Serverless Inference
- 호스팅 제공업체에 가입하거나 모델을 직접 호스팅하지 않고도 AI 애플리케이션과 에이전트를 개발할 수 있습니다.
- Weave 플레이그라운드에서 지원되는 모델을 사용해 볼 수 있습니다.
이 가이드는 다음 정보를 제공합니다:
사전 요구 사항
- W&B 계정. 계정에 가입하세요.
- W&B API 키. User Settings에서 API 키를 생성하세요.
- W&B 프로젝트.
- Python을 통해 Inference 서비스를 사용하는 경우 Python을 통해 API를 사용하기 위한 추가 사전 요구 사항을 참조하세요.
Python에서 API를 사용하기 위한 추가 사전 요구 사항
openai와 weave 라이브러리를 설치하세요. openai 라이브러리는 Inference 엔드포인트를 호출하는 데 사용하는 OpenAI 호환 클라이언트를 제공하며, weave 라이브러리는 이러한 호출을 트레이스하고 평가할 수 있게 해줍니다.
LLM 애플리케이션을 Weave로 트레이스하는 경우에만
weave 라이브러리가 필요합니다. Weave 시작에 대한 자세한 내용은 Weave 퀵스타트를 참조하세요.Weave로 Serverless Inference 서비스를 사용하는 방법을 보여주는 예시는 API 사용 예시를 참조하세요.API 사양
엔드포인트
사용 가능한 방법
Chat completions
/chat/completions이며, 지원되는 모델에 메시지를 보내고 completion을 받기 위한 OpenAI 호환 요청 형식을 지원합니다. Weave로 Serverless Inference 서비스를 사용하는 방법을 보여주는 사용 예시는 API 사용 예시를 참조하세요.
채팅 completion을 생성하려면 다음이 필요합니다:
- Inference 서비스 기본 URL
https://api.inference.wandb.ai/v1 - W&B API 키
<your-api-key> - W&B entity 및 프로젝트 이름
<your-team>/<your-project> - 사용하려는 모델의 ID(다음 중 하나):
meta-llama/Llama-3.1-8B-Instructdeepseek-ai/DeepSeek-V3-0324meta-llama/Llama-3.3-70B-Instructdeepseek