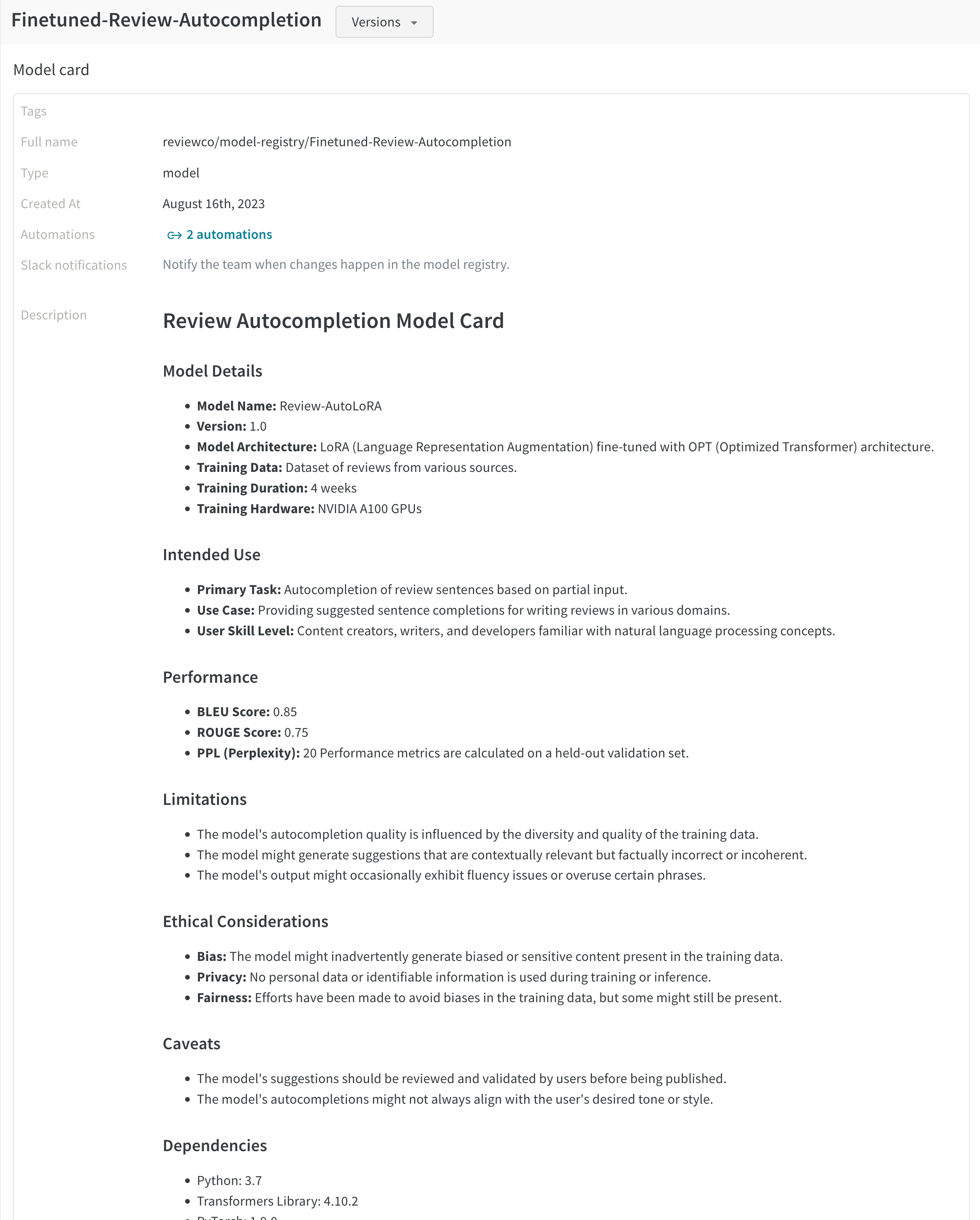
- 요약: 컬렉션의 목적. 기계 학습 실험에 사용된 기계 학습 프레임워크.
- 라이선스: 기계 학습 모델 사용과 관련된 법적 조건 및 권한. 모델 사용자가 모델을 활용할 수 있는 법적 프레임워크를 이해하는 데 도움이 됩니다. 일반적인 라이선스에는 Apache 2.0, MIT 및 GPL이 있습니다.
- 참조: 관련 연구 논문, 데이터셋 또는 외부 리소스에 대한 인용 또는 참조.
- 트레이닝 데이터: 사용된 트레이닝 데이터에 대해 설명합니다.
- 처리: 트레이닝 데이터 세트에서 수행된 처리.
- 데이터 저장소: 해당 데이터가 저장된 위치 및 엑세스 방법.
- 아키텍처: 모델 아키텍처, 레이어 및 특정 설계 선택에 대한 정보.
- 작업: 컬렉션 모델이 수행하도록 설계된 특정 유형의 작업 또는 문제. 모델의 의도된 기능을 분류한 것입니다.
- 모델 역직렬화: 팀의 누군가가 모델을 메모리에 로드할 수 있는 방법에 대한 정보를 제공합니다.
- 작업: 기계 학습 모델이 수행하도록 설계된 특정 유형의 작업 또는 문제입니다. 모델의 의도된 기능을 분류한 것입니다.
- 배포: 모델이 배포되는 방식 및 위치에 대한 세부 정보와 모델을 워크플로우 오케스트레이션 플랫폼과 같은 다른 엔터프라이즈 시스템에 통합하는 방법에 대한 지침.
컬렉션에 대한 설명 추가
W&B Registry UI 또는 Python SDK를 사용하여 컬렉션에 대한 설명을 대화형으로 또는 프로그래밍 방식으로 추가합니다.- W&B Registry UI
- Python SDK
- https://wandb.ai/registry/의 W&B Registry로 이동합니다.
- 컬렉션을 클릭합니다.
- 컬렉션 이름 옆에 있는 세부 정보 보기를 선택합니다.
- 설명 필드 내에서 컬렉션에 대한 정보를 제공합니다. Markdown 마크업 언어를 사용하여 텍스트 형식을 지정합니다.