- 実験を分析して、パターンやインサイトを見つける。
- 新しいアイデアを試すために実験や Sweeps を実行する。
- 試すべきハイパーパラメーターの推奨など、次のステップを提案する。
- データを可視化するためのプロットやパネルを作成する。
- インサイトをチームと共有するために、保存済みビューや Reports を作成する。
- 任意の project で、ページ右上の青い丸をクリックします。
- チャットウィンドウで、質問またはリクエストを入力します。何を聞けばよいかわからない場合は、提案されたプロンプトを選択します。
- チャットウィンドウ右下にある、上向き矢印の Send ボタンをクリックします。
- Thinking ステップは、ARIA が質問にどのように取り組むかを要約します。
- shell ステップは、パネルの作成、Runs のフィルタリング、Python スクリプトの作成や実行など、ARIA がアクションを実行したときに表示されます。
チャット例
ARIA の推奨に基づいて Experiments を実行する
ARIA の推奨に基づいて Experiments を実行する
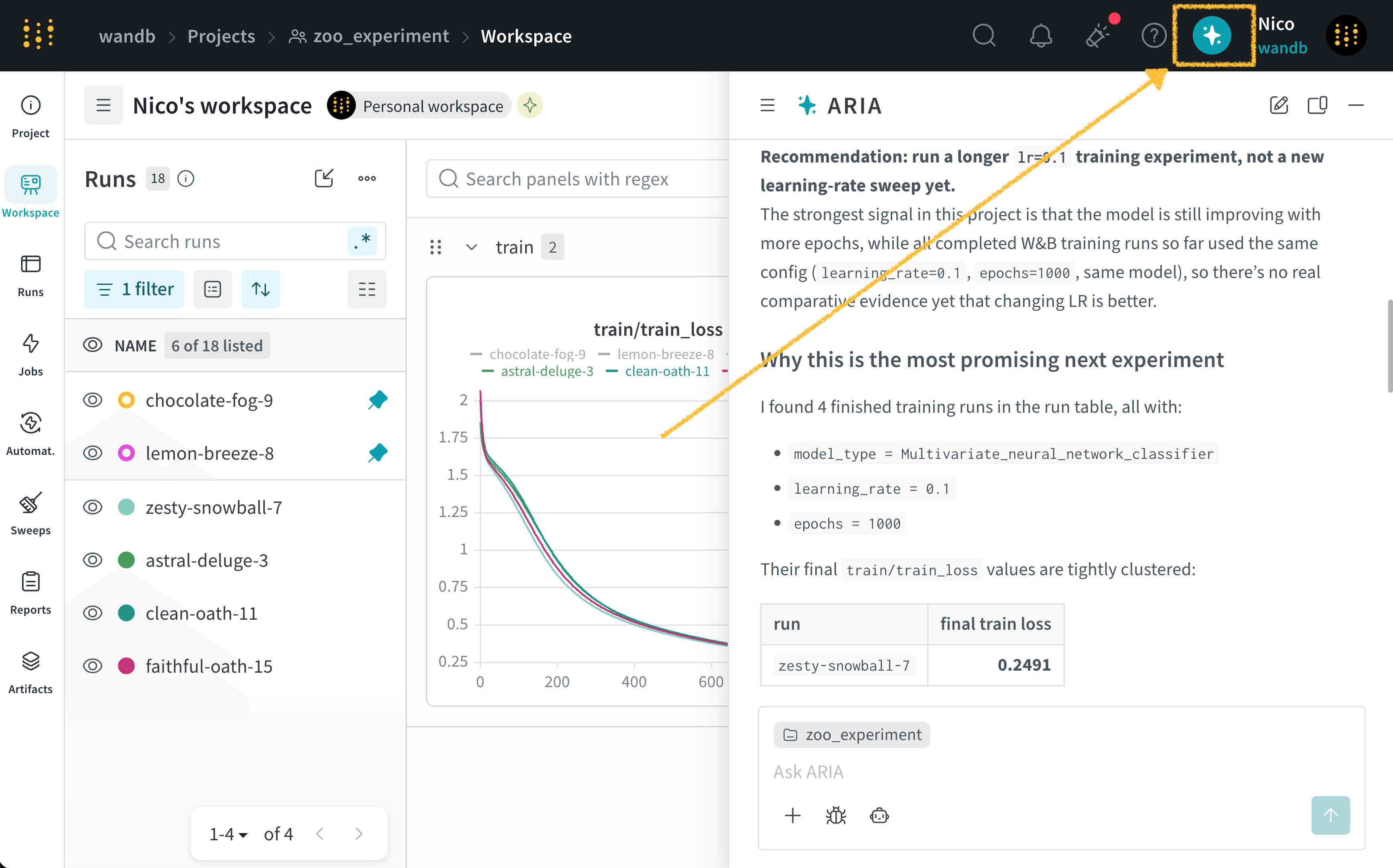
一連の Experiments を終えたばかりの ML Engineer だとします。モデルのパフォーマンスを向上させるには、次に何をすべきかを知りたいと考えています。そのために、Runs をログした project にアクセスします。ARIA を開いて、次のように質問します。以下は、この質問に対する ARIA の応答例です。まず、ARIA はこの質問にどうアプローチするかを判断するために推論ステップを実行します。簡潔にするため、以下には ARIA の推論の一部のみを示します。ARIA の推奨に同意したので、experiment を実行するよう ARIA に依頼します。