Deploy a model artifact from W&B to a NVIDIA NeMo Inference Microservice. To do this, use W&B Launch. W&B Launch converts model artifacts to NVIDIA NeMo Model and deploys to a running NIM/Triton server.
W&B Launch currently accepts the following compatible model types:
- Llama2
- StarCoder
- NV-GPT (coming soon)
Deployment time varies by model and machine type. The base Llama2-7b config takes about 1 minute on Google Cloud’s a2-ultragpu-1g.
Quickstart
-
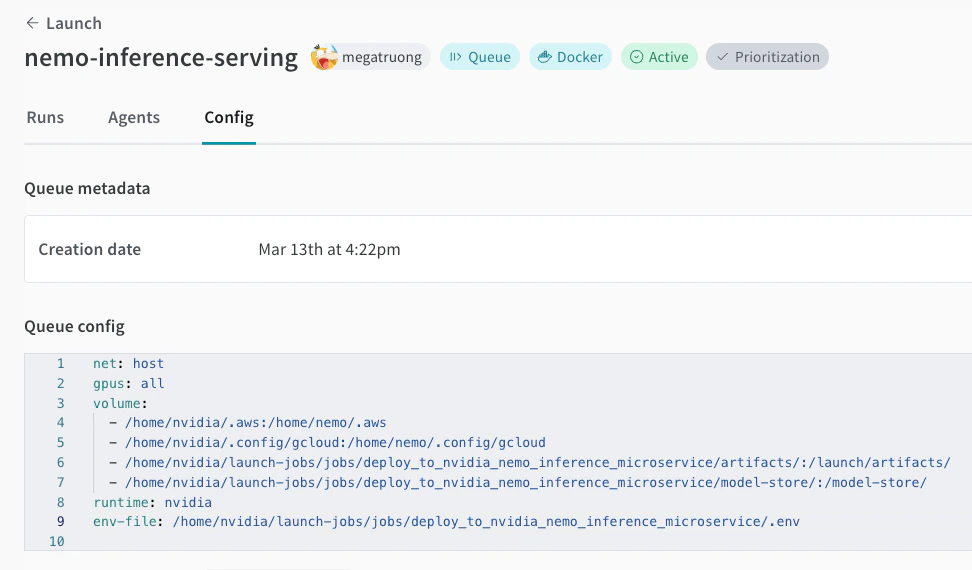
Create a launch queue if you don’t have one already. See an example queue config below.
net: host
gpus: all # can be a specific set of GPUs or `all` to use everything
runtime: nvidia # also requires nvidia container runtime
volume:
- model-store:/model-store/
-
Create this job in your project:
wandb job create -n "deploy-to-nvidia-nemo-inference-microservice" \
-e $ENTITY \
-p $PROJECT \
-E jobs/deploy_to_nvidia_nemo_inference_microservice/job.py \
