Il s’agit d’un notebook interactif. Vous pouvez l’exécuter localement ou utiliser les liens suivants :
Pourquoi utiliser Weave
- Suivre votre pipeline LLM : consigner les entrées, les sorties et les étapes intermédiaires de votre processus de génération de code.
- Évaluer les sorties du LLM : créer et comparer des évaluations de votre code généré à l’aide d’outils de débogage et de visualisations.
Configurez l’environnement
Weave suit automatiquement les appels à l’API OpenAI, y compris les entrées, les sorties et les métadonnées. Vous n’avez pas besoin d’ajouter de code de journalisation supplémentaire pour vos interactions avec OpenAI. Weave s’en charge en arrière-plan.
Sorties structurées et modèles Pydantic
- Sécurité des types : en définissant des modèles Pydantic pour les sorties attendues, nous appliquons une structure stricte au code généré, aux exécutants de programme et aux tests unitaires.
- Analyse simplifiée : le mode de sortie structurée nous permet d’interpréter directement la réponse du modèle dans les modèles Pydantic prédéfinis, ce qui réduit le besoin de post-traitements complexes.
- Fiabilité accrue : en spécifiant le format exact attendu, nous réduisons le risque d’obtenir des sorties inattendues ou mal formées du modèle de langage.
Implémenter un formateur de code
CodeFormatter à l’aide des opérations Weave. Ce formateur applique des règles de linting et de style au code généré, au runner du programme et aux tests unitaires.
CodeFormatter fournit plusieurs opérations Weave pour nettoyer et mettre en forme le code généré :
- Remplacer les sauts de ligne échappés par de vrais sauts de ligne.
