Try in Colab
数行で次世代のロギング
すぐに動作するコードを試したい方は、このGoogle Colabをチェックしてください。
始める: 実験をトラックする
サインアップしてAPIキーを作成する
APIキーは、あなたのマシンをW&Bに認証します。ユーザープロフィールからAPIキーを生成できます。よりスムーズな方法として、https://wandb.ai/authorizeで直接APIキーを生成することができます。表示されたAPIキーをコピーして、パスワードマネージャーのような安全な場所に保存してください。
- 右上のユーザーアイコンをクリックします。
- ユーザー設定を選択し、APIキーセクションまでスクロールします。
- Revealをクリックします。表示されたAPIキーをコピーします。APIキーを非表示にするには、ページを再読み込みします。
wandbライブラリをインストールしてログインする
wandbライブラリをローカルにインストールし、ログインするには:
- Command Line
- Python
- Python notebook
-
WANDB_API_KEY環境変数をAPIキーに設定します。 -
wandbライブラリをインストールしてログインします。
プロジェクトの名前を付ける
W&B Projectは、関連するRunsからログされたすべてのチャート、データ、モデルを保存する場所です。プロジェクト名をつけることで、作業を整理し、1つのプロジェクトに関するすべての情報を一ヶ所にまとめることができます。 プロジェクトにrunを追加するには、単にWANDB_PROJECT 環境変数をプロジェクト名に設定するだけです。WandbCallbackは、このプロジェクト名の環境変数を拾い上げ、runを設定する際にそれを使用します。
- Command Line
- Python
- Python notebook
プロジェクト名は
Trainerを初期化する前に設定することを確認してください。huggingfaceにデフォルト設定されます。
トレーニングRunsをW&Bにログする
これは、コード内またはコマンドラインからトレーニング引数を定義する際の最も重要なステップです。report_toを"wandb"に設定することで、W&Bログを有効にします。
TrainingArgumentsのlogging_steps引数は、トレーニング中にW&Bにトレーニングメトリクスがプッシュされる頻度を制御します。run_name引数を使用して、W&B内でトレーニングrunに名前を付けることもできます。
これで終了です。トレーニング中は、モデルが損失、評価メトリクス、モデルトポロジー、勾配をW&Bにログします。
- Command Line
- Python
TensorFlowを使用していますか? PyTorchの
TrainerをTensorFlowのTFTrainerに置き換えるだけです。モデルのチェックポイントをオンにする
Artifactsを使用すると、最大100GBのモデルやデータセットを無料で保存し、その後Weights & BiasesのRegistryを使用できます。Registryを使用して、モデルを登録し、それらを探索・評価したり、ステージングの準備をしたり、プロダクション環境にデプロイできます。 Hugging FaceモデルのチェックポイントをArtifactsにログするには、WANDB_LOG_MODEL 環境変数を以下のいずれかに設定します:
checkpoint:TrainingArgumentsのargs.save_stepsごとにチェックポイントをアップロードします。end: トレーニング終了時にモデルをアップロードします。またload_best_model_at_endが設定されている場合です。false: モデルをアップロードしません。
- Command Line
- Python
- Python notebook
Trainerは、モデルをW&Bプロジェクトにアップロードします。ログされたモデルチェックポイントはArtifacts UIを通じて表示可能で、完全なモデルリネージを含みます(UIでのモデルチェックポイントの例はこちらをご覧ください here)。
デフォルトでは、
WANDB_LOG_MODELがendに設定されているときはmodel-{run_id}として、WANDB_LOG_MODELがcheckpointに設定されているときはcheckpoint-{run_id}として、モデルがW&B Artifactsに保存されます。しかし、TrainingArgumentsにrun_nameを渡すと、モデルはmodel-{run_name}またはcheckpoint-{run_name}として保存されます。W&B Registry
チェックポイントをArtifactsにログしたら、最良のモデルチェックポイントを登録して、**Registry**でチーム全体に中央集約できます。Registryを使用すると、タスクごとに最良のモデルを整理し、モデルライフサイクルを管理し、機械学習ライフサイクル全体を追跡および監査し、オートメーションダウンストリームアクションを自動化できます。 モデルのアーティファクトをリンクするには、Registryを参照してください。トレーニング中に評価出力を視覚化する
トレーニングや評価中にモデル出力を視覚化することは、モデルがどのようにトレーニングされているかを理解するためにしばしば重要です。 Transformers Trainerのコールバックシステムを使用すると、モデルのテキスト生成出力や他の予測などの役立つデータをW&B Tablesにログできます。 トレーニング中にW&B Tableに評価出力をログする方法については、以下の**カスタムログセクション**をご覧ください: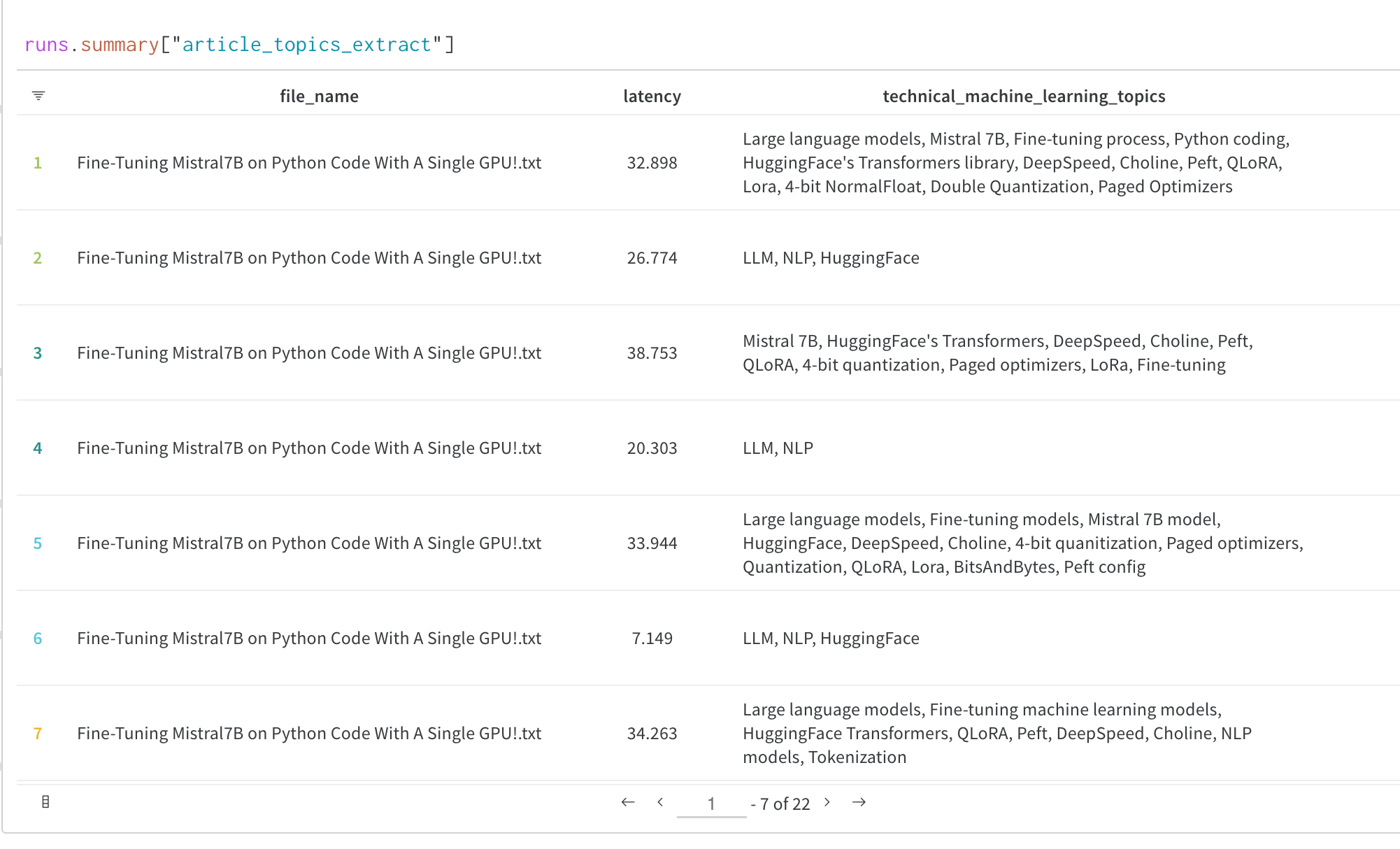
W&B Runを終了させる(ノートブックのみ)
トレーニングがPythonスクリプトでカプセル化されている場合、スクリプトが終了するとW&B runも終了します。 JupyterまたはGoogle Colabノートブックを使用している場合は、トレーニングが終了したことをwandb.finish()を呼び出して知らせる必要があります。
結果を視覚化する
トレーニング結果をログしたら、W&B Dashboardで結果を動的に探索できます。複数のrunを一度に比較したり、興味深い知見にズームインしたり、柔軟でインタラクティブな可視化を用いて複雑なデータから洞察を引き出すのが簡単です。高度な機能とFAQ
最良のモデルを保存する方法は?
