始めに
サインアップしてAPIキーを作成
APIキーは、あなたのマシンをW&Bに認証するためのものです。ユーザーのプロフィールからAPIキーを生成できます。よりスムーズな方法として、https://wandb.ai/authorizeに直接アクセスしてAPIキーを生成することができます。表示されたAPIキーをコピーし、パスワードマネージャーなどの安全な場所に保存してください。
- 右上のユーザープロフィールアイコンをクリック。
- User Settings を選択し、API Keys セクションまでスクロール。
- Reveal をクリック。表示されたAPIキーをコピーします。APIキーを非表示にするには、ページを再読み込みしてください。
wandb ライブラリをインストールしてログイン
ローカルでwandb ライブラリをインストールし、ログインするには:
- Command Line
- Python
- Python notebook
-
WANDB_API_KEY環境変数 をあなたのAPIキーに設定します。 -
wandbライブラリをインストールし、ログインします。
メトリクスをログする
プロットを作成する
ステップ1: wandbをインポートして新しいrunを初期化
ステップ2: プロットを可視化する
個別のプロット
モデルをトレーニングし、予測を行った後、wandbでプロットを生成して予測を分析することができます。サポートされているチャートの完全なリストについては、以下のSupported Plotsセクションを参照してください。すべてのプロット
W&B にはplot_classifier などの関数があり、関連する複数のプロットを描画します。
既存のMatplotlibプロット
Matplotlibで作成されたプロットも、W&B ダッシュボードにログすることができます。そのためには、最初にplotly をインストールする必要があります。
サポートされているプロット
学習曲線
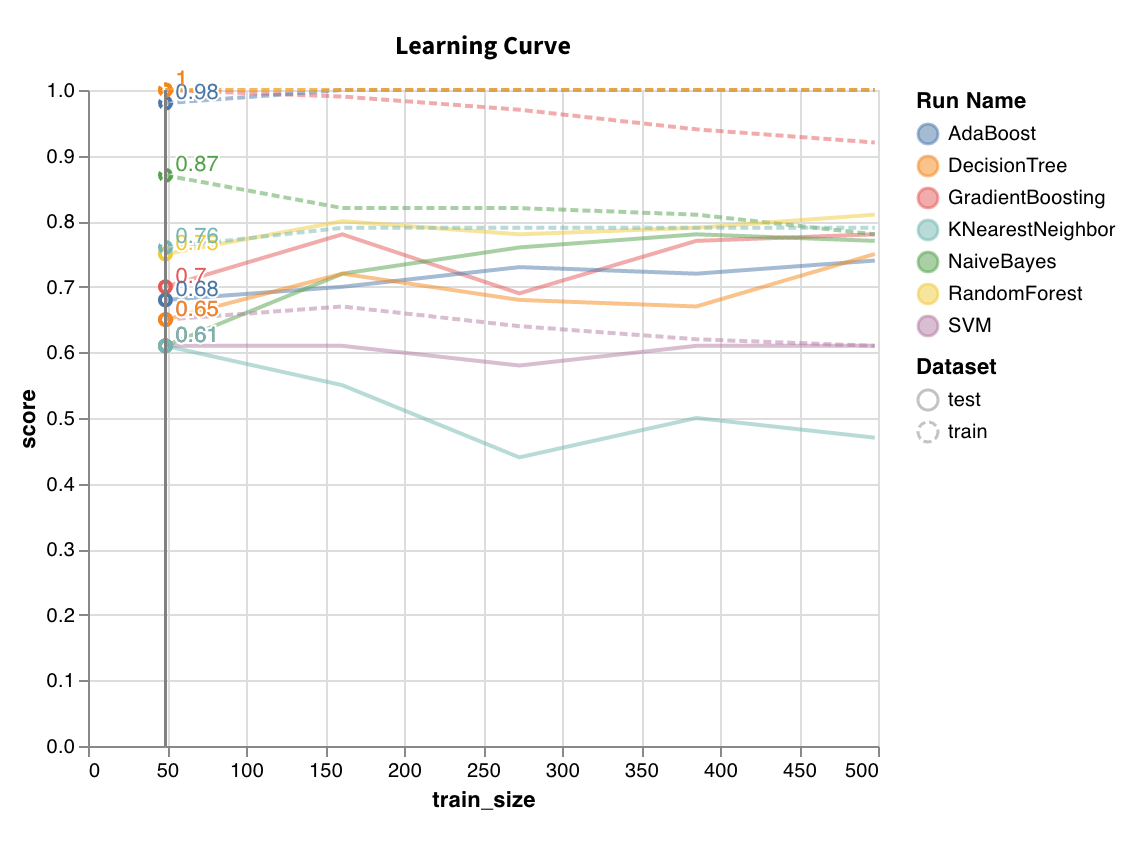
