> ## Documentation Index
> Fetch the complete documentation index at: https://docs.wandb.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Use the Playground to experiment with prompts
> Simplify the process of iterating on LLM prompts and responses
For a limited time, Serverless Inference is included in your free tier. Serverless Inference provides access to leading open-source foundation models via API and the Weave Playground.
* [Developer documentation](../integrations/inference)
* [Product page](https://wandb.ai/site/inference)
Evaluating LLM prompts and responses is challenging. The Weave Playground is designed to simplify the process of iterating on LLM prompts and responses, making it easier to experiment with different models and prompts. With features like prompt editing, message retrying, and model comparison, Playground helps you to quickly test and improve your LLM applications. Playground currently supports models from providers such as OpenAI, Anthropic, and Google, as well as [custom providers](#add-a-custom-provider).
* **Quick access:** Open the 'Playground' from the Weave sidebar menu for a fresh session or from the Call page to test an existing project.
* **Message controls:** Edit, retry, or delete messages directly within the chat.
* **Flexible messaging:** Add new messages as either user or system inputs, and send them to the LLM.
* **Customizable settings:** Configure your preferred LLM provider and adjust model settings.
* **Multi-LLM support:** Switch between models, with team-level API key management.
* **Compare models:** Compare how different models respond to prompts.
* **Custom providers:** Test OpenAI compatible API endpoints for custom models.
* **Saved models:** Create and configure a reusable model preset for your workflow
Get started with the Playground to optimize your LLM interactions and streamline your prompt engineering process and LLM application development.
* [Add provider credentials and information](#add-provider-credentials-and-information)
* [Access the Playground](#access-the-playground)
