Tous les exemples de code présentés sur cette page sont en Python.
weave.init() et utilisez la bibliothèque comme d’habitude.
Avant de commencer, vous devez installer les bibliothèques requises et configurer l’accès au fournisseur de LLM de votre choix.
-
Avant de pouvoir utiliser Smolagents avec Weave, vous devez installer les bibliothèques requises ou les mettre à jour vers leur dernière version. La commande suivante installe ou met à jour
smolagents, openai et weave, et masque la sortie :
-
Smolagents prend en charge plusieurs fournisseurs de LLM, comme OpenAI, Hugging Face Transformers et Anthropic. Définissez la clé API du fournisseur de votre choix afin que Smolagents puisse s’authentifier lors de l’appel du modèle. Définissez la variable d’environnement correspondante :
Cette section montre comment Weave capture automatiquement les traces d’un flux de travail Smolagents de base.
Stocker les traces des applications de modèles de langage dans un emplacement central est essentiel, aussi bien pendant le développement qu’en production. Ces traces facilitent le débogage et servent de jeux de données pour améliorer votre application.
Weave capture automatiquement les traces pour Smolagents. Pour commencer le suivi, initialisez Weave en appelant weave.init(), puis utilisez la bibliothèque comme d’habitude.
L’exemple suivant montre comment journaliser les appels d’Inférence d’un agent LLM utilisant des outils avec Weave. Dans ce scénario :
- Vous définissez un modèle de langage (le
gpt-4o d’OpenAI) à l’aide de OpenAIServerModel de Smolagents.
- Vous configurez un outil de recherche (
DuckDuckGoSearchTool) que l’agent peut invoquer si nécessaire.
- Vous créez un
ToolCallingAgent en lui passant l’outil et le modèle.
- Vous exécutez une requête via l’agent, ce qui déclenche l’outil de recherche.
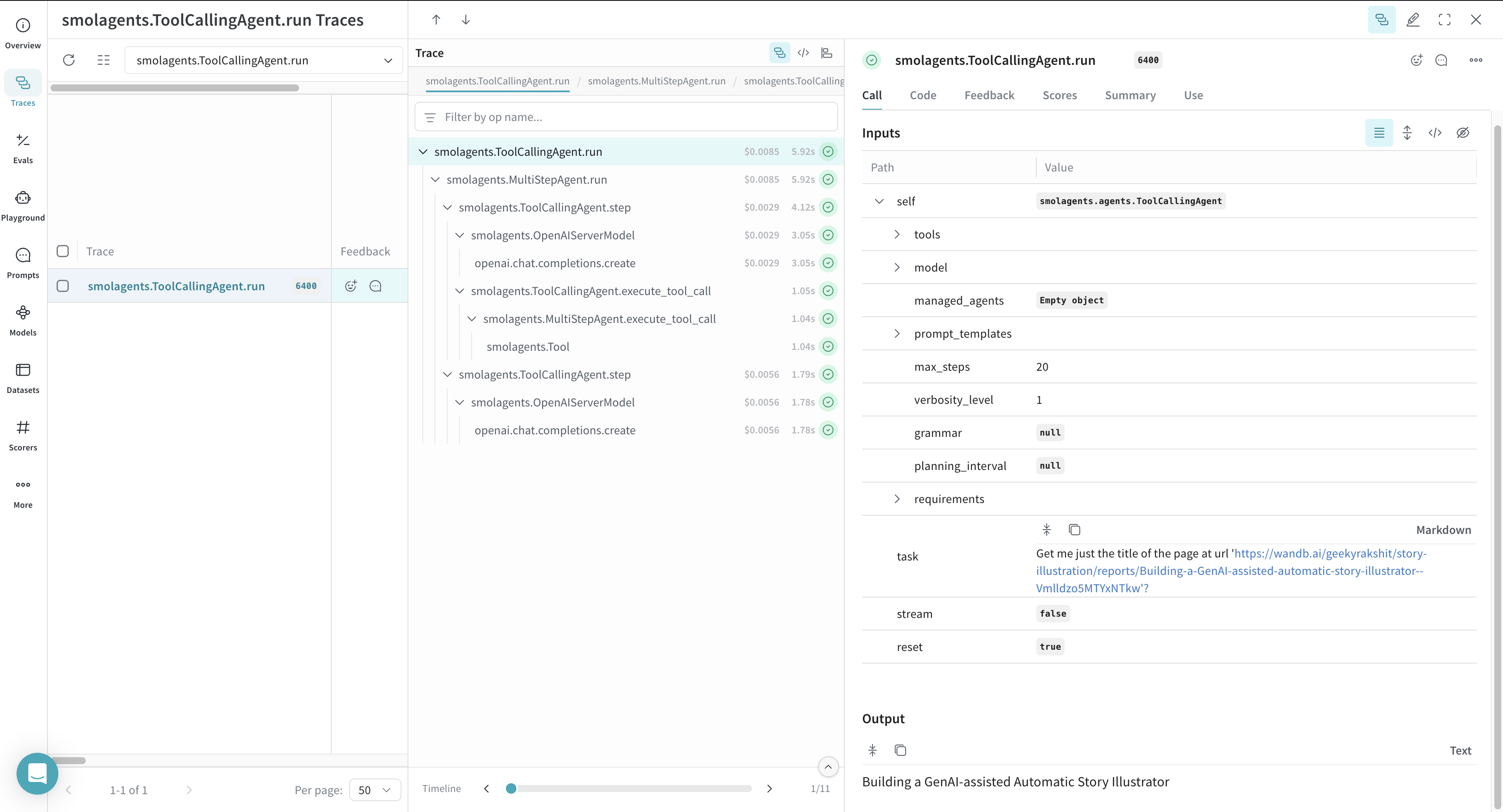
- Weave journalise chaque appel de fonction et de modèle, puis les rend disponibles pour inspection dans son interface web.