wandb.sklearn.plot_learning_curve(model, X, y)
- model (clf or reg): 学習済みの回帰器または分類器を受け取ります。
- X (arr): データセットの特徴。
- y (arr): データセットのラベル。
ROC
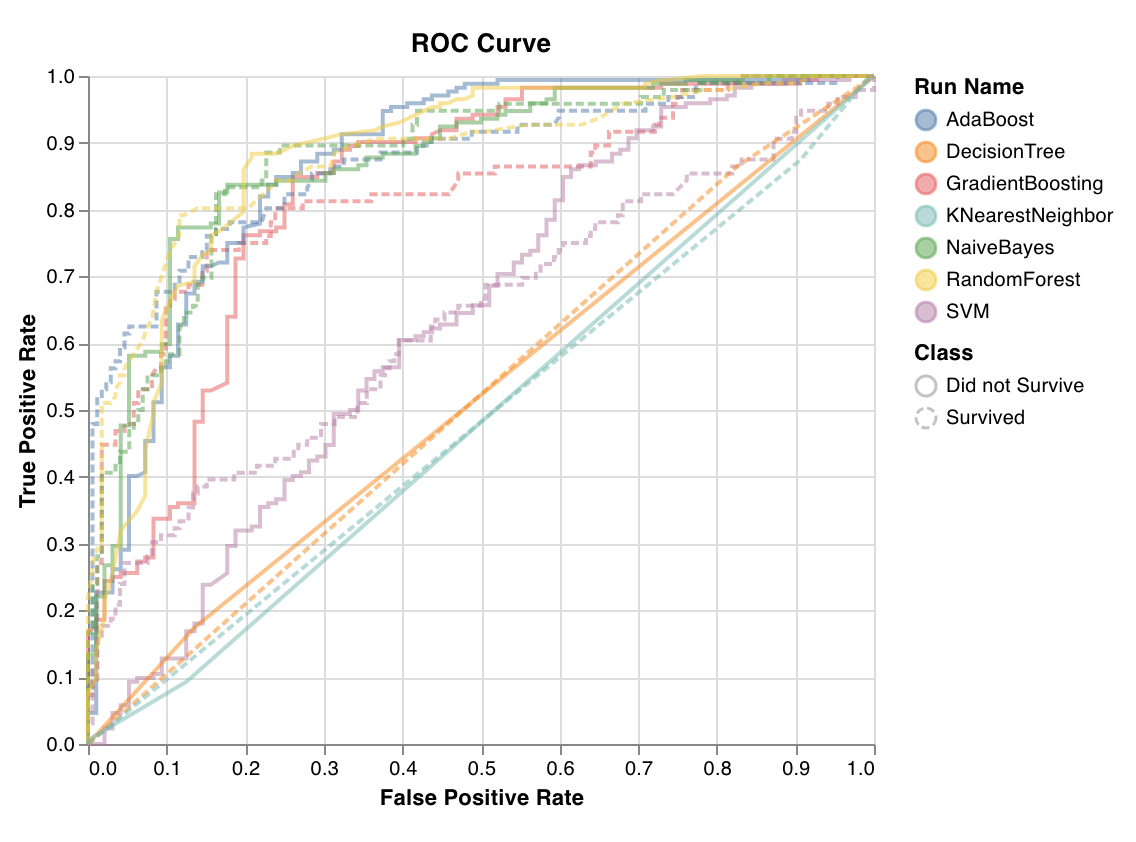
wandb.sklearn.plot_roc(y_true, y_probas, labels)
- y_true (arr): テストセットのラベル。
- y_probas (arr): テストセットの予測確率。
- labels (list): 目標変数 (y) の名前付きラベル。
クラスの割合
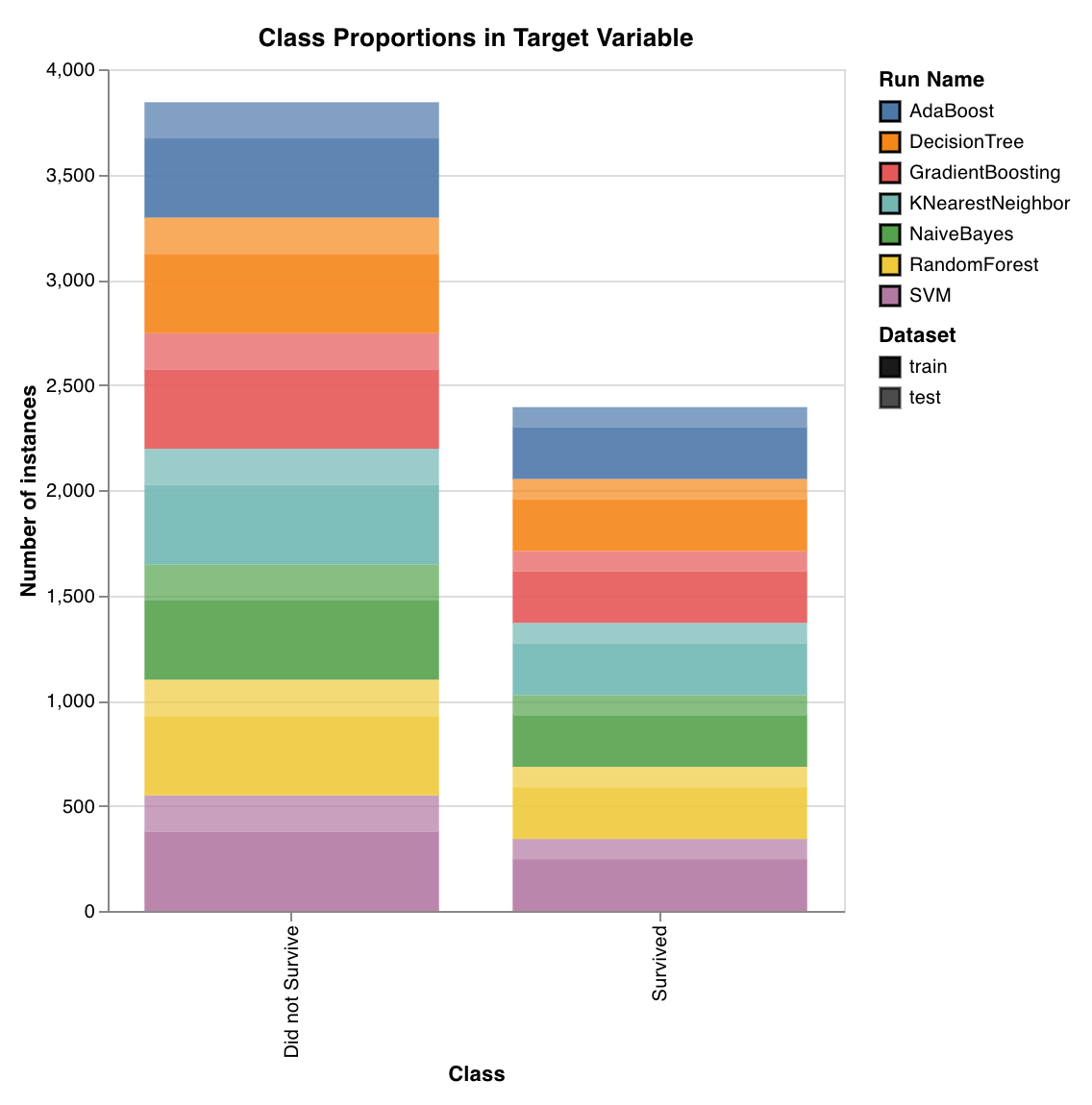
wandb.sklearn.plot_class_proportions(y_train, y_test, ['dog', 'cat', 'owl'])