-ai/DeepSeek-R1-0528meta-llama/Llama-4-Scout-17B-16E-Instructmicrosoft/Phi-4-mini-instruct
- Bash
- Python
지원되는 모델 목록
- Bash
- Python
사용 예시
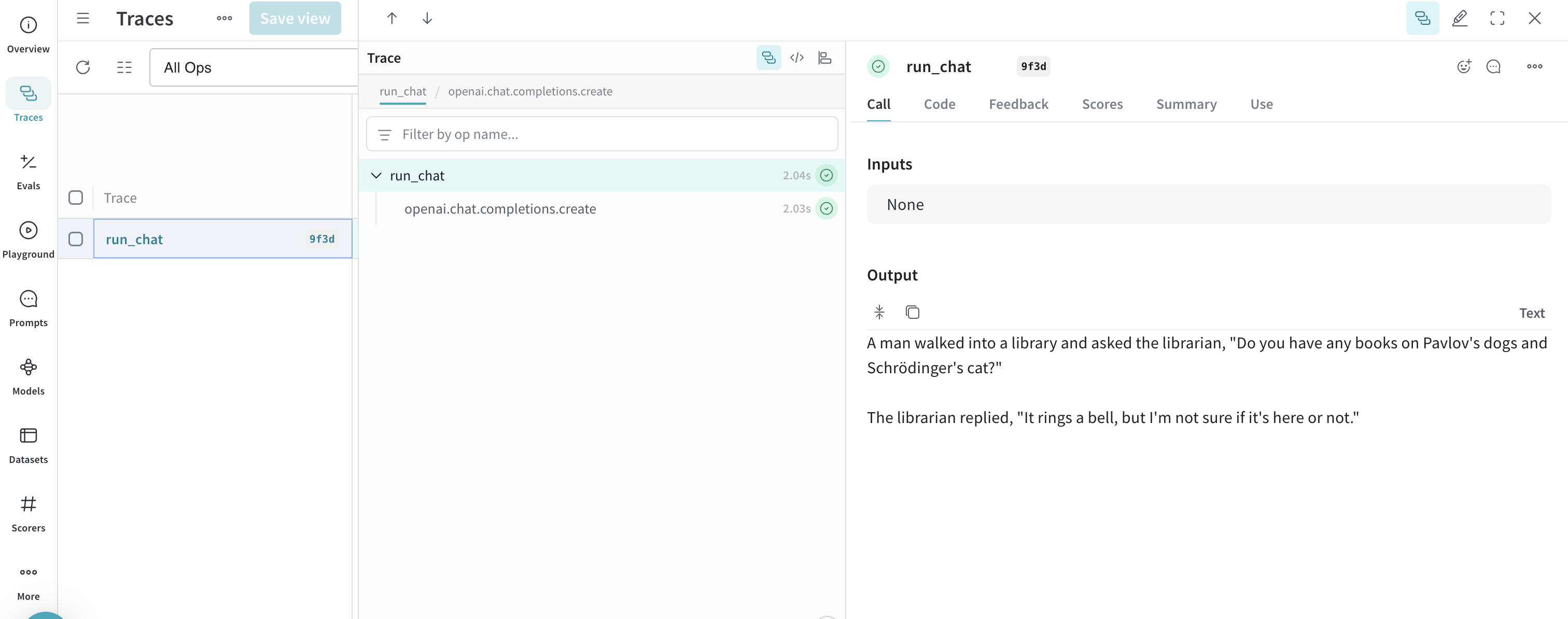
기본 예제: Weave로 Llama 3.1 8B 트레이스하기
- OpenAI 호환 클라이언트를 사용해 chat completion 요청을 보내는
@weave.op()데코레이터가 적용된 함수run_chat를 정의합니다. - Weave는 트레이스를 기록하여 W&B entity 및 프로젝트
project="<your-team>/<your-project>"와 연결합니다. - Weave는 함수를 자동으로 트레이스하여 입력, 출력, 지연 시간, 메타데이터(예: 모델 ID)를 로깅합니다.
- 결과는 터미널에 출력되며, 트레이스는 지정한 프로젝트 아래 https://wandb.ai의 Traces 탭에 표시됩니다.