* [Select an LLM](#select-an-llm)
* [Customize Playground settings](#customize-playground-settings)
* [Message controls](#message-controls)
* [Compare LLMs](#compare-llms)
* [Custom providers](#custom-providers)
* [Saved models](#saved-models)
## Add provider credentials and information
Before you can use Playground, you must add provider credentials. Playground currently supports models from many providers. To use one of the available models, add the appropriate information to your team secrets in W\&B settings.
* Amazon Bedrock:
* `AWS_ACCESS_KEY_ID`
* `AWS_SECRET_ACCESS_KEY`
* `AWS_REGION_NAME`
* Anthropic: `ANTHROPIC_API_KEY`
* Azure:
* `AZURE_API_KEY`
* `AZURE_API_BASE`
* `AZURE_API_VERSION`
* Deepseek: `DEEPSEEK_API_KEY`
* Google: `GEMINI_API_KEY`
* Groq: `GROQ_API_KEY`
* Mistral: `MISTRAL_API_KEY`
* OpenAI: `OPENAI_API_KEY`
* X.AI: `XAI_API_KEY`
## Access the Playground
There are two ways to access the Playground:
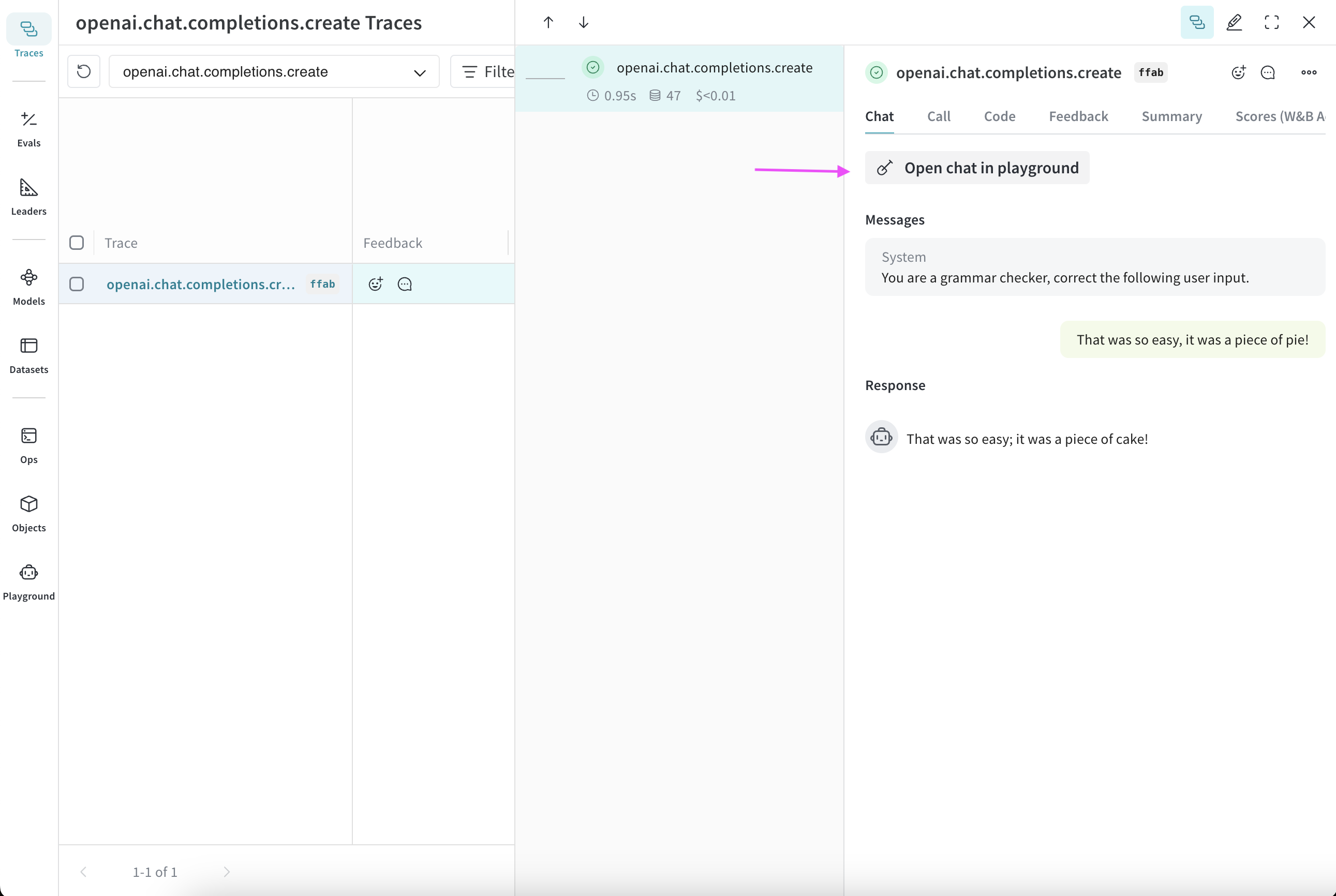
1. *Open a fresh Playground page with a simple system prompt*: In the sidebar of a Weave project, select **Playground**. Playground opens in the same tab.
2. *Open Playground for a specific call*:
1. In the sidebar, select the **Traces** tab. A list of traces displays.
2. In the list of traces, click the name of the call that you want to view. The call's details page opens.
3. Click **Open chat in Playground**. Playground opens in a new tab.
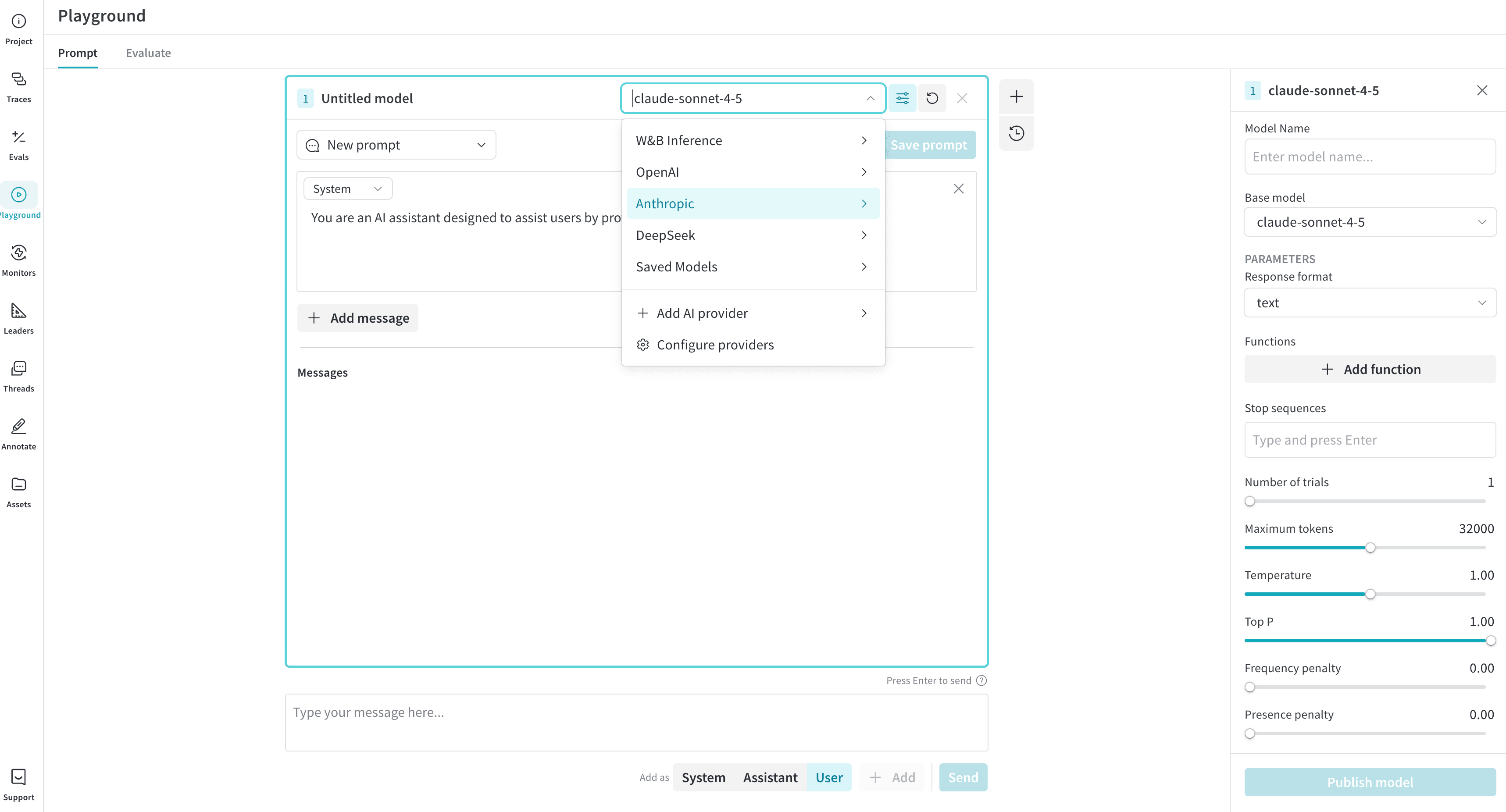
 ## Select an LLM
You can switch the LLM using the **Select a model** dropdown in the prompt header (top of the main Playground panel). The available models from various providers are listed below:
* Amazon Bedrock
* Anthropic
* Azure
* Deepseek
* Google
* Groq
* Mistral
* OpenAI
* X.AI
The available models depend on the providers configured for your team.
## Customize Playground settings
### Adjust LLM parameters
You can experiment with different parameter values for your selected model. To adjust parameters in the Playground, do the following:
1. In the prompt header (top of main panel), click the **Chat settings ()** button to open the **Chat settings** panel.
