Weave로 모델 평가하기
모델 평가의 주요 기능
- Scorer와 평가자: 정확성, 관련성, 일관성 등을 평가하기 위한 사전 제공 및 맞춤형 평가 메트릭
- 평가 데이터셋: 체계적인 평가를 위한 정답이 포함된 구조화된 테스트 세트
- 모델 버전 관리: 모델의 여러 버전을 추적하고 비교
- 상세 트레이싱: 전체 입력/출력 트레이스로 모델 동작을 디버그
- 비용 추적: 평가 전반에서 API 비용과 토큰 사용량을 모니터링
시작하기: W&B 레지스트리의 모델 평가하기
W&B Models와 Weave 평가 통합하기
- 레지스트리에서 모델 로드: W&B Models 레지스트리에 저장된 파인튜닝된 모델을 다운로드합니다
- 평가 파이프라인 생성: 맞춤형 Scorer를 사용해 포괄적인 평가를 구성합니다
- 결과를 W&B에 다시 로깅: 평가 메트릭을 모델 run에 연결합니다
- 평가된 모델 버전 관리: 개선된 모델을 레지스트리에 다시 저장합니다
Weave의 고급 특성
맞춤형 Scorer와 평가자
일괄 평가
다음 단계
테이블을 사용해 모델 평가하기
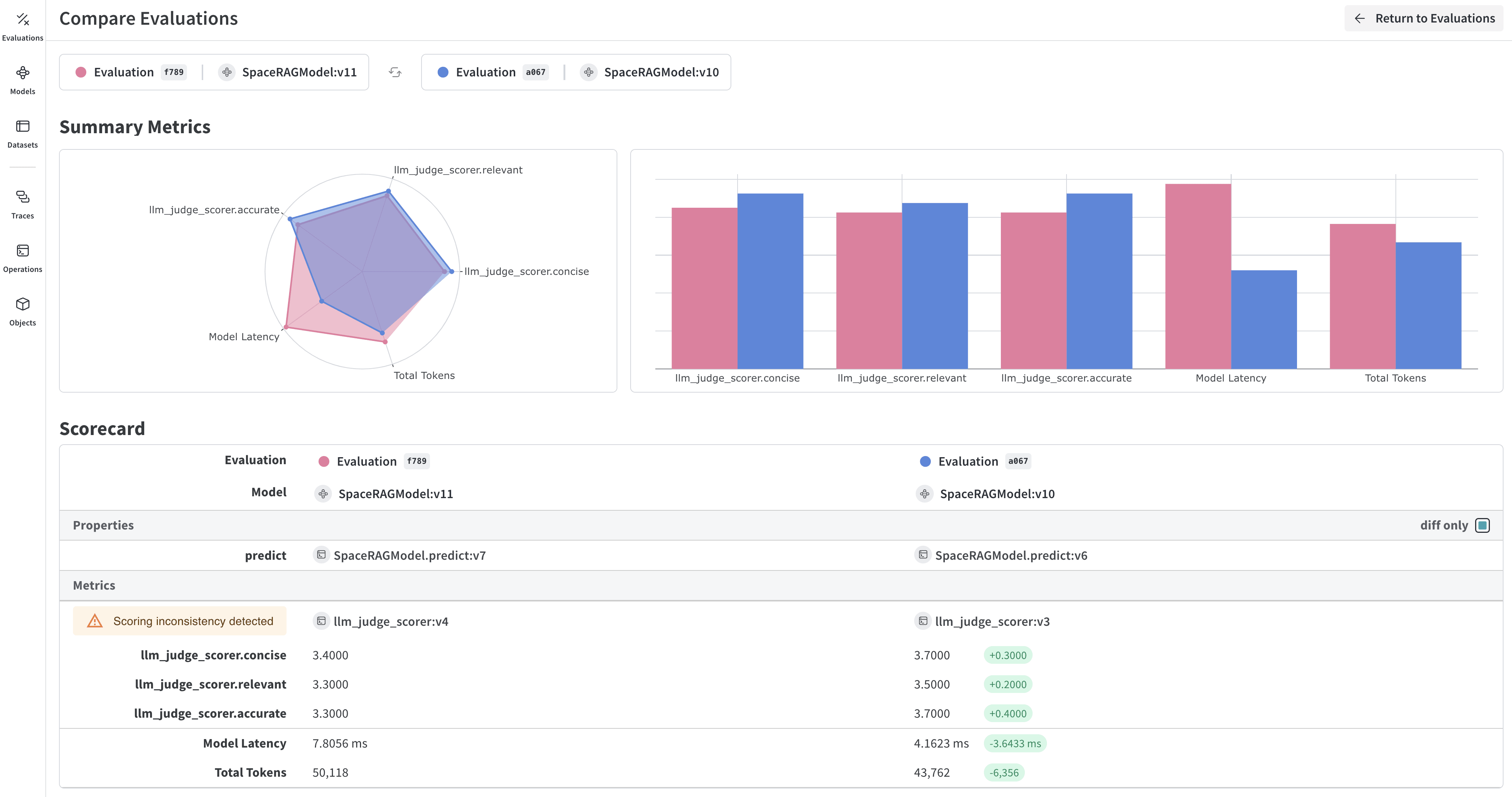
- 모델 예측 비교: 동일한 테스트 세트에서 여러 모델의 성능을 나란히 비교해 볼 수 있습니다