ARIA は W&B Launch を使用して、サンドボックス環境で experiment を実行します。次の画像は、experiment の実行完了後の ARIA の応答を示しています。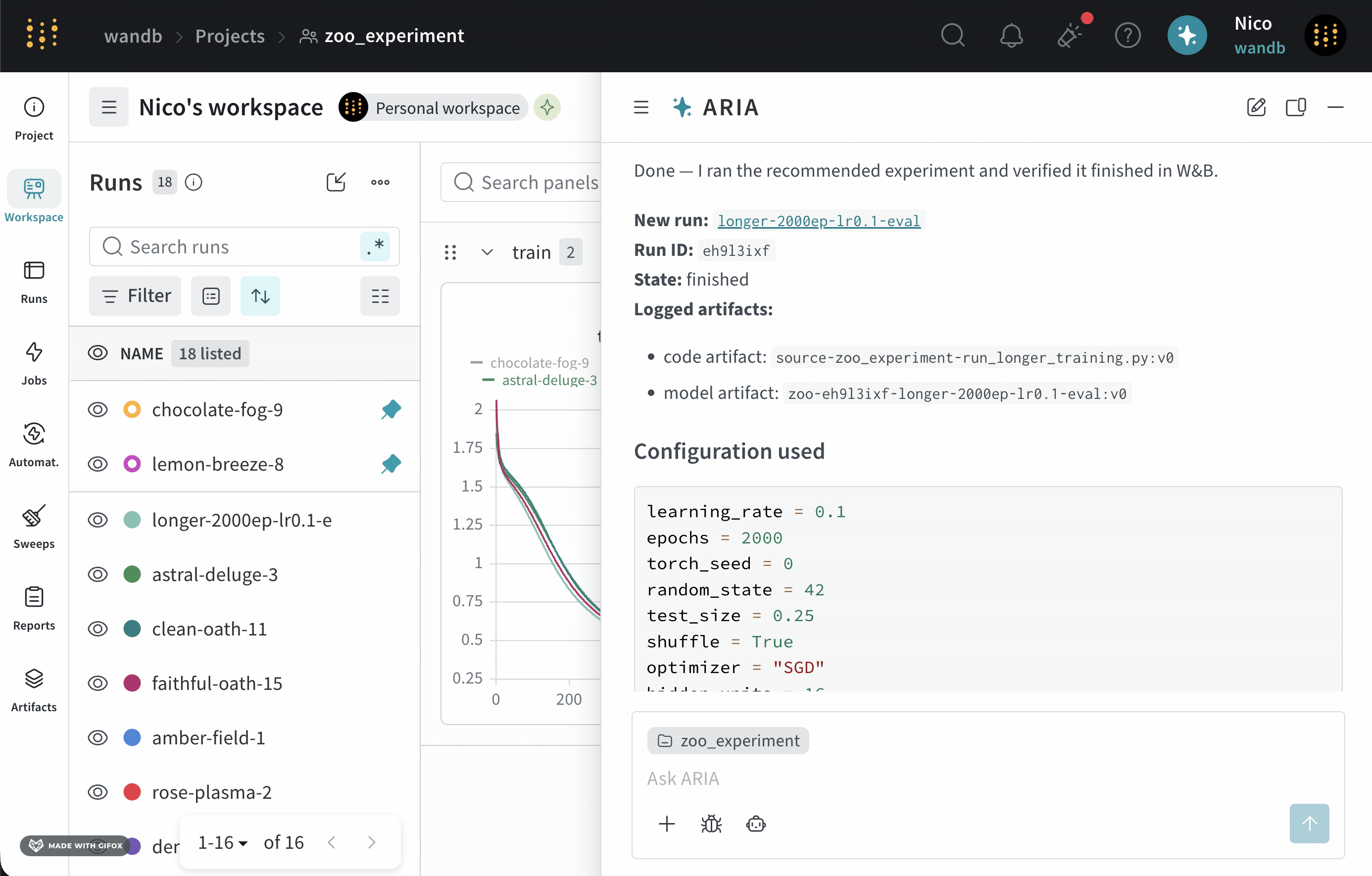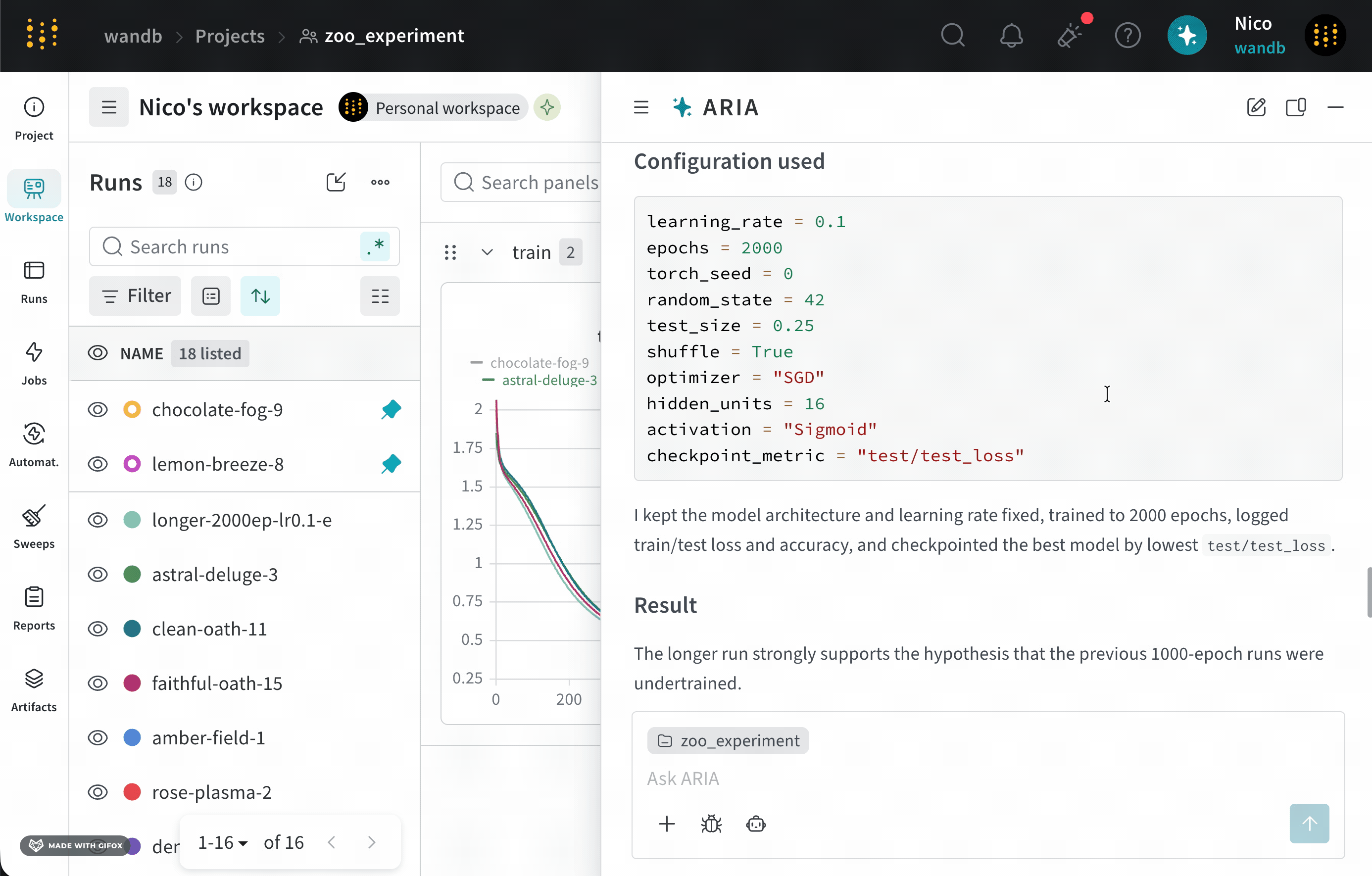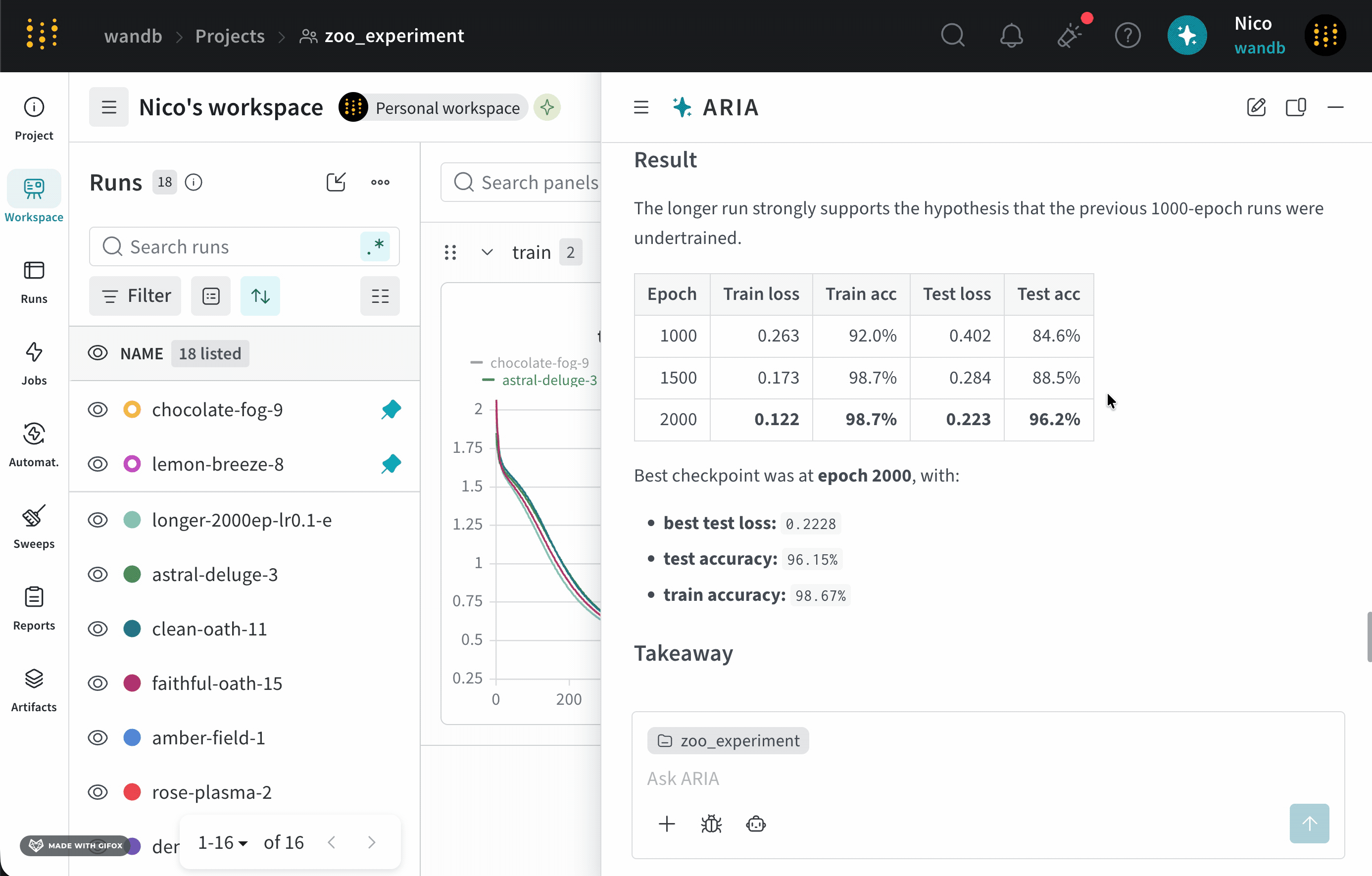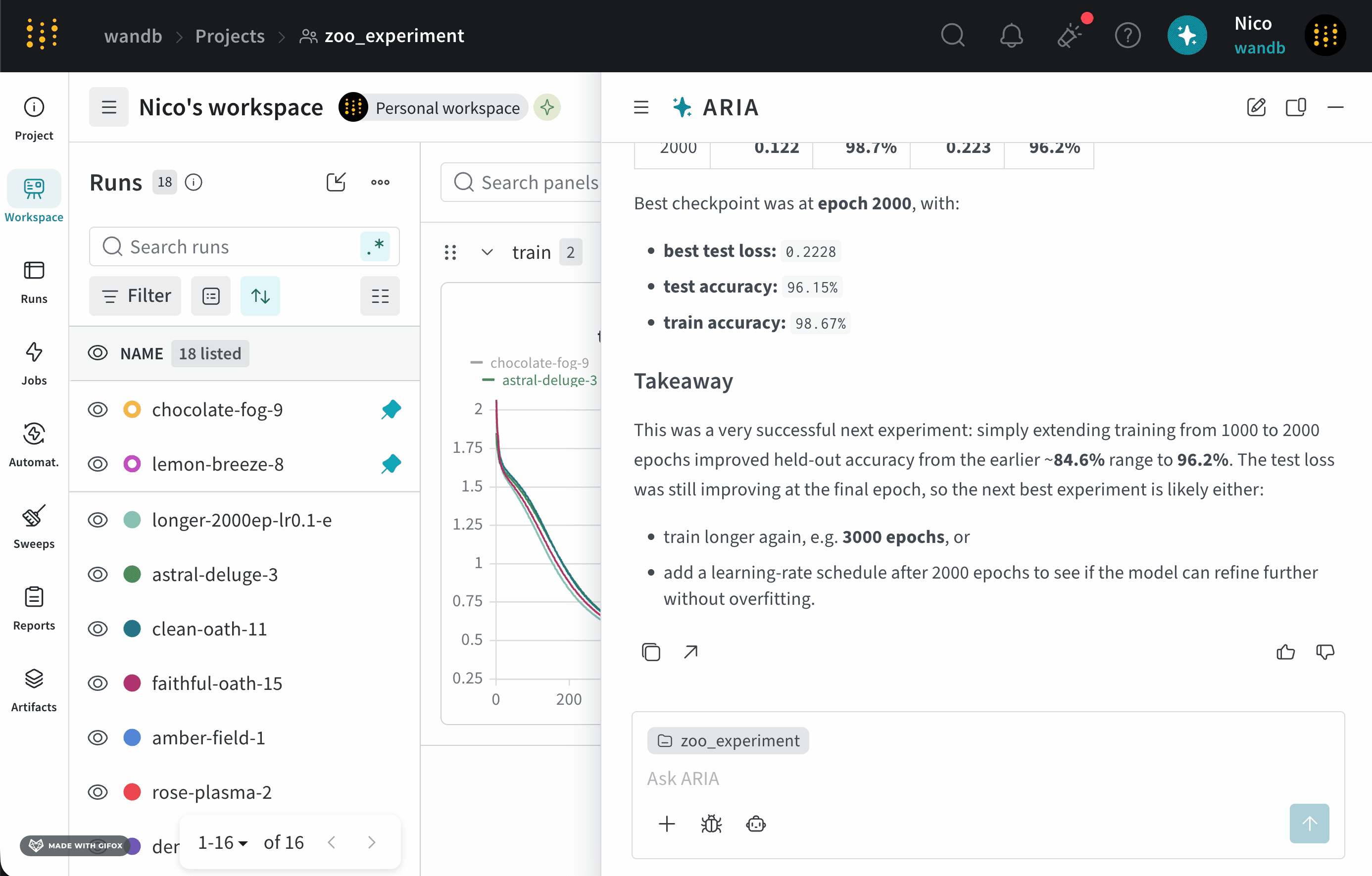
ユーザープロンプト
ARIA の推論ステップ
ユーザープロンプト
実験からインサイトを得る
実験からインサイトを得る
新しいモデルについて一連の run を完了したばかりの ML Engineer だとします。モデルのパフォーマンスを把握し、潜在的な問題を特定して、次に取るべき steps を決めたいと考えています。そのために、run をログした project にアクセスします。