2. In the **Chat settings** panel, adjust parameters as desired. You can also toggle Weave call tracking on or off, and [add a function](#add-a-function).
3. Changes are applied automatically. Click **Chat settings** again, or the **x** in the upper-right corner, to close the panel. The hover text for the **Chat settings** button updates to display the settings you have changed.
If you leave the page, your settings will be lost. To save your settings, [save your model](#save-a-model).
If you want to discard your changed settings and start over, refresh the page.
## Select an LLM
You can switch the LLM using the **Select a model** dropdown in the prompt header (top of the main Playground panel). The available models from various providers are listed below:
* Amazon Bedrock
* Anthropic
* Azure
* Deepseek
* Google
* Groq
* Mistral
* OpenAI
* X.AI
The available models depend on the providers configured for your team.
## Customize Playground settings
### Adjust LLM parameters
You can experiment with different parameter values for your selected model. To adjust parameters in the Playground, do the following:
1. In the prompt header (top of main panel), click the **Chat settings ()** button to open the **Chat settings** panel.
2. In the **Chat settings** panel, adjust parameters as desired. You can also toggle Weave call tracking on or off, and [add a function](#add-a-function).
3. Changes are applied automatically. Click **Chat settings** again, or the **x** in the upper-right corner, to close the panel. The hover text for the **Chat settings** button updates to display the settings you have changed.
If you leave the page, your settings will be lost. To save your settings, [save your model](#save-a-model).
If you want to discard your changed settings and start over, refresh the page.
 Playground allows you to generate multiple outputs for the same input by setting the number of trials. The default setting is `1`. To adjust the number of trials, open the **Chat settings** panel and adjust the **Number of trials** setting.