- Supprimer les imports et les variables inutilisés.
- Trier les imports.
- Appliquer le formatage conforme à la PEP 8.
- Ajouter les imports manquants.
Définir le CodeGenerationPipeline
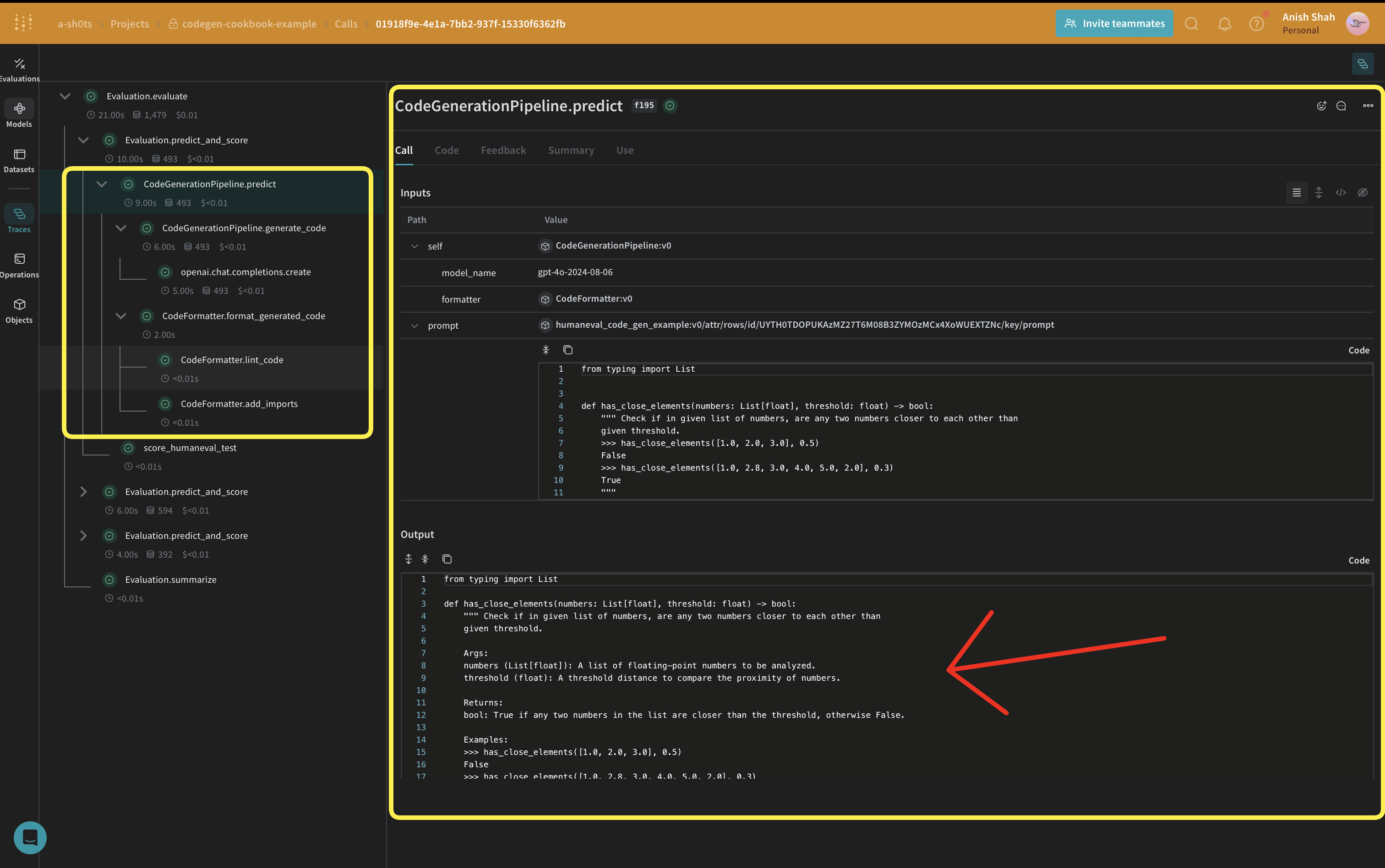
weave.Model afin que le modèle soit automatiquement versionné lorsqu’il est modifié. Le model_name est conservé comme attribut afin que vous puissiez tester différentes valeurs, voir les différences et les comparer dans Weave. Les appels de fonction sont suivis avec @weave.op afin que les entrées et les sorties soient enregistrées pour faciliter le suivi des erreurs et le débogage.
CodeGenerationPipeline encapsule la logique de génération de code sous forme de modèle Weave, ce qui offre plusieurs avantages :
- Suivi automatique des expériences : Weave capture les entrées, les sorties et les paramètres pour chaque run du modèle.
- Gestion des versions : Les modifications apportées aux attributs ou au code du modèle sont automatiquement versionnées, créant un historique de l’évolution de votre pipeline de génération de code au fil du temps.
- Reproductibilité : La gestion des versions et le suivi vous permettent de reproduire tout résultat ou toute configuration antérieure de votre pipeline de génération de code.
- Gestion des hyperparamètres : Les attributs du modèle (comme
model_name) sont définis et suivis d’un run à l’autre, ce qui facilite l’expérimentation. - Intégration à l’écosystème Weave : L’utilisation de
weave.Modelrelie votre pipeline à d’autres outils Weave, comme les évaluations et les fonctionnalités de serving.
