Try in Colab

このノートブックでカバーする内容
PyTorch のコードに Weights & Biases を統合して、実験管理をパイプラインに追加する方法を示します。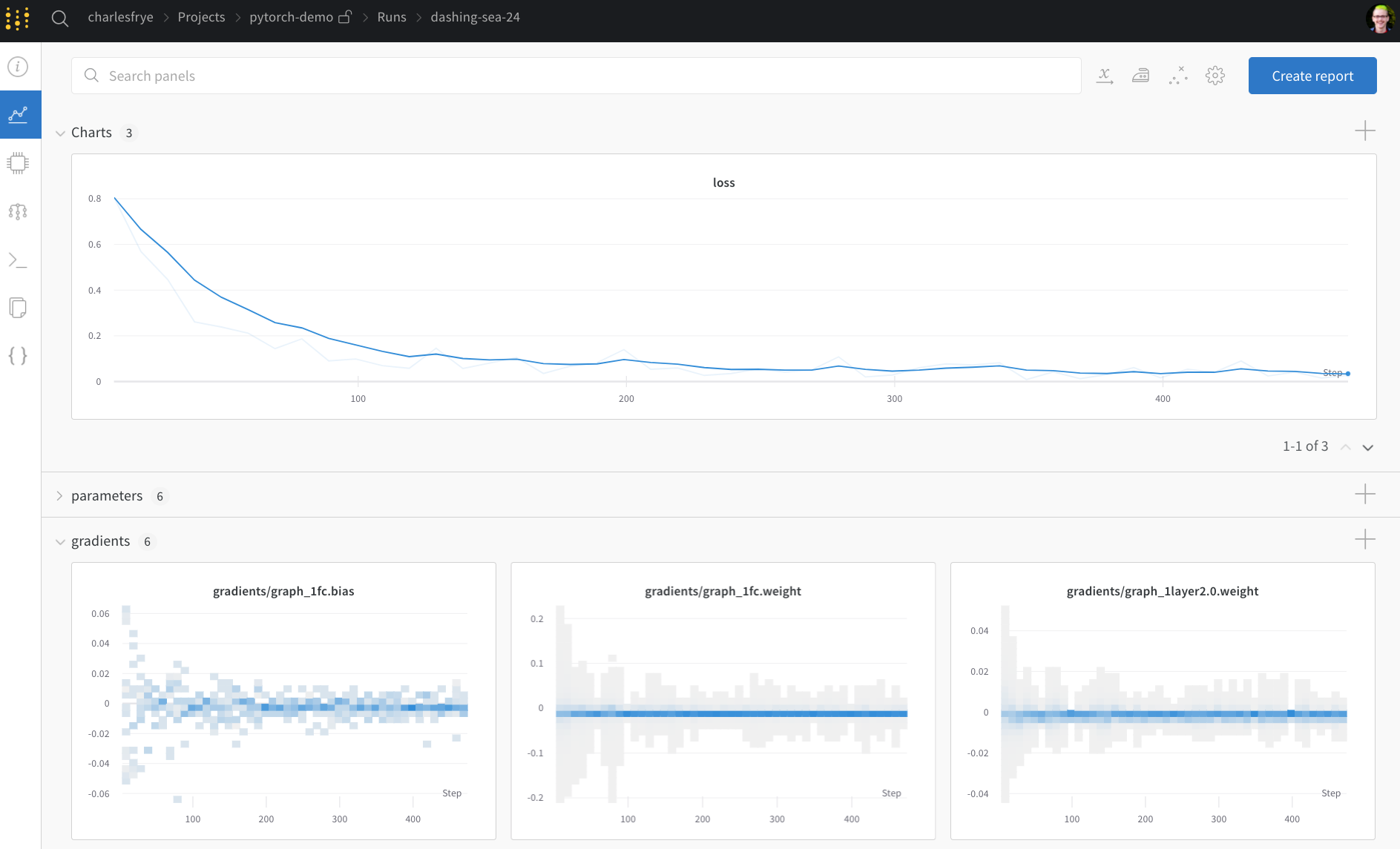
インストール、インポート、ログイン
ステップ 0: W&B をインストール
まずは、このライブラリを入手する必要があります。wandb は pip を使用して簡単にインストールできます。
ステップ 1: W&B をインポートしてログイン
データをウェブサービスにログするためには、 ログインが必要です。 W&B を初めて使用する場合は、 表示されるリンクから無料アカウントに登録する必要があります。実験とパイプラインを定義
wandb.init でメタデータとハイパーパラメータを追跡
プログラム上、最初に行うのは実験を定義することです。
ハイパーパラメータとは何か?この run に関連するメタデータは何か?