### Add a function
You can test how different models use functions based on input it receives from the user. To add a function for testing in Playground, in the **Chat settings** panel, click **+ Add function**. Follow the on-screen guidance to define the function and save your changes.
## Message controls
### Prompt definition area
The **Prompt definition area** lets you define the instructions that shape the model's behavior throughout an interaction.
Use this area to provide context that applies consistently before any messages are exchanged. This includes role definition, tone and style guidance, behavioral constraints, and output requirements. Changes made here affect all subsequent interactions unless modified.
It includes:
* **Prompt selector**: Select an existing saved prompt or create a new one.
* **Message role selector**: Specify the role of the message being defined (**System**, **Assistant**, or **User** role).
* **Prompt text**: Enter the instruction text that establishes how the model should respond.
* **Add message** button: lets you include additional messages in the prompt context before execution.
These messages are sent to the model together and can be used to:
* Add supplemental system-level instructions.
* Provide example assistant messages to guide responses (such as few-shot prompting).
* Predefine user messages for testing specific scenarios.
### Messages panel
The **Messages panel** displays the conversation generated during execution.
It includes:
* Any predefined messages included in the prompt setup.
* Messages sent from the message composer.
* Responses returned by the model.
You can also **Copy**, **Delete**, **Edit**, and **Retry** messages inside the panel.
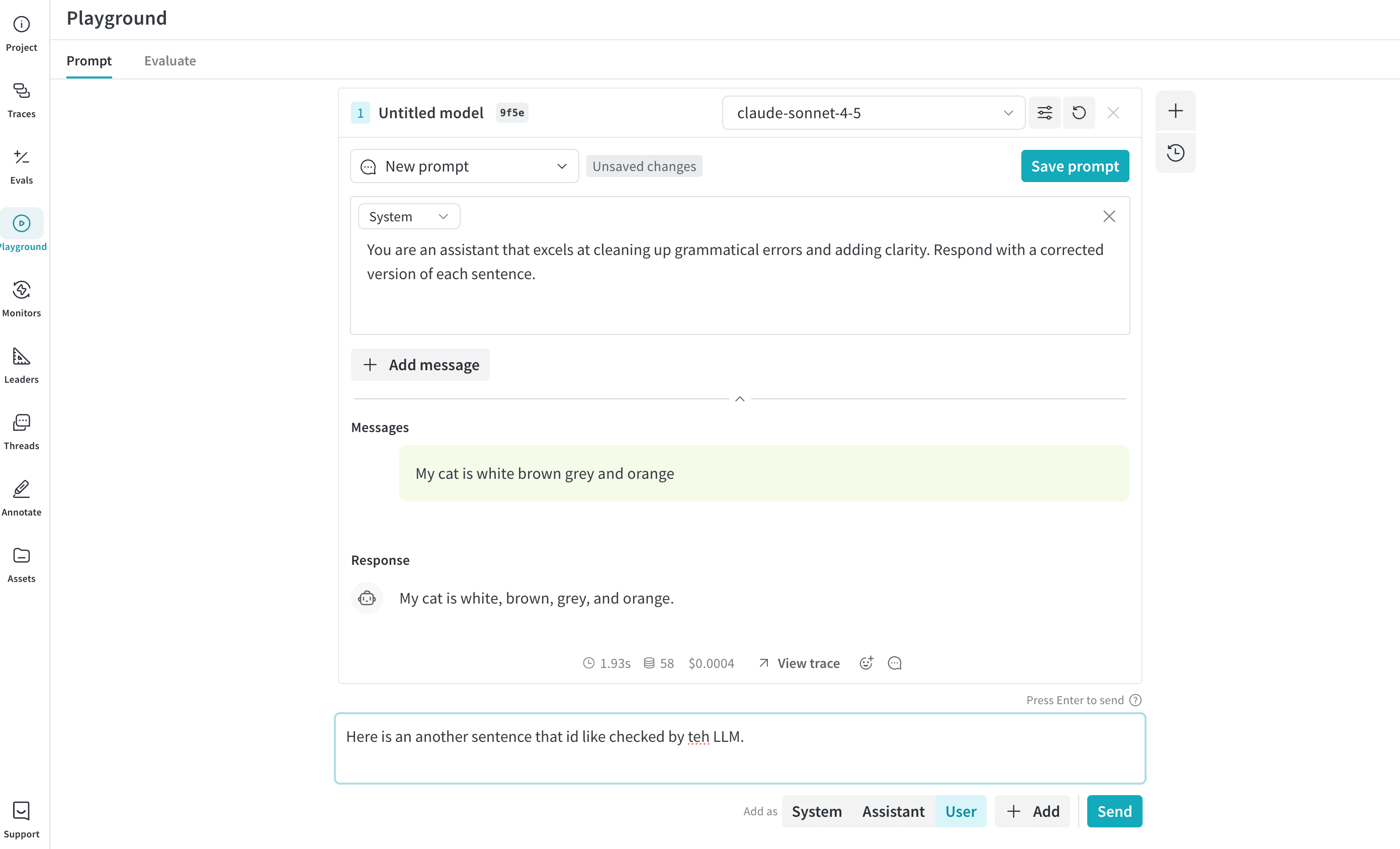
### Message composer (input field)
Use the **Message composer** to send new messages to the model.
