wandb==0.12.11 で利用可能になり、kfp<2.0.0 が必要です。
登録してAPIキーを作成する
より手早く行うには、User Settings にアクセスしてAPIキーを作成してください。APIキーはすぐにコピーし、パスワードマネージャーなどの安全な場所に保存してください。
- 右上にあるユーザープロフィールアイコンをクリックします。
- User Settings を選択し、API Keys セクションまでスクロールします。
wandb ライブラリをインストールしてログインする
wandb ライブラリをローカルにインストールしてログインするには、次の手順に従います。
- コマンドライン
- Python
- Python notebook
-
WANDB_API_KEY環境変数 に APIキーを設定します。<>で囲まれた値はご自身の値に置き換えてください。 -
wandbライブラリをインストールし、ログインします。
コンポーネントをデコレートする
wandb ライブラリをインストールすると、個々のパイプラインコンポーネントで W&B のトラッキングを有効にできるようになります。@wandb_log デコレータを追加し、通常どおりコンポーネントを作成します。これにより、パイプラインを実行するたびに、入力/出力のパラメーターとアーティファクトが自動的に W&B にログされます。
コンテナーに環境変数を渡す
WANDB_KUBEFLOW_URL に Kubeflow Pipelines インスタンスのベース URL も設定してください。たとえば、https://kubeflow.mysite.com です。
データにプログラムでアクセスする
Kubeflow Pipelines UI
- Input/Output タブと ML Metadata タブで、入力と出力の詳細を確認できます。
- Visualizations タブから W&B Web アプリを表示できます。