https://wandb.ai/<your-team>/<your-project>/r/call/01977f8f-839d-7dda-b0c2-27292ef0e04g)를 클릭하면 됩니다. 또는 다음과 같이 할 수 있습니다.
- https://wandb.ai로 이동합니다.
- Traces 탭을 선택해 Weave 트레이스를 확인합니다.
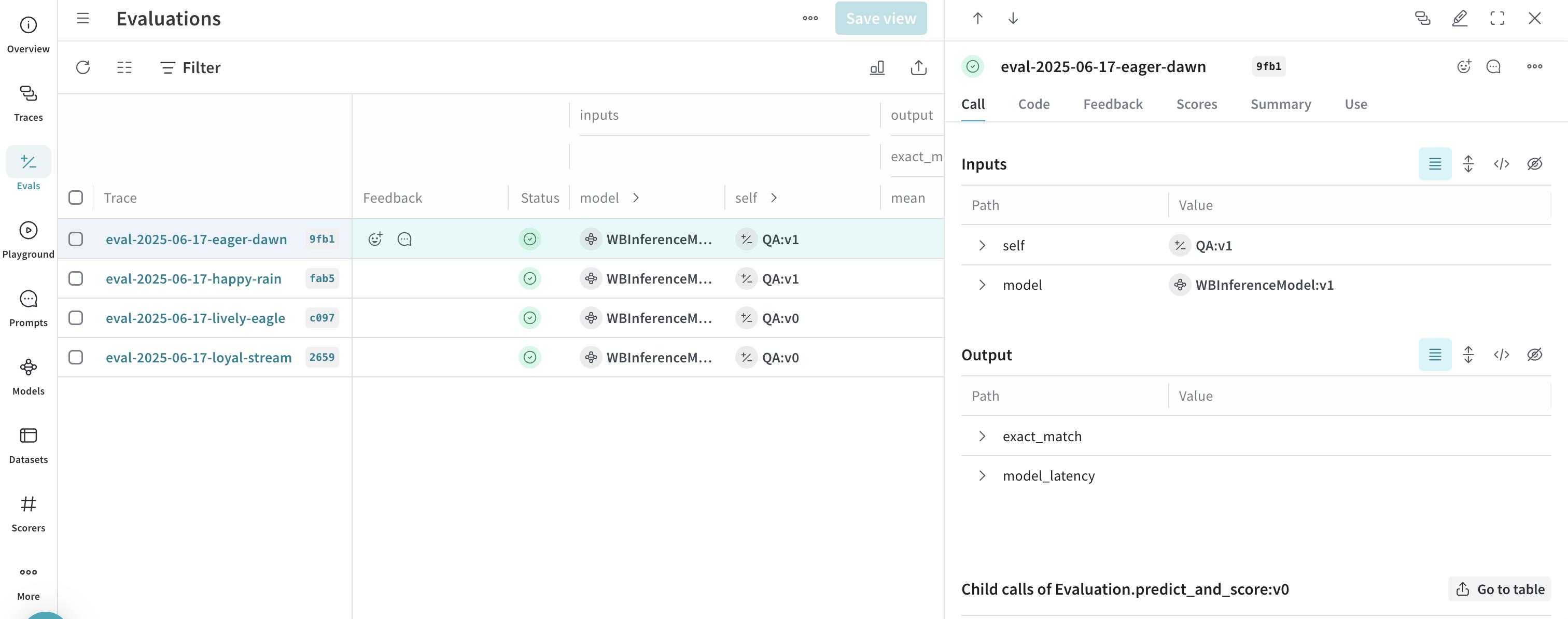
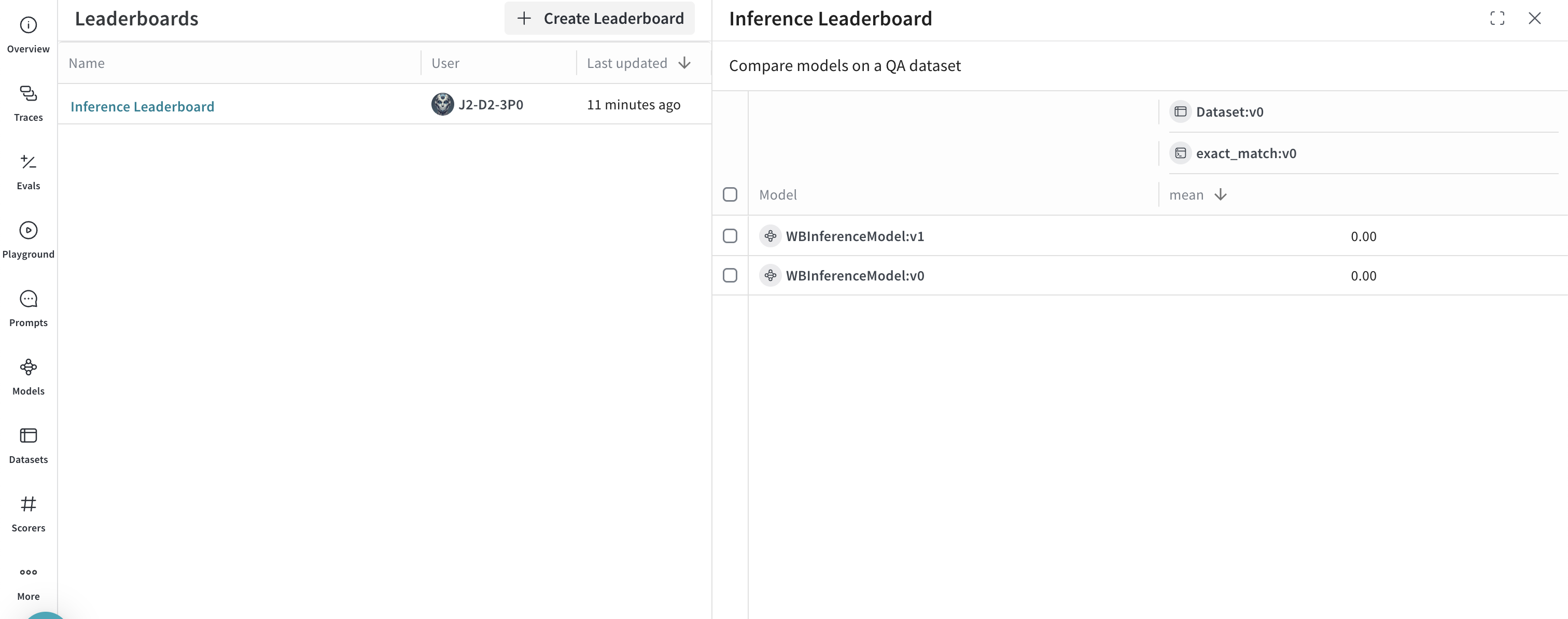
고급 예제: Inference 서비스와 함께 Weave Evaluations 및 리더보드 사용
- Traces 탭으로 이동하여 트레이스를 확인합니다.
- Evals 탭으로 이동하여 모델 평가를 확인합니다.
- Leaders 탭으로 이동하여 생성된 리더보드를 확인합니다.
UI
Inference 서비스에 접속하기
직접 링크
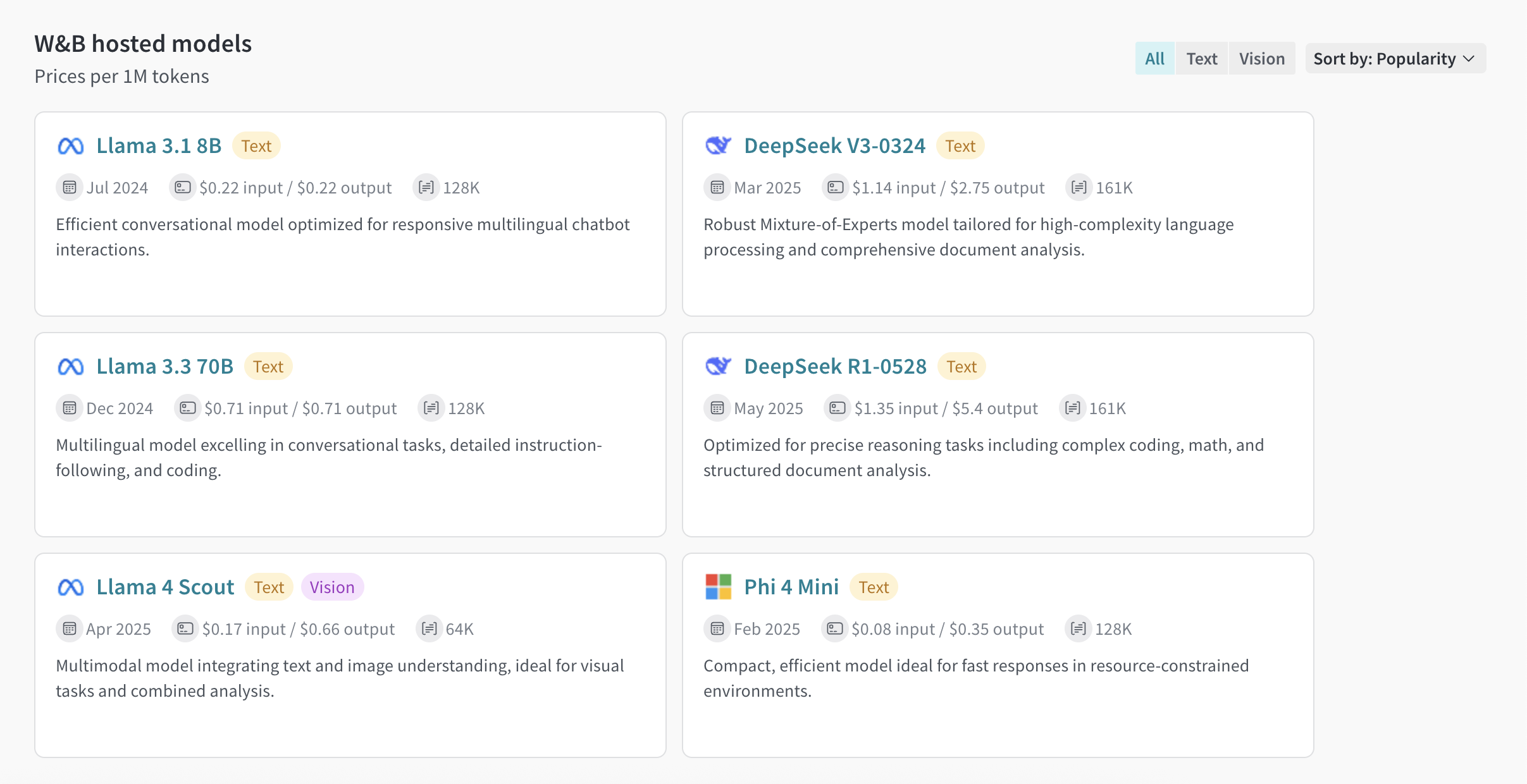
Inference 탭에서
- https://wandb.ai/에서 W&B 계정에 접속합니다.
- 왼쪽 사이드바에서 Inference를 선택합니다. 사용 가능한 모델과 모델 정보가 표시되는 페이지가 열립니다.