It supports selecting the message role and submitting messages for execution. Most interactions are authored as **User** messages. **System** or **Assistant** messages can be added when testing instructions change.
Playground allows you to generate multiple outputs for the same input by setting the number of trials. The default setting is `1`. To adjust the number of trials, open the **Chat settings** panel and adjust the **Number of trials** setting.
### Add a function
You can test how different models use functions based on input it receives from the user. To add a function for testing in Playground, in the **Chat settings** panel, click **+ Add function**. Follow the on-screen guidance to define the function and save your changes.
## Message controls
### Prompt definition area
The **Prompt definition area** lets you define the instructions that shape the model's behavior throughout an interaction.
Use this area to provide context that applies consistently before any messages are exchanged. This includes role definition, tone and style guidance, behavioral constraints, and output requirements. Changes made here affect all subsequent interactions unless modified.
It includes:
* **Prompt selector**: Select an existing saved prompt or create a new one.
* **Message role selector**: Specify the role of the message being defined (**System**, **Assistant**, or **User** role).
* **Prompt text**: Enter the instruction text that establishes how the model should respond.
* **Add message** button: lets you include additional messages in the prompt context before execution.
These messages are sent to the model together and can be used to:
* Add supplemental system-level instructions.
* Provide example assistant messages to guide responses (such as few-shot prompting).
* Predefine user messages for testing specific scenarios.
### Messages panel
The **Messages panel** displays the conversation generated during execution.
It includes:
* Any predefined messages included in the prompt setup.
* Messages sent from the message composer.
* Responses returned by the model.
You can also **Copy**, **Delete**, **Edit**, and **Retry** messages inside the panel.
### Message composer (input field)
Use the **Message composer** to send new messages to the model.
It supports selecting the message role and submitting messages for execution. Most interactions are authored as **User** messages. **System** or **Assistant** messages can be added when testing instructions change.
 ## View message history
To view message history, click the **History ()** button in the right-side Playground toolbar. This opens a History panel showing all messages sent for the current project.
Selecting an item from the history automatically loads it into an additional chat panel for comparison.
## Compare LLMs
Playground allows you to compare LLMs. To perform a comparison, click the **Add Chat ()** button in the right-side Playground toolbar. A second chat opens next to the original chat.
In the second chat, you have the same functionality as the original chat, such as choosing the model, adjusting the settings, and adding functions.
## Custom providers
### Add a custom provider
In addition to the built-in providers, you can use the Playground to test OpenAI compatible API endpoints for custom models. Examples include:
* Older versions of supported model providers
* Local models
To add a custom provider to the Playground, do the following:
1. In the prompt header (top of main panel), click the **Select a model** dropdown.
2. Select **+ Add AI provider**.
3. Select **Custom Provider**.
4. In the pop-up modal, enter the provider information:
* **Provider name**: A name for the provider, such as `openai` or `ollama`.
* **API key**: The API key for the provider, such as an OpenAI API key.
* **Base URL**: The base endpoint for the provider, such as `https://api.openai.com/v1/` or an ngrok URL like `https://e452-2600-1700-45f0-3e10-2d3f-796b-d6f2-8ba7.ngrok-free.app`.
* **Headers**: (Optional) One or more custom HTTP header key-value pairs.
* **Models**: One or more models for the provider, such as `deepseek-r1` or `qwq`.
* **Max tokens**: (Optional) For each model, the maximum number of tokens the model can generate in a response.
