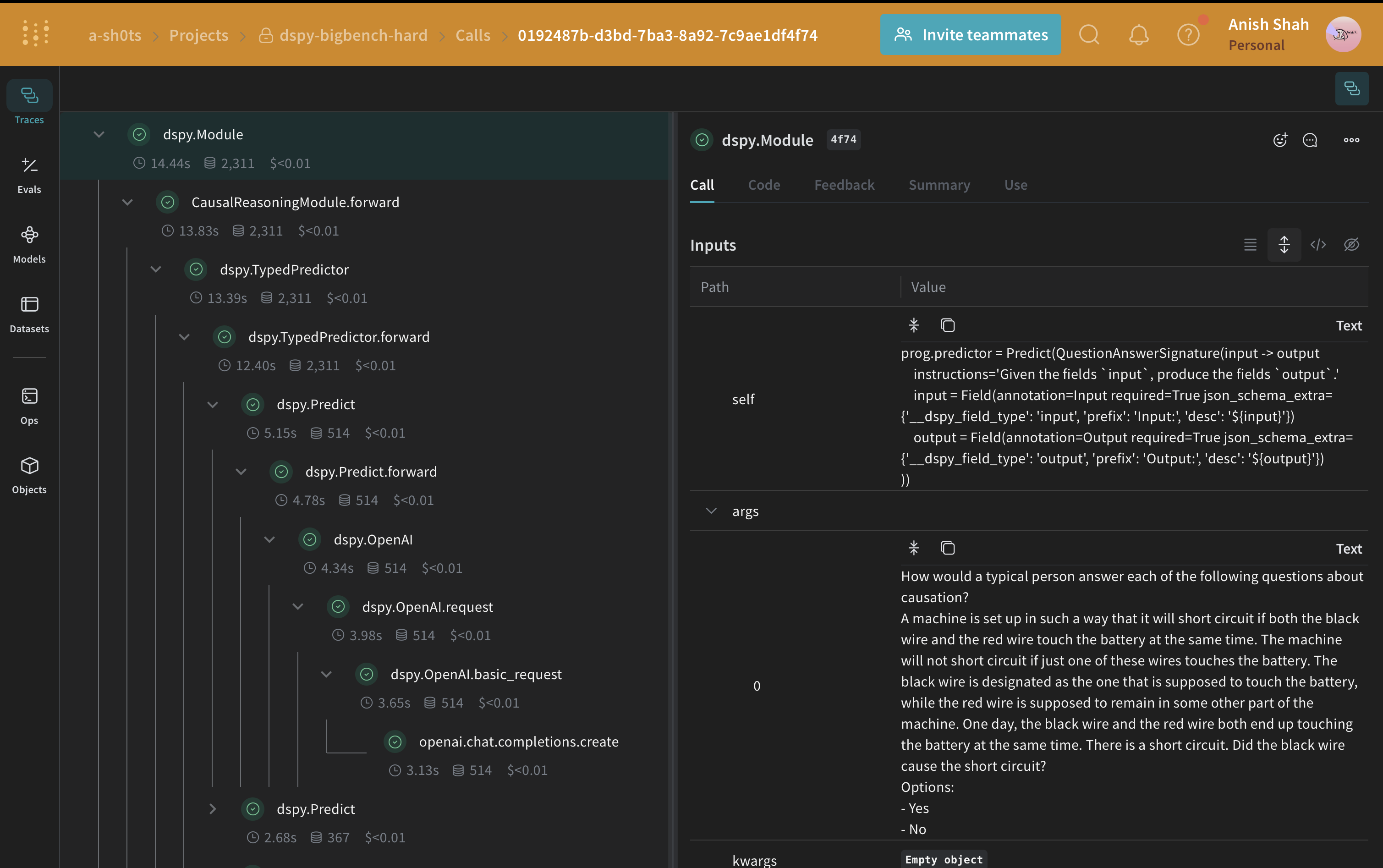 ## Evaluating our DSPy Program
Now that we have a baseline prompting strategy, let's evaluate it on our validation set using [`weave.Evaluation`](/weave/guides/core-types/evaluations) on a simple metric that matches the predicted answer with the ground truth. Weave will take each example, pass it through your application and score the output on multiple custom scoring functions. By doing this, you'll have a view of the performance of your application, and a rich UI to drill into individual outputs and scores.
First, we need to create a scoring function that tells whether the predicted answer matches the ground truth. Weave scoring functions receive the model's return value as `output` and any matching keys from the dataset example as additional arguments. Here, `answer` comes from the dataset and `output` is the dict returned by `CausalReasoningModule.forward`.