Implémenter des métriques d’évaluation
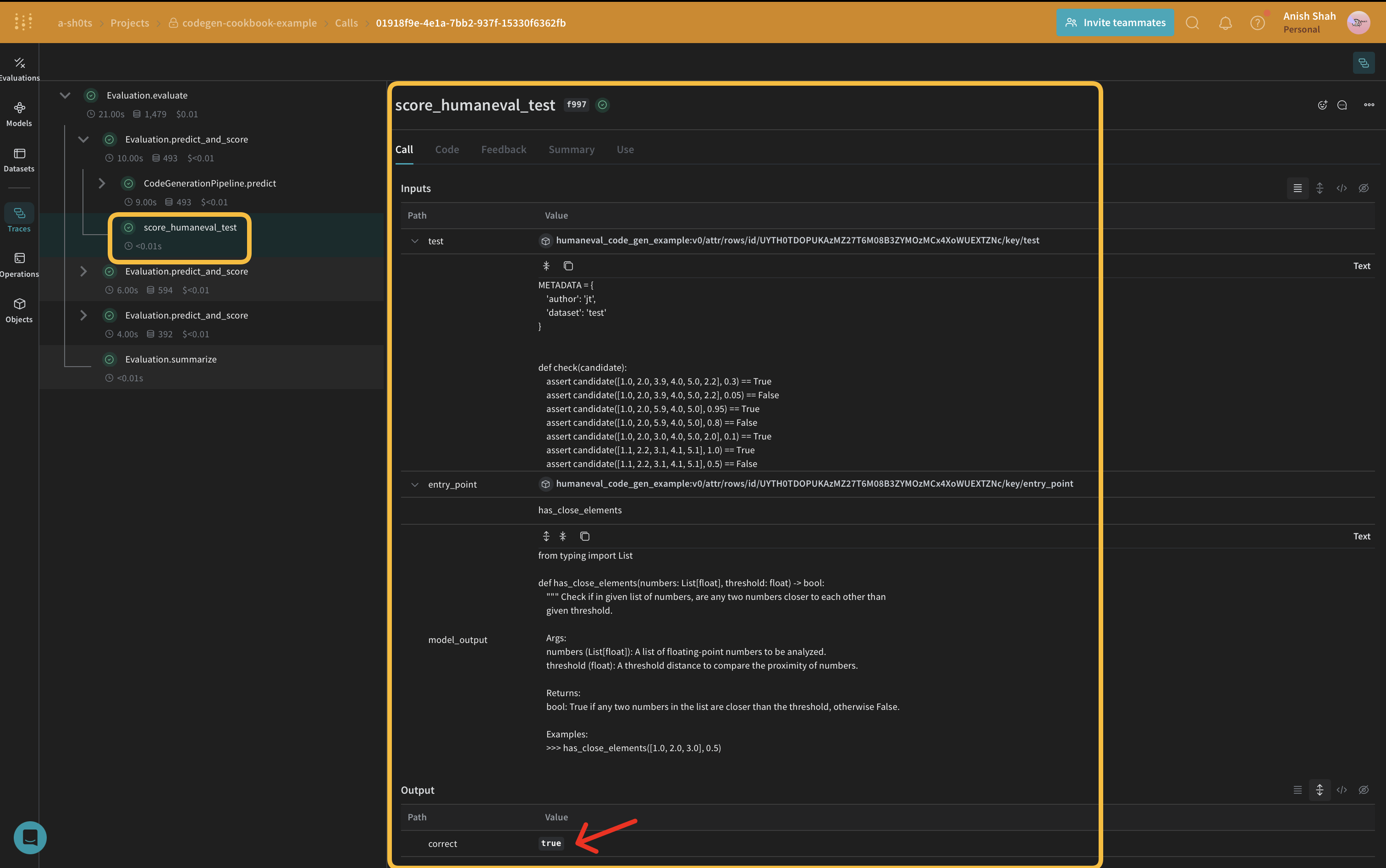
weave.Scorer. Cette opération exécute score sur chaque model_output du jeu de données. model_output provient de la sortie de la fonction predict de weave.Model. Le prompt est extrait du jeu de données human-eval.