5. Once you've entered your provider information, click **Add provider**.
6. Select your new provider and available model(s) from the **Select a model** dropdown.
Because of CORS restrictions, you can't call localhost or 127.0.0.1 URLs directly from the Playground. If you're running a local model server (such as Ollama), use a tunneling service like ngrok to expose it securely. For details, see [Use ngrok with Ollama](#use-a-local-model-as-a-custom-provider).
Now, you can test the custom provider model(s) using standard Playground features. You can also [edit](#edit-a-custom-provider) or [remove](#remove-a-custom-provider) the custom provider.
### Edit a custom provider
To edit information for a [previously created custom provider](#add-a-custom-provider), do the following:
1. In the prompt header, click the **Select a model** dropdown. Then select **+Configure providers**.
* Alternatively, in the sidebar menu, you can select **Project**, and then select the **AI Providers** tab.
2. In the **Custom providers** table, find the custom provider you want to update.
3. In the **Last Updated** column of the entry for your custom provider, click the edit button (the pencil icon).
4. In the pop-up modal, edit the provider information.
5. Click **Save**.
### Remove a custom provider
To remove a [previously created custom provider](#add-a-custom-provider), do the following:
1. In the prompt header, click the **Select a model** dropdown. Then select **+Configure providers**.
* Alternatively, in the sidebar menu, you can select **Project**, and then select the **AI Providers** tab.
2. In the **Custom providers** table, find the custom provider you want to update.
3. In the **Last Updated** column of the entry for your custom provider, click the delete button (the trashcan icon).
4. In the pop-up modal, confirm that you want to delete the provider. This action cannot be undone.
5. Click **Delete**.
### Use a local model as a custom provider
To test a locally running model in the Playground, use ngrok and Ollama to create a temporary public URL that bypasses CORS restrictions.
To set it up, do the following:
1. [Install ngrok](https://ngrok.com/docs/getting-started/#step-1-install) for your operating system.
2. Start your Ollama model:
```bash theme={null}
ollama run
```
3. In a separate terminal, create an ngrok tunnel with the required CORS headers:
```bash theme={null}
ngrok http 11434 --response-header-add "Access-Control-Allow-Origin: *" --host-header rewrite
```
4. After ngrok starts, it will display a public URL, such as `https://xxxx-xxxx.ngrok-free.app`. Use this URL as the **Base URL** when you [add a custom provider](#add-a-custom-provider) in the Playground.
The following diagram illustrates the data flow between your local environment, the ngrok proxy, and the W\&B cloud services:
```mermaid theme={null}
flowchart LR
%% Style definitions
classDef clientMachine fill:#FFD95CCC,stroke:#454B52,stroke-width:2px
classDef proxy fill:#00CDDBCC,stroke:#454B52,stroke-width:2px
classDef wandbCloud fill:#DE72FFCC,stroke:#454B52,stroke-width:2px
classDef publicCloud fill:#FFCBADCC,stroke:#454B52,stroke-width:2px
%% Subgraphs
subgraph Client_Machine
browser[Browser]
llm_local[Local LLM Provider]
end
subgraph Proxy
ngrok[Ngrok Proxy]
end
subgraph WandB_Cloud
trace_server[Trace Server]
end
subgraph Public_Cloud
llm_cloud[Public LLM Provider]
end
%% Apply styles to subgraphs
class Client_Machine clientMachine
class Proxy proxy
class WandB_Cloud wandbCloud
class Public_Cloud publicCloud
%% Current Data Flow
browser -->|Sends chat request| trace_server
trace_server -->|Uses Public LLM| llm_cloud
trace_server -->|Uses Local LLM| ngrok
ngrok -->|Forwards to| llm_local
llm_cloud -->|Returns response| trace_server
llm_local -->|Returns response| ngrok
ngrok -->|Forwards to| trace_server
trace_server -->|Returns response| browser
%% Future Possible Connection
browser -.->|Future: Call local LLM directly| llm_local
%% Link styles
linkStyle default stroke:#454B52,stroke-width:2px
linkStyle 8 stroke:#454B52,stroke-width:2px,stroke-dasharray:5
```
## Saved models
### Save a model
You can create and configure a reusable model preset for your workflow. Saving a model lets you quickly load it with your preferred settings, parameters, and function hooks.
1. In the prompt header (top of main panel), in the **Select a model** dropdown, select a provider and model.
2. In the prompt header, click the **Chat settings ()** button to open the **Chat settings** panel.
3. In the **Chat settings** panel:
* **Model Name** (required): Enter a name for your saved model.