ARIA を開いて、次のように尋ねます。以下は、この質問に対して ARIA がどのように応答するかの例です。まず、ARIA はこの質問にどうアプローチするかを判断するために推論ステップを行います。ARIA は、この質問に答えるには Runs 全体のデータを分析する必要があると判断します。そのために、ARIA は以前にログされた Runs を W&B Python SDK を使ってクエリし、データ内のパターンを特定する Python スクリプト (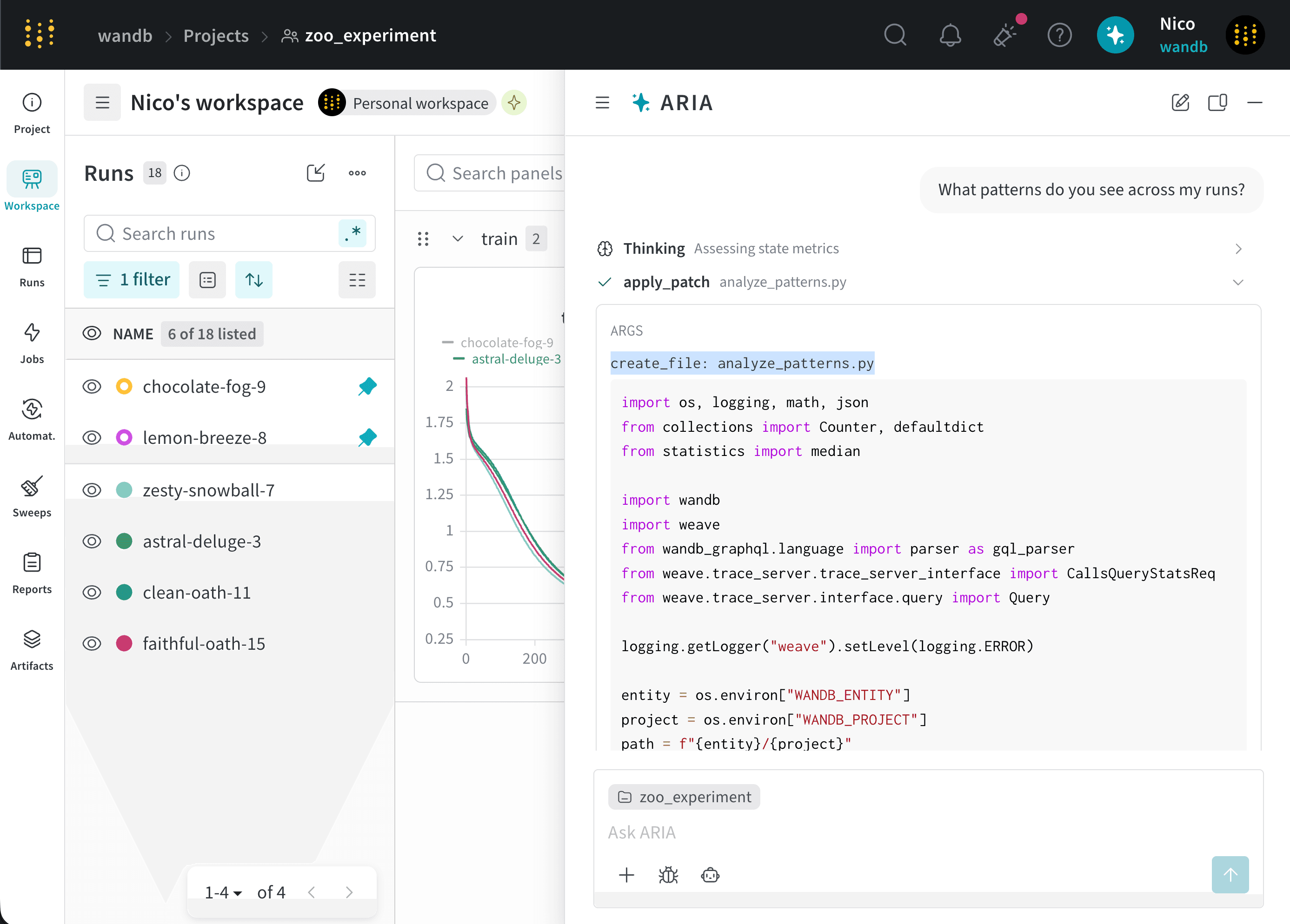
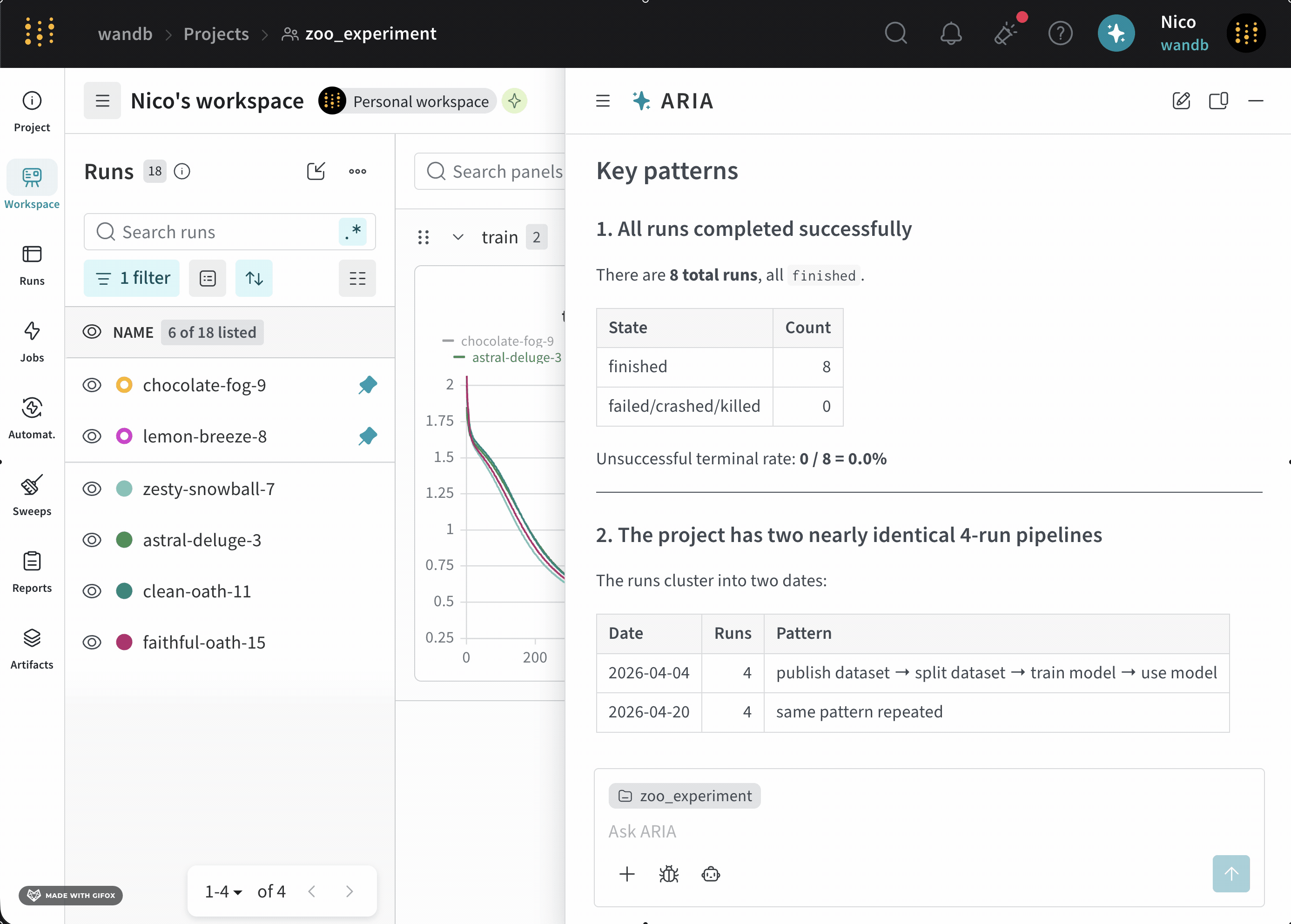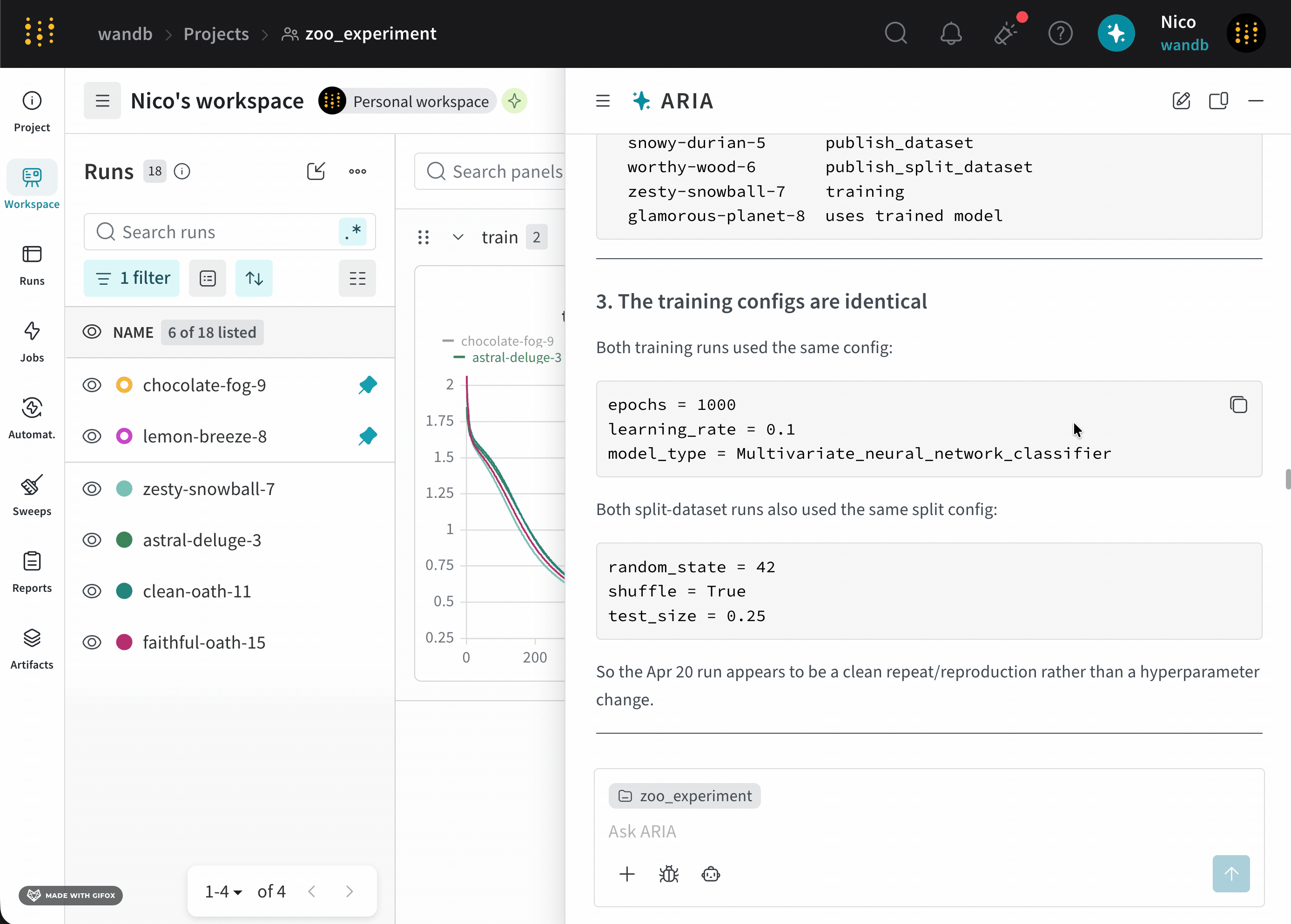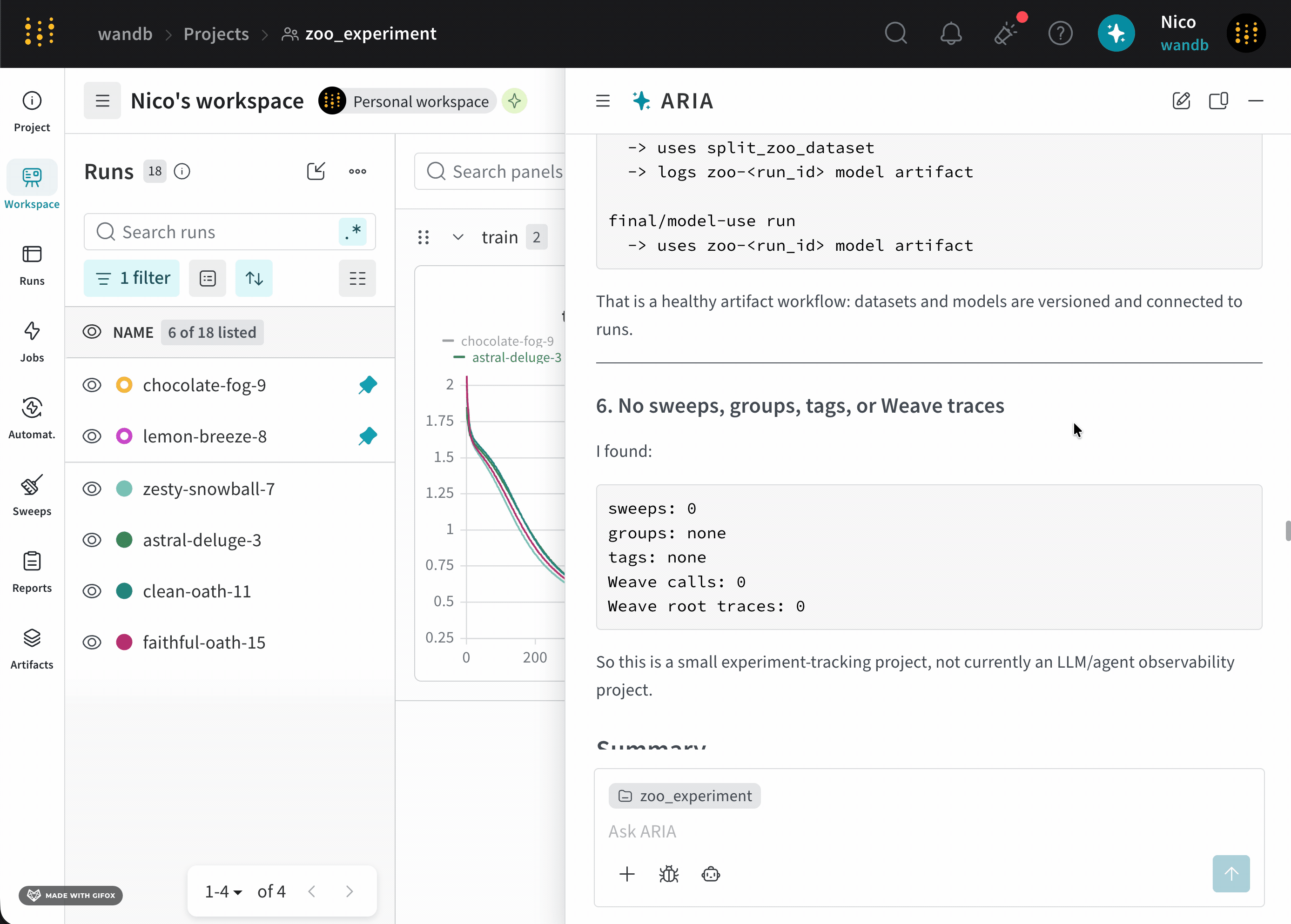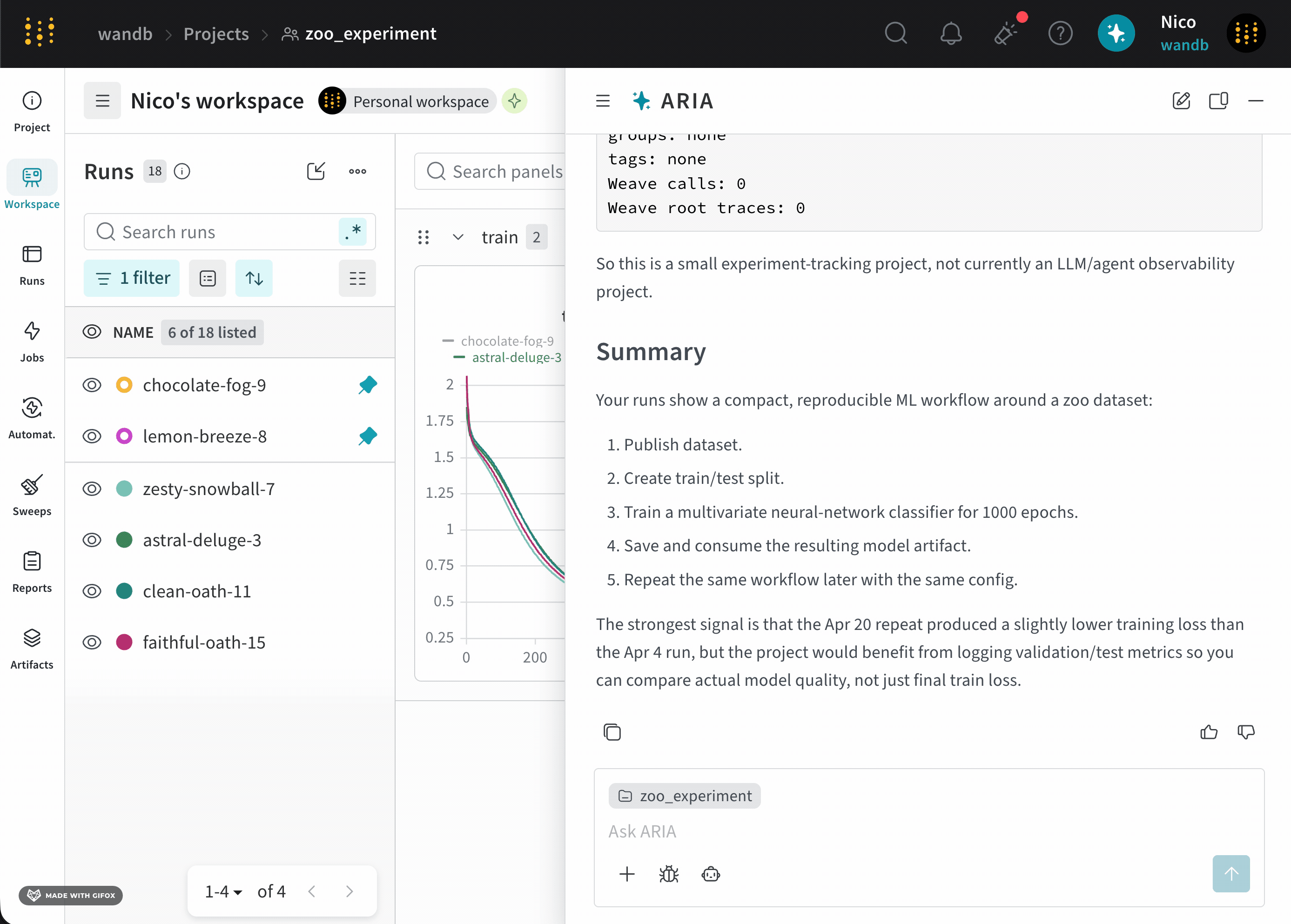