- y_train (arr): トレーニングセットのラベル。
- y_test (arr): テストセットのラベル。
- labels (list): 目標変数 (y) の名前付きラベル。
精度-再現率曲線
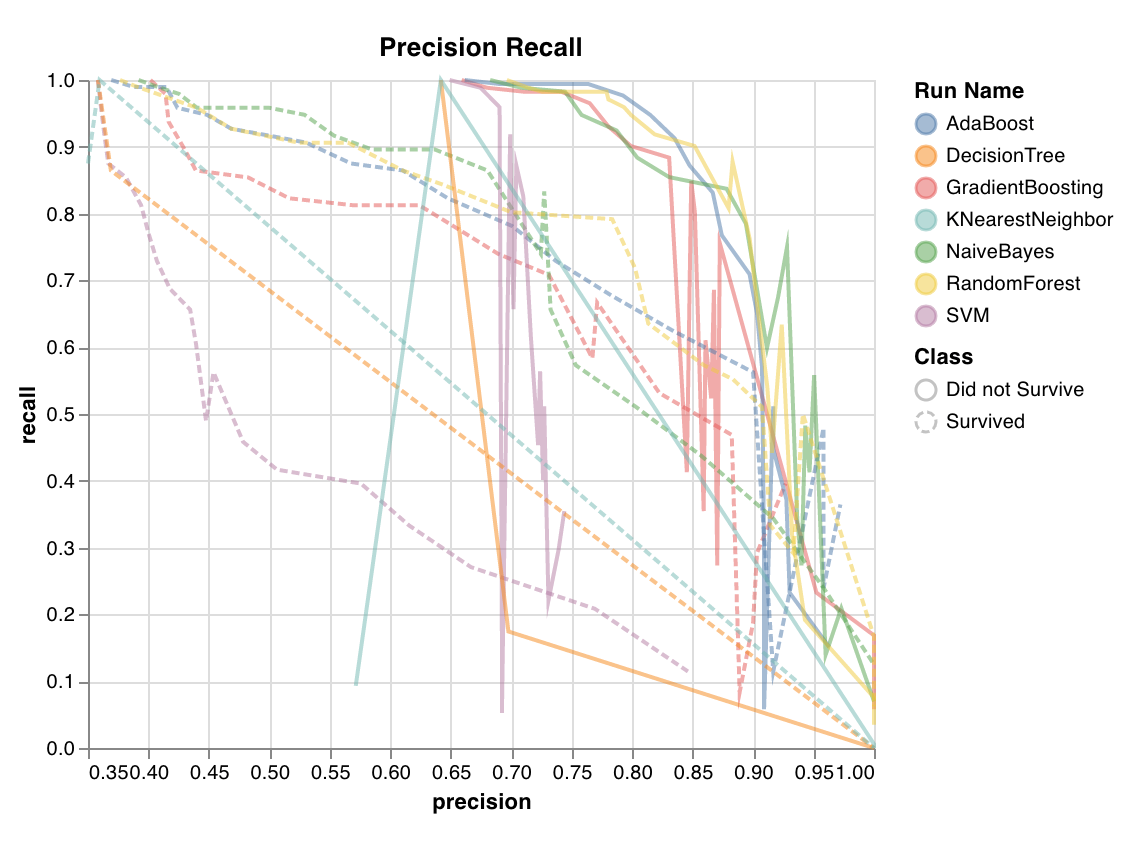
wandb.sklearn.plot_precision_recall(y_true, y_probas, labels)
- y_true (arr): テストセットのラベル。
- y_probas (arr): テストセットの予測確率。
- labels (list): 目標変数 (y) の名前付きラベル。
特徴の重要度
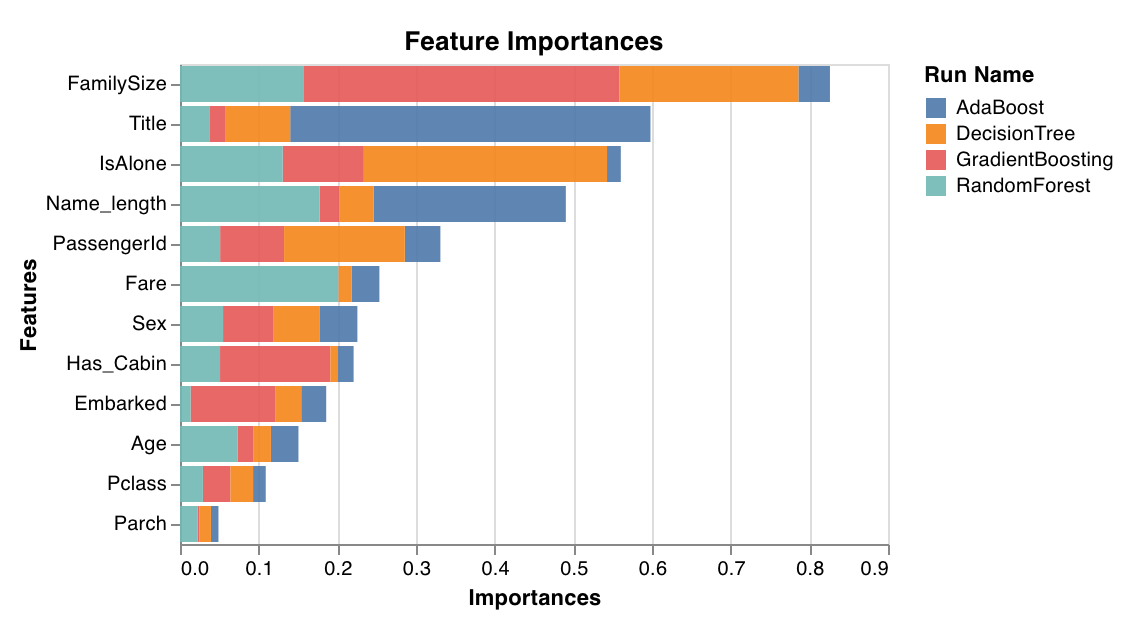
feature_importances_ 属性を持つ分類器でのみ動作します。
wandb.sklearn.plot_feature_importances(model, ['width', 'height', 'length'])