```python lines theme={null}
@weave.op()
def weave_evaluation_scorer(answer: str, output: dict) -> dict:
return {"match": int(answer.lower() == output["answer"].lower())}
```
Next, we wrap the module in a traced function that `weave.Evaluation` can call. The wrapper's argument names must match the dataset column names that the model consumes.
```python lines theme={null}
@weave.op()
def predict(question: str) -> dict:
return baseline_module(question=question)
```
Now we can define the evaluation and run it.
```python lines theme={null}
validation_dataset = weave.ref(
f"bigbenchhard_{metadata.big_bench_hard_task}_val:v0"
).get()
evaluation = weave.Evaluation(
name="baseline_causal_reasoning_module",
dataset=validation_dataset,
scorers=[weave_evaluation_scorer],
)
await evaluation.evaluate(predict)
```
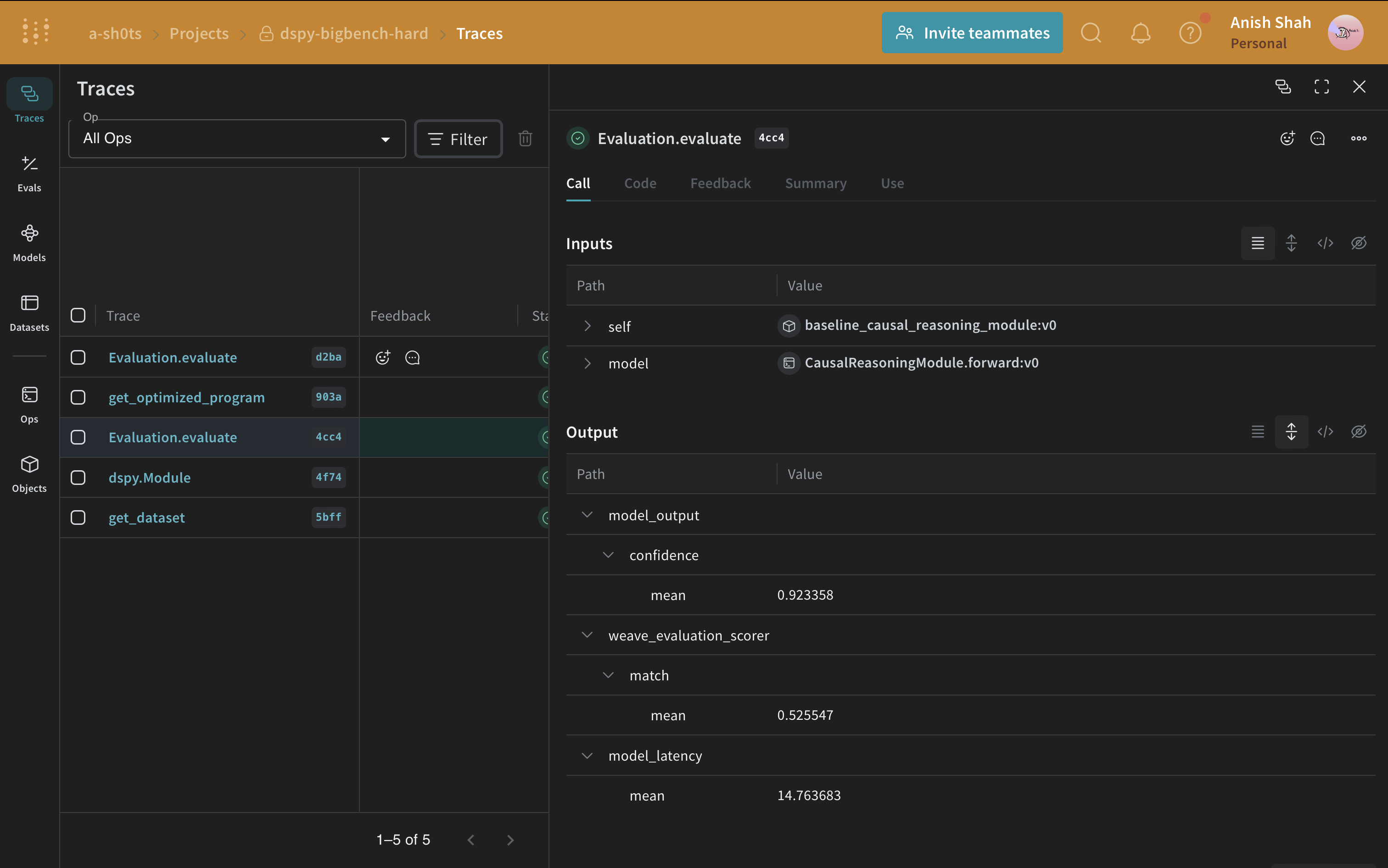
## Evaluating our DSPy Program
Now that we have a baseline prompting strategy, let's evaluate it on our validation set using [`weave.Evaluation`](/weave/guides/core-types/evaluations) on a simple metric that matches the predicted answer with the ground truth. Weave will take each example, pass it through your application and score the output on multiple custom scoring functions. By doing this, you'll have a view of the performance of your application, and a rich UI to drill into individual outputs and scores.