* Adjust parameters as desired. You can also toggle Weave call tracking on or off, and [add a function](#add-a-function).
4. Click **Publish model**. The model is saved and accessible from **Saved Models** in the **Select a model** dropdown. You can now [use](#use-a-saved-model) and [update](#update-a-saved-model) the saved model.
### Use a saved model
Quickly switch to a previously [saved model](#save-a-model) to maintain consistency across experiments or sessions. This way you can pick up right where you left off.
1. In the prompt header, in the **Select a model** dropdown, select **Saved Models**.
2. From the list of saved models, select the saved model you want to load. The model loads and is ready for use in the Playground.
### Update a saved model
Edit an existing [saved model](#save-a-model) to fine-tune parameters or refresh its configuration. This ensures your saved models evolve alongside your use cases.
1. In the prompt header, in the **Select a model** dropdown, select **Saved Models**.
2. From the list of saved models, select the saved model you want to update.
3. In the prompt header, click the **Chat settings ()** button to open the **Chat settings** panel.
4. In the **Chat settings** panel, adjust parameters as desired. You can also toggle Weave call tracking on or off, and [add a function](#add-a-function).
5. Click **Update model**. This updates the model and makes it accessible from **Saved Models** in the **Select a model** dropdown. The version of your saved model increments automatically.
## View message history
To view message history, click the **History ()** button in the right-side Playground toolbar. This opens a History panel showing all messages sent for the current project.
Selecting an item from the history automatically loads it into an additional chat panel for comparison.
## Compare LLMs
Playground allows you to compare LLMs. To perform a comparison, click the **Add Chat ()** button in the right-side Playground toolbar. A second chat opens next to the original chat.
In the second chat, you have the same functionality as the original chat, such as choosing the model, adjusting the settings, and adding functions.
## Custom providers
### Add a custom provider
In addition to the built-in providers, you can use the Playground to test OpenAI compatible API endpoints for custom models. Examples include:
* Older versions of supported model providers
* Local models
To add a custom provider to the Playground, do the following:
1. In the prompt header (top of main panel), click the **Select a model** dropdown.
2. Select **+ Add AI provider**.
3. Select **Custom Provider**.
4. In the pop-up modal, enter the provider information:
* **Provider name**: A name for the provider, such as `openai` or `ollama`.
* **API key**: The API key for the provider, such as an OpenAI API key.
* **Base URL**: The base endpoint for the provider, such as `https://api.openai.com/v1/` or an ngrok URL like `https://e452-2600-1700-45f0-3e10-2d3f-796b-d6f2-8ba7.ngrok-free.app`.
* **Headers**: (Optional) One or more custom HTTP header key-value pairs.
* **Models**: One or more models for the provider, such as `deepseek-r1` or `qwq`.
* **Max tokens**: (Optional) For each model, the maximum number of tokens the model can generate in a response.
5. Once you've entered your provider information, click **Add provider**.
6. Select your new provider and available model(s) from the **Select a model** dropdown.
Because of CORS restrictions, you can't call localhost or 127.0.0.1 URLs directly from the Playground. If you're running a local model server (such as Ollama), use a tunneling service like ngrok to expose it securely. For details, see [Use ngrok with Ollama](#use-a-local-model-as-a-custom-provider).
Now, you can test the custom provider model(s) using standard Playground features. You can also [edit](#edit-a-custom-provider) or [remove](#remove-a-custom-provider) the custom provider.
### Edit a custom provider
To edit information for a [previously created custom provider](#add-a-custom-provider), do the following:
1. In the prompt header, click the **Select a model** dropdown. Then select **+Configure providers**.
* Alternatively, in the sidebar menu, you can select **Project**, and then select the **AI Providers** tab.
2. In the **Custom providers** table, find the custom provider you want to update.
3. In the **Last Updated** column of the entry for your custom provider, click the edit button (the pencil icon).
4. In the pop-up modal, edit the provider information.
5. Click **Save**.
### Remove a custom provider
To remove a [previously created custom provider](#add-a-custom-provider), do the following:
1. In the prompt header, click the **Select a model** dropdown. Then select **+Configure providers**.
* Alternatively, in the sidebar menu, you can select **Project**, and then select the **AI Providers** tab.