-g andrew/nim-updates \
git https://github.com/wandb/launch-jobs
-
Launch an agent on your GPU machine:
wandb launch-agent -e $ENTITY -p $PROJECT -q $QUEUE
-
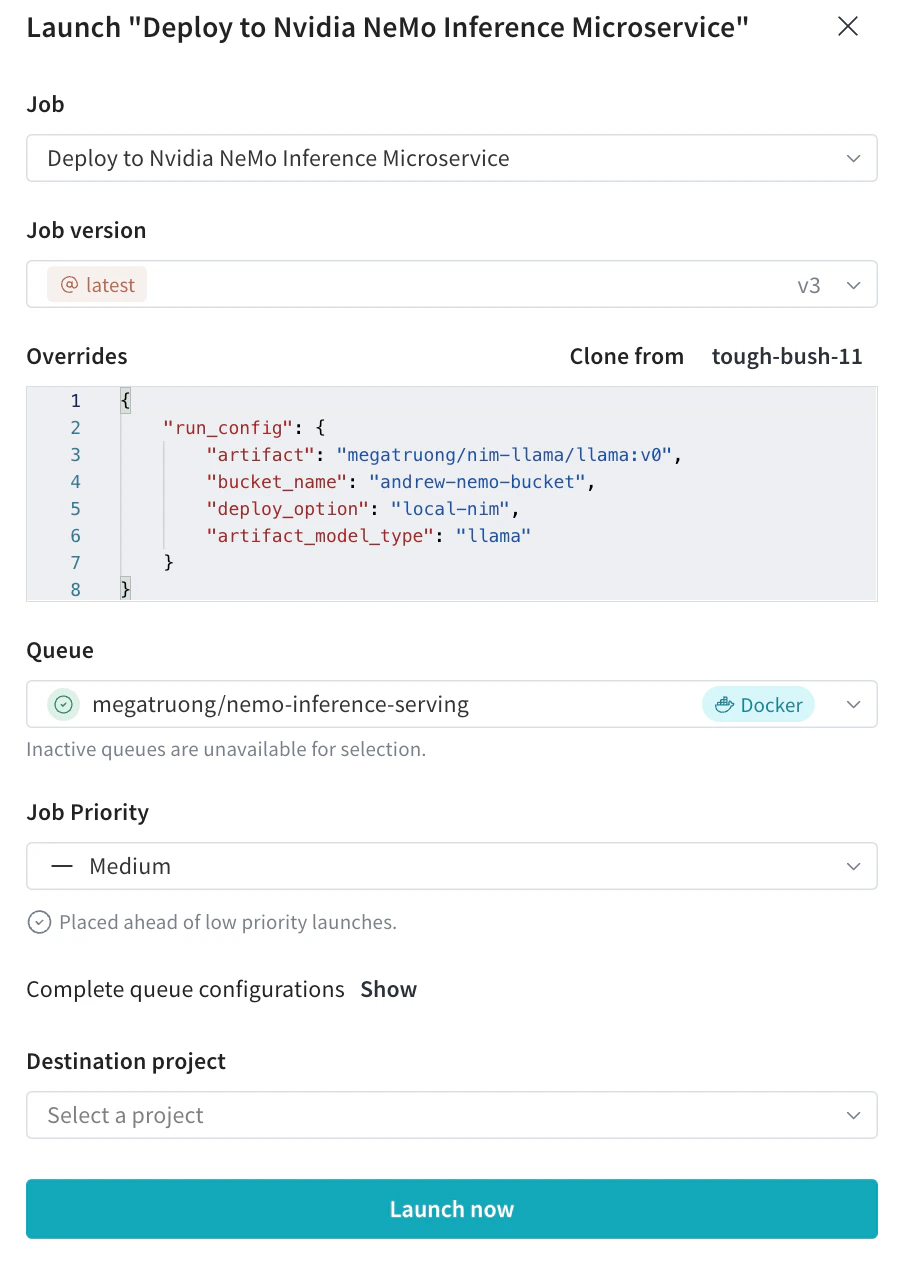
Submit the deployment launch job with your desired configs from the Launch UI
- You can also submit via the CLI:
wandb launch -d gcr.io/playground-111/deploy-to-nemo:latest \
-e $ENTITY \
-p $PROJECT \
-q $QUEUE \
-c $CONFIG_JSON_FNAME
-
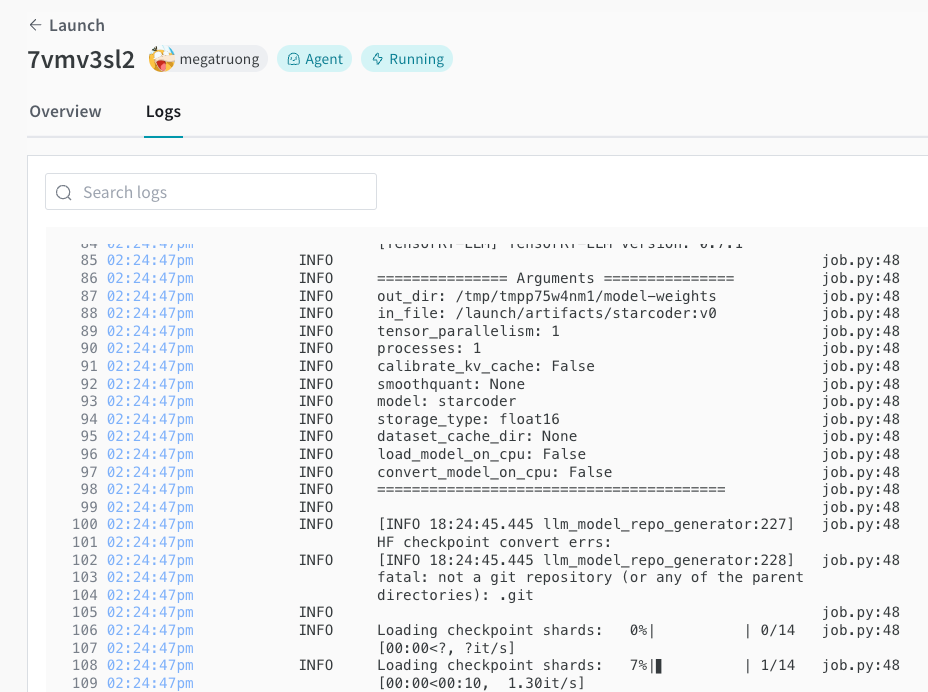
You can track the deployment process in the Launch UI.
-
Once complete, you can immediately curl the endpoint to test the model. The model name is always
ensemble.
#!/bin/bash
curl -X POST "http://0.0.0.0:9999/v1/completions" \
-H "accept: application/json" \
-H "Content-Type: application/json" \
-d '{
"model": "ensemble",
"prompt": "Tell me a joke",
"max_tokens": 256,
"temperature": 0.5,
"n": 1,
"stream": false,
"stop": "string",
"frequency_penalty": 0.0
}'