- model (clf): 学習済みの分類器を受け取ります。
- feature_names (list): 特徴の名前。プロット中の特徴のインデックスを対応する名前で置き換えることで読みやすくします。
キャリブレーション曲線
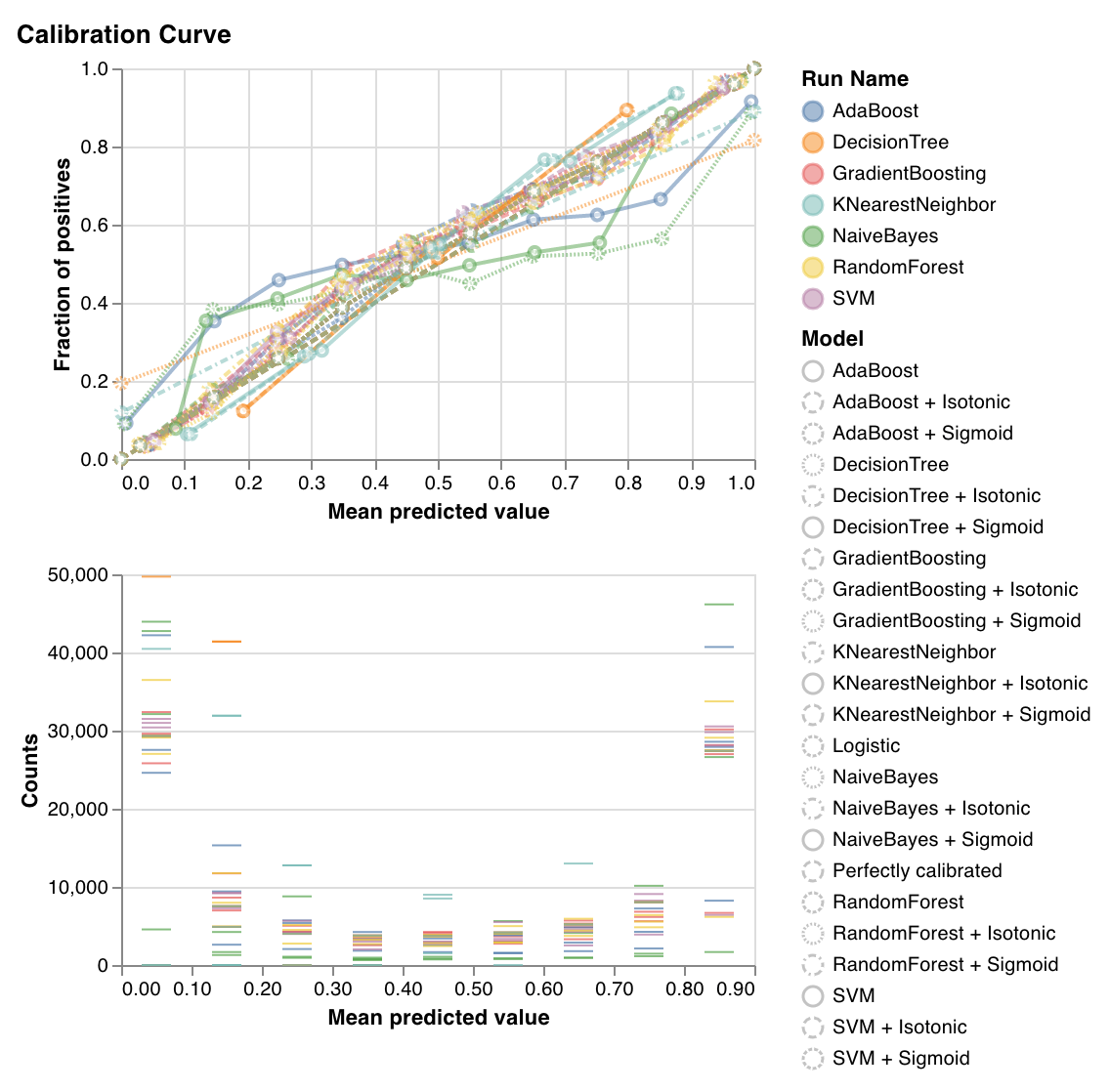
wandb.sklearn.plot_calibration_curve(clf, X, y, 'RandomForestClassifier')
- model (clf): 学習済みの分類器を受け取ります。
- X (arr): トレーニングセットの特徴。
- y (arr): トレーニングセットのラベル。
- model_name (str): モデル名。デフォルトは’Classifier’です。
混同行列
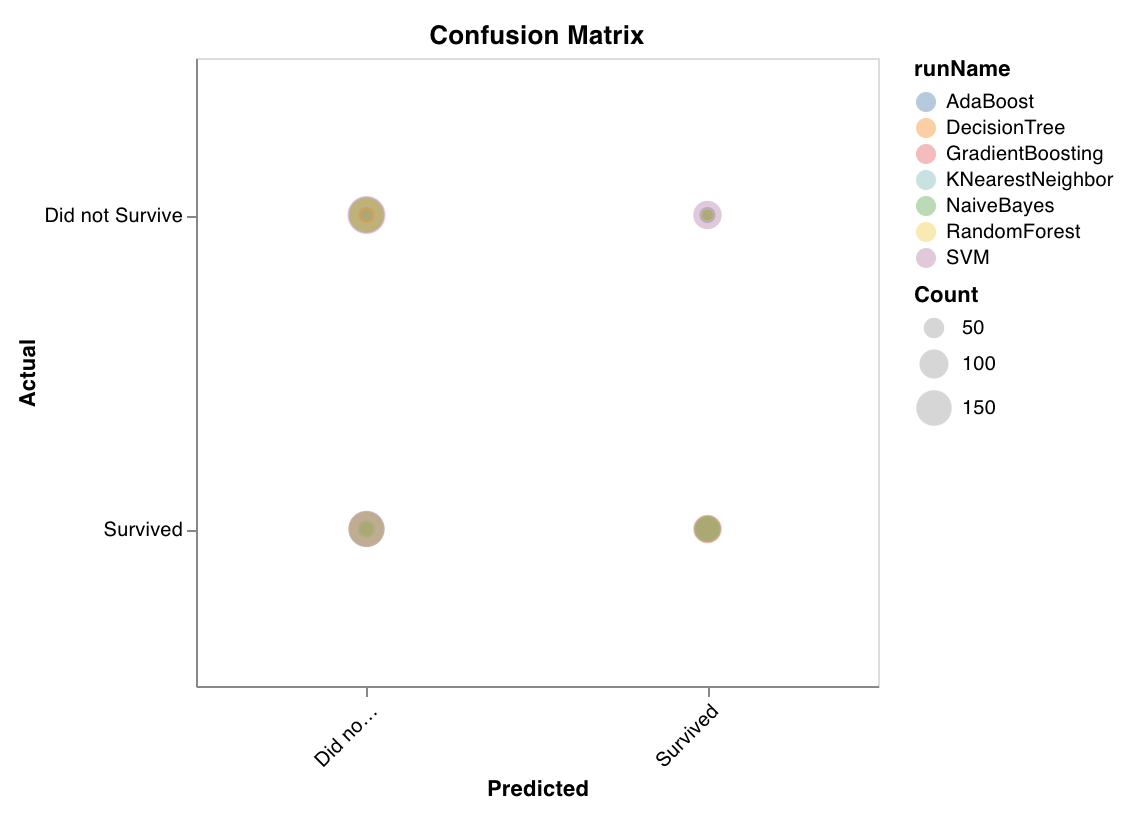