- 예측 변화 추적: 트레이닝 에포크 또는 모델 버전에 따라 예측이 어떻게 달라지는지 모니터링합니다
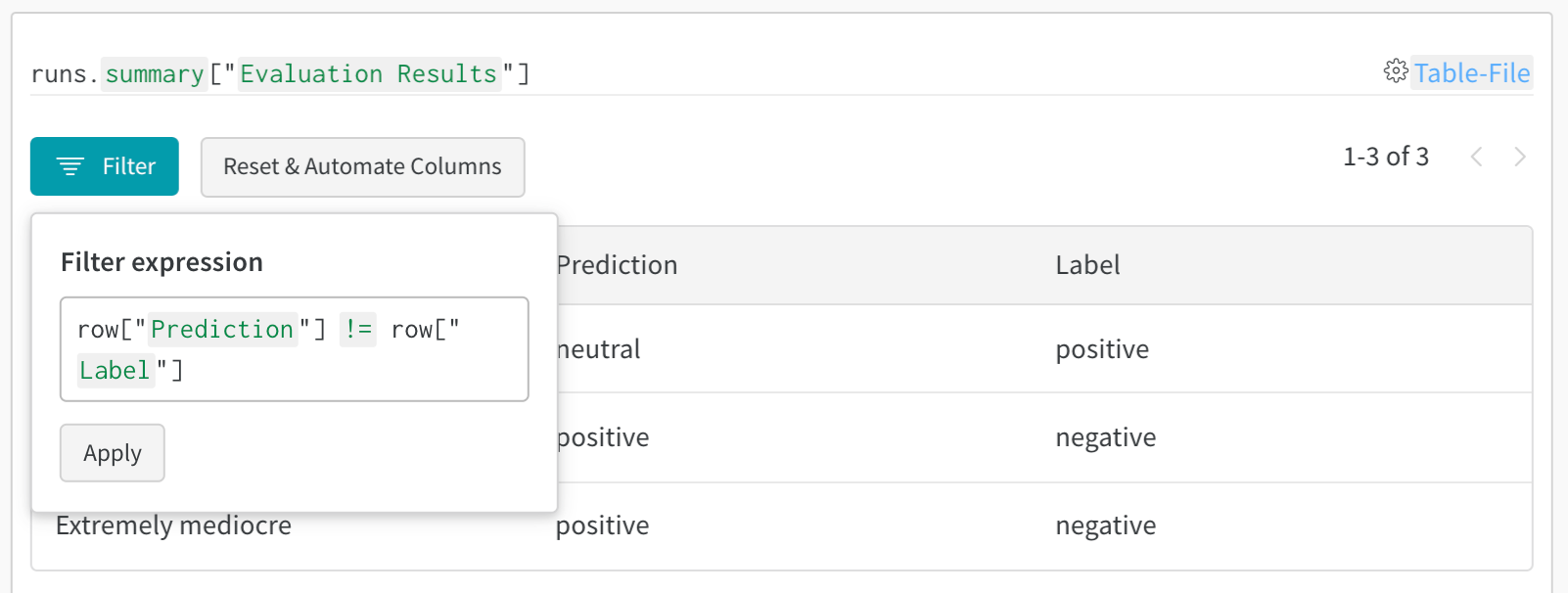
- 오류 분석: 필터와 쿼리를 사용해 자주 오분류되는 예시와 오류 패턴을 찾습니다
- 리치 미디어 시각화: 이미지, Audio, 텍스트 및 기타 미디어 유형을 예측 및 메트릭과 함께 표시합니다
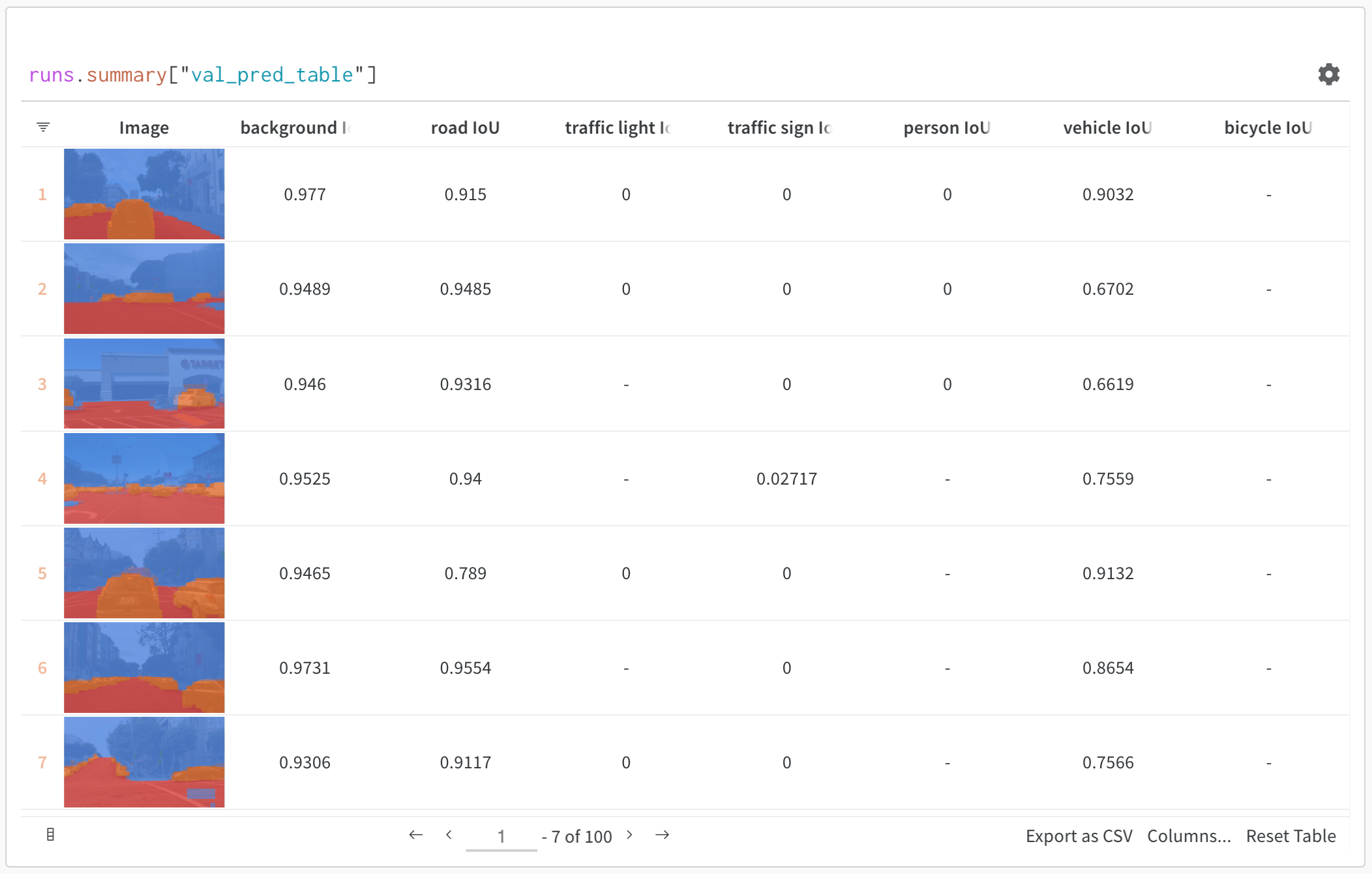
기본 예시: 평가 결과 로깅하기
고급 테이블 워크플로