First, we need to create a scoring function that tells whether the predicted answer matches the ground truth. Weave scoring functions receive the model's return value as `output` and any matching keys from the dataset example as additional arguments. Here, `answer` comes from the dataset and `output` is the dict returned by `CausalReasoningModule.forward`.
```python lines theme={null}
@weave.op()
def weave_evaluation_scorer(answer: str, output: dict) -> dict:
return {"match": int(answer.lower() == output["answer"].lower())}
```
Next, we wrap the module in a traced function that `weave.Evaluation` can call. The wrapper's argument names must match the dataset column names that the model consumes.
```python lines theme={null}
@weave.op()
def predict(question: str) -> dict:
return baseline_module(question=question)
```
Now we can define the evaluation and run it.
```python lines theme={null}
validation_dataset = weave.ref(
f"bigbenchhard_{metadata.big_bench_hard_task}_val:v0"
).get()
evaluation = weave.Evaluation(
name="baseline_causal_reasoning_module",
dataset=validation_dataset,
scorers=[weave_evaluation_scorer],
)
await evaluation.evaluate(predict)
```
 If you're running from a python script, you can use the following code to run the evaluation:
```python lines theme={null}
import asyncio
asyncio.run(evaluation.evaluate(predict))
```
Running the evaluation causal reasoning dataset will cost approximately \$0.24 in OpenAI credits.
## Optimizing our DSPy Program
Now that we have a baseline DSPy program, let us try to improve its performance for causal reasoning using the [BootstrapFewShot](https://dspy.ai/api/optimizers/BootstrapFewShot/) optimizer, which can tune the parameters of a DSPy program to maximize the specified metrics.
```python lines theme={null}
from dspy.teleprompt import BootstrapFewShot
@weave.op()
def get_optimized_program(model: dspy.Module, metadata: Metadata) -> dspy.Module:
@weave.op()
def dspy_evaluation_metric(true, prediction, trace=None):
return prediction["answer"].lower() == true.answer.lower()
teleprompter = BootstrapFewShot(
metric=dspy_evaluation_metric,
max_bootstrapped_demos=metadata.max_bootstrapped_demos,
max_labeled_demos=metadata.max_labeled_demos,
)
return teleprompter.compile(model, trainset=dspy_train_examples)
optimized_module = get_optimized_program(baseline_module, metadata)
```
If you're running from a python script, you can use the following code to run the evaluation:
```python lines theme={null}
import asyncio
asyncio.run(evaluation.evaluate(predict))
```
Running the evaluation causal reasoning dataset will cost approximately \$0.24 in OpenAI credits.
## Optimizing our DSPy Program
Now that we have a baseline DSPy program, let us try to improve its performance for causal reasoning using the [BootstrapFewShot](https://dspy.ai/api/optimizers/BootstrapFewShot/) optimizer, which can tune the parameters of a DSPy program to maximize the specified metrics.