wandb.sklearn.plot_confusion_matrix(y_true, y_pred, labels)
- y_true (arr): テストセットのラベル。
- y_pred (arr): テストセットの予測ラベル。
- labels (list): 目標変数 (y) の名前付きラベル。
サマリーメトリクス
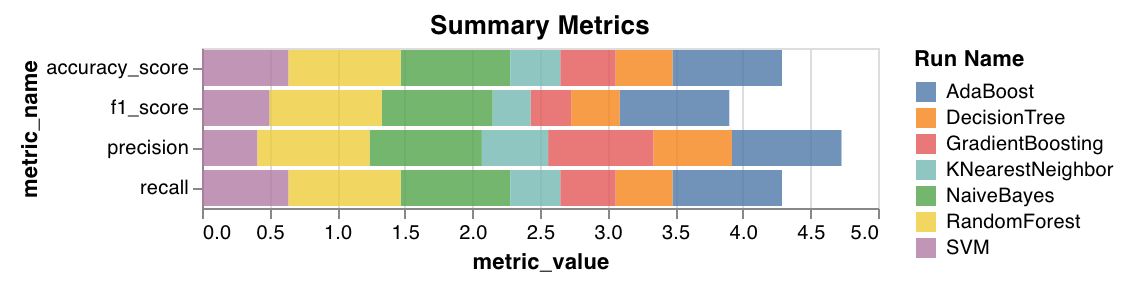
mse、mae、r2スコアなどの分類のサマリーメトリクスを計算します。f1、精度、再現率などの回帰のサマリーメトリクスを計算します。
wandb.sklearn.plot_summary_metrics(model, X_train, y_train, X_test, y_test)
- model (clf or reg): 学習済みの回帰器または分類器を受け取ります。
- X (arr): トレーニングセットの特徴。
- y (arr): トレーニングセットのラベル。