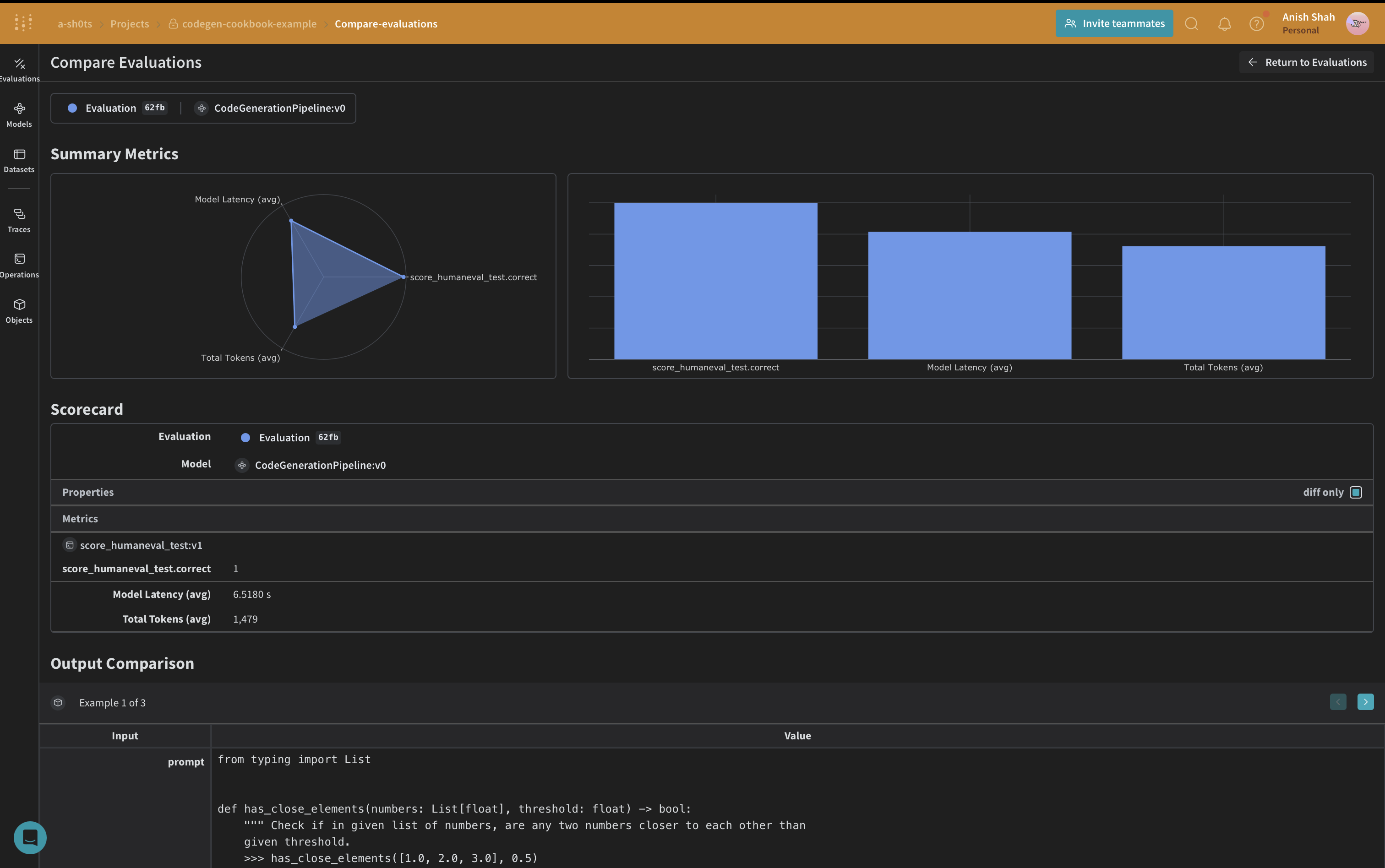
Créer un jeu de données Weave et effectuer une évaluation
Conclusion
- Créer des opérations Weave pour chaque étape du processus de génération de code.
- Encapsuler le pipeline dans un modèle Weave afin de rationaliser le suivi et l’évaluation.
- Implémenter des métriques d’évaluation personnalisées à l’aide d’opérations Weave.
- Créer un jeu de données et lancer une évaluation du pipeline.