2. In the **Custom providers** table, find the custom provider you want to update.
3. In the **Last Updated** column of the entry for your custom provider, click the delete button (the trashcan icon).
4. In the pop-up modal, confirm that you want to delete the provider. This action cannot be undone.
5. Click **Delete**.
### Use a local model as a custom provider
To test a locally running model in the Playground, use ngrok and Ollama to create a temporary public URL that bypasses CORS restrictions.
To set it up, do the following:
1. [Install ngrok](https://ngrok.com/docs/getting-started/#step-1-install) for your operating system.
2. Start your Ollama model:
```bash theme={null}
ollama run
```
3. In a separate terminal, create an ngrok tunnel with the required CORS headers:
```bash theme={null}
ngrok http 11434 --response-header-add "Access-Control-Allow-Origin: *" --host-header rewrite
```
4. After ngrok starts, it will display a public URL, such as `https://xxxx-xxxx.ngrok-free.app`. Use this URL as the **Base URL** when you [add a custom provider](#add-a-custom-provider) in the Playground.
The following diagram illustrates the data flow between your local environment, the ngrok proxy, and the W\&B cloud services:
```mermaid theme={null}
flowchart LR
%% Style definitions
classDef clientMachine fill:#FFD95CCC,stroke:#454B52,stroke-width:2px
classDef proxy fill:#00CDDBCC,stroke:#454B52,stroke-width:2px
classDef wandbCloud fill:#DE72FFCC,stroke:#454B52,stroke-width:2px
classDef publicCloud fill:#FFCBADCC,stroke:#454B52,stroke-width:2px
%% Subgraphs
subgraph Client_Machine
browser[Browser]
llm_local[Local LLM Provider]
end
subgraph Proxy
ngrok[Ngrok Proxy]
end
subgraph WandB_Cloud
trace_server[Trace Server]
end
subgraph Public_Cloud
llm_cloud[Public LLM Provider]
end
%% Apply styles to subgraphs
class Client_Machine clientMachine
class Proxy proxy
class WandB_Cloud wandbCloud
class Public_Cloud publicCloud
%% Current Data Flow
browser -->|Sends chat request| trace_server
trace_server -->|Uses Public LLM| llm_cloud
trace_server -->|Uses Local LLM| ngrok
ngrok -->|Forwards to| llm_local
llm_cloud -->|Returns response| trace_server
llm_local -->|Returns response| ngrok
ngrok -->|Forwards to| trace_server
trace_server -->|Returns response| browser
%% Future Possible Connection
browser -.->|Future: Call local LLM directly| llm_local
%% Link styles
linkStyle default stroke:#454B52,stroke-width:2px
linkStyle 8 stroke:#454B52,stroke-width:2px,stroke-dasharray:5
```
## Saved models
### Save a model
You can create and configure a reusable model preset for your workflow. Saving a model lets you quickly load it with your preferred settings, parameters, and function hooks.
1. In the prompt header (top of main panel), in the **Select a model** dropdown, select a provider and model.
2. In the prompt header, click the **Chat settings ()** button to open the **Chat settings** panel.
3. In the **Chat settings** panel:
* **Model Name** (required): Enter a name for your saved model.
* Adjust parameters as desired. You can also toggle Weave call tracking on or off, and [add a function](#add-a-function).
4. Click **Publish model**. The model is saved and accessible from **Saved Models** in the **Select a model** dropdown. You can now [use](#use-a-saved-model) and [update](#update-a-saved-model) the saved model.
### Use a saved model
Quickly switch to a previously [saved model](#save-a-model) to maintain consistency across experiments or sessions. This way you can pick up right where you left off.
1. In the prompt header, in the **Select a model** dropdown, select **Saved Models**.
2. From the list of saved models, select the saved model you want to load. The model loads and is ready for use in the Playground.
### Update a saved model
Edit an existing [saved model](#save-a-model) to fine-tune parameters or refresh its configuration. This ensures your saved models evolve alongside your use cases.
1. In the prompt header, in the **Select a model** dropdown, select **Saved Models**.
2. From the list of saved models, select the saved model you want to update.
3. In the prompt header, click the **Chat settings ()** button to open the **Chat settings** panel.
4. In the **Chat settings** panel, adjust parameters as desired. You can also toggle Weave call tracking on or off, and [add a function](#add-a-function).
5. Click **Update model**. This updates the model and makes it accessible from **Saved Models** in the **Select a model** dropdown. The version of your saved model increments automatically.