ユーザー プロンプト
ARIA の推論ステップ
analyze_patterns.py) を作成します。スクリプトが生成されると、ARIA はそれをサンドボックス環境内で実行します。validation/test メトリクスがログされていないことを特定し、モデルのパフォーマンスをよりよく理解するために、今後の Runs ではそれらのメトリクスをログすることを推奨しました。次の step として、検証メトリクスがログされる experiment の設定を ARIA に手伝ってもらうことができます。たとえば、ARIA に次のように尋ねることができます。ユーザー プロンプト
ハイパーパラメーター調整の推奨事項を得る
ハイパーパラメーター調整の推奨事項を得る
新しいモデルについて一連の run を完了したばかりの ML Engineer だとします。モデルのパフォーマンスを把握し、今後の Runs でモデルのパフォーマンスを改善するための推奨事項を得たいと考えています。そこで、ハイパーパラメーター調整に関する推奨事項を ARIA に求めることにします。ARIA に次のように尋ねることができます。ARIA は、次のような推論ステップで応答する可能性があります。ARIA は、ハイパーパラメーター調整の推奨事項を提供するために、以前の Runs で使用されたハイパーパラメーターと、それらがトレーニング損失にどう関係しているかを分析する必要があると判断します。ARIA は、指定された project ではすべての Runs で学習率 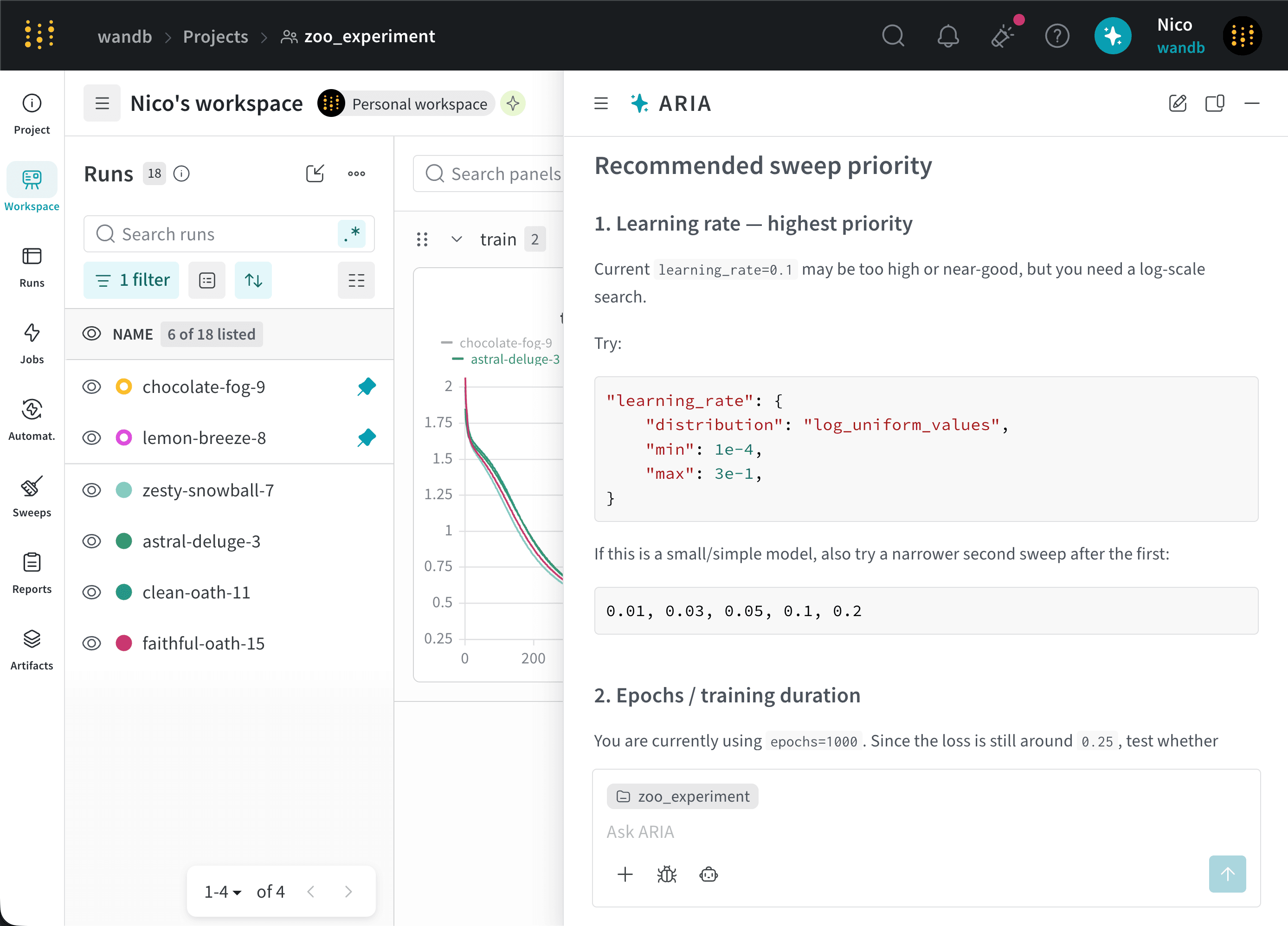
ユーザー プロンプト
ARIA の推論ステップ
0.01 が使われていたことを特定します。これらのインサイトに基づき、ARIA は、今後の Runs ではモデルのパフォーマンス改善に役立つか確認するため、0.001 などのより低い学習率を試すことを推奨します。