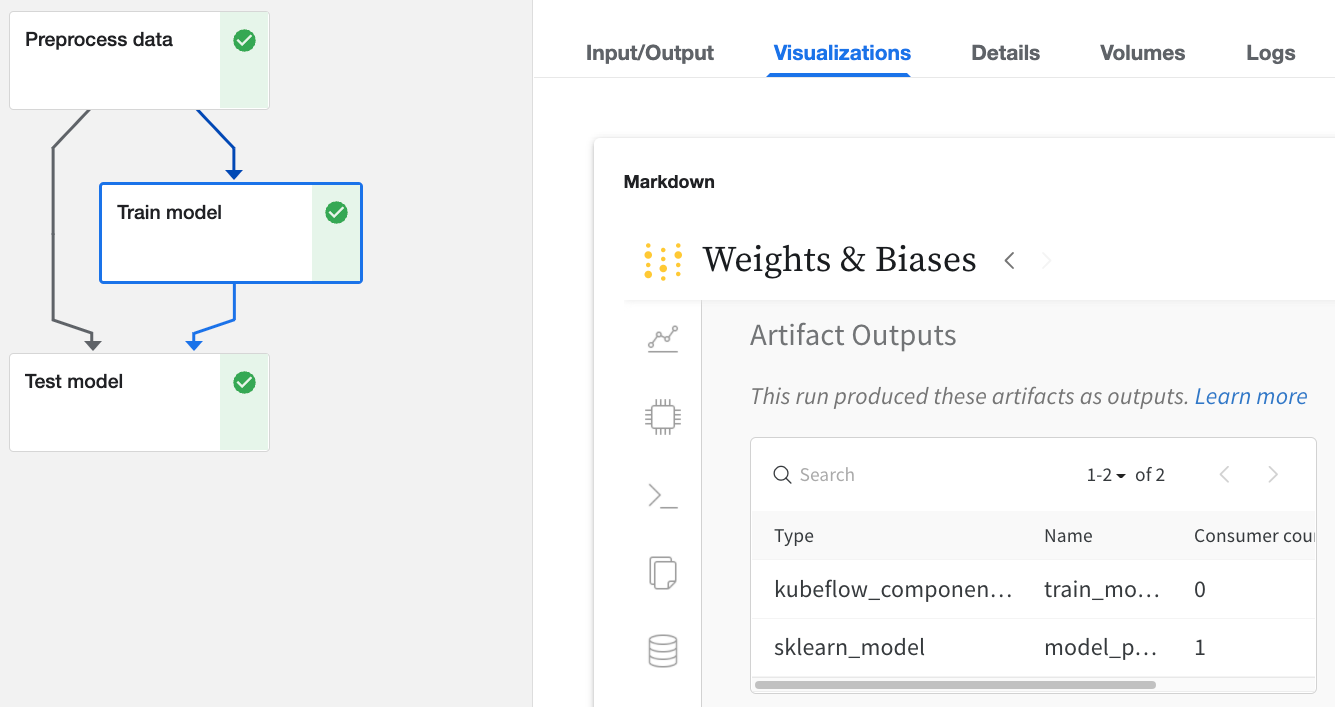
W&B Web アプリ UI
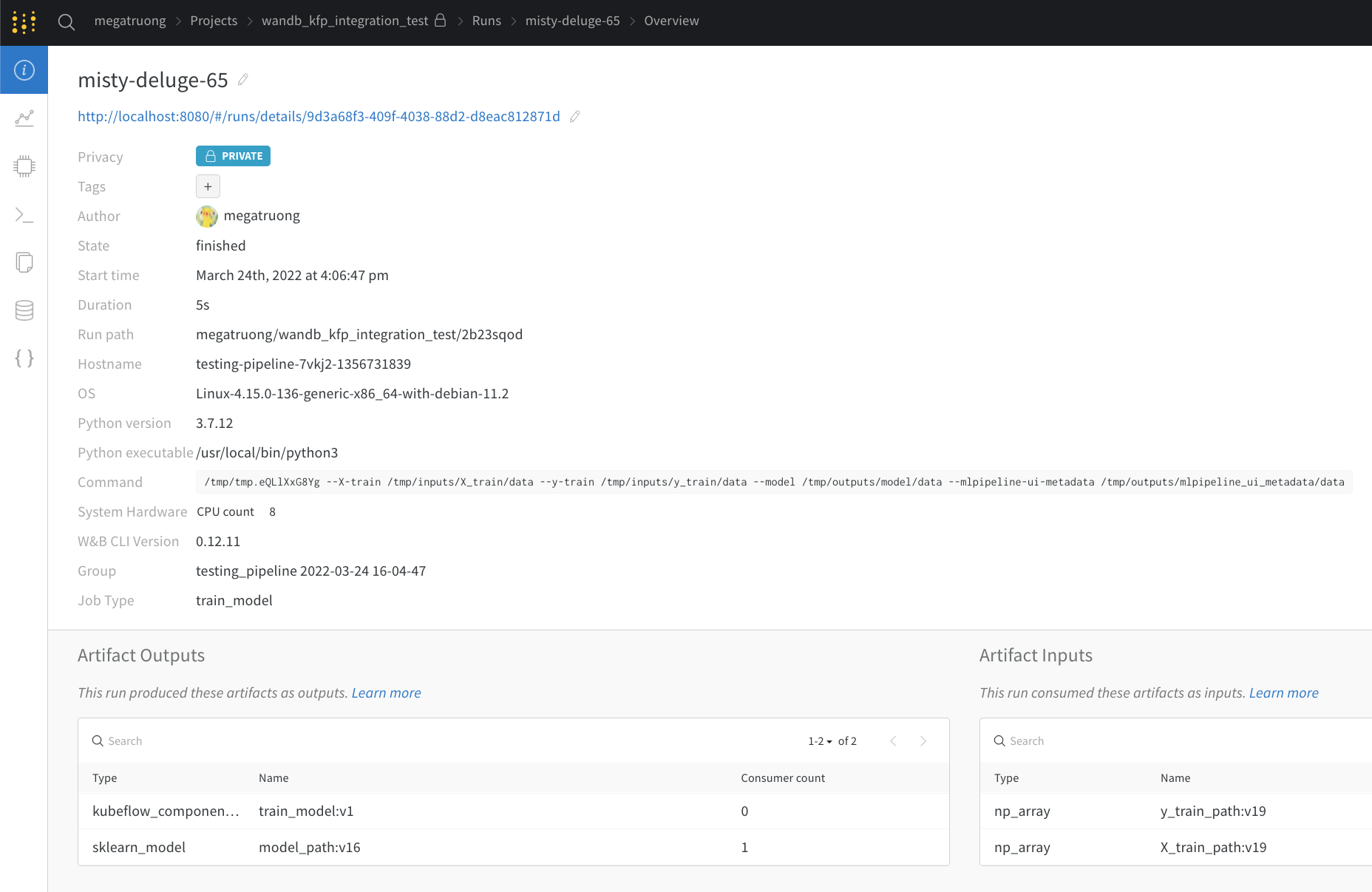
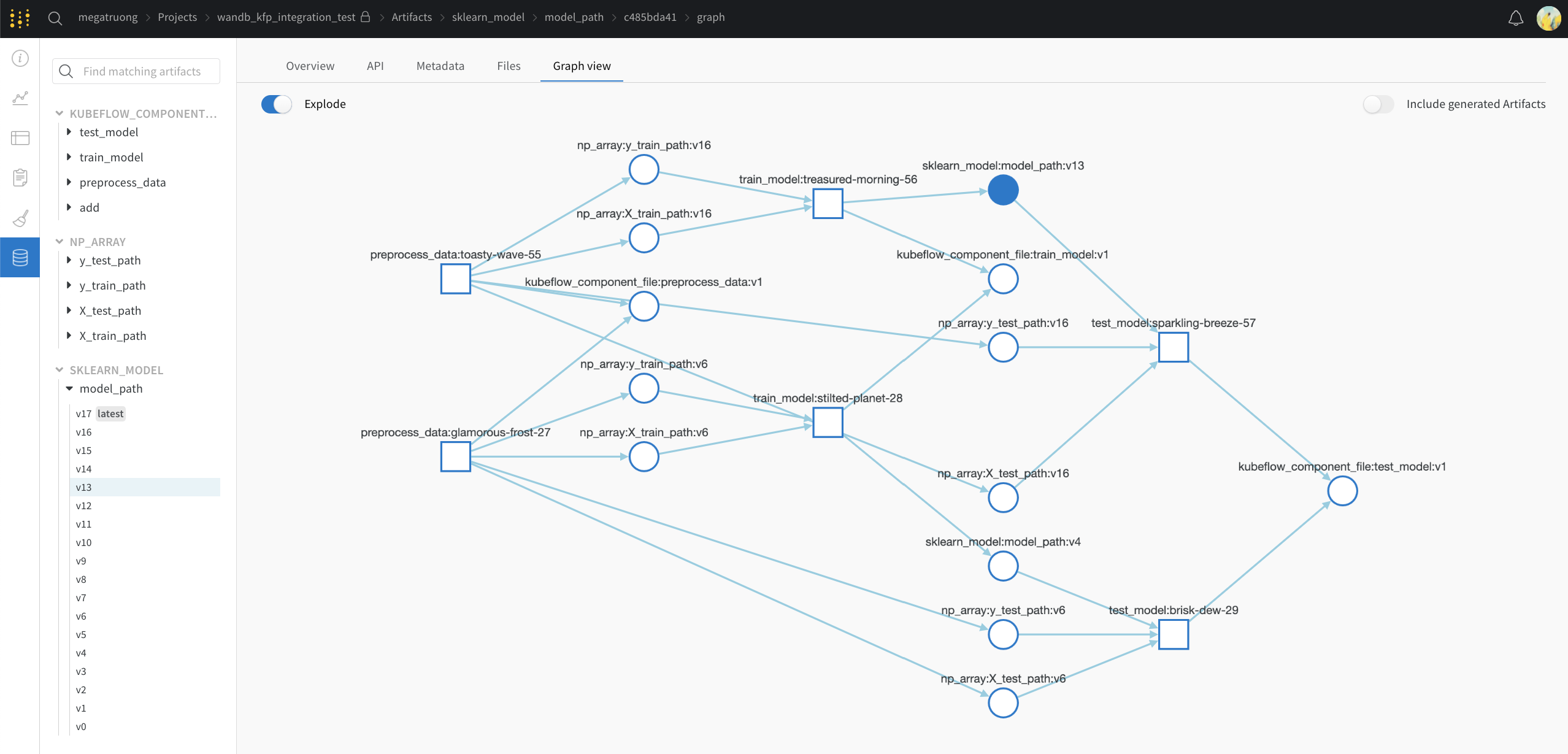
Public API
Kubeflow Pipelines と W&B の概念対応
より細かなログ制御
@wandb_log デコレータは入力と出力を自動的に処理しますが、各エポックにわたるトレーニング メトリクスなどの中間値は取得しません。ログをより細かく制御したい場合は、コンポーネント内で wandb.log() と wandb.log_artifact() を適宜呼び出せます。
wandb.log_artifact() を明示的に呼び出す
@wandb_log デコレータは、関連する入力と出力を自動的にトラッキングします。トレーニングプロセスもログしたい場合は、次のようにそのログを明示的に追加できます。