Une fois l’exemple de code exécuté, accédez au tableau de bord de votre projet Weave pour consulter les traces.
En plus des outils intégrés, vous pouvez étendre vos agents avec des outils personnalisés, et Weave peut également tracer ces appels.
Vous pouvez déclarer des outils personnalisés pour vos flux de travail agentiques en décorant une fonction avec @tool de smolagents ou en héritant de la classe smolagents.Tool.
Weave assure automatiquement le suivi des appels d’outil personnalisés pour vos flux de travail smolagents. L’exemple suivant montre comment journaliser un appel d’outil personnalisé smolagents avec Weave :
- Vous définissez une fonction personnalisée
get_weather et la décorez avec @tool de Smolagents, ce qui permet à l’agent de l’appeler dans le cadre de son processus de raisonnement.
- La fonction accepte un emplacement ainsi qu’un indicateur facultatif pour renvoyer la température en Celsius.
- Vous instanciez un modèle de langage à l’aide de
OpenAIServerModel.
- Vous créez un
ToolCallingAgent avec l’outil personnalisé et le modèle.
- Lorsque l’agent exécute la requête, il sélectionne et appelle l’outil
get_weather.
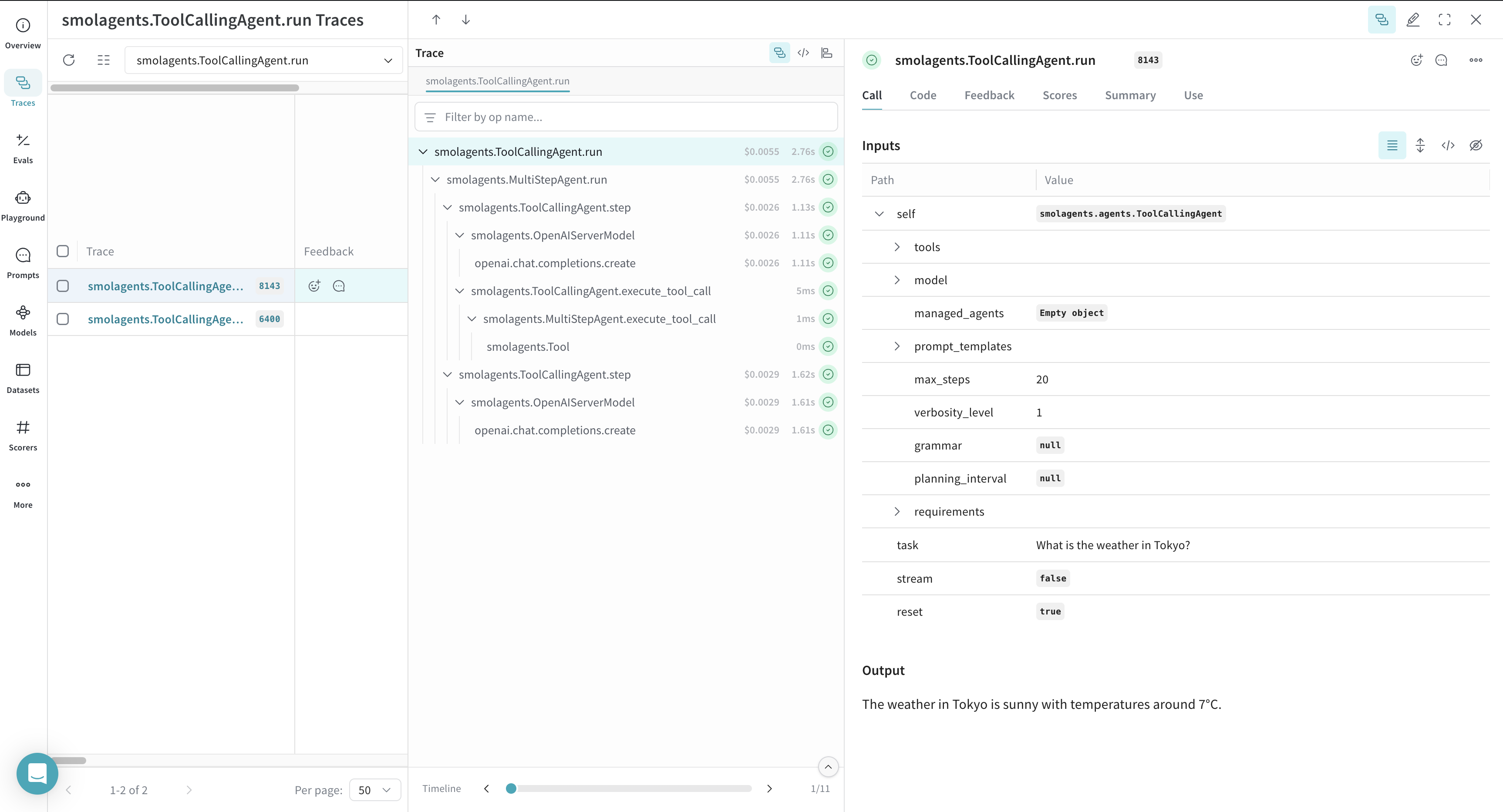
- Weave journalise à la fois l’inférence du modèle et l’appel à l’outil personnalisé, y compris les arguments et les valeurs de retour.
Après avoir exécuté l’exemple de code, accédez au tableau de bord de votre projet Weave pour consulter les traces.