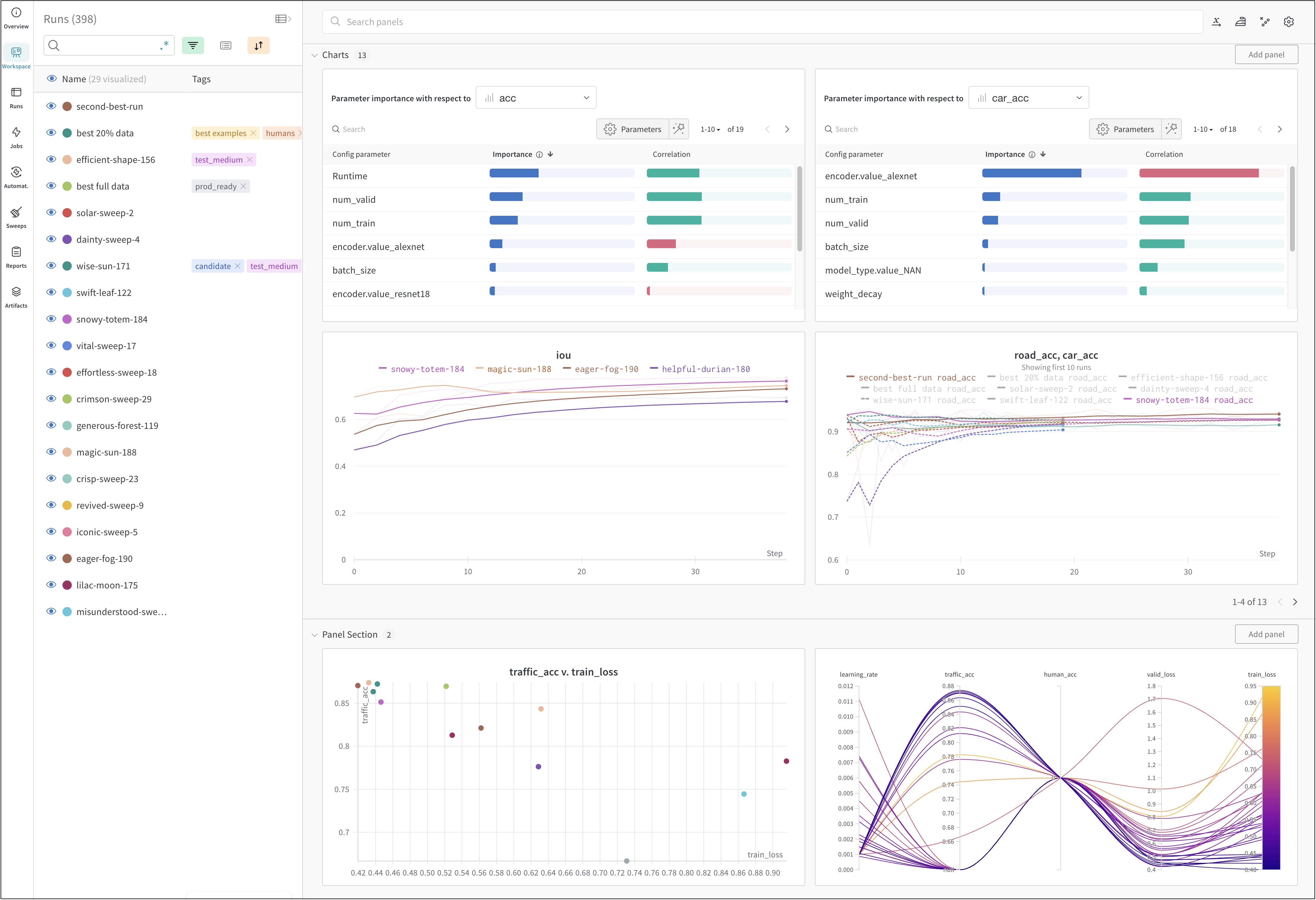
How it works
Track a machine learning experiment with a few lines of code:- Create a W&B Run.
- Store a dictionary of hyperparameters, such as learning rate or model type, into your configuration (
wandb.Run.config). - Log metrics (
wandb.Run.log()) over time in a training loop, such as accuracy and loss. - Save outputs of a run, like the model weights or a table of predictions.
Get started
Depending on your use case, explore the following resources to get started with W&B Experiments:- Read the W&B Quickstart for a step-by-step outline of the W&B Python SDK commands you could use to create, track, and use a dataset artifact.
- Explore this chapter to learn how to:
- Create an experiment
- Configure experiments
- Log data from experiments
- View results from experiments
- Explore the W&B Python Library within the W&B API Reference Guide.