Playground 탭에서
- 왼쪽 사이드바에서 Playground를 선택합니다. Playground 채팅 UI가 표시됩니다.
- LLM 드롭다운 목록에서 Serverless Inference 위에 마우스를 올립니다. 사용 가능한 Serverless Inference 모델이 포함된 드롭다운이 오른쪽에 표시됩니다.
- Serverless Inference 모델 드롭다운에서 다음을 수행할 수 있습니다:
- 사용 가능한 모델의 이름을 클릭하여 Playground에서 사용해 볼 수 있습니다.
- Playground에서 하나 이상의 모델을 비교할 수 있습니다.
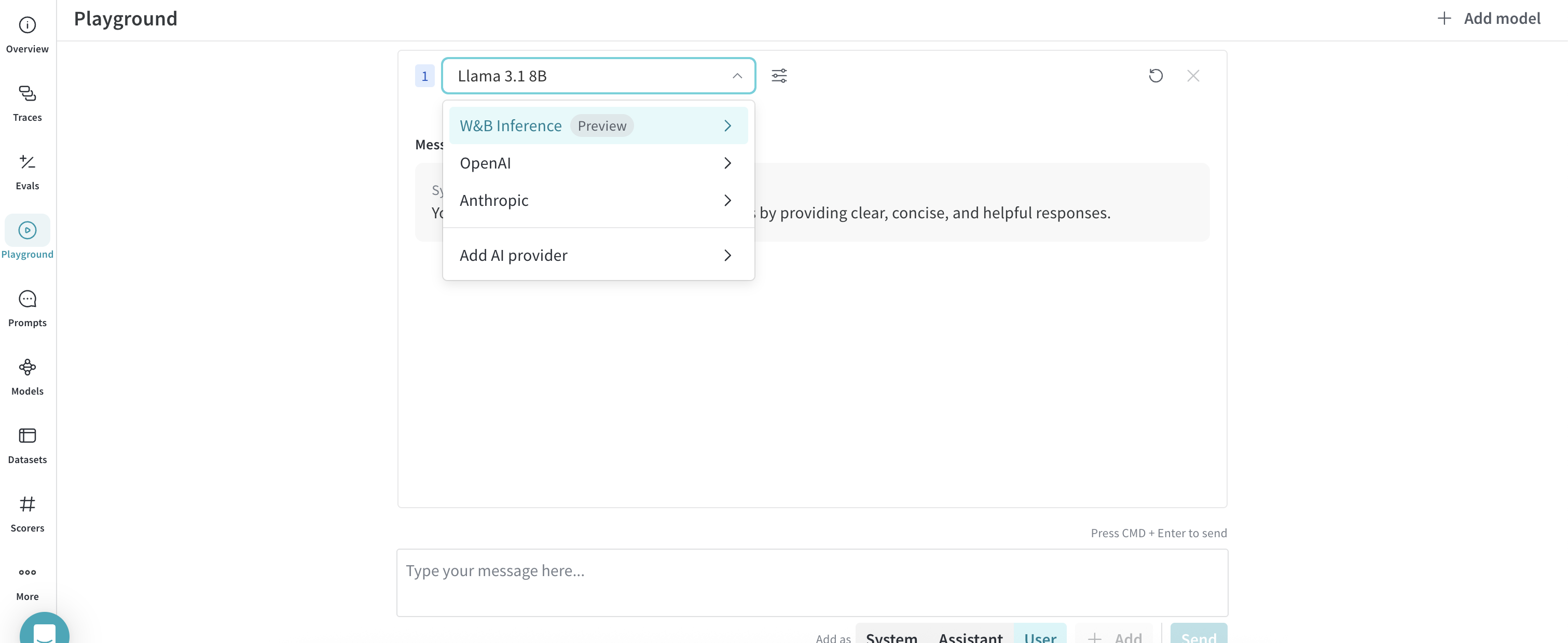
플레이그라운드에서 모델 사용해 보기
여러 모델 비교
Inference 탭에서 Compare 뷰 열기
- 왼쪽 사이드바에서 Inference를 선택합니다. 사용 가능한 모델과 모델 정보가 표시된 페이지가 열립니다.
- 비교할 모델을 선택하려면 모델 카드에서 모델 이름을 제외한 아무 곳이나 클릭합니다. 선택되었음을 나타내기 위해 모델 카드 테두리가 파란색으로 강조 표시됩니다.