여러 모델 비교
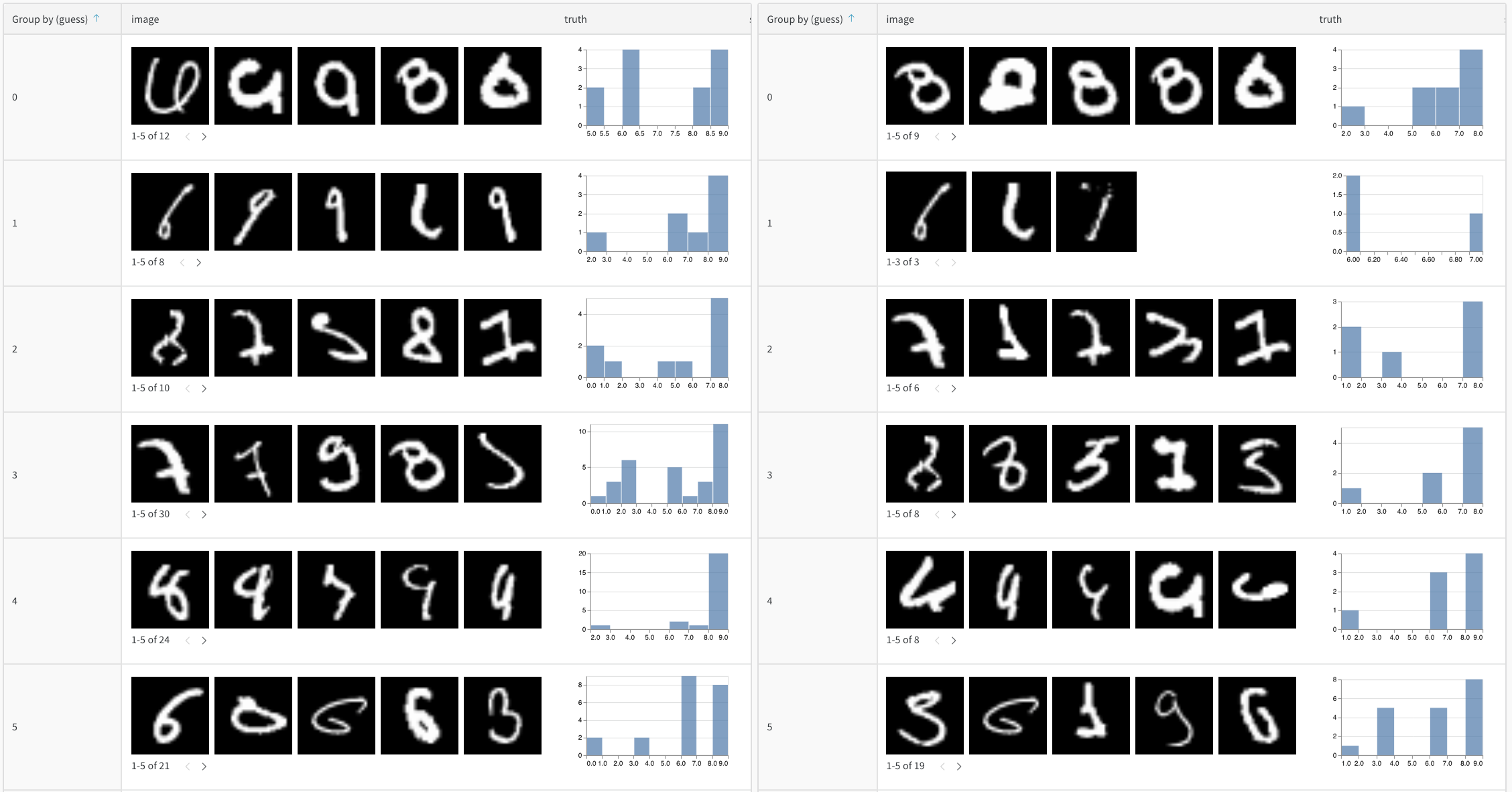
시간 경과에 따른 예측 추적
W&B UI에서 대화형 분석
- 결과 필터링: 열 헤더를 클릭해 예측 정확도, 신뢰도 임계값 또는 특정 클래스 기준으로 필터링합니다
- 테이블 비교: 여러 테이블 버전을 선택해 나란히 비교합니다
- 데이터 쿼리: 쿼리 바를 사용해 특정 패턴을 찾습니다(예:
"correct" = false AND "confidence" > 0.8) - 그룹화 및 집계: 예측 클래스별로 그룹화해 클래스별 정확도 메트릭을 확인합니다