- X_test (arr): テストセットの特徴。
- y_test (arr): テストセットのラベル。
エルボープロット
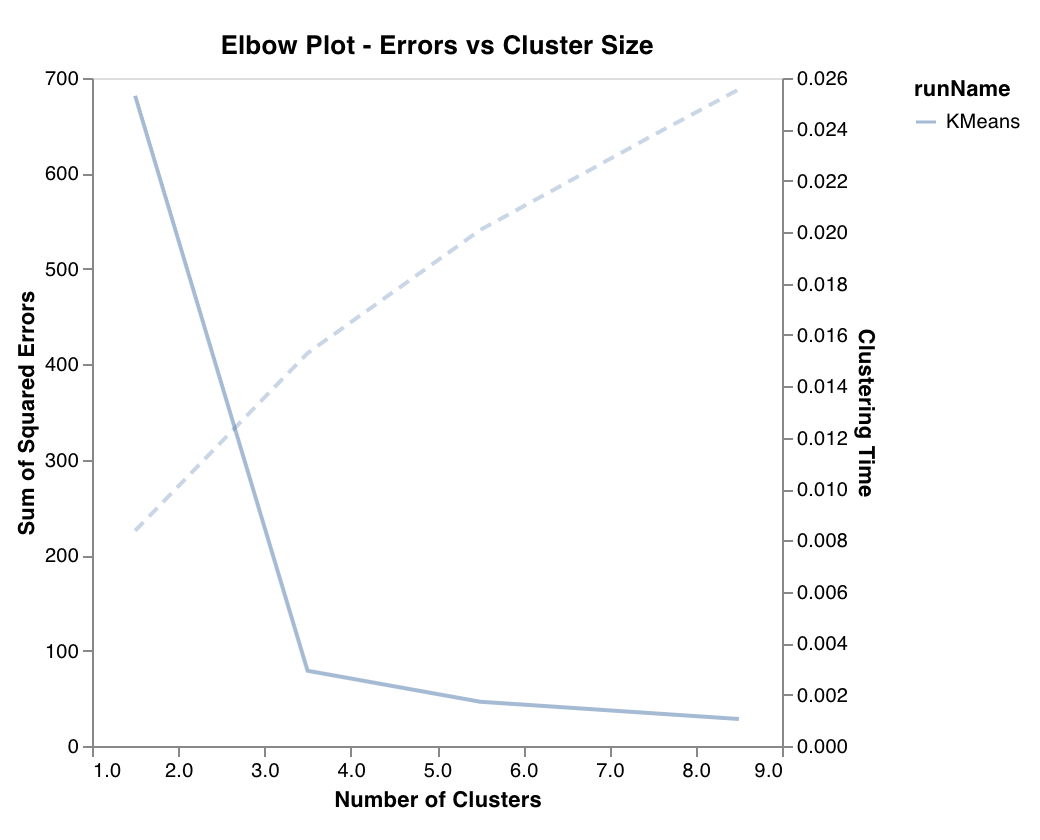
wandb.sklearn.plot_elbow_curve(model, X_train)
- model (clusterer): 学習済みのクラスタリングアルゴリズムを受け取ります。
- X (arr): トレーニングセットの特徴。
シルエットプロット
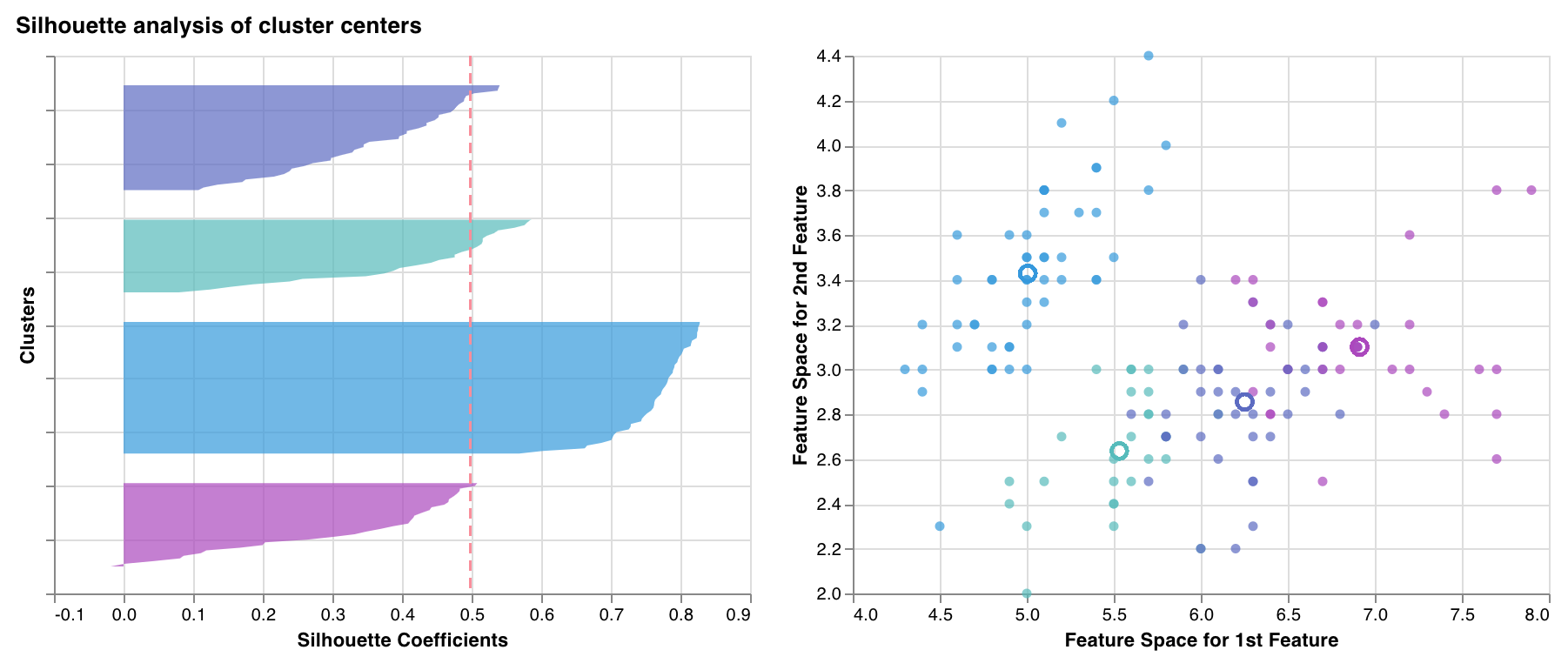
wandb.sklearn.plot_silhouette(model, X_train, ['spam', 'not spam'])
- model (clusterer): 学習済みのクラスタリングアルゴリズムを受け取ります。
- X (arr): トレーニングセットの特徴。