Trainerにload_best_model_at_end=TrueのTrainingArgumentsを渡すと、W&Bは最良のパフォーマンスを示すモデルチェックポイントをアーティファクトに保存します。
モデルチェックポイントをアーティファクトとして保存すれば、それらをRegistryに昇格させることができます。Registryでは以下のことが可能です:
- MLタスクによって最良のモデルバージョンを整理する。
- モデルを集約してチームと共有する。
- モデルをステージングしてプロダクションに展開するか、さらに評価するためにブックマークする。
- 下流のCI/CDプロセスをトリガーする。
保存したモデルをロードするには?
WANDB_LOG_MODELでW&B Artifactsにモデルを保存した場合、追加トレーニングや推論のためにモデルウェイトをダウンロードできます。同じHugging Faceアーキテクチャーにモデルを読み戻すだけです。
チェックポイントからトレーニングを再開するには?
WANDB_LOG_MODEL='checkpoint'を設定していた場合、model_dirをTrainingArgumentsのmodel_name_or_path引数として使用し、Trainerにresume_from_checkpoint=Trueを渡すことでトレーニングを再開できます。
トレーニング中に評価サンプルをログして表示するには?
TransformersTrainerを介してW&Bにログすることは、TransformersライブラリのWandbCallbackによって処理されます。Hugging Faceのログをカスタマイズする必要がある場合は、WandbCallbackをサブクラス化し、Trainerクラスから追加のメソッドを利用する追加機能を追加することにより、このコールバックを変更できます。
以下は、HF Trainerにこの新しいコールバックを追加する際の一般的なパターンであり、さらに下にはW&B Tableに評価出力をログするコード完備の例があります:
トレーニング中に評価サンプルを表示
以下のセクションでは、WandbCallbackをカスタマイズして、モデルの予測を実行し、トレーニング中にW&B Tableに評価サンプルをログする方法を示します。on_evaluateメソッドを使用してeval_stepsごとにログします。
ここでは、トークナイザーを使用してモデル出力から予測とラベルをデコードするためのdecode_predictions関数を書いています。
その後、予測とラベルからpandas DataFrameを作成し、DataFrameにepoch列を追加します。
最後に、DataFrameからwandb.Tableを作成し、それをwandbにログします。
さらに、freqエポックごとに予測をログすることで、ログの頻度を制御できます。
注意: 通常のWandbCallbackとは異なり、このカスタムコールバックはTrainerの初期化時ではなく、Trainerがインスタンス化された後でトレーナーに追加する必要があります。これは、Trainerインスタンスが初期化中にコールバックに渡されるためです。
利用可能な追加のW&B設定は?
Trainerでログされる内容のさらなる設定は、環境変数を設定することで可能です。W&B環境変数の完全なリストはこちらにあります。
| 環境変数 | 使用法 |
|---|---|
WANDB_PROJECT | プロジェクト名を付けます(デフォルトはhuggingface) |
WANDB_LOG_MODEL | モデルチェックポイントをW&Bアーティファクトとしてログします(デフォルトは
|
WANDB_WATCH | モデルの勾配、パラメータ、またはそのいずれもログするかどうかを設定します
|
WANDB_DISABLED | trueに設定すると、ログが完全にオフになります(デフォルトはfalse) |
WANDB_SILENT | trueに設定すると、wandbによって印刷される出力が消音されます(デフォルトはfalse) |
- Command Line
- Notebook
wandb.initをカスタマイズする方法は?
Trainerが使用するWandbCallbackは、Trainerが初期化される際に内部的にwandb.initを呼び出します。代わりに、Trainerが初期化される前にwandb.initを手動で呼び出してrunを設定することもできます。これにより、W&Bのrun設定を完全にコントロールできます。
以下は、initに何を渡すかの例です。wandb.initの使用方法の詳細については、リファレンスドキュメントを参照してください。