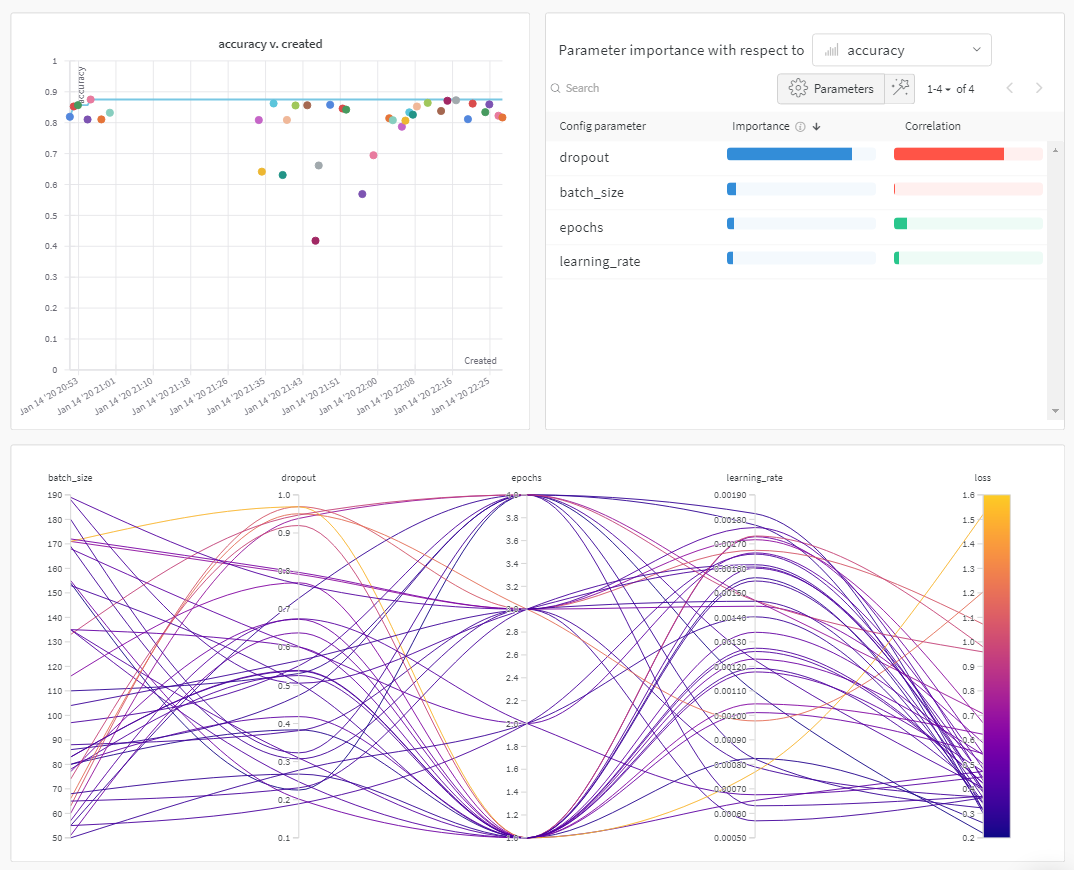
How it works
Create a sweep with two W&B CLI commands:- Initialize a sweep.
- Start the sweep agent.
The preceding code snippet, and the colab linked on this page, show how to initialize and create a sweep with the W&B CLI. See the Sweeps walkthrough to use the Python SDK to configure, initialize, and run a sweep.
How to get started
Depending on your use case, explore the following resources to get started with W&B Sweeps:- Read through the sweeps walkthrough for a step-by-step outline of the W&B Python SDK commands to use to define a sweep configuration, initialize a sweep, and start a sweep.
- Explore this chapter to learn how to:
- Explore a curated list of Sweep experiments that explore hyperparameter optimization with W&B Sweeps. Results are stored in W&B Reports.