- cluster_labels (list): クラスターラベルの名前。プロット中のクラスターインデックスを対応する名前で置き換え、読みやすくします。
外れ値候補プロット
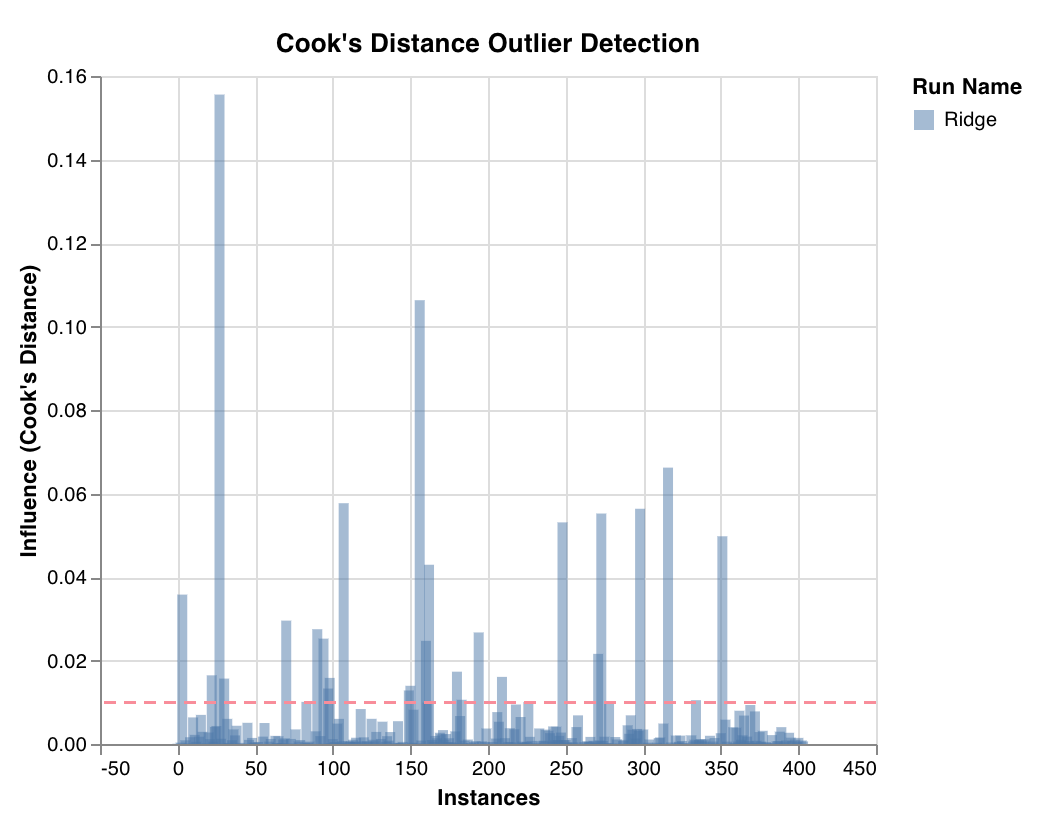
wandb.sklearn.plot_outlier_candidates(model, X, y)
- model (regressor): 学習済みの分類器を受け取ります。
- X (arr): トレーニングセットの特徴。
- y (arr): トレーニングセットのラベル。
残差プロット
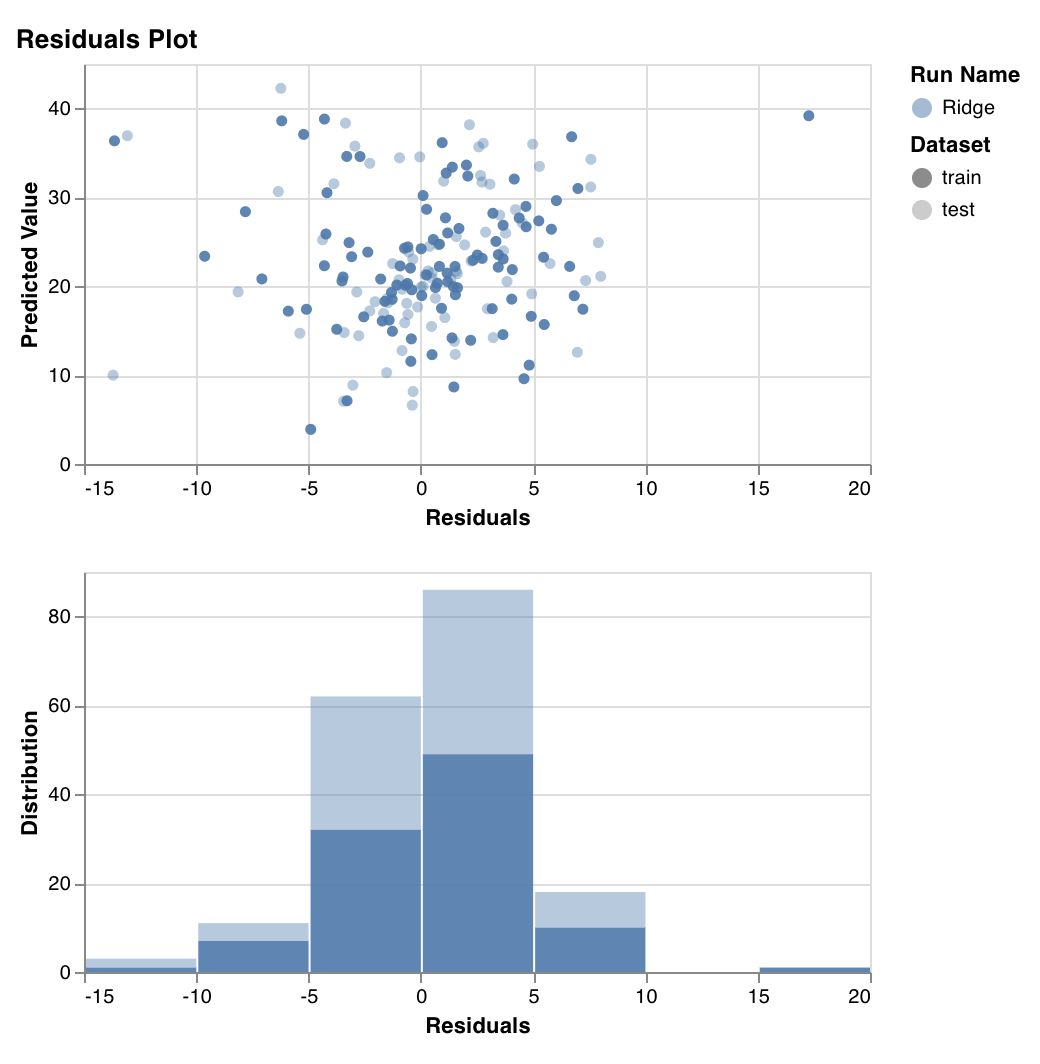
wandb.sklearn.plot_residuals(model, X, y)
- model (regressor): 学習済みの分類器を受け取ります。
- X (arr): トレーニングセットの特徴。
- y (arr): トレーニングセットのラベル。
例
- コラボで実行: 始めるためのシンプルなノートブック