```python lines theme={null}
from dspy.teleprompt import BootstrapFewShot
@weave.op()
def get_optimized_program(model: dspy.Module, metadata: Metadata) -> dspy.Module:
@weave.op()
def dspy_evaluation_metric(true, prediction, trace=None):
return prediction["answer"].lower() == true.answer.lower()
teleprompter = BootstrapFewShot(
metric=dspy_evaluation_metric,
max_bootstrapped_demos=metadata.max_bootstrapped_demos,
max_labeled_demos=metadata.max_labeled_demos,
)
return teleprompter.compile(model, trainset=dspy_train_examples)
optimized_module = get_optimized_program(baseline_module, metadata)
```
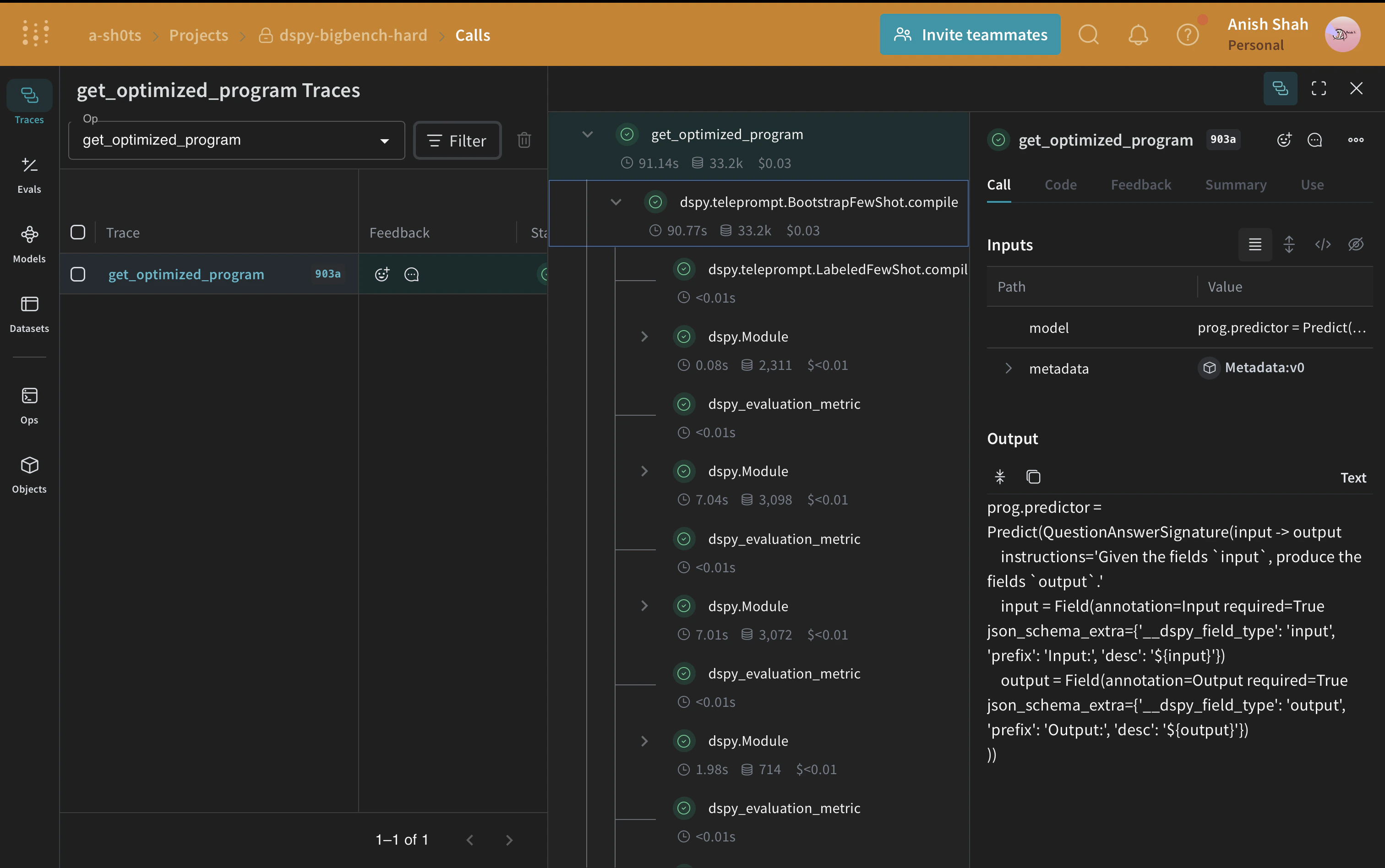 Running the evaluation causal reasoning dataset will cost approximately \$0.04 in OpenAI credits.
Now that we have our optimized program (the optimized prompting strategy), let's evaluate it once again on our validation set and compare it with our baseline DSPy program.
```python lines theme={null}
@weave.op()
def predict_optimized(question: str) -> dict:
return optimized_module(question=question)
evaluation = weave.Evaluation(
name="optimized_causal_reasoning_module",
dataset=validation_dataset,
scorers=[weave_evaluation_scorer],
)
await evaluation.evaluate(predict_optimized)
```
Running the evaluation causal reasoning dataset will cost approximately \$0.04 in OpenAI credits.
Now that we have our optimized program (the optimized prompting strategy), let's evaluate it once again on our validation set and compare it with our baseline DSPy program.