この情報を config 辞書(または類似オブジェクト)に保存し、
必要に応じてアクセスするのは非常に一般的なワークフローです。
この例では、数少ないハイパーパラメータのみを変動させ、
残りを手動でコーディングします。
しかし、あなたのモデルのどの部分も config の一部にすることができます。
また、いくつかのメタデータも含めます:私たちは MNIST データセットと畳み込み
ニューラルネットワークを使用しているので、
同じプロジェクトで、たとえば全結合ニューラルネットワークで CIFAR を扱う場合、
この情報が run を分ける助けになります。
- まず、モデル、関連するデータ、オプティマイザーを
makeし、 - それに基づいてモデルを
trainし、最後に - トレーニングがどのように行われたかを確認するために
testします。
wandb.init のコンテキスト内で行われる点です。
この関数を呼び出すことで、
コードとサーバーとの間に通信のラインが確立されます。
config 辞書を wandb.init に渡すことで、
すべての情報が即座にログされるため、
実験に使用するハイパーパラメータの値を常に把握できます。
選んでログした値が常にモデルに使用されることを保証するために、
wandb.config のオブジェクトコピーを使用することをお勧めします。
以下で make の定義をチェックして、いくつかの例を見てください。
サイドノート: コードを別々のプロセスで実行するようにします、
私たちの側で問題があっても
(たとえば、巨大な海の怪物がデータセンターを攻撃した場合でも)
コードはクラッシュしません。
問題が解決したら、クラーケンが深海に戻る頃に、
wandb sync でデータをログできます。
データのロードとモデルを定義
次に、データがどのようにロードされるか、およびモデルの見た目を指定する必要があります。 これは非常に重要な部分ですが、wandb なしで通常行われるのと何も違いませんので、
ここで詳しくは説明しません。
wandb でも何も変わらないので、
標準的な ConvNet アーキテクチャーにとどまりましょう。
この部分をいじっていくつかの実験を試みるのを恐れないでください —
あなたの結果はすべて wandb.ai にログされます。
トレーニングロジックを定義
model_pipeline を進めると、train の指定を行う時がきます。
ここでは wandb の 2 つの関数、watch と log が活躍します。
wandb.watch で勾配を追跡し、他のすべてを wandb.log で管理
wandb.watch はトレーニングの log_freq ステップごとに
モデルの勾配とパラメータをログします。
トレーニングを開始する前にこれを呼び出すだけで済みます。
トレーニングコードの残りは前と変わらず、
エポックとバッチを繰り返し、
forward pass と backward pass を実行し、
optimizer を適用します。
wandb.log に同じ情報を渡します。
wandb.log は文字列をキーとする辞書を期待します。
これらの文字列は、ログされるオブジェクトを識別し、値を構成します。
また、オプションでトレーニングのどの step にいるかをログできます。
サイドノート: 私はモデルが見た例の数を使用するのが好きです、