ARIA はまた、SGD オプティマイザーを使用している Runs についても特定します。このインサイトに基づき、ARIA は、今後の Runs ではモデルのパフォーマンス改善に役立つか確認するため、Adam (Adaptive Moment Estimation) などの別のオプティマイザーを試すことを推奨します。次の画像は、ハイパーパラメーター調整に関する推奨事項を含む ARIA の応答の一部を示しています。チームと共有するための report を作成する
チームと共有するための report を作成する
project の Runs を分析していて、データ内に興味深いパターンを見つけたデータサイエンティストだとします。これらの知見を、わかりやすい形式でチームと共有したいと考えています。そこで、W&B Report の作成を ARIA に手伝ってもらうことにします。これを行うには、ARIA を開いて次のように依頼します。ARIA は、次のような推論ステップを返すことがあります。ARIA は、データから見つけた知見を要約する W&B Report を作成する必要があると判断します。推論プロセスの一環として、関連するデータと知見を含む report を W&B SDK で作成する Python スクリプトを生成します。ARIA はこのスクリプトをサンドボックス環境で実行し、その結果、project に W&B Report が作成されます。次の画像は、ARIA がサンドボックス環境で W&B Report を作成し、その後チャットで report へのリンクを返す様子を示しています。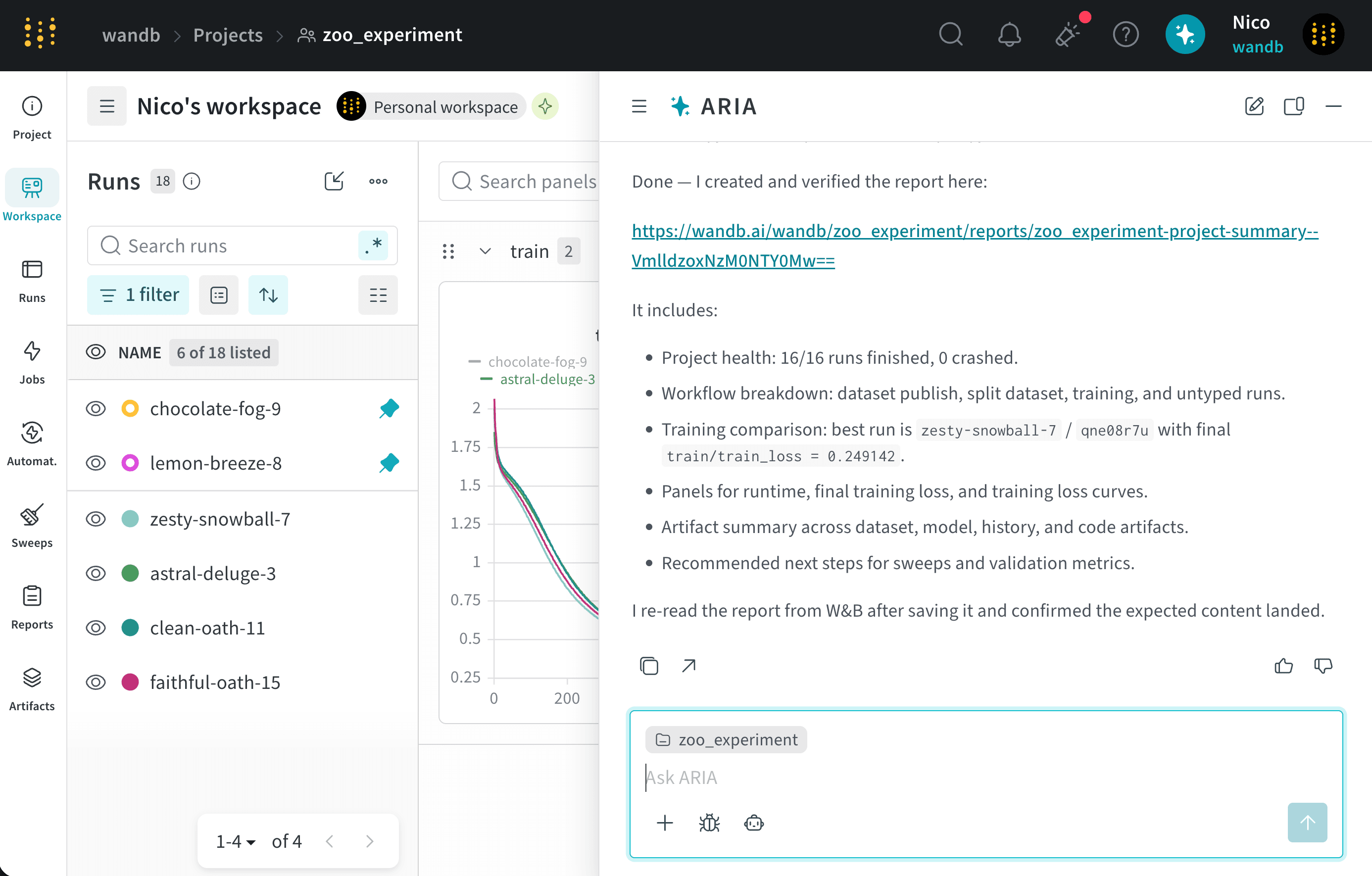
ユーザー プロンプト
ARIA の推論ステップ
内部では、ARIA は Workspaces and Reports API を使用して W&B Report を作成します。