```python lines theme={null}
@weave.op()
def predict_optimized(question: str) -> dict:
return optimized_module(question=question)
evaluation = weave.Evaluation(
name="optimized_causal_reasoning_module",
dataset=validation_dataset,
scorers=[weave_evaluation_scorer],
)
await evaluation.evaluate(predict_optimized)
```
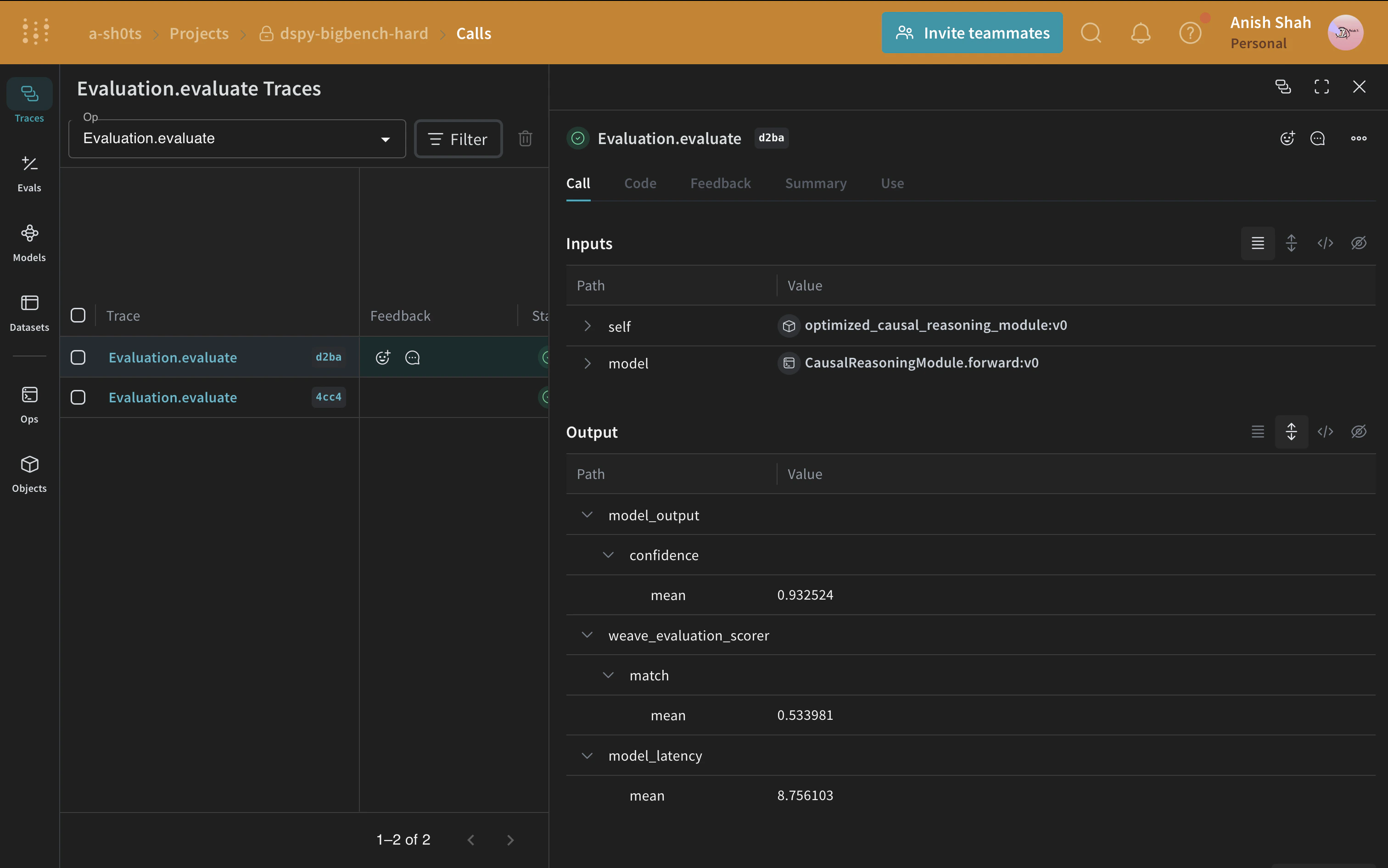 Comparing the evaluation of the baseline program with the optimized one shows that the optimized program answers the causal reasoning questions with significantly more accuracy.
## Conclusion
In this tutorial, we learned how to use DSPy for prompt optimization alongside using Weave for tracking and evaluation to compare the original and optimized programs.
Comparing the evaluation of the baseline program with the optimized one shows that the optimized program answers the causal reasoning questions with significantly more accuracy.
## Conclusion
In this tutorial, we learned how to use DSPy for prompt optimization alongside using Weave for tracking and evaluation to compare the original and optimized programs.