これはバッチサイズを超えて比較しやすくなるためですが、
生のステップやバッチカウントを使用することもできます。
長いトレーニングランの場合、epoch 単位でログすることも理にかなっているかもしれません。
テストロジックを定義
モデルのトレーニングが完了したら、テストしてみましょう: 本番環境から新たなデータに対して実行したり、 手作業で準備した例に適用したりします。(オプション) wandb.save を呼び出す
この時点で、モデルのアーキテクチャと最終パラメータをディスクに保存するのも良い時です。
最大の互換性を考慮して、モデルを
Open Neural Network eXchange (ONNX) フォーマット でエクスポートします。
そのファイル名を wandb.save に渡すことで、モデルのパラメータが W&B のサーバーに保存されます:
もはやどの .h5 や .pb がどのトレーニングrunに対応しているのかを見失うことはありません。
モデルの保存、バージョン管理、配布のための、高度な wandb 機能については、
Artifacts ツールをご覧ください。
トレーニングを実行し、wandb.ai でライブメトリクスを確認
さて、全体のパイプラインを定義し、数行の W&B コードを追加したら、 完全に追跡された実験を実行する準備が整いました。 いくつかのリンクを報告します: ドキュメンテーション、 プロジェクトページ、これにはプロジェクトのすべての run が整理されています。 この run の結果が保存されるランページ。 ランページに移動して、これらのタブを確認:- Charts、トレーニング中にモデルの勾配、パラメーター値、損失がログされます
- System、ここにはディスク I/O 応答率、CPU および GPU メトリクス(温度上昇も監視)、その他のさまざまなシステムメトリクスが含まれます
- Logs、トレーニング中に標準出力にプッシュされたもののコピーがあります
- Files、トレーニングが完了すると、
model.onnxをクリックして Netron モデルビューア でネットワークを表示できます。
with wandb.init ブロック終了時にランが終了すると、
結果の要約もセルの出力で印刷されます。
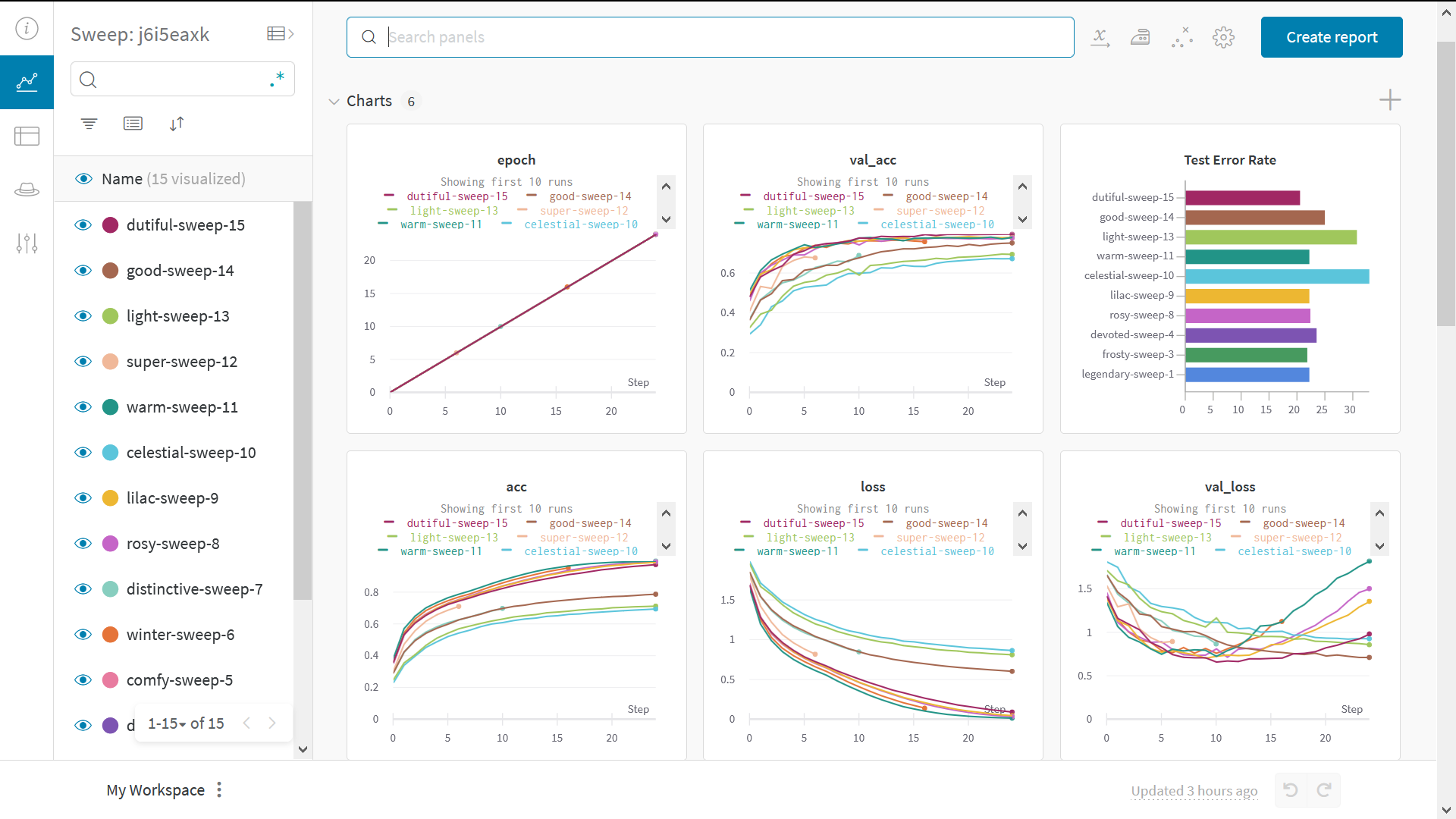
ハイパーパラメータをスイープでテスト
この例では、ハイパーパラメータのセットを 1 つしか見ていません。 しかし、ほとんどの ML ワークフローの重要な部分は、 多くのハイパーパラメータを反復することです。 Weights & Biases Sweeps を使用してハイパーパラメータのテストを自動化し、モデルと最適化戦略の空間を探索できます。W&B Sweeps を使用した PyTorch におけるハイパーパラメータ最適化をチェック
Weights & Biases を使用したハイパーパラメータ探索です。非常に簡単です。たった3つの簡単なステップがあります:- スイープを定義する: これは、検索するパラメータ、検索戦略、最適化メトリクスなどを指定する辞書またはYAML ファイルを作成することで行います。
-
スイープを初期化する:
sweep_id = wandb.sweep(sweep_config) -
スイープエージェントを実行する:
wandb.agent(sweep_id, function=train)