- 비교하려는 각 모델에 대해 2단계를 반복합니다.
- 선택한 카드 중 아무 카드에서나 Compare N models in the Playground 버튼을 클릭합니다(
N은 비교할 모델 수입니다. 예를 들어 모델 3개를 선택하면 버튼에는 Compare 3 models in the Playground가 표시됩니다). 뷰가 열립니다.
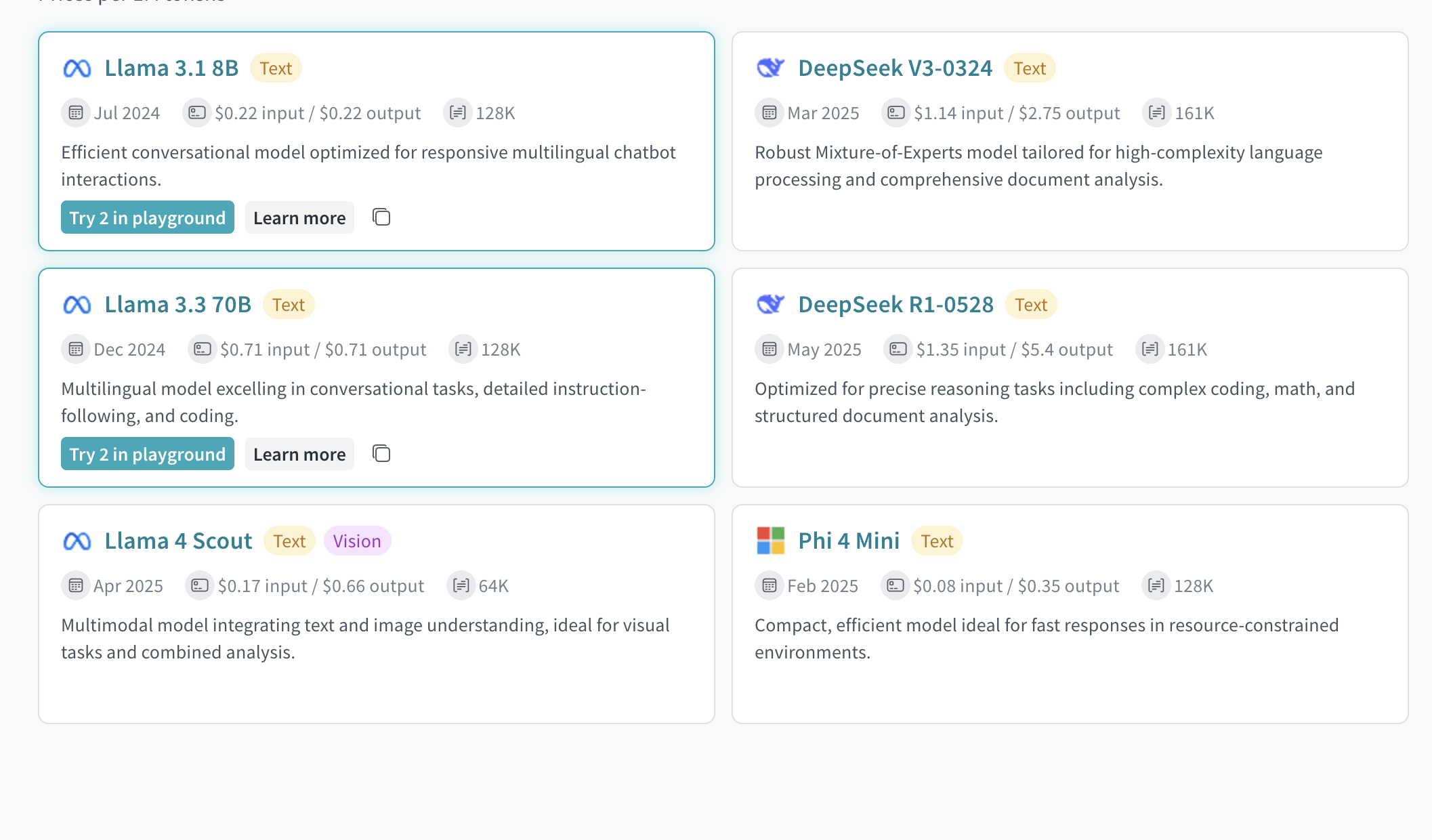
Playground 탭에서 Compare 뷰 열기
- 왼쪽 사이드바에서 Playground를 선택합니다. Playground 채팅 UI가 표시됩니다.
- LLM 드롭다운 목록에서 Serverless Inference에 마우스를 올립니다. 오른쪽에 사용 가능한 Serverless Inference 모델이 포함된 드롭다운이 표시됩니다.
- 드롭다운에서 Compare를 선택합니다. Inference 탭이 표시됩니다.
- 비교할 모델을 선택하려면 모델 카드의 아무 곳이나 클릭합니다(모델 이름 제외). 선택되면 모델 카드 테두리가 파란색으로 강조 표시됩니다.
- 비교하려는 각 모델에 대해 step 4를 반복합니다.
- 선택한 카드 중 아무 카드에서나 Compare N models in the Playground 버튼을 클릭합니다(
N은 비교 중인 모델 수입니다. 예를 들어 모델 3개를 선택하면 버튼은 Compare 3 models in the Playground로 표시됩니다). 뷰가 열립니다.
결제 및 사용 정보 보기
- W&B UI에서 W&B Billing 페이지로 이동합니다.
- 오른쪽 하단에 Inference 결제 정보 카드가 표시됩니다. 여기에서 다음 작업을 수행할 수 있습니다.
- Inference 결제 정보 카드에서 View usage 버튼을 클릭해 시간에 따른 사용량을 확인합니다.
- 유료 플랜을 사용 중인 경우 예정된 Inference 요금을 확인합니다.
사용 정보 및 제한 사항
지리적 제한
동시성 제한
- 오용을 방지하고 API 안정성을 보호.
- 모든 사용자가 액세스할 수 있도록 보장.
- 인프라 부하를 효과적으로 관리.
429 Concurrency limit reached for requests 응답을 반환합니다. 이 오류를 해결하려면 동시에 전송하는 요청 수를 줄이세요.